容器化部署 Whisper
本指南详细阐述了在共绩算力上部署 openai 开源的语音识别 Whisper 项目的解决方案。
1.部署步骤
Section titled “1.部署步骤”我们在服务配置——预制镜像中提供了预构建的 Whisper 容器映像,旨在满足一般要求。您可以选择直接在共绩算力上运行这些容器以执行任务。或者,您还可以通过使用我们资源管理——镜像仓库所提供的免费 Docker 镜像仓库服务,来方便管理您自身的 Docker 镜像。
镜像仓库地址:https://console.suanli.cn/serverless/image 镜像仓库使用教程:https://www.gongjiyun.com/docs/y/NnNkwiWLkiD3m1kSgXDcRvsKnrJ/RKicwD7zQi39Lmkti9gc5PcunGb.html
下面是部署步骤:
1.1 访问共绩算力控制台 https://console.suanli.cn,点击任意一个弹性部署服务。
Section titled “1.1 访问共绩算力控制台 https://console.suanli.cn,点击任意一个弹性部署服务。”
1.2 进入服务列表后点击新增部署服务按钮
Section titled “1.2 进入服务列表后点击新增部署服务按钮”
1.3 基于自身需要进行配置,参考配置为单卡 4090(初次使用进行调试)。
Section titled “1.3 基于自身需要进行配置,参考配置为单卡 4090(初次使用进行调试)。”
1.4 选择服务配置中的预制镜像 选择我们打包好的 Whisper 镜像快速开启服务
Section titled “1.4 选择服务配置中的预制镜像 选择我们打包好的 Whisper 镜像快速开启服务”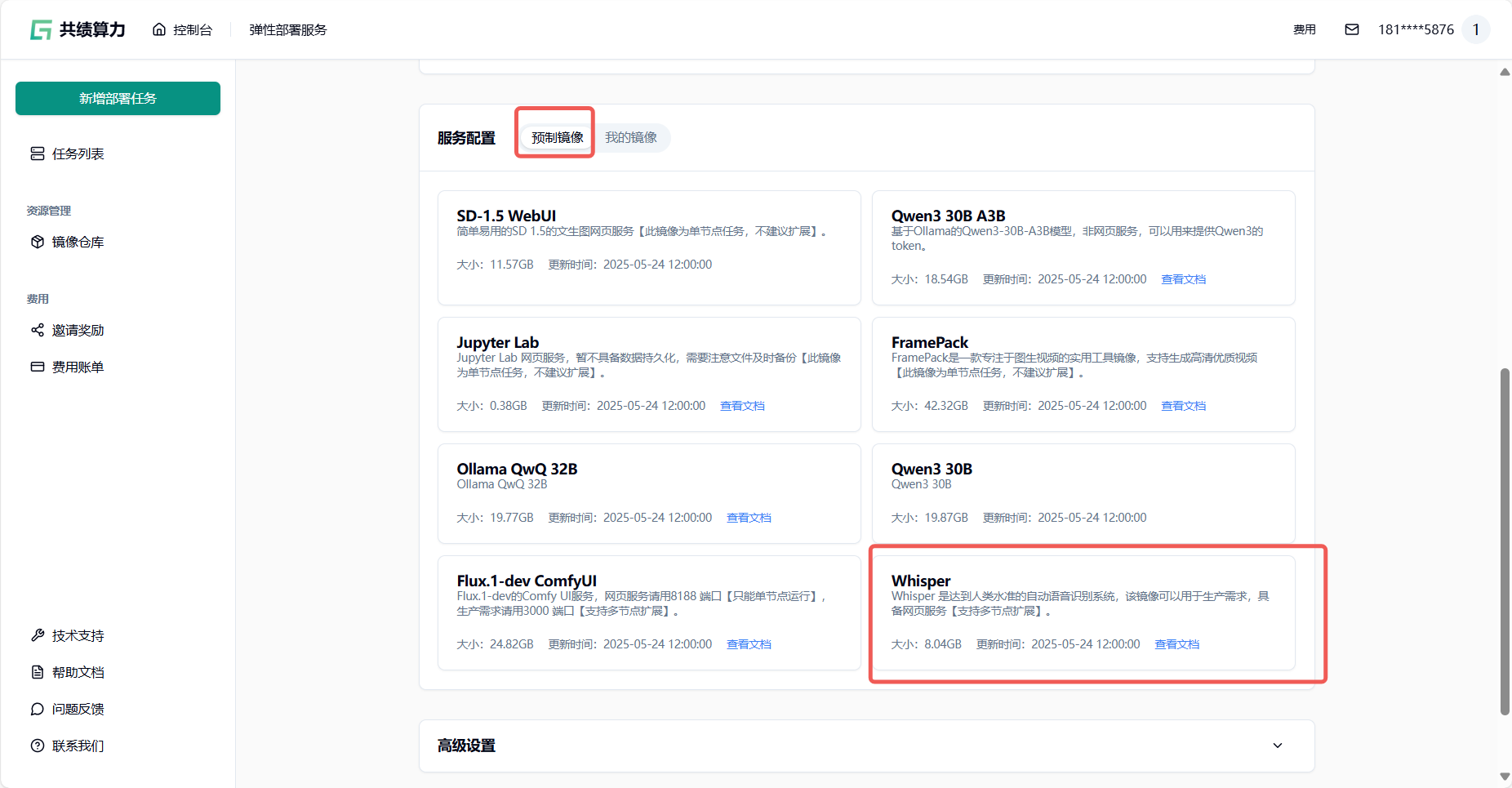
1.5 点击部署服务,耐心等待节点拉取镜像并启动 第一次访问会下载模型,所以需要稍等一会
Section titled “1.5 点击部署服务,耐心等待节点拉取镜像并启动 第一次访问会下载模型,所以需要稍等一会”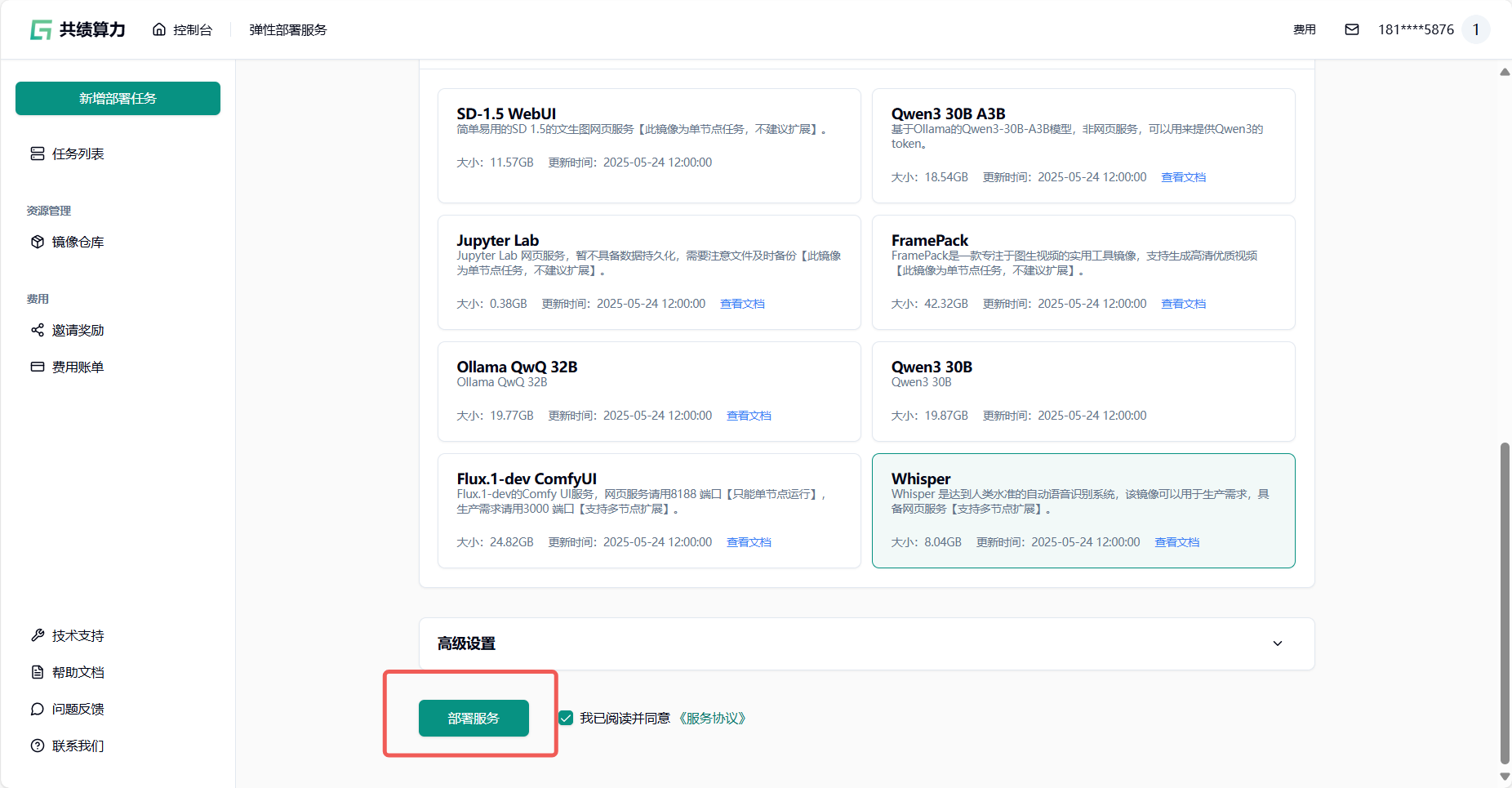
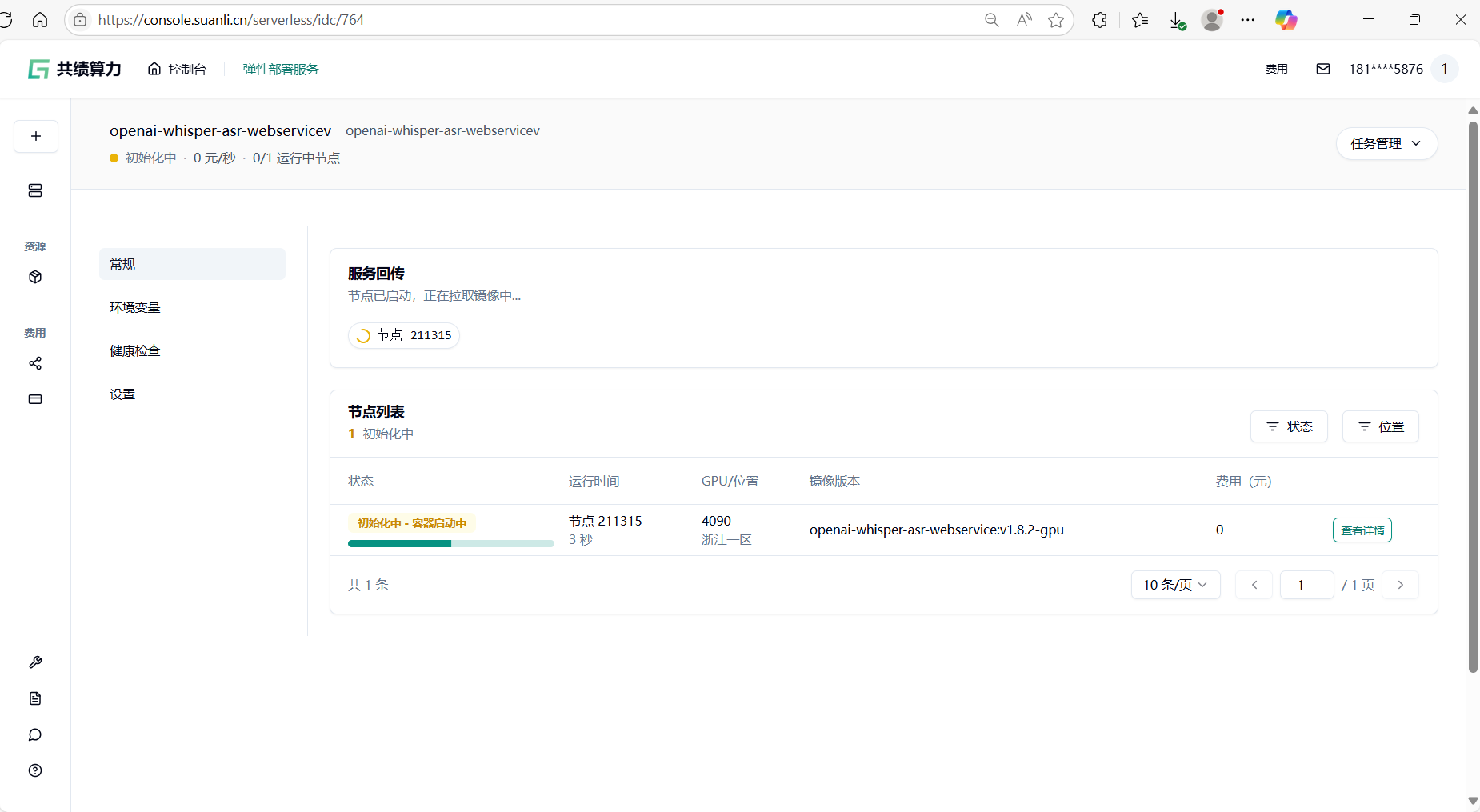
1.6 节点启动后,你所在“公开访问”中看到的内容可能如下:
Section titled “1.6 节点启动后,你所在“公开访问”中看到的内容可能如下:”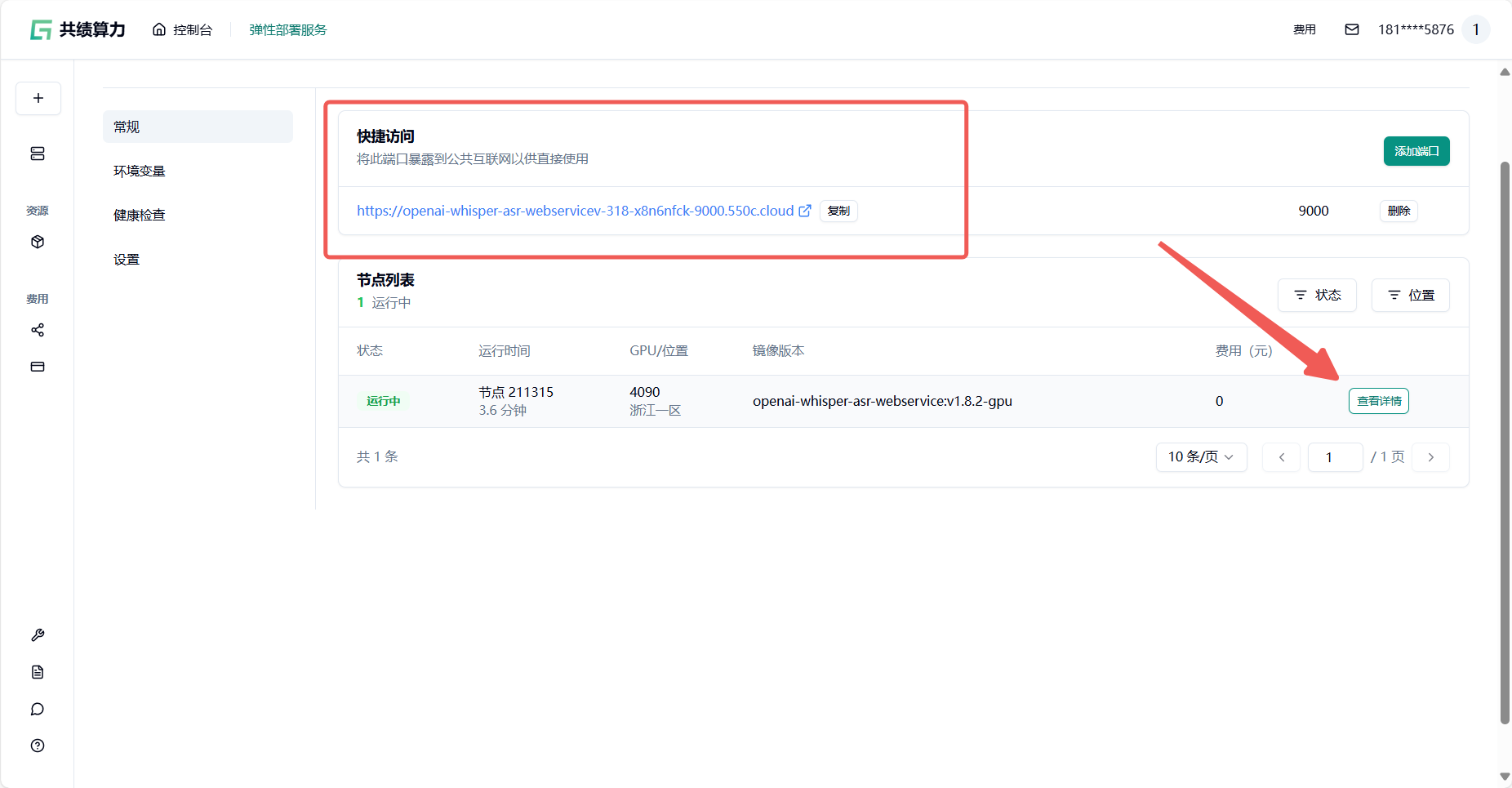
通过查看节点列表——查看详情 通过容器信息确定模型加载完成即可正常进入服务
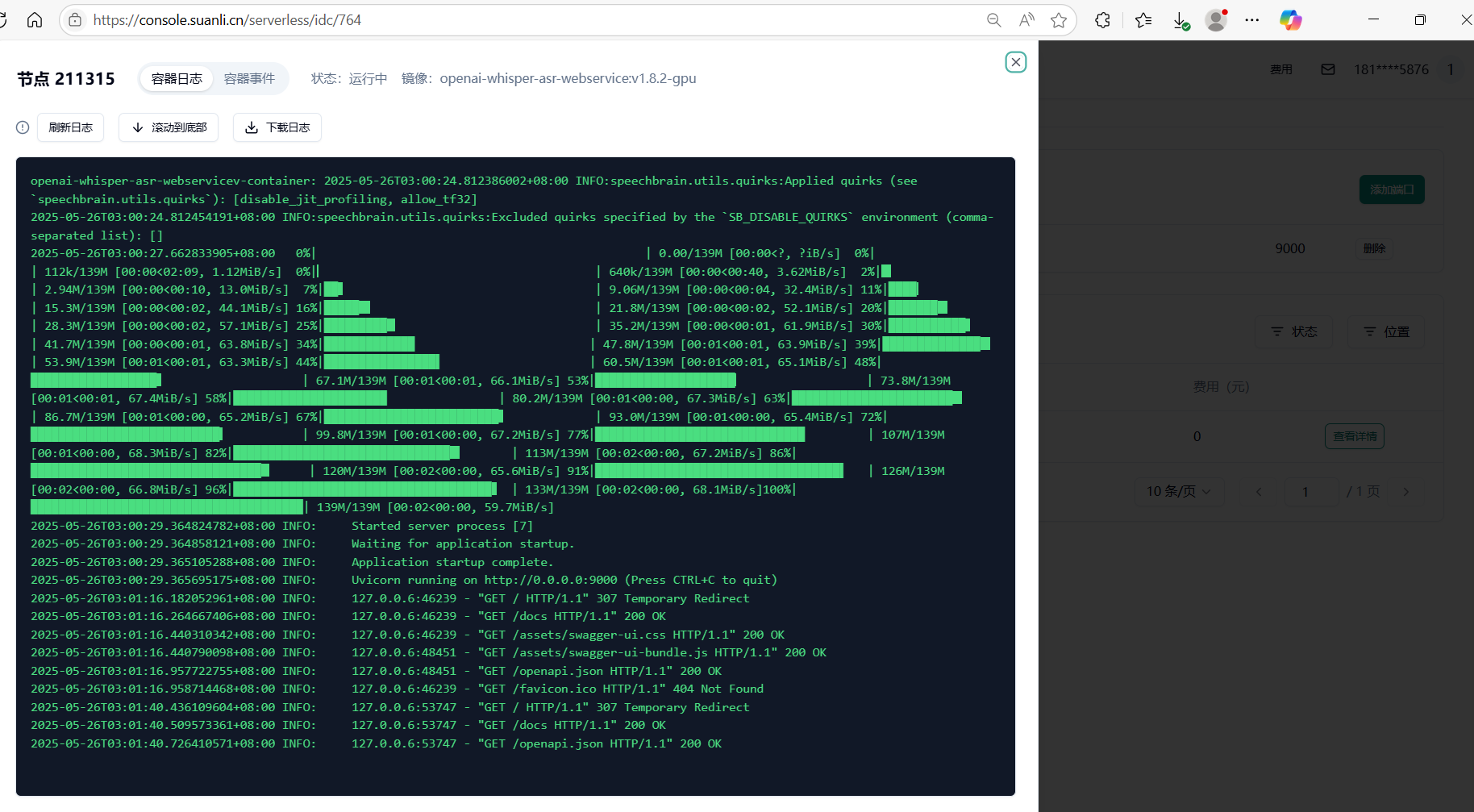
1.7 我们可以点击“9000”端口的链接,测试 whisper 部署情况,系统会自动分配一个可公网访问的域名,接下来我们即可自由地使用 whisper 的服务
