容器化部署 JupyterLab
在共绩算力上运行 JupyterLab
我们在镜像仓库中提供了预构建的 JupyterLab 容器映像,旨在满足一般要求。您可以选择直接在共绩算力上运行这些容器以执行任务。或者,您可以自定义它们通过利用我们的 资源管理——镜像仓库 中提供的免费的 Docker 镜像仓库服务,方便您管理您自己的 Docker 镜像。
在 Serverless 平台上此任务仅可使用单个节点运行,并且任务暂停将致使数据丢失。若需保留数据,可参照文档中阿里云 OSS 配置部分,通过挂载云存储实现数据持久化。
访问共绩算力控制台 https://console.suanli.cn/serverless/create/idc
点击新建部署。
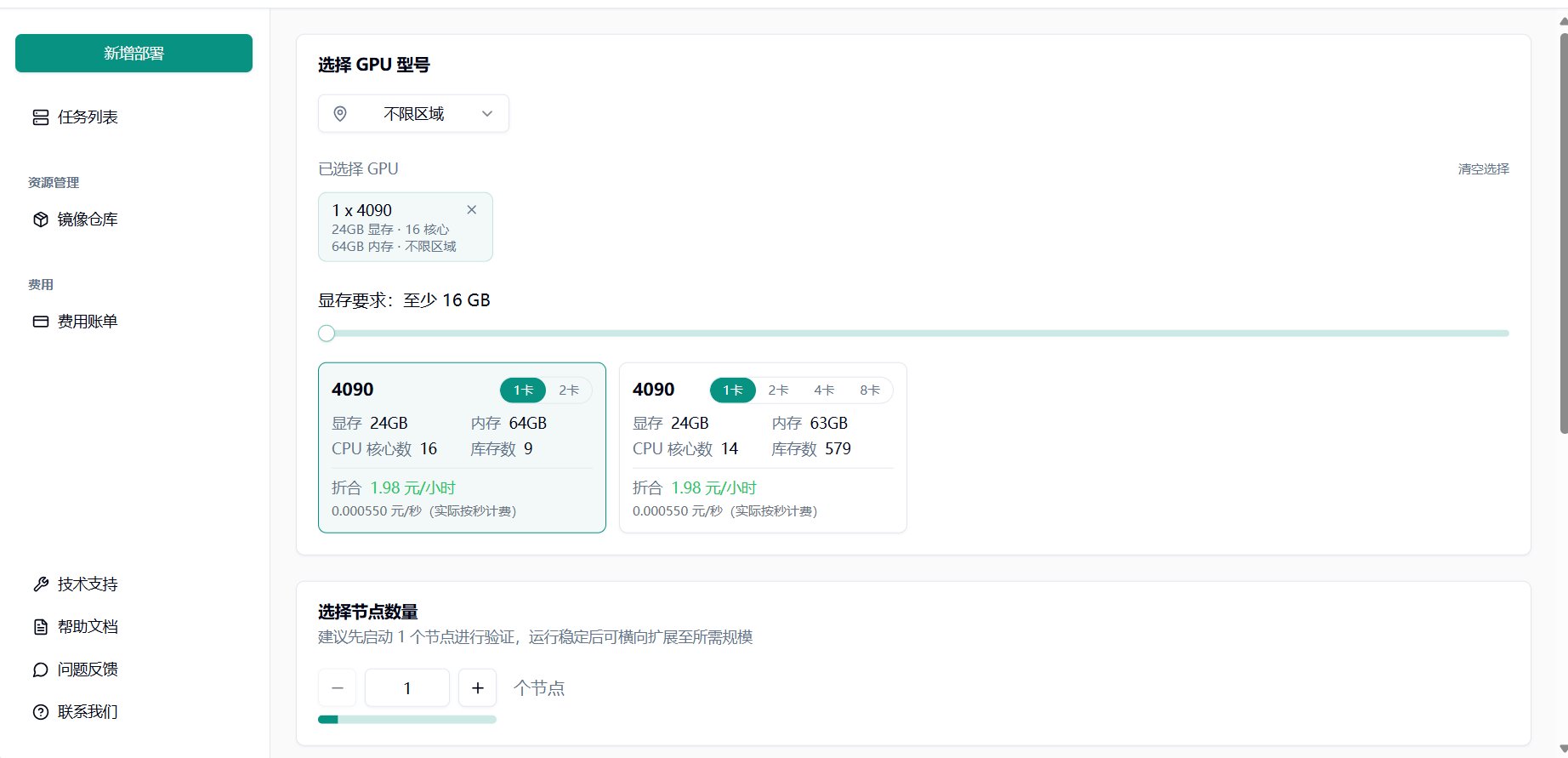
填写基本信息
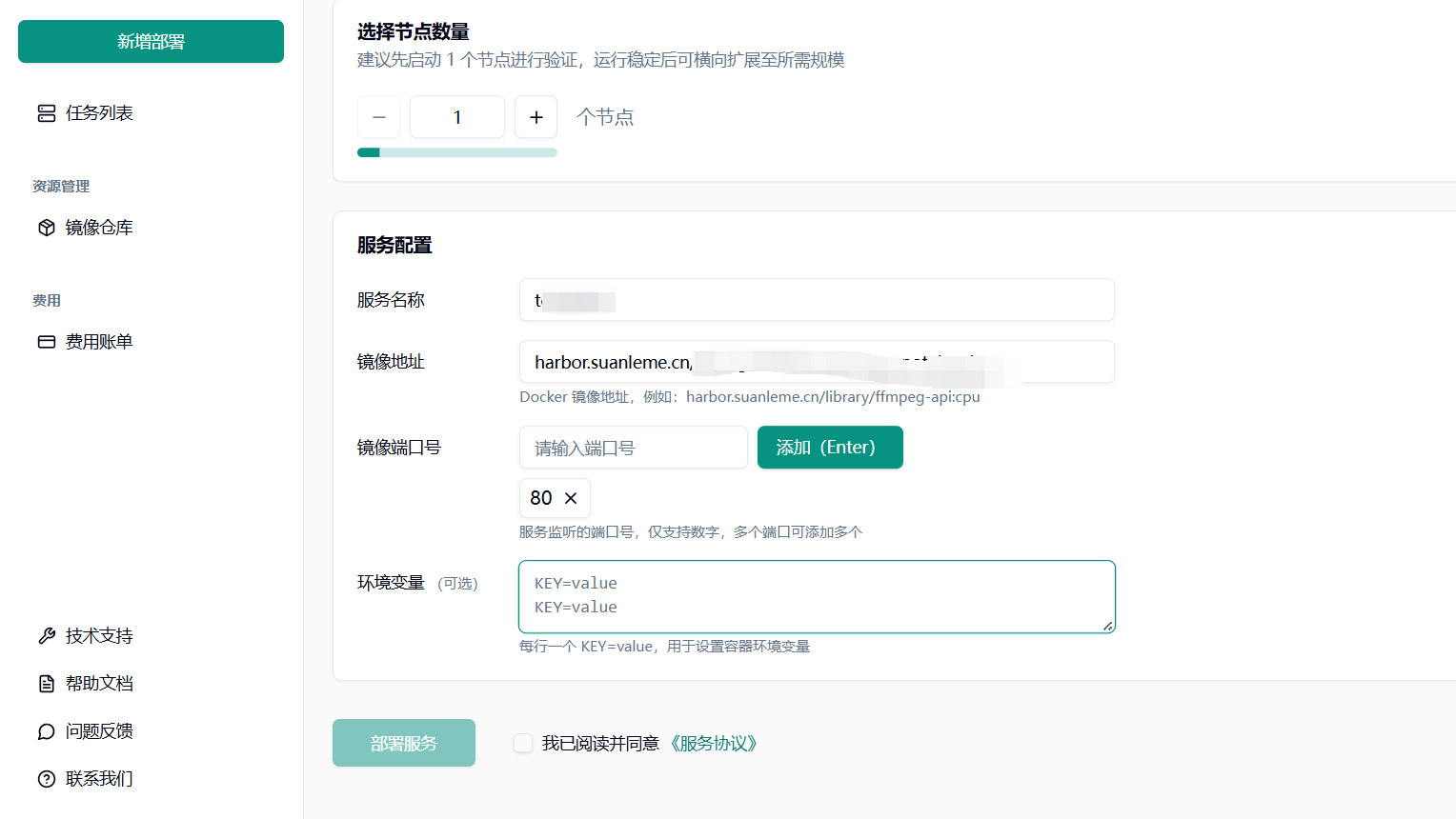
可使用的镜像地址:harbor.suanleme.cn/huang5876/mikebirdgeneau/jupyterlab:v1.0
端口号:8888
(选配)云数据服务环境变量:访问密钥 ID/访问密钥,以及存储桶和文件夹名称传递给容器
部署
由于镜像体积较大,我们需要耐心等待一段时间,部署完成后页面显示如下图。节点分配完成后,可以通过回传链接访问服务:
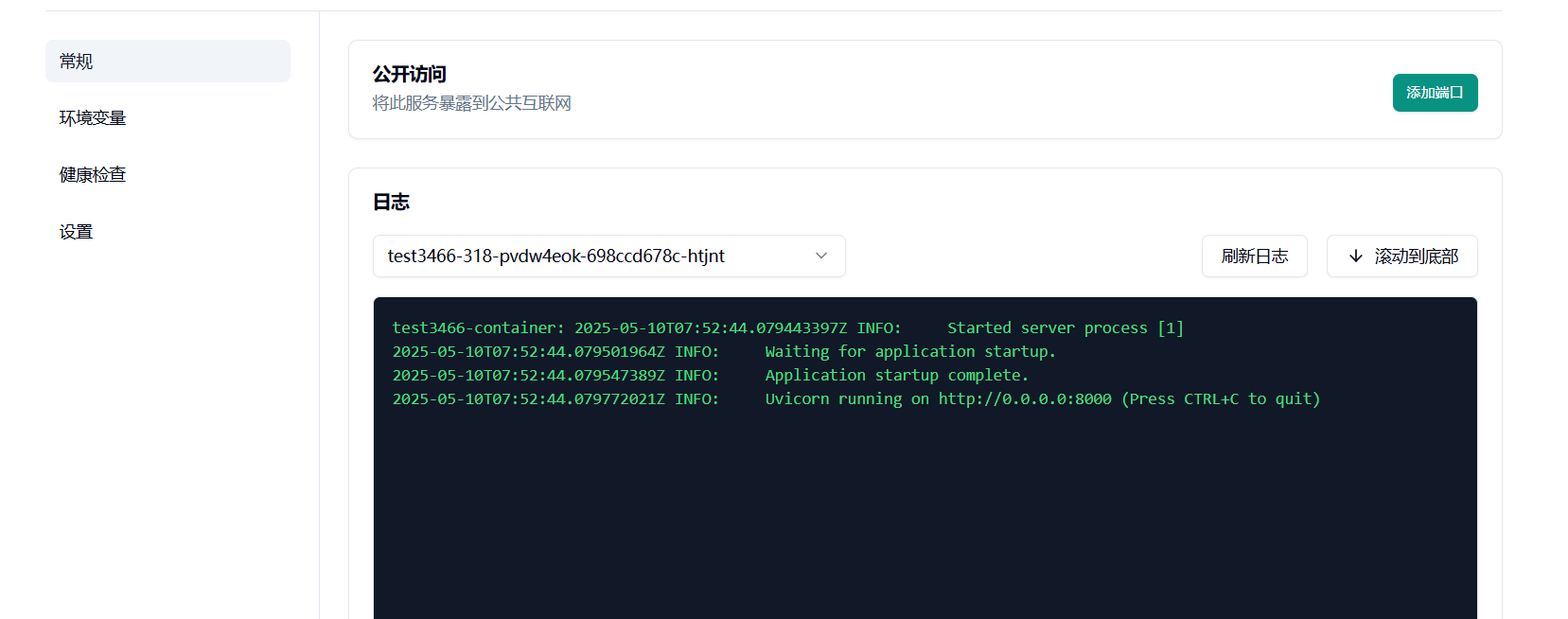
