3 步上手
前提条件:请先在 https://console.suanli.cn 完成注册和登录
3 步快速上手流程:
一共有两种方法:利用我们预制的镜像快速发布任务和使用用户自定义打包的镜像发任务
1 用预制镜像发任务
1.1 第一步:新增部署任务
进入新增部署任务界面:https://console.suanli.cn/serverless/create
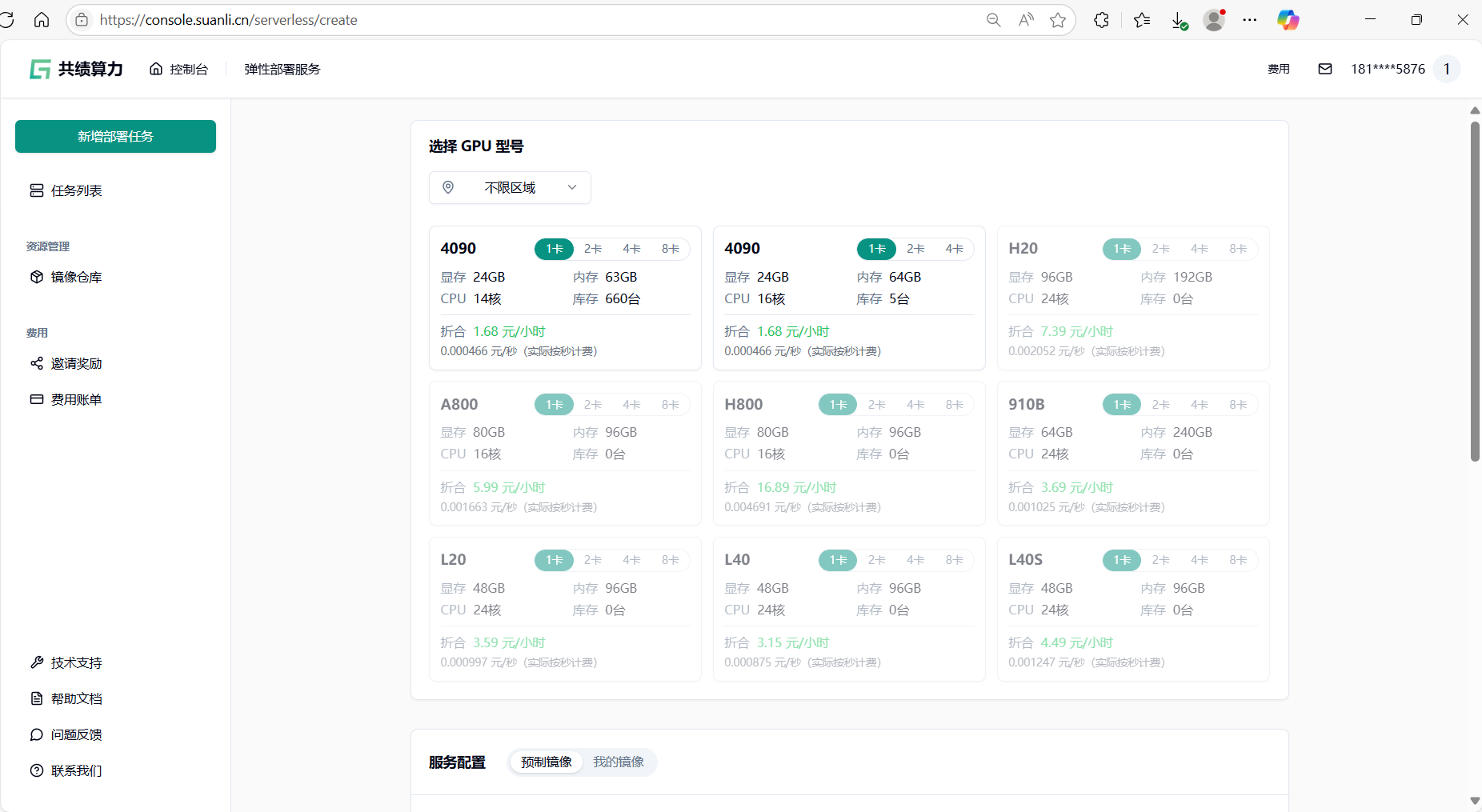
1.2 第二步:填写任务信息
1.2.1 选择资源
根据您的需要筛选 GPU,包括所在区域、显存要求、CPU 核心数、内存大小等。
选择 GPU 型号:推荐选择不限区域——享受全国闲置算力资源 随取随用
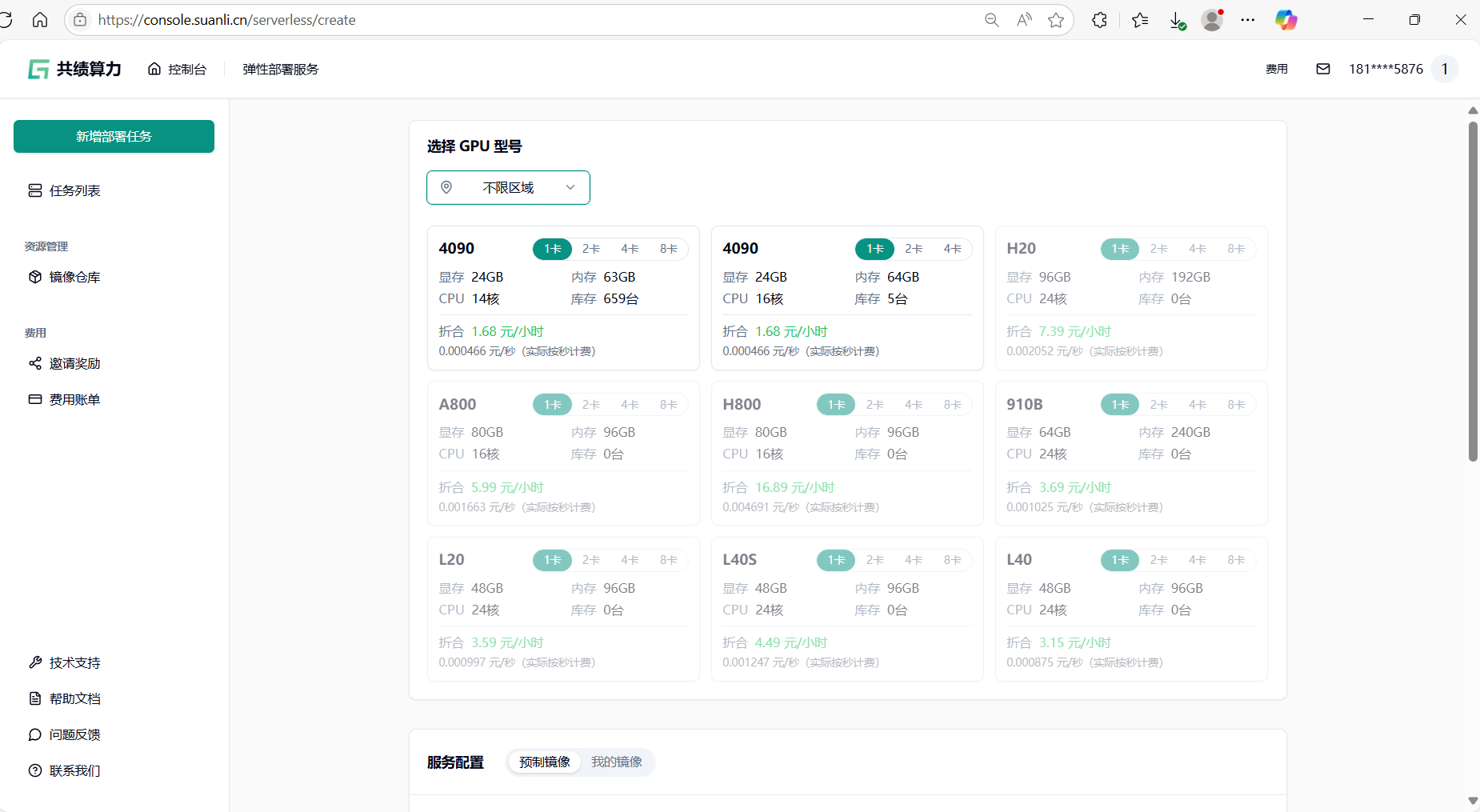
GPU 型号推荐配置:随便选
显存完全达标:
- 图片中所有型号单卡均提供 24GB 以上显存,远超服务部署启动的要求,无需担心显存不足。
性价比与灵活性:
- 1 卡配置:每小时仅需 1.68 元,按秒计费(0.000446 元/秒),适合短期测试或常规任务。
