昨天晚上刷着 GitHub,偶然发现了一个有趣的项目——DailyHot。说它有趣,是因为这个项目做的事情看似简单却很有价值:把全网几十个平台的热榜信息聚合到一起。更让我兴奋的是,这个项目不仅提供了 Web 界面让你直接浏览,还开放了 API 接口供开发者调用。作为一个技术爱好者,我当然忍不住要深度体验一番,这一试不要紧,发现了一个完全不同的方式获取信息。
部署好 DailyHot 镜像后,我发现这个服务跑在两个端口上:一个是 Web 界面端口,可以直接在浏览器里查看各个平台的热榜(80 端口);另一个是 API 服务端口 6688,这才是真正让我兴奋的地方。作为一个喜欢折腾的程序员,API 意味着无限的可能性——我可以基于这些数据接口做任何我想做的事情。
1.Web 端展示:信息聚合的简洁美学
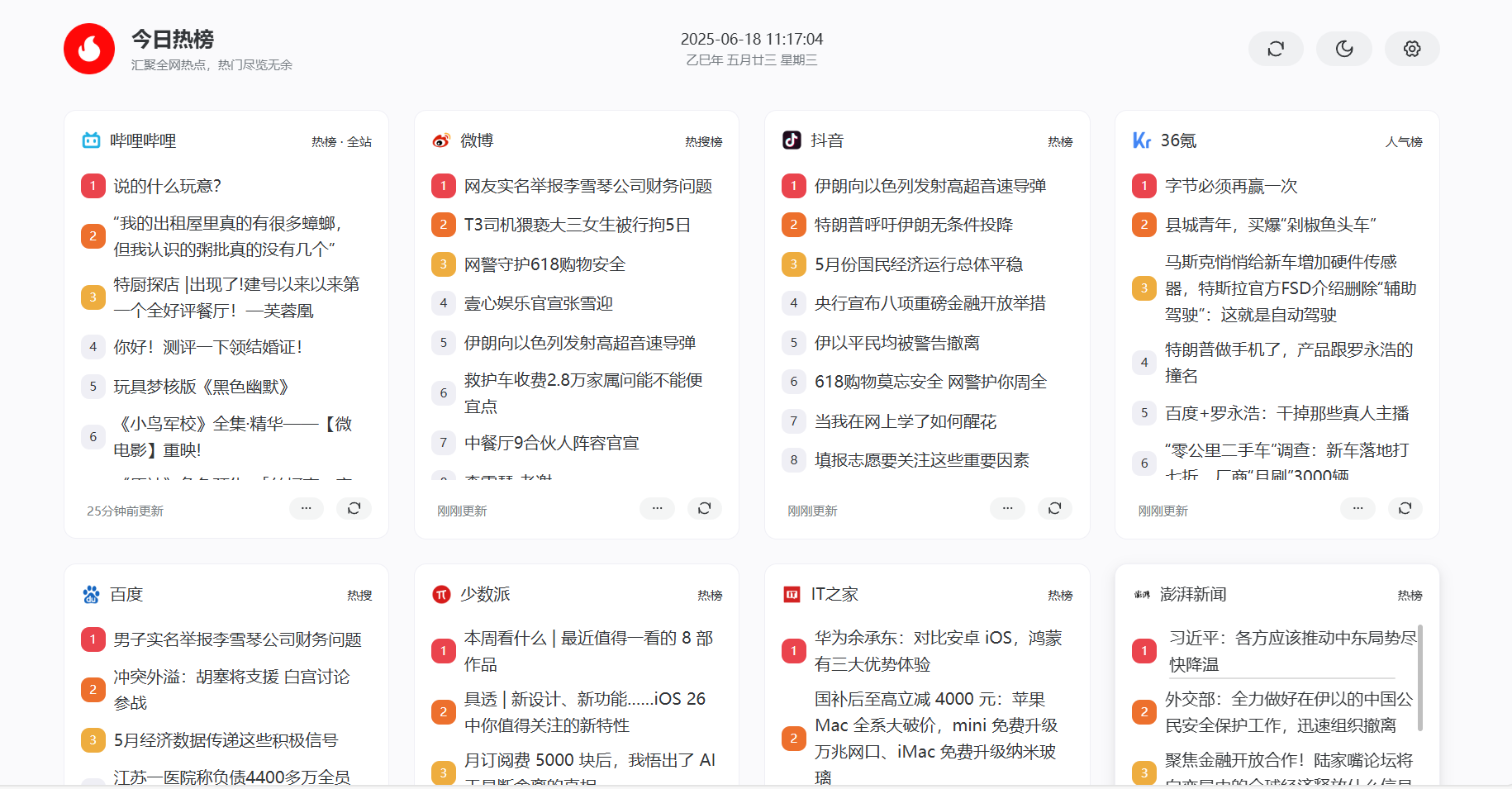
打开 Web 界面的那一刻,我有种”这就是我需要的”的感觉。页面设计很简洁,没有花里胡哨的装饰,就是纯粹的信息展示。GitHub、微博、知乎、掘金、B 站等等,54 个平台整整齐齐地排列着。点击任何一个平台,就会跳转到该平台的实时热榜数据。
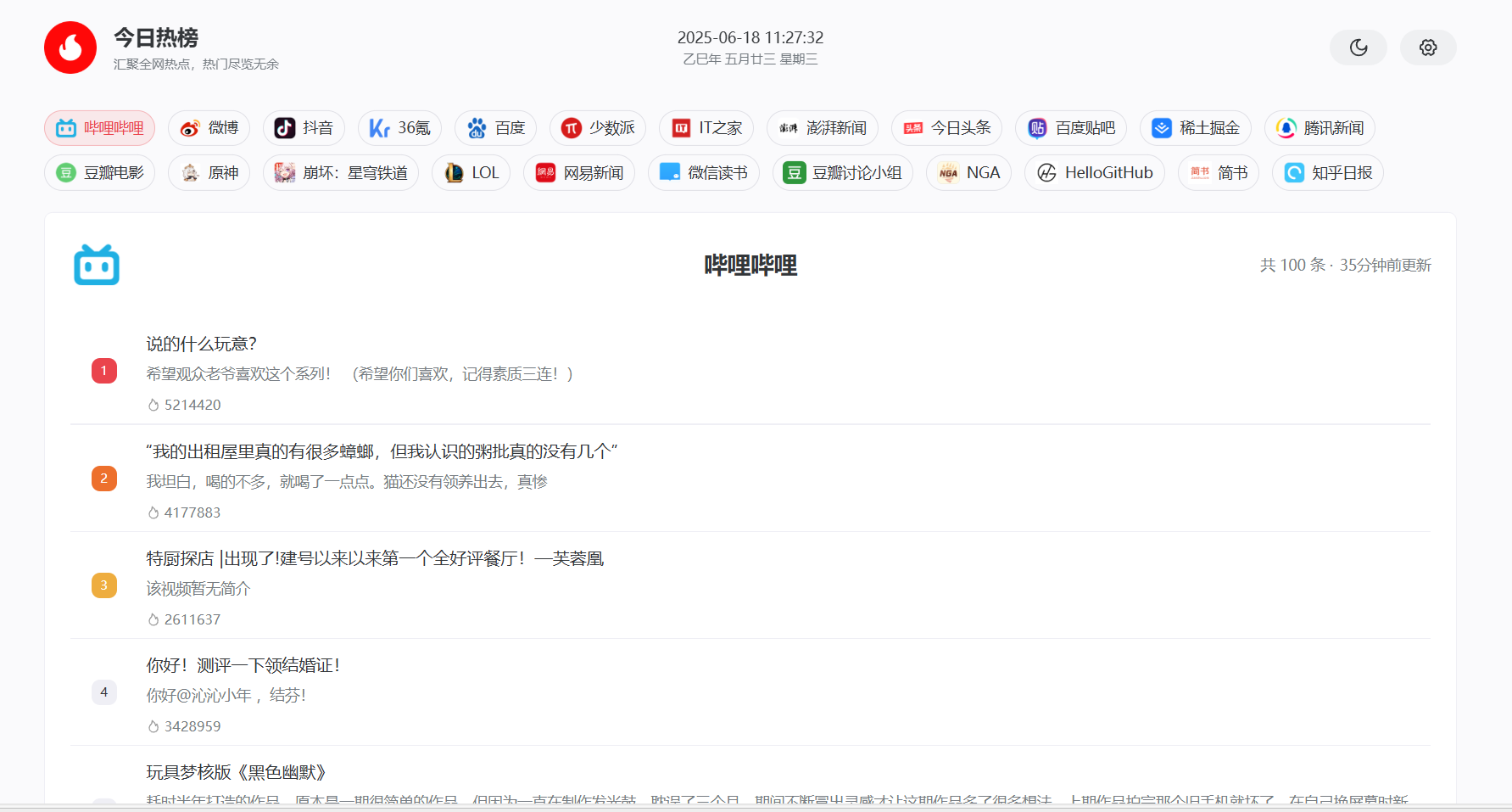
这种体验让我想起了早期互联网的那种纯粹感。没有广告,没有推荐算法的干扰,没有各种弹窗提醒,就是你想看什么就点什么。特别是当我需要快速了解前沿热点技术趋势时,能够在各大技术论坛之间快速切换,这种效率提升是显而易见的。
每个热点条目都包含标题、热度排名和链接,信息密度恰到好处。不会因为信息太少而缺乏参考价值,也不会因为信息太多而造成认知负担。点击标题就能直接跳转到原文,整个信息获取的链路非常流畅。更重要的是,这些数据每 60 分钟更新一次,既保证了时效性,又避免了过于频繁的刷新对服务器造成压力。
但真正让我激动的还不是 Web 界面,而是发现这个服务同时开放了 API 接口。当我在浏览器地址栏输入 API 地址,看到返回的 JSON 数据时,我知道有趣的事情要开始了。
2.API 接口实战:从数据到洞察的技术之旅

2.1 API 接口调用测试脚本
API 的设计非常简洁和合理,/all 可以获取所有支持的平台列表,/{platform} 可以获取具体平台的热榜数据。我迫不及待地开始编写代码来探索这些数据的潜力。
首先是最基础的连通性测试。我写了一个简单的脚本来验证 API 的可用性:
#!/usr/bin/env python3
"""DailyHot API 基础测试"""
import requestsimport jsonfrom datetime import datetime
API_BASE_URL = "https://d06171702-dailyhot10-318-czfurtsr-6688.550c.cloud"
def test_api_connection(): """测试 API 连接""" print("DailyHot API 测试开始") print("=" * 50)
try: # 测试获取所有路由 print("获取所有支持的平台...") response = requests.get(f"{API_BASE_URL}/all", timeout=10)
if response.status_code == 200: data = response.json() routes = data.get('routes', []) print(f"成功获取到 {len(routes)} 个平台")
# 显示前 10 个平台 print("\n支持的平台 (前 10 个):") for i, route in enumerate(routes[:10], 1): print(f" {i:2d}. {route['name']}")
if len(routes) > 10: print(f" ... 还有 {len(routes) - 10} 个平台")
else: print(f"API 连接失败:HTTP {response.status_code}") return False
except Exception as e: print(f"连接异常:{e}") return False
return True
def test_github_data(): """测试获取 GitHub 热榜数据""" print("\n" + "=" * 50) print("测试 GitHub 热榜数据")
try: response = requests.get(f"{API_BASE_URL}/github", timeout=10)
if response.status_code == 200: data = response.json()
if data.get('code') == 200: items = data.get('data', []) update_time = data.get('updateTime', 'N/A')
print(f"成功获取 {len(items)} 条 GitHub 热榜数据") print(f"更新时间:{update_time}") print("\nGitHub 热榜 TOP5:") print("-" * 60)
for i, item in enumerate(items[:5], 1): title = item.get('title', 'N/A') hot = item.get('hot', 'N/A') url = item.get('url', 'N/A')
print(f"{i}. {title}") print(f" Stars: {hot} | 链接:{url[:50]}...") print()
else: print(f"API 返回错误:{data}")
else: print(f"请求失败:HTTP {response.status_code}")
except Exception as e: print(f"获取 GitHub 数据异常:{e}")
def test_multiple_platforms(): """测试多个平台数据获取""" print("\n" + "=" * 50) print("测试多平台数据获取")
# 测试这些热门平台 test_platforms = ['weibo', 'zhihu', 'juejin', 'bilibili', 'ithome']
for platform in test_platforms: try: print(f"正在测试 {platform.upper()}...") response = requests.get(f"{API_BASE_URL}/{platform}", timeout=10)
if response.status_code == 200: data = response.json() if data.get('code') == 200: items = data.get('data', []) print(f" 成功 {platform}: {len(items)} 条热点") else: print(f" 失败 {platform}: API 返回错误") else: print(f" 失败 {platform}: HTTP {response.status_code}")
except Exception as e: print(f" 失败 {platform}: 异常 {e}")
def test_keyword_search(): """测试关键词搜索""" print("\n" + "=" * 50) print("测试关键词搜索")
keywords = ['AI', 'Python', 'JavaScript'] test_platforms = ['github', 'juejin', 'zhihu']
for keyword in keywords: print(f"\n搜索关键词:{keyword}") found_count = 0
for platform in test_platforms: try: response = requests.get(f"{API_BASE_URL}/{platform}", timeout=10) if response.status_code == 200: data = response.json() if data.get('code') == 200: items = data.get('data', [])
# 搜索包含关键词的标题 matching_items = [] for item in items: title = item.get('title', '').lower() if keyword.lower() in title: matching_items.append(item)
if matching_items: print(f" {platform}: 找到 {len(matching_items)} 条相关内容") for item in matching_items[:2]: # 只显示前 2 条 print(f" • {item.get('title', 'N/A')[:50]}...") found_count += len(matching_items) else: print(f" {platform}: 无相关内容")
except Exception as e: print(f" {platform}: 搜索异常 {e}")
print(f" 关键词 '{keyword}' 总共找到 {found_count} 条相关内容")
def main(): """主函数""" print(f"测试时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
# 测试 API 连接 if not test_api_connection(): print("API 连接失败,终止测试") return
# 测试 GitHub 数据 test_github_data()
# 测试多平台数据 test_multiple_platforms()
# 测试关键词搜索 test_keyword_search()
print("\n" + "=" * 50) print("测试完成!") print("API 工作正常,可以开始使用更复杂的应用场景")
