基于 ComfyUI 的社区镜像二次创作流程
创作 ComfyUI 的社区镜像——三条路线,总有一款适合你
开箱即用:直接选用平台预装 ComfyUI-Manager 的基础镜像,缺什么节点 模型一键补齐,复制现成工作流即可开工。
全链自建:本地写 Dockerfile,把 ComfyUI、插件、模型、流程一次打包成私有镜像,推到仓库,后续秒级批量部署。
在线改完即存:先拉官方或社区成品镜像跑起来,边跑边调节点/模型,调试满意后“关机→保存为新镜像”,随时复用。
一、从云主机 ComfyUI 基础镜像扩展工作流(推荐方式)
Section titled “一、从云主机 ComfyUI 基础镜像扩展工作流(推荐方式)”1. 环境准备
Section titled “1. 环境准备”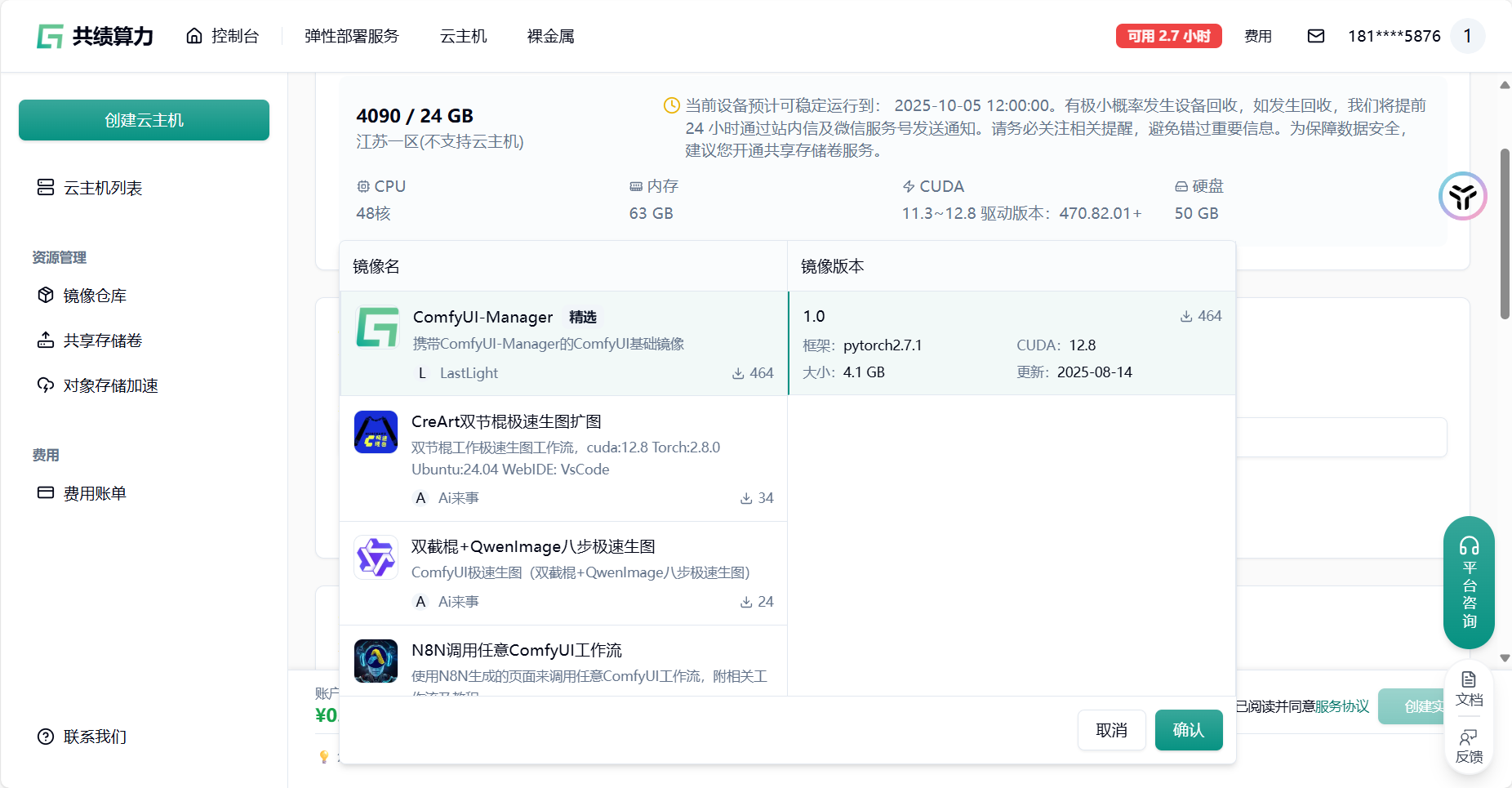
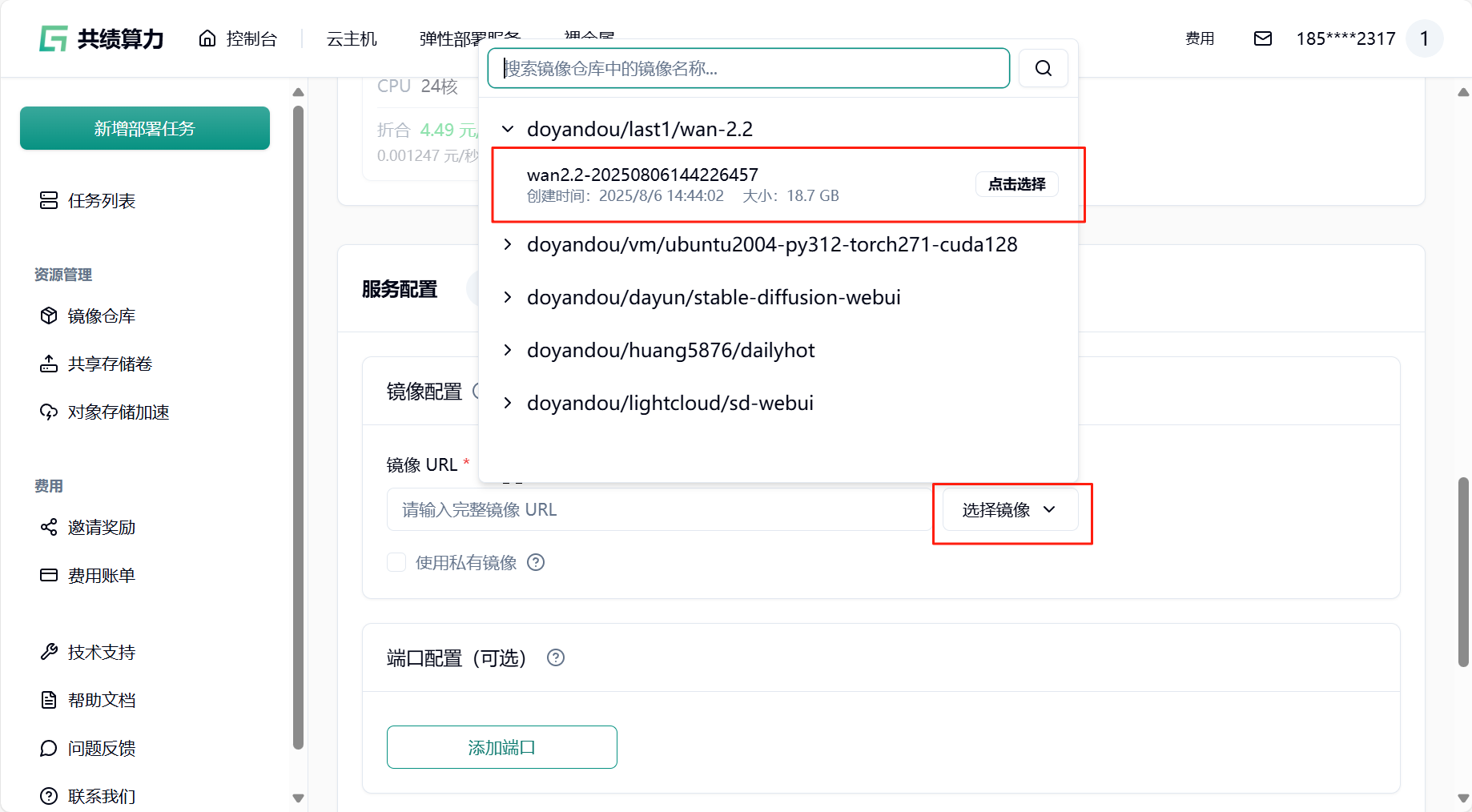
登录共绩算力云主机控制台,在社区镜像中选择我们自带 ComfyUI Manger 的基础镜像
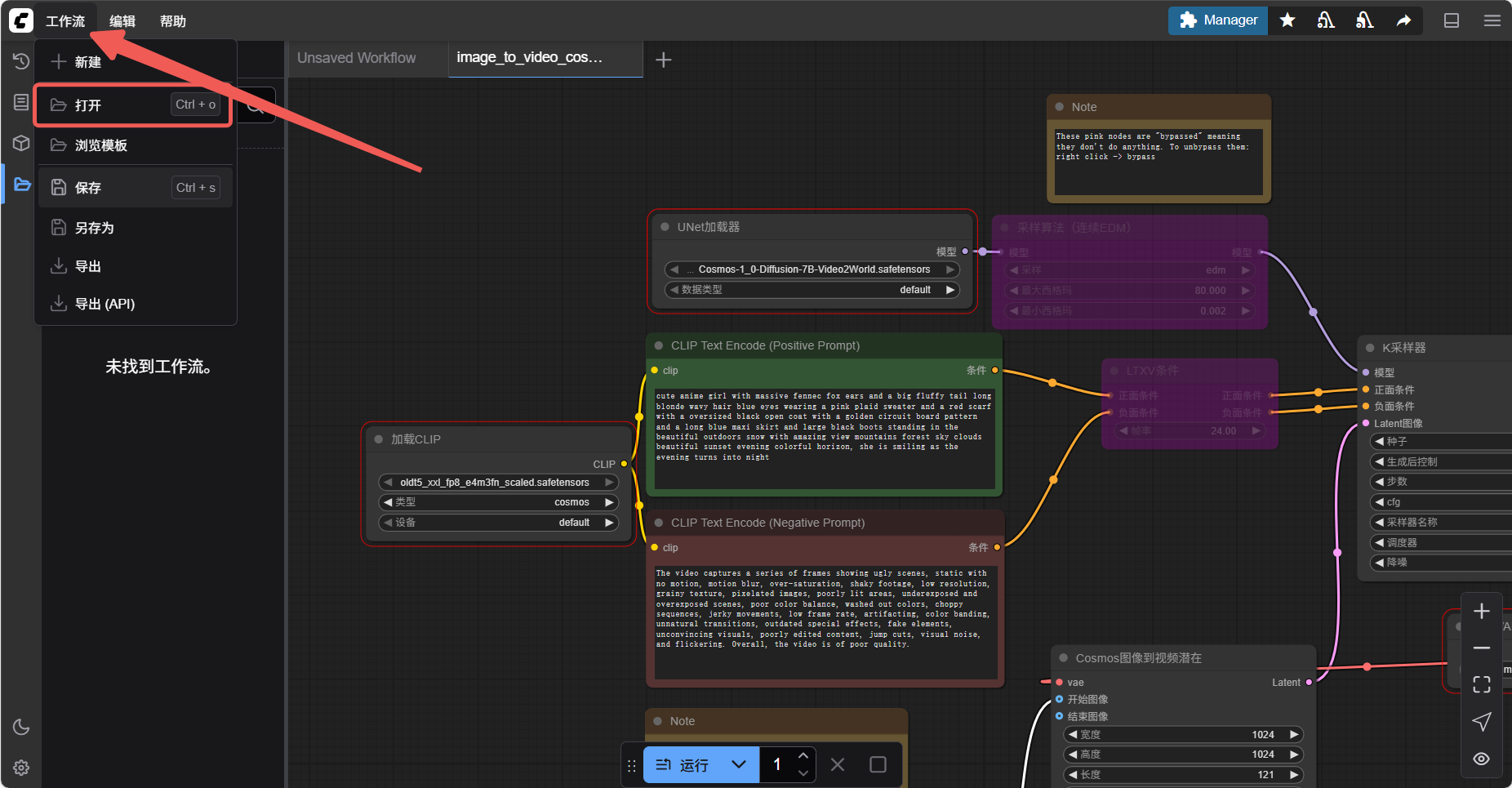
可以直接通过复制或者从上方菜单工作流中直接打开需要的工作流(json 文件)
2. 下载缺失节点
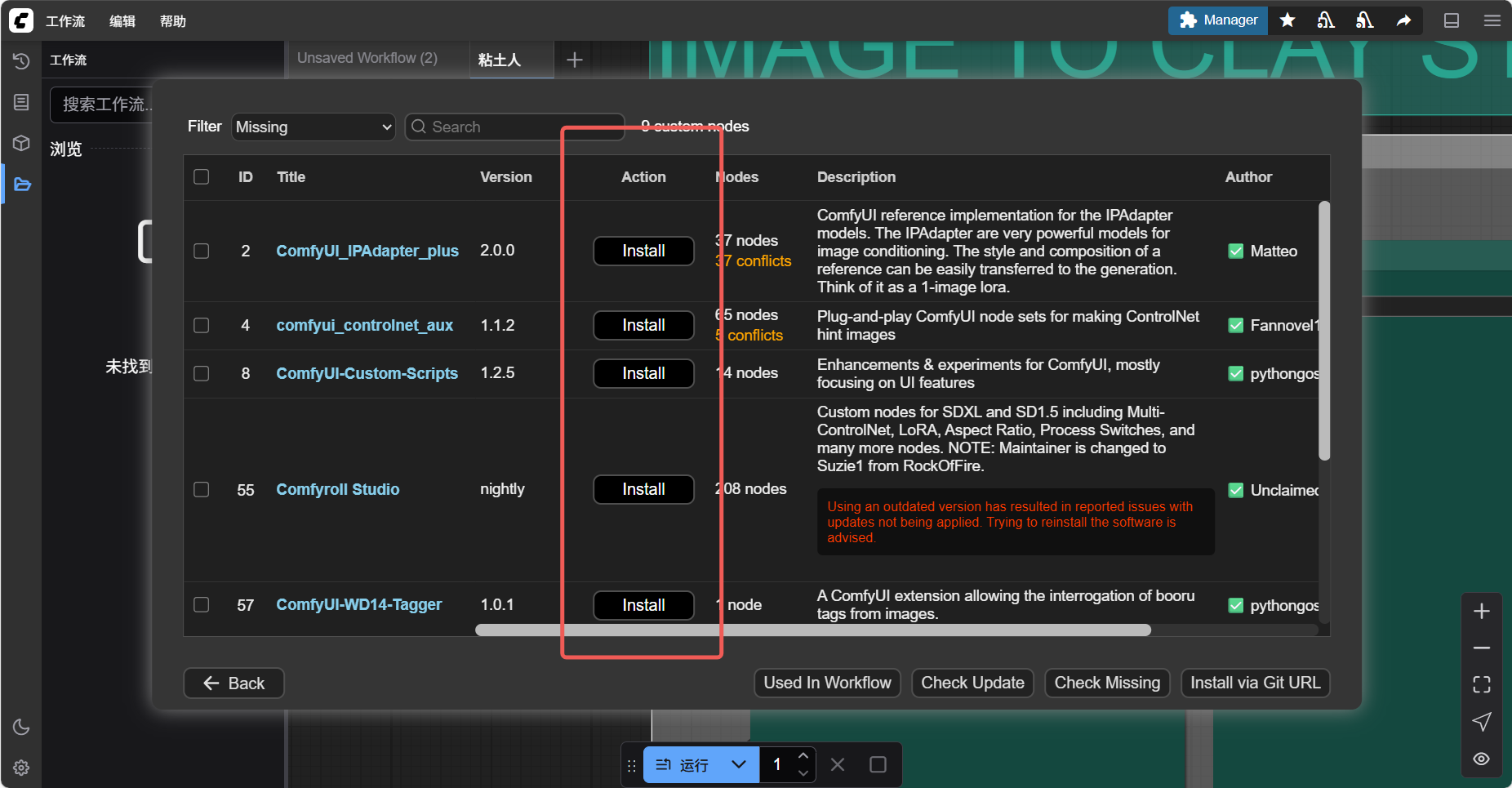
Section titled “2. 下载缺失节点”- 方法一:通过 ComfyUI Manager 自动安装
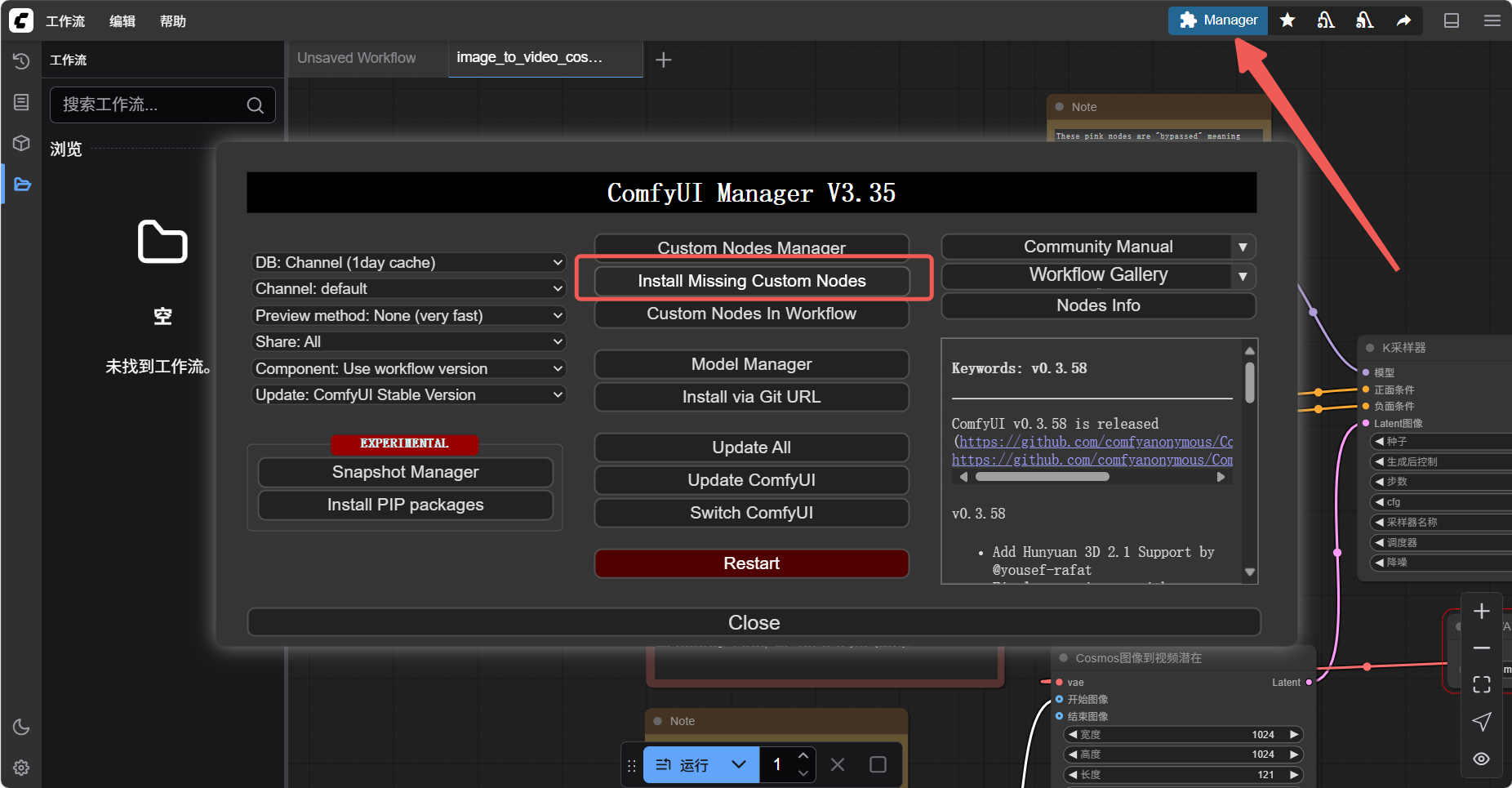
在 WebUI 中点击 Manager → Install Missing Custom Nodes,工具会自行搜索缺失节点(如 ControlNet、IP-Adapter),点击安装。
节点安装完成后按照提示重新启动 comfyUI 刷新浏览器
- 方法二:手动克隆节点仓库以安装
ControlNet为例:
当通过 ComfyUI Manager 自动安装时导入失败此时点击 尝试修复 大概率无法正常修复
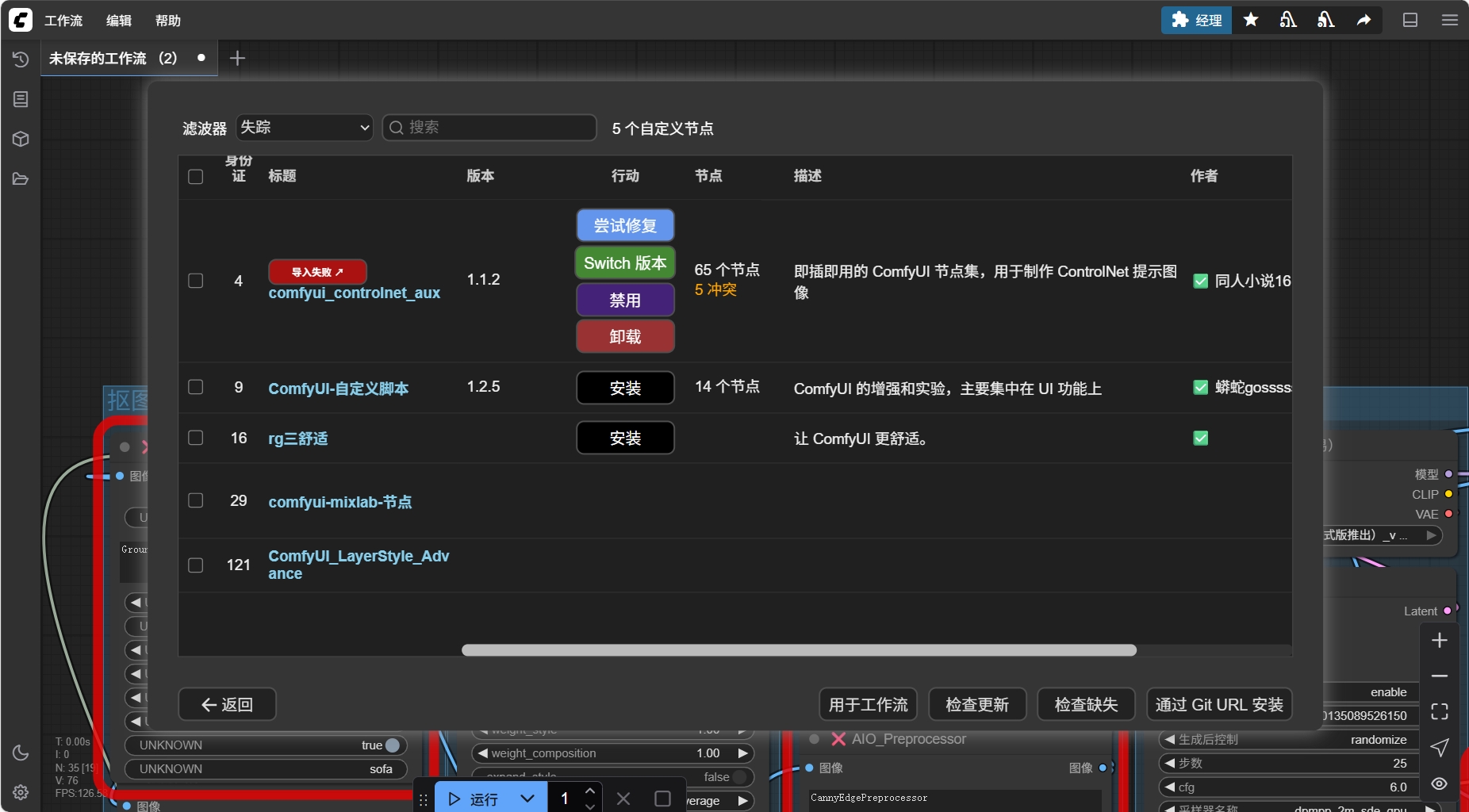
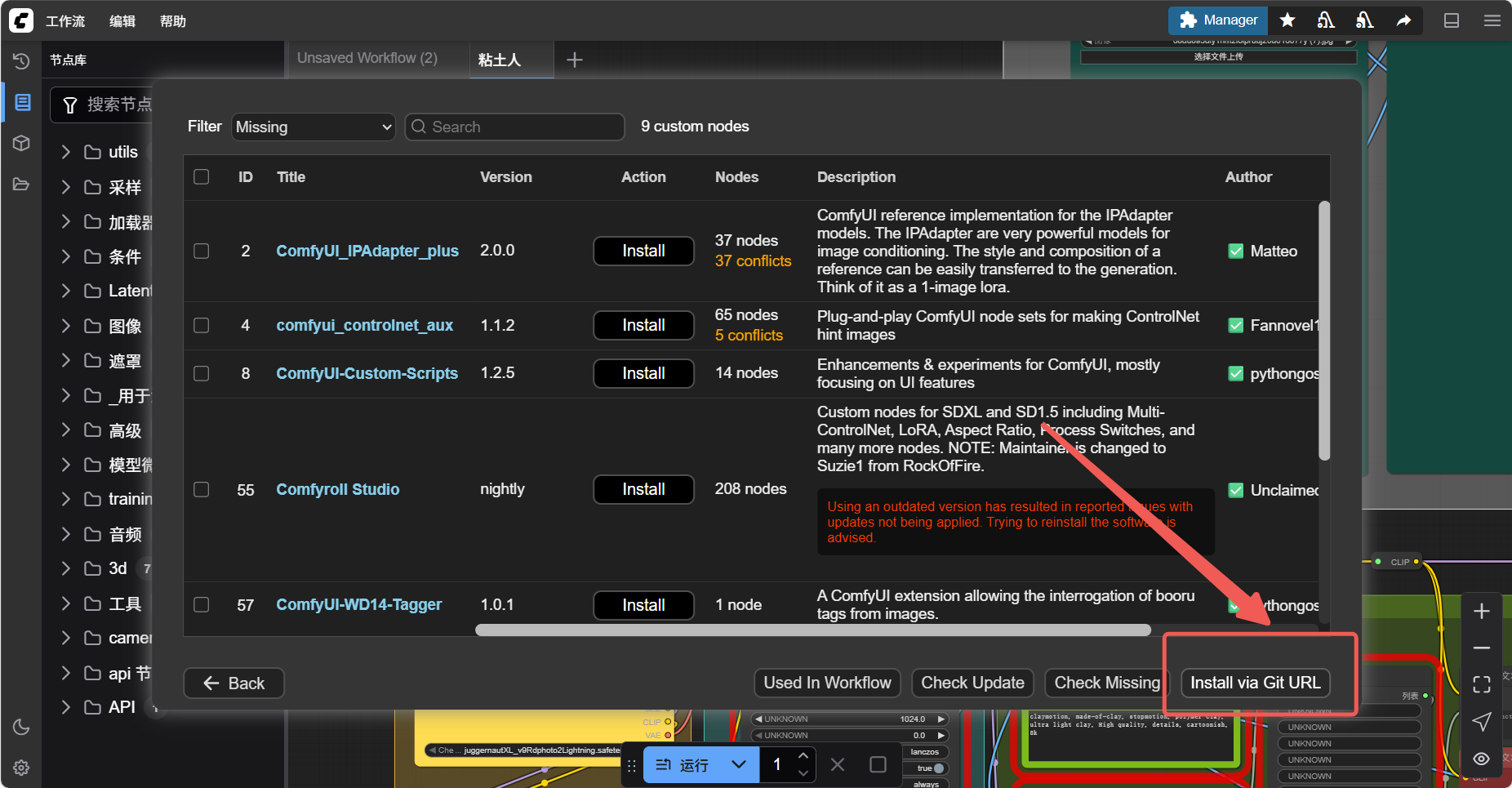
此时我们可以通过 Install via Git URL 来从 github 仓库上直接拉取对应节点的内容
