谷歌最新推出的 Gemini 2.5 Flash Image(代号 nano-banana)模型,给图像生成和编辑领域带来了一场不小的变革。它不仅极大提升了图片生成质量和创意控制力,更是首次让我们看到了一个真正能理解现实世界的图像 AI,而不仅仅停留在美学层面。
我过去一直觉得,大部分图像生成模型就像是高效的视觉复读机,擅长把文字指令转化成像素,但在面对更深层次的语义理解和逻辑推理时,往往力不从心。然而,Gemini 2.5 Flash Image 的这次更新,特别是它对世界知识的融入,让我意识到图像 AI 正在从美学表达者向智能沟通者进化。它不再只是把画面画出来,而是开始理解画面背后的意义、物品间的关系,甚至能处理手绘草图并给出基于现实的反馈,这种能力上的飞跃,远超我们对传统图像生成器的直觉认知。
核心能力全面突破
模型这次更新主要围绕四个核心点,极大地增强了图像生成和编辑的灵活性与智能性。
角色始终如一
以往在不同场景中保持角色或物体外观的一致性是生成式 AI 的痛点。Gemini 2.5 Flash Image 现在能够轻松做到这一点,无论是把同一个角色放到不同环境中,还是展示一个产品从不同角度的新设置,甚至生成统一的品牌资产,都能保持主题的一致性。

谷歌 AI Studio 里甚至有专门的模板应用(例如这里的 Past Forward 应用)来展示这项能力,开发者可以基于此轻松定制。
自然语言精准编辑