- 库存充足:1 卡版本库存多台,无需等待,快速部署。
- 多卡选项备用:若未来需要分布式训练或高并发任务,可随时切换 2 卡/4 卡。
- 简化选择逻辑:
- 无特殊需求:如果只是运行文档镜像中的常规任务(如模型推理、数据处理),单卡性能完全足够。
- 兼容性无忧:镜像仓库默认适配主流 GPU 型号(如 4090),无需额外调试。
操作建议
- 随便选 直接勾选「4090(1 卡)」+「1 个节点」,填写服务名称(如
demo-test-2025),快速完成部署。 - 进阶场景:仅当需要训练大模型(如 LLM、多模态)时,再考虑 2 卡/4 卡配置。
图片中的配置均为“无坑选项”,闭眼选 1 卡即可开箱即用,成本可控,资源立即可用。
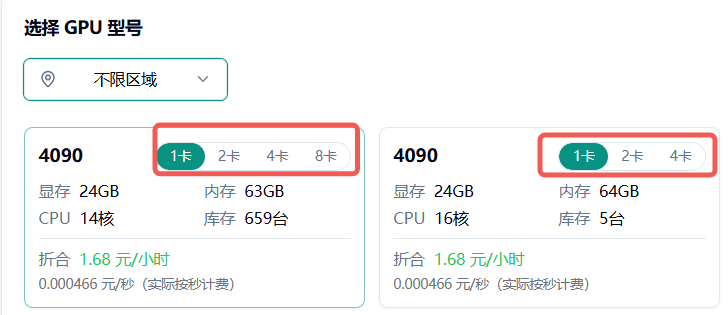
点击选择某一型号 GPU 后,可配置任务需要的计算节点数量。至少选择 1 个节点,最多可选 20 个节点,建议先启动 1 个节点进行验证,运行稳定后可横向扩展至所需规模。
选择 GPU 和节点数量后,继续填写服务配置信息
1.2.2 定义服务配置信息
