
拆解轻量视觉模型的黑马
LLaVA-Phi-3-mini 是 XTuner 团队推出的一款多模态小模型,融合了 Microsoft 的 Phi-3-mini 和 OpenAI 的 CLIP-ViT-Large-patch14-336,经由 ShareGPT4V-PT 与 InternVL-SFT 数据调教完成,最终以 Hugging Face 上的 LLaVA 格式发布。
链接如下:
- GitHub 项目地址:xtuner:https://github.com/InternLM/xtuner
- 模型主页:xtuner/llava-phi-3-mini:https://huggingface.co/xtuner/llava-phi-3-mini
- GGUF 格式模型:https://huggingface.co/xtuner/llava-phi-3-mini-gguf
为什么这款模型值得关注
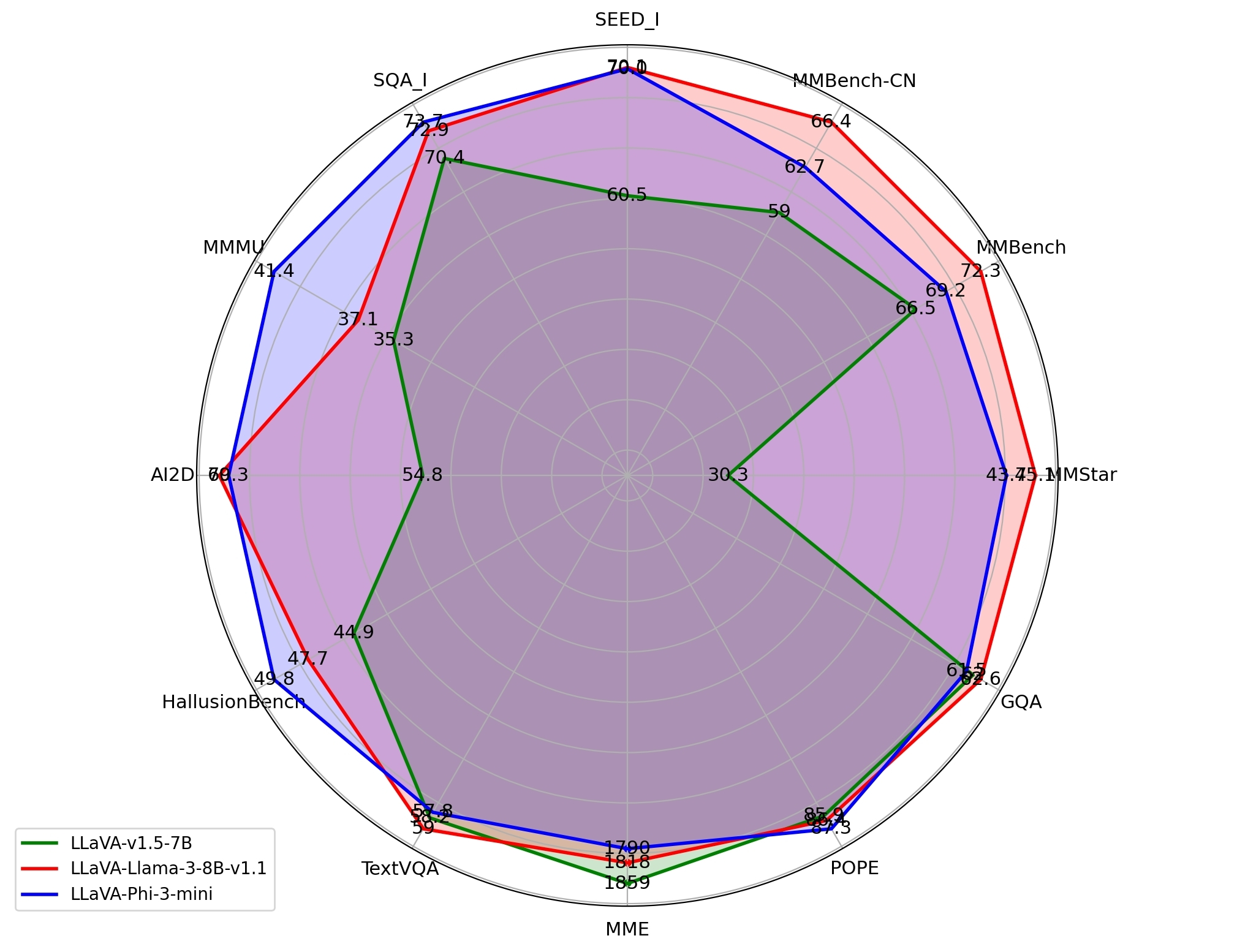
模型规模仅约 4B 参数,却在多个多模态基准上超越了 LLaVA-7B 与 LLaVA-LLaMA3-8B,尤其是在复杂视觉推理任务如 MMU Val 与 AI2D Test 上表现出极高精度。关键在于其预训练策略:语言模型与视觉编码器都冻结,随后进行全参数微调。这种“先冻后训”的方式在小模型上比大模型更有效,因为能以结构化数据最大化提取图片语义。
训练中使用的数据来自 ShareGPT4V-PT(124 万样本)和 InternVL-SFT(126 万样本),覆盖范围广泛,包括图形问答、科学可视化到现实物体识别。
极低资源也能部署
这款模型最大的潜力在于边缘部署场景。现有多模态模型,如 GPT-4V 或 Gemini,少数开源者难以承载。而 LLaVA-Phi-3-mini 不仅模型轻量,还已提供 GGUF 格式,支持 llama.cpp 与 llama-cpp-python 快速部署。
一位开发者在 Jetson Orin Nano 上部署该模型,用于农田监控图像识别,后端接通 MQTT 推送,达到了每秒 1.2 帧的响应,稳定运行超过三天。大模型时代的边角料,被轻量模型完整接收。
真正通用的多模态接口
官方已经实现 transformers 与 pipeline 两套调用方式,支持直接喂图+prompt 输出回答。适配 Hugging Face 的 LlavaForConditionalGeneration 与 AutoProcessor,可与其他 LLaVA 格式模型无缝切换。
示例代码详见 Hugging Face 项目页(xtuner/llava-phi-3-mini-hf)。数据集与训练设置在 GitHub 说明中也完整开放。
不只是“小而精”更是“细而稳”
不同于常规的 LoRA 微调,XTuner 在视觉部分彻底解冻训练,用更长周期、更多样本验证迁移鲁棒性。结果在如 HallusionBench、TextVQA 等具幻想陷阱的数据集上,比规模是其两倍的模型更健壮。
真正的亮点不在参数量,而在微调的“工匠精神”上。对于预算有限又追求多模态认知能力的开发者来说,LLaVA-Phi-3-mini 是当下不可忽视的一条路线。