OpenAI Whisper 语音识别模型:技术与应用全面分析
引言
OpenAI 于 2022 年 12 月开源的 Whisper 模型,凭借 多语言支持(98 种语言)、零样本迁移能力、噪声鲁棒性 等核心优势,迅速成为语音识别领域的“明星工具”。其在英语语音识别任务中接近人类水平(LibriSpeech 测试清洁切分 WER 达 2.5%),同时支持语音翻译、语言识别等多任务,无需针对特定场景微调即可直接应用。
本文将从技术原理出发,结合共绩科技的容器化部署方案,详细解析 Whisper 的部署步骤、使用方法及参数调优技巧,帮助开发者快速上手专业级语音转写服务。
1.技术基础:Whisper 为什么能“听懂全世界”?
1.1 模型架构与训练数据
Whisper 采用经典的 Transformer 编码器 - 解码器架构 ,模型参数从 Tiny(39M)到 Large(1550M)不等,适配不同场景需求。其原始版本基于 68 万小时多语言音频数据训练(含 75 种语言的转录数据和 21 种语言的翻译数据),而 Large-v3 模型进一步扩展至 100 万小时弱标注音频 +400 万小时伪标注音频,显著提升了复杂场景下的泛化能力。
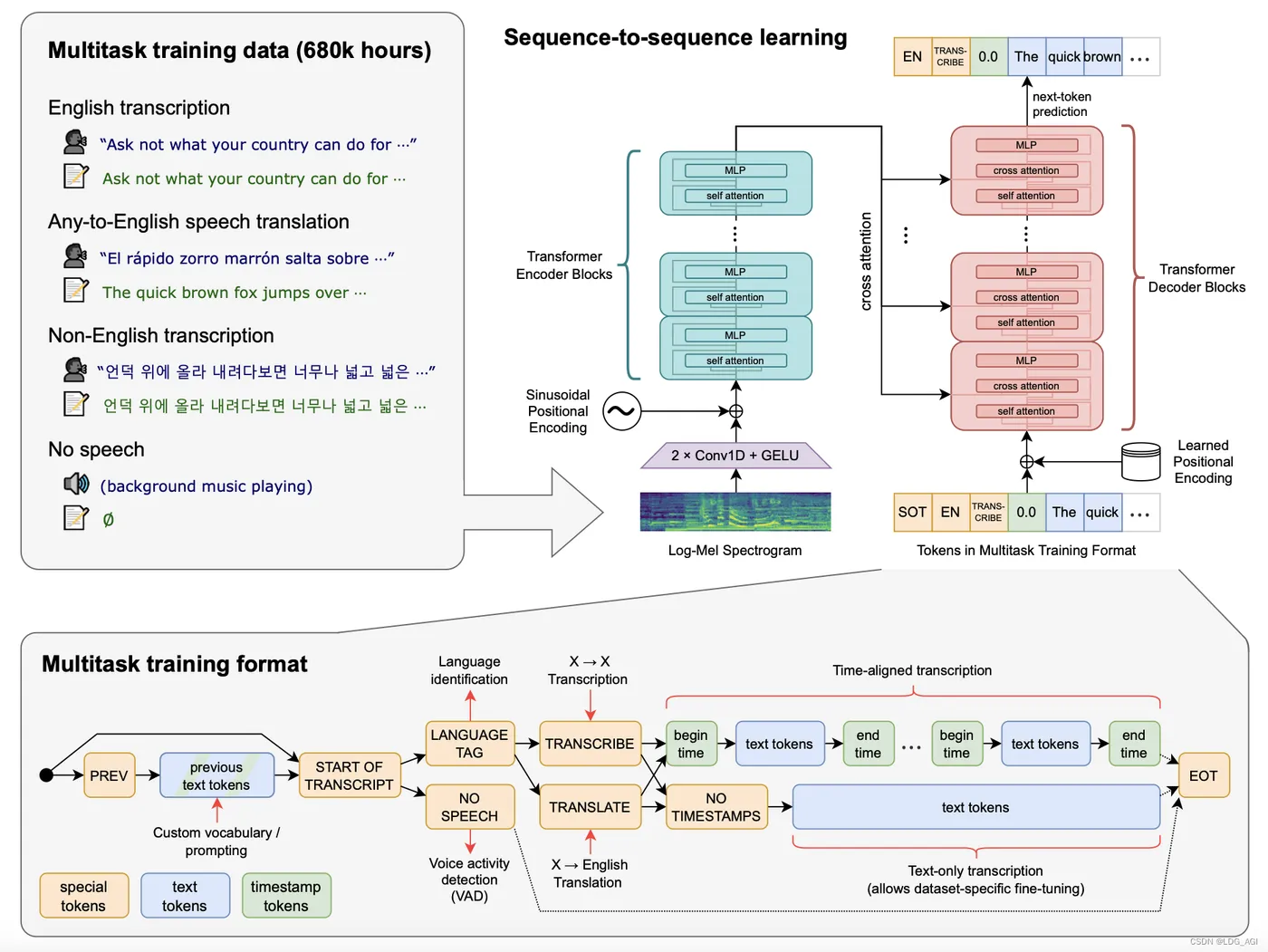
1.2 核心创新:多任务“一站式”处理
通过在输入中加入 任务标记(如转录/翻译)和语言标记 ,Whisper 实现了多任务统一处理:
