通过镜像站下载插件并编译
本文面向在共绩算力云主机上做推理框架部署、模型训练加速的开发者,介绍如何借助 GitHub 镜像站把需要编译的插件源码拉取到云主机,再完成本地编译安装。常见场景包括 flash-attention、xformers、apex、triton 等需要 CUDA 扩展的 Python 包,核心流程一致。
示例插件:Dao-AILab/flash-attention —— Tri Dao 团队开源的高性能注意力算子,是 vLLM、SGLang 等推理框架的关键依赖。 加速代理:https://ghfast.top/(第三方公益节点,不承诺 100% 可用、不保证带宽、不保证长期稳定运行)
- 云主机实例在国内网络环境下直连 GitHub 克隆速度慢或失败
- 需要源码编译的 Python 扩展包(flash-attention、xformers、apex 等)拉取困难
- 官方 PyPI wheel 与云主机的 CUDA / PyTorch 版本不匹配,必须本地编译
- 编译完成后需要把环境打包成自定义镜像,供弹性部署服务一键使用
启动带 CUDA 环境的云主机实例
Section titled “启动带 CUDA 环境的云主机实例”在共绩控制台创建云主机实例,选择官方 PyTorch / CUDA 基础镜像(如 pytorch:2.3.0-cuda12.1-cudnn8-devel),确保镜像内包含 nvcc 编译器而非仅 runtime。实例启动后通过浏览器 Console 或 SSH 进入调试终端。
验证编译工具链:
nvcc --versionpython -c "import torch; print(torch.__version__, torch.version.cuda)"gcc --version规划插件源码与编译目录
Section titled “规划插件源码与编译目录”推荐把源码集中放在一个固定目录,便于后续回溯和重编译:
- 本地盘(快速试验):
/root/plugins/,实例销毁后丢失 - 共享存储卷(推荐):
/mnt/shared/plugins/,编译完成后可复用到其他云主机或弹性部署服务。共享存储卷的挂载方式参考 云主机中使用共享存储卷。
本文后续示例统一使用 /root/plugins/,实际使用时按需替换。
mkdir -p /root/pluginscd /root/plugins配置 GitHub Personal Access Token(按需)
Section titled “配置 GitHub Personal Access Token(按需)”公开仓库(如 flash-attention)无需 Token 即可克隆。但有两种情况建议提前准备:
- 团队内部的 私有仓库:镜像站不支持 SSH 协议(
git@github.com:...无效),必须用 HTTPS + Token 克隆 - 高频克隆触发 GitHub 匿名访问速率限制:携带 Token 的请求有更高配额
Token 获取地址:https://github.com/settings/tokens
生成时选择 repo 作用域即可。拿到形如 ghp_xxxxxxxxxxxxxxxxxxxxxxxx 的字符串后通过环境变量注入:
export GITHUB_TOKEN="ghp_xxxxxxxxxxxxxxxxxxxxxxxx"⚠️ Token 属于敏感凭证,不要硬编码在脚本、Dockerfile 或打包成的自定义镜像中,推荐每次在终端临时
export,或写入~/.bashrc个人环境。
核心流程:下载并编译 flash-attention
Section titled “核心流程:下载并编译 flash-attention”步骤 1:通过镜像站克隆源码
Section titled “步骤 1:通过镜像站克隆源码”公开仓库直接在原始 URL 前拼接 https://ghfast.top/ 即可:
cd /root/pluginsgit clone https://ghfast.top/https://github.com/Dao-AILab/flash-attention.git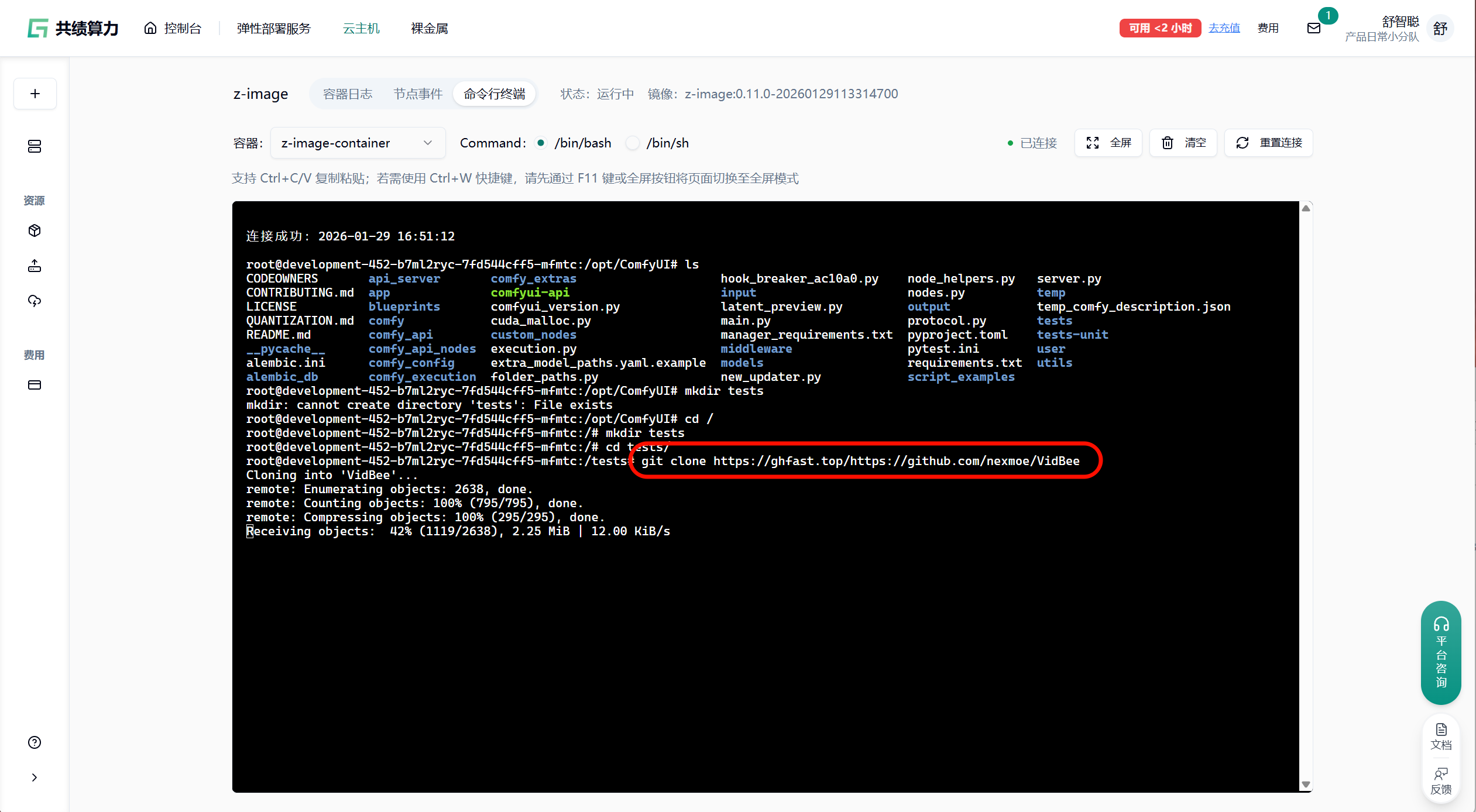
如果是 私有仓库,格式为:
