通常我们认为 AI 在处理规整数据时表现出色,但在腾讯 ARC 新开源的 ARC-Hunyuan-Video-7B 模型面前,这个观念可能需要重新审视。它是一款重磅多模态模型,专门为理解真实世界中那些看似杂乱无章、却充满情感和深意的用户生成短视频而生,实现了从看懂到读懂的突破。这不仅是技术上的跃进,更代表了 AI 开始深入探索人类创造内容最核心的意图和情绪层面,直击短视频内容最深层的价值。
深层理解能力
传统视频理解常常停留在识别物体或行为,但面对微信视频号、抖音这类用户生成内容(UGC)时,其复杂视觉元素、高信息密度、快节奏以及着重情感表达和观点传递的特点,让机器理解倍感挑战。ARC-Hunyuan-Video-7B(由腾讯 ARC 开发)的目标正是克服这些难题。它不再满足于简单的看到什么,而是致力于理解为什么。模型通过端到端处理视觉、音频、文本信号,能够把握创作者的意图、情绪甚至视频背后的深层含义。这是一种从描述到心智洞察的飞跃,对于短视频 AI 和 UGC 内容分析领域意义非凡。
多模态的协同
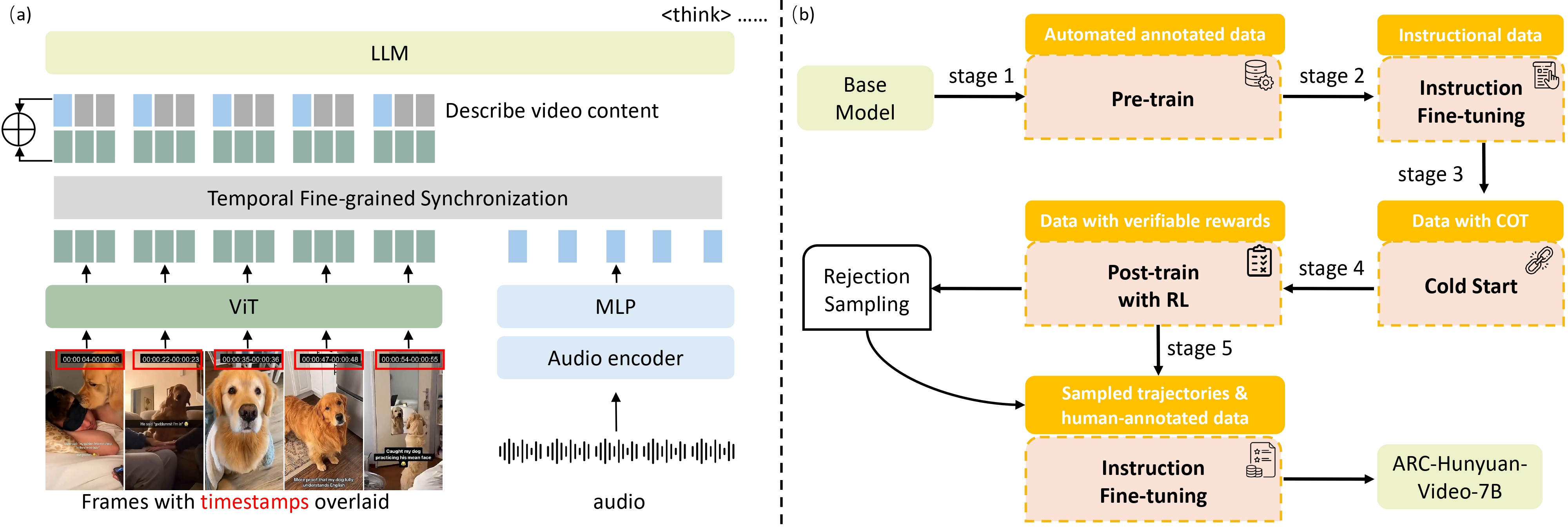
要真正理解一个短视频,视觉和听觉缺一不可。ARC-Hunyuan-Video-7B 巧妙地实现了原始视觉与音频信号的同步推理。这意味着,模型可以处理那些仅靠单一模态无法解决的复杂问题,比如一段小品中的幽默感如何通过台词和表情协同产生,一个产品测评视频中语气语调怎样影响了产品优劣的判断。这种音画信息的无缝融合,让模型对视频内容的理解更加立体和精确,展现了多模态大模型的强大潜力。
事件的精确打点
仅仅知道发生了什么是不够的,还需要知道何时发生。ARC-Hunyuan-Video-7B 具备精准的时间感知能力,支持多粒度带时间戳的字幕生成、时间视频定位和详细事件总结。无论是需要快速查找视频中的某个高光时刻,还是对长视频进行结构化分析,模型的这项能力都显得至关重要。这对于视频搜索、自动化剪辑和内容审核等应用来说,无疑是提升效率的关键技术。
技术解密
ARC-Hunyuan-Video-7B 基于强大的 Hunyuan-7B 视觉语言模型构建,并进行了一系列创新设计。其中包括一个额外的音频编码器,用于实现精细的视觉 - 音频同步;一种时间戳叠加机制,显式地赋予模型时间感知能力;以及通过自动化自举标注流水线处理了数百万真实世界视频数据。更重要的是,模型采用了包含强化学习(RL)在内的多阶段训练方案,这对于解锁其高质量的主观理解能力至关重要,让模型能够从客观任务中学习,最终实现对主观内容的深刻洞察。在 H20 GPU 上,一分钟视频的推理时间仅需约 10 秒,平均可生成 500 个 token,并由 vLLM 框架加速。
上手体验
目前,ARC-Hunyuan-Video-7B 的模型检查点及推理代码(包括 vLLM 版本)已在 Hugging Face 上开源,开发者可以直接下载和使用。如果你只关注中文短视频的描述和摘要,还可以选择 V0 版本。