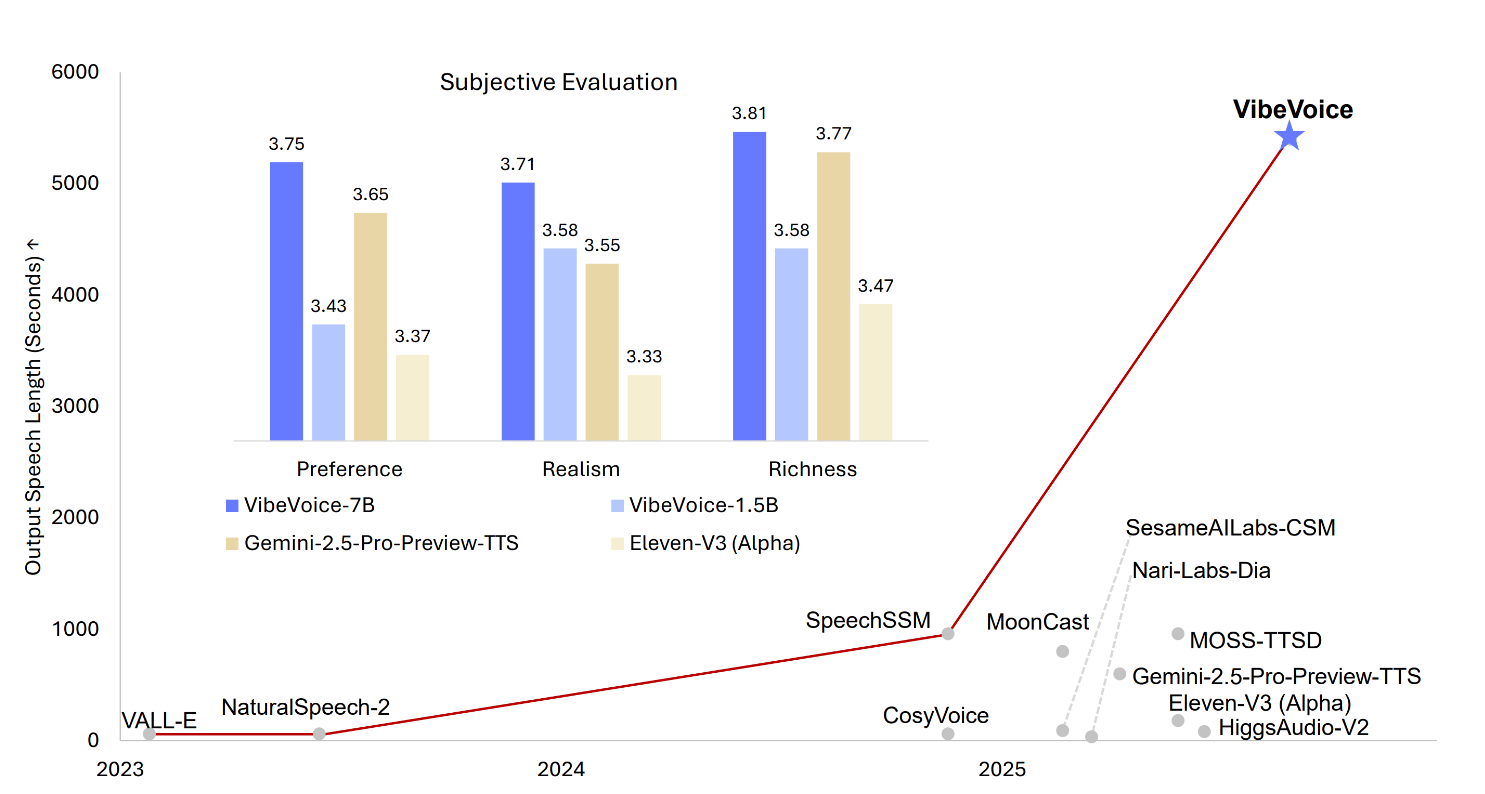
微软新推出的 VibeVoice 模型,彻底革新了我们对 AI 语音合成的认知。它能生成长达 90 分钟的多角色对话音频,简直是播客制作神器。这不仅是音质的提升,更是 AI 理解和驾驭复杂对话能力的飞跃,预示着 AI 语音生成正从简单的单句发音,迈入复杂长篇对话的全新时代。
长篇多角色对话
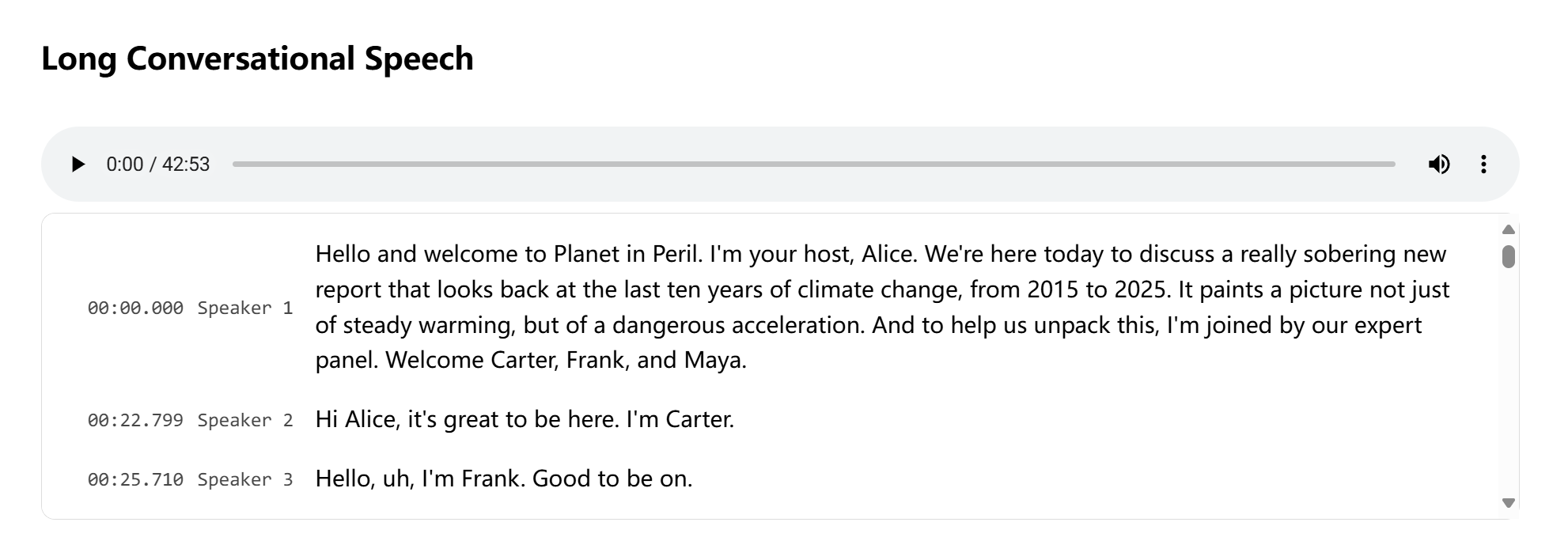
以往的文本转语音模型大多只能应付短句或单人发音,遇到需要多个人对话或者内容很长的场景时就显得力不从心。但微软这次发布的 VibeVoice,直接把这个天花板捅破了。想象一下,一个 AI 模型能够从纯文本中,生成最长 90 分钟、包含多达四个独立角色的自然对话音频,就像专业的播客节目一样。这不只是听起来像人,它在驾驭对话复杂性上更像一场精彩的演绎,解决了传统 TTS 在长时序、角色一致性和轮流对话方面的巨大挑战。

LLM 驱动高效生成
VibeVoice 之所以能做到这一点,技术上的创新非常亮眼。它引入了一种反直觉但高效的设计——使用极低帧率(仅 7.5 赫兹)的连续语音分词器。这听起来有点不可思议,这么低帧率还能保持音频质量?但它确实做到了,并且极大提升了处理长序列的计算效率。更关键的是,VibeVoice 巧妙地融合了一个大型语言模型(LLM),比如他们这次用的是 Qwen2.5-1.5B。这个 LLM 不再仅仅是处理文本内容,它被用来理解对话的上下文、语流和角色间的逻辑关系,再配合一个扩散头来生成高保真的声音细节。在我看来,这标志着 AI 语音合成不再是简单的字词发声,而是进化到了对话理解与表达的新阶段。