git clone https://用户名:$GITHUB_TOKEN@ghfast.top/https://github.com/用户名/仓库名.git步骤 2:切换到目标版本
Section titled “步骤 2:切换到目标版本”编译型插件对版本敏感,务必锁定到具体 tag,避免 main 分支的 breaking change 导致编译失败。
cd /root/plugins/flash-attentiongit checkout v2.7.2.post1查看所有可用 tag:
git tag --sort=-v:refname | head -20步骤 3:安装编译依赖
Section titled “步骤 3:安装编译依赖”flash-attention 的编译过程依赖 ninja(否则默认串行编译,单次编译耗时可达数小时):
pip install ninja packaging wheel验证 ninja 可用:
ninja --version步骤 4:设置编译环境变量
Section titled “步骤 4:设置编译环境变量”CUDA 扩展编译会占用大量 CPU 与内存。如果不限制并行度,容易在编译中途 OOM 被 kill。
export MAX_JOBS=4export TORCH_CUDA_ARCH_LIST="8.9"export FLASH_ATTENTION_FORCE_BUILD=TRUE三个变量的作用:
-
MAX_JOBS:限制 ninja 并行编译任务数,4090 实例一般设 4;内存充裕可设到 8 -
TORCH_CUDA_ARCH_LIST:指定编译目标架构,只编当前 GPU 对应架构能显著缩短耗时- RTX 4090 / L20 / L40:
8.9 - A100:
8.0 - H20 / H800 / H100:
9.0 - 如需跨卡通用镜像:
"8.0;8.9;9.0"
- RTX 4090 / L20 / L40:
-
FLASH_ATTENTION_FORCE_BUILD:强制从源码编译,不尝试拉取官方 wheel
步骤 5:执行编译安装
Section titled “步骤 5:执行编译安装”cd /root/plugins/flash-attentionpip install -e . --no-build-isolation两个关键参数:
-e:editable 安装,源码目录直接挂载为包路径,方便后续本地改代码调试--no-build-isolation:复用当前环境的 PyTorch、CUDA,避免 pip 在临时虚拟环境中重装 torch 导致 ABI 不匹配
编译耗时在 4090 上大约 20~40 分钟,取决于 MAX_JOBS 与 TORCH_CUDA_ARCH_LIST 配置。
步骤 6:验证安装
Section titled “步骤 6:验证安装”python -c "import flash_attn; print(flash_attn.__version__)"python -c "from flash_attn import flash_attn_func; print(flash_attn_func)"能够正常打印版本号与函数对象,即表示编译安装成功。
优先使用 Releases 预编译 wheel
Section titled “优先使用 Releases 预编译 wheel”flash-attention 每个 tag 会在 Releases 页面附带针对主流 torch × CUDA × Python 组合的预编译 wheel。在版本匹配的前提下,直接装 wheel 可以省掉 30 分钟的编译等待,应作为首选方案。
先通过浏览器访问 Releases 页面 确认对应版本 wheel 的文件名,再用镜像站下载:
wget https://ghfast.top/https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.2.post1/flash_attn-2.7.2.post1+cu12torch2.3cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
pip install flash_attn-2.7.2.post1+cu12torch2.3cxx11abiFALSE-cp310-cp310-linux_x86_64.whlwheel 的文件名里会同时编码 cuXX(CUDA 版本)、torchX.Y(PyTorch 版本)、cxx11abiTRUE/FALSE、cpXX(Python 版本),四项必须完全匹配当前环境,否则仍需回退到源码编译。
