阿里云通义千问团队最近又给我们带来惊喜,发布了他们的旗舰级端到端多模态模型 Qwen2.5-Omni。
这不仅仅是个模型,它更像一位全能选手,能看、能听、能说、能写,甚至还能实时互动,真正将 AI 的感知与表达融为一体。它预示着 AI 交互体验将迎来一次质的飞跃。
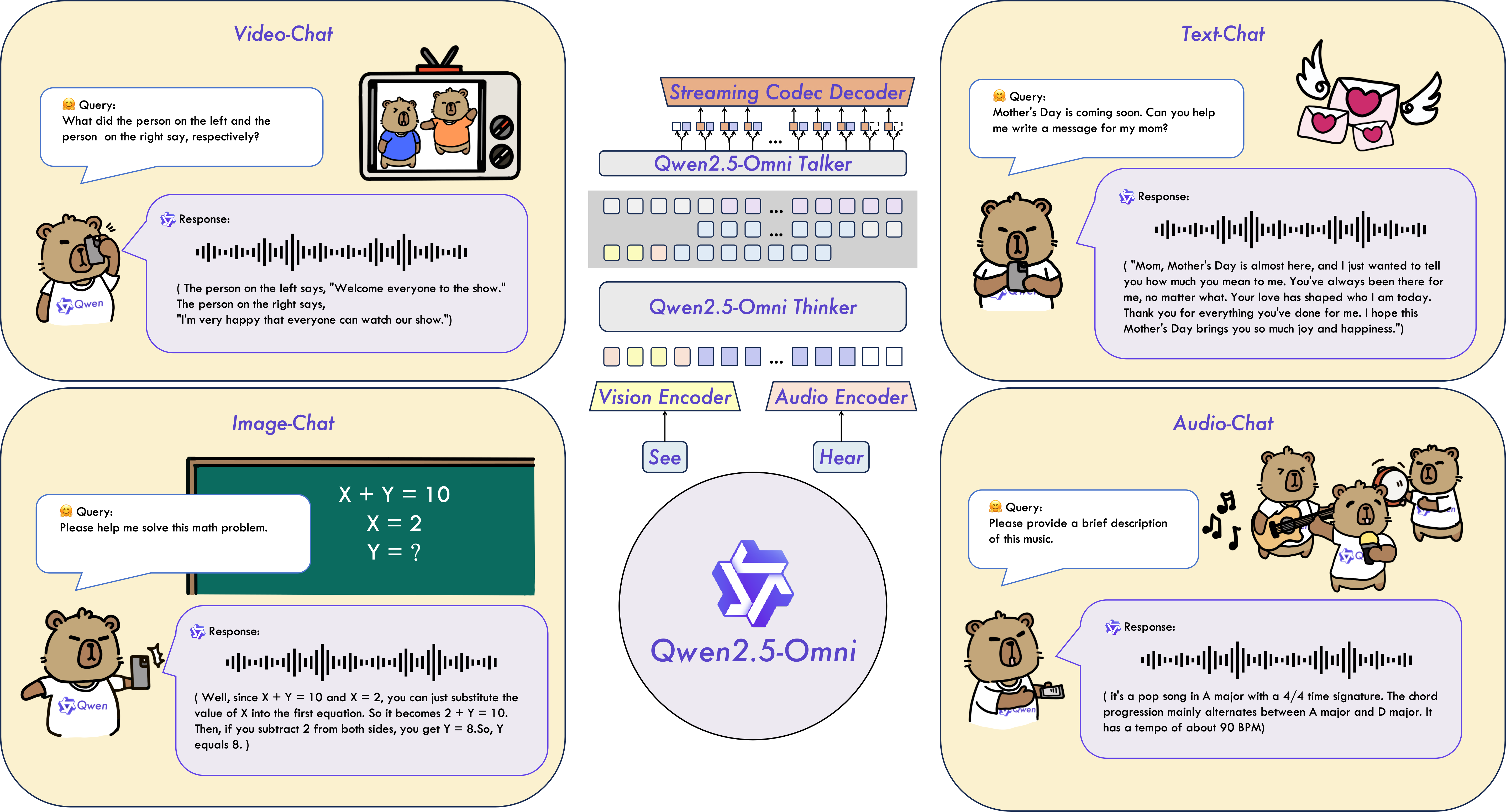
亮点速览
- 多模态统一理解:可处理文本、图像、音频、视频等复杂输入。
- 自然语言与语音输出:文本生成 + 自然语音合成,流式输出。
- 端到端训练与推理:减少中间环节割裂,提升一致性与稳定性。
- 时间同步更优:引入 TMRoPE(时间相关位置编码)用于视频时间轴对齐。
这款由阿里云通义千问团队开发的 Qwen2.5-Omni,最引人注目的能力在于,能够无缝处理文本、图像、音频、视频等多种复杂输入,并且通过文本生成和自然语音合成,实现 实时流式响应。
这意味着,你和 AI 的交流将变得像和真人对话一样自然流畅,AI 不再需要等待全部输入才能做出回应。
独特架构
Thinker–Talker 是 Qwen2.5-Omni 的核心设计思路:
- Thinker(大脑):统一理解多模态输入(文本/图像/音频/视频),产生高级语义表示与文本输出。
- Talker(嘴巴):实时接收 Thinker 的中间输出,连续地将其转化为自然语音,实现边想边说。
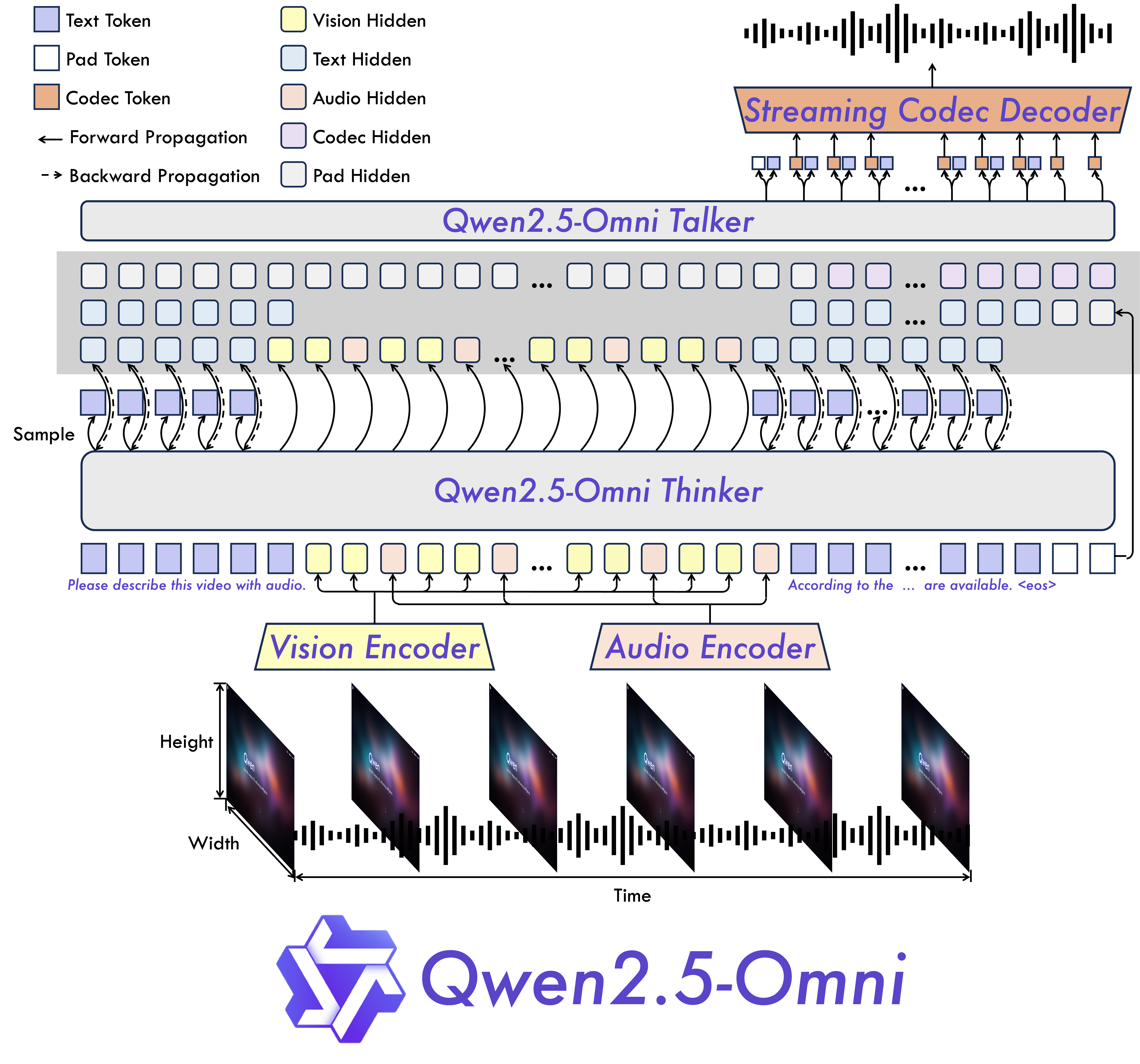
Qwen2.5-Omni 采用了一个名为 Thinker-Talker 的创新架构。
