Google 正式推出 Gemma 家族的最新力作 Gemma 3,这标志着开源 AI 领域又一次重要突破。Gemma 3 不仅继承了前代模型的优秀基因,更在多模态理解、多语言支持以及超长上下文处理方面实现了飞跃,为开发者和研究者提供了前所未有的强大工具。
Gemma 3 核心亮点
Gemma 3 系列模型提供了 10 亿、40 亿、120 亿及 270 亿参数四种规模,以满足不同应用场景的需求。其中,40 亿、120 亿和 270 亿参数的模型首次实现了多模态功能,能够同时处理图像和文本输入,而 10 亿参数版本则专注于纯文本处理。
该系列模型的上下文窗口长度显著提升,10 亿参数版本支持 32k tokens,其余版本更是达到了惊人的 128k tokens。这意味着 Gemma 3 能够理解和生成更长的复杂内容,极大地扩展了其在文档分析、长篇对话等领域的应用潜力。此外,40 亿、120 亿和 270 亿参数的模型还支持超过 140 种语言,展现出卓越的全球化适应能力。
技术革新深度解析
Gemma 3 的核心能力提升得益于一系列精妙的技术创新。
长上下文处理 为了实现 128k tokens 的超长上下文,Google 优化了模型的预训练策略,在不从头训练的情况下,将部分模型从 32k 序列高效扩展至 128k。