按照需求选择我们预制好的镜像,同时可以通过文档链接快速了解容器化部署对应服务的步骤。
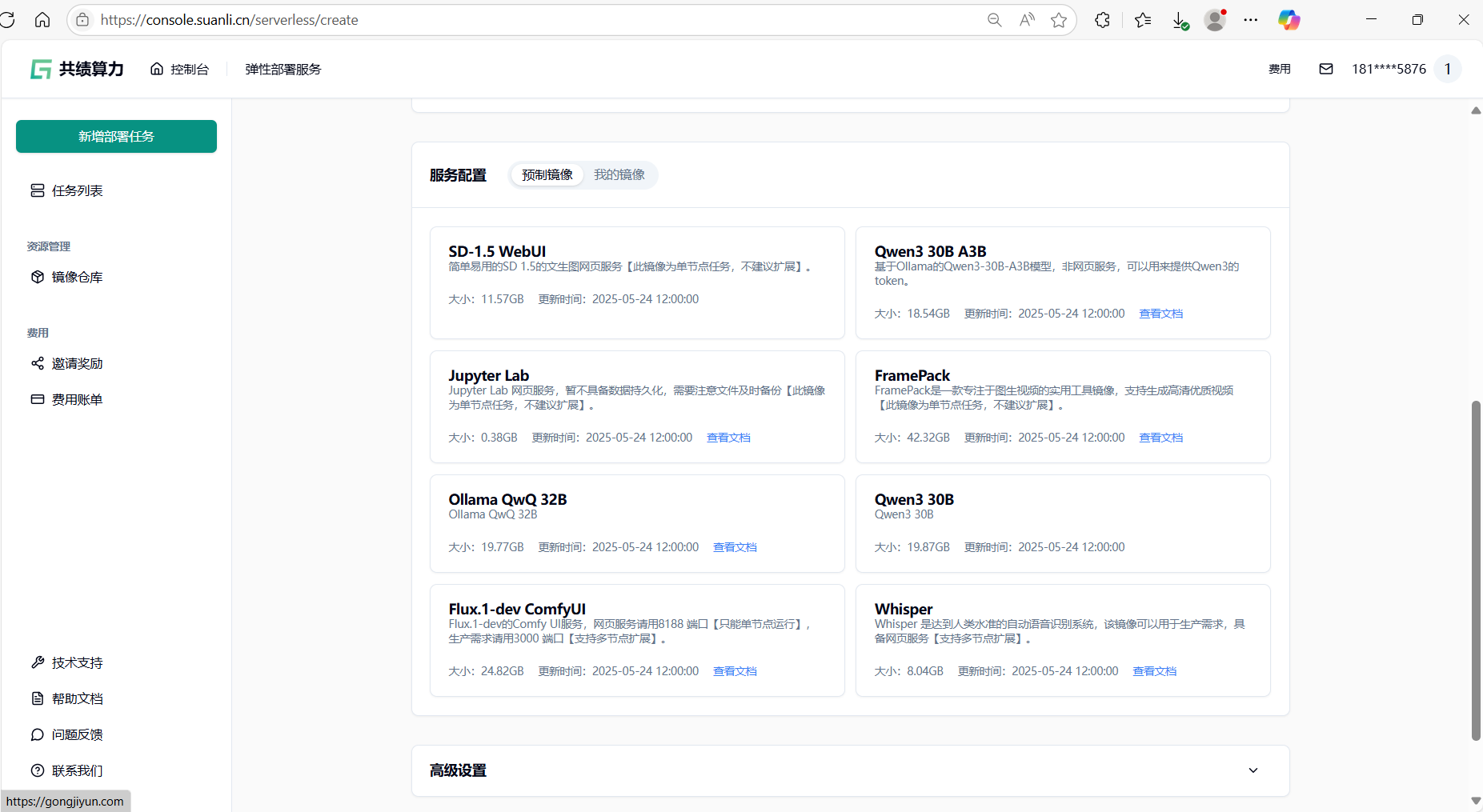
这里我们选择了 jupyter 的 CPU 服务信息作为示例
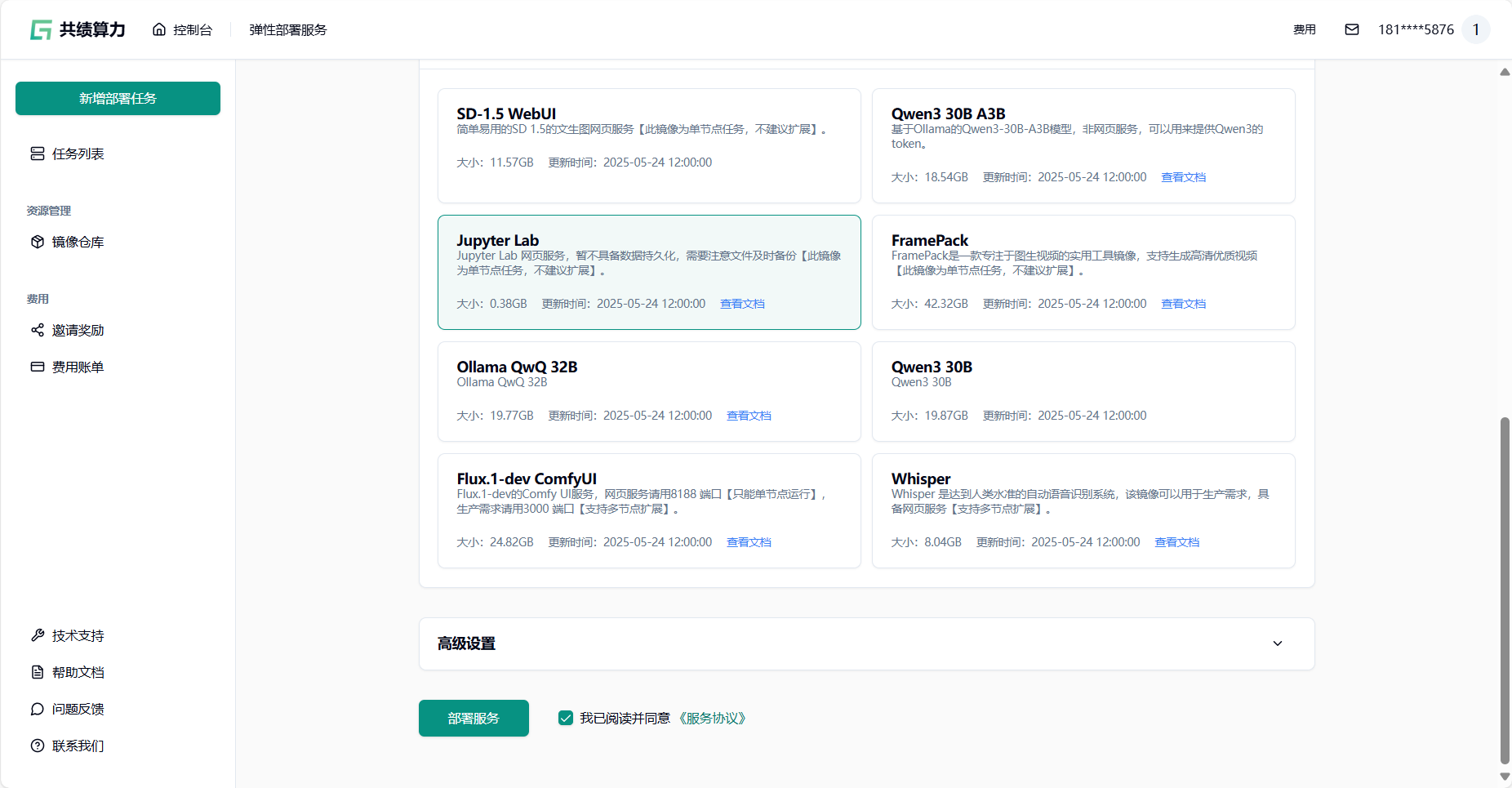
选择完成后,点击【部署服务】按钮,发布任务。
1.3 第三步:查看运行状态
发布任务后会自动跳转至任务详情界面,等待节点分配。
节点分配完成后,点击【公开访问】中的任一链接均可正常访问该服务
JupyterLab 建议只用一个节点,不然可能导致异常
节点分配完成后,可以通过点击回传链接访问服务:
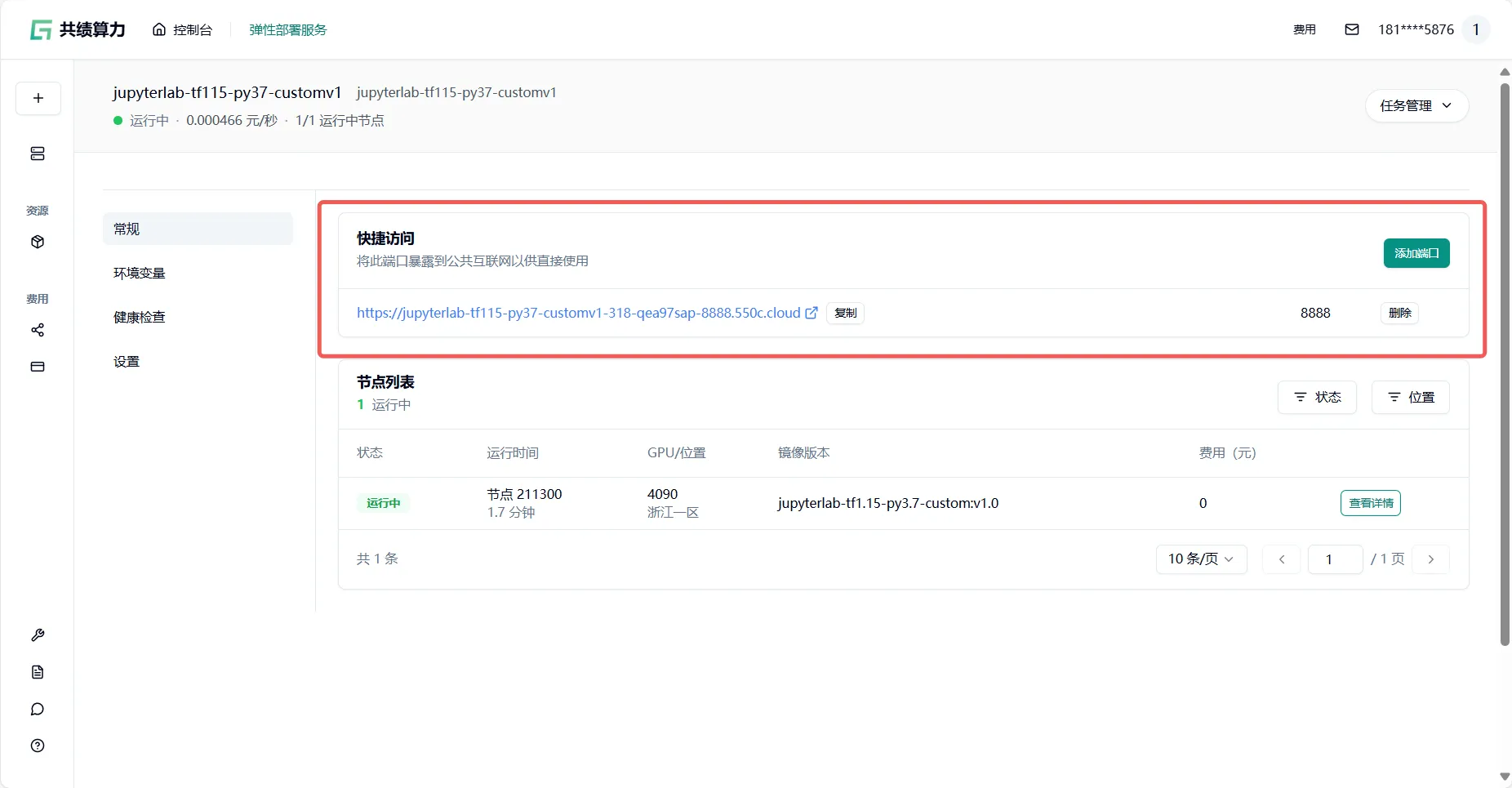
进入 JupyterLab 服务:
2 使用用户自定义打包的镜像发任务
2.1 第一步:新增部署任务
进入新增部署任务界面:https://console.suanli.cn/serverless/create
2.2 第二步:填写任务信息
2.2.1 选择资源