模型细节
这个模型的整体架构是 Transformer 架构的 LLM,结合了声学和语义分词器,以及扩散解码头。声学分词器能够将 24kHz 的音频数据压缩 3200 倍,同时保持高质量。语义分词器则通过类似语音识别的任务进行训练,帮助模型理解文本的含义。而那个仅有 1.23 亿参数的扩散头,则负责根据 LLM 理解的信息,精细地生成最终的语音波形。整个训练过程也很有趣,先是独立预训练分词器,然后冻结它们,只训练 LLM 和扩散头的参数。他们还用了课程学习策略,逐步增加输入序列的长度,最终达到了惊人的 65536 个 Token 的上下文窗口。这意味着模型可以记住非常长的对话历史,保证对话的连贯性。
最后
微软明确指出 VibeVoice 目前主要用于研究目的。虽然它的潜力巨大,比如可以想象在有声读物、教育内容、虚拟主播乃至未来游戏角色对话生成方面的应用前景,但伴随而来的风险也不容忽视,尤其是深度伪造和虚假信息的传播。好在微软在这方面做得非常严谨,他们不仅在每次合成的音频中自动嵌入了听不见的水印,还增加了可听见的免责声明,明确告知听众这是 AI 生成的内容。这让我觉得开发者在追求技术突破的同时,对社会责任的考量也越来越深入。这样的透明度和责任感,对于 AI 技术的健康发展至关重要。目前模型仅支持英语和中文,非这两种语言的文本可能会得到奇怪的输出,并且它不生成背景音效或音乐。