配置 8888 端口(与 TCP 的默认联通)
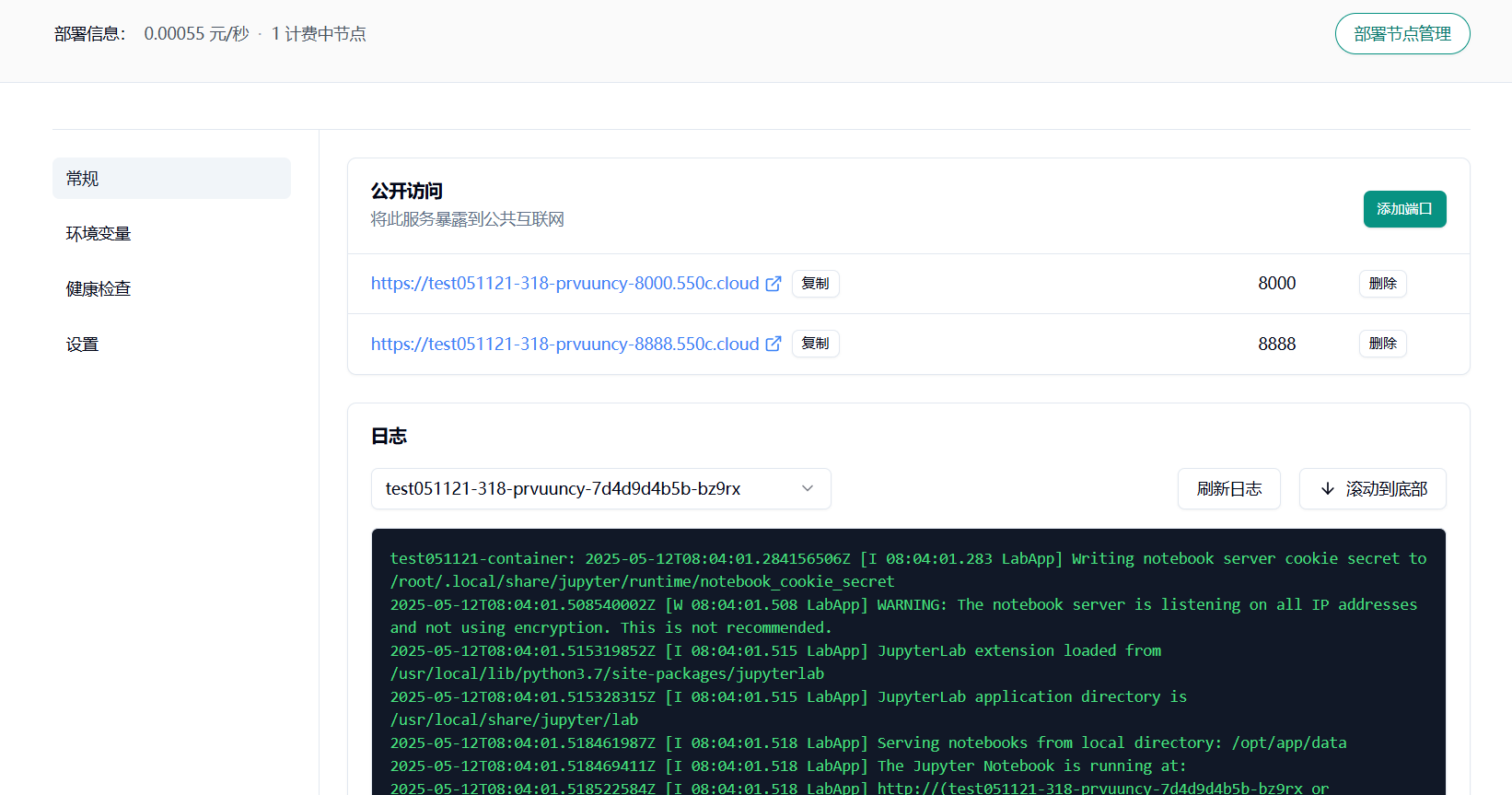
实例运行后,您可以在浏览器的地址栏中输入生成的访问域名,在服务运行日志中找到 token
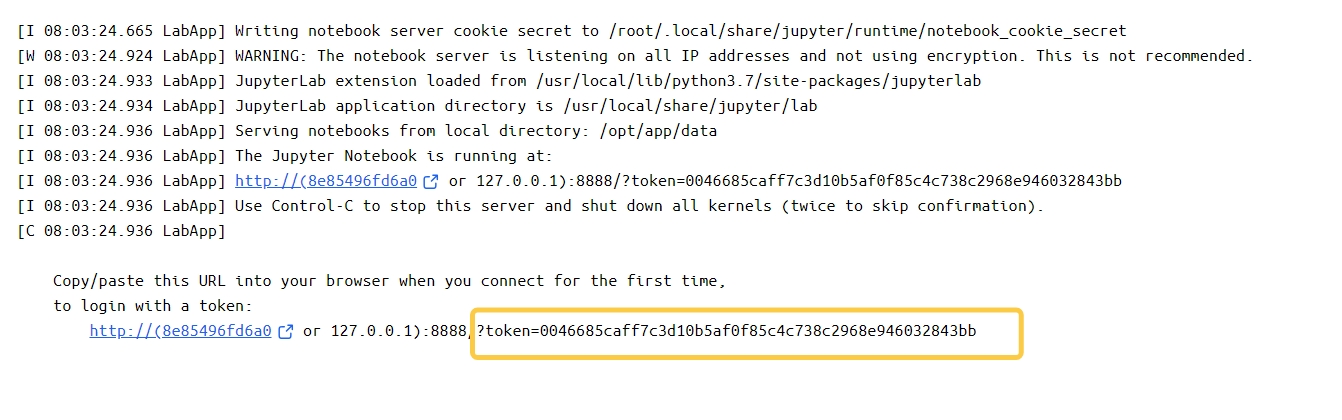
复制到此处即可正常进入登录
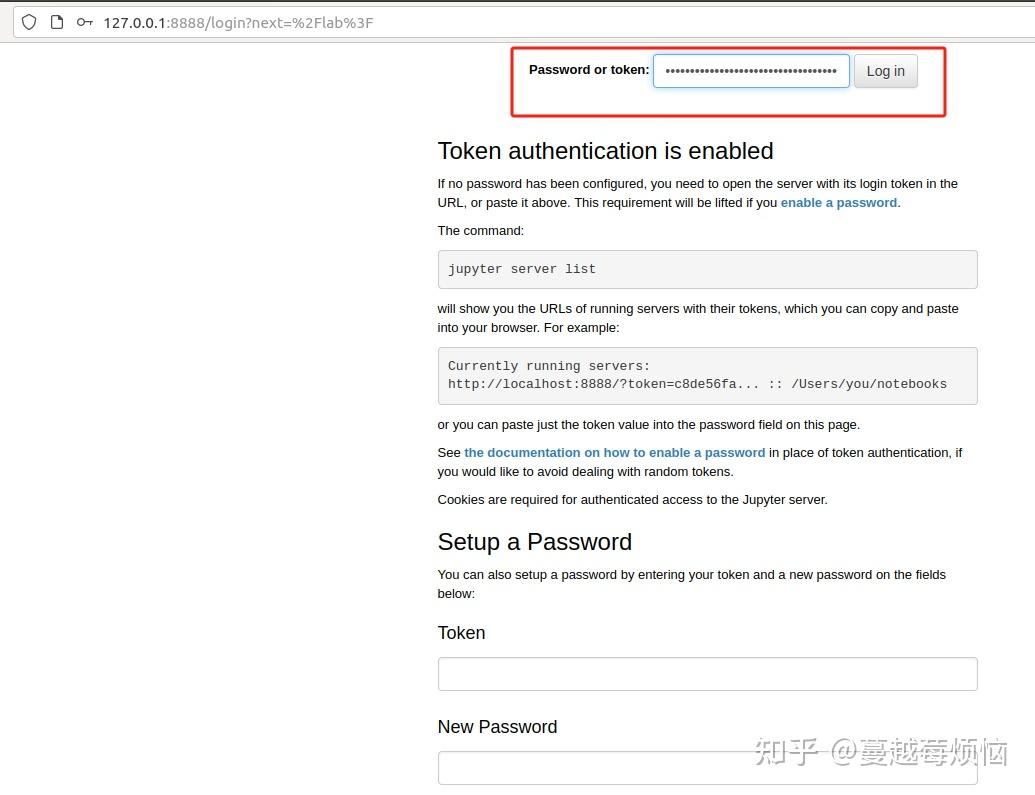
然后开始使用 JupyterLab 服务
现在,您可以编写 Python 代码来学习、测试、微调或训练 Hugging Face 中流行的 AI 模型。如有 缺少库或依赖项,您可以在 notebook 或 Terminal 中在线安装它们。您还可以构建您的容器镜像,以包含基于提供的 Dockerfile 模板的特定库和依赖项。
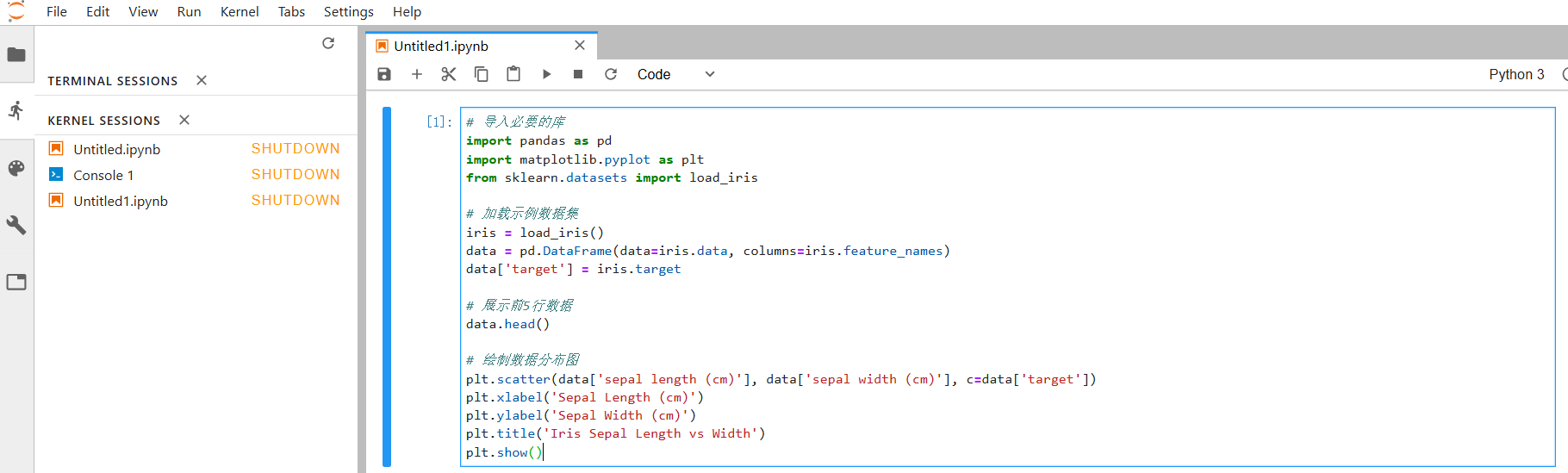
通过共享对 JupyterLab 实例的访问权限,团队成员可以协同编辑同一笔记本或使用相同的终端。在 JupyterLab 终端中进行的操作会实时同步到其他团队成员的浏览器界面中,反之亦然。这种协作体验类似于 WebEx 或 Zoom 中的屏幕共享功能,实现了高效的远程协作。
JupyterLab 是一款开源应用,围绕计算型 Notebook 文档的概念构建。它支持代码共享和执行、数据处理、可视化,并提供一系列交互功能来创建图表。