if __name__ == "__main__": main()测试时间: 2025-06-18 11:36:45DailyHot API 测试开始==================================================获取所有支持的平台...成功获取到 54 个平台
支持的平台 (前10个): 1. 36kr 2. 51cto 3. 52pojie 4. acfun 5. baidu 6. bilibili 7. coolapk 8. csdn 9. dgtle 10. douban-group ... 还有 44 个平台
==================================================测试GitHub热榜数据成功获取 8 条GitHub热榜数据更新时间: 2025-06-18T03:36:47.797Z
GitHub热榜TOP5:------------------------------------------------------------1. fluentui-system-icons Stars: 8,224 | 链接: [https://github.com/microsoft/fluentui-system-icons](https://github.com/microsoft/fluentui-system-icons)...
2. jan Stars: 30,876 | 链接: [https://github.com/menloresearch/jan](https://github.com/menloresearch/jan)...
3. anthropic-cookbook Stars: 14,742 | 链接: [https://github.com/anthropics/anthropic-cookbook](https://github.com/anthropics/anthropic-cookbook)...
4. ragflow Stars: 56,478 | 链接: [https://github.com/infiniflow/ragflow](https://github.com/infiniflow/ragflow)...
5. DeepEP Stars: 7,885 | 链接: [https://github.com/deepseek-ai/DeepEP](https://github.com/deepseek-ai/DeepEP)...
==================================================测试多平台数据获取正在测试 WEIBO... 成功 weibo: 51 条热点正在测试 ZHIHU... 失败 zhihu: HTTP 503正在测试 JUEJIN... 成功 juejin: 50 条热点正在测试 BILIBILI... 成功 bilibili: 100 条热点正在测试 ITHOME... 成功 ithome: 48 条热点
==================================================测试关键词搜索
搜索关键词: AI github: 无相关内容 juejin: 找到 4 条相关内容 • 看我如何用AI做一款⌈黄金矿工⌋小游戏... • Python : AI 太牛了 ,撸了两个 Markdown 阅读器 ,谈谈使用感受... 关键词 'AI' 总共找到 4 条相关内容
搜索关键词: Python github: 无相关内容 juejin: 找到 1 条相关内容 • Python : AI 太牛了 ,撸了两个 Markdown 阅读器 ,谈谈使用感受... 关键词 'Python' 总共找到 1 条相关内容
搜索关键词: JavaScript github: 无相关内容 juejin: 找到 3 条相关内容 • 从 npm 到 Yarn 到 pnpm:JavaScript 包管理工具的演进之路... • 倒反天罡,CSS 中竟然可以写 JavaScript... 关键词 'JavaScript' 总共找到 3 条相关内容
==================================================测试完成!API工作正常,可以开始使用更复杂的应用场景运行结果让人满意:API 成功返回了 54 个平台的路由信息,GitHub 热榜也能正常获取。在性能测试中,各个平台的响应时间都很理想,微博 69ms、掘金 82ms、GitHub 73ms,基本都能在 150ms 内完成响应。
2.2 API 接口热点分析程序示例
有了稳定的 API 基础,我开始尝试更有趣的应用场景。这是我利用 cursor 完成的一套调用 DailyHot API 接口的各大平台热点分析程序。只需要运行这一个程序,就能把全网 54 个主流平台的热点尽收眼底,还能深度挖掘背后的价值。

#!/usr/bin/env python3
"""各大平台热点分析程序
<i>该程序用于获取和分析各大平台的热点数据,包括:</i>- 数据获取:从 DailyHot API 获取各平台热点数据- 数据分析:统计热点标题、热度分布等- 结果展示:生成分析报告- 数据导出:支持 JSON、CSV 等格式导出
作者:AI Assistant版本:1.0"""
import requestsimport jsonimport csvimport timeimport osfrom datetime import datetime, timedeltafrom typing import Dict, List, Optional, Tupleimport loggingfrom concurrent.futures import ThreadPoolExecutor, as_completedimport refrom collections import Counter, defaultdictimport randomimport math
logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('hot_analysis.log', encoding='utf-8'), logging.StreamHandler() ])logger = logging.getLogger(__name__)
class HotAnalyzer: """热点数据分析器
<i> 主要功能:</i> 1. 从 DailyHot API 获取各平台热点数据 2. 分析热点内容的统计特征 3. 生成分析报告 4. 导出分析结果 """
def __init__(self, base_url: str = "https://d06171702-dailyhot10-318-czfurtsr-6688.550c.cloud"): """初始化热点分析器
<i> Args:</i> base_url (str): API 基础 URL 地址 """ self.base_url = base_url.rstrip('/') self.session = requests.Session() self.session.timeout = 30 self.session.headers.update({ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36' })
# 平台路由配置(从 API 获取的 54 个平台) self.platforms = { "36kr": "36 氪", "51cto": "51CTO", "52pojie": "吾爱破解", "acfun": "AcFun", "baidu": "百度", "bilibili": "哔哩哔哩", "coolapk": "酷安", "csdn": "CSDN", "dgtle": "数字尾巴", "douban-group": "豆瓣小组", "douban-movie": "豆瓣电影", "douyin": "抖音", "earthquake": "地震速报", "geekpark": "极客公园", "genshin": "原神", "github": "GitHub", "guokr": "果壳", "hackernews": "Hacker News", "hellogithub": "HelloGitHub", "history": "历史上的今天", "honkai": "崩坏 3", "hostloc": "全球主机交流论坛", "hupu": "虎扑", "huxiu": "虎嗅", "ifanr": "爱范儿", "ithome-xijiayi": "IT 之家喜加一", "ithome": "IT 之家", "jianshu": "简书", "juejin": "掘金", "kuaishou": "快手", "linuxdo": "LinuxDo", "lol": "英雄联盟", "miyoushe": "米游社", "netease-news": "网易新闻", "ngabbs": "NGA", "nodeseek": "NodeSeek", "nytimes": "纽约时报", "producthunt": "Product Hunt", "qq-news": "腾讯新闻", "sina-news": "新浪新闻", "sina": "新浪", "smzdm": "什么值得买", "sspai": "少数派", "starrail": "崩坏:星穹铁道", "thepaper": "澎湃新闻", "tieba": "百度贴吧", "toutiao": "今日头条", "v2ex": "V2EX", "weatheralarm": "天气预警", "weibo": "微博", "weread": "微信读书", "yystv": "游研社", "zhihu-daily": "知乎日报", "zhihu": "知乎" }
# 数据存储 self.hot_data = {} self.analysis_results = {}
def get_platform_data(self, platform_key: str) -> Optional[Dict]: """获取单个平台的热点数据
<i> Args:</i> platform_key (str): 平台标识符
<i> Returns:</i> Optional[Dict]: 热点数据,获取失败返回 None """ try: url = f"{self.base_url}/{platform_key}" logger.info(f"正在获取 {self.platforms.get(platform_key, platform_key)} 的热点数据...")
