inclusionAI 团队近日发布的 Ming Lite 万能模型,是一款仅需 2.8 亿激活参数的轻量级多模态模型,却实现了前所未有的全模态感知与生成能力,首次在开放领域向 GPT-4o 的多模态支持范围发起挑战,无疑是 AI 社区的一枚重磅炸弹。
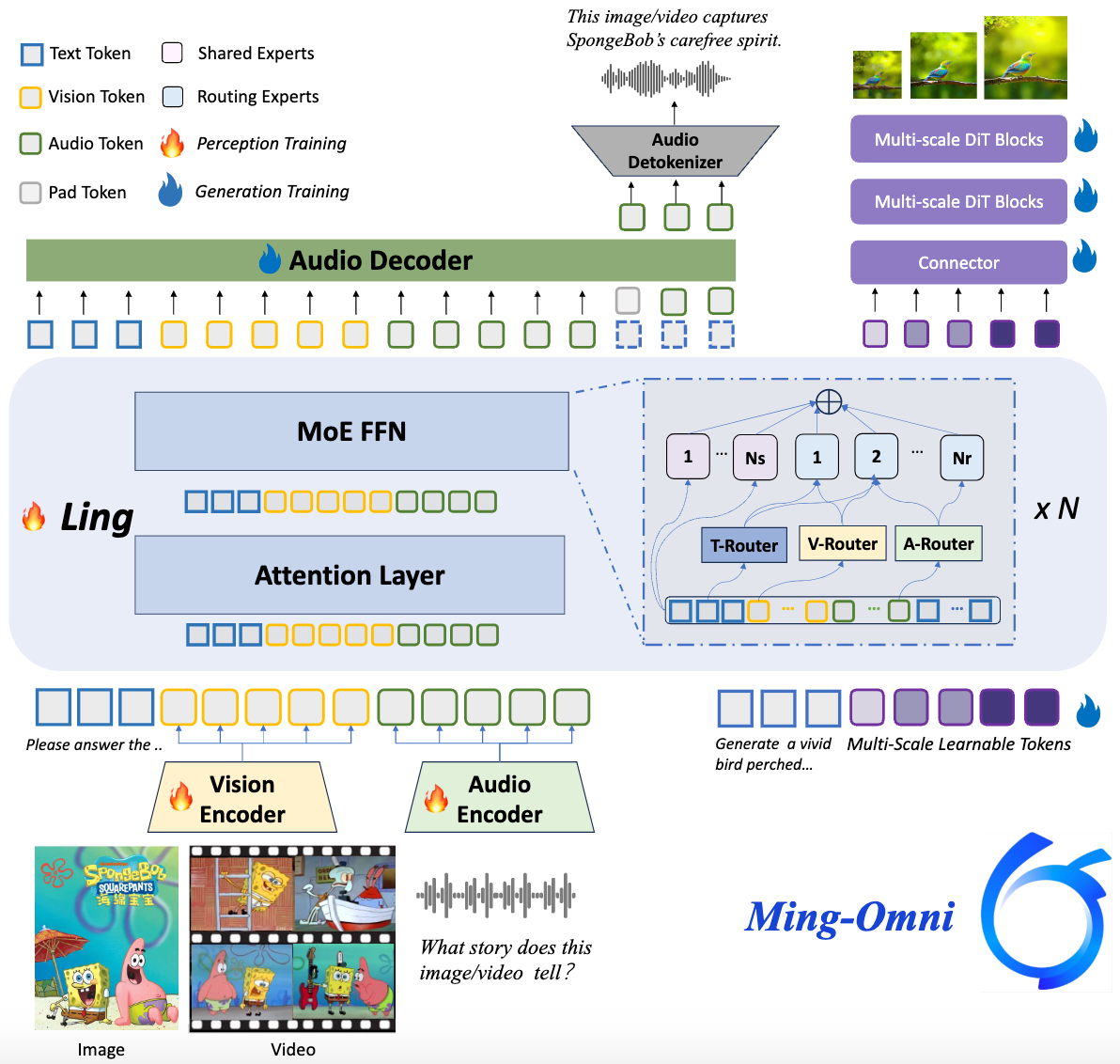
轻量级身段的万能选手
我们常常认为,要实现图像、文本、音频、视频的全能感知,并进一步触及多模态生成,模型参数量必然是海量的。然而,Ming Lite 万能模型通过其巧妙的混合专家(MoE)架构,并为不同模态设计了专门的路由机制,在仅有 2.8 亿激活参数的情况下,展现了令人惊叹的效率与广度。
这种设计不仅解决了多模态任务间的潜在冲突,更让一个模型能够高效地处理并融合各种输入,避免了为不同任务分别微调或重新设计结构的繁琐,这是一种对大模型路径的反直觉探索。它不仅能理解,还能像一个多才多艺的艺术家,生成图像和自然语音,将多模态交互带入一个新境界。
感知与生成的双重突破
Ming Lite 万能模型并非仅仅停留在理解层面,它将生成能力提升到与感知同等重要的地位。通过集成先进的音频解码器和 Ming Lite 统一模型(Ming-Lite-Uni),它能够进行自然流畅的语音生成和高质量图像生成。这意味着除了常规的多模态问答、视频理解、多轮对话外,它还能胜任文本转语音、上下文感知的聊天,甚至进行多样化的图像编辑。这种从输入理解到输出创造的无缝切换,在用户体验和应用潜力上都带来了巨大飞跃。
硬核数据亮眼性能