共绩算力为 AI 与数据科学学习者及从业者提供创新解决方案:通过云端搭建 JupyterLab 环境直接调用高性价比弹性 GPU 算力,用户可无缝开展 CUDA 编程实践,进行 PyTorch/TensorFlow 框架开发,并高效完成模型训练调优、迁移学习及推理部署。突破传统模式三大瓶颈——无需采购昂贵硬件实现成本优化,免去本地环境搭建节省运维精力,更通过即时算力扩容和标准化开发环境显著提升研究效率,使开发者能够专注于核心算法创新与工程实践。
自定义与扩展:利用 Docker Hub 资源优化您的 JupyterLab 镜像
当您当前的任务需求无法由我们提供的默认镜像满足时,您可以选择使用 Docker Hub 上提供的多种预构建 JupyterLab 容器镜像。这些镜像针对不同场景(如人工智能/机器学习、数据科学、高性能计算等)进行了优化,支持开箱即用。此外,您还可以基于 GitHub 上提供的 Dockerfile 模板,灵活定制和扩展符合自身需求的镜像。
镜像名称 | 下载命令 | 特点 |
jupyter/base-notebook |
| 官方基础镜像,适合初学者和轻量级需求。 |
jupyter/minimal-notebook |
| 官方轻量级镜像,启动速度快。 |
quay.io/jupyter/base-notebook |