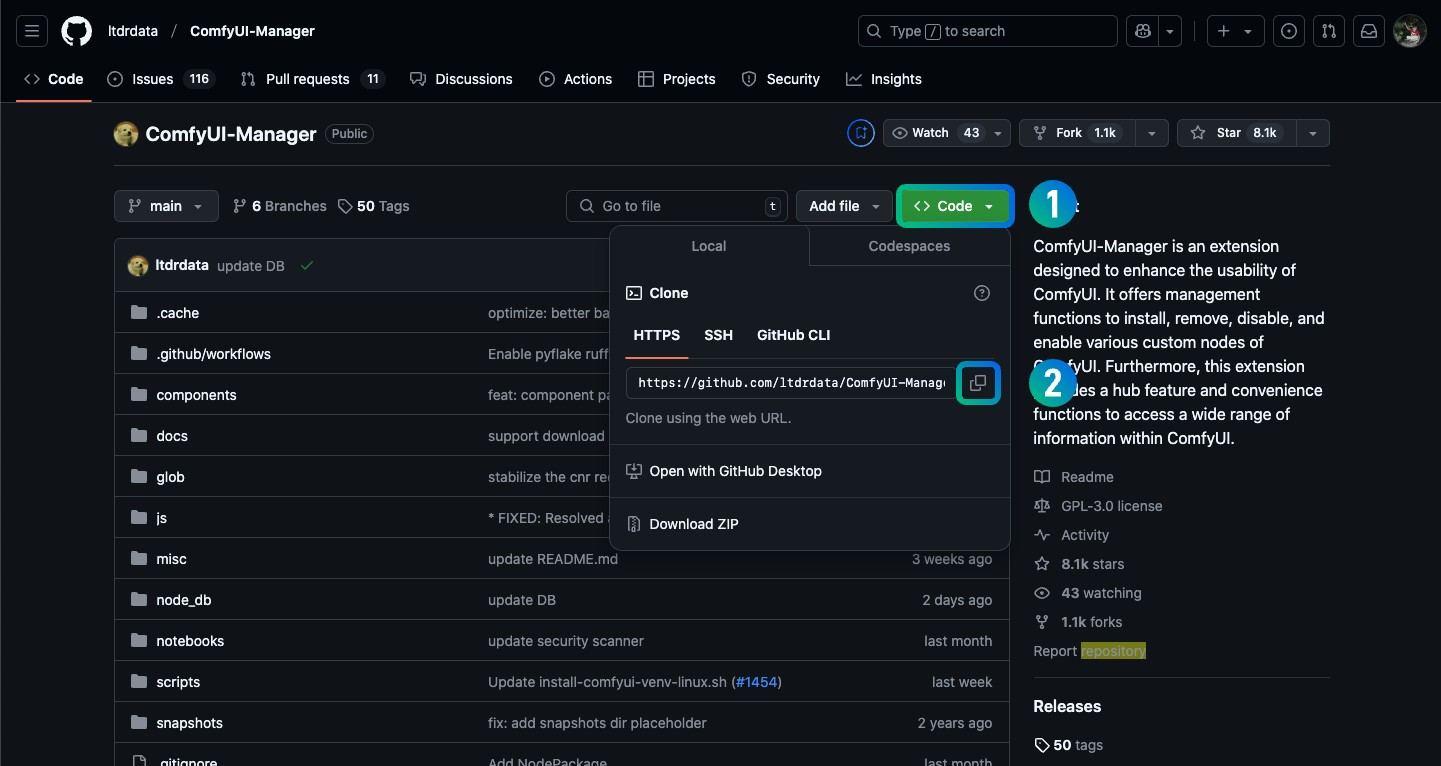
首先找到你要安装的插件的 Git 仓库,如 https://github.com/ltdrdata/ComfyUI-Manager
- 点击页面中 绿色的 code 按钮
- 点击弹窗的 https 选项下输入框后的复制按钮
- 你将复制得到 https://github.com/ltdrdata/ComfyUI-Manager.git 的链接
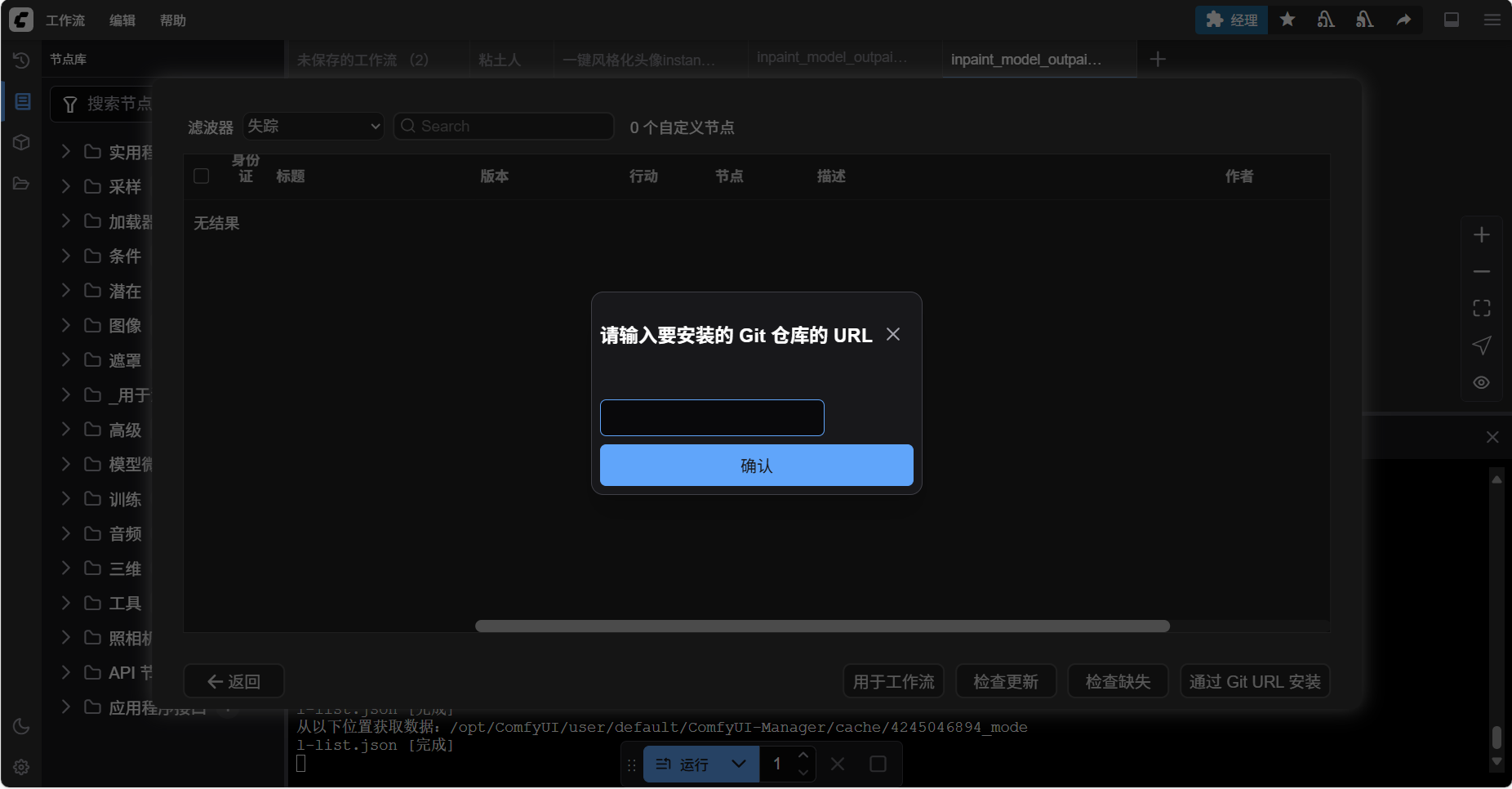
复制进来即可开始下载
3. 补全模型与配置文件
Section titled “3. 补全模型与配置文件”3.1 通过官方的模型管理器下载补充模型
Section titled “3.1 通过官方的模型管理器下载补充模型”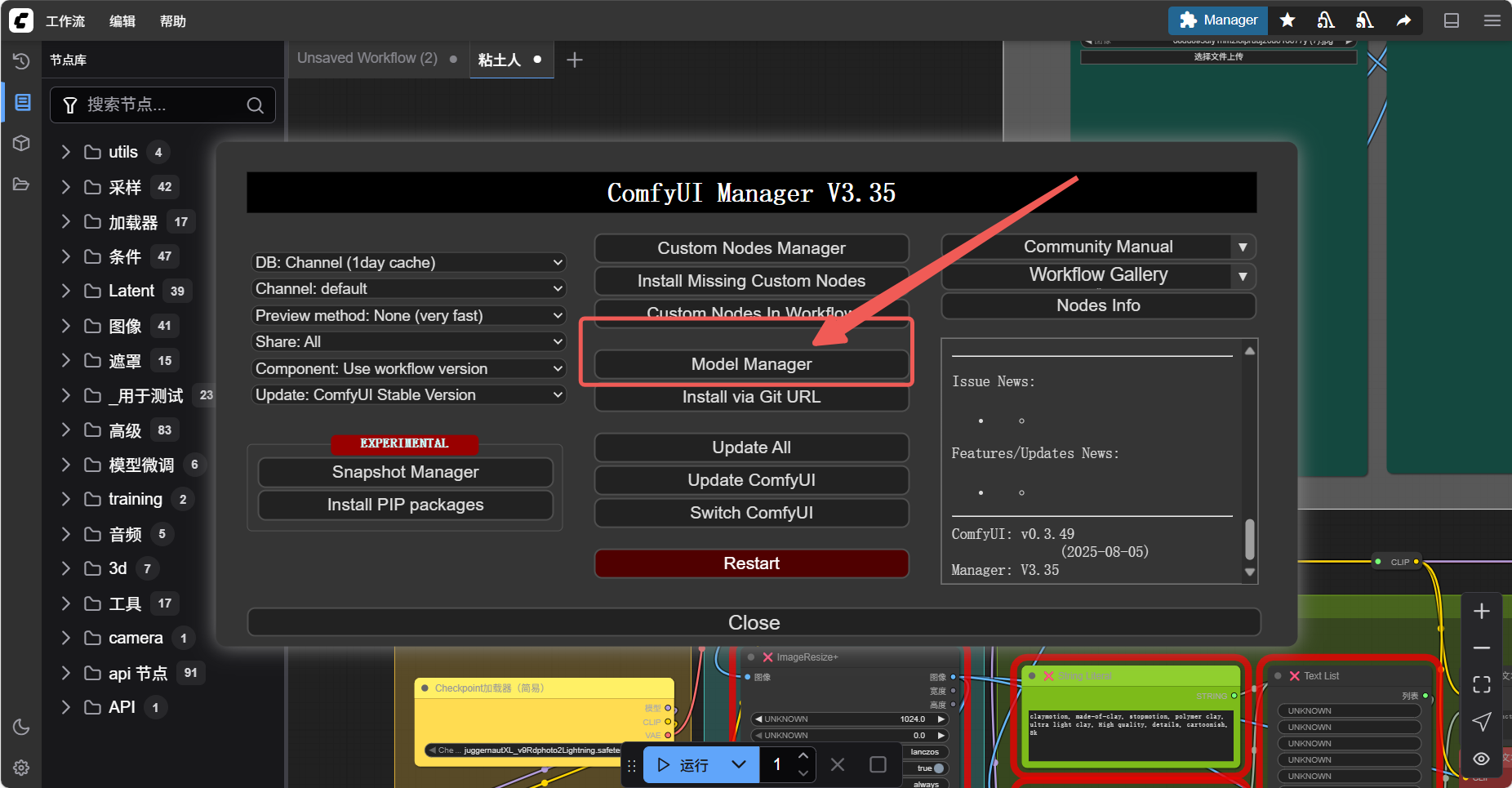
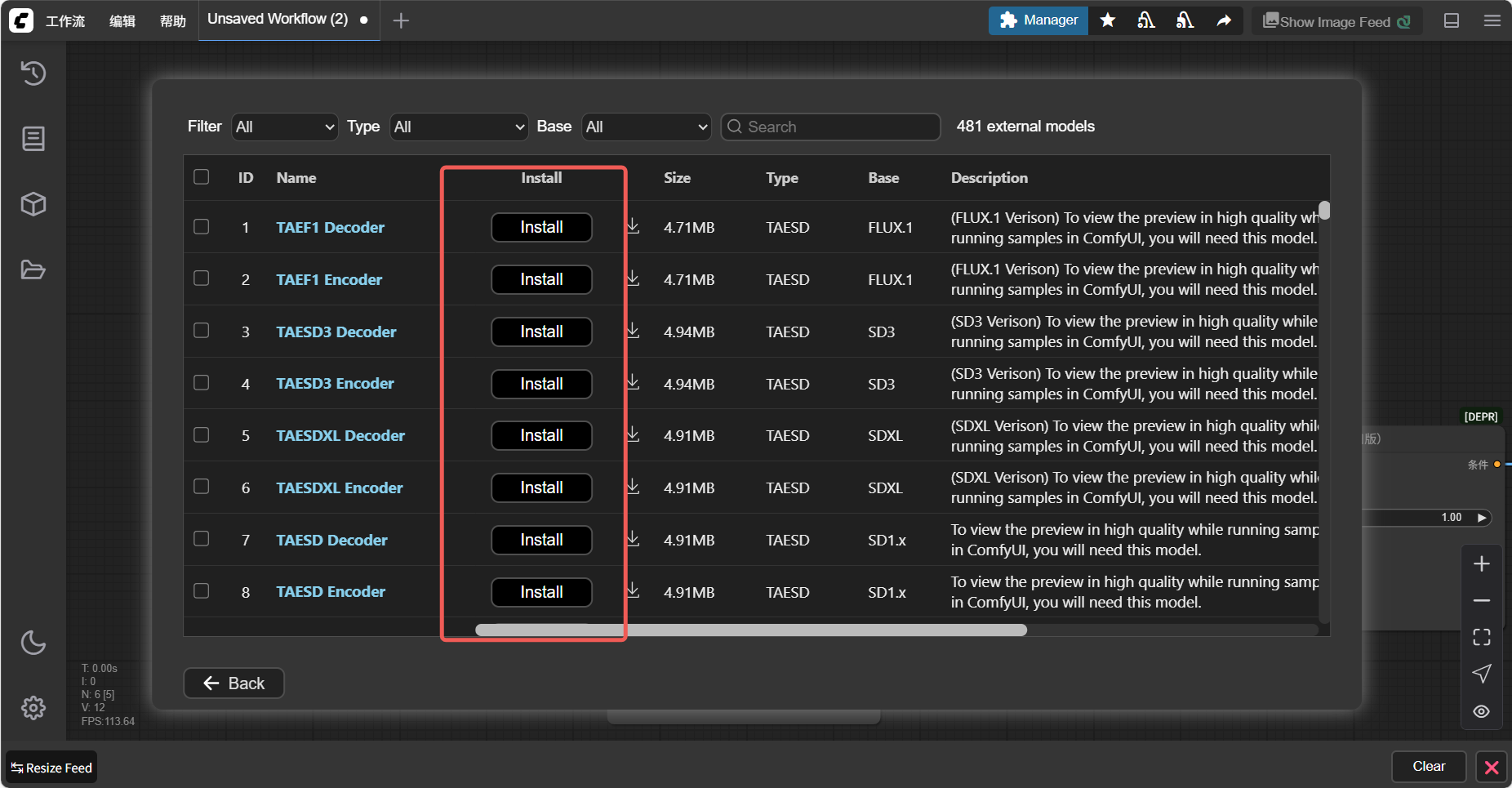
3.2 外部下载 & 导入模型
Section titled “3.2 外部下载 & 导入模型”拿 Stable Diffusion XL 举例
- 这是 Stable Diffusion 的最新版本,它在 2.0 版本的基础上进行了进一步的优化和改进。
- XL 版本的主要特点是其更大的模型大小,从 0.98B 扩大到 6.6B 参数,这使得它能够生成更高质量的图像。
- XL 版本还引入了新的功能,如更有艺术感的图像,更真实的图像,以及更清晰可读的字体等。
- 模型官方介绍:Stable Diffusion xl 1.0 press release
- 下载链接:
3.2.1 模型下载
Section titled “3.2.1 模型下载”我常用的下载渠道有两个,一个是 HuggingFace,最后一个是 CivitAI 站点。
3.2.2 HuggingFace
Section titled “3.2.2 HuggingFace”你可以将 HuggingFace 理解为 AI 届的 Github。上面会有不少人或组织会将他们的模型分享到上面。你可以通过 HuggingFace 的搜索功能来搜索你想要的模型。