Section titled “1.7 我们可以点击“9000”端口的链接,测试 whisper 部署情况,系统会自动分配一个可公网访问的域名,接下来我们即可自由地使用 whisper 的服务”2.使用教程
Section titled “2.使用教程”这个项目提供了 2 个 http 接口:
1./asr:语音识别接口,上传语音或者视频文件,输出文字。
2./detect-language:语言检测接口,上传语音或者视频文件,输出语言。
以下是针对生产环境使用的说明,包含完整的请求命令、响应时间预估及返回结果示例:
2.1.1 语音识别接口 (/asr)
Section titled “2.1.1 语音识别接口 (/asr)”请求命令(CURL)
curl -X POST "http://api.example.com/asr?language=en" \ -H "Authorization: Bearer YOUR_API_KEY" \ # 若需认证 -H "Content-Type: multipart/form-data" \ -F "file=@audio_en.mp3"
curl -X POST "http://api.example.com/asr?language=zh" \ -H "Content-Type: multipart/form-data" \ -F "file=@video_zh.mp4"参数说明
language:必填,指定音频语言(en为英文,zh为中文)。file:必填,支持格式:.mp3,.wav,.mp4,.mov等。
响应时间参考
文件大小 | 预估响应时间 |
<10MB | 3-8 秒 |
10MB-50MB | 10-25 秒 |
>50MB | 异步处理(返回任务 ID) |
注:大文件建议分片上传或使用异步接口,同步请求超时时间默认为 30 秒。
返回结果示例
// 成功{ "status": "success", "text": "This is the transcribed text from your audio file."}
// 失败(如语言参数错误){ "status": "error", "code": 400, "message": "Invalid language parameter. Supported: en, zh."}2.1.2 语言检测接口 (/detect-language)
Section titled “2.1.2 语言检测接口 (/detect-language)”请求命令(CURL)
curl -X POST "http://api.example.com/detect-language" \ -H "Content-Type: multipart/form-data" \ -F "file=@unknown_audio.wav"参数说明
file:必填,支持格式同上。