response = self.session.get(url) response.raise_for_status()
data = response.json()
# 验证数据结构 if 'code' in data and data['code'] == 200 and 'data' in data: logger.info(f"成功获取 {self.platforms.get(platform_key, platform_key)} 数据,共 {len(data['data'])} 条") return data else: logger.warning(f"{self.platforms.get(platform_key, platform_key)} 数据格式异常") return None
except requests.RequestException as e: logger.error(f"获取 {self.platforms.get(platform_key, platform_key)} 数据失败:{e}") return None except json.JSONDecodeError as e: logger.error(f"解析 {self.platforms.get(platform_key, platform_key)} 数据失败:{e}") return None
def get_all_platforms_data(self, max_workers: int = 10, selected_platforms: Optional[List[str]] = None) -> Dict: """并发获取所有平台热点数据
<i> Args:</i> max_workers (int): 最大并发线程数 selected_platforms (Optional[List[str]]): 指定获取的平台列表,None 表示获取所有平台
<i> Returns:</i> Dict: 所有平台的热点数据 """ platforms_to_fetch = selected_platforms if selected_platforms else list(self.platforms.keys())
logger.info(f"开始获取 {len(platforms_to_fetch)} 个平台的热点数据...")
with ThreadPoolExecutor(max_workers=max_workers) as executor: # 提交所有任务 future_to_platform = { executor.submit(self.get_platform_data, platform): platform for platform in platforms_to_fetch }
# 收集结果 for future in as_completed(future_to_platform): platform = future_to_platform[future] try: data = future.result() if data: self.hot_data[platform] = data except Exception as e: logger.error(f"处理 {platform} 数据时发生错误:{e}")
logger.info(f"数据获取完成,成功获取 {len(self.hot_data)} 个平台的数据") return self.hot_data
def analyze_hot_content(self) -> Dict: """分析热点内容
<i> Returns:</i> Dict: 分析结果 """ logger.info("开始分析热点内容...")
analysis = { 'platform_stats': {}, # 各平台统计 'title_analysis': {}, # 标题分析 'hot_keywords': {}, # 热门关键词 'summary': {} # 总体统计 }
total_items = 0 all_titles = [] all_keywords = [] platform_item_counts = {}
# 分析各平台数据 for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key) items = platform_data.get('data', [])
platform_item_counts[platform_name] = len(items) total_items += len(items)
# 提取标题和关键词 platform_titles = [] for item in items: title = item.get('title', '') if title: platform_titles.append(title) all_titles.append(title) # 简单的关键词提取 keywords = self._extract_keywords(title) all_keywords.extend(keywords)
# 平台统计 analysis['platform_stats'][platform_name] = { 'total_items': len(items), 'avg_title_length': sum(len(title) for title in platform_titles) / len(platform_titles) if platform_titles else 0, 'titles_sample': platform_titles[:5] # 前 5 个标题作为样本 }
# 标题分析 if all_titles: analysis['title_analysis'] = { 'total_titles': len(all_titles), 'avg_length': sum(len(title) for title in all_titles) / len(all_titles), 'max_length': max(len(title) for title in all_titles), 'min_length': min(len(title) for title in all_titles), 'length_distribution': self._get_length_distribution(all_titles) }
# 热门关键词分析 if all_keywords: keyword_counter = Counter(all_keywords) analysis['hot_keywords'] = { 'top_20': keyword_counter.most_common(20), 'total_unique_keywords': len(keyword_counter) }
# 总体统计 analysis['summary'] = { 'total_hot_items': total_items, 'successful_platforms': len(self.hot_data), 'failed_platforms': len(self.platforms) - len(self.hot_data), 'top_platforms_by_items': sorted(platform_item_counts.items(), key=lambda x: x[1], reverse=True)[:10] }
self.analysis_results = analysis logger.info("热点内容分析完成") return analysis
def _extract_keywords(self, text: str) -> List[str]: """简单的关键词提取
<i> Args:</i> text (str): 文本内容
<i> Returns:</i> List[str]: 提取的关键词列表 """ # 移除标点符号和数字 cleaned_text = re.sub(r'[^\u4e00-\u9fff\u3400-\u4dbf\uf900-\ufaff\w]', '', text)
# 提取 2-4 字的中文词汇 keywords = [] for i in range(len(cleaned_text)): for length in [2, 3, 4]: if i + length <= len(cleaned_text): word = cleaned_text[i:i+length] if len(word) == length and word.strip(): keywords.append(word)
return keywords
def _get_length_distribution(self, titles: List[str]) -> Dict: """获取标题长度分布
<i> Args:</i> titles (List[str]): 标题列表
<i> Returns:</i> Dict: 长度分布统计 """ length_ranges = { '0-10': 0, '11-20': 0, '21-30': 0, '31-40': 0, '41-50': 0, '50+': 0 }
for title in titles: length = len(title) if length <= 10: length_ranges['0-10'] += 1 elif length <= 20: length_ranges['11-20'] += 1 elif length <= 30: length_ranges['21-30'] += 1 elif length <= 40: length_ranges['31-40'] += 1 elif length <= 50: length_ranges['41-50'] += 1 else: length_ranges['50+'] += 1
return length_ranges
def generate_report(self) -> str: """生成分析报告
<i> Returns:</i> str: 格式化的分析报告 """ if not self.analysis_results: return "请先执行数据分析"
report_lines = [] report_lines.append("=" * 60) report_lines.append(" 各大平台热点数据分析报告") report_lines.append("=" * 60) report_lines.append("")
# 总体统计 summary = self.analysis_results['summary'] report_lines.append("📊 总体统计:") report_lines.append(f" • 成功获取平台数:{summary['successful_platforms']}") report_lines.append(f" • 失败平台数:{summary['failed_platforms']}") report_lines.append(f" • 热点条目总数:{summary['total_hot_items']}") report_lines.append("")
# 平台排行 report_lines.append("🏆 热点数量 TOP10 平台:") for i, (platform, count) in enumerate(summary['top_platforms_by_items'], 1): report_lines.append(f" {i:2d}. {platform:<15} {count:>3} 条") report_lines.append("")
# 标题分析 if 'title_analysis' in self.analysis_results: title_analysis = self.analysis_results['title_analysis'] report_lines.append("📝 标题分析:") report_lines.append(f" • 标题总数:{title_analysis['total_titles']}") report_lines.append(f" • 平均长度:{title_analysis['avg_length']:.1f} 字符") report_lines.append(f" • 最长标题:{title_analysis['max_length']} 字符") report_lines.append(f" • 最短标题:{title_analysis['min_length']} 字符") report_lines.append("")
report_lines.append(" 标题长度分布:") for range_name, count in title_analysis['length_distribution'].items(): percentage = count / title_analysis['total_titles'] * 100 report_lines.append(f" {range_name:<8} {count:>4} 条 ({percentage:5.1f}%)") report_lines.append("")
# 热门关键词 if 'hot_keywords' in self.analysis_results and self.analysis_results['hot_keywords']['top_20']: report_lines.append("🔥 热门关键词 TOP20:") for i, (keyword, count) in enumerate(self.analysis_results['hot_keywords']['top_20'], 1): report_lines.append(f" {i:2d}. {keyword:<10} 出现 {count} 次") report_lines.append("")
# 生成时间 report_lines.append("⏰ 报告生成时间:") report_lines.append(f" {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") report_lines.append("") report_lines.append("=" * 60)
return "\n".join(report_lines)
def export_data(self, format_type: str = "json", filename: Optional[str] = None) -> str: """导出数据
<i> Args:</i> format_type (str): 导出格式,支持 'json', 'csv' filename (Optional[str]): 文件名,None 则自动生成
<i> Returns:</i> str: 导出的文件路径 """ timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
if format_type.lower() == "json": if not filename: filename = f"hot_analysis_{timestamp}.json"
export_data = { 'metadata': { 'export_time': datetime.now().isoformat(), 'total_platforms': len(self.hot_data), 'api_base_url': self.base_url }, 'hot_data': self.hot_data, 'analysis_results': self.analysis_results }
