图像模型首次懂视频
LLaVA-Onevision 是一种由 LLaVA 团队发布的新型多模态大模型,结合了 Qwen2 的语言理解能力和视觉对齐能力。
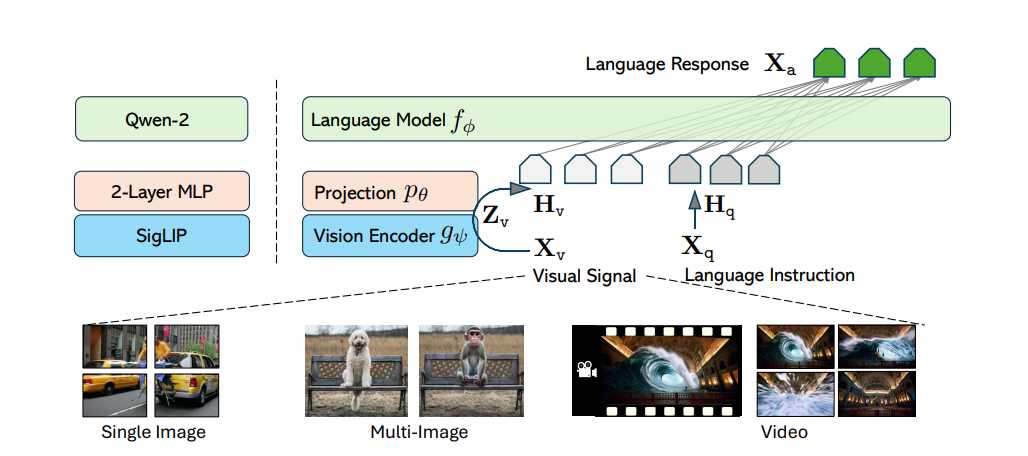
这套模型的独特之处在于,它既能处理单图、多图,又能自然迁移至视频理解场景。对开发者来说,意味着一个统一的 API 可以让不同模态任务无缝切换。
模型亮点解析
模型基础是 SO400M + Qwen2 架构,总参数量达 8B,在浮点精度上使用 bfloat16 格式。整个训练过程被拆为四个阶段,包括预训练(LCS-558K)、中期混合(4.7M 合成数据)、最终单图阶段(3.6M 图像)与 Onevision 阶段(1.6M 图像 + 视频数据)。这个阶段性的设计直接促成了图片与视频之间的任务迁移能力。
特别值得注意的是,Onevision 阶段的混合模式,让模型以统一结构学习图像和视频语言指令,从而实现跨模态迁移:例如你可以用描述静态图的语法,让它理解一整段视频的主要事件。
一个 API 多种模态
开发者可以直接使用 Hugging Face Transformers >= 4.45.0 发布的接口加载模型,也可以通过 Guassian-style message 格式传入多图或视频帧序列,同时支持 Chat 模板自动处理预处理工作。
pipe = pipeline("image-text-to-text", model="llava-hf/llava-onevision-qwen2-7b-si-hf")此外,还支持高效优化选项,例如:
- 通过
bitsandbytes启用 4bit 量化以节省显存 - 配合
Flash Attention 2加速生成过程
反直觉发现 一模型胜多模态
LLaVA-Onevision 展示了一种反直觉的趋势:原以为视觉语言模型需要专门为视频单独建模,但该模型证明,通过少量的统一模态迁移任务设计,就能显著提升跨领域性能,不需重建整个架构。视频理解未必非得上 3D CNN,图像模型加少量视频预训练,同样能打。
演示与资源
-
Hugging Face 模型仓库
[https://huggingface.co/llava-hf/llava-onevision-qwen2-7b-si-hf](https://huggingface.co/llava-hf/llava-onevision-qwen2-7b-si-hf))
-
官方项目主页
-
Flash-Attention 项目地址
[https://github.com/Dao-AILab/flash-attention](https://github.com/Dao-AILab/flash-attention))
如果你正在开发一款视频问答、事件检测或多图故事生成应用,LLaVA-Onevision 没准能帮你一步到位。