根据您的需要筛选 GPU,包括所在区域、显存要求、CPU 核心数、内存大小等。
选择 GPU 型号:推荐选择不限区域——享受全国闲置算力资源 随取随用
GPU 型号推荐配置:随便选
显存完全达标:
- 图片中所有型号单卡均提供 24GB 以上显存,远超服务部署启动的要求,无需担心显存不足。
性价比与灵活性:
- 1 卡配置:每小时仅需 1.68 元,按秒计费(0.000446 元/秒),适合短期测试或常规任务。
- 库存充足:1 卡版本库存多台,无需等待,快速部署。
- 多卡选项备用:若未来需要分布式训练或高并发任务,可随时切换 2 卡/4 卡。
- 简化选择逻辑:
- 无特殊需求:如果只是运行文档镜像中的常规任务(如模型推理、数据处理),单卡性能完全足够。
- 兼容性无忧:镜像仓库默认适配主流 GPU 型号(如 4090),无需额外调试。
操作建议
- 随便选 直接勾选「4090(1 卡)」+「1 个节点」,填写服务名称(如
demo-test-2025),快速完成部署。 - 进阶场景:仅当需要训练大模型(如 LLM、多模态)时,再考虑 2 卡/4 卡配置。
图片中的配置均为“无坑选项”,闭眼选 1 卡即可开箱即用,成本可控,资源立即可用。
点击选择某一型号 GPU 后,可配置任务需要的计算节点数量。至少选择 1 个节点,最多可选 20 个节点,建议先启动 1 个节点进行验证,运行稳定后可横向扩展至所需规模。
选择 GPU 和节点数量后,继续填写服务配置信息
2.2.2 定义服务配置信息
选择服务配置——我的镜像
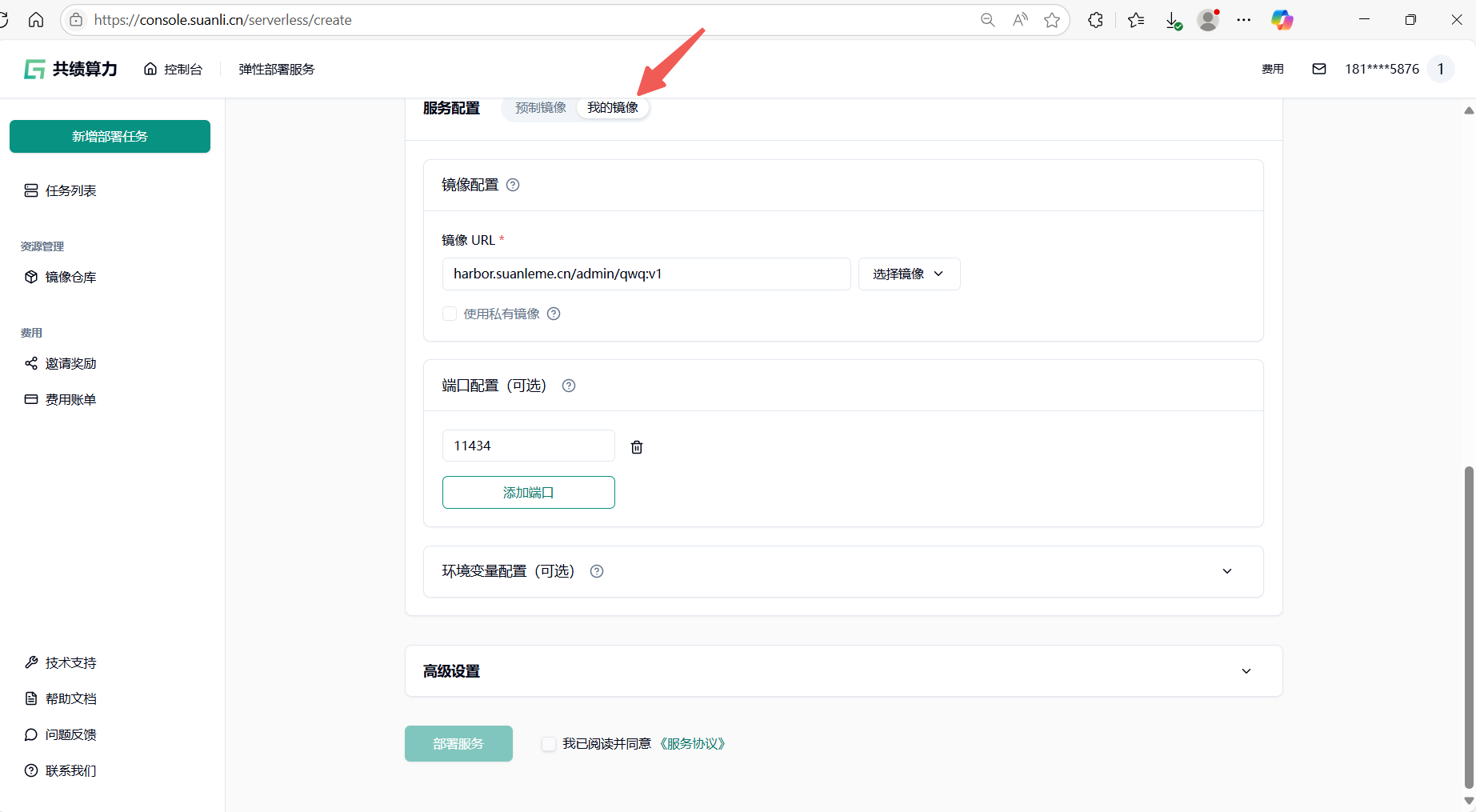
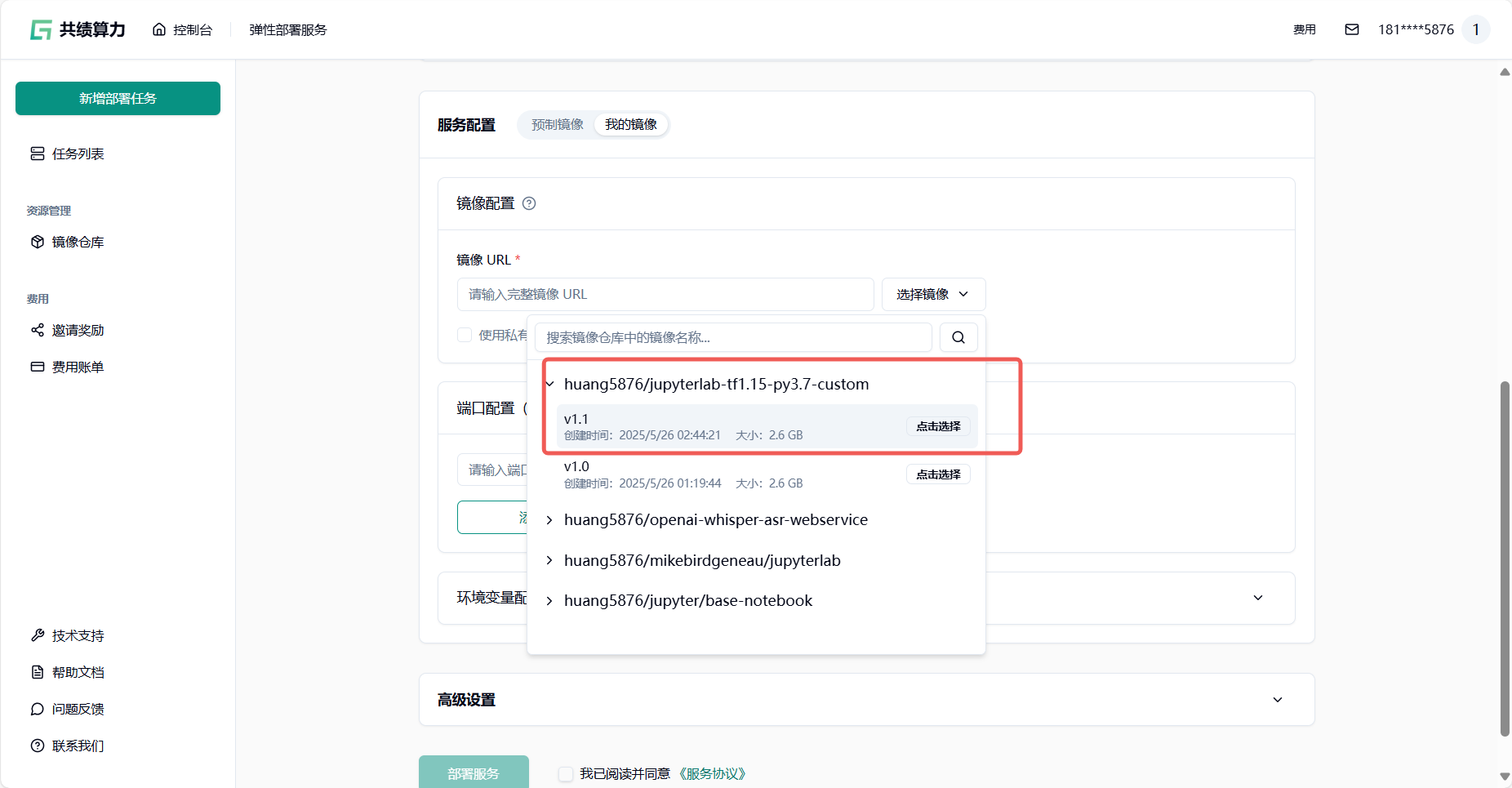
在镜像 URL字段中填写完整的镜像地址及标签。支持以下两种方式:
第一种:第三方公共镜像库(如 Docker Hub、阿里云镜像库等): 直接使用公开镜像地址,例如:
swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/jupyter/pytorch-notebook:cuda12-python-3.11.8第二种:我们提供的私有镜像库(需预先上传镜像): 若需使用内部私有镜像仓库,请参考镜像仓库完成镜像推送后,刷新后在界面中选择内部仓库地址。