你可以把 Thinker 想象成模型的大脑,它负责理解并处理各种模态的输入,无论是文字、图像还是声音视频,最终生成高级别的语义表示和对应的文本。而 Talker 就像是模型的嘴巴,它能够实时接收 Thinker 的输出,并将其流畅地转化为自然的语音。
这种端到端的协同工作,让整个模型成为一个高度整合的整体,实现了训练和推理的无缝衔接。此外,它还引入了 TMRoPE 这种新型位置编码,用于视频输入的时间同步,确保音视频的准确对齐。
性能强悍
在多模态整合任务(如 OmniBench)上,Qwen2.5-Omni 取得了 SOTA 级表现。面向单模态能力,它在语音识别、翻译、音频理解、图像推理、视频理解等多项任务上同样表现出色。
与同等规模的单模态模型(如 Qwen2.5-VL-7B、Qwen2-Audio)横向比较:
- 音频/语音理解:对比音频专长模型,更强或至少不弱;
- 图像理解:达到相当水平;
- 指令遵循:语音指令与文本指令一致可靠,做到言出即行。
Qwen2.5-Omni 的性能表现让人印象深刻。在多模态整合任务比如 OmniBench 上,它取得了领先的 SOTA 表现。即便在单一模态任务中,它也在语音识别、翻译、音频理解、图像推理和视频理解等多个领域展现出卓越能力。与同等规模的单模态模型如 Qwen2.5-VL-7B 和 Qwen2-Audio 相比,Qwen2.5-Omni 在音频能力上甚至超越了后者,并且图像理解能力也达到了同等水平。它对语音指令的遵循能力也与文本输入相当,真正做到了言出即行。