现在,你可以用日常语言对图片进行细致入微的局部编辑和精确转换。比如,模糊背景,去除 T 恤上的污渍,从照片中移除某个人,改变主体的姿势,或者给黑白照片上色,一切只需一个简单的提示词。
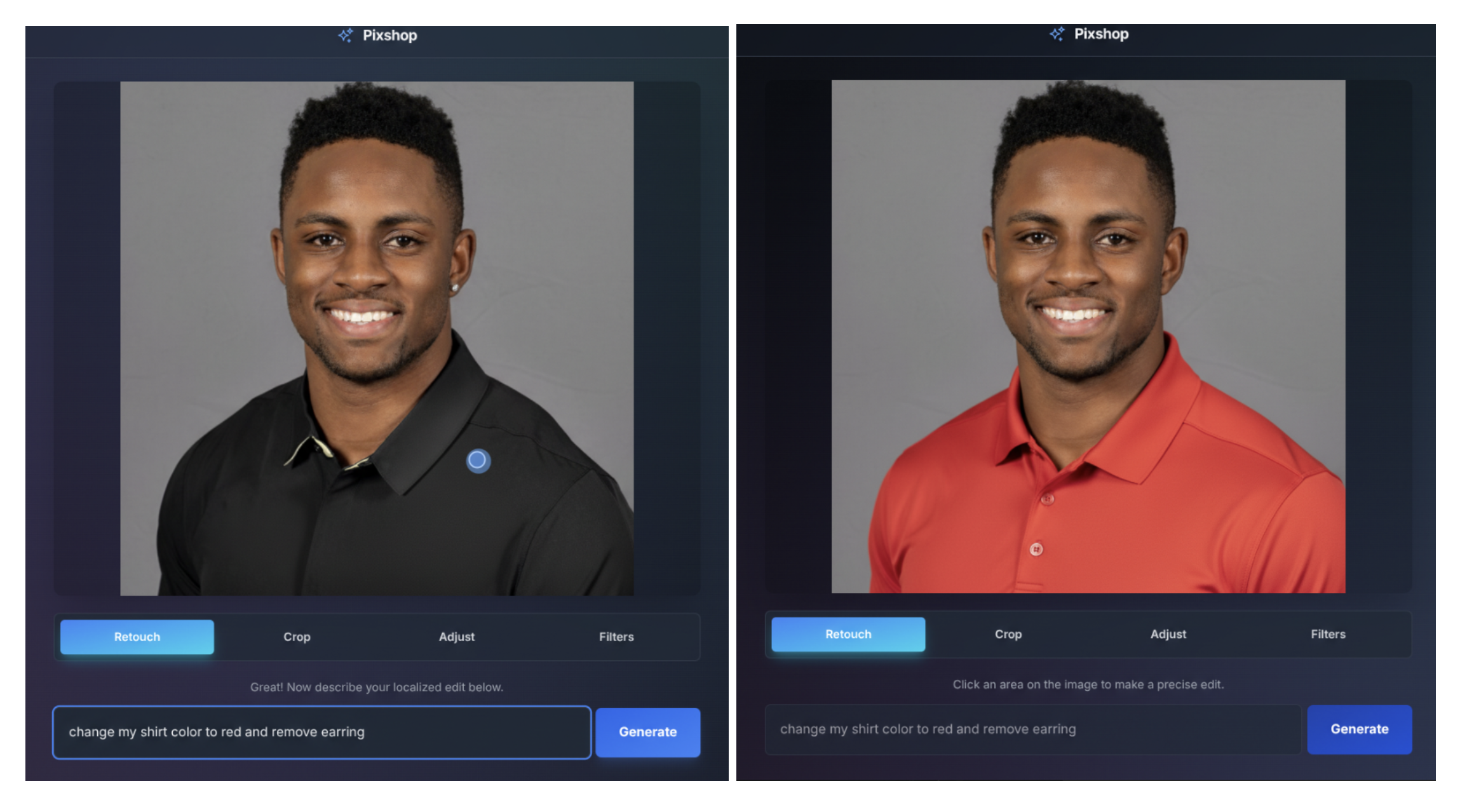
谷歌 AI Studio 中的照片编辑模板应用(例如 Pixshop 应用),结合 UI 和提示词控制,让这些操作变得触手可及。
融入真实世界认知
这是我认为最令人惊喜的一点。过去的图像模型虽能生成精美图片,但对真实世界的深层语义理解是其短板。
Gemini 2.5 Flash Image 得益于 Gemini 本身的世界知识,解锁了全新的应用场景。
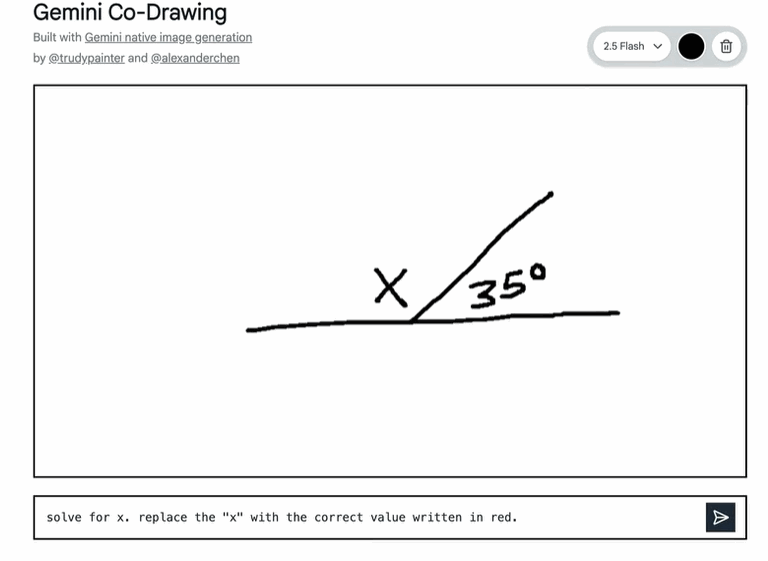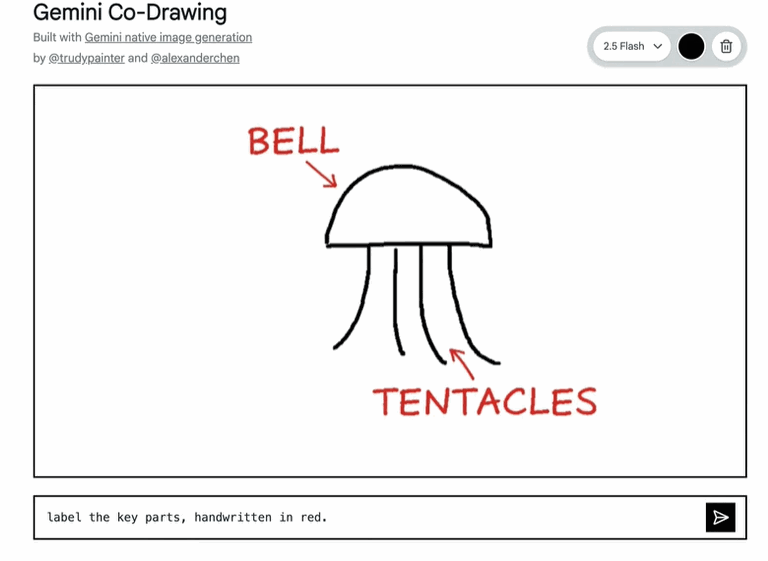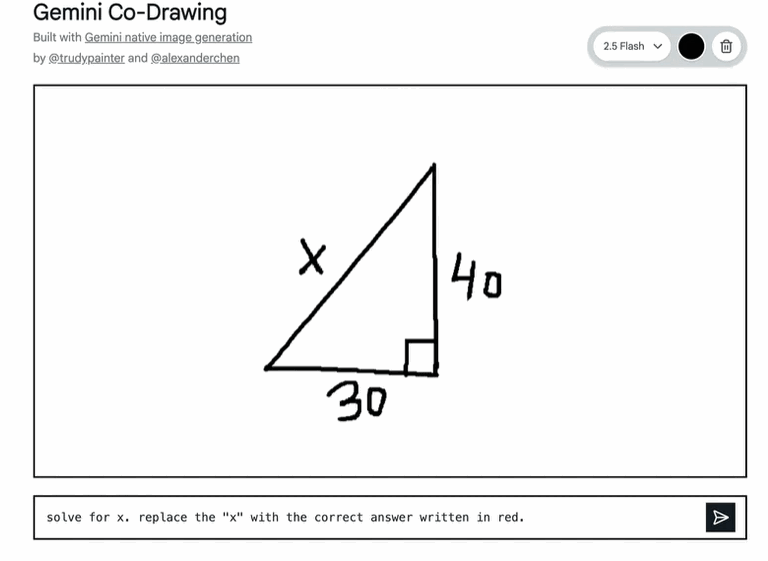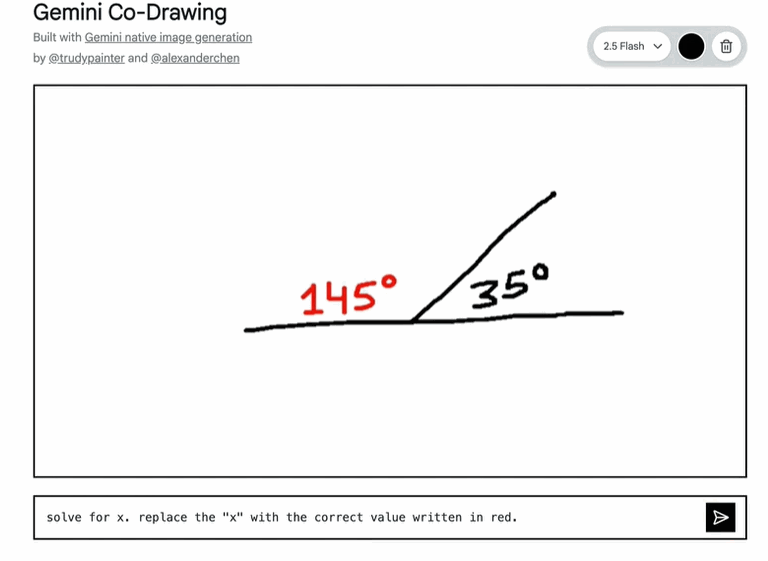
例如,一个在 Google AI Studio 的模板应用(例如 Codrawing 应用),能将简单的画布变成互动教育工具。它能阅读并理解手绘图表,回答现实世界的问题,甚至一步到位地执行复杂的编辑指令。这不只是画画,更像是 AI 在帮你理解和探索世界。
多图智能融合
模型现在能理解并融合多张输入图片。你可以将一个物体放入新场景,用特定的配色方案或纹理重新设计一个房间,只需一个提示词,就能将多张图片无缝融合。