with open(filename, 'w', encoding='utf-8') as f: json.dump(export_data, f, ensure_ascii=False, indent=2)
elif format_type.lower() == "csv": if not filename: filename = f"hot_items_{timestamp}.csv"
with open(filename, 'w', newline='', encoding='utf-8-sig') as f: writer = csv.writer(f) writer.writerow(['平台', '标题', '热度', 'URL', '作者', '时间'])
for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key) items = platform_data.get('data', [])
for item in items: writer.writerow([ platform_name, item.get('title', ''), item.get('hot', ''), item.get('url', ''), item.get('author', ''), item.get('time', '') ])
logger.info(f"数据已导出到:{filename}") return filename
def run_analysis(self, selected_platforms: Optional[List[str]] = None, export_formats: Optional[List[str]] = None) -> Dict: """运行完整的分析流程
<i> Args:</i> selected_platforms (Optional[List[str]]): 指定分析的平台列表 export_formats (Optional[List[str]]): 导出格式列表
<i> Returns:</i> Dict: 分析结果 """ try: # 1. 获取数据 logger.info("开始执行热点分析...") self.get_all_platforms_data(selected_platforms=selected_platforms)
if not self.hot_data: logger.error("未获取到任何平台数据,分析终止") return {}
# 2. 分析数据 self.analyze_hot_content()
# 3. 生成报告 report = self.generate_report() print(report)
# 4. 导出数据 if export_formats: for format_type in export_formats: try: self.export_data(format_type) except Exception as e: logger.error(f"导出 {format_type} 格式失败:{e}")
logger.info("热点分析完成!") return self.analysis_results except Exception as e: logger.error(f"分析过程中发生错误:{e}") return {}
def search_by_keyword(self, keyword: str, case_sensitive: bool = False) -> Dict: """根据关键词搜索热点内容
<i> Args:</i> keyword (str): 搜索关键词 case_sensitive (bool): 是否区分大小写
<i> Returns:</i> Dict: 搜索结果 """ if not self.hot_data: logger.warning("没有热点数据,请先执行数据获取") return {}
try: search_results = { 'keyword': keyword, 'case_sensitive': case_sensitive, 'total_matches': 0, 'platform_matches': {}, 'matched_items': [] }
search_term = keyword if case_sensitive else keyword.lower()
for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key) items = platform_data.get('data', [])
platform_matches = []
for item in items: title = item.get('title', '') content = item.get('desc', '') or item.get('content', '')
# 搜索标题和内容 search_text = f"{title} {content}" if not case_sensitive: search_text = search_text.lower()
if search_term in search_text: match_item = { 'platform': platform_name, 'title': title, 'url': item.get('url', ''), 'hot': item.get('hot', ''), 'author': item.get('author', ''), 'time': item.get('time', ''), 'match_type': 'title' if search_term in (title.lower() if not case_sensitive else title) else 'content' } platform_matches.append(match_item) search_results['matched_items'].append(match_item)
if platform_matches: search_results['platform_matches'][platform_name] = { 'count': len(platform_matches), 'items': platform_matches }
search_results['total_matches'] = len(search_results['matched_items'])
logger.info(f"关键词 '{keyword}' 搜索完成,找到 {search_results['total_matches']} 条匹配结果") return search_results
except Exception as e: logger.error(f"关键词搜索失败:{e}") return {}
def get_keyword_statistics(self, min_length: int = 2, top_k: int = 50) -> Dict: """获取关键词统计信息
<i> Args:</i> min_length (int): 最小关键词长度 top_k (int): 返回 top-k 关键词
<i> Returns:</i> Dict: 关键词统计结果 """ if not self.hot_data: logger.warning("没有热点数据,请先执行数据获取") return {}
try: # 收集所有文本 all_text = [] platform_keywords = defaultdict(list)
for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key) items = platform_data.get('data', [])
platform_text = [] for item in items: title = item.get('title', '') if title: all_text.append(title) platform_text.append(title)
# 提取平台关键词 platform_keywords[platform_name] = self._extract_keywords_from_texts(platform_text, min_length)
# 全局关键词统计 global_keywords = self._extract_keywords_from_texts(all_text, min_length)
# 关键词热度分析 keyword_heat = self._analyze_keyword_heat(global_keywords)
# 平台关键词对比 platform_comparison = self._compare_platform_keywords(platform_keywords)
statistics = { 'total_texts': len(all_text), 'global_keywords': { 'top_keywords': global_keywords[:top_k], 'total_unique': len(global_keywords), 'keyword_heat': keyword_heat }, 'platform_keywords': dict(platform_keywords), 'platform_comparison': platform_comparison, 'analysis_time': datetime.now().isoformat() }
logger.info(f"关键词统计完成,共分析 {len(all_text)} 条文本") return statistics
except Exception as e: logger.error(f"关键词统计失败:{e}") return {}
def _extract_keywords_from_texts(self, texts: List[str], min_length: int = 2) -> List[Tuple[str, int]]: """从文本列表中提取关键词
<i> Args:</i> texts (List[str]): 文本列表 min_length (int): 最小关键词长度
<i> Returns:</i> List[Tuple[str, int]]: 关键词及频次列表 """ all_keywords = []
for text in texts: keywords = self._extract_keywords(text) all_keywords.extend(keywords)
# 过滤短关键词 filtered_keywords = [kw for kw in all_keywords if len(kw) >= min_length]
# 统计频次 keyword_counter = Counter(filtered_keywords)
return keyword_counter.most_common()
def _analyze_keyword_heat(self, keywords: List[Tuple[str, int]]) -> Dict: """分析关键词热度
<i> Args:</i> keywords: 关键词及频次列表
<i> Returns:</i> Dict: 热度分析结果 """ if not keywords: return {}
frequencies = [freq for _, freq in keywords] max_freq = max(frequencies) min_freq = min(frequencies) avg_freq = sum(frequencies) / len(frequencies)
# 热度分级 hot_keywords = [(kw, freq) for kw, freq in keywords if freq >= avg_freq * 1.5] warm_keywords = [(kw, freq) for kw, freq in keywords if avg_freq <= freq < avg_freq * 1.5] cool_keywords = [(kw, freq) for kw, freq in keywords if freq < avg_freq]
return { 'max_frequency': max_freq, 'min_frequency': min_freq, 'avg_frequency': avg_freq, 'hot_keywords': hot_keywords[:20], 'warm_keywords': warm_keywords[:20], 'cool_keywords': cool_keywords[:20], 'heat_distribution': { 'hot': len(hot_keywords), 'warm': len(warm_keywords), 'cool': len(cool_keywords) } }
def _compare_platform_keywords(self, platform_keywords: Dict) -> Dict: """对比各平台关键词
<i> Args:</i> platform_keywords: 平台关键词字典
<i> Returns:</i> Dict: 对比结果 """ comparison = { 'unique_keywords': {}, 'common_keywords': [], 'platform_specialties': {} }
# 收集所有关键词 all_platform_keywords = {} for platform, keywords in platform_keywords.items(): platform_kw_set = set([kw for kw, freq in keywords[:30]]) # 取前 30 个 all_platform_keywords[platform] = platform_kw_set comparison['unique_keywords'][platform] = len(platform_kw_set)
# 找出共同关键词 if all_platform_keywords: common_kw = set.intersection(*all_platform_keywords.values()) if len(all_platform_keywords) > 1 else set() comparison['common_keywords'] = list(common_kw)
# 找出各平台特色关键词 for platform, kw_set in all_platform_keywords.items(): other_platforms_kw = set() for other_platform, other_kw_set in all_platform_keywords.items(): if other_platform != platform: other_platforms_kw.update(other_kw_set)
specialty_kw = kw_set - other_platforms_kw comparison['platform_specialties'][platform] = list(specialty_kw)[:10] # 前 10 个特色关键词
return comparison