这包括将旋转位置编码 RoPE 的基频从 Gemma 2 的 10k 提升到 1M,并按 8 倍因子进行缩放。KV 缓存管理也进行了优化,采用了 Gemma 2 的滑动窗口交错注意力机制,将局部层与全局层的交错比例调整为 5 比 1,并将窗口大小缩减至 1024 tokens,在节省内存的同时保持了性能。
多模态融合 Gemma 3 采用 SigLIP 作为图像编码器,将图像转化为语言模型可处理的 tokens。其输入图像固定为 896x896 像素。为应对非方形或高分辨率图像,模型在推理时引入了“pan and scan”算法,通过自适应裁剪图片区域,实现了对图像细节的更精细捕捉。
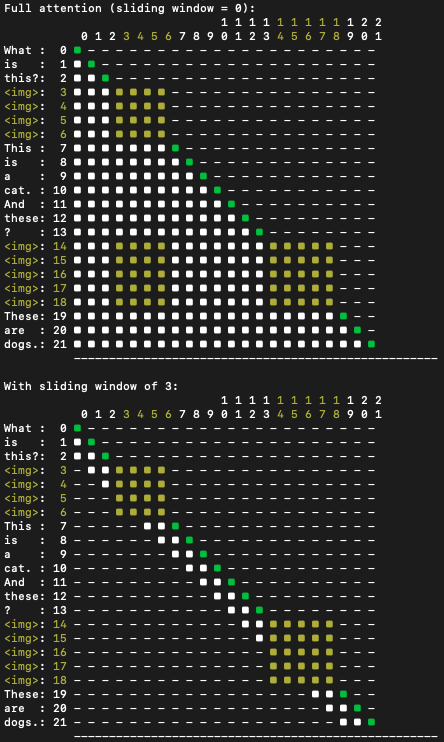
在注意力机制方面,Gemma 3 对文本输入采用单向注意力,而图像输入则采用无掩码的双向注意力,确保对视觉内容的全面理解。
多语言能力增强 为增强多语言覆盖,Gemma 3 的预训练数据集将多语言数据量翻倍。同时,采用了与 Gemini 2.0 相同的 SentencePiece 分词器,包含 26.2 万词条。此分词器显著改进了中文、日文和韩文文本的编码效率,即使英语和代码的 token 计数略有增加,整体收益也十分可观。
性能表现与未来展望
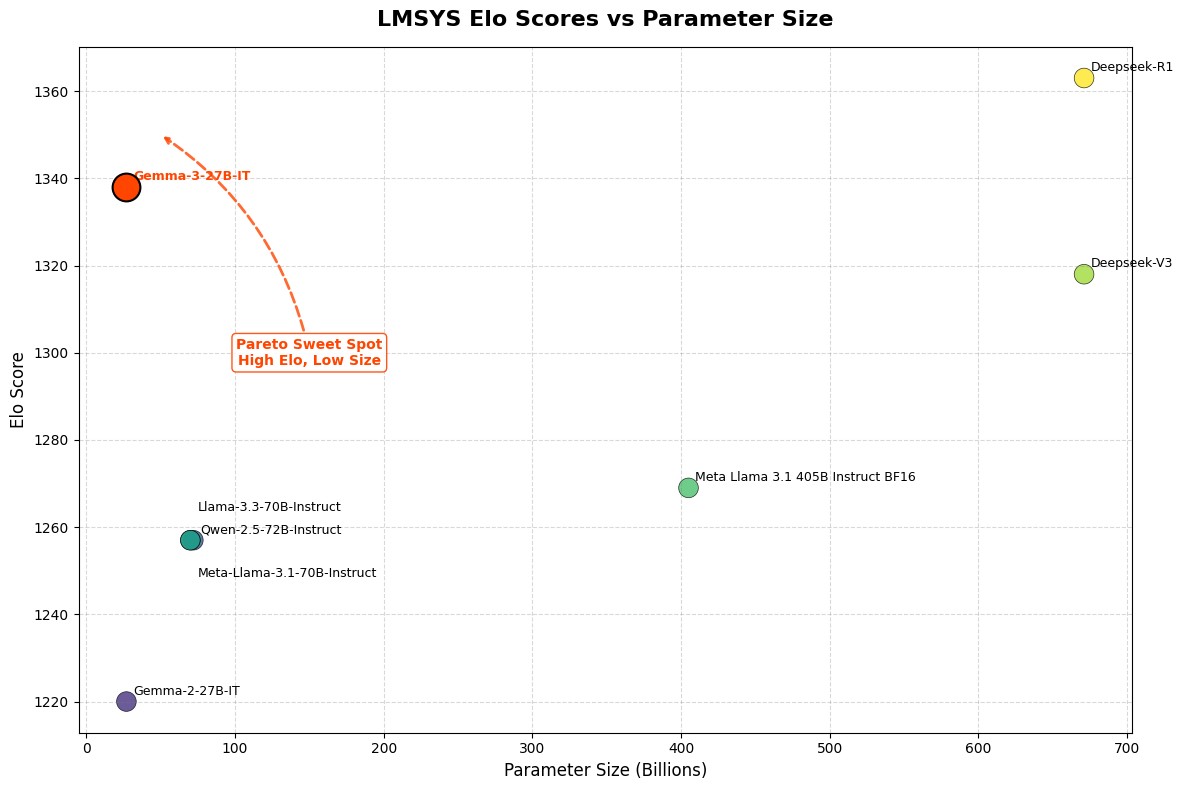
