
Maya 多模态模型支持 8 国语言
多模态与多语种同时进化 图像理解和语言生成的结合一直是 AI 研究的热点,但跨语种支持通常是短板。Maya 的出现正在改写这一常识,由 Cohere For AI Community 打造,这款模型不仅打通了视觉与语言,还能在八种语言中稳定运行,包括中文、阿拉伯语和印地语。 架构与数据独特性 Ma...
2025年12月1日
1 分钟
探索前沿技术,分享实践经验,追踪行业动态
多模态与多语种同时进化 图像理解和语言生成的结合一直是 AI 研究的热点,但跨语种支持通常是短板。Maya 的出现正在改写这一常识,由 Cohere For AI Community 打造,这款模型不仅打通了视觉与语言,还能在八种语言中稳定运行,包括中文、阿拉伯语和印地语。 架构与数据独特性 Ma...

专为真实图像优化的多语种 OCR NCSOFT 发布的 VARCO-VISION-2.0-1.7B-OCR,是当前视觉 OCR 模型里一个很值得关注的新成员。相较于那些动辄十几亿参数的多模态大家伙,这个模型只有 17 亿参数,但效果并没因为“瘦身”而缩水。 它不是普通的图文大模型(VLM),也不只...

VARCO-VISION-2.0-1.7B 是少数在端侧部署仍保有强大视觉理解能力的模型之一。由 NCSOFT 发布,这个多模态模型支持图文混合输入,并具备多图推理与文本本地化 OCR,专为韩文优化,但在英文任务中依然表现不俗。用轻量化模型处理结构化图像内容的能力,正在重塑移动设备上的 AI 应用格...

图像模型首次懂视频 LLaVA-Onevision 是一种由 LLaVA 团队发布的新型多模态大模型,结合了 Qwen2 的语言理解能力和视觉对齐能力。 这套模型的独特之处在于,它既能处理单图、多图,又能自然迁移至视频理解场景。对开发者来说,意味着一个统一的 API 可以让不同模态任务无缝切换。...

更小但更强的多模态利器 视觉语言模型赛道的惯性思维是,大就是强。打榜比拼中,MM1-30B、LLava-Next-34B 这些高参数巨兽长期霸榜。 然而 Hugging Face 推出的 Idefics2 推翻了这套逻辑:仅用 8B 参数,却能在一众大模型中杀出血路。这不仅是一次工程层面的胜利,更...

拆解轻量视觉模型的黑马 LLaVA-Phi-3-mini 是 XTuner 团队推出的一款多模态小模型,融合了 Microsoft 的 Phi-3-mini 和 OpenAI 的 CLIP-ViT-Large-patch14-336,经由 ShareGPT4V-PT 与 InternVL-SFT...

多模态终于进化到能读文档了 Hugging Face 带来了 Idefics3,一个重新定义视觉语言理解边界的开源模型。它不仅支持图文混合输入,更重要的是在文件分析和视觉推理场景中性能大幅跃升,让人第一次感到多模态模型真的有现实可用性。 Idefics3 的前身 Idefics2 就已经是 Hug...

多模态不是终点 它只是起点 微软最新发布的多模态模型 Magma 不是在走传统视觉语言模型那条老路。它针对的不是静态感知任务,而是让 AI 理解、计划并行动。换句话说,Magma 并不只是看图说话,更像是看图干活。 在整个 Agent 赛道,Magma 给出了一个令人信服的方向:AI 不止要理解世...

全新架构带来超长上下文 Llama 4 Scout 的问世,再次把上下文窗口拉到了一个几乎荒谬的长度——1000 万 token。这并非仅仅是一个宣传用的数据,在实际部署中,它确实可以处理数百万字的输入而不崩溃,更重要的是:模型理解长文的能力明显增强。 这与 Meta 在架构设计上的大刀阔斧直接相...
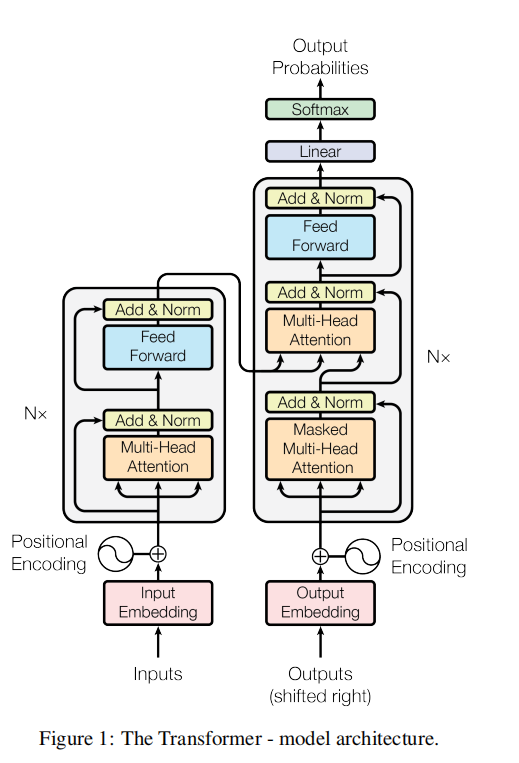
Transformer 是什么? Transformer 是 2017 年 Google 提出的革命性深度学习架构,它彻底改变了自然语言处理(NLP)领域的游戏规则。今天我们将深入探讨这篇被誉为"改变 AI 历史"的论文——《Attention Is All You Need》,理解 GPT、BER...