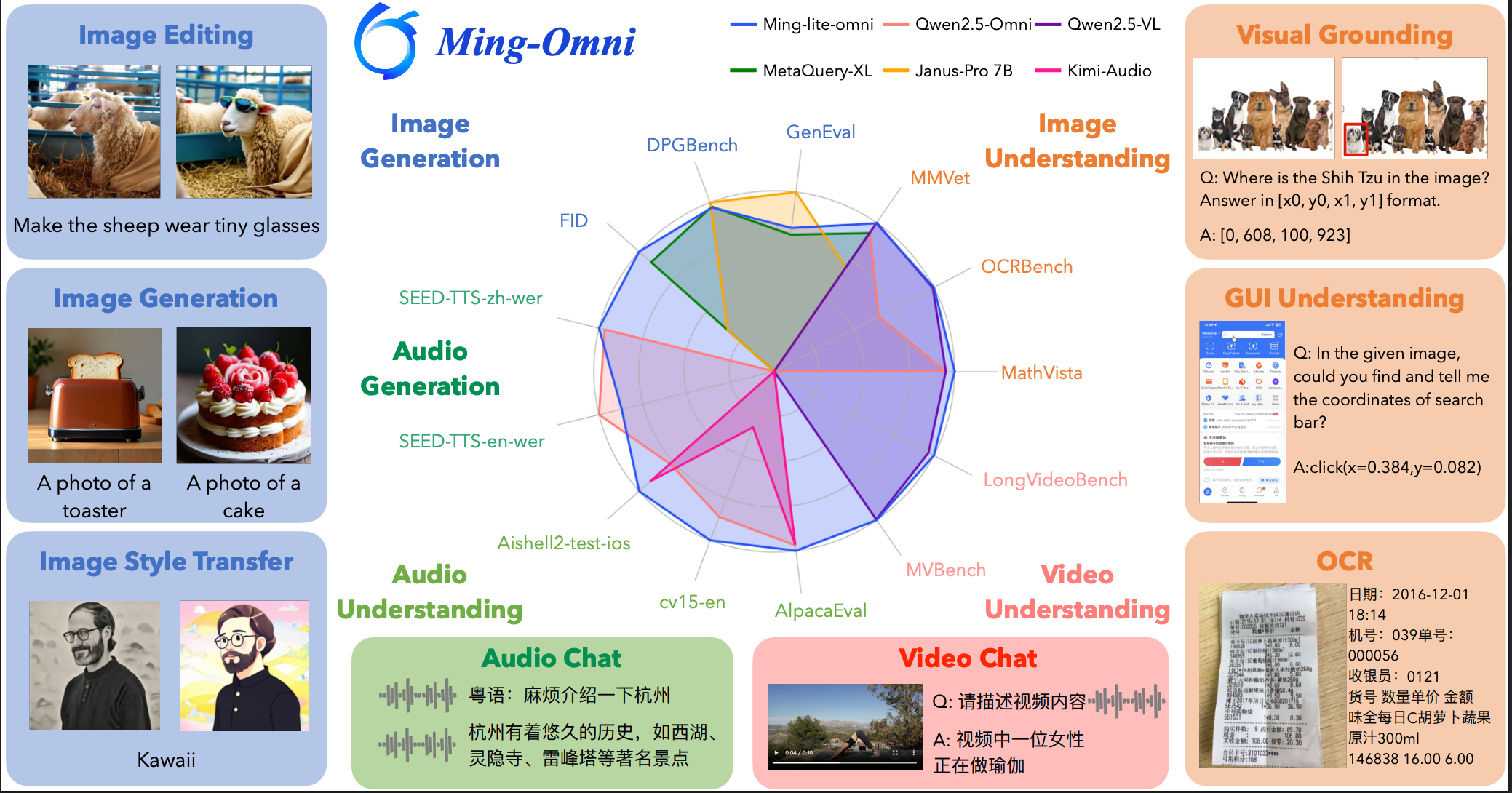
Ming Lite 万能模型在多项基准测试中展现出强劲实力。在图像感知任务上,它以 2.8 亿激活参数,实现了与 Qwen2.5-VL-7B 相媲美的性能。语音问答方面,其表现超越了 Qwen2.5-Omni 和 Kimi-Audio,特别是在端到端语音理解和指令遵循上优势明显。在图像生成领域,Ming Lite 万能模型支持原生分辨率的图像生成、编辑及风格迁移,GenEval 评分高达 0.64,超越了主流模型 SDXL,FID 指标更是达到了 4.85,刷新了现有方法的最新记录。在信息检索基准中,它在未见问题和未见实体上的优异表现,也彰显了其强大的泛化能力。这些数据共同描绘出一个事实:轻量化并不意味着妥协,通过精巧的架构,同样能实现顶尖的多模态能力。
即刻上手体验
Ming Lite 万能模型的代码和模型权重已在 Hugging Face 和 ModelScope 全面开源,鼓励社区进一步探索和开发。无论你是想尝试图文问答、视频内容分析、多轮智能对话,还是亲手体验文生图、图像编辑、语音合成及识别,都可以在其官方页面找到详细的示例代码和使用指南。
项目主页 https://lucaria-academy.github.io/Ming-Omni/
Hugging Face https://huggingface.co/inclusionAI/Ming-Lite-Omni
ModelScope https://www.modelscope.cn/models/inclusionAI/Ming-Lite-Omni