响应时间参考
文件大小 | 预估响应时间 |
<10MB | 2-5 秒 |
10MB-50MB | 5-10 秒 |
>50MB | 仅分析前 1 分钟内容 |
注:大文件默认截取前 1 分钟内容进行检测以加速响应。
返回结果示例
// 成功{ "status": "success", "language": "fr", "confidence": 0.92 // 检测置信度(0-1)}
// 失败(如文件格式不支持){ "status": "error", "code": 415, "message": "Unsupported media type. Allowed: audio/*, video/*."}关键说明
-
认证:若需 API 密钥,需在 Header 中添加
Authorization: Bearer YOUR_API_KEY。 -
异步处理:
- 大文件可调用
/asr/async?language=en提交任务,返回{"task_id": "123"}。 - 通过
/tasks/123查询结果。
- 大文件可调用
-
限速:默认限制 10 请求/分钟/IP,生产环境需联系调整配额。
按需直接复制命令即可集成到脚本或应用程序中。
2.2.1 英文音频转文字
Section titled “2.2.1 英文音频转文字”点击/asr:语音识别接口后点击页面右上角Try it out 开始使用
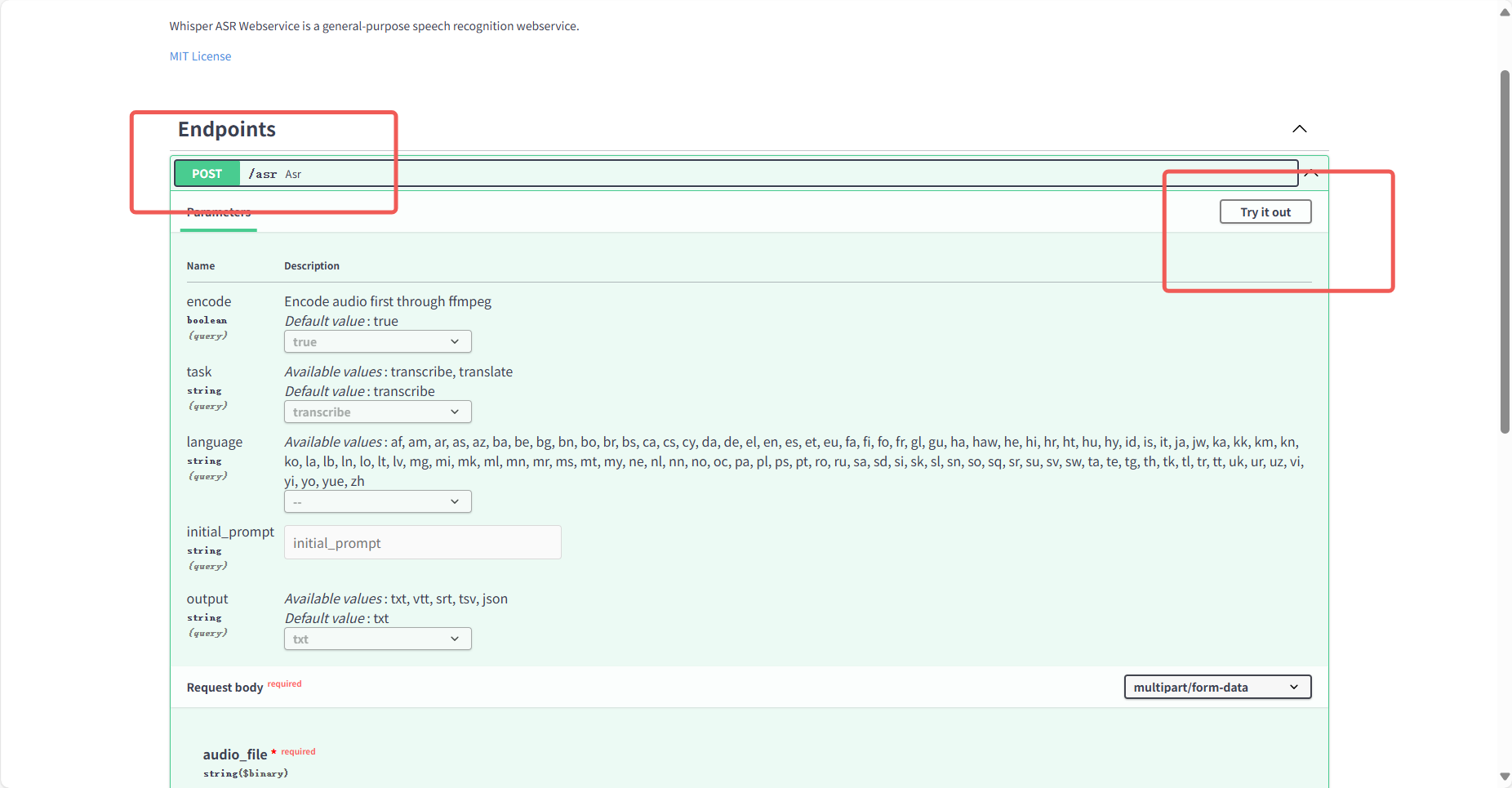
先用一个英文 mp3 音频看看效果,可以先照抄截图中的参数看看效果,后面会介绍每个参数的意思。需要音频文件的可以在这里下载:
https://www.gongjiyun.com/resource/frozen231202_0242164tMa.mp3
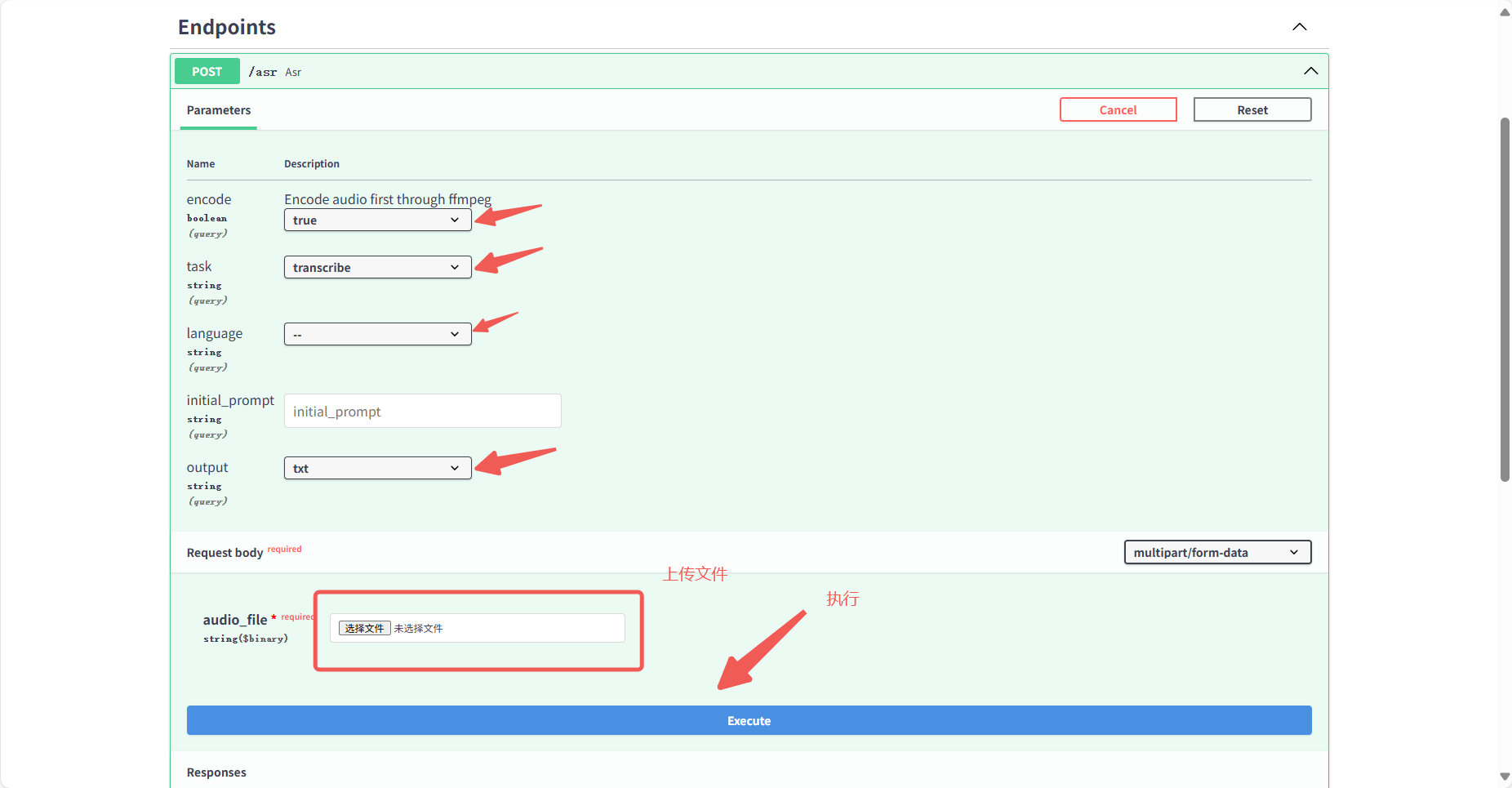
稍等一会即可转换完成,在 response body 中可看到转换结果。
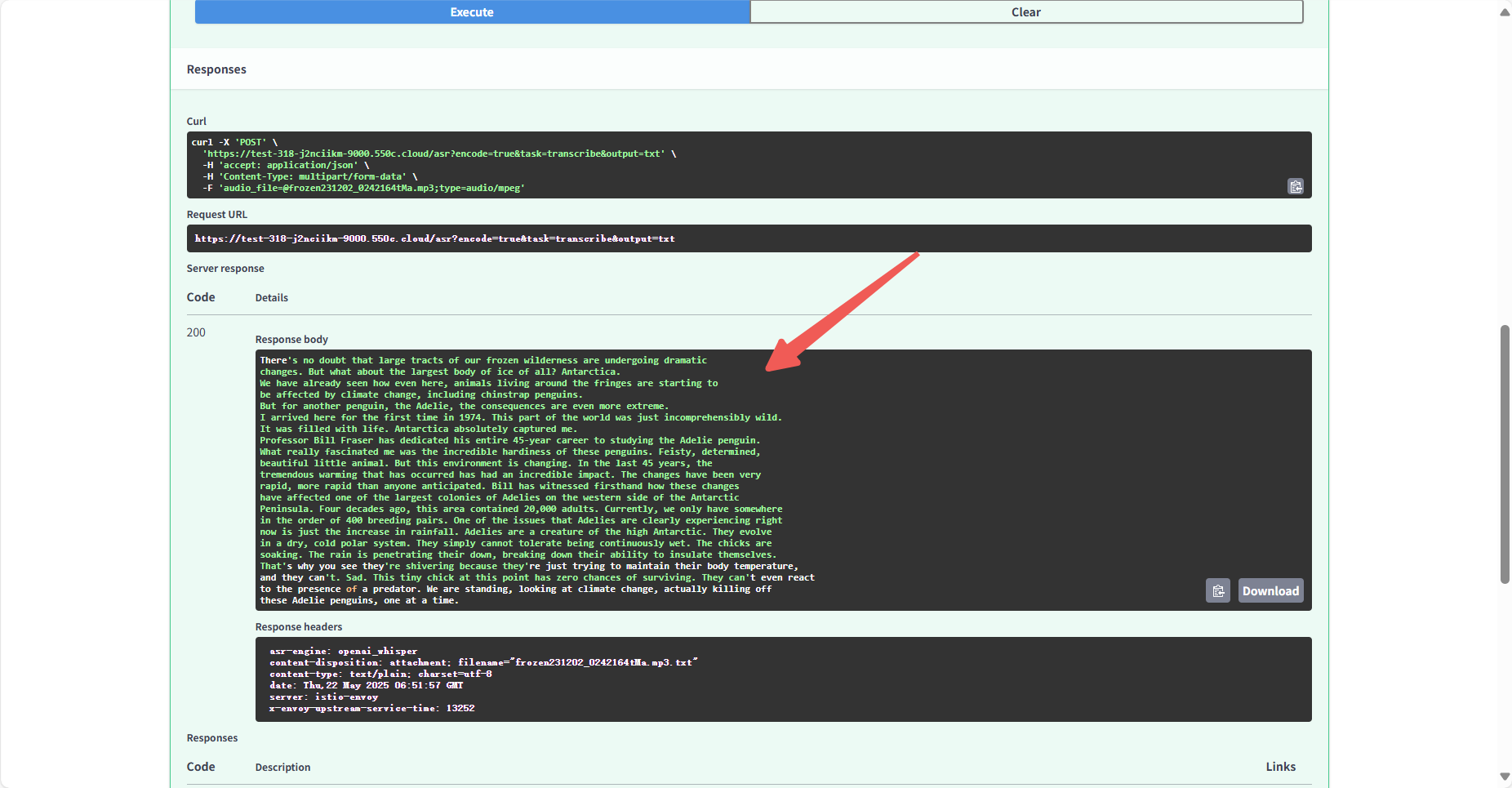
下面是复制出来的文本,可以看到效果是非常好的:
There's no doubt that large tracts of our frozen wilderness are undergoing dramaticchanges. But what about the largest body of ice of all? Antarctica.We have already seen how even here, animals living around the fringes are starting tobe affected by climate change, including chinstrap penguins.But for another penguin, the Adelie, the consequences