比如我们搜索 Stable Diffusion v1.5,你会看到这样的页面,然后我们点击页面里的 Files and versions 按钮(图中 1),接着你会看到很多文件,此时你需要选择你需要下载的模型文件,然后点击下载按钮或者获取到下载的链接后续在节点中进行终端下载操作: git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
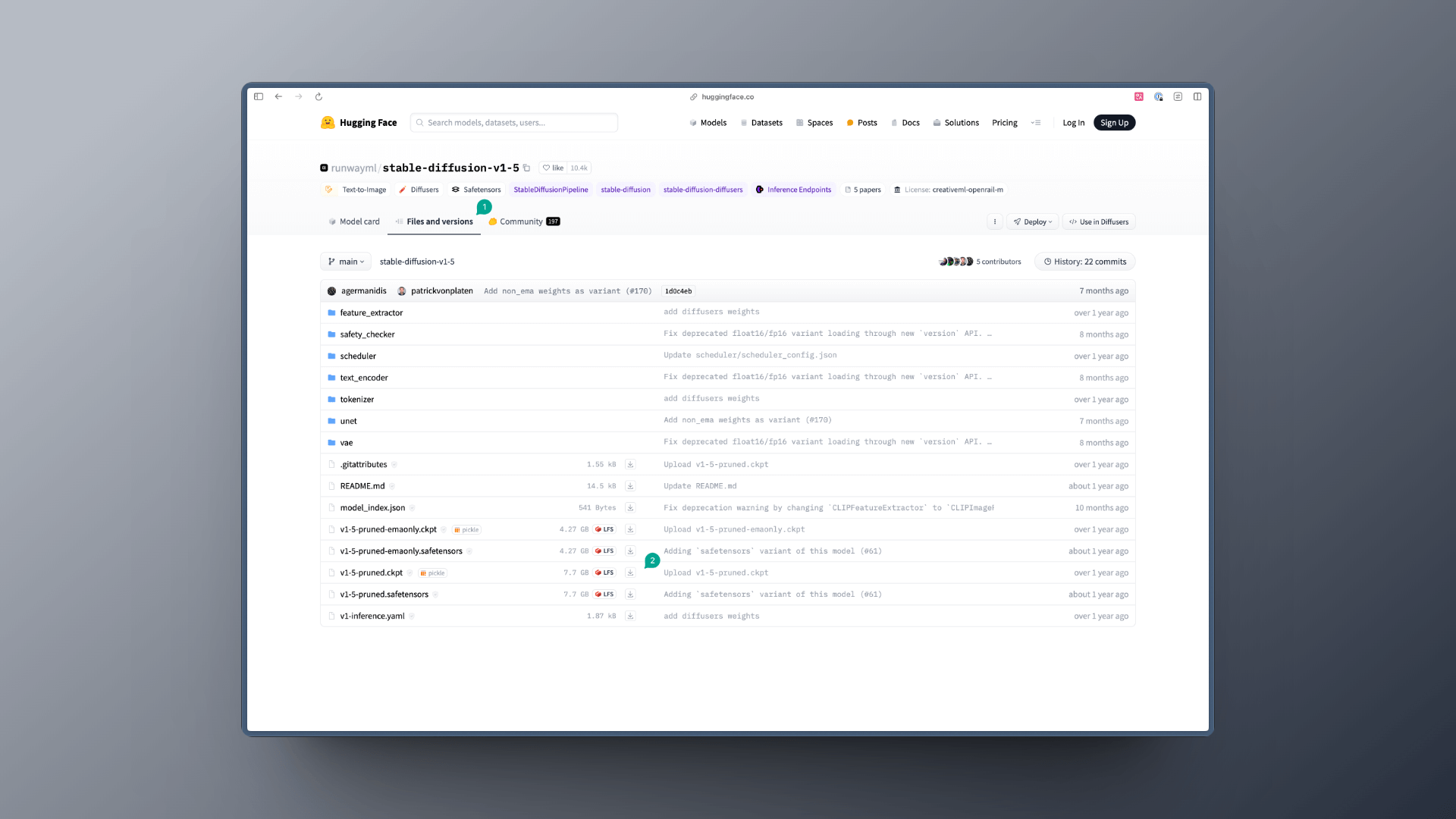
一般你会看到两种后缀的模型:
- safetensors:这种模型一般用的是 numpy 格式保存,这就意味着它只保存了张量数据,没有任何代码,加载这类文件会更安全和更快。
- ckpt:这种文件是序列化过的,这意味着它们可能会包含一些恶意代码,加载这类模型就可能会带来安全风险。
所以在上述的案例中,我会推荐你下载 safetensors 格式的模型。
另外,我建议你在搜索模型的时候,需要看看是不是该模型的官方发的,一般我会看模型的下载数,一般下载数越多的模型,越有可能是官方发的。
3.2.3 CivitAI
Section titled “3.2.3 CivitAI”与 HuggingFace 不同,CivitAI 站点更偏向于 UGC 一些,所以你会看到更多个人训练的模型,但是这并不意味着它们的质量会差,相反,你会发现有些模型的质量非常好。
而且 CivitAI 比 HuggingFace 多了很多好用的功能,比如你可以通过筛选等方式,看到各种各样优秀的模型:
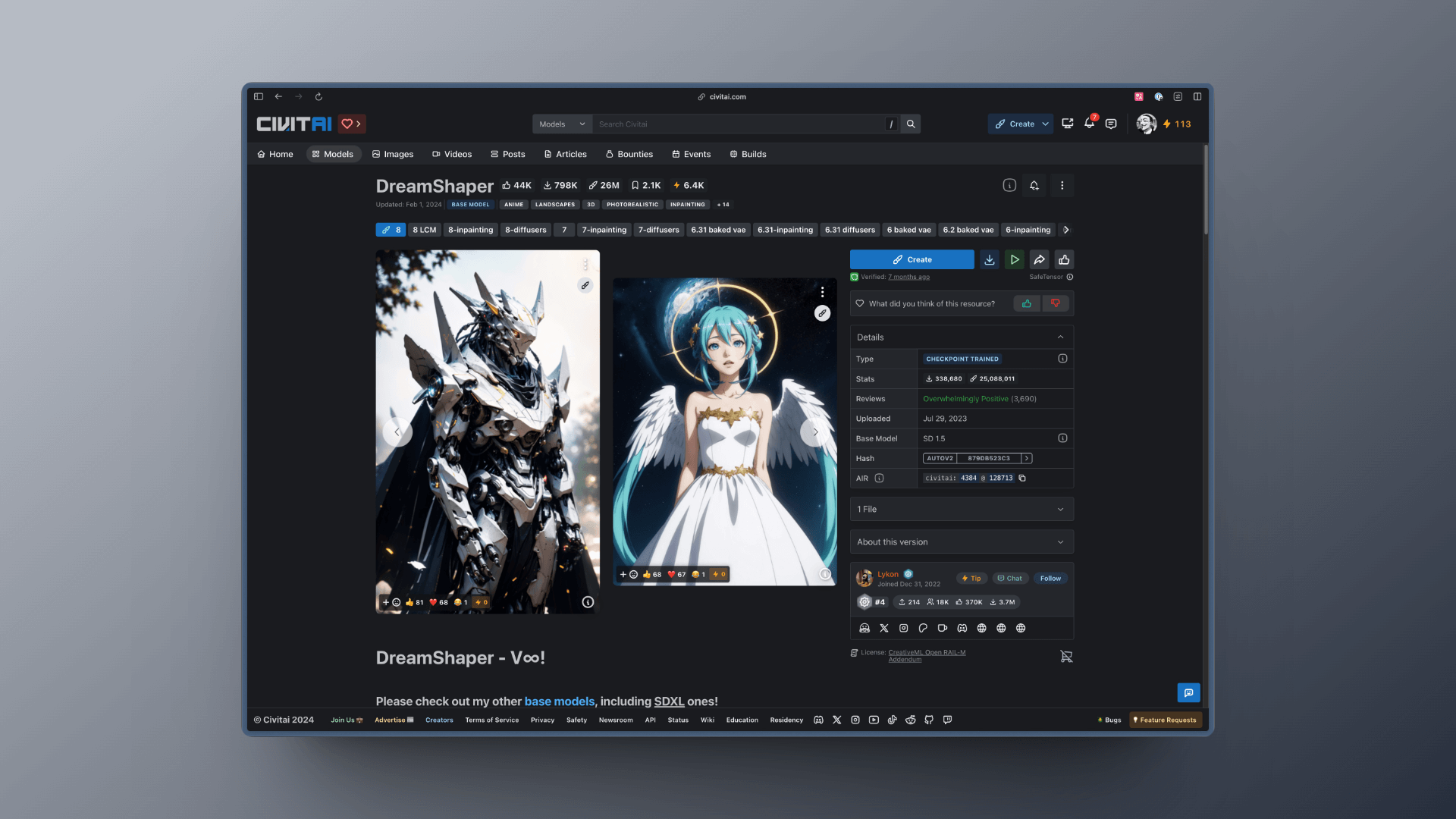
同样的,你也可以通过 CivitAI 的搜索功能来搜索你想要的模型,并下载该模型,以 DreamShaper 为例,你只要点击下载按钮即可下载模型:
3.2.4 模型下载导入镜像
Section titled “3.2.4 模型下载导入镜像”在获取到模型下载地址后,我们需要将模型通过指令下载到 ComfyUI 的 models 目录下,这样 ComfyUI 才能够加载到对应的模型。
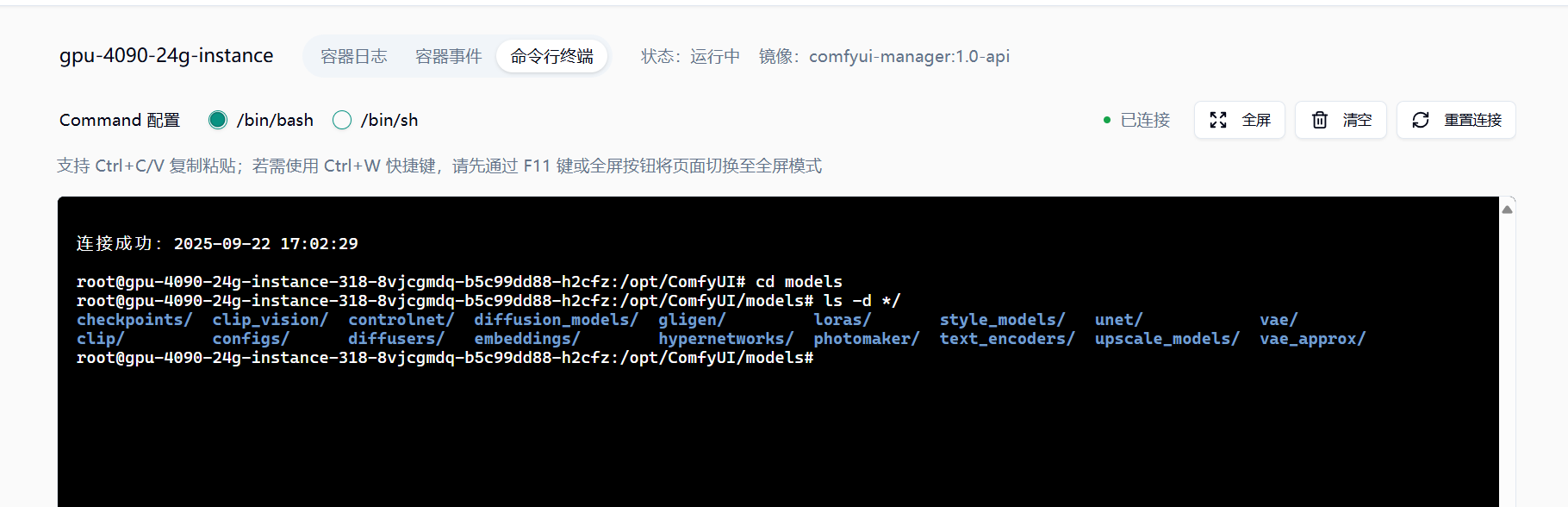
示例指令:git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
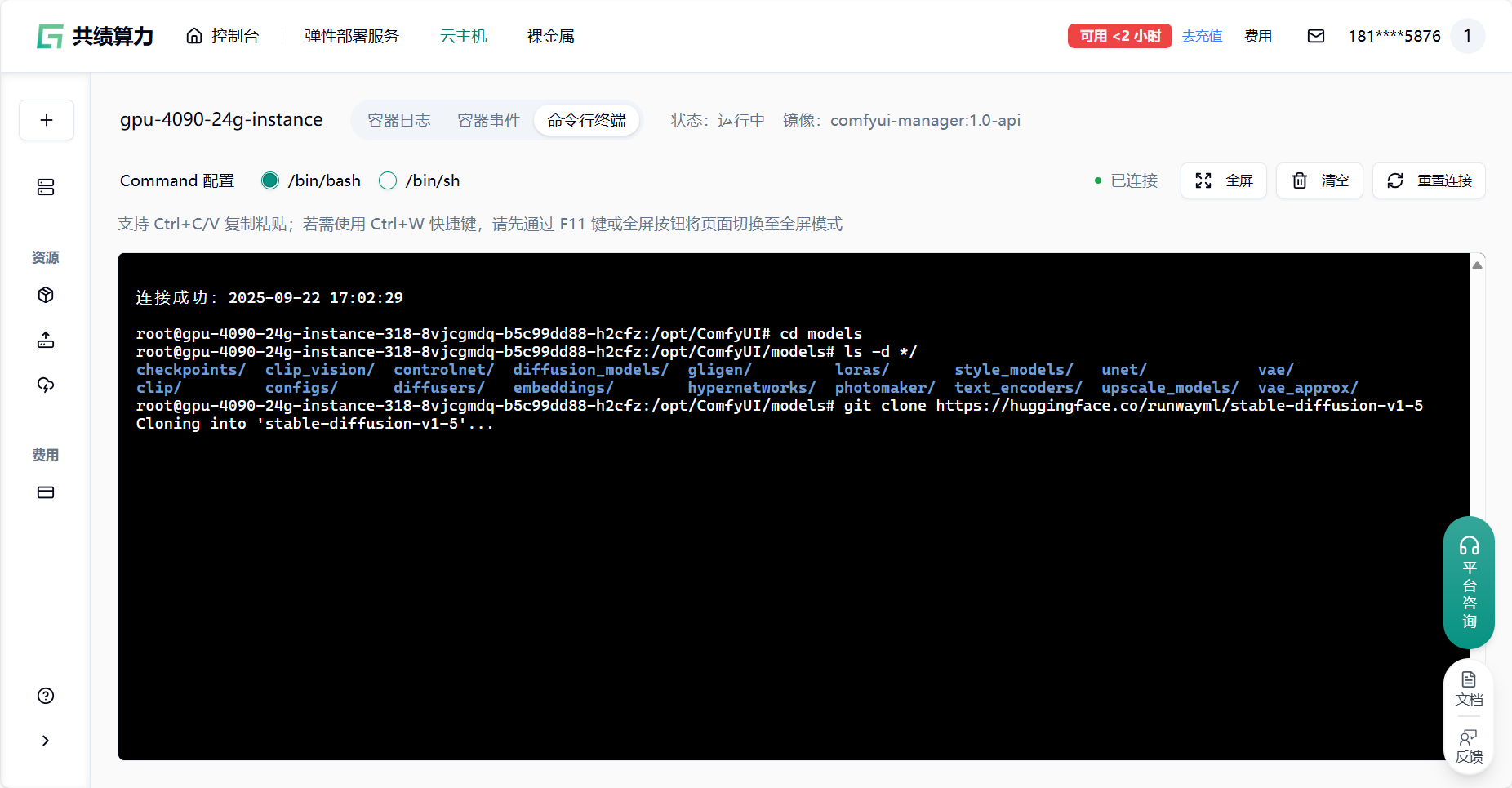
不同的模型下载在不同的文件夹下
二、通过 Dockerfile 构建自定义镜像(进阶方案)