- 语音识别(支持 98 种语言转录);
- 语音翻译(任意语言转英语);
- 语言识别(检测音频语言类型);
- 语音活动检测(判断是否含人声)。
这种设计简化了传统多任务系统的复杂架构,开发者无需为每个任务单独调用模型。
2.零门槛部署:共绩算力容器化方案
为降低部署门槛,共绩算力平台提供了 预制 Whisper 容器镜像 ,支持快速在云端部署生产级语音识别服务。以下是详细部署步骤(适合首次接触的开发者):
2.1 部署准备
- 访问共绩算力控制台(https://console.suanli.cn);
- 确保账户具备弹性部署服务权限。
2.2 部署步骤
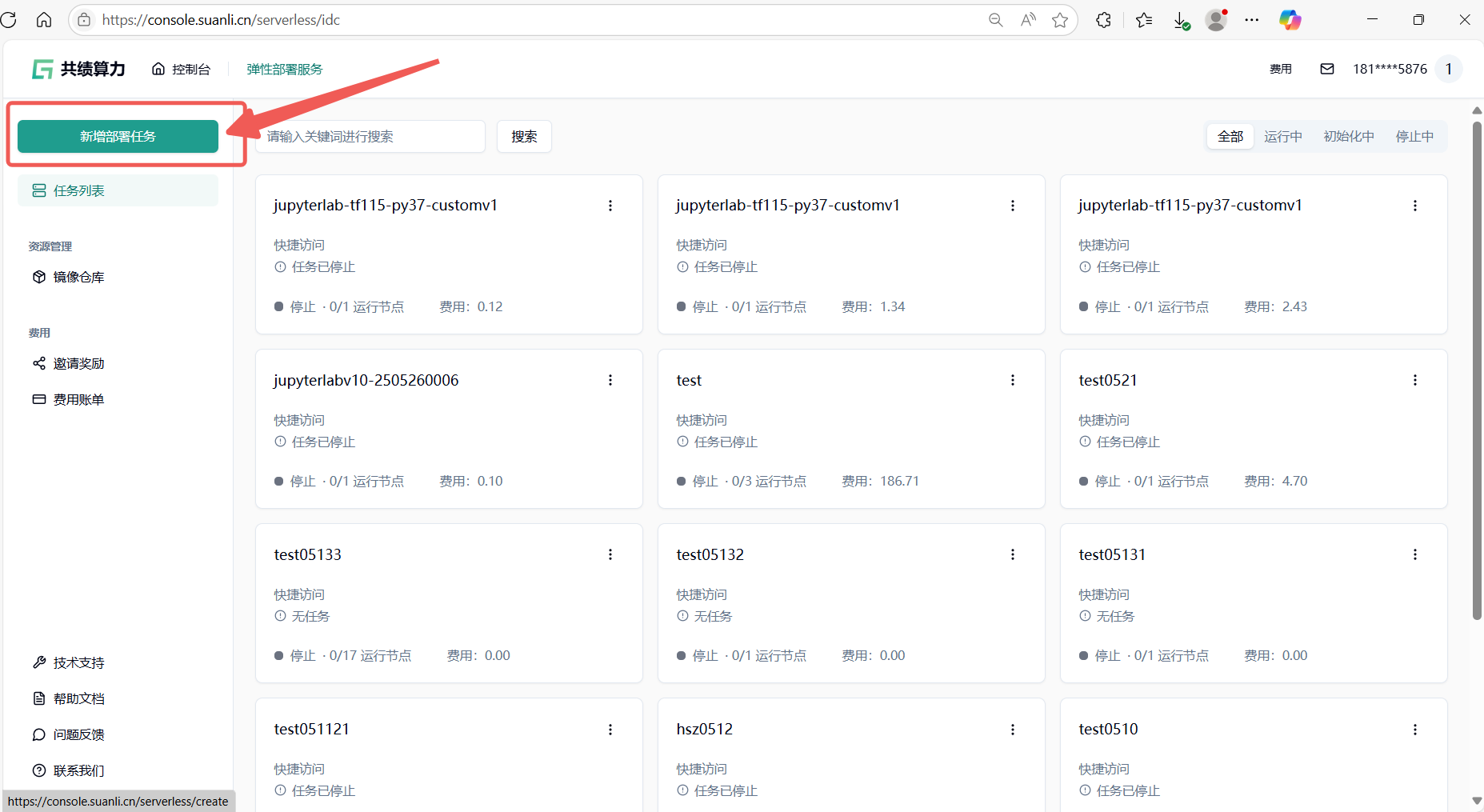
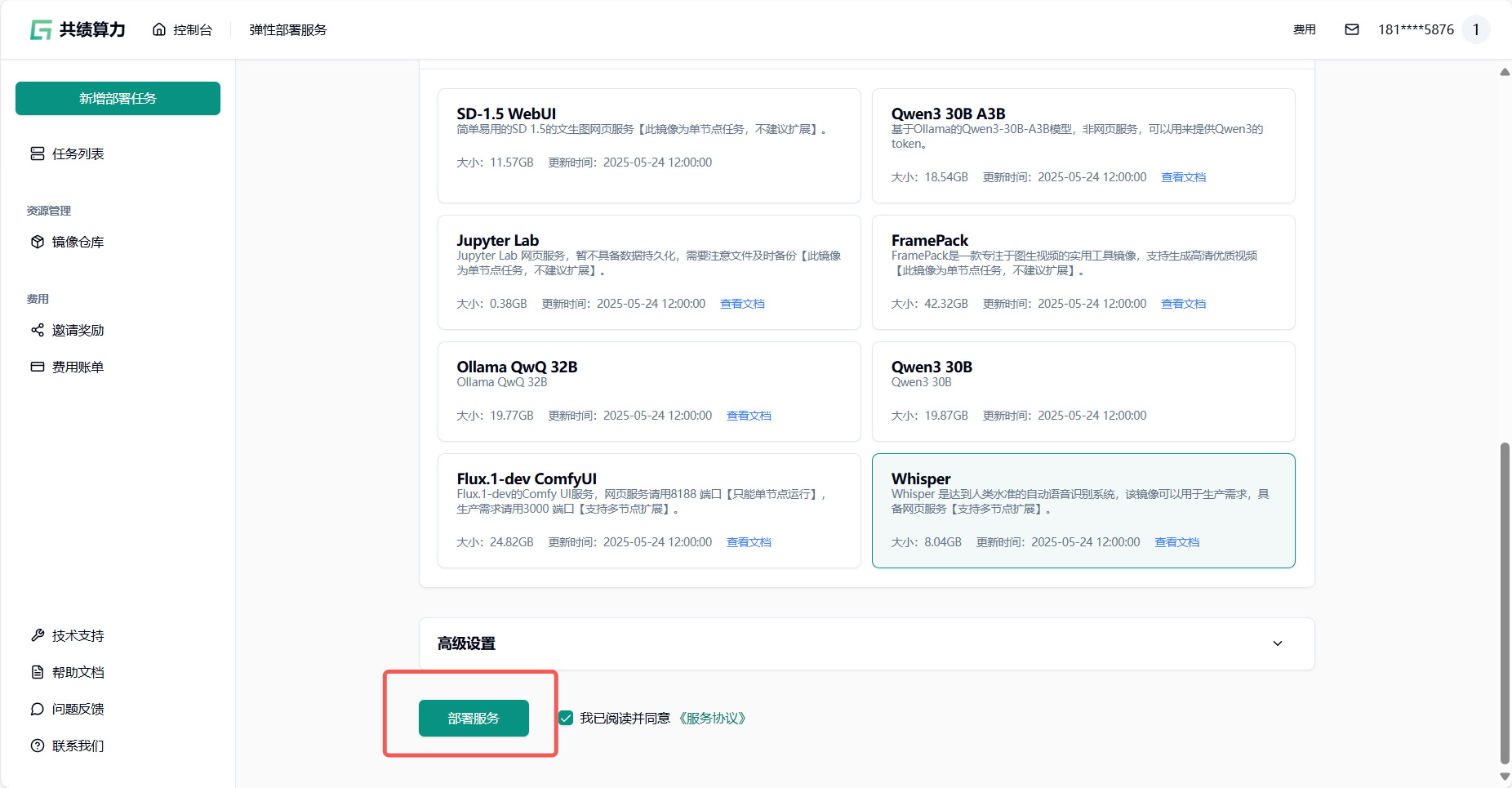
- 选择弹性部署服务 :登录控制台后,点击任意弹性部署服务进入管理页面(图 1);

- 创建新服务 :在服务列表中点击“新增部署服务”按钮(图 2);
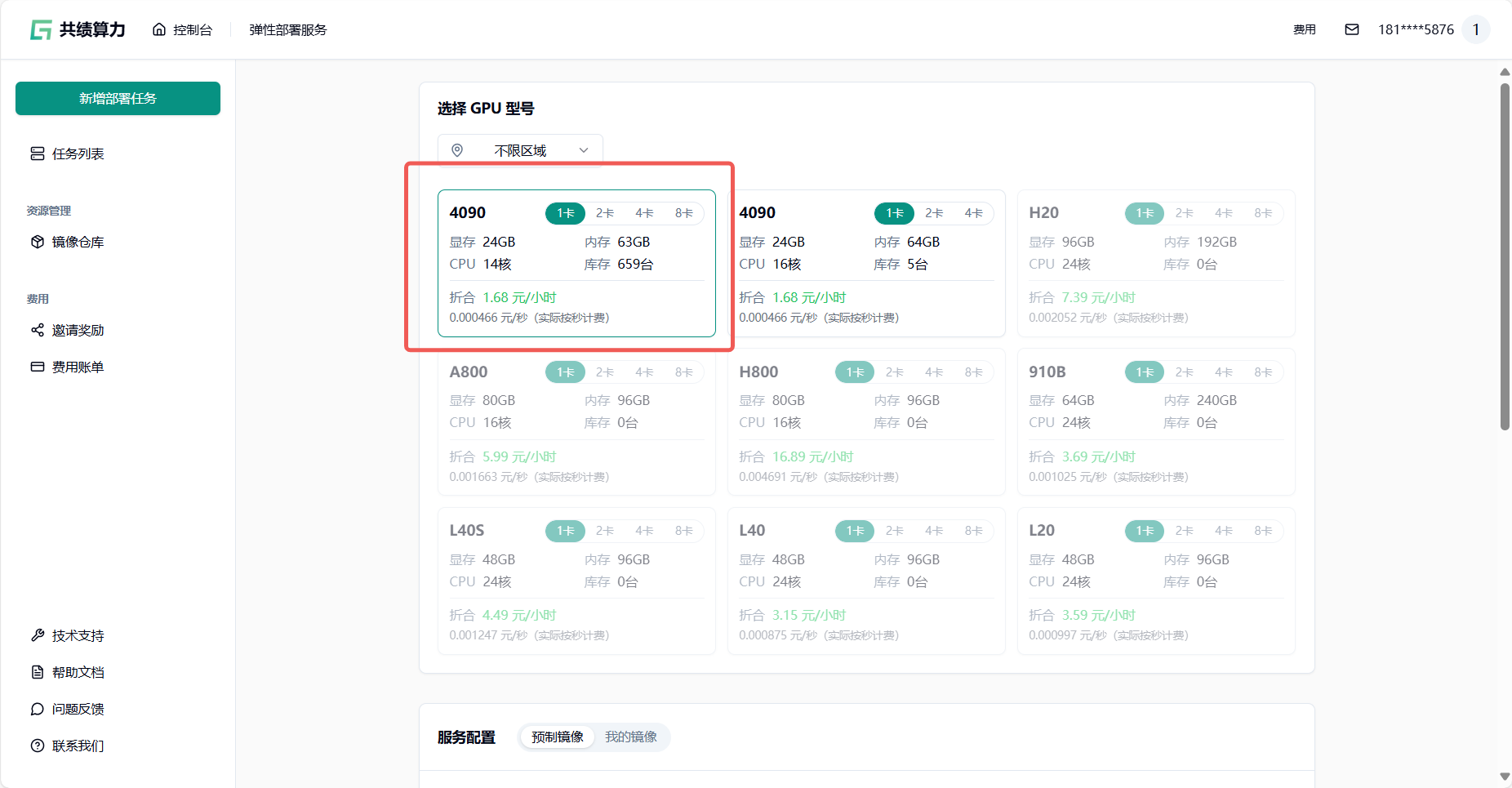
- 配置硬件资源 :参考配置为单卡 4090(适合调试),可根据实际需求调整显卡型号和数量(图 3);
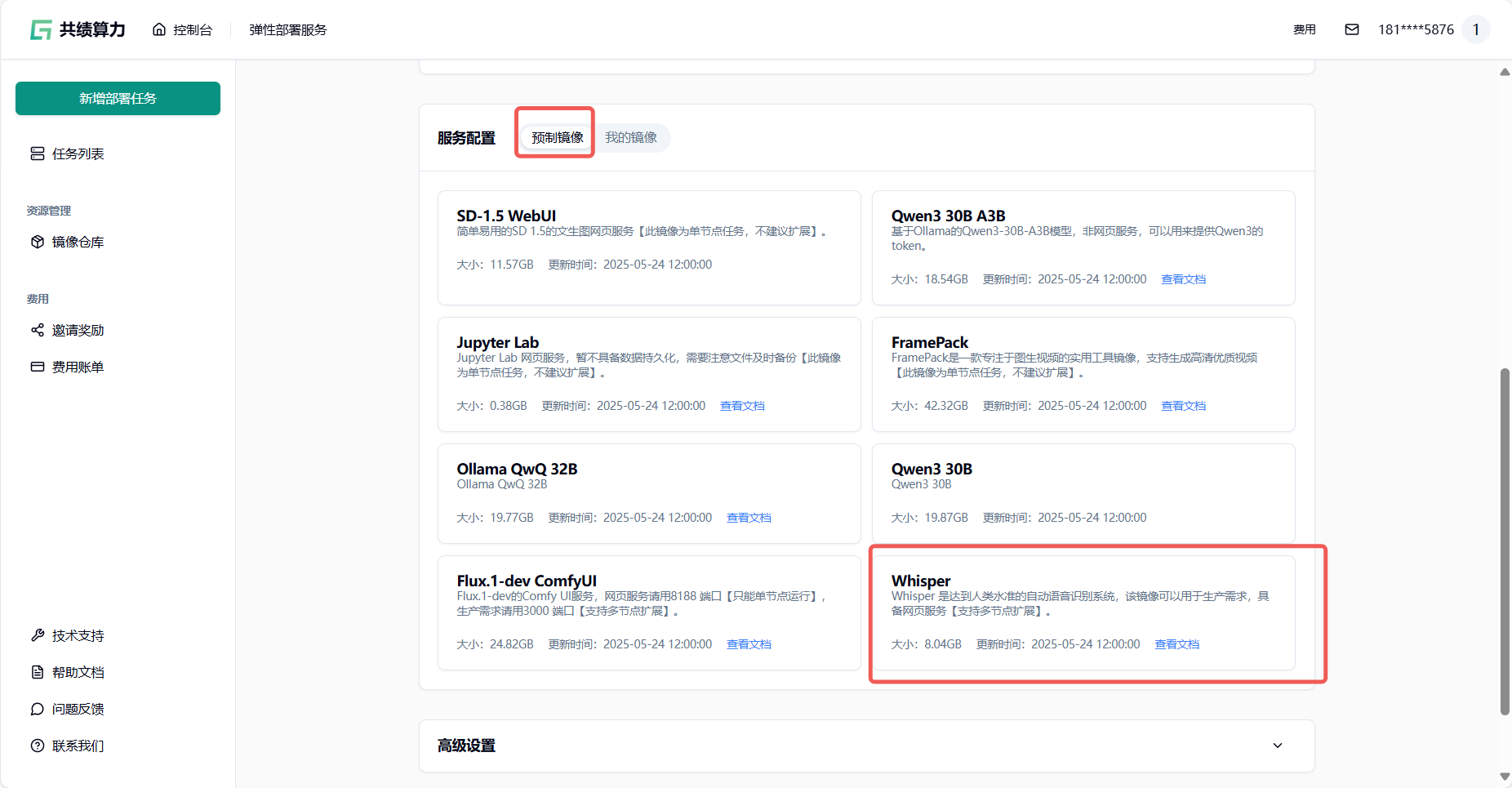
