如何在云主机上快速开始机器学习训练
👋
【数据安全必读】
系统盘与数据盘均为本地 SSD,无冗余,单点故障可能导致数据永久丢失。
请务必将重要数据实时备份至「共享存储卷」或本地,共绩算力对本地盘损坏及数据丢失不承担任何责任。
立即开通共享存储卷,获得企业级冗余 + 跨区域同步,彻底告别数据丢失:
https://www.gongjiyun.com/docs/server/jojuw4rfdiepfxkchonctw0jnxe/yvawwrzvcivbypk8vihcgjrkn8c/
1 用基础镜像创建云主机
Section titled “1 用基础镜像创建云主机”1.1 第一步:创建云主机
Section titled “1.1 第一步:创建云主机”点击顶部的【云主机】按钮,进入云主机界面:https://console.suanli.cn/server
挑选合适的设备,本例中点击【142 台设备可租】按钮
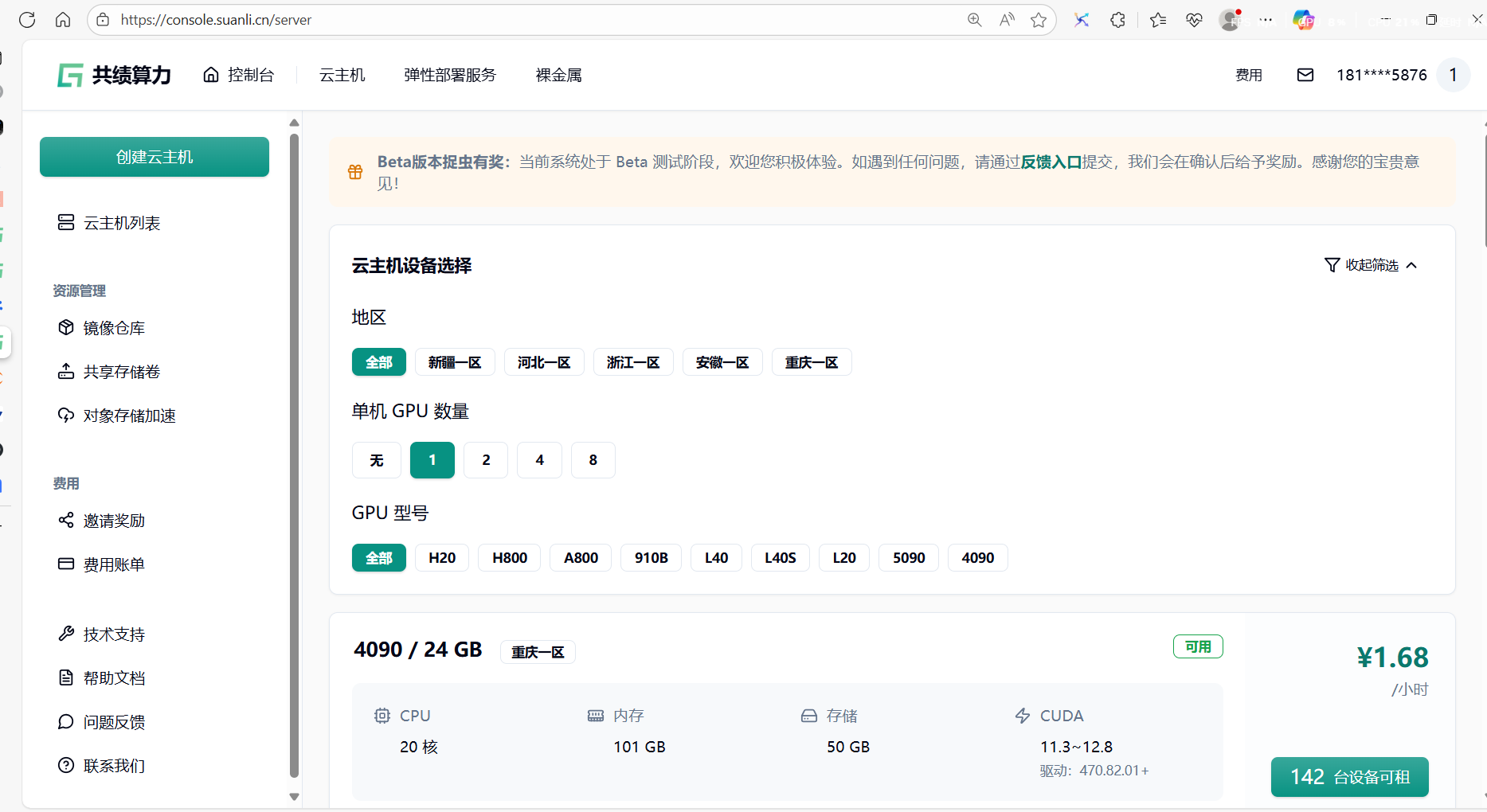
GPU 型号推荐配置:
1 卡:每小时仅需 1.68 元,按秒计费(0.000446 元/秒),适合短期测试或常规任务。
多卡选项备用:若未来需要多卡训练或高并发任务,可随时通过关机切换 2 卡/4 卡配置。
1.2 第二步:配置资源
Section titled “1.2 第二步:配置资源”1.2.1 设置实例名称
Section titled “1.2.1 设置实例名称”为创建的开发机设置一个容易记住的名字,也可以采用系统自动生成的实例名称。
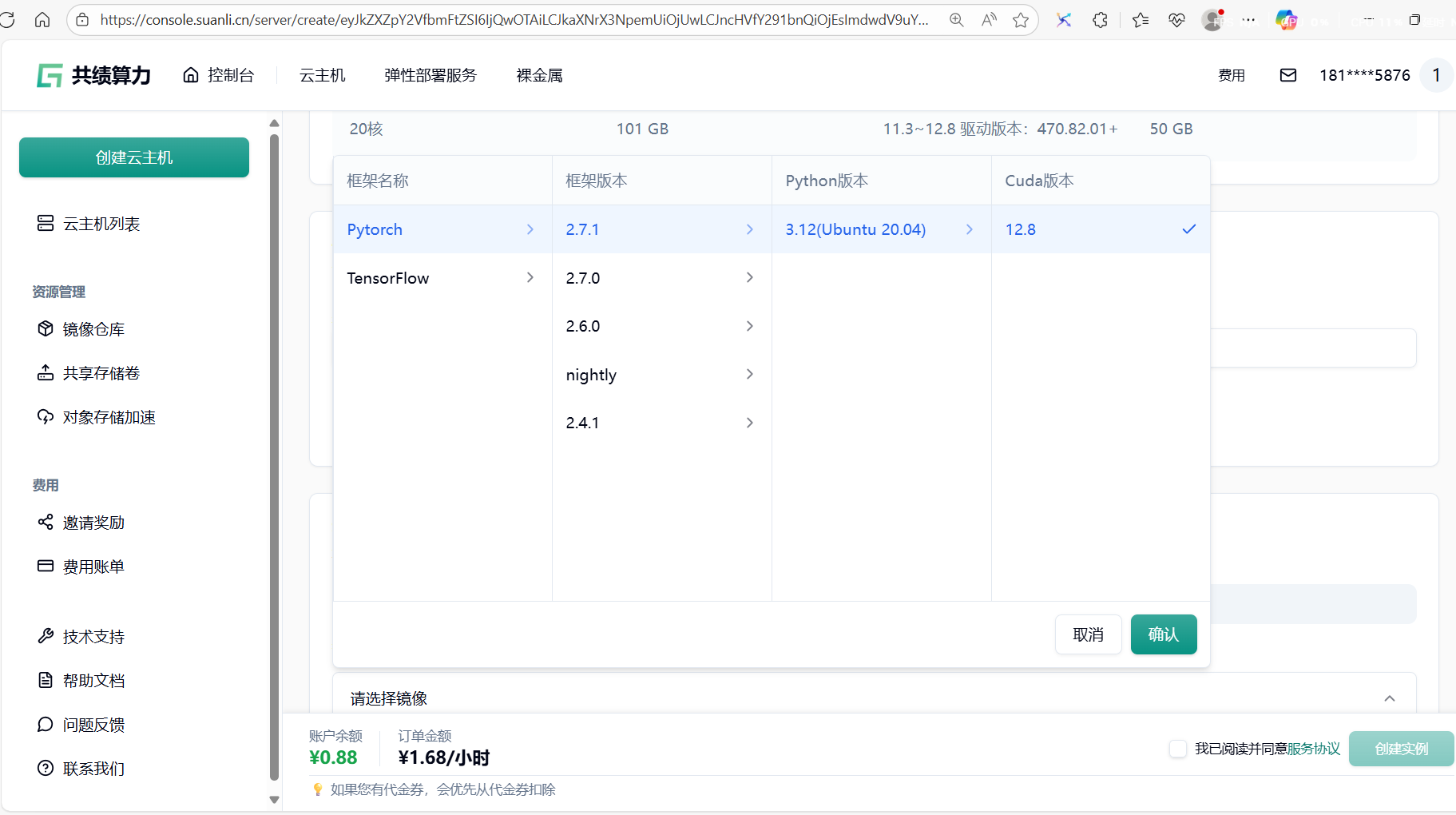
1.2.2 选择基础镜像