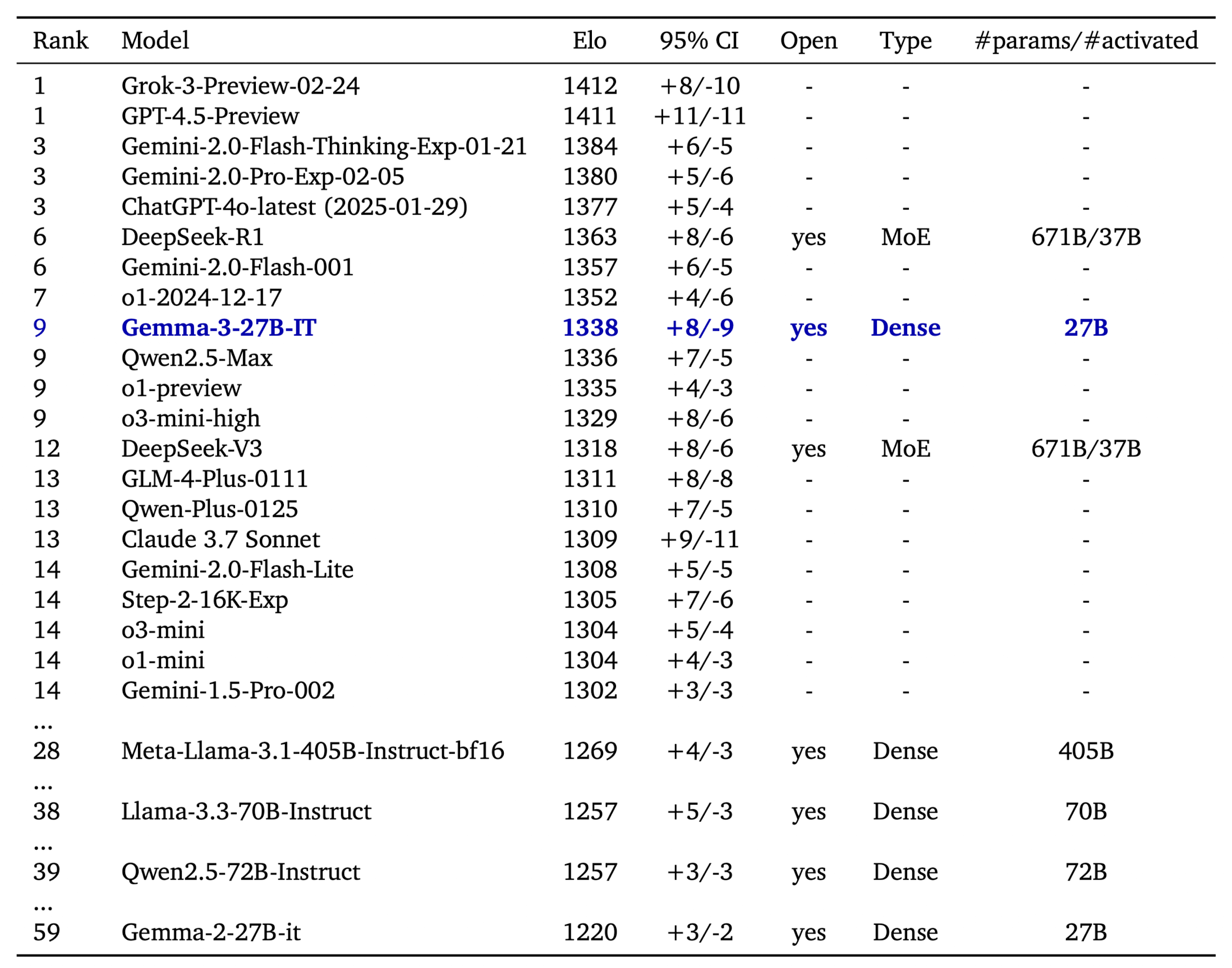
在 LMSys Chatbot Arena 的 Elo 评分中,Gemma 3 27B IT 模型取得了 1339 分的成绩,位列前十,其表现与 o1-preview 相当,并超越了其他非思维链的开源模型。值得一提的是,Gemma-3-4B-IT 的性能超越了前代 Gemma-2-27B IT,而 Gemma-3-27B-IT 在多项基准测试中甚至击败了闭源模型 Gemini 1.5-Pro。这充分展示了 Gemma 3 在推理、数学和多模态能力上的强大实力,同时作为开源模型,其开放性使得先进 AI 技术更加触手可及。
Hugging Face 平台已对 Gemma 3 提供全面支持,用户可以在 Hugging Face Hub 上找到所有模型变体,并利用 transformers 库进行快速推理。此外,模型还支持 MLX 用于 Apple Silicon 设备以及 llama.cpp 的 GGUF 文件,方便在低资源设备上部署。Hugging Face Endpoints 也提供了一键部署选项,加速了 Gemma 3 的应用落地。
这份发布不仅是 Google 在开源 AI 领域的又一重磅贡献,更是推动通用人工智能技术普惠化的重要一步。Gemma 3 的出现,无疑将激发更多创新应用,加速 AI 技术在各行各业的融合与发展。