- 选择预制镜像 :在“服务配置 - 预制镜像”中选择共绩科技打包的 Whisper 镜像(地址:harbor.suanleme.cn/huang5876/openai-whisper-asr-webservice:v1.8.2-gpu),一键启动服务(图 4);
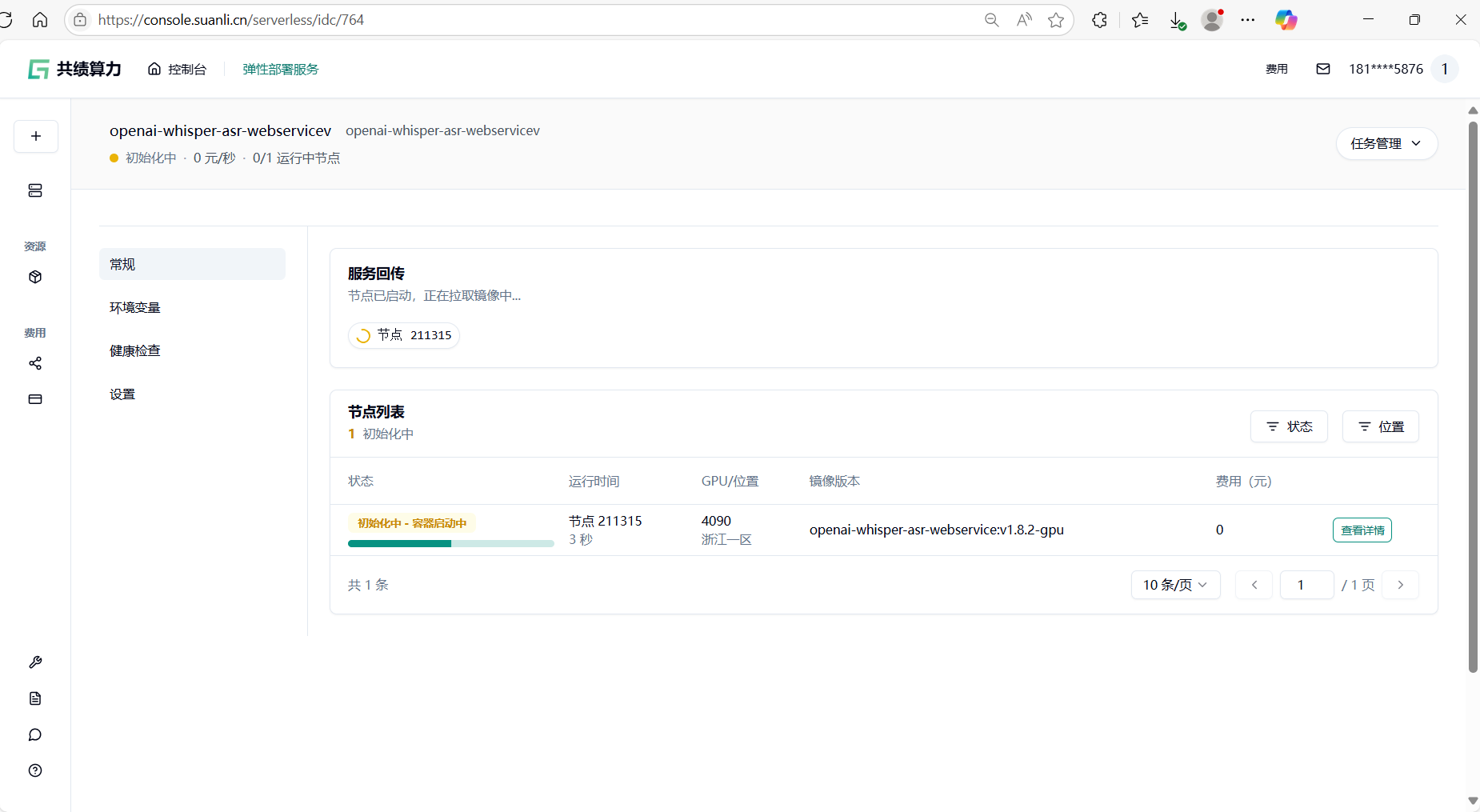
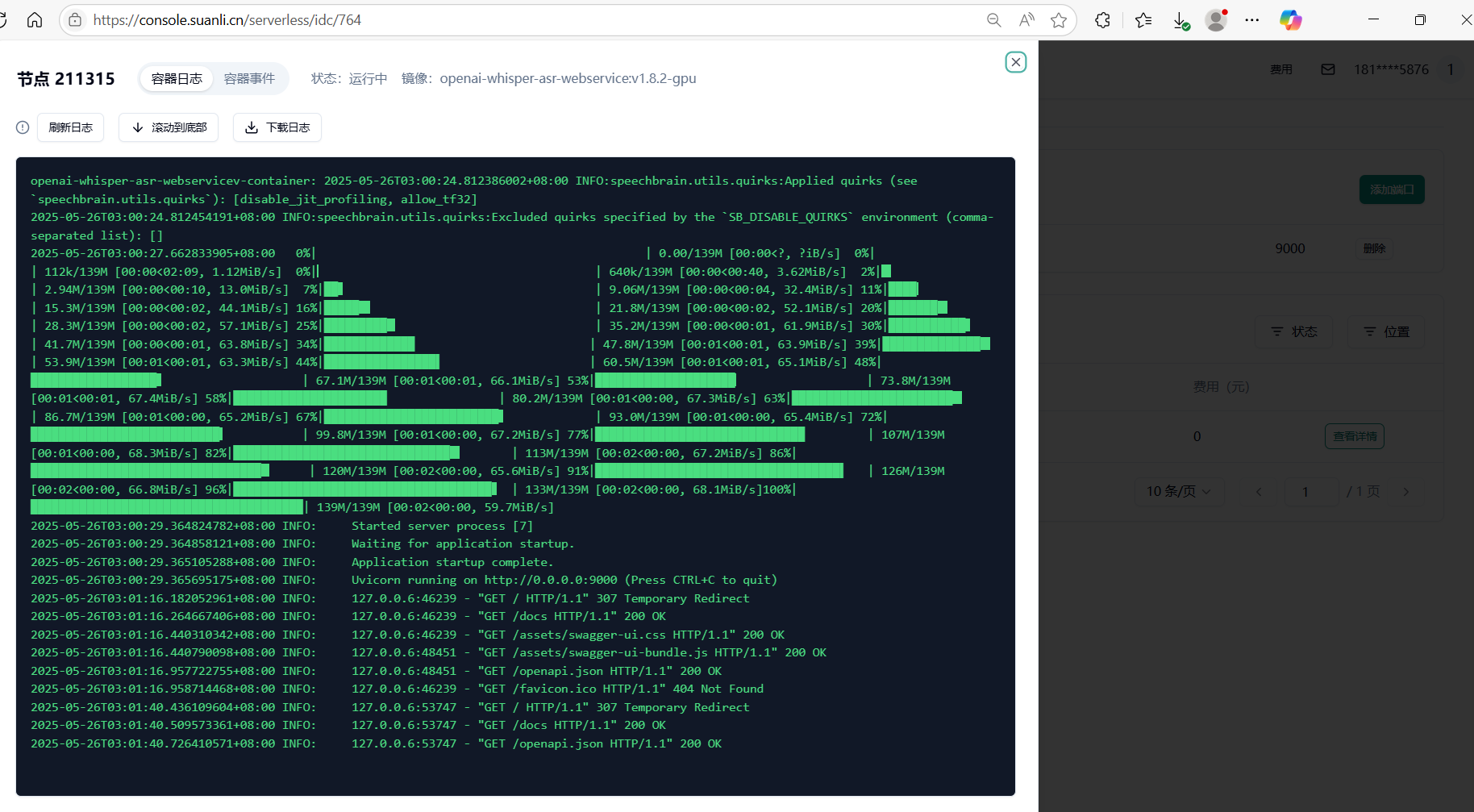
- 启动并等待加载 :点击“部署服务”后,节点将自动拉取镜像并初始化。首次启动需下载模型(约 1-2 分钟),可通过“节点列表 - 查看详情”监控容器状态(图 5)(图 6);
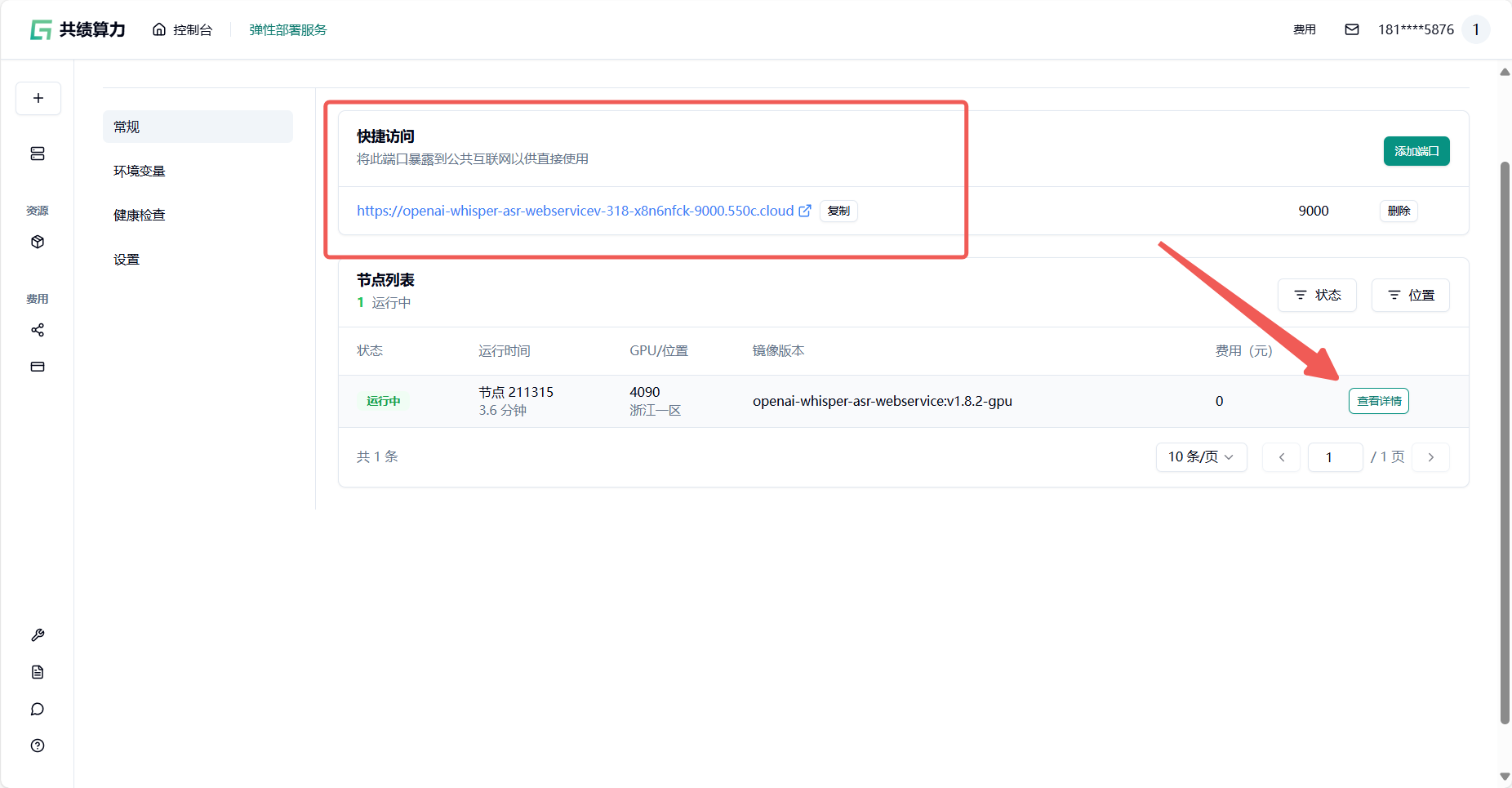
- 验证服务 :节点启动后,在“公开访问”中找到 9000 端口的公网域名链接,点击即可测试服务(图 7)(图 8)(图 9)。
3.全场景使用指南:从 API 到网页服务
部署完成后,Whisper 提供 HTTP 接口 和 网页服务 两种使用方式,覆盖生产环境调用与普通用户操作。
3.1 生产环境:HTTP 接口调用
共绩 Whisper 镜像提供 2 个核心 API:
3.1.1 /asr:语音识别接口
功能 :上传音频/视频文件,输出文本(支持转录/翻译模式)。
参数 :
language(必填):指定音频语言(如en/zh);file(必填):支持 MP3、WAV、MP4 等格式;task(选填):transcribe(转录,源语言→同语言文本)或translate(翻译,任意语言→英语文本)。