| 官方维护,基于 quay.io 仓库,稳定可靠。 |
docker.1ms.run/jupyter/minimal-notebook:x86_64-python-3.10.9 |
| 国内源镜像,适合网络条件不佳的用户。 |
JupyterLab 数据持久化容器镜像的构建
为满足无状态容器工作负载的数据持久化需求,我们基于主流公有云存储服务(包括阿里云 OSS、华为云 OBS、腾讯云 COS 等)设计了集成化解决方案。该方案通过以下流程实现 JupyterLab 数据持久化:
- 云存储集成 将云平台存储服务深度集成至预构建的 JupyterLab 容器镜像中。初始部署时需完成:
- 在目标云平台创建存储资源(如 Bucket)
- 通过环境变量向容器注入存储资源标识及访问凭证
- 持久化目录配置 在容器内预设持久化工作目录:
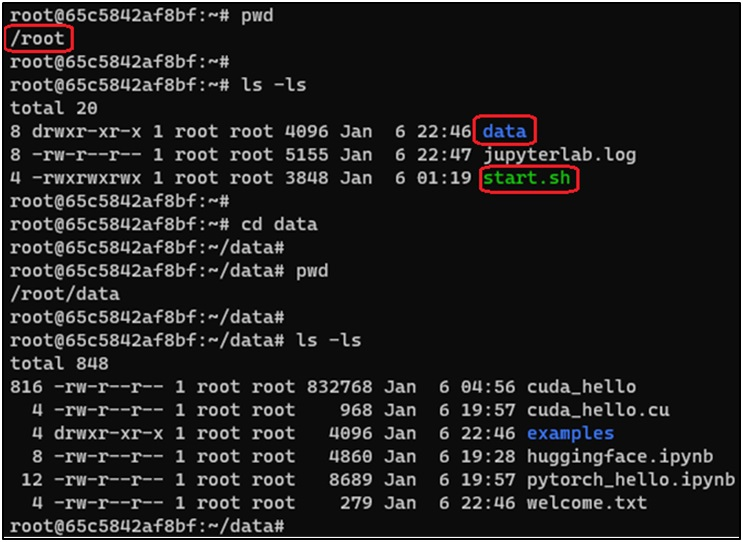
/root/data # 云存储挂载点,所有操作均基于此目录该目录作为容器运行期间所有数据操作的基准路径。
- 自动化同步机制 通过内置的 start.sh 脚本实现双向同步:
- 初始化同步:容器启动时自动执行全量数据拉取,将云端数据同步至本地目录
- 实时监控:基于 inotify 机制持续监听目录变更事件(创建/修改/删除)
- 增量同步:检测到变更后,通过对应云平台 CLI 工具执行增量数据回传