后台编译,避免 SSH 断开中断
Section titled “后台编译,避免 SSH 断开中断”编译过程长达数十分钟,SSH 会话中断会导致前功尽弃。推荐 nohup 转后台并落盘日志:
cd /root/plugins/flash-attention
nohup pip install -e . --no-build-isolation \ > /root/plugins/flash-attention-build.log 2>&1 &实时查看编译进度:
tail -f /root/plugins/flash-attention-build.log更系统的后台托管方案参考 守护进程(开后台)。
把编译产物打包成自定义镜像
Section titled “把编译产物打包成自定义镜像”编译一次耗时较长,不要让每个新启动的云主机或弹性部署实例都重新编译。推荐流程:
- 在一台云主机中按上述步骤完成 flash-attention 编译安装
- 通过控制台「保存为镜像」把当前实例打包成自定义镜像
- 后续新建云主机、弹性部署服务直接选用该镜像,flash-attention 开箱即用
镜像保存参考 如何使用基础镜像/通过基础镜像保存的镜像。
编译产物放到共享存储卷
Section titled “编译产物放到共享存储卷”若不打算打包镜像,也可以把编译好的 wheel 保存到共享存储卷,供其他实例直接 pip install:
cd /root/plugins/flash-attentionpython setup.py bdist_wheel
cp dist/*.whl /mnt/shared/wheels/其他实例挂载同一共享卷后:
pip install /mnt/shared/wheels/flash_attn-2.7.2.post1-*.whlQ:编译中途报错 Killed 或 out of memory?
A:并行编译占用内存超过实例配额被系统 OOM Killer 终止。调小 MAX_JOBS(从 4 改为 2 或 1)重试,或选用内存更大的云主机规格。
Q:编译成功但 import flash_attn 报 undefined symbol?
A:PyTorch ABI 不匹配。通常是 wheel 版本与当前 PyTorch 不对应,或源码编译时环境变量里残留了旧 PyTorch 路径。清理 pip uninstall flash-attn 后,重新确认 torch.version、torch.version.cuda、Python 版本三者一致再编。
Q:TORCH_CUDA_ARCH_LIST 应该设什么?
A:用 python -c "import torch; print(torch.cuda.get_device_capability())" 查当前 GPU 的 compute capability,例如 (8, 9) 对应 TORCH_CUDA_ARCH_LIST="8.9"。
Q:ghfast.top 克隆卡住不动?
A:镜像节点负载波动,按 Ctrl+C 中断后重试即可。git 支持断点续传(shallow clone 除外)。必要时可切换到其他公益镜像或直连。
Q:能否跳过镜像站直连 GitHub?
A:可以,去掉 URL 前的 https://ghfast.top/ 前缀即可。云主机外网若可直连 GitHub,直连速度往往更稳定。
- 镜像站为第三方公益服务,稳定性取决于节点状态,不适合作为生产 CI/CD 的强依赖
- 不要把
GITHUB_TOKEN硬编码到脚本、Dockerfile 或打包的自定义镜像中,始终通过环境变量注入 - 源码编译对 PyTorch、CUDA、Python 三者版本非常敏感,切换任一组件后通常需要重编
- 不支持 SSH 协议克隆(
git@github.com:...走镜像站无效),私有仓库必须用 HTTPS + Token - 编译耗时较长,务必通过
nohup/screen转后台,并把成果沉淀到自定义镜像或共享存储卷 - 不建议在长期脚本、CI/CD 配置中硬编码镜像地址,建议通过环境变量统一管理
- 仅用于学术研究与个人学习用途,请勿用于商业用途或任何违法用途
祝插件编译顺利~