响应时间 :
文件大小 | 预估时间 |
<10MB | 3-8 秒 |
10-50MB | 10-25 秒 |
>50MB | 异步处理(返回任务 ID) |
示例请求(CURL):
curl -X POST "http://[公网域名]/asr" -H "Authorization: Bearer YOUR_API_KEY" -F "file=@test.mp3" -F "language=en" -F "task=transcribe"3.1.2 /detect-language:语言检测接口
- 功能 :上传文件,返回音频语言类型(仅检测,不生成文本)。
- 参数 :仅需
file(支持格式同上)。 - 响应时间 :大文件仅检测前 30 秒,<10MB 文件约 2-5 秒完成。
3.2 网页服务:可视化操作 通过 9000 端口的公网域名访问网页服务,支持“所见即所得”操作:
3.2.1 英文音频转文字
- 进入/asr 接口页面,点击右上角“Try it out”(图 10);
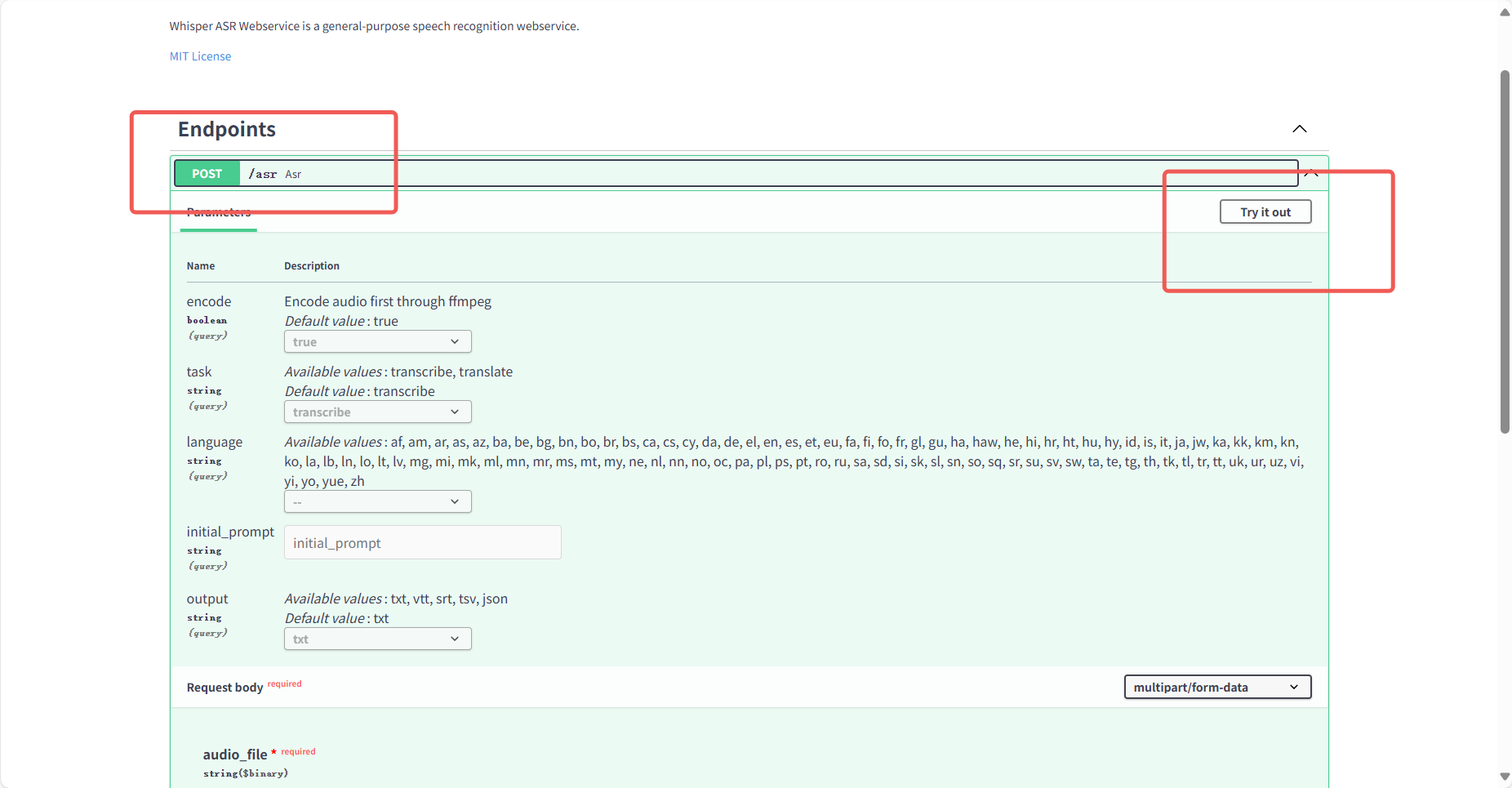
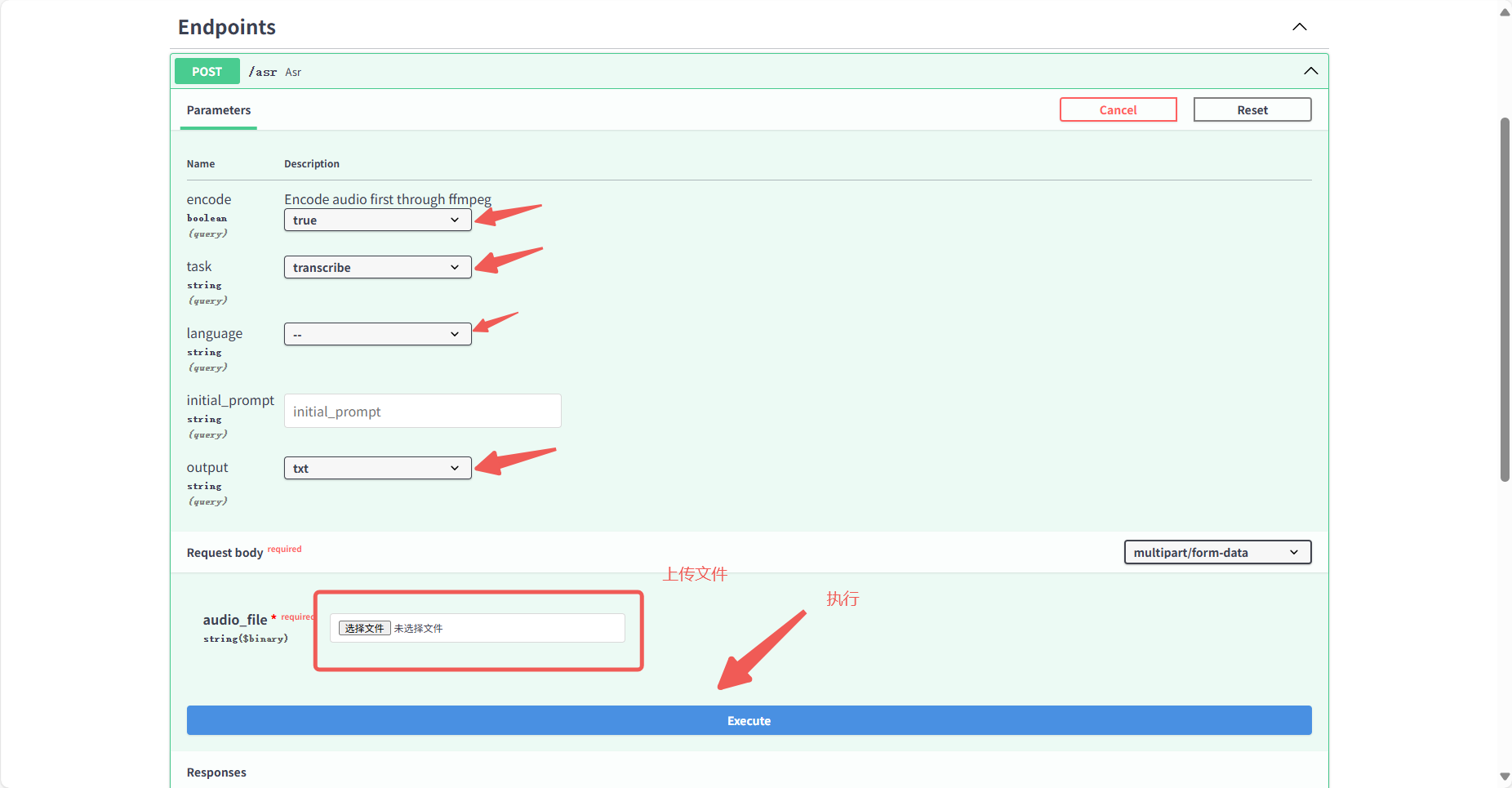
- 上传英文 MP3 文件(测试用例下载:https://www.gongjiyun.com/resource/frozen231202_0242164tMa.mp3),填写参数(默认