Section titled “1.2.2 选择基础镜像”按照需求选择我们预制好的镜像,同时可以通过文档链接快速了解容器化部署对应服务的步骤。
这里我们选择了 在 Ubuntu22.04 上运行的 PyTorch 的 2.7.1 版本,Python 为 3.12,CUDA 版本 12.8 的镜像作为示例。
- 平台默认提供了一批基础镜像供试用,可以根据实际需要选择合适的镜像
1.2.3 开通共享存储卷服务,挂载到本机目录(实现多机训练数据共享)
Section titled “1.2.3 开通共享存储卷服务,挂载到本机目录(实现多机训练数据共享)”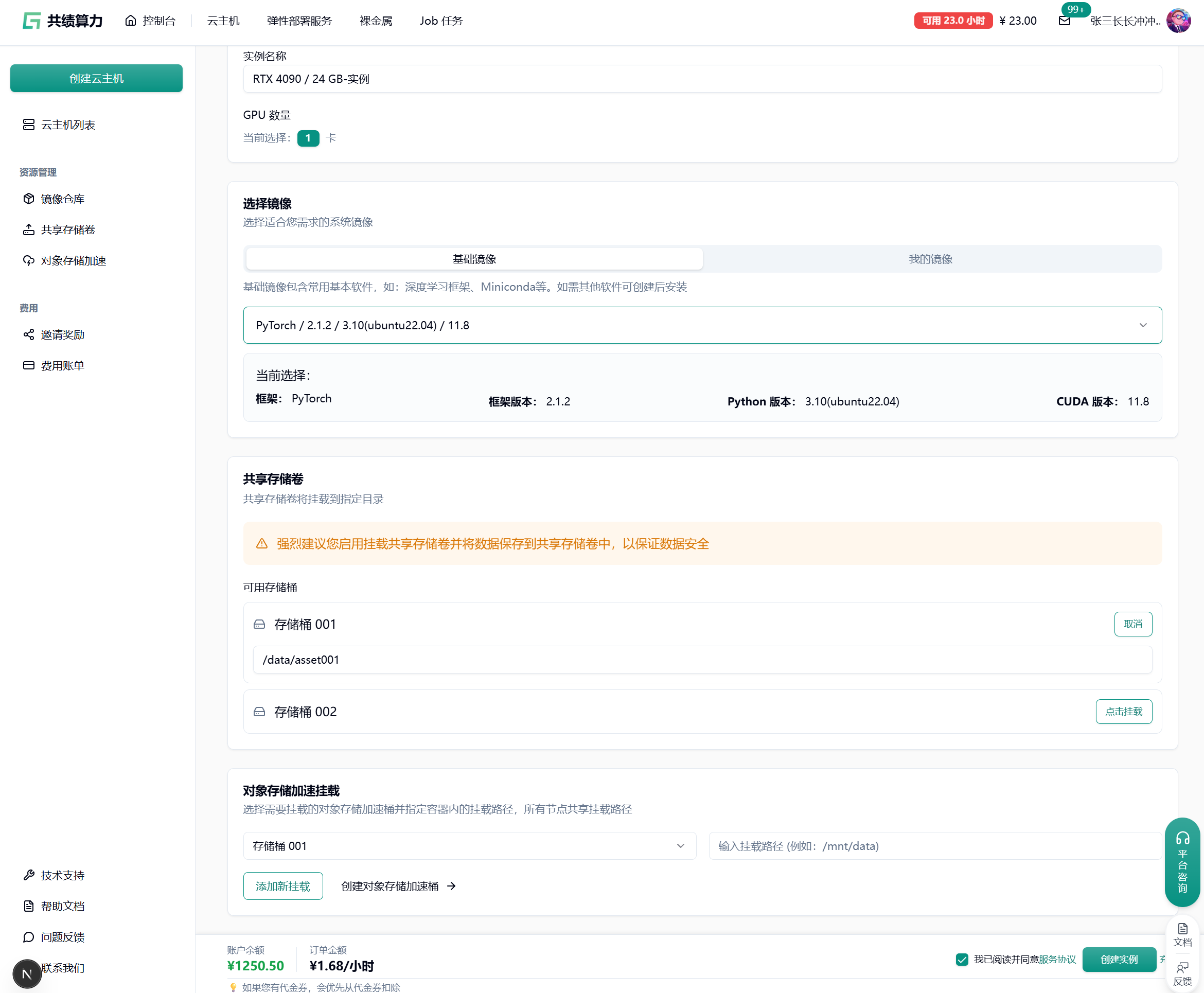
注意:
- 挂载存储的时候,不要直接挂载到/、/root、 /root/目录,否则会出现一些奇怪的问题。建议挂载在类似/root/data 、/root/code 之类的二级目录。
同意服务协议,点击【创建实例】按钮,完成云主机的 创建过程。
1.3 第三步:查看运行状态开始使用程序
Section titled “1.3 第三步:查看运行状态开始使用程序”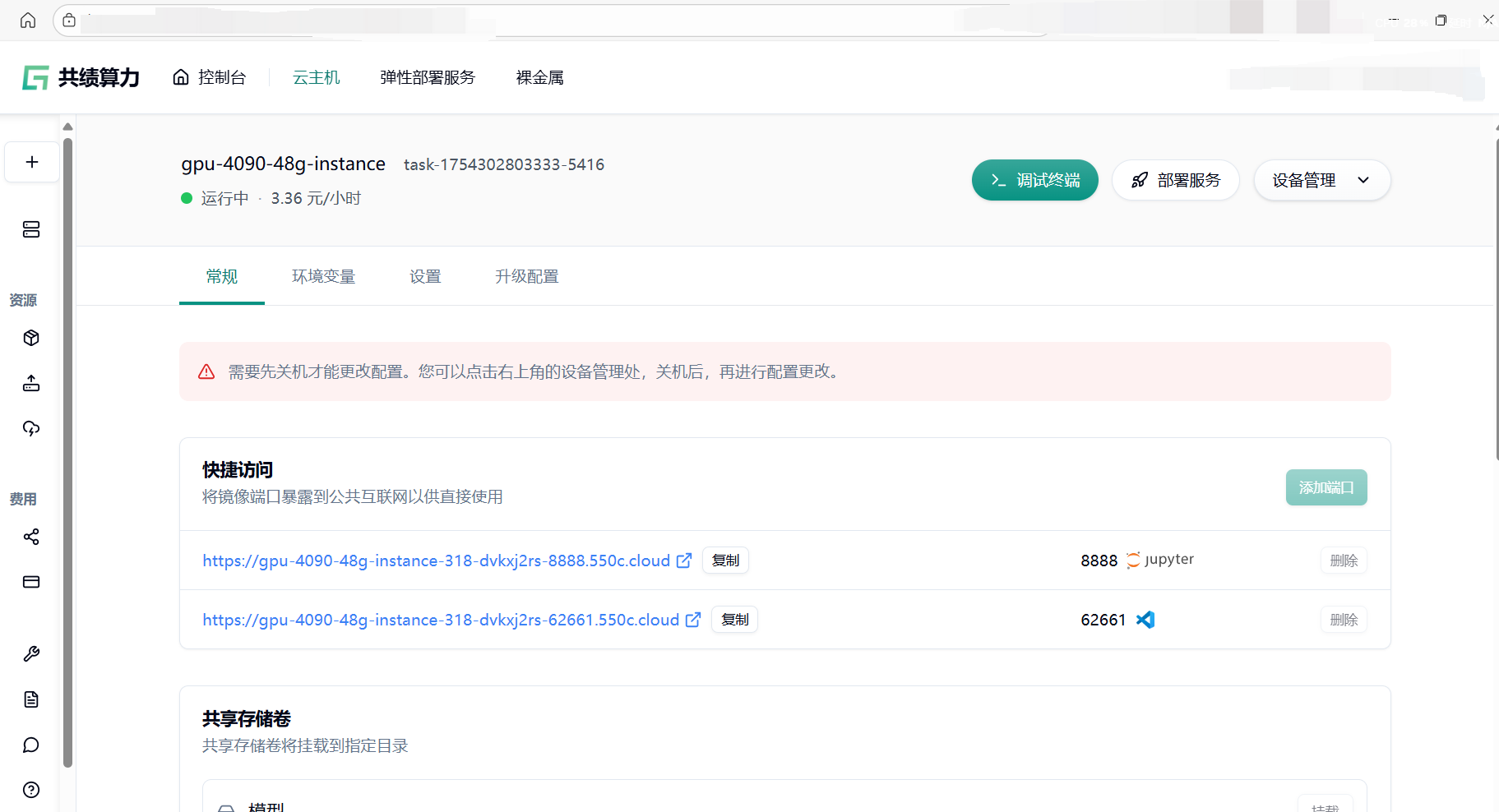
2.在云主机上快速开始训练
Section titled “2.在云主机上快速开始训练”示例程序:
"""一个端到端演示:用 PyTorch 训练 MLP 二分类器并在训练过程中实时可视化损失曲线与决策边界。"""import mathimport timeimport randomimport numpy as npimport matplotlib.pyplot as pltimport torchimport torch.nn as nnfrom torch.utils.data import TensorDataset, DataLoader