- 跨平台兼容性 采用统一抽象层设计,通过标准化接口适配不同云平台存储服务,确保:
- 同步逻辑与具体云平台解耦
- 通过配置切换即可实现多云部署
- 同步性能优化(如并发传输、断点续传)
方案优势:
- 数据强一致性:通过事件驱动同步机制,保障本地与云端数据偏差<1 秒
- 资源隔离:每个容器实例独立绑定专属存储空间,避免数据污染
- 弹性扩展:存储容量随云平台资源自动扩容,无硬性上限
- 安全传输:全程采用 TLS 加密通道,凭证信息仅驻留于内存环境变量
在后台,我们采用 inotifywait 系统工具对/root/data 目录实施实时监控。无论是通过 JupyterLab 界面手动保存文档,还是系统自动保存机制触发更新,该监控组件均能即时捕获文件创建、删除或修改等操作事件。当检测到变更时,系统会自动激活同步流程。值得注意的是,当前支持的三大公有云平台均内置智能化同步机制,其核心算法通过精确计算源与目标间的数据差异,仅传输变更内容而非全量复制。这种架构设计显著优化了网络传输效率,将云服务 API 调用频率和实际传输数据量均压缩至最低阈值。
关于机器学习资源的处理策略,从 Hugging Face 或 TensorFlow Hub 动态获取的模型参数与数据集默认缓存在系统级隐藏目录(/root/. cache 或/root/。keras) 。此类缓存数据遵循惰性同步原则,仅当用户显式将其迁移至/root/data 目录时才会触发云存储操作。考虑到当前主流云存储服务的标准化定价策略,在主要使用云存储承载代码库的场景下,整体存储成本可控制在极低水平。