transcribe模式)(图 11);
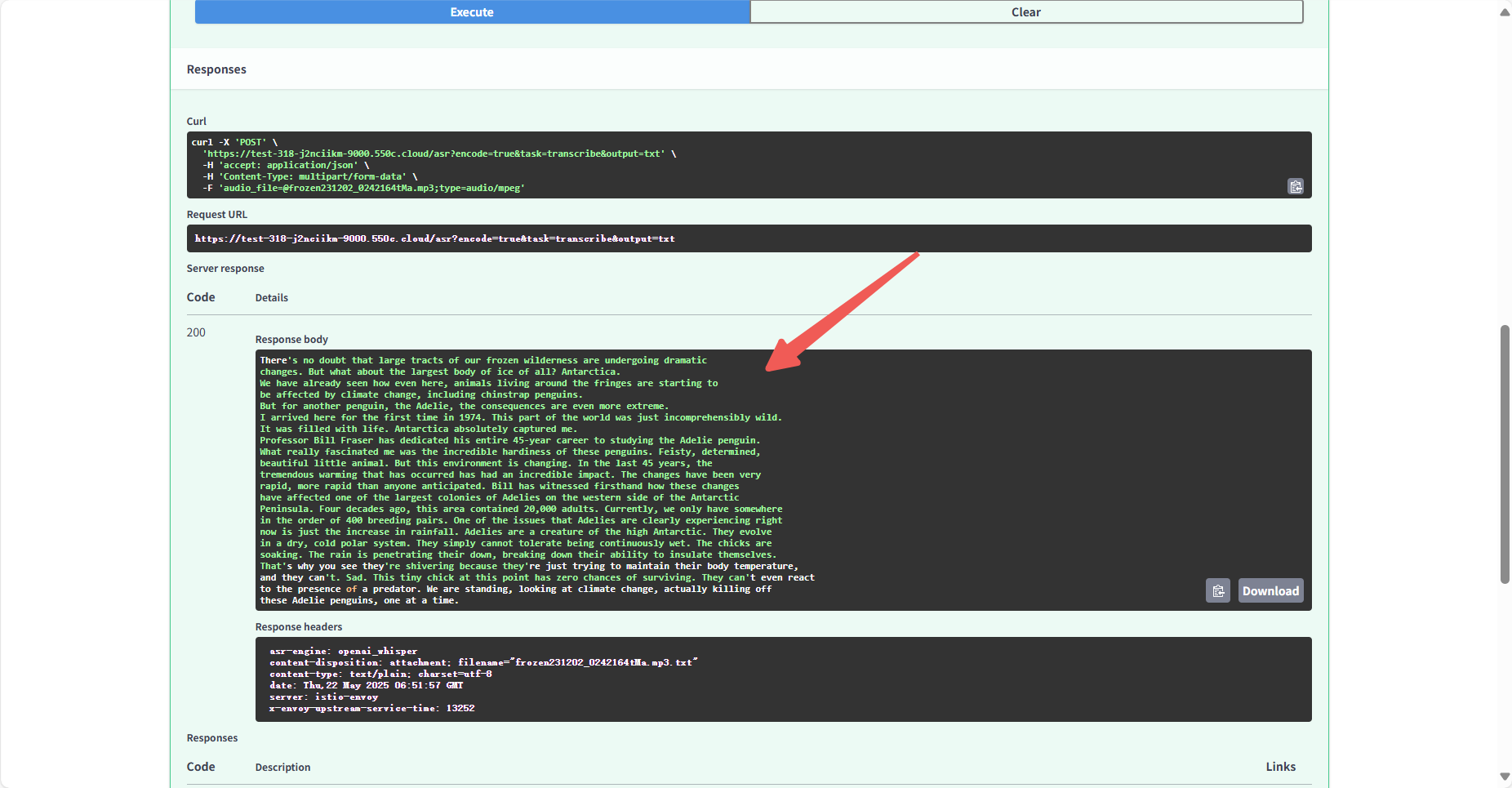
- 提交后,在“response body”查看转录结果(含词级时间戳和置信度)(图 12)。
3.2.2 中文视频转文字
操作与英文类似,但需注意:
- 上传中文视频(如 MP4 格式);
- 在
initial_prompt中填写“简体中文”(默认输出繁体)(图 13);
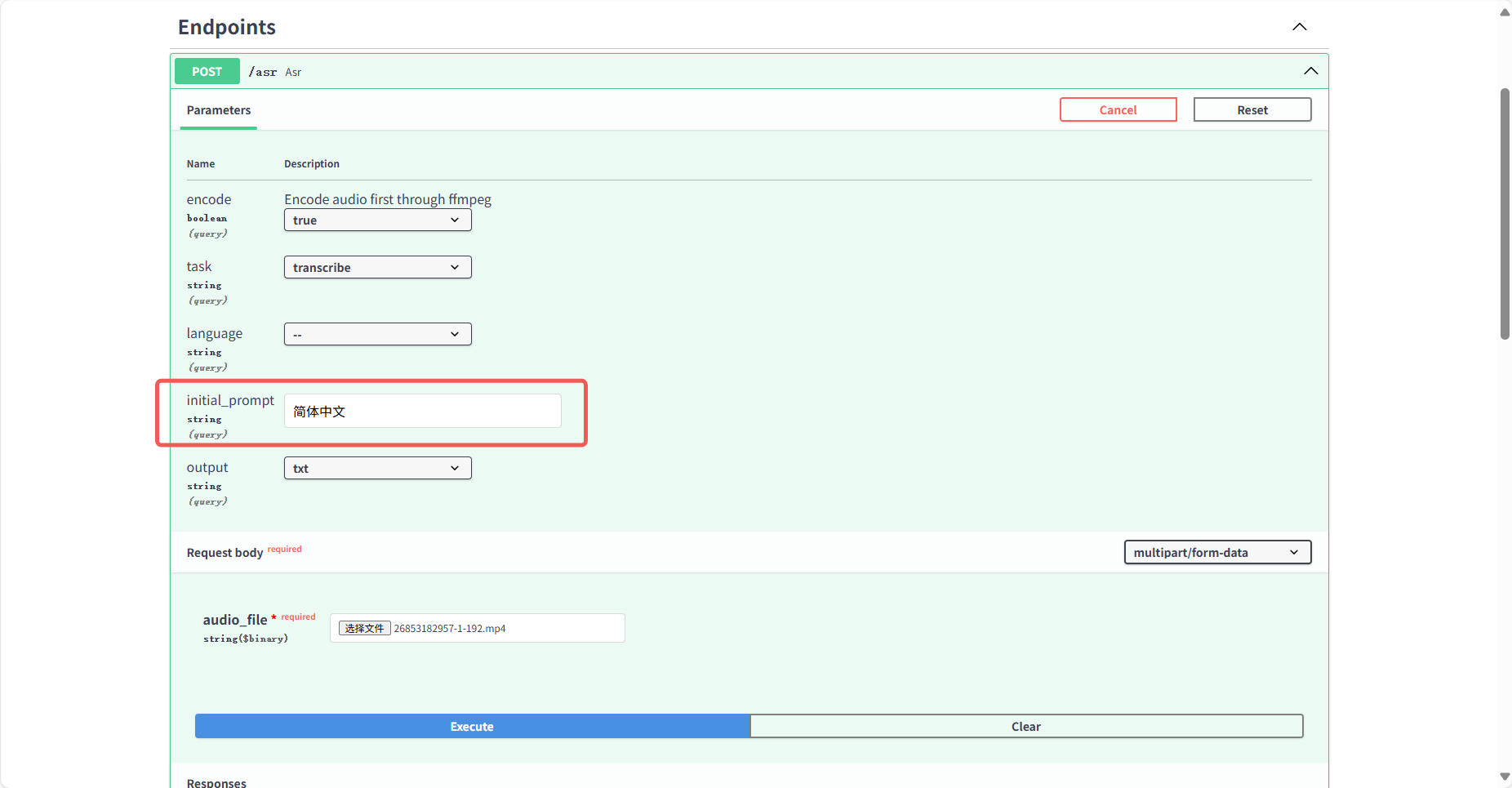
- 输出支持 SRT、VTT 等字幕格式,可直接嵌入视频。
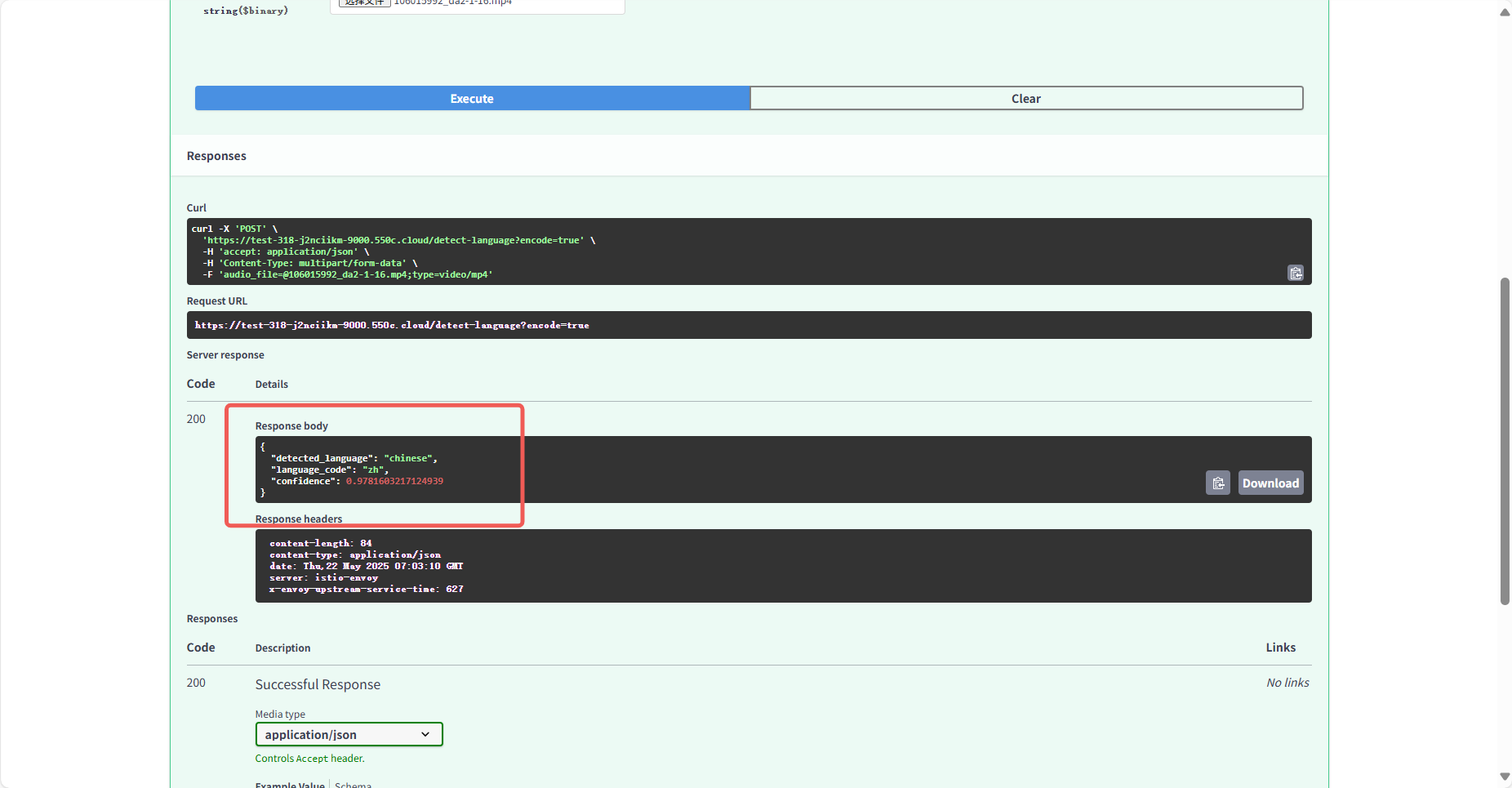
3.2.3 语言检测 选择/detect-language 接口,上传文件后系统自动分析前 30 秒内容,返回语言类型(如 zh/ en/ es 等)(图 14)(图 15)。
4.参数调优:提升识别精度的关键
Whisper 支持多个参数调整,可根据场景优化效果:
4.1 encode(编码预处理)
- 作用 :通过 FFmpeg 自动处理非标准音频格式(如 MP4 中的音轨);
- 建议 :始终设为
true(仅当输入为原始 WAV 文件时可设为false)。
4.2 initial_prompt(上下文提示)
- 作用 :输入领域关键词(如“人工智能、大模型”),提升专业术语识别精度;