def set_seed(seed=42): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed)
set_seed(42)
def make_moons(n_samples=1000, noise=0.2): """手工实现 make_moons,不依赖 sklearn""" n_samples_out = n_samples // 2 n_samples_in = n_samples - n_samples_out outer_circ_x = np.cos(np.linspace(0, math.pi, n_samples_out)) outer_circ_y = np.sin(np.linspace(0, math.pi, n_samples_out)) inner_circ_x = 1 - np.cos(np.linspace(0, math.pi, n_samples_in)) inner_circ_y = 1 - np.sin(np.linspace(0, math.pi, n_samples_in)) - .5 X = np.vstack([np.append(outer_circ_x, inner_circ_x), np.append(outer_circ_y, inner_circ_y)]).T.astype(np.float32) y = np.hstack([np.zeros(n_samples_out, dtype=np.float32), np.ones(n_samples_in, dtype=np.float32)]) if noise > 0: X += np.random.normal(0, noise, X.shape) return X, y
X, y = make_moons(1200, noise=0.25)
perm = np.random.permutation(len(X))train_size = int(0.8 * len(X))X_train, y_train = X[perm[:train_size]], y[perm[:train_size]]X_val, y_val = X[perm[train_size:]], y[perm[train_size:]]
train_ds = TensorDataset(torch.from_numpy(X_train), torch.from_numpy(y_train))val_ds = TensorDataset(torch.from_numpy(X_val), torch.from_numpy(y_val))train_loader = DataLoader(train_ds, batch_size=64, shuffle=True)val_loader = DataLoader(val_ds, batch_size=256)
class MLP(nn.Module): def __init__(self, in_dim=2, hidden=64): super().__init__() self.net = nn.Sequential( nn.Linear(in_dim, hidden), nn.ReLU(), nn.Linear(hidden, hidden), nn.ReLU(), nn.Linear(hidden, 1) ) def forward(self, x): return self.net(x).squeeze(1)