要利用预构建的 JupyterLab 容器映像,需要特定的环境变量来传递信息 到容器。如果不需要数据持久性,则可以省略相关的环境变量。
环境变量 | 描述 | |
JUPYTERLAB_PW | 定义 JupyterLab 的访问密码,可选参数,默认值为 'data' | |
ALIYUN_OSS_BUCKET_FOLDER | 阿里云 OSS 接入配置:
|
云存储阿里云 OSS 配置流程
1. 登录阿里云控制台
- 访问 阿里云官网,进入 控制台 > 对象存储 OSS。
创建对象存储 OSS 标准桶
2. 创建存储桶(Bucket)
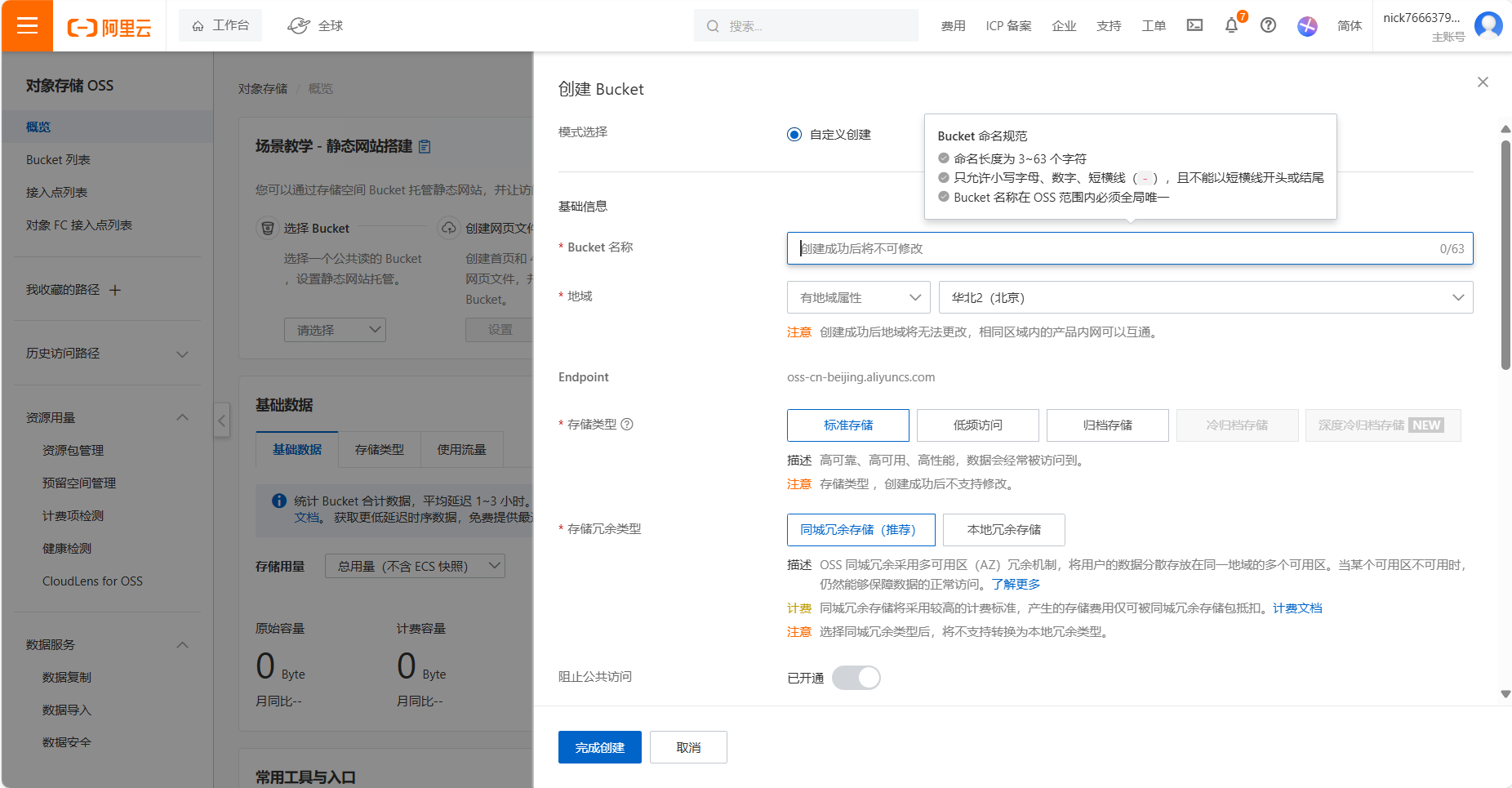
点击 创建 Bucket,进入配置页面。
基础配置:
- Bucket 名称: 命名规则:
- 长度 3~63 个字符。
- 仅允许小写字母、数字、短横线(
-)。 - 不能以短横线开头或结尾。
- 在所选地域内全局唯一。
- 地域选择:推荐选择靠近用户群体的地域,以降低访问延迟。
- 存储类型:
标准存储(高频访问数据推荐使用) - 存储冗余类型:同城
冗余存储说明:多可用区冗余可保障跨机房容灾
- Bucket 名称: 命名规则:
权限配置:
- 读写权限:默认
私有,按需调整为公共读。 - 服务端加密:可选
