更小但更强的多模态利器
视觉语言模型赛道的惯性思维是,大就是强。打榜比拼中,MM1-30B、LLava-Next-34B 这些高参数巨兽长期霸榜。
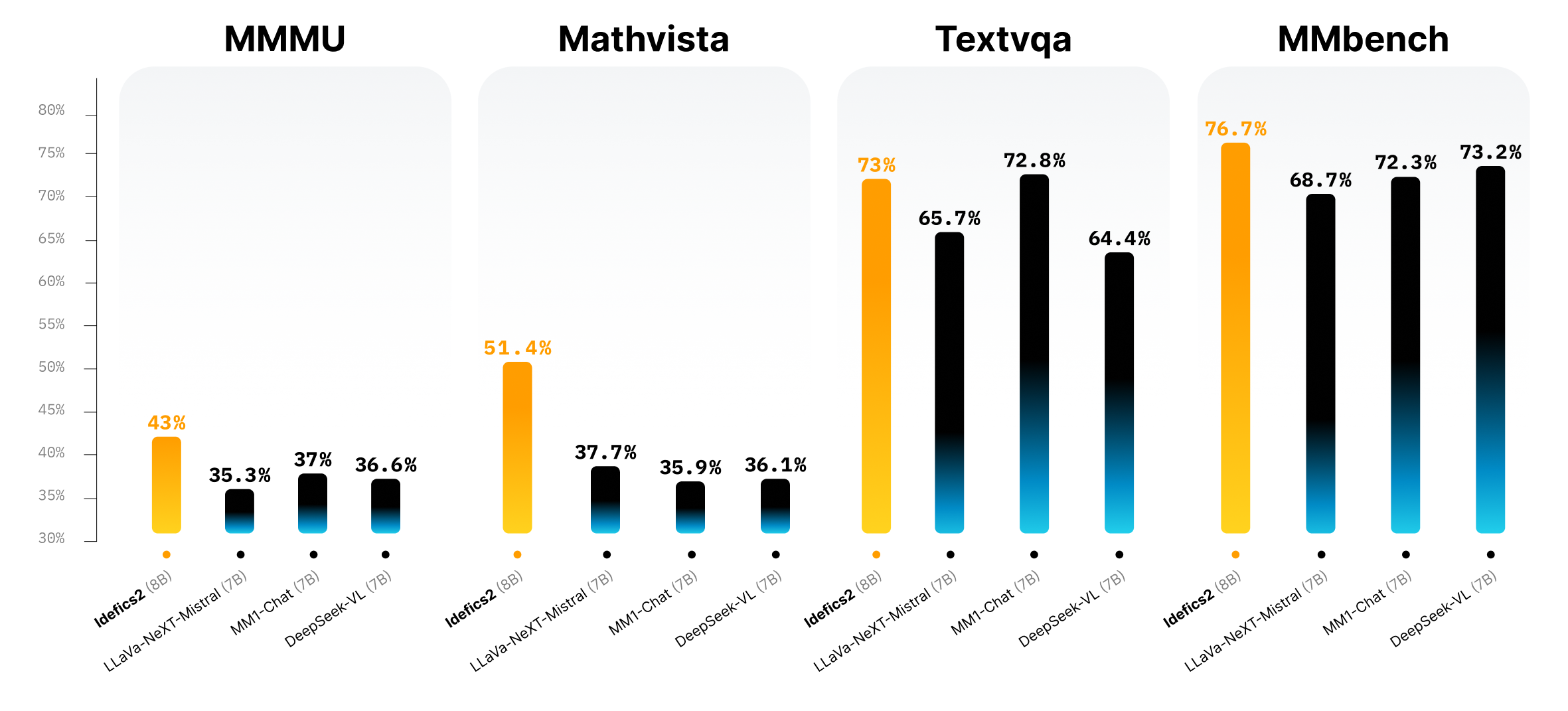
然而 Hugging Face 推出的 Idefics2 推翻了这套逻辑:仅用 8B 参数,却能在一众大模型中杀出血路。这不仅是一次工程层面的胜利,更是一套全新多模态建模路径的验证。
简化架构带来性能腾飞
Idefics2 相比前代最大改动不是增大容量,而是简化思路。它砍掉了复杂的门控交叉注意结构,采用更轻量的视觉主干投影设计,结合 NaViT 图像处理策略,保留原始宽高比和分辨率,无需缩放图像为正方形。这种做法看似“违反常规”,实际极大缓解了多图场景下的信息扭曲与上下文偏移。
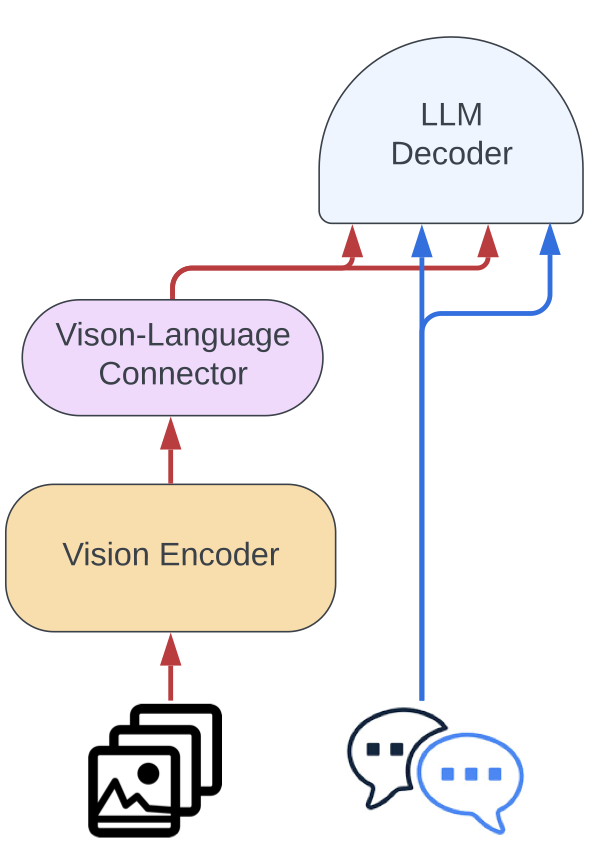
运行 Idefics2 时,无需担心图像尺寸统一问题,也不强制图切,这种高自由配置,对于要处理复杂场景图、表格或 OCR 任务的开发者而言,是提升一致性和准确性的关键。
真实可用的 OCR 水平
OCR 一直是多模态模型的痛点。Idefics2 不靠后处理,而是直接从训练数据上发力:新增了 PDF 文档、网页截图、代码 UI 等多模态高文本密度场景,在训练阶段强化对字符、布局与语义之间的理解。
对 VQAv2、TextVQA、DocVQA 等任务表现卓越。在同尺寸模型中,它的精度超过主流 13B 模型,与更大体积的商用模型(如 Gemini 1.5 Pro)也能打得有来有回。
一个值得记住的数据集:The Cauldron