Section titled “二、通过 Dockerfile 构建自定义镜像(进阶方案)”这里从 0-1 起步构建一个 WAN2.2 镜像为示例:
1.工具准备
Section titled “1.工具准备”一台电脑,稳定的网络环境
2.准备 Dockerfile 文件
Section titled “2.准备 Dockerfile 文件”-
找一个合适的位置新建“comfyUI_WAN2.2”文件夹,并打开
-
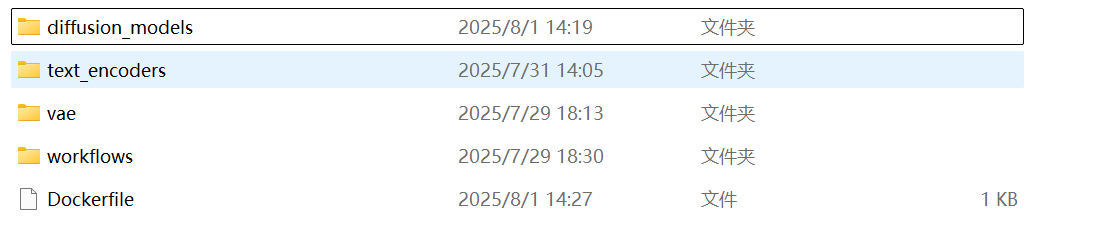
在“comfyUI_WAN2.2”中分别新建“diffusion_models”、“text_encoders”、“vae”、“workflow”文件夹
-
在“comfyUI_WAN2.2”新建文本文档,命名为 Dockerfile(注意删去文件后缀)
最终应与下图一致
- 打开 Dockerfile 文件,直接粘贴以下代码
FROM ghcr.io/saladtechnologies/comfyui-api:comfy0.3.45-api1.9.2-torch2.7.1-cuda12.8-runtime
ENV COMFYUI_PORT=8188 \ MODEL_DIR=/opt/ComfyUI/models \ BASE=""
RUN mkdir -p ${MODEL_DIR}/{loras,vaes,text_encoders,diffusion_models}
COPY diffusion_models/*.safetensors ${MODEL_DIR}/diffusion_models/COPY vae/*.safetensors ${MODEL_DIR}/vae/COPY text_encoders/*.safetensors ${MODEL_DIR}/text_encoders/
COPY workflows/*.json /opt/ComfyUI/user/default/workflows/
EXPOSE ${COMFYUI_PORT}3.Hugging face 相关准备
Section titled “3.Hugging face 相关准备”- 登录https://huggingface.co官网,点击右上角 Sign Up 注册账号
- 登录后点击右上角头像,点击“Access Tokens”
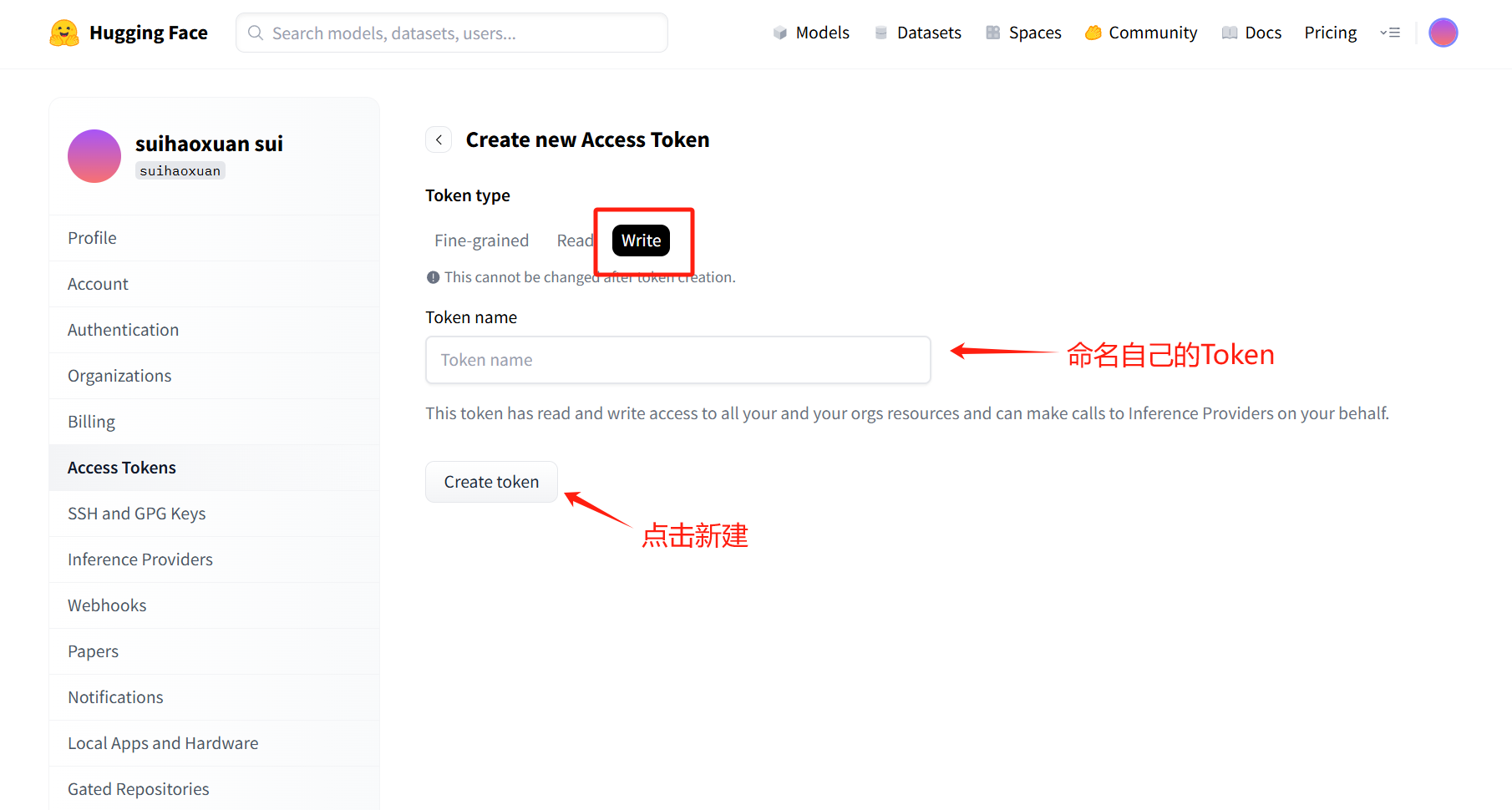