时间理解才是图像编辑的新上限 图像生成的“智商门槛”正在悄然提高,而 NVIDIA 刚发布的 ChronoEdit-14B 正好证明了这一趋势。这个模型不是传统意义上的图像编辑器,而是一个能理解“动作”并进行时序推理的世界模拟工具。它不仅能改图,还懂得改“怎么动”。 ChronoEdit 的最大亮...

Emu3.5 是北京智源研究院(BAAI)推出的新一代多模态大模型,在架构层面做出了一个激进决策——不再区分视觉和语言的输入输出,而是通过统一的 token 序列进行处理。这种做法听起来简单,但一旦扩展到超过 10 万亿 token 规模的跨模态预训练,带来的语义一致性和生成流畅性,已经明显超过依赖...

NVIDIA 推出全新的 Nemotron Nano v2 12B VL 模型为多模态 AI 领域注入强劲动力。这款前沿模型由 NVIDIA 精心打造,旨在提供卓越的多图像推理、视频理解以及强大的文档智能处理能力,即日起便可用于商业部署。 核心亮点 Nemotron Nano v2 12B VL 最...
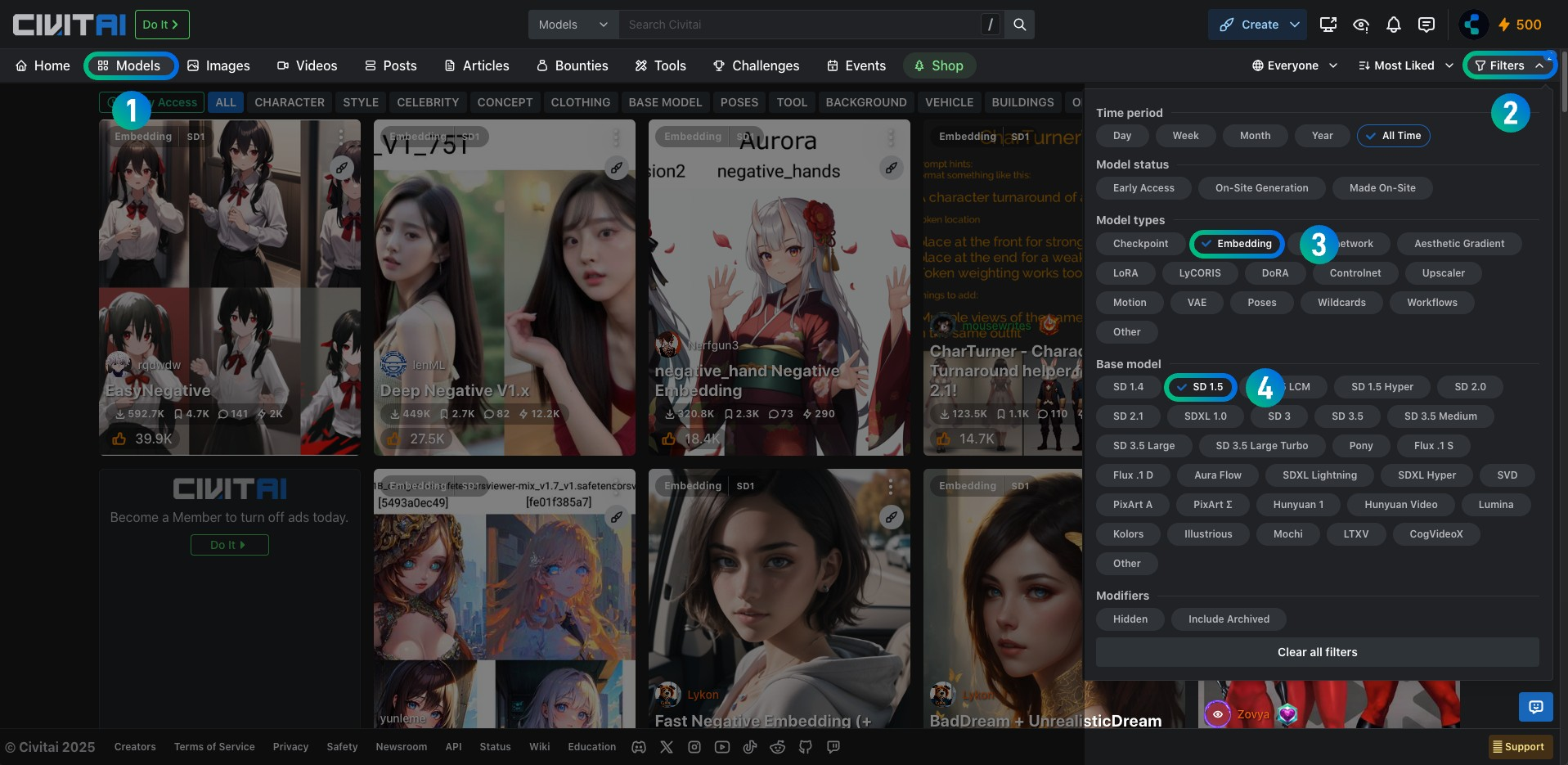