Google AI Studio 的家居画布模板应用(例如 Home Canvas 应用)就是展示这一功能的绝佳例子,你可以拖拽产品到新场景中,快速生成逼真的融合图像。
开发者如何轻松上手
Gemini 2.5 Flash Image 目前已通过 Gemini API 和 Google AI Studio 提供预览版,未来几周内将发布稳定版。所有上面提到的演示应用都是在 Google AI Studio 中所见即所得地构建的,可以直接进行二次创作和定制。具体如何开始,可以查阅 Google AI 的开发者文档。
定价方面,每输出 100 万个 token 收取 30 美元,每张图片(1290 个输出 token)费用约为 0.039 美元。其他输入和输出模式的价格遵循 Gemini 2.5 Flash 的现有定价。
值得一提的是,OpenRouter.ai 已与谷歌合作,将 Gemini 2.5 Flash Image 带给其三百万开发者,这是 OpenRouter 上第一个能生成图像的模型。fal.ai 也加入了合作,进一步扩大了模型的可用性。
安全与未来展望
为了确保内容负责任,所有通过 Gemini 2.5 Flash Image 生成或编辑的图像,都会包含一个隐形的 SynthID 数字水印,用以识别其 AI 生成或编辑的身份。
谷歌团队正在积极改进长文本渲染,提升角色一致性的可靠性,以及图像中细节的事实表现。如果你有任何建议,欢迎通过开发者论坛或 X 平台与他们分享。