are even more extreme.I arrived here for the first time in 1974. This part of the world was just incomprehensibly wild.It was filled with life. Antarctica absolutely captured me.Professor Bill Fraser has dedicated his entire 45-year career to studying the Adelie penguin.What really fascinated me was the incredible hardiness of these penguins. Feisty, determined,beautiful little animal. But this environment is changing. In the last 45 years, thetremendous warming that has occurred has had an incredible impact. The changes have been veryrapid, more rapid than anyone anticipated. Bill has witnessed firsthand how these changeshave affected one of the largest colonies of Adelies on the western side of the AntarcticPeninsula. Four decades ago, this area contained 20,000 adults. Currently, we only have somewherein the order of 400 breeding pairs. One of the issues that Adelies are clearly experiencing rightnow is just the increase in rainfall. Adelies are a creature of the high Antarctic. They evolvein a dry, cold polar system. They simply cannot tolerate being continuously wet. The chicks aresoaking. The rain is penetrating their down, breaking down their ability to insulate themselves.That's why you see they're shivering because they're just trying to maintain their body temperature,and they can't. Sad. This tiny chick at this point has zero chances of surviving. They can't even reactto the presence of a predator. We are standing, looking at climate change, actually killing offthese Adelie penguins, one at a time.2.2.2 中文视频转文字
Section titled “2.2.2 中文视频转文字”与上面操作一样,只是选文件的时候选一个中文视频就可以了,然后提示词这里写上简体中文的要求(默认会输出繁体)
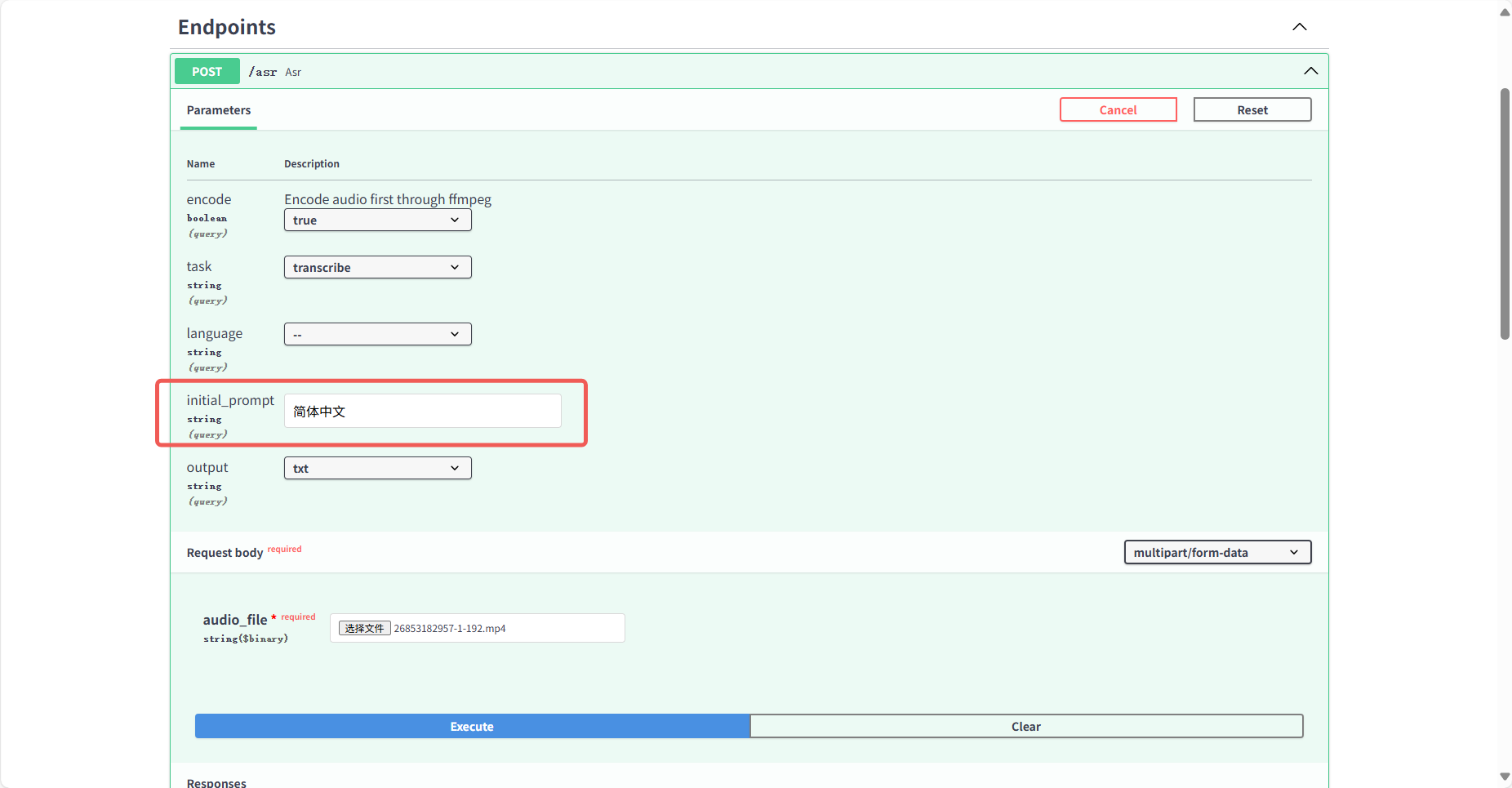
下面是复制出来的文本,可以看到效果是非常好的:
今年是我做记者的第九个年头在我做过的很多报道结尾我都会报尾比如说央视记者 美国华盛顿报道又或者是走运CGTNBJ在过去的九年里我的名字和工作单位都没有变但是最后这个地点却一直在变从中国的主场外交活动到精准扶贫政策落地的一个小村庄从美联储货币政策的发布再到颶风丧敌的重灾区我从一个个新闻现场去见证一个个历史性的时刻有人说站在这个舞台主持人大赛的舞台需要一种气那就是底气我也很认真地想过我的底气到底来自于哪儿因为我不属于那种站在台上特别打眼儿的人我也不是科班出身但是我想我的底气可能来自于在过去的九年里我的报道是我一条一条跑出来一个字一个字敲出来一个画面一个画面编出来一场直播一场直播完成出来的生命见证过多少真实付出过怎样的努力我希望就会有怎样的底气这条路真的很难所以我也有过动摇这也是为什么在2015年我去剑桥读书的时候没有选择读跟媒体相关的专业而是选择了一个最容易转型的商科但是读完书反而更坚定地想要在这条路上走下去因为我太想念那种在一个国际场合我作为一个中国记者去努力地获得一个提问的机会来去发出中国的声音我太想念不管是在三都澳的鱼排上还是在宁德的茶园里去跟国际的观众分享那些有趣的事有趣的人的那种紧迫感今天站在这个舞台上我有很多话想说康辉老师曾经说过从记者到好记者到主持人再到好主持人这是一个媒体人很扎实的路径在过去的九年里我努力地去实现从记者到好记者的转变而在今天在这个舞台上我希望可以迈出从好记者到记者型主持人的转变这个转变注定艰难但我想我会拼尽全力因为毕竟走运走运支撑起它的不是运气而是越努力越走运在未来我希望在这个国际化的以静中可以有我的小小的遗习之地我想我会努力地去成为一个更加开放的中国人始终打开聆听各方声音的大门但是不忘自己的中国根因为只有这样我们才能写出更多的鏗枪有力的中国文为我们的祖国在国际话语体系上加分谢谢大家2.2.3 语言检测
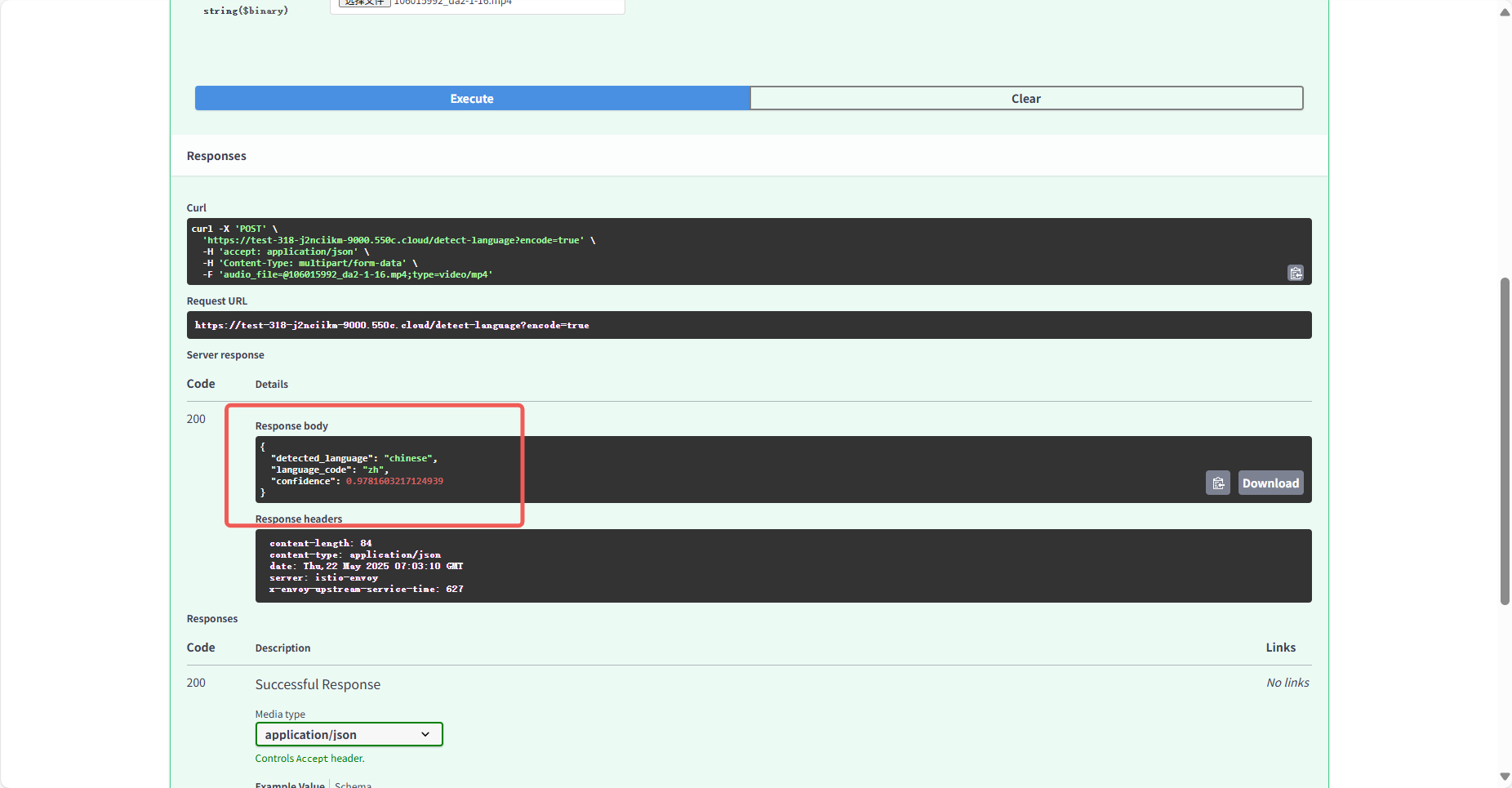