- 技巧 :即使处理中文音频,也需用英文填写(如“artificial intelligence, large model”),可提升 12-13% 准确率。
4.3 word_timestamps(时间戳控制)
- 作用 :控制输出是否包含词级时间标注;
- 兼容格式 :JSON(完整时间戳)、SRT(句子级分段)、TXT(无时间戳)。
4.4 output(输出格式)
- 推荐场景 :
- TXT:快速预览;
- SRT/VTT:视频字幕嵌入;
- JSON:开发者分析(含置信度等元数据) 。
5.共绩镜像的核心优势:解决传统转写痛点
对比本地部署和 OpenAI 云端 API,共绩算力的容器化方案在 资源、效率、体验 三方面实现突破:
场景 | 传统方案痛点 | 共绩方案价值 |
核显笔记本使用 | CPU 转写 3 小时音频需 15 小时+ | 智能调度 4090 显卡,压缩至 25 分钟 |
本地 GPU 不足 | 需采购 10G 显存以上显卡(如 4090) | 碎片化显存池化,多卡并行计算,零硬件投入 |
跨平台操作 | Windows/Mac客户端功能割裂,需手动配置环境 | 浏览器即服务,跨平台一致体验 |
6.Whisper 模型语音识别最佳实践场景
Whisper 凭借多语言支持、零样本迁移及共绩容器化方案的赋能,已在多领域形成成熟应用场景,以下为核心实践场景解析:
6.1 内容创作与媒体制作