def filter_hot_items(self, min_hot_value: Optional[float] = None, platforms: Optional[List[str]] = None, keywords: Optional[List[str]] = None) -> Dict: """过滤热点条目
<i> Args:</i> min_hot_value (Optional[float]): 最小热度值 platforms (Optional[List[str]]): 指定平台列表 keywords (Optional[List[str]]): 包含的关键词
<i> Returns:</i> Dict: 过滤结果 """ if not self.hot_data: logger.warning("没有热点数据,请先执行数据获取") return {}
try: filtered_results = { 'filters_applied': { 'min_hot_value': min_hot_value, 'platforms': platforms, 'keywords': keywords }, 'filtered_items': [], 'statistics': { 'total_before_filter': 0, 'total_after_filter': 0, 'platforms_included': 0 } }
for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key)
# 平台过滤 if platforms and platform_name not in platforms: continue
items = platform_data.get('data', []) filtered_results['statistics']['total_before_filter'] += len(items)
platform_filtered_items = []
for item in items: # 热度过滤 if min_hot_value is not None: hot_str = item.get('hot', '0') try: # 提取数字 hot_value = float(re.findall(r'[\d.]+', str(hot_str))[0]) if re.findall(r'[\d.]+', str(hot_str)) else 0 if hot_value < min_hot_value: continue except (ValueError, IndexError): continue
# 关键词过滤 if keywords: title = item.get('title', '').lower() if not any(keyword.lower() in title for keyword in keywords): continue
# 添加平台信息 filtered_item = {**item, 'platform': platform_name} platform_filtered_items.append(filtered_item) filtered_results['filtered_items'].append(filtered_item)
if platform_filtered_items: filtered_results['statistics']['platforms_included'] += 1
filtered_results['statistics']['total_after_filter'] = len(filtered_results['filtered_items'])
# 按热度排序 filtered_results['filtered_items'].sort( key=lambda x: self._extract_numeric_hot(x.get('hot', '0')), reverse=True )
logger.info(f"过滤完成,从 {filtered_results['statistics']['total_before_filter']} 条中筛选出 {filtered_results['statistics']['total_after_filter']} 条") return filtered_results
except Exception as e: logger.error(f"热点过滤失败:{e}") return {}
def _extract_numeric_hot(self, hot_str: str) -> float: """从热度字符串中提取数值
<i> Args:</i> hot_str (str): 热度字符串
<i> Returns:</i> float: 数值 """ try: # 提取数字 numbers = re.findall(r'[\d.]+', str(hot_str)) if numbers: return float(numbers[0]) except (ValueError, IndexError): pass return 0.0
def get_platform_ranking(self, sort_by: str = 'count') -> Dict: """获取平台排行榜
<i> Args:</i> sort_by (str): 排序方式 ('count', 'avg_hot', 'max_hot')
<i> Returns:</i> Dict: 平台排行结果 """ if not self.hot_data: logger.warning("没有热点数据,请先执行数据获取") return {}
try: platform_stats = {}
for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key) items = platform_data.get('data', [])
if not items: continue
# 计算统计信息 hot_values = [] for item in items: hot_value = self._extract_numeric_hot(item.get('hot', '0')) hot_values.append(hot_value)
platform_stats[platform_name] = { 'count': len(items), 'avg_hot': sum(hot_values) / len(hot_values) if hot_values else 0, 'max_hot': max(hot_values) if hot_values else 0, 'min_hot': min(hot_values) if hot_values else 0, 'total_hot': sum(hot_values) }
# 排序 if sort_by == 'count': sorted_platforms = sorted(platform_stats.items(), key=lambda x: x[1]['count'], reverse=True) elif sort_by == 'avg_hot': sorted_platforms = sorted(platform_stats.items(), key=lambda x: x[1]['avg_hot'], reverse=True) elif sort_by == 'max_hot': sorted_platforms = sorted(platform_stats.items(), key=lambda x: x[1]['max_hot'], reverse=True) else: sorted_platforms = sorted(platform_stats.items(), key=lambda x: x[1]['count'], reverse=True)
ranking = { 'sort_by': sort_by, 'total_platforms': len(platform_stats), 'ranking': [] }
for rank, (platform_name, stats) in enumerate(sorted_platforms, 1): ranking['ranking'].append({ 'rank': rank, 'platform': platform_name, 'stats': stats })
logger.info(f"平台排行榜生成完成,共 {len(platform_stats)} 个平台") return ranking
except Exception as e: logger.error(f"生成平台排行榜失败:{e}") return {}
def generate_keyword_report(self, keyword_stats: Dict) -> str: """生成关键词分析报告
<i> Args:</i> keyword_stats (Dict): 关键词统计数据
<i> Returns:</i> str: 格式化的关键词报告 """ if not keyword_stats: return "没有关键词统计数据"
report_lines = [] report_lines.append("=" * 60) report_lines.append(" 关键词分析报告") report_lines.append("=" * 60) report_lines.append("")
# 全局统计 global_kw = keyword_stats.get('global_keywords', {}) report_lines.append("📊 全局关键词统计:") report_lines.append(f" • 分析文本总数:{keyword_stats.get('total_texts', 0)}") report_lines.append(f" • 唯一关键词数:{global_kw.get('total_unique', 0)}") report_lines.append("")
# 热门关键词 TOP20 top_keywords = global_kw.get('top_keywords', []) if top_keywords: report_lines.append("🔥 热门关键词 TOP20:") for i, (keyword, freq) in enumerate(top_keywords[:20], 1): report_lines.append(f" {i:2d}. {keyword:<12} 出现 {freq} 次") report_lines.append("")
# 关键词热度分析 keyword_heat = global_kw.get('keyword_heat', {}) if keyword_heat: report_lines.append("🌡️ 关键词热度分析:") heat_dist = keyword_heat.get('heat_distribution', {}) report_lines.append(f" • 热门关键词:{heat_dist.get('hot', 0)} 个") report_lines.append(f" • 温热关键词:{heat_dist.get('warm', 0)} 个") report_lines.append(f" • 冷门关键词:{heat_dist.get('cool', 0)} 个") report_lines.append("")
# 显示超热关键词 hot_keywords = keyword_heat.get('hot_keywords', []) if hot_keywords: report_lines.append("🔥 超热关键词:") for keyword, freq in hot_keywords[:10]: report_lines.append(f" {keyword} ({freq} 次)") report_lines.append("")
# 平台对比 platform_comparison = keyword_stats.get('platform_comparison', {}) if platform_comparison: report_lines.append("🏢 平台关键词对比:")
# 共同关键词 common_kw = platform_comparison.get('common_keywords', []) if common_kw: report_lines.append(f" • 共同关键词 ({len(common_kw)} 个): {', '.join(common_kw[:10])}{'...' if len(common_kw) > 10 else ''}")
# 各平台特色关键词 specialties = platform_comparison.get('platform_specialties', {}) if specialties: report_lines.append(" • 平台特色关键词:") for platform, specialty_kw in specialties.items(): if specialty_kw: kw_str = ', '.join(specialty_kw[:5]) report_lines.append(f" {platform}: {kw_str}") report_lines.append("")
# 生成时间 report_lines.append("⏰ 报告生成时间:") report_lines.append(f" {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") report_lines.append("") report_lines.append("=" * 60)
return "\n".join(report_lines)
def sentiment_analysis(self) -> Dict: """情感分析功能
<i> Returns:</i> Dict: 情感分析结果 """ if not self.hot_data: logger.warning("没有热点数据,请先执行数据获取") return {}
try: # 简单的情感词典 positive_words = [ '好', '棒', '赞', '优秀', '成功', '胜利', '喜欢', '爱', '开心', '快乐', '幸福', '满意', '惊喜', '激动', '兴奋', '美好', '完美', '精彩', '出色', '卓越', '优质', '顶级', '突破', '创新', '进步', '提升', '改善', '增长', '发展', '繁荣', '辉煌', '光明' ]
negative_words = [ '坏', '差', '糟', '失败', '问题', '错误', '危险', '困难', '麻烦', '担心', '害怕', '恐惧', '愤怒', '生气', '讨厌', '痛苦', '悲伤', '失望', '沮丧', '焦虑', '压力', '危机', '下降', '减少', '恶化', '衰退', '崩溃', '破产', '倒闭', '关闭', '停产', '裁员' ]
neutral_words = [ '发布', '公布', '宣布', '表示', '称', '表明', '显示', '报告', '统计', '数据', '信息', '消息', '新闻', '通知', '公告', '声明', '说明', '介绍', '分析', '研究', '调查' ]