Section titled “2.2.3 语言检测”不识别文字,只检测一下是什么语言,大文件只会检查前 30 秒。
结果展示:
3.参数解释
Section titled “3.参数解释”3.1 encode(编码预处理)
Section titled “3.1 encode(编码预处理)”-
作用:自动通过
ffmpeg对音视频文件进行预处理 -
必填:✅ 是(推荐始终设为
true) -
场景说明:
- true:对非标准音频格式(如 MP4/MKV 中的音轨)提取为 PCM/WAV 格式
- false:仅当输入为原始音频(如已解压的 WAV 文件)时使用
-
示例错误:
Error: Audio extraction failed - unsupported container format3.2 task(任务模式)
Section titled “3.2 task(任务模式)”模式 | 功能说明 | 输出示例 |
| 语音转文字(源语言→同语言文本) | 中文音频 → 中文文本 |
| 语音翻译(任何语言→英文文本) | 中文音频 → 英文文本 |
- 注意:
translate仅支持输出英文,不可指定其他目标语言- 教学场景建议优先用
transcribe保留原语言语义
3.3 language(源语言指定)
Section titled “3.3 language(源语言指定)”-
作用:声明输入音频的语言(ISO 639-1 代码,如
ch/en) -
必填:❌ 否(自动检测模式)
-
使用策略:
场景
推荐操作
单一语言录音
留空(自动检测更准确)
混合语言学术会议
强制指定主语言(如
en) -
错误示例:
"text": "Yangyang, will you give me money..." # 拼音化乱码3.4 initial_prompt(上下文提示)
Section titled “3.4 initial_prompt(上下文提示)”- 作用:提供领域关键词提升识别精度(类似 ChatGPT 的 system prompt)
- 格式:英文短语或术语列表(即使处理中文音频也需用英文填写)
- 经典用例:
- 识别准确率提升 12-13%(针对专业术语)
- 支持动态更新词库(通过
X-KeyPool请求头注入)
{ "initial_prompt": "machine learning, convolutional neural networks, GPT-4"}3.5 word_timestamps(时间戳控制)
Section titled “3.5 word_timestamps(时间戳控制)”- 作用:控制输出是否包含词级时间标注
- 兼容性:
输出格式 | 时间戳表现 |
| 完整时间戳(精确到 10ms) |
| 句子级分段(自动聚合词级数据) |
| 不生效 |
3.6 output(输出格式)
Section titled “3.6 output(输出格式)”格式 | 适用场景 | 示例片段 |