- 快速文字生成:创作者通过语音输入快速生成文案,告别手动打字,提升创作效率。例如短视频脚本撰写、播客内容整理,可直接通过语音转文字功能输出初稿,再进行润色。
- 视频字幕制作:支持输出 SRT、VTT、TXT、JSON 等格式,其中 SRT/VTT 格式可直接嵌入视频,适用于影视剪辑、课程视频等场景。中文视频转写时,通过
initial_prompt填写“简体中文”可避免默认繁体输出,提升字幕适配性。
6.2 教育与学术研究
- 语言学习辅助:支持 98 种语言转录与翻译,可用于听力训练(如外语音频转文字对照学习)、课程录音整理(将教授讲座转成文字笔记),辅助学生巩固知识。
- 专业领域音频转写:通过
initial_prompt参数输入领域关键词(如“人工智能、大模型”,需用英文填写),可提升学术会议、专业讲座中术语识别精度,准确率可提升 12-13%,满足学术资料整理需求。 - 语言研究助手:语言研究者可上传多语言会议录音,自动输出精准字幕 + 翻译文本,通过调整参数深入分析语音模型性能,辅助语言特征研究。
6.3 多语言交流与协作
- 多语言会议记录:支持混合语言会议转录,可强制指定主语言(如英语)提高识别准确性,自动生成会议纪要,解决跨国团队协作中的语言障碍。
- 实时语言检测:通过
/detect-language接口快速检测音频前 30 秒语言类型(如中文、英语、西班牙语等),为后续转录或翻译提供语言依据,适用于国际论坛、跨语言访谈等场景。
6.4 硬件资源适配场景