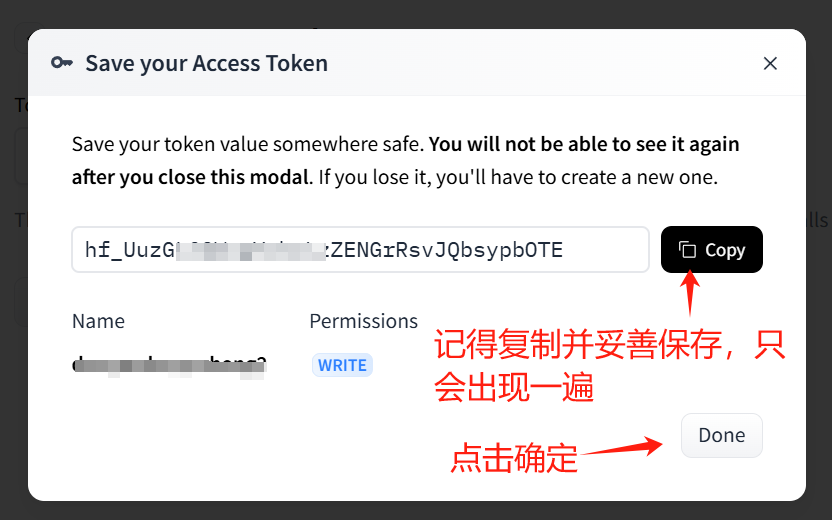
- 点击 creat new token,之后选择 write,创建新 token,记得复制并保存
4.直接下载模型文件
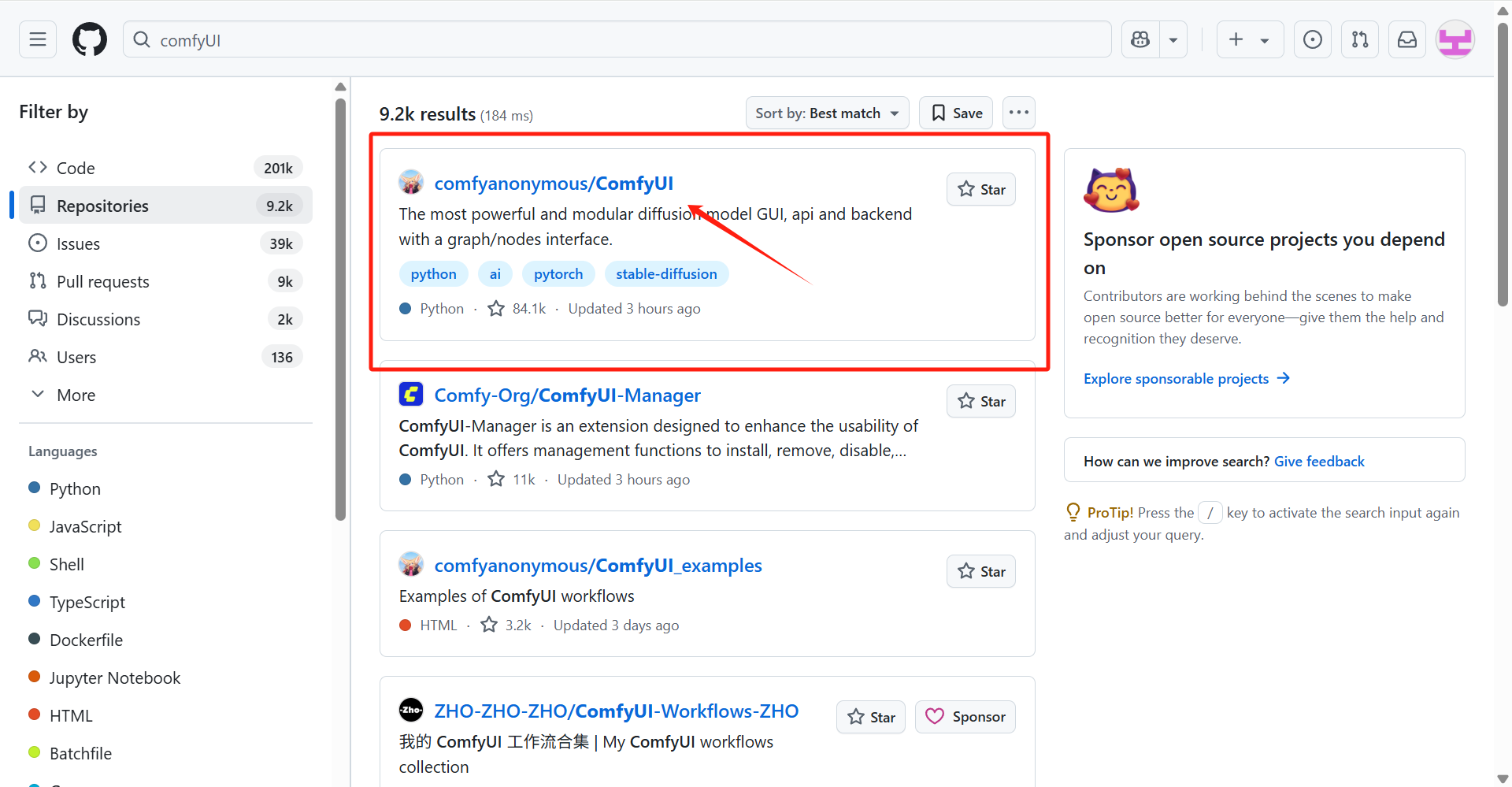
Section titled “4.直接下载模型文件”- 打开 github 官网 https://github.com/(需要登录),搜索`comfyUI`,点击
comfyanonymous/ComfyUI
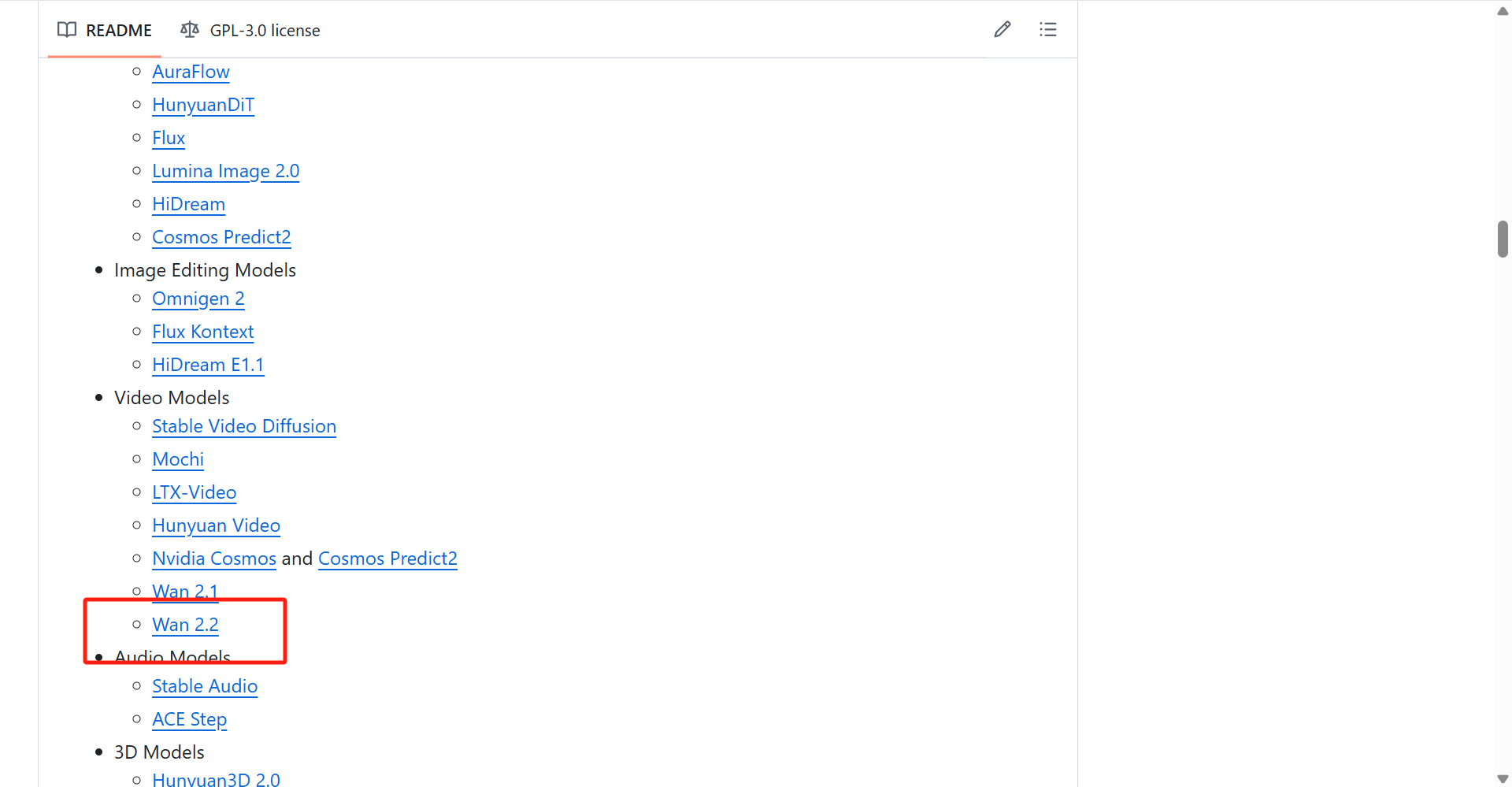
- 点开后向下翻,找到,点击Wan 2.2
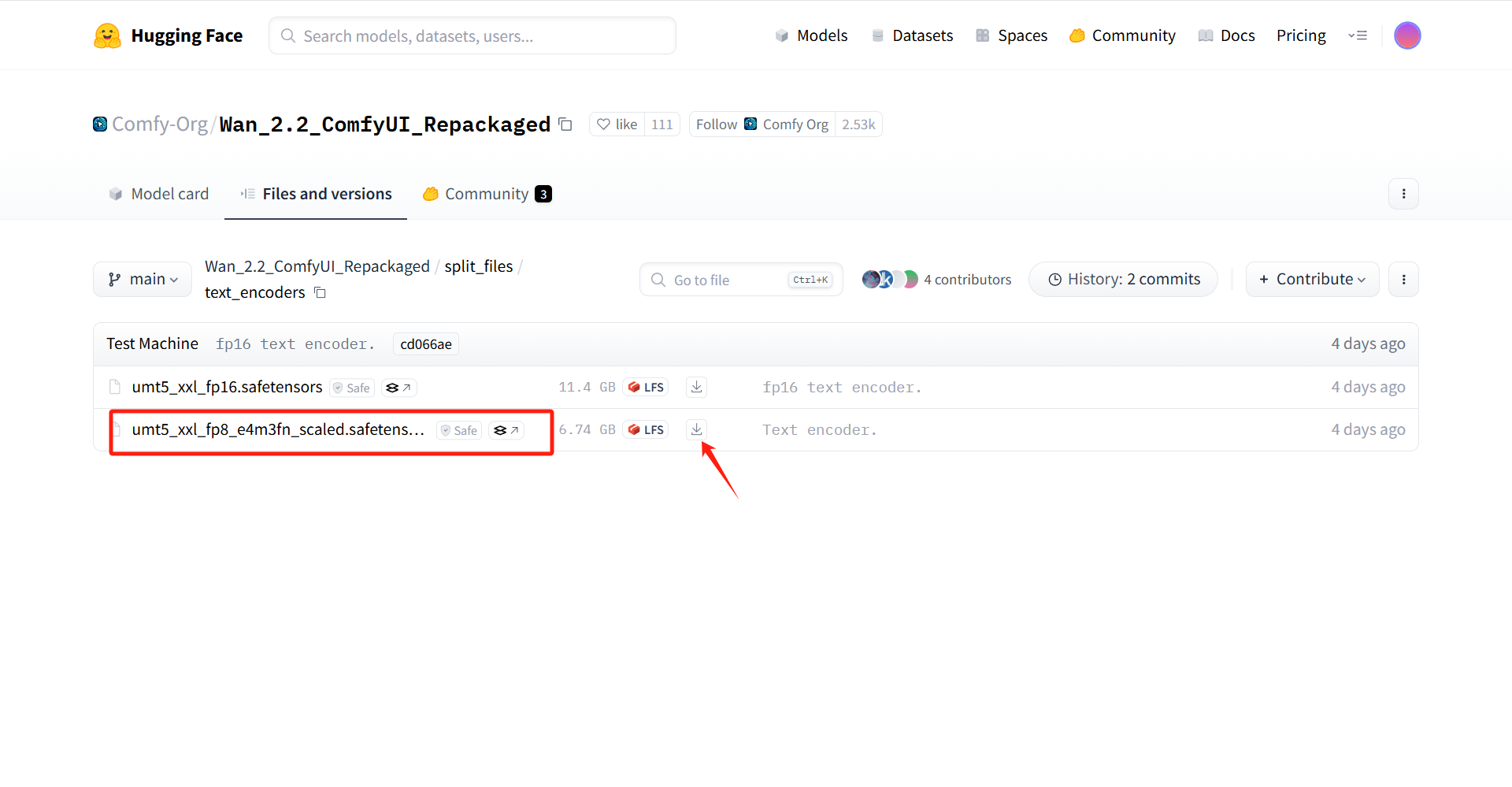
- 在 Files to Download 一栏中我们需要下载以下两个文件(点击链接,跳转到新页面之后,点击 Download 即可下载)
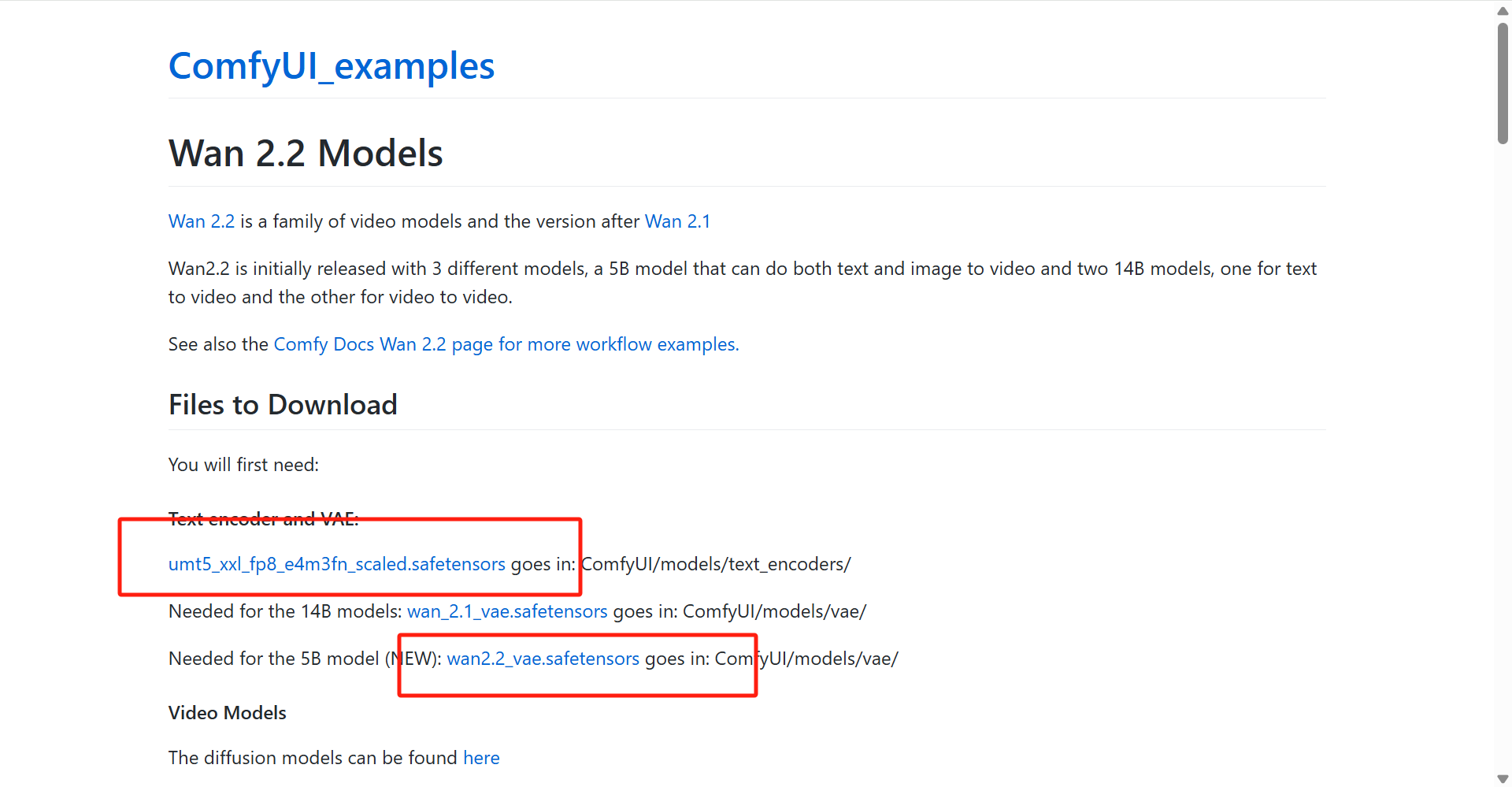
需注意的是“umt5_xxl_fp8_e4m3fn_scaled.safetensors”中有两个文件,下载 fp8 的那个
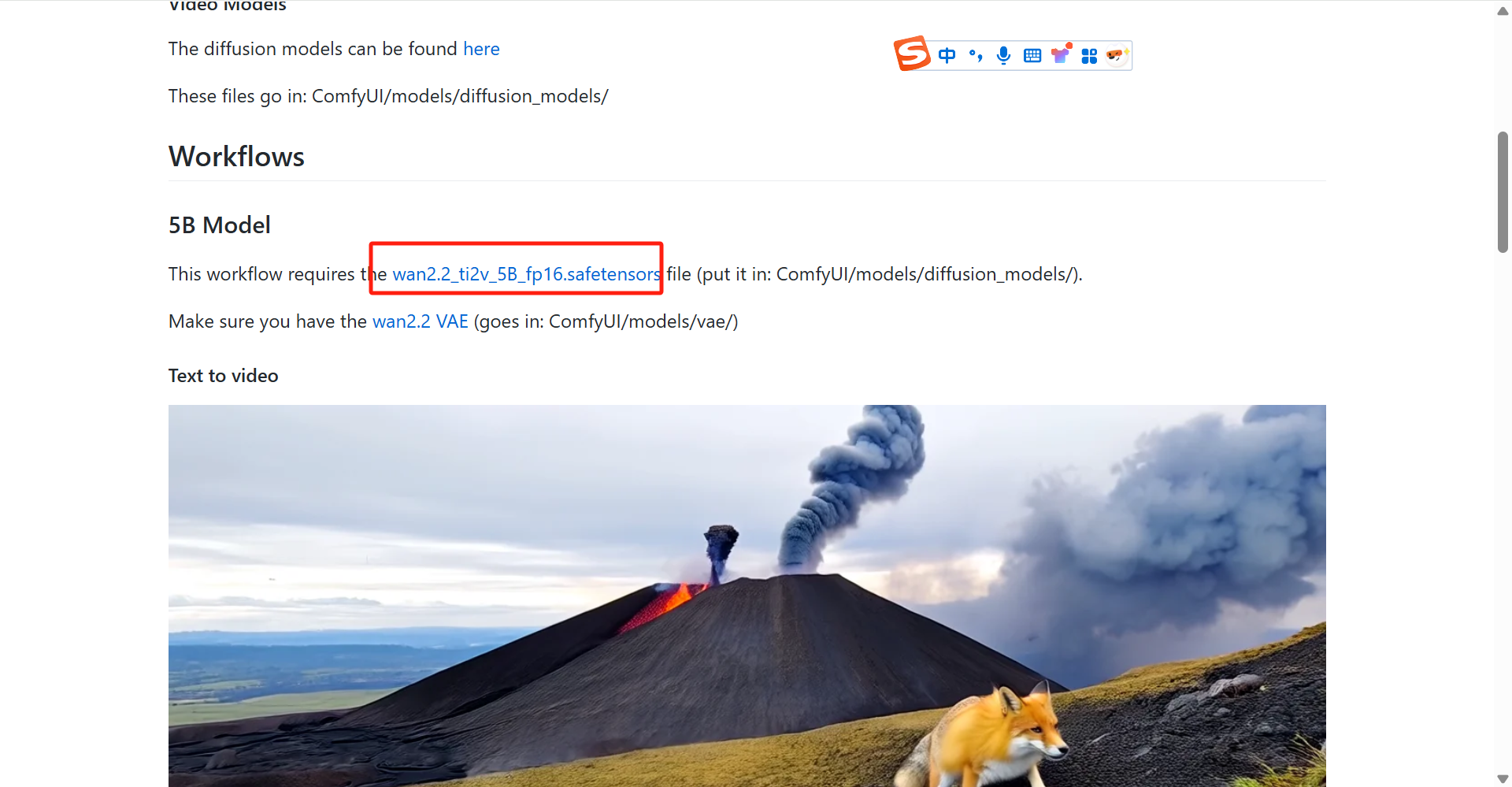
- 之后页面下翻,找到“wan2.2_ti2v_5B_fp16.safetensors”,点击进入并点击 Download 下载
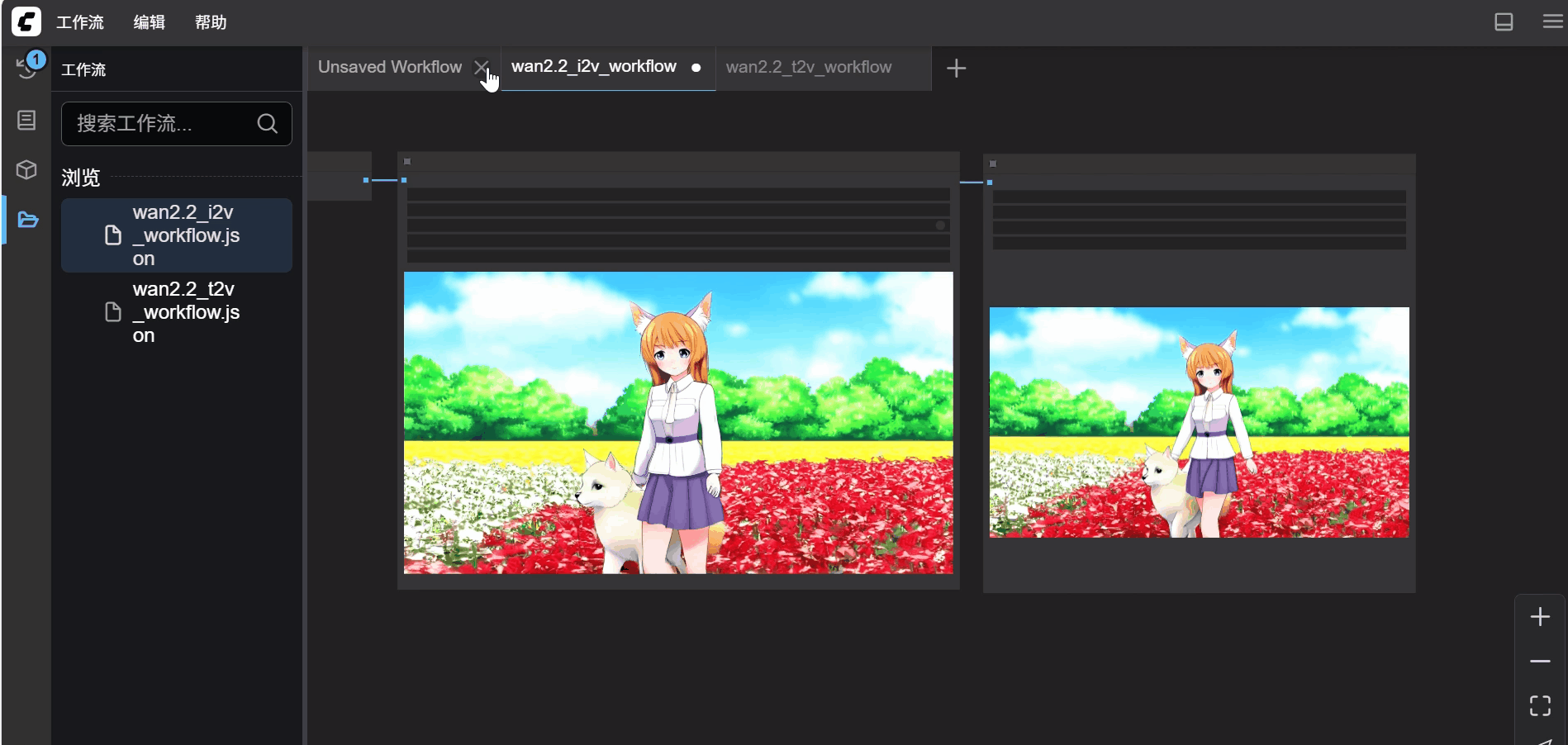
- 继续下翻,找到 Workflow in Json format 点击进入,复制页面全部内容
- 在“workflow”文件夹中创建一个文本文档,改名为
wan2.2_t2v_workflow.json注意后缀必须是.json,点开文档,复制以上内容 - 页面继续下翻,在 Image to Video 下还有一个Workflow in Json format,同理创建一个
wan2.2_i2v_workflow.json文档,最终结果如下
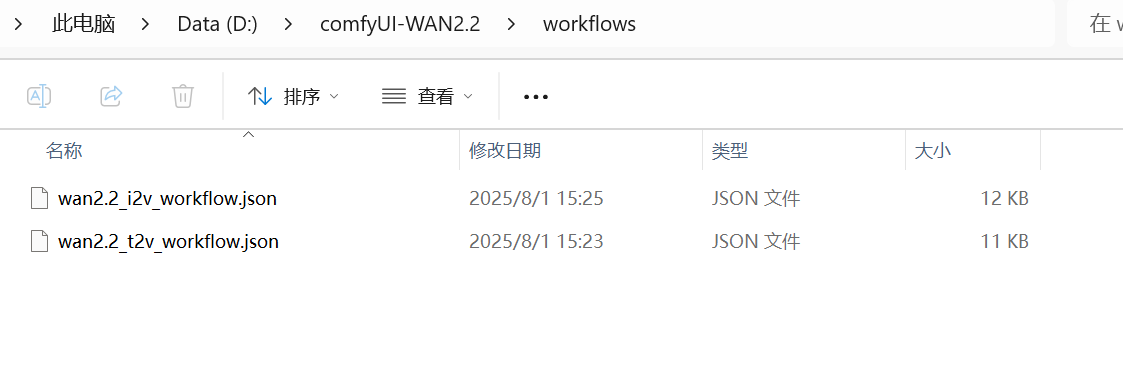
- 将下载的模型文档移动到相应文件夹
wan2.2_ti2v_5B_fp16.safetensors移动到“diffusion_models”文件夹wan2.2_vae.safetensors移动到“vae”文件夹umt5_xxl_fp8_e4m3fn_scaled.safetensors移动到“text_encoders”文件夹