Embedding 模型是 AI 绘图中一个非常实用的工具,它能够将复杂的提示词效果压缩成一个小小的模型文件,让你轻松实现特定的艺术风格、人物特征或画面效果。这些模型通常只有几 KB 大小,但效果却非常强大,是提升图像生成质量的重要工具。 ComfyUI 作为目前最强大的 Stable Diffus...
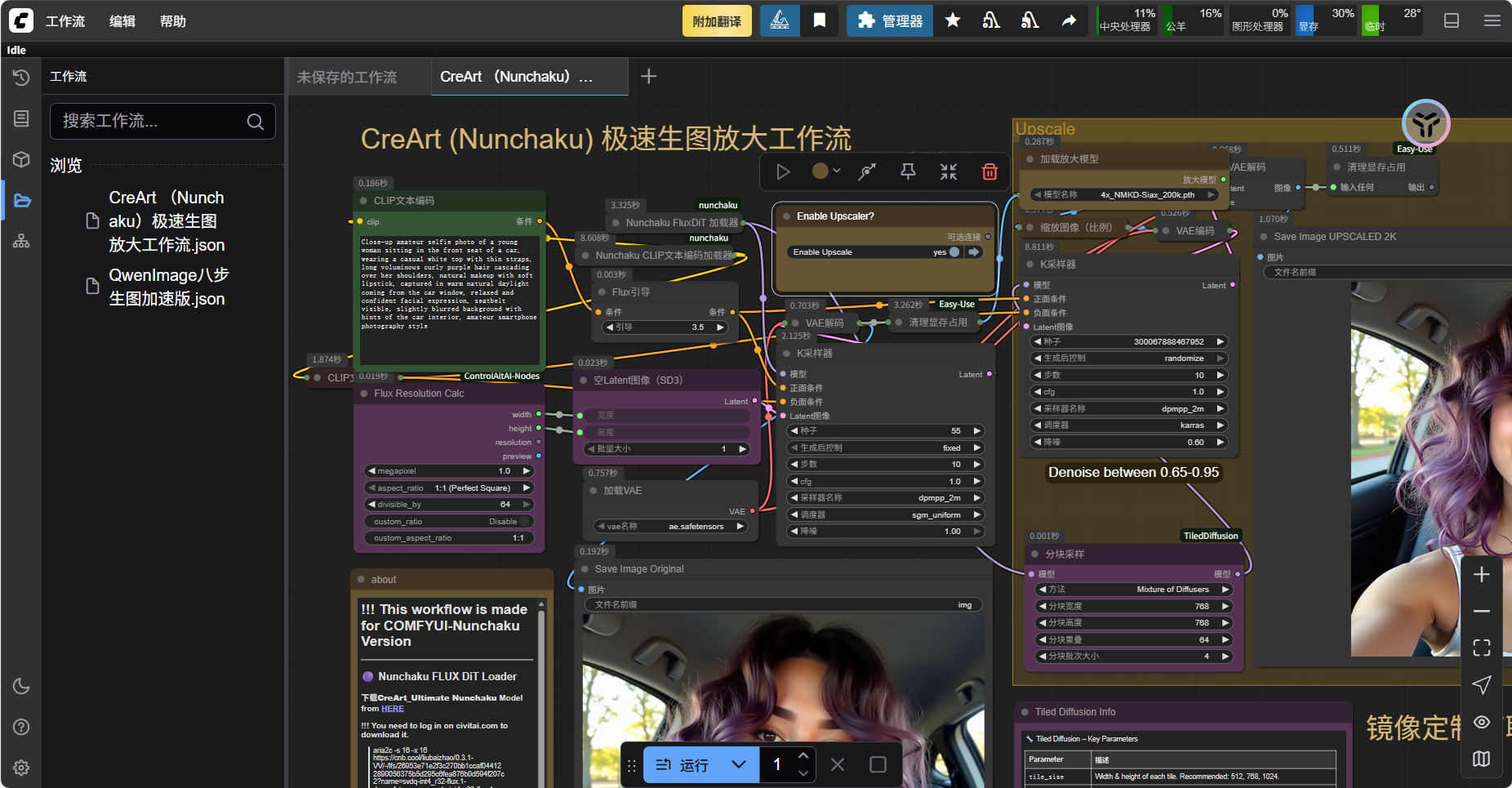
在 AI 图像生成过程中,我们经常因为设备性能限制无法一次性生成大尺寸图片,通常需要先生成小尺寸图像再进行放大。ComfyUI 提供了多种图片放大方法,每种方法都有其独特的特点和适用场景。 本文将详细介绍 ComfyUI 中三种主要的图片放大方法:像素重新采样、SD 二次采样放大和使用放大模型放大图...
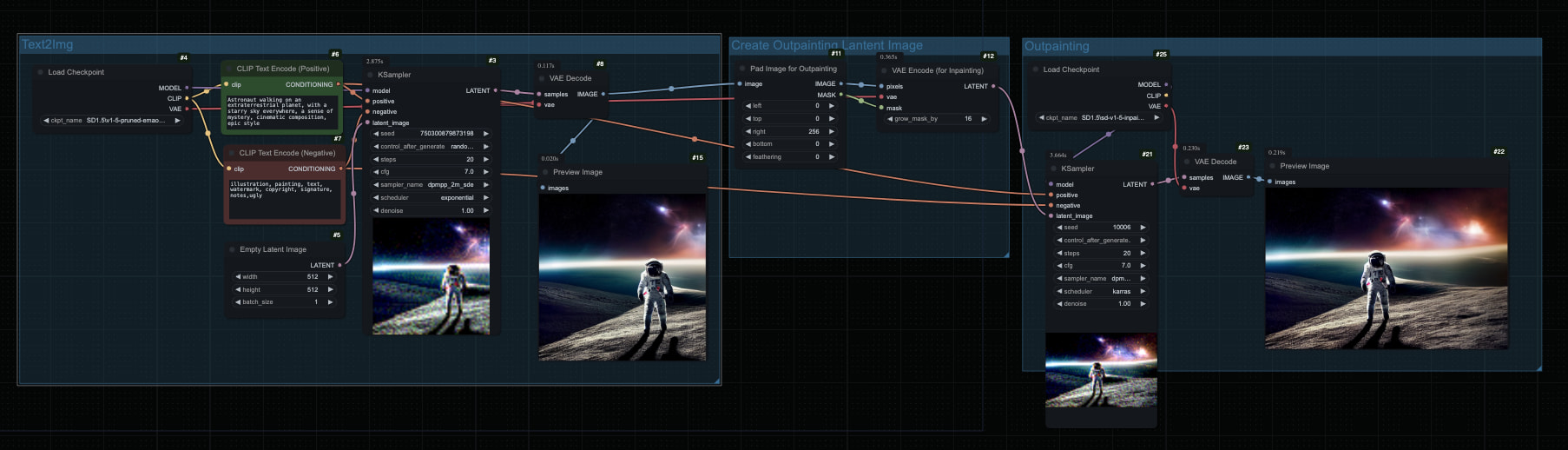
扩图(Outpainting)是 AI 绘图中一项非常实用的技术,它能够让你在原始图片的边缘区域继续生成内容,从而扩展图片的尺寸和视野范围。无论是补充画面缺失的部分、调整图片的宽高比例,还是创造更大场景的视觉效果,扩图都能帮你实现。 ComfyUI 作为目前最强大的 Stable Diffusion...

局部重绘是 AI 绘图中最实用的功能之一,它让你能够精确地修改图像的特定部分,而不影响其他区域。无论是清除画面中的物体、修改人物表情、调整服饰颜色,还是替换背景元素,局部重绘都能帮你实现。 ComfyUI 作为目前最强大的 Stable Diffusion 工作流工具,在局部重绘方面提供了灵活的控制...

AI 前沿观察发现 Google 推出的 ShieldGemma 2 模型为图像内容安全领域带来了一次重要升级。这款基于 Gemma 3 打造的 40 亿参数模型,专为图像安全分类设计,旨在帮助开发者和研究人员有效规避有害内容风险,这不仅是对现有 AI 安全模型的补充,更是一种前瞻性的内容防护策略...
共绩科技 2023 年成立于清华,专注于构建融合算力与电力的智能调度网络,旨在提供平价、可靠、绿色的算力服务,使 AI 技术真正普及至每个人。通过精细调度算法,已为多家 AIGC 领军企业及科研机构提供高效算力,目标提升资源利用率 60%。作为一群清华背景的年轻创新者,我们在 2023 年秋季获得奇绩创坛等投资,正引领算力革命,开启普惠科技新篇章。