sentiment_results = { 'platform_sentiment': {}, 'overall_sentiment': { 'positive': 0, 'negative': 0, 'neutral': 0, 'total': 0 }, 'sentiment_keywords': { 'positive_keywords': [], 'negative_keywords': [], 'neutral_keywords': [] }, 'detailed_analysis': [] }
all_positive = 0 all_negative = 0 all_neutral = 0 all_total = 0
for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key) items = platform_data.get('data', [])
platform_positive = 0 platform_negative = 0 platform_neutral = 0
for item in items: title = item.get('title', '') content = item.get('desc', '') or item.get('content', '') text = f"{title} {content}".lower()
pos_score = sum(1 for word in positive_words if word in text) neg_score = sum(1 for word in negative_words if word in text) neu_score = sum(1 for word in neutral_words if word in text)
# 计算情感倾向 if pos_score > neg_score and pos_score > neu_score: sentiment = 'positive' platform_positive += 1 elif neg_score > pos_score and neg_score > neu_score: sentiment = 'negative' platform_negative += 1 else: sentiment = 'neutral' platform_neutral += 1
# 记录详细分析 sentiment_results['detailed_analysis'].append({ 'platform': platform_name, 'title': title, 'sentiment': sentiment, 'pos_score': pos_score, 'neg_score': neg_score, 'neu_score': neu_score, 'hot': item.get('hot', ''), 'url': item.get('url', '') })
# 计算平台情感比例 total_items = len(items) if total_items > 0: sentiment_results['platform_sentiment'][platform_name] = { 'positive': platform_positive, 'negative': platform_negative, 'neutral': platform_neutral, 'positive_ratio': platform_positive / total_items * 100, 'negative_ratio': platform_negative / total_items * 100, 'neutral_ratio': platform_neutral / total_items * 100, 'total': total_items }
all_positive += platform_positive all_negative += platform_negative all_neutral += platform_neutral all_total += total_items
# 总体情感统计 if all_total > 0: sentiment_results['overall_sentiment'] = { 'positive': all_positive, 'negative': all_negative, 'neutral': all_neutral, 'total': all_total, 'positive_ratio': all_positive / all_total * 100, 'negative_ratio': all_negative / all_total * 100, 'neutral_ratio': all_neutral / all_total * 100 }
# 提取情感关键词 pos_keywords = Counter() neg_keywords = Counter() neu_keywords = Counter()
for analysis in sentiment_results['detailed_analysis']: keywords = self._extract_keywords(analysis['title']) if analysis['sentiment'] == 'positive': pos_keywords.update(keywords) elif analysis['sentiment'] == 'negative': neg_keywords.update(keywords) else: neu_keywords.update(keywords)
sentiment_results['sentiment_keywords'] = { 'positive_keywords': pos_keywords.most_common(20), 'negative_keywords': neg_keywords.most_common(20), 'neutral_keywords': neu_keywords.most_common(20) }
logger.info(f"情感分析完成,分析了 {all_total} 条内容") return sentiment_results
except Exception as e: logger.error(f"情感分析失败:{e}") return {}
def trend_prediction(self, days_ahead: int = 7) -> Dict: """趋势预测功能
<i> Args:</i> days_ahead (int): 预测未来几天
<i> Returns:</i> Dict: 趋势预测结果 """ if not self.hot_data: logger.warning("没有热点数据,请先执行数据获取") return {}
try: # 收集当前热点关键词 current_keywords = Counter() platform_trends = {}
for platform_key, platform_data in self.hot_data.items(): platform_name = self.platforms.get(platform_key, platform_key) items = platform_data.get('data', [])
platform_keywords = Counter() hot_values = []
for item in items: title = item.get('title', '') keywords = self._extract_keywords(title) platform_keywords.update(keywords) current_keywords.update(keywords)
# 收集热度值 hot_value = self._extract_numeric_hot(item.get('hot', '0')) hot_values.append(hot_value)
# 计算平台趋势指标 avg_hot = sum(hot_values) / len(hot_values) if hot_values else 0 max_hot = max(hot_values) if hot_values else 0
platform_trends[platform_name] = { 'current_avg_hot': avg_hot, 'current_max_hot': max_hot, 'top_keywords': platform_keywords.most_common(10), 'total_items': len(items) }
# 模拟趋势预测(基于当前数据的简单预测模型) top_keywords = current_keywords.most_common(50) trend_predictions = { 'prediction_date': datetime.now().isoformat(), 'days_ahead': days_ahead, 'keyword_trends': [], 'platform_predictions': {}, 'emerging_topics': [], 'declining_topics': [], 'overall_trend': 'stable' }
# 关键词趋势预测 for keyword, current_freq in top_keywords: # 简单的预测模型:基于当前频率和随机因子 base_trend = random.uniform(0.8, 1.2) # 基础趋势因子 seasonal_factor = 1 + 0.1 * math.sin(2 * math.pi * days_ahead / 30) # 季节性因子
predicted_freq = int(current_freq * base_trend * seasonal_factor) trend_direction = 'rising' if predicted_freq > current_freq else 'falling' if predicted_freq < current_freq else 'stable' confidence = random.uniform(0.6, 0.9)
trend_predictions['keyword_trends'].append({ 'keyword': keyword, 'current_frequency': current_freq, 'predicted_frequency': predicted_freq, 'trend_direction': trend_direction, 'change_percentage': ((predicted_freq - current_freq) / current_freq * 100) if current_freq > 0 else 0, 'confidence': confidence })
# 平台预测 for platform_name, current_data in platform_trends.items(): trend_factor = random.uniform(0.9, 1.1) predicted_avg = current_data['current_avg_hot'] * trend_factor predicted_max = current_data['current_max_hot'] * trend_factor
trend_predictions['platform_predictions'][platform_name] = { 'current_metrics': current_data, 'predicted_avg_hot': predicted_avg, 'predicted_max_hot': predicted_max, 'trend_direction': 'rising' if trend_factor > 1 else 'falling' if trend_factor < 1 else 'stable', 'confidence': random.uniform(0.7, 0.9) }
# 识别新兴和衰落话题 sorted_trends = sorted(trend_predictions['keyword_trends'], key=lambda x: x['change_percentage'], reverse=True)
trend_predictions['emerging_topics'] = [ { 'keyword': item['keyword'], 'growth_rate': item['change_percentage'], 'confidence': item['confidence'] } for item in sorted_trends[:10] if item['change_percentage'] > 10 ]
trend_predictions['declining_topics'] = [ { 'keyword': item['keyword'], 'decline_rate': abs(item['change_percentage']), 'confidence': item['confidence'] } for item in sorted_trends[-10:] if item['change_percentage'] < -10 ]
# 整体趋势判断 avg_change = sum(item['change_percentage'] for item in trend_predictions['keyword_trends']) / len(trend_predictions['keyword_trends']) if avg_change > 5: trend_predictions['overall_trend'] = 'rising' elif avg_change < -5: trend_predictions['overall_trend'] = 'declining' else: trend_predictions['overall_trend'] = 'stable'
logger.info(f"趋势预测完成,预测未来 {days_ahead} 天的趋势") return trend_predictions
except Exception as e: logger.error(f"趋势预测失败:{e}") return {}
def export_all_data(self, include_analysis: bool = True) -> str: """导出所有数据和分析结果
<i> Args:</i> include_analysis (bool): 是否包含分析结果
<i> Returns:</i> str: 导出文件路径 """ try: timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") filename = f"complete_analysis_{timestamp}.json"
export_data = { 'metadata': { 'export_time': datetime.now().isoformat(), 'total_platforms': len(self.hot_data), 'api_base_url': self.base_url, 'export_type': 'complete_analysis' }, 'raw_data': self.hot_data }
if include_analysis: # 执行所有分析 logger.info("正在执行完整分析...")