- 最终效果如下:
comfyUI_WAN2.2/├── diffusion_models/│ └── wan2.2_ti2v_5B_fp16.safetensors├── text_encoders/│ └── umt5_xxl_fp8_e4m3fn_scaled.safetensors├── vae/│ └── wan2.2_vae.safetensors├── workflow/│ ├── wan2.2_i2v_workflow.json│ └── wan2.2_t2v_workflow.json└── Dockerfile5.通过 Hugging face 镜像站下载模型文件
Section titled “5.通过 Hugging face 镜像站下载模型文件”(可加快下载速度,提高效率)
- 准备 Hugging face 镜像站
- 通过 Win+S 搜索 PowerShell 或 CMD,右键选择“以管理员身份运行”(避免权限问题)
- 输入
pip install -c conda-forge huggingface_hub,回车 - 等待下载
- 下载模型文件
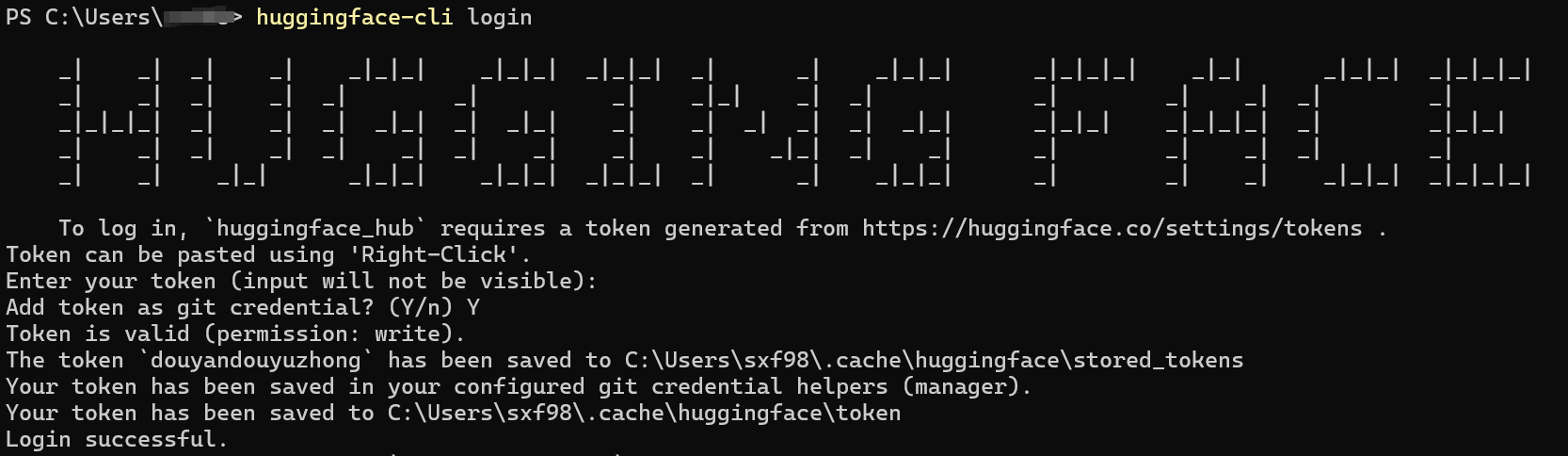
- 在 PowerShell 中输入
$env:HF_ENDPOINT="https://hf-mirror.com",临时配置镜像站

- 继续在 PowerShell 中输入
huggingface-cli login,输入之前复制并保存的自己的 Token,完成登录
- 分别下载所需模型文件,并放置到相关路径,可通过以下代码完成
完成 huggingface-cli download <name> --repo-type model --local-dir "address" --local-dir-use-symlinks False --resume-download#其中<name>为所需模型文件名称,address 应替换为对应文件夹地址6.执行构建
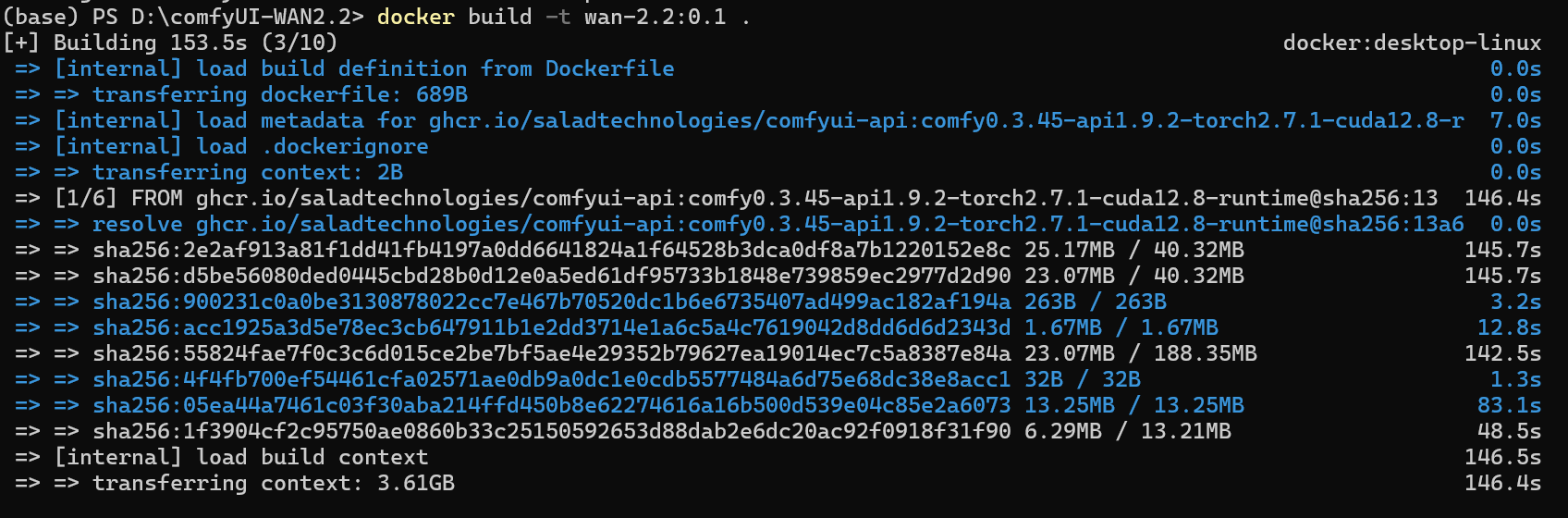
Section titled “6.执行构建”- 打开 Docker Desktop
