容器化部署 Qwen3.5-27B
本文聚焦 Qwen/Qwen3.5-27B 在 vLLM 上的两类常见部署方式:
- 4 卡部署:更适合单机 4×4090 这类资源受限环境,优先兼顾可用性与成本。
- 8 卡部署:更接近官方标准示例,适合更长上下文、更高吞吐和更稳定的并发。
同时提供对应的 启动命令、最佳实践、OpenAI 兼容调用示例 和 适用场景。
选择 四卡/八卡 4090(运行最低要求四卡)
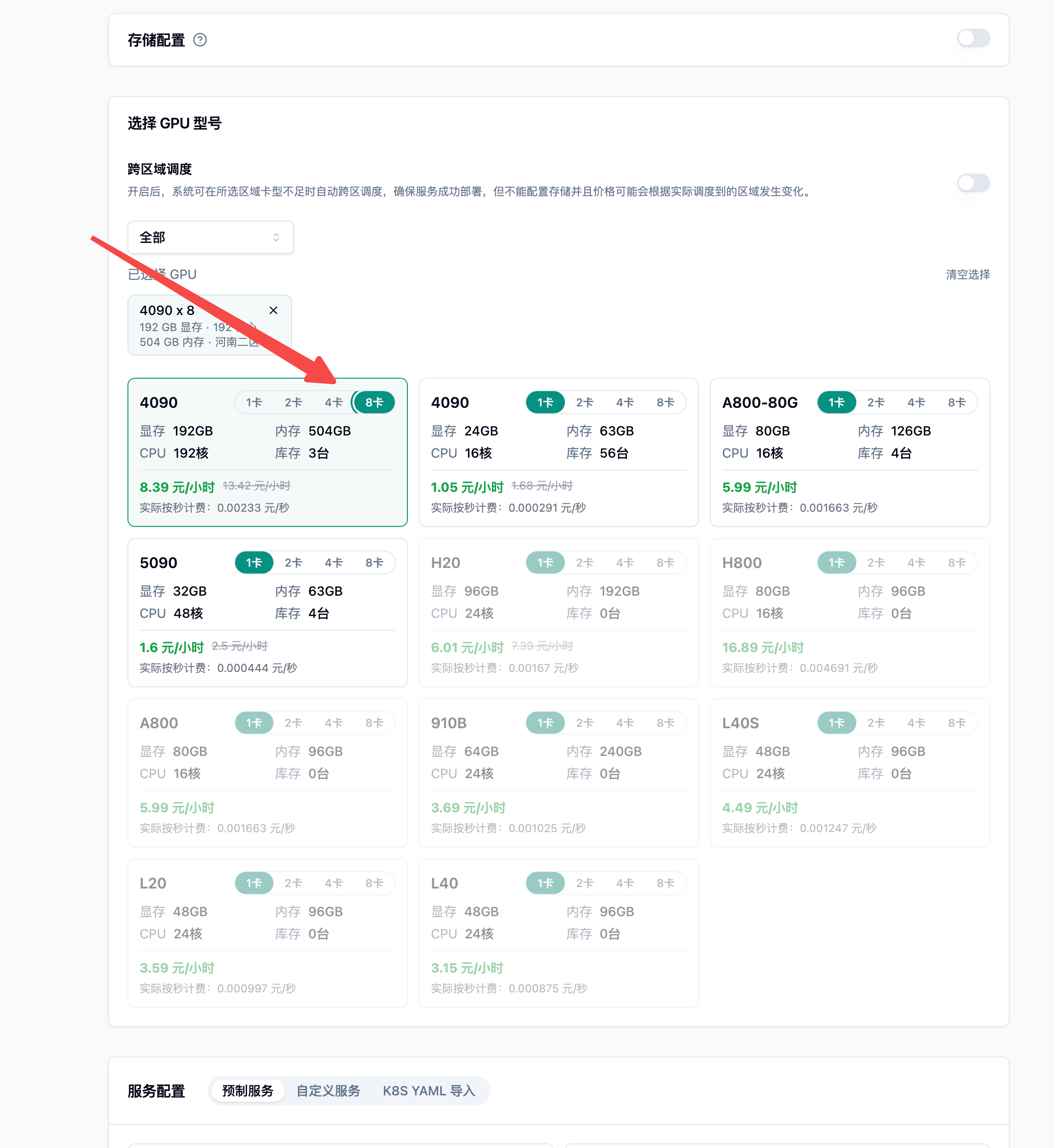
在预制镜像里面选择对应镜像
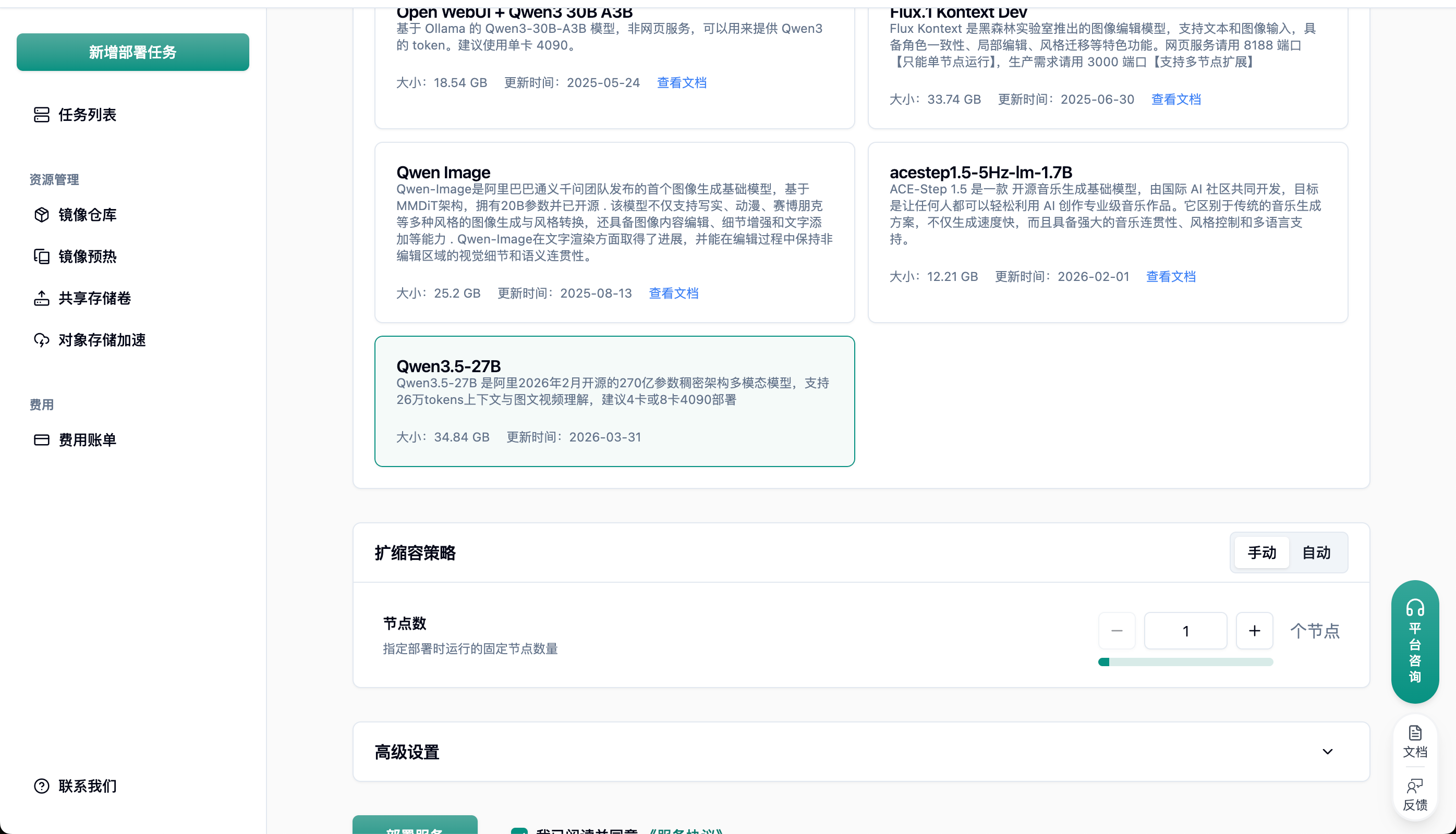
1. Qwen3.5-27B 4 卡部署方案
Section titled “1. Qwen3.5-27B 4 卡部署方案”适合单机 4×RTX 4090(24GB) 或同级别 4 卡环境。
1.1 推荐启动命令
Section titled “1.1 推荐启动命令”vllm serve Qwen/Qwen3.5-27B \ --tensor-parallel-size 4 \ --max-model-len 65536 \ --max-num-seqs 128 \ --gpu-memory-utilization 0.90 \ --kv-cache-dtype fp81.2 最佳实践
Section titled “1.2 最佳实践”- 优先控制上下文长度:
65536是比较务实的起点,明显低于官方 262K 标准示例,更适合 4×4090。 - KV Cache 使用 FP8:有助于降低 KV 显存压力,提升 64K 上下文下的可行性。
- max-num-seqs 128 要结合业务实测:如果 prompt 普遍较长,建议先从
32或64起步压测,再逐步升到128。 - 建议只跑文本场景:若你的版本支持,可考虑加
--language-model-only,把显存更多留给 KV Cache。 - 调用侧限制 max_tokens:客户端不要默认给过大输出长度,避免单请求占用过多时长和显存。
- 重点观察 nvidia-smi:4 卡方案最关键的是看高峰时是否接近 OOM,而不是只看空载能否启动。
1.3 OpenAI 兼容调用示例
Section titled “1.3 OpenAI 兼容调用示例”非流式调用:
curl https://your-domain/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.5-27B", "messages": [ {"role": "user", "content": "请用三句话总结人工智能的发展趋势"} ], "temperature": 0.6, "top_p": 0.95, "max_tokens": 512 }'流式调用:
curl https://your-domain/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.5-27B", "messages": [ {"role": "user", "content": "请给我一个项目周报模板"} ], "stream": true, "max_tokens": 512 }'1.4 适用场景
Section titled “1.4 适用场景”场景 | 说明 |
内部知识库问答 | 适合中等长度问答、企业内部助手、研发 Copilot 等场景。 |
API 联调与产品验证 | 适合开发阶段快速接入 OpenAI 兼容接口。 |
中等并发对话服务 | 可以支撑常规在线问答,但要控制上下文和并发峰值。 |
成本敏感部署 | 在已有 4 卡机器上尽量跑起来,比直接扩到 8 卡更现实。 |
2. Qwen3.5-27B 8 卡部署方案
Section titled “2. Qwen3.5-27B 8 卡部署方案”适合 更长上下文、更高吞吐、更接近官方标准配置 的环境。
2.1 推荐启动命令
Section titled “2.1 推荐启动命令”vllm serve Qwen/Qwen3.5-27B \ --port 8000 \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --reasoning-parser qwen3如果需要工具调用:
vllm serve Qwen/Qwen3.5-27B \ --port 8000 \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --kv-cache-dtype fp8 \ --gpu-memory-utilization 0.8 \ --reasoning-parser qwen3 \ --enable-auto-tool-choice \ --tool-call-parser qwen3_coder2.2 最佳实践
Section titled “2.2 最佳实践”- 8 卡更适合对齐官方标准示例:尤其是需要 262K 上下文 时,8 卡明显更稳。
- 长上下文优先看 KV 压力:即使 8 卡,也不能忽视 prompt 过长和高并发叠加带来的显存消耗。
- 适合更高吞吐:相比 4 卡,8 卡更容易承接长文档、复杂推理、更多在线会话。
- 可配合推理链与工具调用:若你的应用需要
reasoning、函数调用、Agent 能力,8 卡更适合做生产环境主实例。 - 建议配套监控:8 卡环境成本更高,建议监控 GPU 利用率、显存、tokens/s、P95 延迟。
2.3 OpenAI 兼容调用示例
Section titled “2.3 OpenAI 兼容调用示例”长文档总结:
curl https://your-domain/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.5-27B", "messages": [ {"role": "system", "content": "你是一个专业文档分析助手。"}, {"role": "user", "content": "请根据以下长文档内容,提炼摘要、风险点与执行建议:..."} ], "temperature": 0.4, "top_p": 0.9, "max_tokens": 1024 }'工具调用场景:
curl https://your-domain/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.5-27B", "messages": [ {"role": "user", "content": "帮我查询今天北京天气,并给出出行建议"} ], "tools": [ { "type": "function", "function": { "name": "get_weather", "description": "查询天气", "parameters": { "type": "object", "properties": { "city": {"type": "string"} }, "required": ["city"] } } } ], "max_tokens": 512 }'2.4 适用场景
Section titled “2.4 适用场景”场景 | 说明 |
长文档理解与摘要 | 更适合长上下文输入,如法律、金融、招投标、报告分析。 |
生产级智能助手 | 在线客服、企业助手、研发助手等对稳定性要求较高的服务。 |
Agent / 工具调用 | 更适合结合函数调用、工作流编排、检索增强等复杂任务。 |
高并发 API 服务 | 当请求数多、每条请求也不短时,8 卡更有余量。 |
3. Qwen3.5-27B OpenAI 兼容 API 调用最佳实践
Section titled “3. Qwen3.5-27B OpenAI 兼容 API 调用最佳实践”3.1 参数建议
Section titled “3.1 参数建议”参数 | 建议 | 说明 |
|
| 通用问答与文档总结可从这个区间起步。 |
|
| 常见稳定配置。 |
| 按业务收紧 | 不要一上来就给很大,尤其在 4 卡部署上。 |
| 对话类建议开启 | 可改善首字延迟体验。 |
3.2 服务端参数覆盖提醒
Section titled “3.2 服务端参数覆盖提醒”若日志中出现:
Default vLLM sampling parameters have been overridden by the model's generation_config.json说明服务端模型目录中的 generation_config.json 覆盖了 vLLM 默认采样参数。调用时看到的行为,应以 线上实际输出 为准。
3.3 联调建议
Section titled “3.3 联调建议”- 先测
GET /v1/models,确认模型能被正确发现。 - 再测非流式
POST /v1/chat/completions,确认结构和usage正常。 - 然后测
stream: true,确认 SSE 输出正常。 - 最后用真实业务 prompt 压一轮并发,观察 GPU 显存和延迟。