# 基础分析 if not self.analysis_results: self.analyze_hot_content() export_data['basic_analysis'] = self.analysis_results
# 关键词统计 keyword_stats = self.get_keyword_statistics() export_data['keyword_statistics'] = keyword_stats
# 情感分析 sentiment_results = self.sentiment_analysis() export_data['sentiment_analysis'] = sentiment_results
# 趋势预测 trend_results = self.trend_prediction() export_data['trend_prediction'] = trend_results
# 平台排行 ranking_count = self.get_platform_ranking('count') ranking_hot = self.get_platform_ranking('avg_hot') export_data['platform_rankings'] = { 'by_count': ranking_count, 'by_average_hot': ranking_hot }
# 生成综合报告 comprehensive_report = self.generate_comprehensive_report( keyword_stats, sentiment_results, trend_results ) export_data['comprehensive_report'] = comprehensive_report
# 保存到文件 with open(filename, 'w', encoding='utf-8') as f: json.dump(export_data, f, ensure_ascii=False, indent=2)
logger.info(f"完整数据已导出到:{filename}") return filename
except Exception as e: logger.error(f"导出完整数据失败:{e}") return ""
def generate_comprehensive_report(self, keyword_stats: Dict, sentiment_results: Dict, trend_results: Dict) -> str: """生成综合分析报告
<i> Args:</i> keyword_stats: 关键词统计结果 sentiment_results: 情感分析结果 trend_results: 趋势预测结果
<i> Returns:</i> str: 综合报告 """ report_lines = [] report_lines.append("=" * 80) report_lines.append(" 综合热点分析报告") report_lines.append("=" * 80) report_lines.append("")
# 基础统计 if self.analysis_results: summary = self.analysis_results.get('summary', {}) report_lines.append("📊 基础统计:") report_lines.append(f" • 成功分析平台:{summary.get('successful_platforms', 0)} 个") report_lines.append(f" • 热点内容总数:{summary.get('total_hot_items', 0)} 条") report_lines.append("")
# 情感分析摘要 if sentiment_results: overall = sentiment_results.get('overall_sentiment', {}) report_lines.append("😊 情感分析摘要:") report_lines.append(f" • 积极情感:{overall.get('positive', 0)} 条 ({overall.get('positive_ratio', 0):.1f}%)") report_lines.append(f" • 消极情感:{overall.get('negative', 0)} 条 ({overall.get('negative_ratio', 0):.1f}%)") report_lines.append(f" • 中性情感:{overall.get('neutral', 0)} 条 ({overall.get('neutral_ratio', 0):.1f}%)") report_lines.append("")
# 情感关键词 pos_kw = sentiment_results.get('sentiment_keywords', {}).get('positive_keywords', []) if pos_kw: report_lines.append("🔥 积极情感关键词 TOP10:") for i, (keyword, freq) in enumerate(pos_kw[:10], 1): report_lines.append(f" {i:2d}. {keyword} ({freq} 次)") report_lines.append("")
# 趋势预测摘要 if trend_results: report_lines.append("📈 趋势预测摘要:") report_lines.append(f" • 整体趋势:{trend_results.get('overall_trend', 'unknown')}") report_lines.append(f" • 预测天数:{trend_results.get('days_ahead', 0)} 天")
emerging = trend_results.get('emerging_topics', []) if emerging: report_lines.append(" • 新兴话题:") for topic in emerging[:5]: report_lines.append(f" - {topic['keyword']} (增长 {topic['growth_rate']:.1f}%)")
declining = trend_results.get('declining_topics', []) if declining: report_lines.append(" • 衰落话题:") for topic in declining[:5]: report_lines.append(f" - {topic['keyword']} (下降 {topic['decline_rate']:.1f}%)") report_lines.append("")
# 关键词分析摘要 if keyword_stats: global_kw = keyword_stats.get('global_keywords', {}) top_keywords = global_kw.get('top_keywords', []) if top_keywords: report_lines.append("🏷️ 热门关键词 TOP15:") for i, (keyword, freq) in enumerate(top_keywords[:15], 1): report_lines.append(f" {i:2d}. {keyword:<12} {freq} 次") report_lines.append("")
# 平台分析 if sentiment_results: platform_sentiment = sentiment_results.get('platform_sentiment', {}) report_lines.append("📱 平台情感分析:") for platform, data in list(platform_sentiment.items())[:10]: pos_ratio = data.get('positive_ratio', 0) neg_ratio = data.get('negative_ratio', 0) report_lines.append(f" {platform:<12} 积极:{pos_ratio:5.1f}% 消极:{neg_ratio:5.1f}%") report_lines.append("")
# 生成时间 report_lines.append("⏰ 报告生成信息:") report_lines.append(f" • 生成时间:{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") report_lines.append(f" • 数据来源:{len(self.hot_data)} 个平台") report_lines.append("") report_lines.append("=" * 80)
return "\n".join(report_lines)
def interactive_menu(): """交互式菜单""" print("\n" + "="*60) print(" 功能菜单") print("="*60) print("1. 🔍 执行完整热点分析") print("2. 🔎 关键词搜索") print("3. 📊 关键词统计分析") print("4. 🎯 热点内容过滤") print("5. 🏆 平台排行榜") print("6. 📱 查看可用平台") print("7. 📄 生成关键词报告") print("8. 😊 情感分析") print("9. 📈 趋势预测") print("10. 📋 导出全部数据和分析") print("11. 🌟 综合分析报告") print("0. ❌ 退出程序") print("="*60)
def display_search_results(results: Dict): """显示搜索结果""" if not results or results.get('total_matches', 0) == 0: print("❌ 没有找到匹配的结果") return
print(f"\n🔍 搜索关键词:'{results['keyword']}'") print(f"📊 匹配结果:{results['total_matches']} 条") print("─" * 60)
# 按平台显示结果 for platform, data in results['platform_matches'].items(): print(f"\n📱 {platform} ({data['count']} 条):") for i, item in enumerate(data['items'][:5], 1): # 只显示前 5 条 print(f" {i}. {item['title']}") if item.get('hot'): print(f" 🔥 热度:{item['hot']}") if item.get('url'): print(f" 🔗 链接:{item['url']}") print()
def display_filter_results(results: Dict): """显示过滤结果""" if not results: print("❌ 过滤失败") return
stats = results['statistics'] print(f"\n🎯 过滤结果统计:") print(f" 原始数据:{stats['total_before_filter']} 条") print(f" 过滤后:{stats['total_after_filter']} 条") print(f" 包含平台:{stats['platforms_included']} 个")
if results['filtered_items']: print(f"\n🔥 TOP10 热点内容:") for i, item in enumerate(results['filtered_items'][:10], 1): print(f"{i:2d}. [{item['platform']}] {item['title']}") if item.get('hot'): print(f" 🔥 热度:{item['hot']}") print()
def display_ranking(ranking: Dict): """显示平台排行榜""" if not ranking: print("❌ 排行榜生成失败") return
print(f"\n🏆 平台排行榜 (按{ranking['sort_by']}排序):") print("─" * 60)
for item in ranking['ranking'][:15]: # 显示前 15 名 stats = item['stats'] if ranking['sort_by'] == 'count': value = f"{stats['count']} 条" elif ranking['sort_by'] == 'avg_hot': value = f"{stats['avg_hot']:.1f} 平均热度" else: value = f"{stats['max_hot']:.1f} 最高热度"
print(f"{item['rank']:2d}. {item['platform']:<15} {value}")
def display_sentiment_analysis(sentiment_results: Dict): """显示情感分析结果""" if not sentiment_results: print("❌ 情感分析结果为空") return
overall = sentiment_results.get('overall_sentiment', {}) print(f"\n😊 情感分析总体结果:") print(f" 总计分析:{overall.get('total', 0)} 条内容") print(f" 积极情感:{overall.get('positive', 0)} 条 ({overall.get('positive_ratio', 0):.1f}%)") print(f" 消极情感:{overall.get('negative', 0)} 条 ({overall.get('negative_ratio', 0):.1f}%)") print(f" 中性情感:{overall.get('neutral', 0)} 条 ({overall.get('neutral_ratio', 0):.1f}%)") print("─" * 60)
# 平台情感分布 platform_sentiment = sentiment_results.get('platform_sentiment', {}) if platform_sentiment: print(f"\n📱 各平台情感分布:") for platform, data in list(platform_sentiment.items())[:10]: pos_ratio = data.get('positive_ratio', 0) neg_ratio = data.get('negative_ratio', 0) neu_ratio = data.get('neutral_ratio', 0) print(f" {platform:<12} 积极:{pos_ratio:5.1f}% 消极:{neg_ratio:5.1f}% 中性:{neu_ratio:5.1f}%")
def display_trend_prediction(trend_results: Dict): """显示趋势预测结果""" if not trend_results: print("❌ 趋势预测结果为空") return
print(f"\n📈 趋势预测结果:") print(f" 整体趋势:{trend_results.get('overall_trend', 'unknown')}") print(f" 预测时间:未来 {trend_results.get('days_ahead', 0)} 天") print("─" * 60)
# 新兴话题 emerging = trend_results.get('emerging_topics', []) if emerging: print(f"\n🚀 新兴话题 (预测增长):") for i, topic in enumerate(emerging[:8], 1): print(f" {i:2d}. {topic['keyword']:<15} +{topic['growth_rate']:6.1f}% (置信度:{topic['confidence']*100:.0f}%)")
# 衰落话题 declining = trend_results.get('declining_topics', []) if declining: print(f"\n📉 衰落话题 (预测下降):") for i, topic in enumerate(declining[:8], 1): print(f" {i:2d}. {topic['keyword']:<15} -{topic['decline_rate']:6.1f}% (置信度:{topic['confidence']*100:.0f}%)")
def main(): """主函数 - 程序入口点""" print("🔥 各大平台热点分析程序") print("=" * 70) print("最新功能:") print("✨ 关键词搜索和过滤 📊 关键词统计分析") print("🏆 平台排行榜 🎯 智能内容过滤") print("📄 详细报告生成 😊 情感分析") print("📈 趋势预测 📋 全部数据导出") print("🌟 综合分析报告 🔍 多维度分析") print("=" * 70)
# 创建分析器实例 analyzer = HotAnalyzer() data_loaded = False
while True: try: interactive_menu() choice = input("\n请选择功能 (0-11): ").strip()
if choice == "0": print("👋 谢谢使用,再见!") break
elif choice == "1": print("\n🔍 开始执行完整热点分析...")