- 核显笔记本高效转写:普通笔记本仅用 CPU 转写 3 小时音频需 15 小时以上,共绩方案通过智能调度算力池闲置 4090 显卡,将时间压缩至 25 分钟(部分场景可达 55 分钟),解放核显本用户生产力。
- 本地 GPU 不足场景:无需采购 10G 显存以上显卡(如 4090),通过碎片化显存池化技术,将多台设备显存组合为逻辑显卡,实现分布式推理,零硬件投入即可获得专业级计算能力。
- 跨平台一致体验:针对 Windows/Mac 客户端功能割裂、环境配置复杂问题,共绩方案通过浏览器提供网页服务(上传/转写/导出一键操作),无论 Chromium 或 Safari 内核,均能获得统一高效的使用体验。
通过以上场景可见,Whisper 结合共绩容器化部署方案,已从“技术工具”升级为覆盖创作、教育、协作、硬件适配的“通用生产力平台”,持续推动语音识别技术的普惠化应用。
7.总结与展望
Whisper 凭借多语言支持、零样本迁移等优势,已成为语音处理领域的“通用工具”。通过共绩算力的容器化部署方案,开发者可快速搭建生产级语音识别服务,无需关注底层硬件与环境配置。未来,随着多模态学习(结合视觉信息)、领域适应(金融/医疗定制化)等技术的发展,Whisper 的应用场景将进一步拓展,为内容创作、教育、多语言交流等领域提供更高效的解决方案。
立即访问共绩算力控制台(https://console.suanli.cn),体验“开箱即用”的 Whisper 语音转写服务吧!