- 打开“comfyUI_WAN2.2”文件夹,在空白处单机鼠标右键,选择“在终端打开”,打开控制台
- 输入
docker build -t wan-2.2:0.1 .(可根据需要自行修改标签和镜像名),回车,等待即可
(过程中的一些图片)
- 操作完成后可在 docker 中查看,或在 powershell 中输入
docker images查看

三、直接在共绩算力预制镜像中补充节点
Section titled “三、直接在共绩算力预制镜像中补充节点”1 在云主机上部署 WAN2.2
Section titled “1 在云主机上部署 WAN2.2”我们提供了构建完毕的 WAN2.2 镜像,您可以直接部署使用。
镜像地址:harbor.suanleme.cn/last1/wan-2.2:0.2
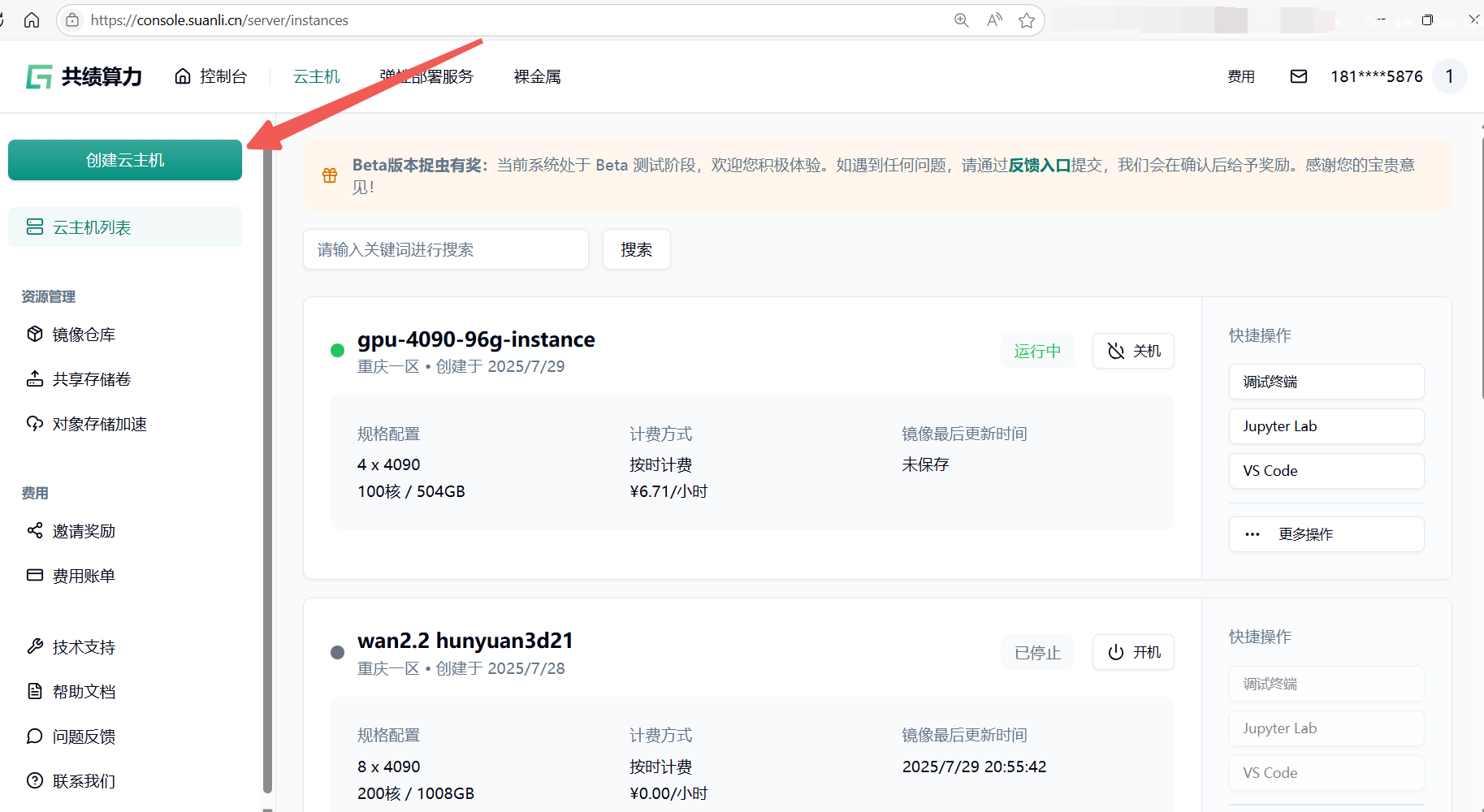
1.1 访问云主机控制台 https://console.suanli.cn/server/instances,点击创建云主机
1.2 基于自身需要进行配置,参考配置为单卡 4090 和 1 个节点(初次使用进行调试)。
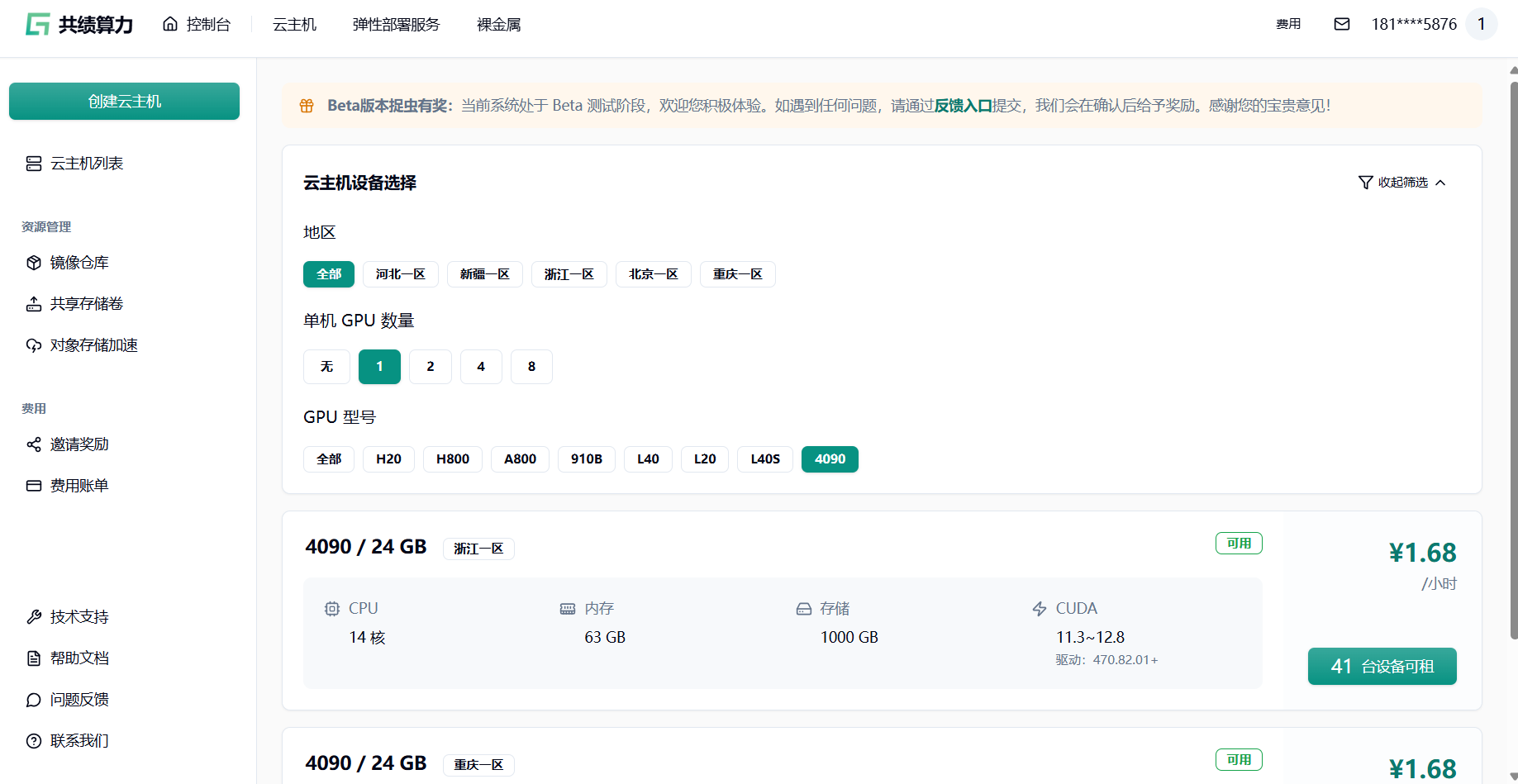
1.3 在我的镜像中填入完整镜像 url
镜像地址:harbor.suanleme.cn/last1/wan-2.2:0.1
添加端口:8188
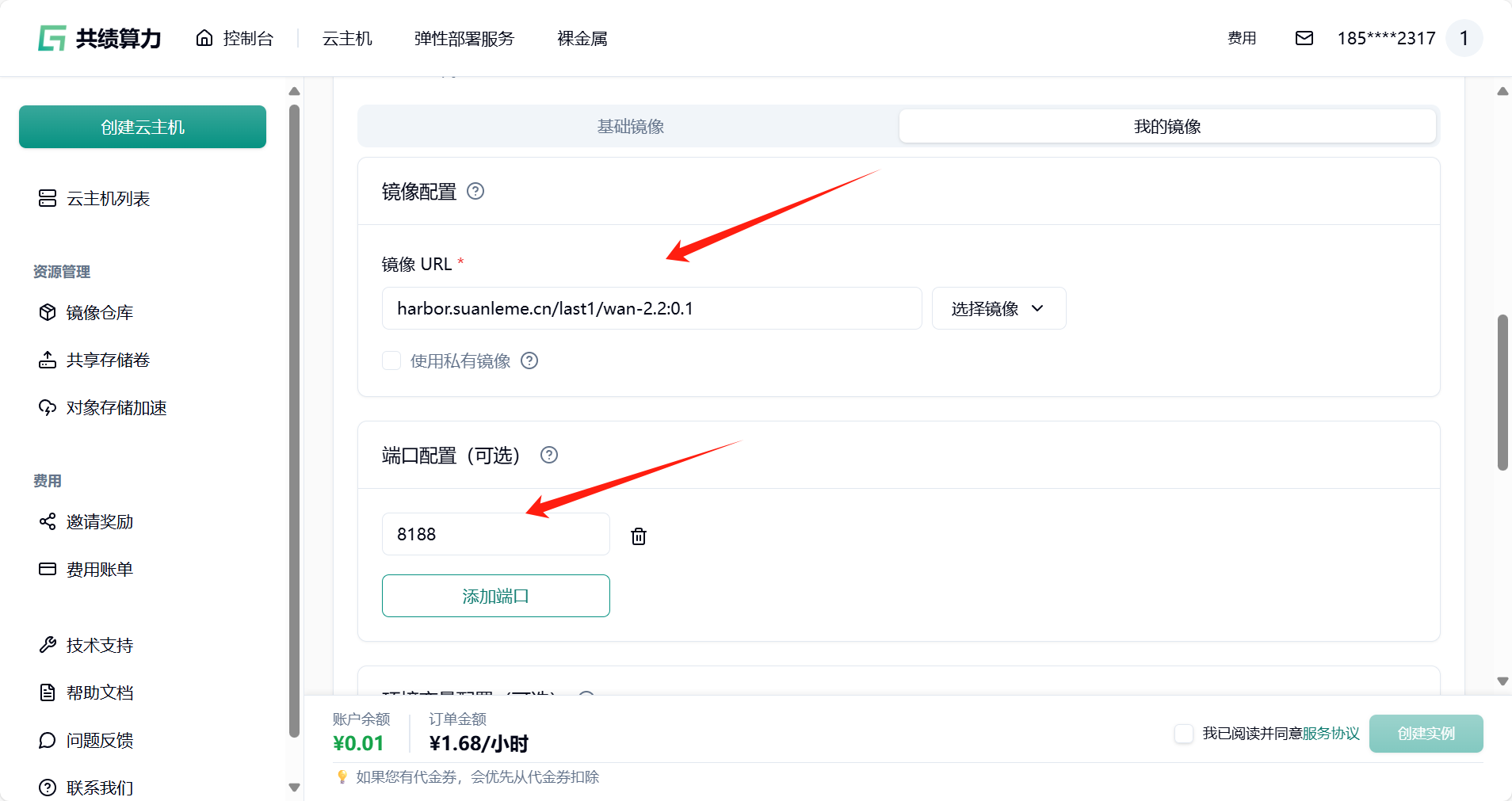
1.4 点击部署服务,耐心等待节点拉取镜像并启动。
1.5 节点启动后,你所在“任务详情页”中看到的内容可能如下:
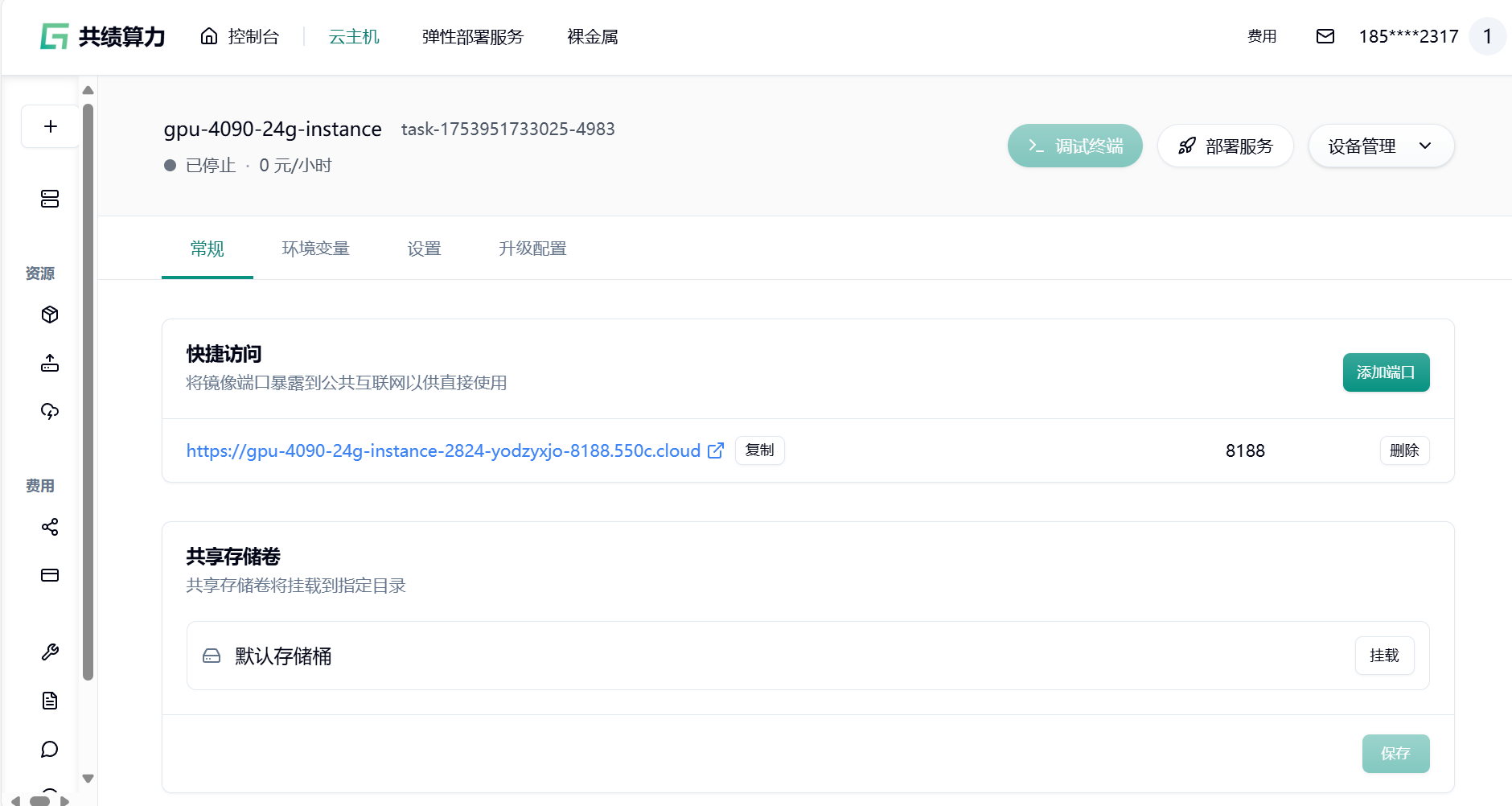
1.6 我们可以点击快速访问下方“8188”端口的链接,测试 comfyui 部署情况
系统会自动分配一个可公网访问的域名,点击 8188 端口的链接。接下来我们即可自由地通过使用工作流在 comfyui 中使用 WAN2.2 模型进行图像生成。
2 对 WAN2.2 新增节点
Section titled “2 对 WAN2.2 新增节点”通过对 wan2.2 工作流的调整,可提高成果质量,根据个人需求新增节点即可,以下展示一种简单的去噪方法作为示范:
- 进入 8188 端口的 web ui 界面,选择左侧的“工作流“菜单,找到名为”wan2.2_i2v_workflow.json“的工作流文件,鼠标双击进行插入。