| 快速预览 |
|
| 视频字幕嵌入 |
|
| 开发者分析(含置信度等元数据) |
|
| 流媒体兼容字幕 |
|
4.项目介绍
Section titled “4.项目介绍”拥有 ChatGPT 语言模型的 OpenAI 公司,开源了 Whisper 自动语音识别系统,OpenAI 强调 Whisper 的语音识别能力已达到人类水准。
Whisper 是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。Whisper 还可以进行多语言语音识别、语音翻译和语言识别等任务。Whisper 的架构是一个简单的端到端方法,采用了编码器 - 解码器的 Transformer 模型,将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务。
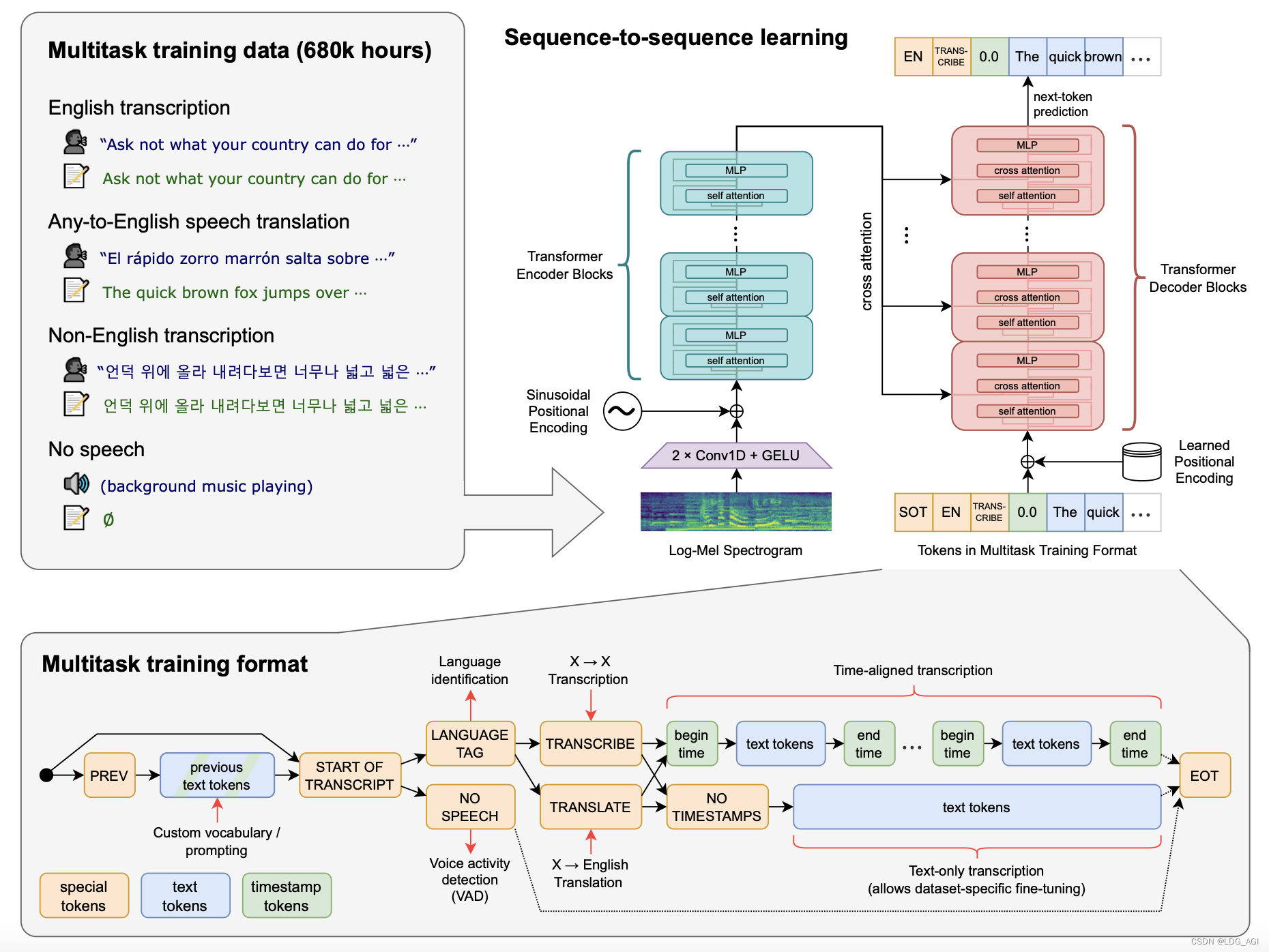
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
项目地址:https://github.com/openai/whisper
5.共绩算力打包好的 whisper 项目镜像的优势:
Section titled “5.共绩算力打包好的 whisper 项目镜像的优势:”5.1 本地转写的麻烦之处:
Section titled “5.1 本地转写的麻烦之处:”笔记本上缺乏好的硬件:纯 CPU 模式跑 Whisper 速度非常慢,3 小时的音频可能需要十几个小时才能转写完毕。如果想用 GPU 加速,根据 Whisper 模型显存需求表格,官方的 Whisper-large 模型需要 10G 显存,普通的核显本实在是力不从心。后续的 Whisper cpp 项目 倒是大幅降低了内存需求,但这也引出了第二个问题。
环境部署复杂:OpenAI 开放的毕竟是项目代码,自己写代码适配的成本还是有点高。Whisper 的 GUI 客户端在 Mac 上不少(Whisper Transcription、MacWhisper..),Windows 上也有 Buzz,然而要找到一个支持 GPU 加速的客户端依然十分困难。
5.2 利用 OpenAI 的 Whisper API 云端转写的问题:
Section titled “5.2 利用 OpenAI 的 Whisper API 云端转写的问题:”利用 OpenAI 的 Whisper API 云端转写的优势在于不会受到本地机器性能的限制,且速度相对较快。但它存在两个问题:
项目处理流程复杂:OpenAI 的 Whisper API 限制单次请求的音频大小为 25Mb,而一节 3h 的音频通常都会有大几十 MB。这就需要对音频先做分段处理,再请求结果,最后合并结果。如果是 mp4 文件则还需要从中抽取音频文件,这个过程里没少踩坑。