无或SSE-KMS。
- 读写权限:默认
3. 创建用户目录
- 存储桶创建完成后,进入 文件管理 页面。
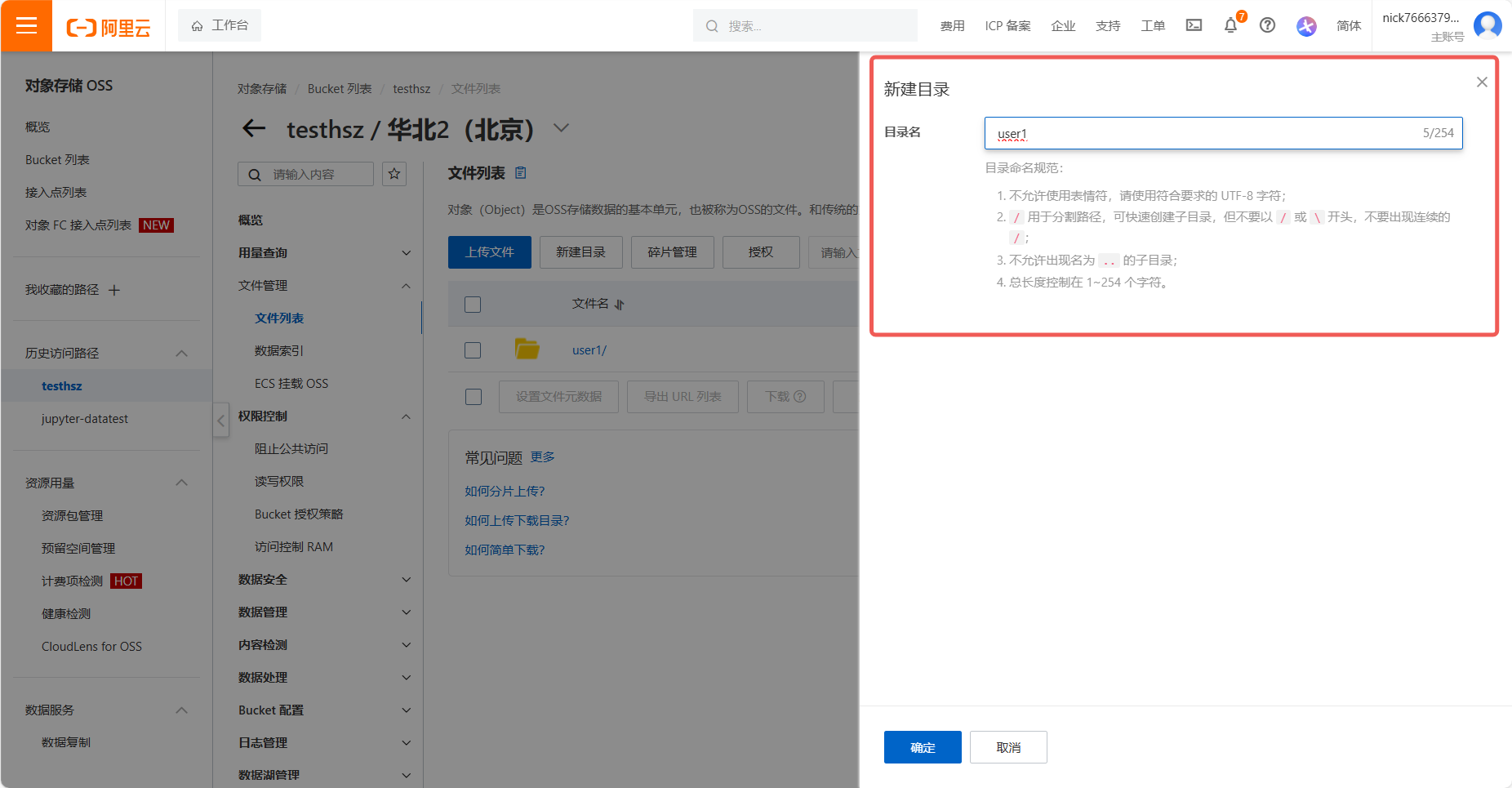
- 点击 新建目录,输入目录名称:
/user1。说明:OSS 为扁平化存储,目录通过前缀模拟,直接输入路径即可。
4. 完成与验证
- 点击 确定,完成存储桶创建。
- 验证操作:
- 在
Bucket 列表中查看新建的 XXX(刚才创建的桶的名称)。 - 进入存储桶,确认目录
/user1已存在。 - 通过 API/SDK 或控制台上传测试文件,确保读写正常。
- 在
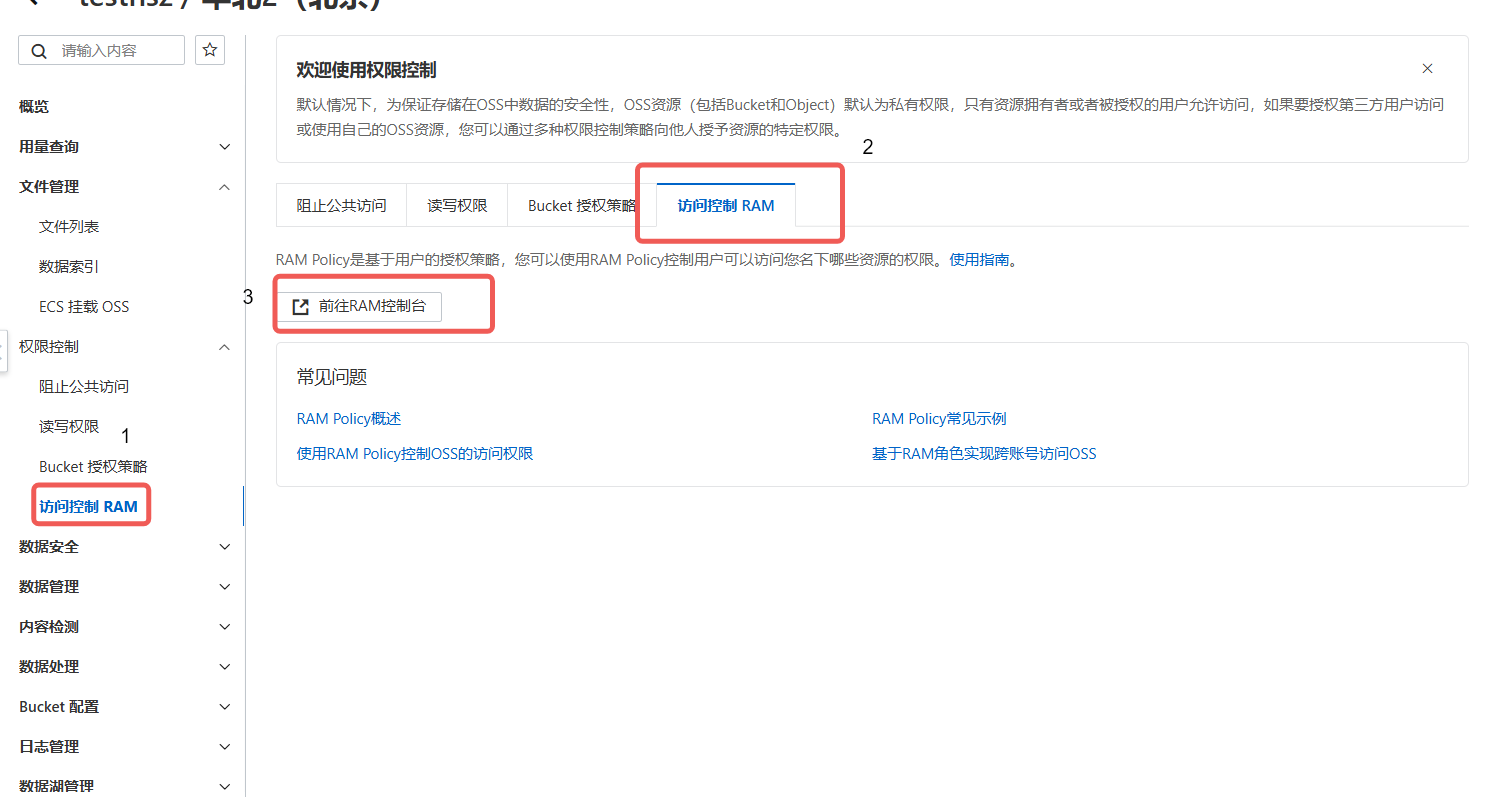
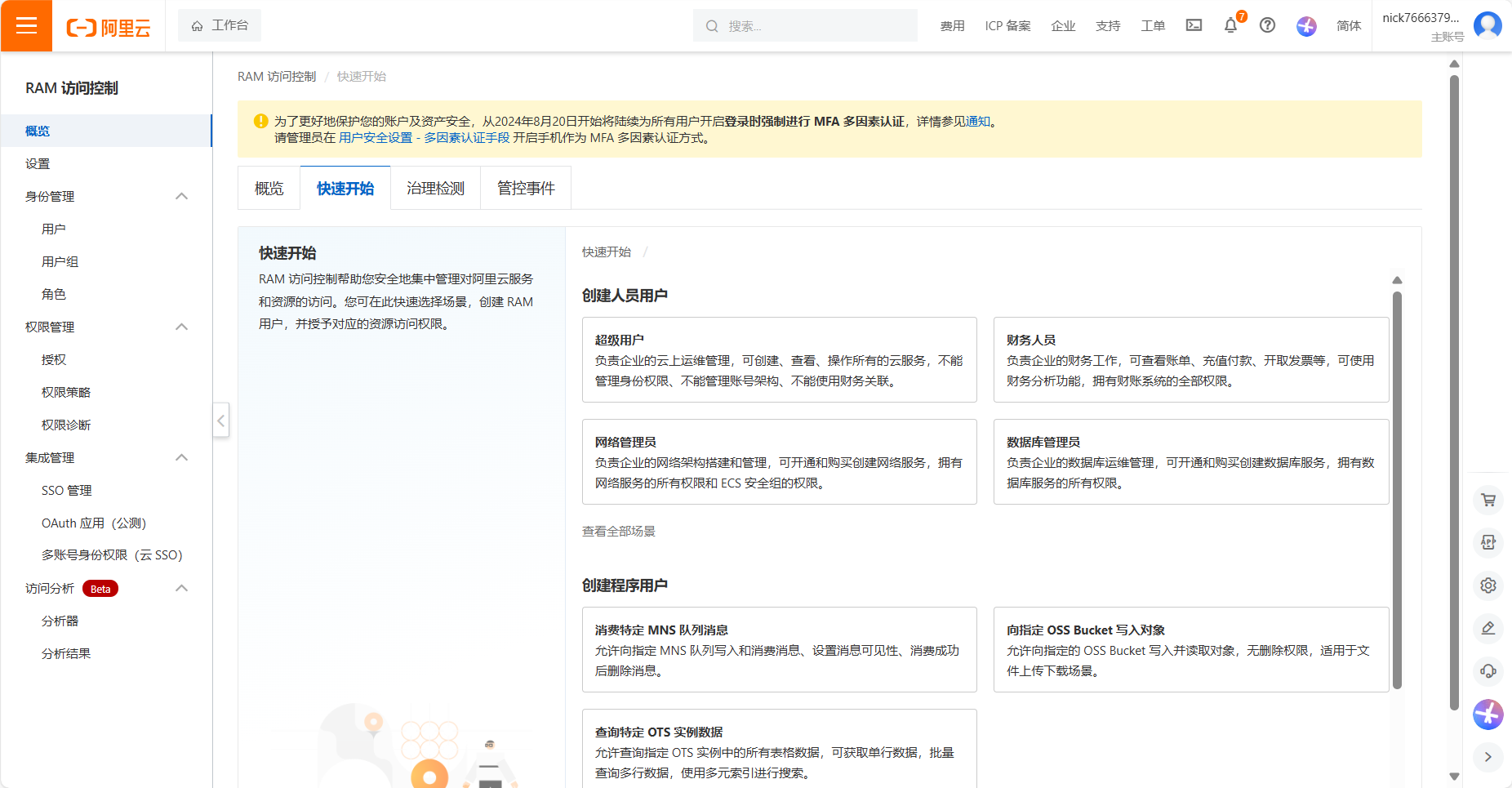
5.生成访问密钥:在 RAM 控制台创建子账号,授予OSS读写权限,生成 AccessKey 和 SecretKey
选择对应适配的角色权限并开通:
使用提供的 JSON 文件创建 OSS IAM 策略(“access_its_own_folder”)。此策略将附加到 OSS IAM 用户,确保每个用户都可以独占访问同一 存储桶中自己的文件夹。
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": [
"oss:PutObject",