device = 'cuda' if torch.cuda.is_available() else 'cpu'model = MLP().to(device)criterion = nn.BCEWithLogitsLoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
EPOCHS = 200PLOT_FREQ = 10 # 每 10 个 epoch 画一次图
plt.ion() # 交互模式fig = plt.figure(figsize=(12, 5))ax_loss = fig.add_subplot(1, 2, 1)ax_boundary = fig.add_subplot(1, 2, 2)
train_losses, val_losses = [], []
def plot_boundary(ax): ax.clear() # 背景网格 h = 0.02 x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) grid = torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float().to(device) with torch.no_grad(): Z = torch.sigmoid(model(grid)).cpu().numpy().reshape(xx.shape) ax.contourf(xx, yy, Z, levels=50, cmap='RdBu', alpha=0.7) ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap='bwr', edgecolors='k') ax.set_title('Decision boundary')
def plot_loss(ax): ax.clear() ax.plot(train_losses, label='Train') ax.plot(val_losses, label='Val') ax.set_title('Loss curve') ax.legend()
for epoch in range(1, EPOCHS + 1): # ---------- 训练 ---------- model.train() epoch_loss = 0. for xb, yb in train_loader: xb, yb = xb.to(device), yb.to(device) optimizer.zero_grad() logits = model(xb) loss = criterion(logits, yb) loss.backward() optimizer.step() epoch_loss += loss.item() * xb.size(0) train_loss = epoch_loss / len(train_loader.dataset) train_losses.append(train_loss)
# ---------- 验证 ---------- model.eval() epoch_loss = 0. with torch.no_grad(): for xb, yb in val_loader: xb, yb = xb.to(device), yb.to(device) logits = model(xb) loss = criterion(logits, yb) epoch_loss += loss.item() * xb.size(0) val_loss = epoch_loss / len(val_loader.dataset) val_losses.append(val_loss)
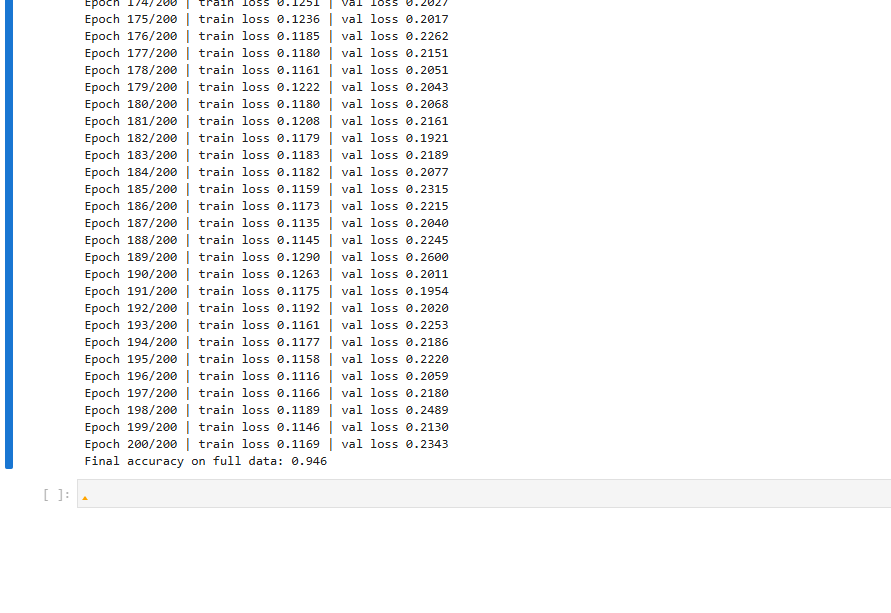
print(f'Epoch {epoch:03d}/{EPOCHS} | train loss {train_loss:.4f} | val loss {val_loss:.4f}')
# ---------- 可视化 ---------- if epoch % PLOT_FREQ == 0 or epoch == EPOCHS: plot_loss(ax_loss) plot_boundary(ax_boundary) plt.pause(0.01)
plt.ioff()plt.show()
model.eval()with torch.no_grad(): X_tensor = torch.from_numpy(X).to(device) y_pred = (torch.sigmoid(model(X_tensor)) > 0.5).cpu().numpy().astype(int)accuracy = (y_pred == y).mean()print(f'Final accuracy on full data: {accuracy:.3f}')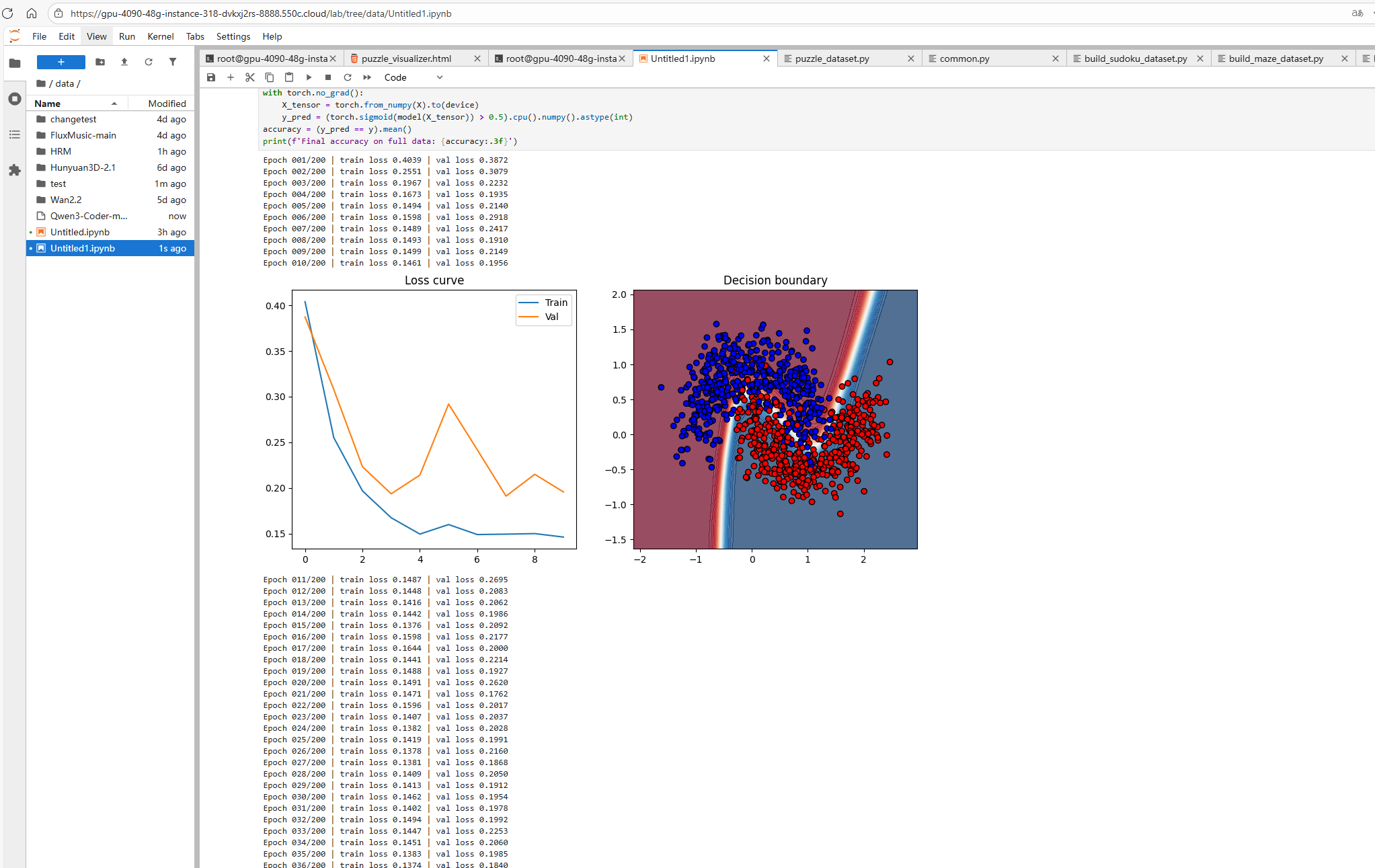
更多的实践和功能可以参考我们的云主机文档~