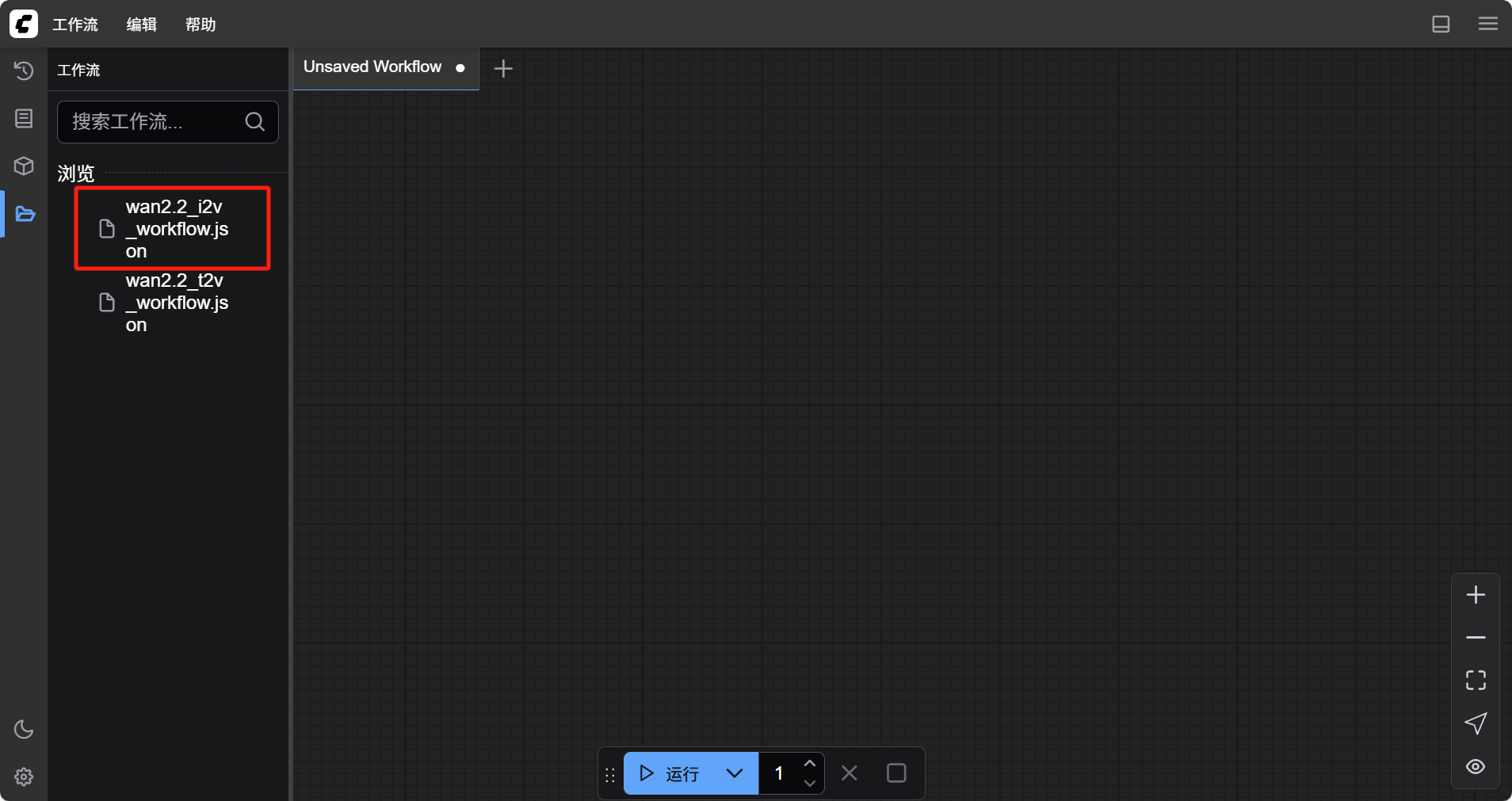
- 在空白处右键,找到“添加节点”中的“采样”,选择“k 采样器”
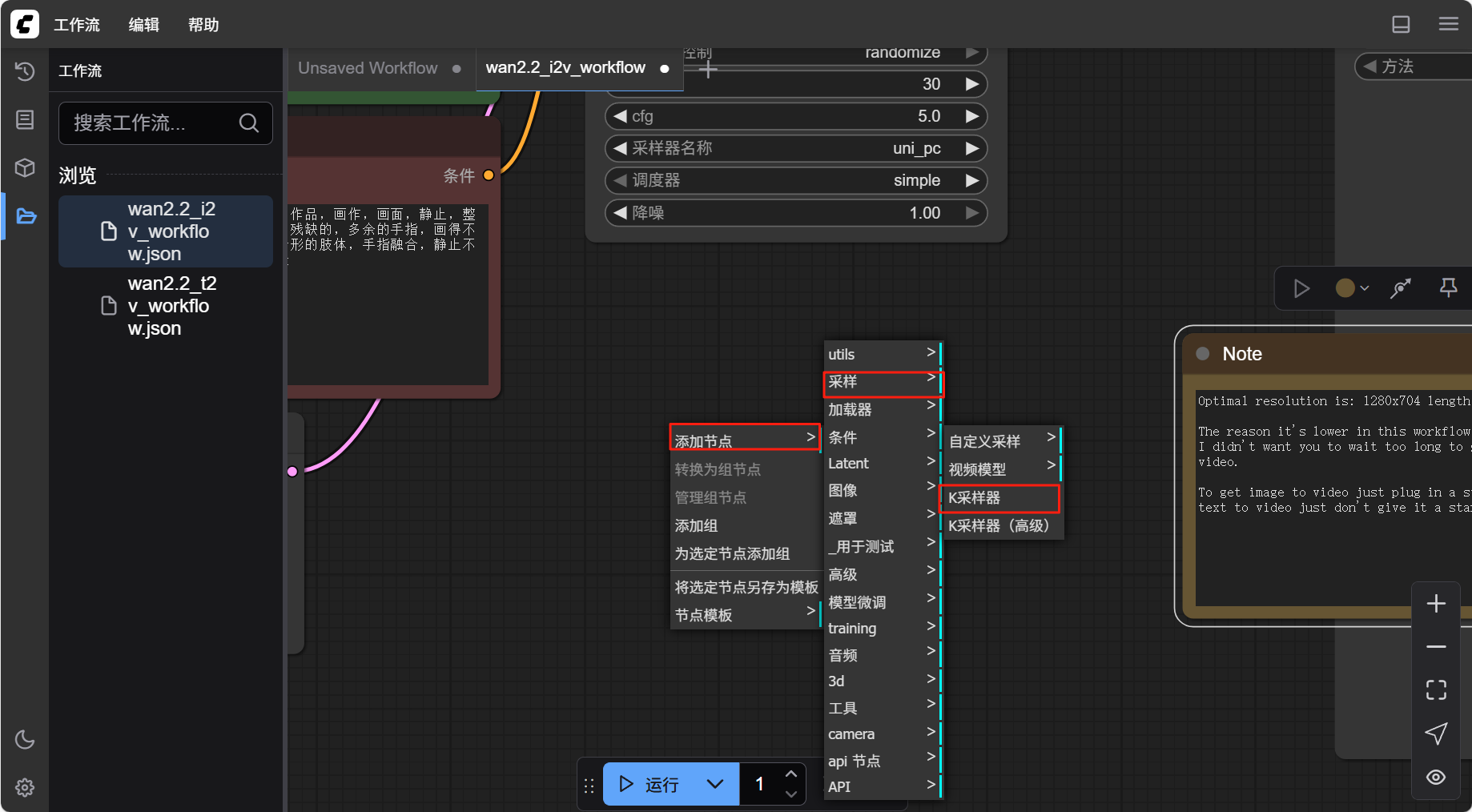
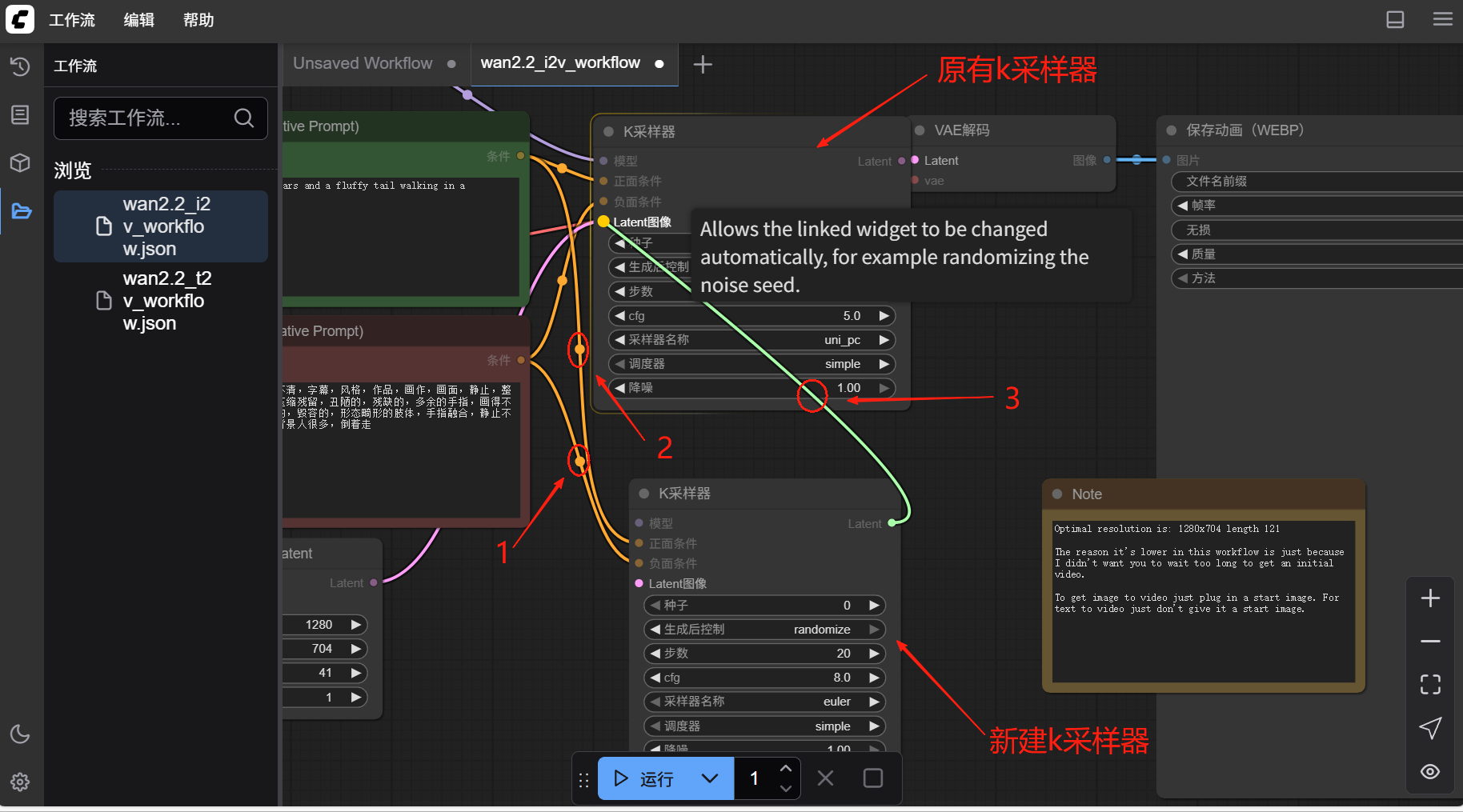
- 如图所示与前后对应节点完成连接(三处)
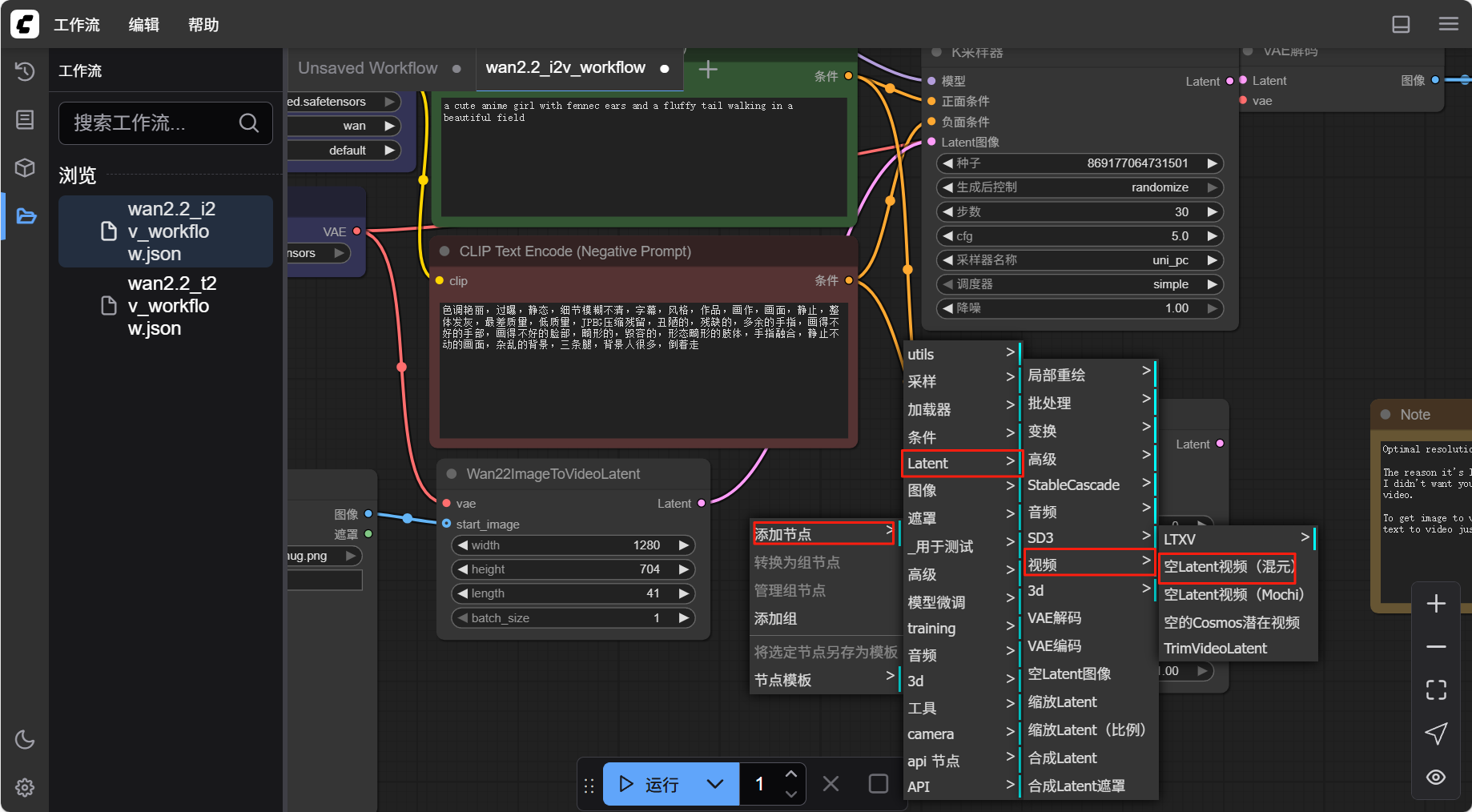
- 在空白处点击鼠标右键,选择“添加节点”中“Latent”中“视频”下的“空 Latent 视频(混元)”,并将其连接到新建的“k 采样器”
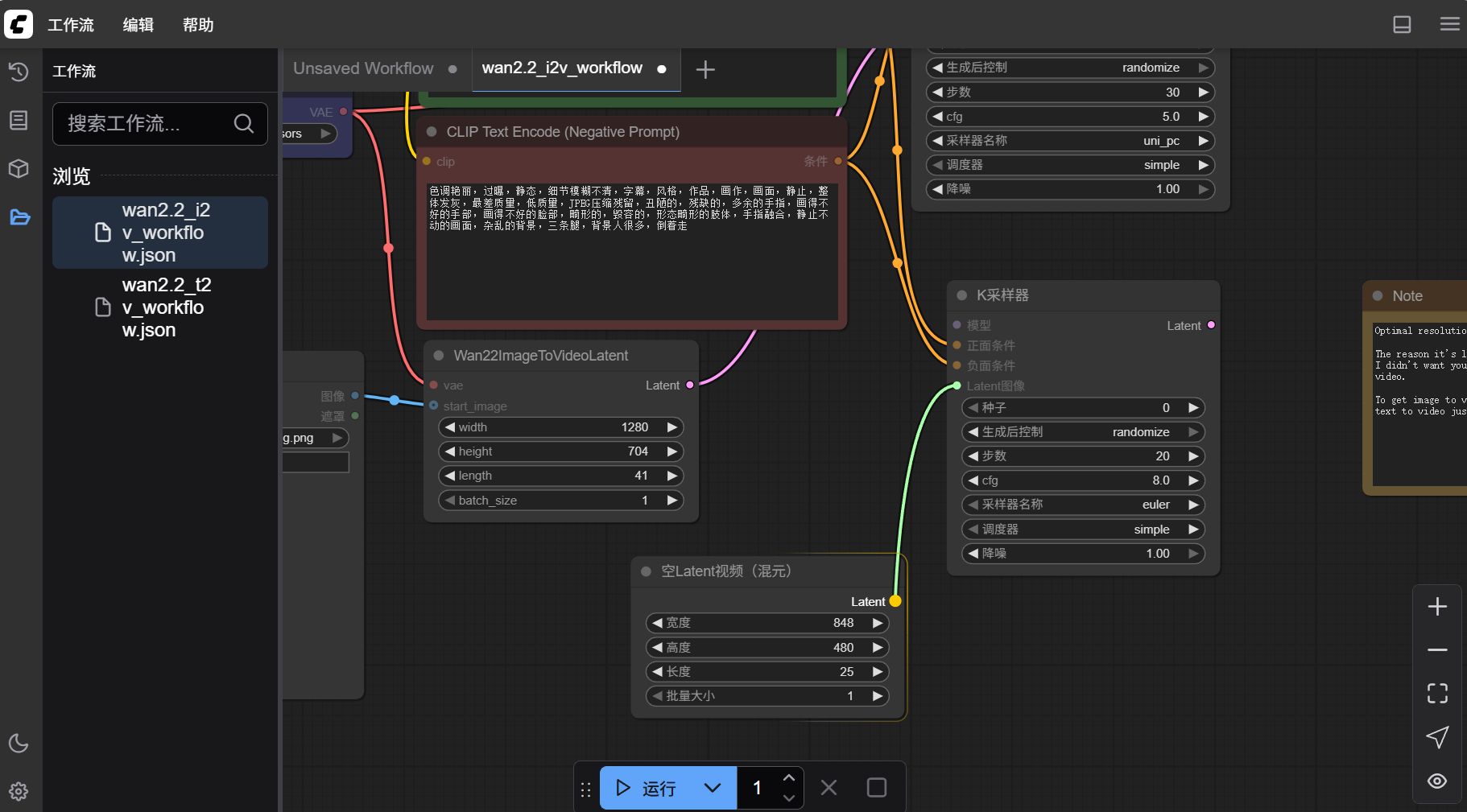
- 这样这个文生视频工作流就得到了进一步的完善,点击“运行”即可对其进行测试
3 打包镜像
Section titled “3 打包镜像”可通过重新部署服务,发布为一个新的镜像,转换为弹性部署服务,方便下次使用
(在完成下列操作前,需在共绩算力平台创建个人镜像仓库,具体步骤查看镜像仓库文档)
- 回到云主机页面,找到“部署服务”
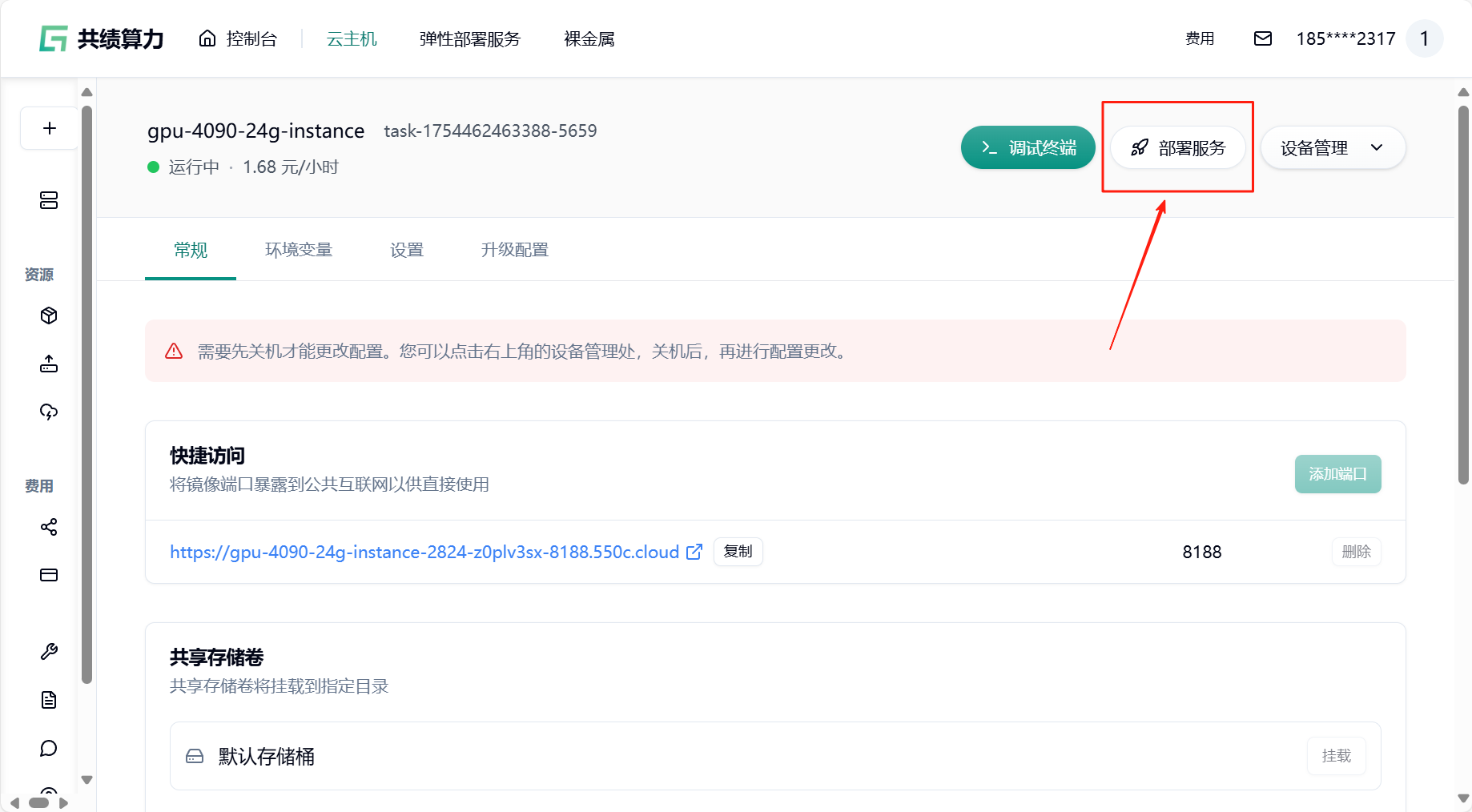
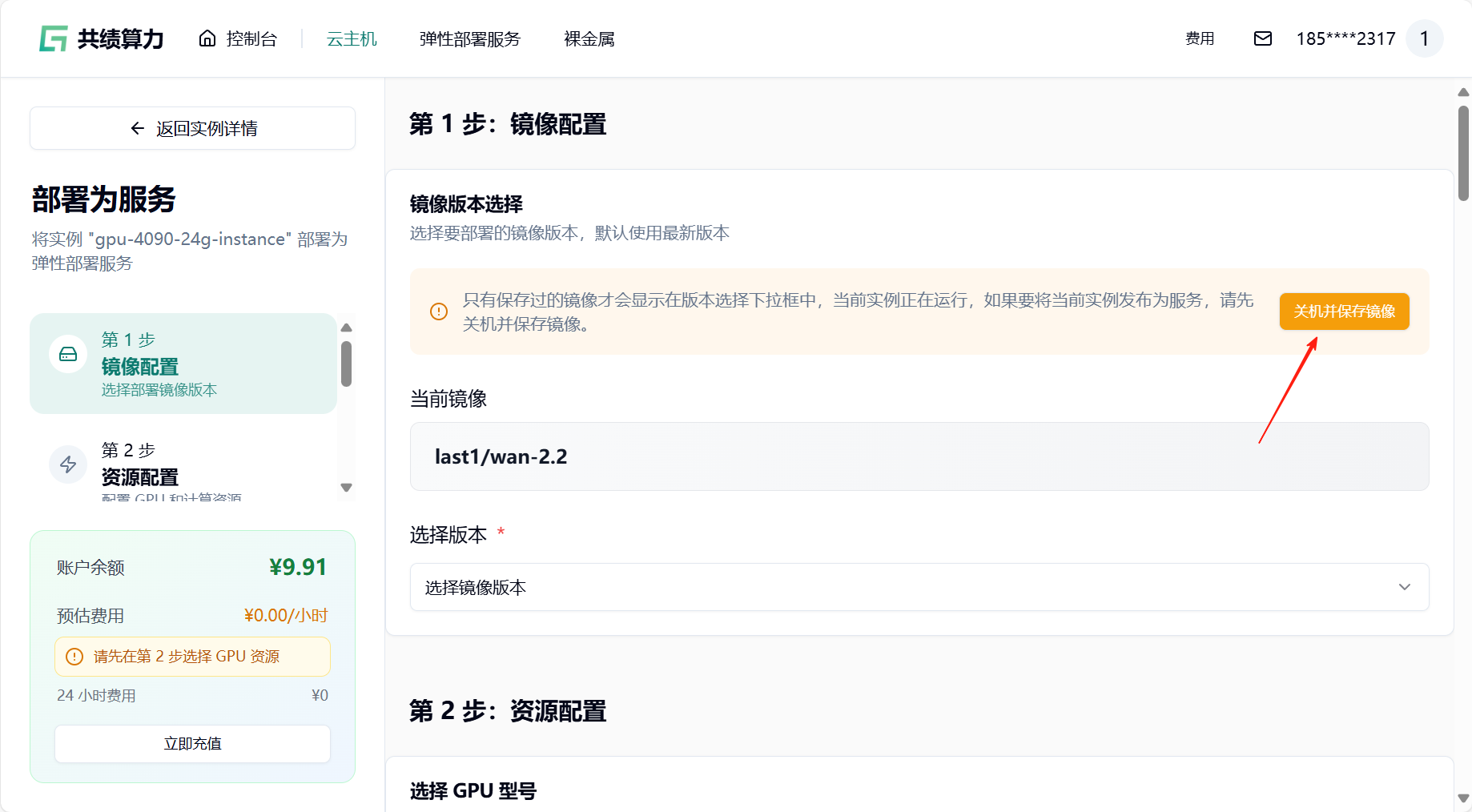
- 关机并保存镜像,输入镜像标签
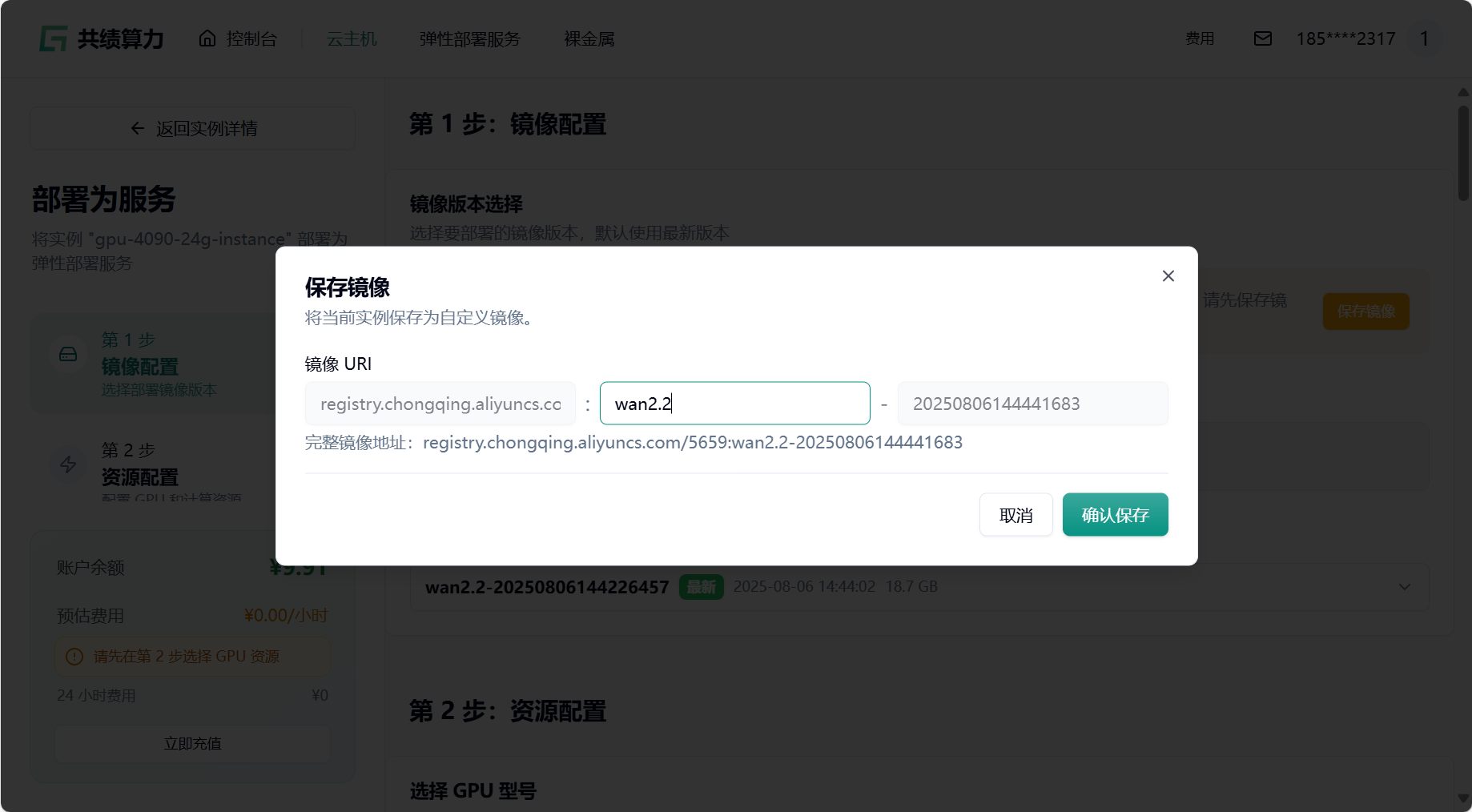
- 选择最新版本
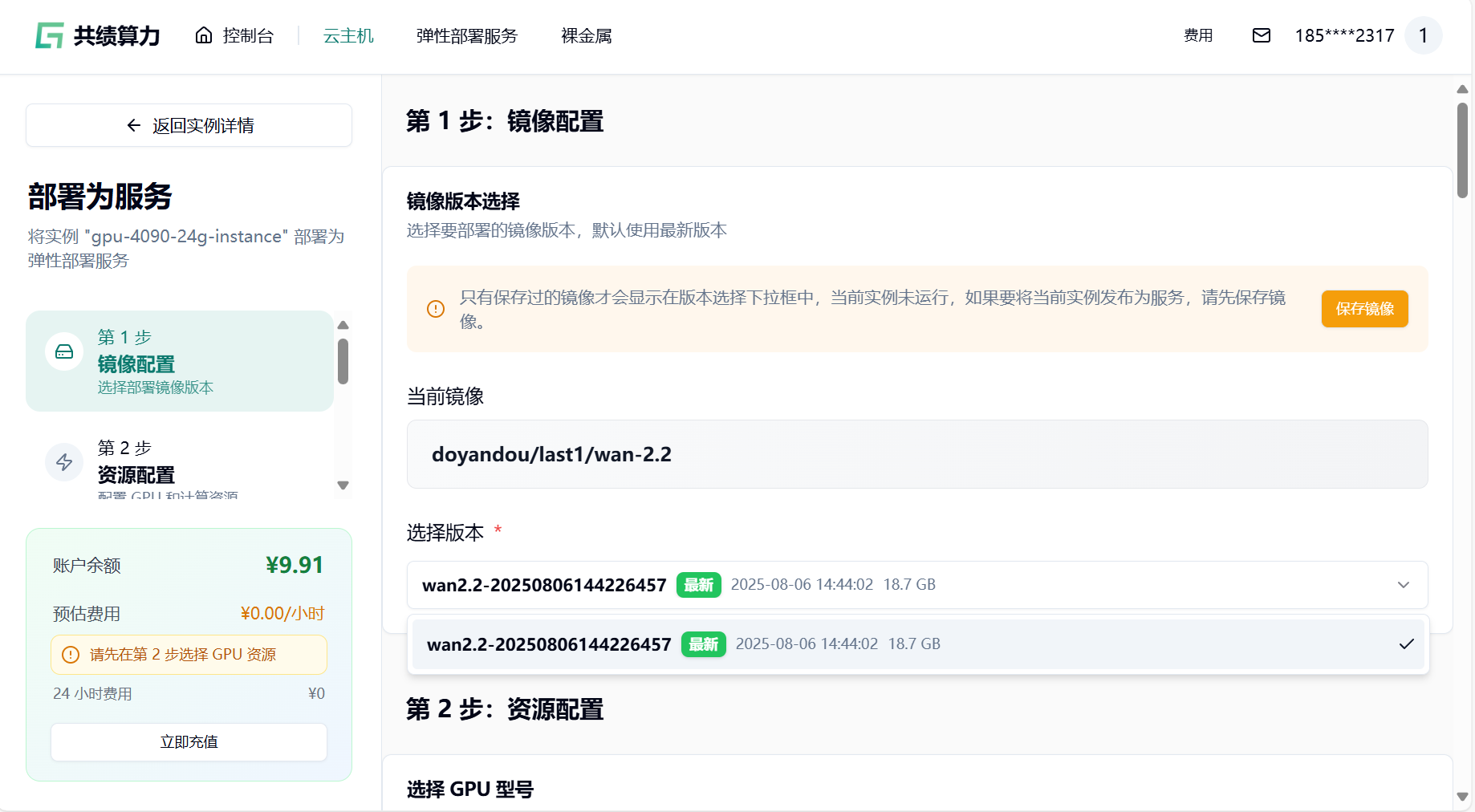
- 选择 GPU 配置(如 4090),节点默认选择 1 个
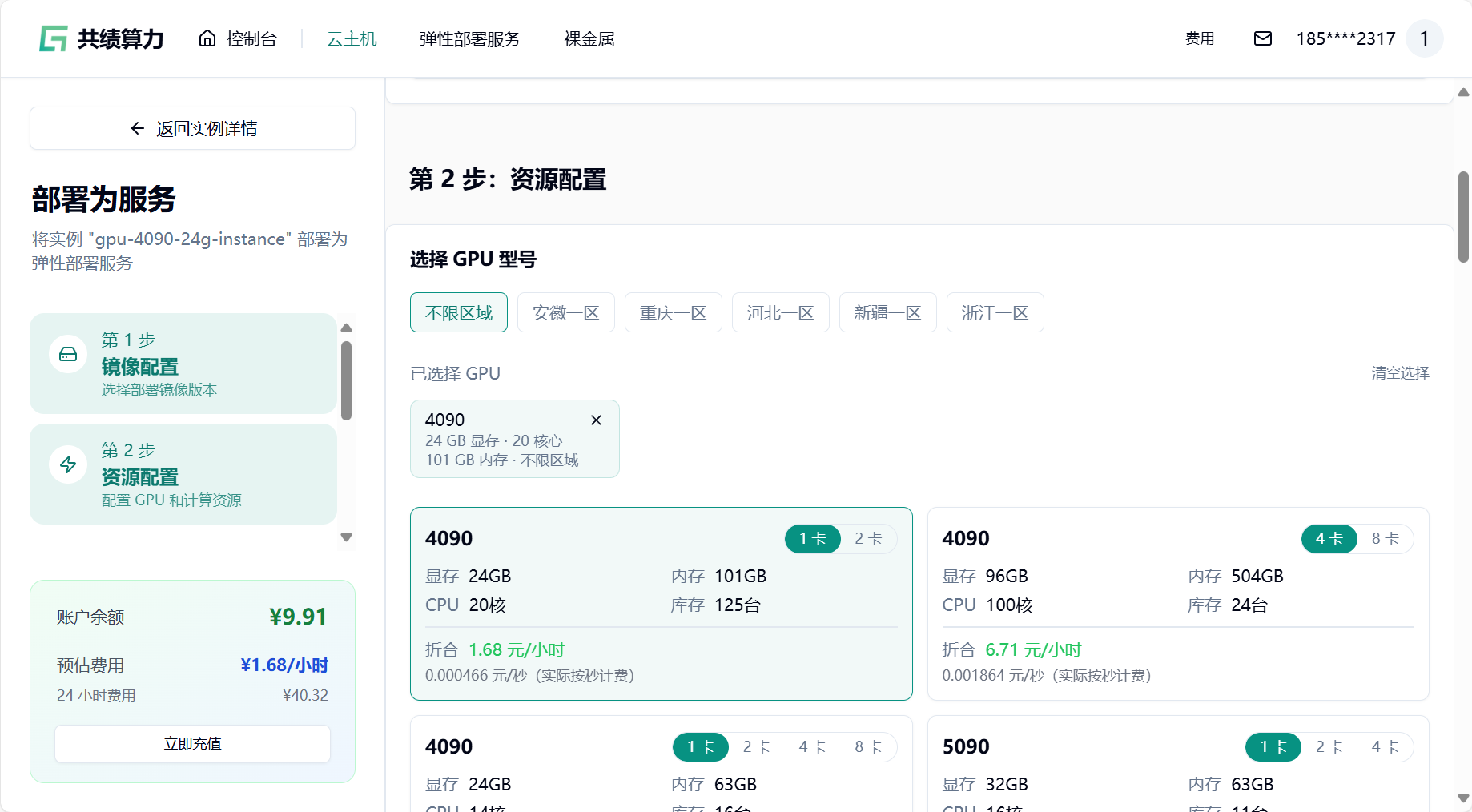
- 添加端口,只需要一个 8188 端口,若已存在无需再次添加
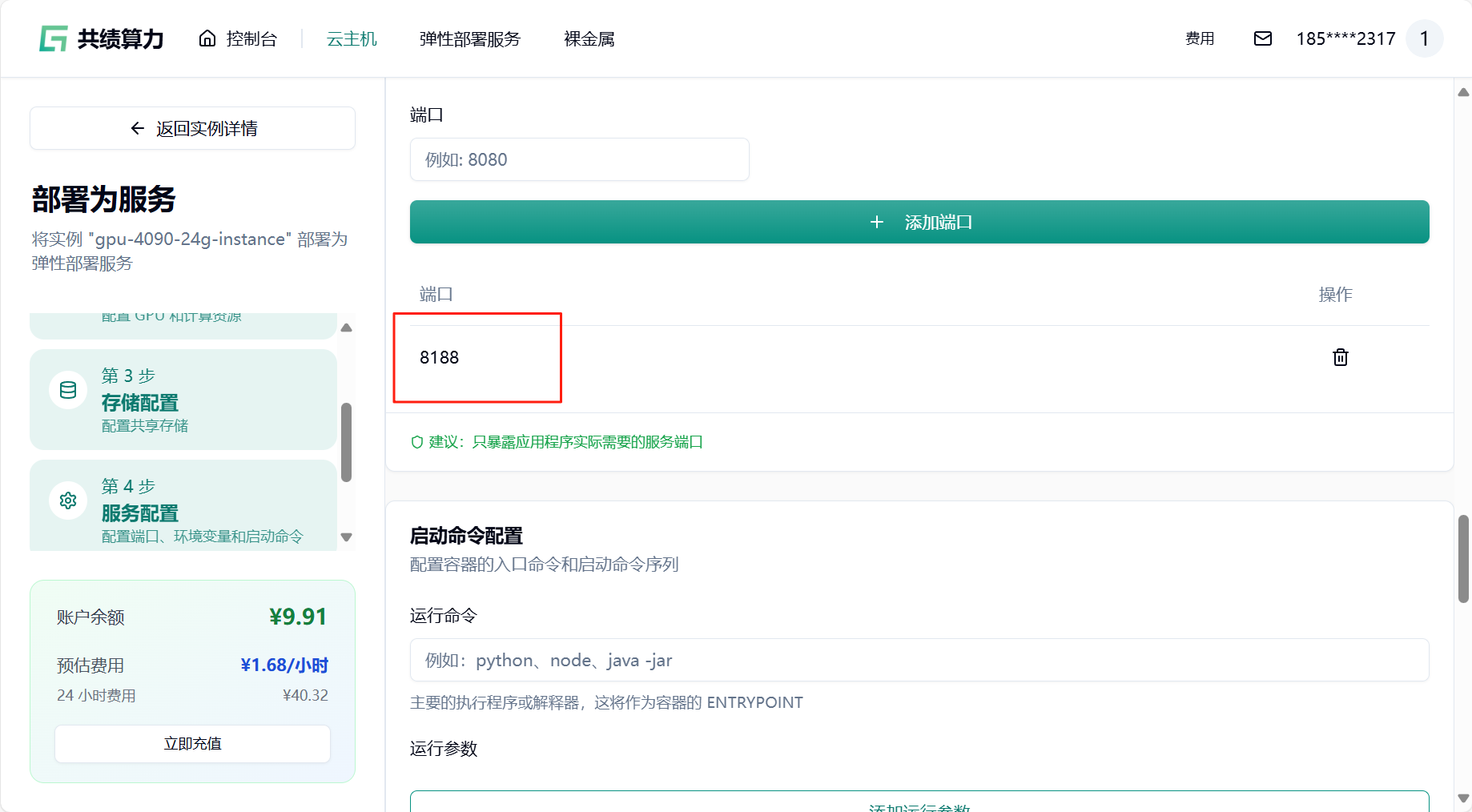
- 启动命令与环境变量可根据个人需求配置
- 点击最下方“确认部署”即可,若无问题则会进入节点拉取界面,耐心等待即可
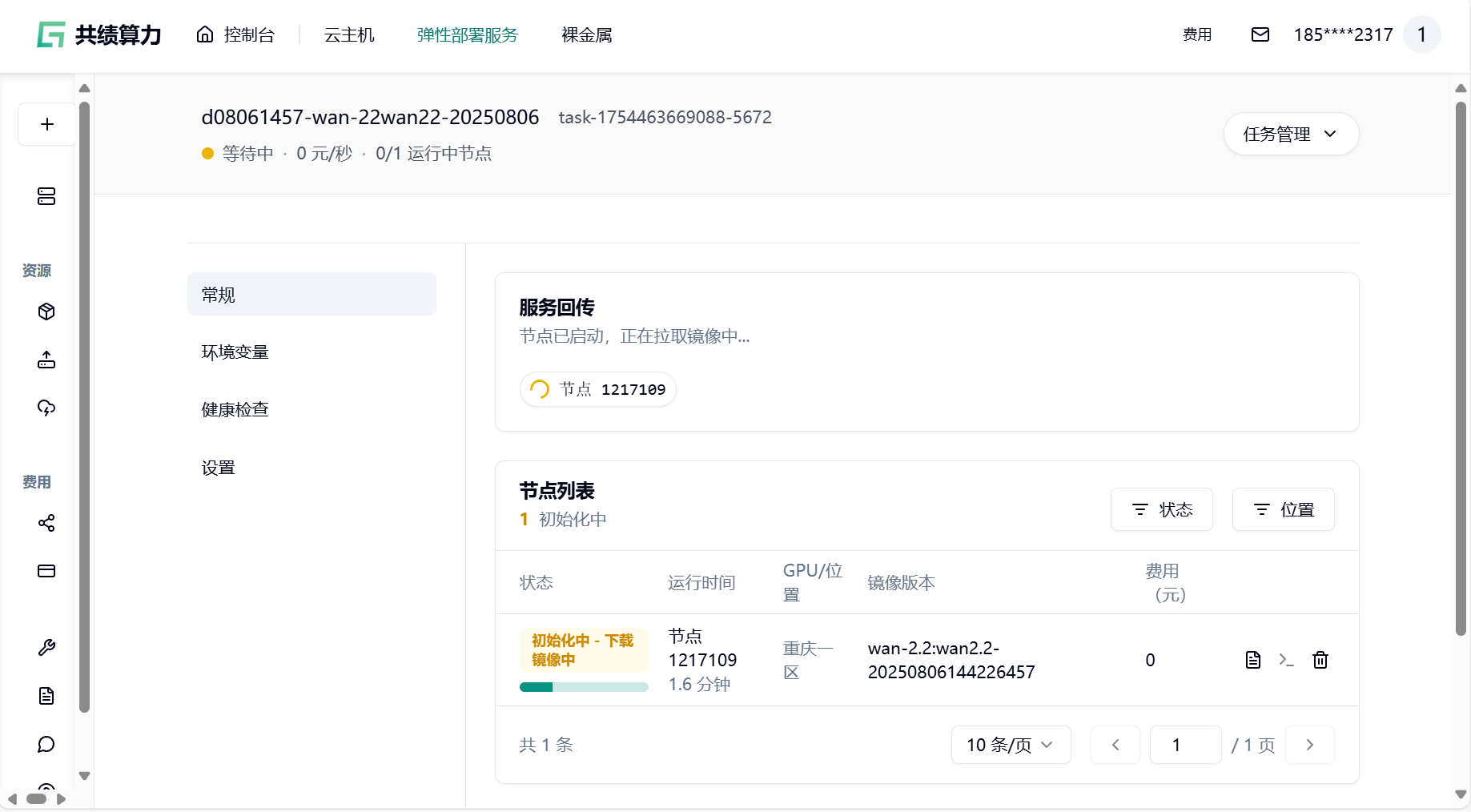
- 节点拉取成功后,点击链接即可快速访问服务
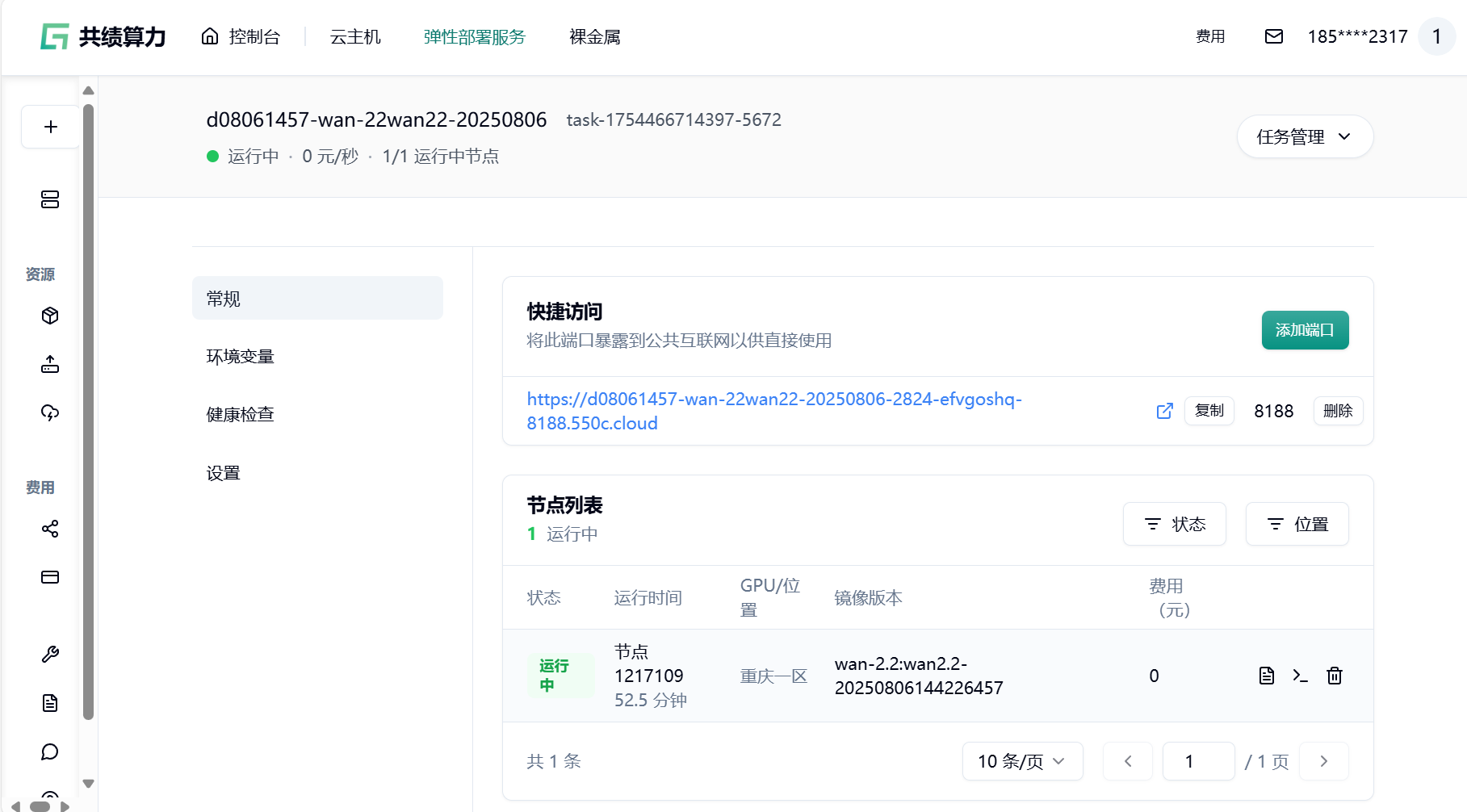
注:该镜像已被保存到我的仓库中,再次使用时可在“选择镜像”中找到并使用