"oss:GetObject",
"oss:DeleteObject"
],
"Resource": [
"acs:oss:*:*:your-oss-bucket-name/${ram:User}/*",
"acs:oss:*:*:your-oss-bucket-name/${ram:User}"
]
},
{
"Effect": "Allow",
"Action": "oss:ListObjects",
"Resource": "acs:oss:*:*:your-oss-bucket-name",
"Condition": {
"StringLike": {
"oss:Prefix": "${ram:User}/*"
}
}
}
]
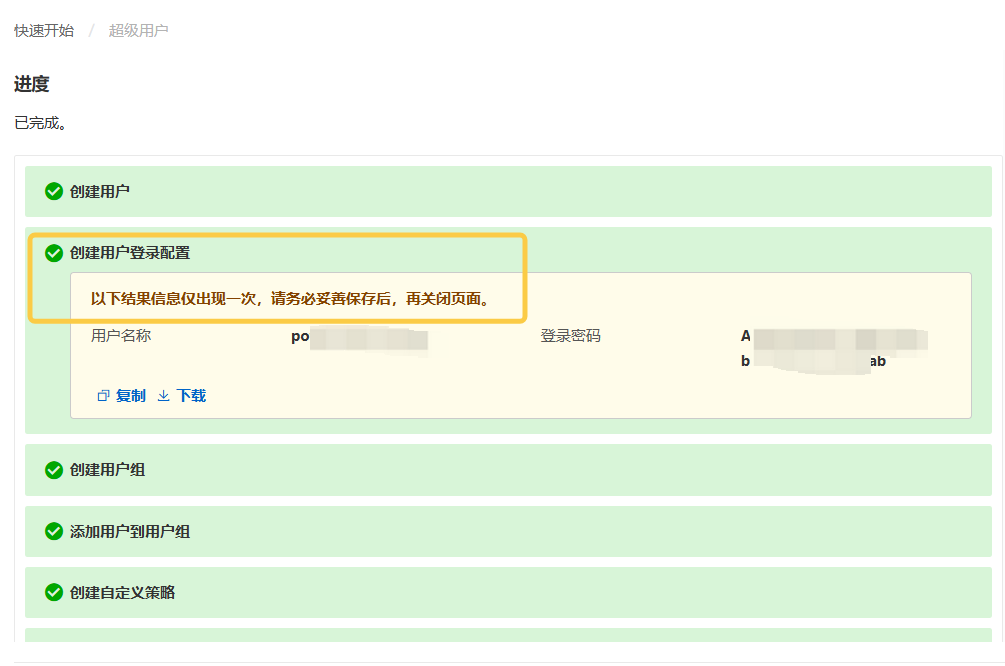
}创建好密码后及时保存用户名称和密码相关信息(Access Key/Secret Key 对)
注意事项
不可修改项:创建后,Bucket 名称、地域、存储冗余类型均不可更改。
费用影响:多可用区冗余存储的单价高于本地冗余,请根据业务需求选择。
数据安全:私有 Bucket 需通过签名 URL 或 STS 临时授权访问。
当在共绩算力控制台上运行 JupyterLab 容器并将 阿里云 OSS 作为后端云存储时,三个与 阿里云 OSS 相关的环境变量用于将访问密钥 ID/访问密钥,以及存储桶和文件夹名称传递给容器。