Idefics2 的指令微调用了 Hugging Face 整理的 The Cauldron 合辑数据集。这不是拼盘,而是一个以“多轮对话”为核心格式的统一框架,涵盖五十个开放数据集。从图片解读到文档问答,每个子任务都按统一格式处理。这种统一性是目前多模态指令微调数据缺失的突破点。
更多资源:
- 模型地址(Hugging Face Hub):
[https://huggingface.co/HuggingFaceM4/idefics2-8b](https://huggingface.co/HuggingFaceM4/idefics2-8b) - 数据集 The Cauldron:
[https://huggingface.co/datasets/HuggingFaceM4/the_cauldron](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron) - 可运行示例代码(Colab):
[https://colab.research.google.com/drive/1NtcTgRbSBKN7pYD3Vdx1j9m8pt3fhFDB?usp=sharing](https://colab.research.google.com/drive/1NtcTgRbSBKN7pYD3Vdx1j9m8pt3fhFDB?usp=sharing)
来点反直觉:参数少,反而更稳定
许多用户在实际部署多模态模型时会发现,大模型上下文混淆严重,多图输入时模型容易前后逻辑错乱。Idefics2 因为参数适中、设计简洁,多轮交互式图像问答更自然,回答一致性更高。部署成本也比 30B 级别模型低近八成,是团队构建原型和落地轻量服务的理想选择。
总结来看,Idefics2 重新定义了多模态的“基础模型”概念——不求最大,但求可控、稳定、多面手。它不仅是一次 Hugging Face 式的产品发布,更像是一次设计哲学上的反击。