示例私有镜像地址库:harbor.suanleme.cn/huang5876/jupyter_tf2_18:v1.0
版本信息:python3.12+tensorflow-gpu2.18.1
完成镜像 URL 填写后进行端口配置(这里以 JupyterLab 为例 端口号填写8888)
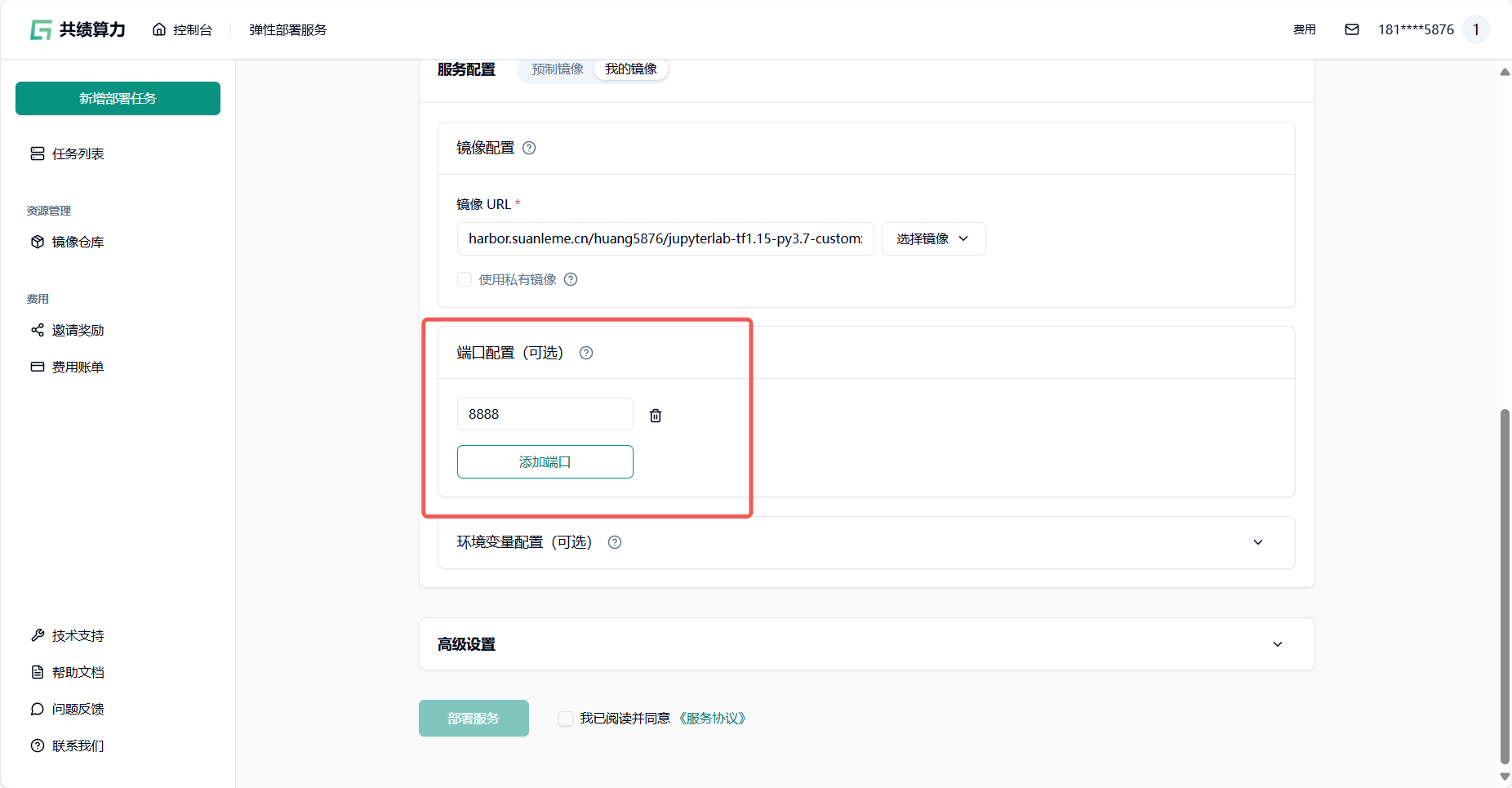
jupyter 建议只用一个节点,不然可能导致异常
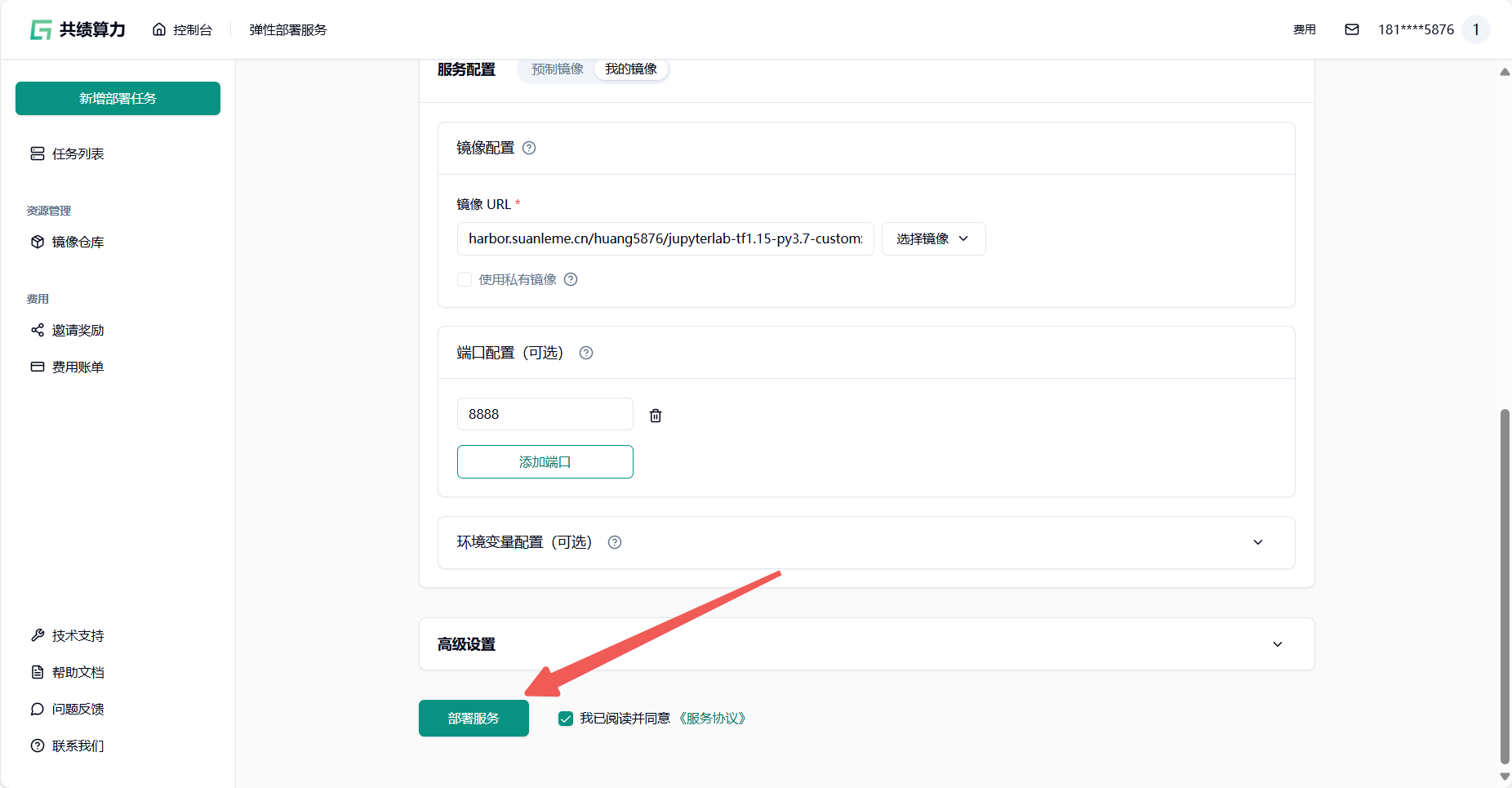
完成上面的配置后点击部署服务发布任务
2.3 第三步:查看运行状态
发布任务后会自动跳转至任务详情界面,等待节点分配。
节点分配完成后,点击【公开访问】中的任一链接均可正常访问该服务
jupyter 建议只用一个节点,不然可能导致异常
节点分配完成后,可以通过点击回传链接访问服务:
然后开始使用 JupyterLab 服务
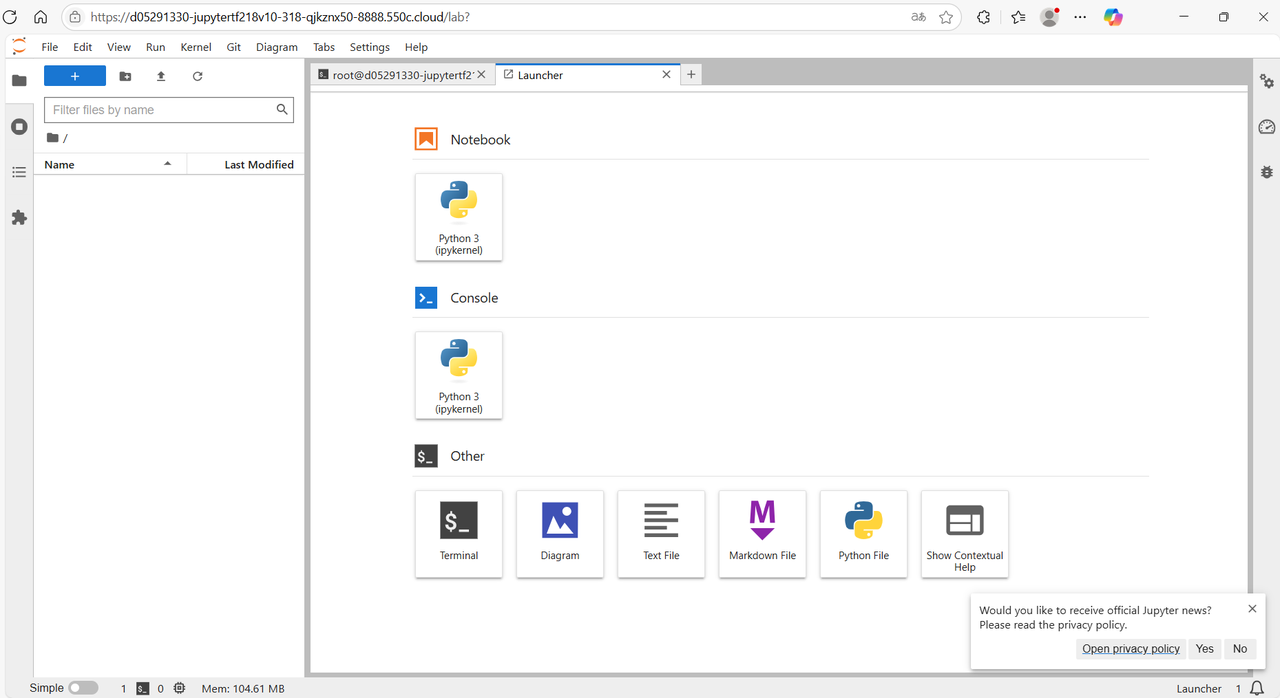
3 一些名词详细解释
3.1 新增部署
