VARCO-VISION-2.0-1.7B 是少数在端侧部署仍保有强大视觉理解能力的模型之一。由 NCSOFT 发布,这个多模态模型支持图文混合输入,并具备多图推理与文本本地化 OCR,专为韩文优化,但在英文任务中依然表现不俗。用轻量化模型处理结构化图像内容的能力,正在重塑移动设备上的 AI 应用格局。

多图理解解锁新场景
VARCO-VISION-2.0-1.7B 最大的亮点是支持多张图像输入,并理解图像间的上下文。例如在对比两页发票或文档时,它不仅能识别出文本,还能推断出差异点。这种能力在信息抽取与文档审核中尤其重要,以往只有在云端部署的大模型才具备类似能力。
平衡尺寸与能力
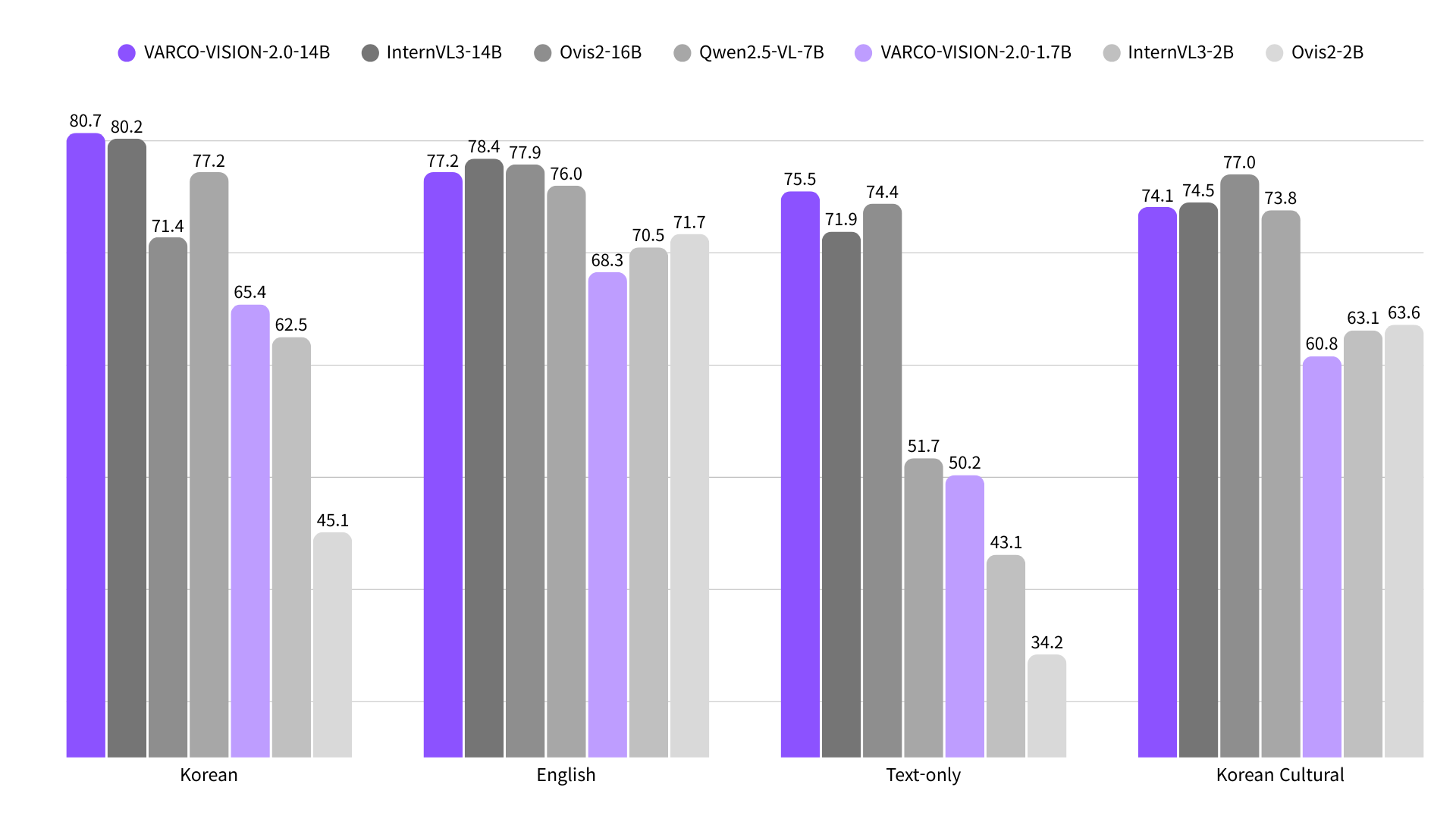
这个模型大小仅 1.7B,基于 siglip2-so400m 与 Qwen3-1.7B 构建,是继 14B 旗舰模型后为本地应用而发布的轻量版本。但在多个基准测试上,它依旧表现抢眼。尤其在韩文基准 K-SEED 与 K-MMStar 上分别拿下 70.7 与 40.8 的高分,超过了很多使用同规模视觉编码器的模型。在英文学术基准如 LLaVABench、RealWorldQA 中也有稳定表现。
文本本地化能力令人惊喜
OCR 模型常常只识别文字,却不给出文字位置。而 VARCO-VISION-2.0 的 OCR 版本为文字加上了边界框定位能力。这种“结构感知型识别”让它可以应对复杂表格、商店招牌、流程图等数据,更接近工业应用需求。例如在 Retail 场景中提取货架价格标签、表格对比,甚至翻译和文字排布检查都能本地完成。
视觉类 AI 的未来方向
相较于视觉能力普遍“重模型设备”的传统思维,这次 NCSOFT 搭载 OCR 与多图理解能力的轻量化配置是一种挑战主流的设计选择。特别是在移动设备、PC 端做推理时,不依赖云服务意味着更快响应、更佳隐私性。
可以在 Hugging Face 上试用该模型