成本问题:OpenAI 的 Whisper 模型 1min 收费 0.006 美元,1h 的音频按照 7.3 的汇率需要收费 2.7 元。坦白讲,Whisper 的 API 价格非常便宜了,几乎只是 Google Speech2Text API 的四分之一。但是,如果我们假设有 5 门课程,每堂课长 3 小时,每周有一次课,那么每个月的转写成本 = 5 x 3 x 4 x 2.7 = 162 元,这个价格还是有点肉疼。
5.3 共绩算力打包好的 Whisper 镜像的核心优势
Section titled “5.3 共绩算力打包好的 Whisper 镜像的核心优势”针对传统音频转写场景的三大核心痛点,共绩算力通过技术创新实现”资源重构、效率跃升、体验革新”,具体优势对比如下:
5.3.1 核显笔记本运行 Whisper-large 的算力解放
Section titled “5.3.1 核显笔记本运行 Whisper-large 的算力解放”▎痛点场景
普通笔记本用 CPU 运行大型模型,3 小时音频需耗时 15 小时
▎传统方案
- 忍受超长等待或花费数万元升级显卡
▎共绩方案
- 智能路由:自动接入算力池闲置 4090 显卡
- 显存池化:突破单卡物理限制,动态聚合多节点显存资源
- 效能提升:3 小时音频转写时间从 15 小时压缩至 55 分钟
5.3.2 本地 GPU 资源不足的柔性调度
Section titled “5.3.2 本地 GPU 资源不足的柔性调度”▎痛点场景
官方要求 10G 显存,普通设备无法满足
▎传统方案
- 被迫采购高配显卡(如 RTX 4090)
▎共绩方案
- 碎片化显存调用:将多台设备显存组合为 10G 逻辑显卡
- 分布式推理:把 Whisper-large 模型拆解到多卡并行计算
- 成本规避:零硬件投入即可获得专业级计算能力
5.3.3 跨平台 GUI 的终极统一方案
Section titled “5.3.3 跨平台 GUI 的终极统一方案”▎痛点场景
Windows/Mac 客户端功能割裂,且缺乏 GPU 加速支持
▎传统方案
- 在不同平台反复配置环境,手动处理兼容性问题
▎共绩方案
- 浏览器即工作站:通过 Web 界面一键操作(上传/转写/导出)
- 无缝衔接:无论 Chromium 还是 Safari 内核,均可获得一致体验
5.4 技术价值提炼
Section titled “5.4 技术价值提炼”维度 | 传统方案 | 共绩创新价值 |
硬件门槛 | 被设备性能锁死生产力 | 算力资源"无感穿透",让核显本拥有 A100 级能力 |
部署成本 | 动辄上万元的硬件投入 | 按需付费,单次任务最低 0.5 元起 |
运维复杂度 | 跨平台调试耗时 3 小时+/次 | 浏览器打开即用,全程无需技术背景 |
通过将复杂的 GPU 资源调度、模型优化、跨平台兼容等底层技术封装为开箱即用的标准化服务,共绩算力让专业级语音转写从实验室特权真正转变为基础教育工具。