打个比方:
就像在工厂里新建一条“生产线”,需要准备原材料(GPU 型号)、设计生产流程(镜像仓库)、计算成本(费用账单)。
包含内容:
- 资源管理:分配和管理计算资源(如 GPU、内存),类似工厂调度机器和工人。
- 镜像仓库:存储和管理容器镜像,就像存放标准化的“生产配方”,确保每次部署一致性。
- 费用账单:记录资源使用成本,类似工厂的“水电费明细表”。
3.2 GPU 型号(4090)
打个比方:
像不同规格的“工程机械车”:
- 1 卡/2 卡/4 卡/8 卡:代表单台机器搭载的 GPU 数量,类似一辆卡车能装 1 台或 8 台发动机,动力逐级增强。
- 显存 24GB:相当于车辆的“货仓容量”,决定了一次性能处理多少数据(如大型模型参数)。
- 内存 64GB & CPU 核心数 16:如同驾驶室的空间和司机数量,影响多任务并行处理效率。
- 库存数 xxx:表示当前可用的“车辆库存”,库存越多,部署越快。
适用场景:
- 1 卡:常规任务(模型推理、数据处理)。
- 多卡:分布式训练、高并发计算(如大语言模型训练)。
3.3 显存要求(至少 16GB)
打个比方:
就像要求“绘图桌”的最小尺寸,必须足够大才能铺开复杂的设计图纸(如大型神经网络参数)。
简而言之:
显存是 GPU 用于临时存储计算数据的空间,16GB 是运行中等规模 AI 模型(如 Stable Diffusion)的最低要求。4090 提供 24GB 显存,远超基准,确保任务流畅运行。
3.4 节点数量
打个比方:
节点就像“克隆的工厂车间”,每个车间(节点)拥有相同的配置(如 1 卡 GPU)。增加节点数量等于同时启用多个车间,并行处理更多任务。
操作逻辑:
- 先选择“车间设备规格”(GPU 型号)。
- 再决定需要多少间“车间”(节点数量)。
示例:
- 1 节点:单任务处理(如训练一个模型)。
- 多节点:分布式计算(如同时训练多个模型)。
3.5 服务配置(服务名称)
打个比方:
就像给项目文件贴标签,例如“2025-双十一促销数据分析”,方便后续查找和管理。
简而言之:
服务名称是用户为当前部署任务定义的唯一标识,建议采用「用途 + 日期」格式(如 image-classification-20250515),便于后续监控、管理和成本追踪。