# 询问是否指定平台 use_selected = input("是否只分析热门平台?(y/N): ").strip().lower() if use_selected == 'y': selected_platforms = ['weibo', 'zhihu', 'baidu', 'bilibili', 'toutiao', 'ithome', 'csdn'] print(f"📱 将分析以下平台:{', '.join(selected_platforms)}") else: selected_platforms = None print("📱 将分析所有可用平台")
results = analyzer.run_analysis( selected_platforms=selected_platforms, export_formats=['json', 'csv'] )
if results: print("\n✅ 分析完成!") data_loaded = True
# 显示基础统计 summary = results.get('summary', {}) print(f"📊 成功分析 {summary.get('successful_platforms', 0)} 个平台") print(f"📄 总热点条目:{summary.get('total_hot_items', 0)} 条")
# 显示热门关键词 hot_keywords = results.get('hot_keywords', {}) if hot_keywords.get('top_20'): print("\n🔥 热门关键词 TOP10:") for i, (keyword, count) in enumerate(hot_keywords['top_20'][:10], 1): print(f" {i:2d}. {keyword} ({count} 次)") else: print("\n❌ 分析失败,请检查网络连接")
elif choice == "2": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
keyword = input("\n请输入搜索关键词:").strip() if not keyword: print("❌ 关键词不能为空") continue
case_sensitive = input("是否区分大小写?(y/N): ").strip().lower() == 'y'
print(f"\n🔍 正在搜索关键词:'{keyword}'...") search_results = analyzer.search_by_keyword(keyword, case_sensitive) display_search_results(search_results)
elif choice == "3": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
print("\n📊 正在进行关键词统计分析...") keyword_stats = analyzer.get_keyword_statistics(min_length=2, top_k=50)
if keyword_stats: # 显示简要统计 global_kw = keyword_stats.get('global_keywords', {}) print(f"📊 分析了 {keyword_stats.get('total_texts', 0)} 条文本") print(f"🔤 发现 {global_kw.get('total_unique', 0)} 个唯一关键词")
# 显示 TOP10 关键词 top_keywords = global_kw.get('top_keywords', []) if top_keywords: print("\n🔥 热门关键词 TOP10:") for i, (keyword, freq) in enumerate(top_keywords[:10], 1): print(f" {i:2d}. {keyword:<12} {freq} 次")
# 询问是否生成详细报告 gen_report = input("\n是否生成详细关键词报告?(y/N): ").strip().lower() if gen_report == 'y': report = analyzer.generate_keyword_report(keyword_stats) print("\n" + report) else: print("❌ 关键词统计失败")
elif choice == "4": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
print("\n🎯 设置过滤条件:")
# 热度过滤 min_hot = input("最小热度值 (留空跳过): ").strip() min_hot_value = float(min_hot) if min_hot else None
# 平台过滤 platforms_input = input("指定平台 (用逗号分隔,留空表示所有平台): ").strip() platforms = [p.strip() for p in platforms_input.split(',')] if platforms_input else None
# 关键词过滤 keywords_input = input("包含关键词 (用逗号分隔,留空跳过): ").strip() keywords = [k.strip() for k in keywords_input.split(',')] if keywords_input else None
print("\n🎯 正在过滤热点内容...") filter_results = analyzer.filter_hot_items( min_hot_value=min_hot_value, platforms=platforms, keywords=keywords ) display_filter_results(filter_results)
elif choice == "5": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
print("\n🏆 选择排序方式:") print("1. 按热点数量排序") print("2. 按平均热度排序") print("3. 按最高热度排序")
sort_choice = input("请选择 (1-3): ").strip() sort_map = {'1': 'count', '2': 'avg_hot', '3': 'max_hot'} sort_by = sort_map.get(sort_choice, 'count')
print(f"\n🏆 正在生成平台排行榜...") ranking = analyzer.get_platform_ranking(sort_by) display_ranking(ranking)
elif choice == "6": print(f"\n📱 可用平台总数:{len(analyzer.platforms)}") print("\n平台列表:") platforms_list = list(analyzer.platforms.items()) for i in range(0, len(platforms_list), 3): row = platforms_list[i:i+3] row_str = " ".join([f"{key}: {value}" for key, value in row]) print(f" {row_str}")
elif choice == "7": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
print("\n📄 正在生成关键词分析报告...") keyword_stats = analyzer.get_keyword_statistics() if keyword_stats: report = analyzer.generate_keyword_report(keyword_stats) print("\n" + report)
# 询问是否保存报告 save_report = input("\n是否保存报告到文件?(y/N): ").strip().lower() if save_report == 'y': filename = f"keyword_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt" with open(filename, 'w', encoding='utf-8') as f: f.write(report) print(f"📄 报告已保存到:{filename}") else: print("❌ 生成报告失败")
elif choice == "8": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
print("\n😊 正在进行情感分析...") sentiment_results = analyzer.sentiment_analysis()
if sentiment_results: overall = sentiment_results.get('overall_sentiment', {}) print(f"\n📊 情感分析结果:") print(f" 总计分析:{overall.get('total', 0)} 条内容") print(f" 积极情感:{overall.get('positive', 0)} 条 ({overall.get('positive_ratio', 0):.1f}%)") print(f" 消极情感:{overall.get('negative', 0)} 条 ({overall.get('negative_ratio', 0):.1f}%)") print(f" 中性情感:{overall.get('neutral', 0)} 条 ({overall.get('neutral_ratio', 0):.1f}%)")
# 显示各平台情感分布 platform_sentiment = sentiment_results.get('platform_sentiment', {}) if platform_sentiment: print(f"\n📱 各平台情感分布:") for platform, data in list(platform_sentiment.items())[:8]: pos_ratio = data.get('positive_ratio', 0) neg_ratio = data.get('negative_ratio', 0) print(f" {platform:<12} 积极:{pos_ratio:5.1f}% 消极:{neg_ratio:5.1f}%")
# 显示情感关键词 sentiment_kw = sentiment_results.get('sentiment_keywords', {}) pos_kw = sentiment_kw.get('positive_keywords', []) if pos_kw: print(f"\n🔥 积极情感关键词 TOP10:") for i, (keyword, freq) in enumerate(pos_kw[:10], 1): print(f" {i:2d}. {keyword} ({freq} 次)")
neg_kw = sentiment_kw.get('negative_keywords', []) if neg_kw: print(f"\n❄️ 消极情感关键词 TOP10:") for i, (keyword, freq) in enumerate(neg_kw[:10], 1): print(f" {i:2d}. {keyword} ({freq} 次)") else: print("❌ 情感分析失败")
elif choice == "9": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
days_input = input("\n预测未来几天?(默认 7 天): ").strip() days_ahead = int(days_input) if days_input.isdigit() else 7
print(f"\n📈 正在进行趋势预测(未来{days_ahead}天)...") trend_results = analyzer.trend_prediction(days_ahead)
if trend_results: print(f"\n📊 趋势预测结果:") print(f" 整体趋势:{trend_results.get('overall_trend', 'unknown')}") print(f" 预测时间:未来 {trend_results.get('days_ahead', 0)} 天")
# 显示新兴话题 emerging = trend_results.get('emerging_topics', []) if emerging: print(f"\n🚀 新兴话题 TOP5:") for i, topic in enumerate(emerging[:5], 1): print(f" {i}. {topic['keyword']} (预测增长 {topic['growth_rate']:.1f}%)")
# 显示衰落话题 declining = trend_results.get('declining_topics', []) if declining: print(f"\n📉 衰落话题 TOP5:") for i, topic in enumerate(declining[:5], 1): print(f" {i}. {topic['keyword']} (预测下降 {topic['decline_rate']:.1f}%)")
# 显示平台趋势 platform_pred = trend_results.get('platform_predictions', {}) if platform_pred: print(f"\n📱 平台趋势预测:") for platform, pred in list(platform_pred.items())[:8]: trend_dir = pred.get('trend_direction', 'stable') confidence = pred.get('confidence', 0) * 100 print(f" {platform:<12} 趋势:{trend_dir:<8} 置信度:{confidence:.0f}%") else: print("❌ 趋势预测失败")
elif choice == "10": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
print("\n📋 正在导出全部数据和分析结果...") filename = analyzer.export_all_data(include_analysis=True)
if filename: print(f"✅ 完整数据已导出到:{filename}") print("📊 导出内容包括:") print(" • 原始热点数据") print(" • 基础统计分析") print(" • 关键词统计") print(" • 情感分析结果") print(" • 趋势预测数据") print(" • 平台排行榜") print(" • 综合分析报告") else: print("❌ 数据导出失败")
elif choice == "11": if not data_loaded: print("⚠️ 请先执行完整分析加载数据") continue
print("\n🌟 正在生成综合分析报告...")
# 获取所有分析结果 keyword_stats = analyzer.get_keyword_statistics() sentiment_results = analyzer.sentiment_analysis() trend_results = analyzer.trend_prediction()
if keyword_stats and sentiment_results and trend_results: comprehensive_report = analyzer.generate_comprehensive_report( keyword_stats, sentiment_results, trend_results ) print("\n" + comprehensive_report)
# 询问是否保存报告 save_report = input("\n是否保存综合报告到文件?(y/N): ").strip().lower() if save_report == 'y': filename = f"comprehensive_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt" with open(filename, 'w', encoding='utf-8') as f: f.write(comprehensive_report) print(f"📄 综合报告已保存到:{filename}") else: print("❌ 生成综合报告失败")
else: print("❌ 无效选择,请重新输入")
except KeyboardInterrupt: print("\n⚠️ 用户中断操作") continue except Exception as e: logger.error(f"程序执行异常:{e}") print(f"\n❌ 操作出错:{e}") continue
if __name__ == "__main__": main()3. 面向不同人群的应用场景
开放的 API 意味着无限的可能性。不同角色的人可以基于同样的数据源,构建出完全符合自己需求的应用。下面我将展示几个具体的应用场景,希望能抛砖引玉,激发更多创意。
3.1 产品经理:洞察市场趋势与竞品动态
对于产品经理(PM)来说,持续关注市场动态、用户反馈和竞品动向是日常工作的重中之重。通过 DailyHot API,PM 可以打造一个轻量级的自动化舆情监控和行业趋势分析工具。
例如,一个负责 AI Agent 产品的 PM,需要密切关注 V2EX、36 氪、虎嗅等平台上关于”AI”、“Agent”、“LLM”等关键词的讨论,同时监控竞品(如 Moonshot AI、Inflection)的声量。
代码示例:产品经理市场洞察脚本
import requestsfrom datetime import datetime
API_BASE_URL = "https://d06171702-dailyhot10-318-czfurtsr-6688.550c.cloud"
class MarketInsightTool: def __init__(self, base_url, platforms, keywords, competitors): self.base_url = base_url self.platforms = platforms # 要监控的平台 self.keywords = keywords # 行业关键词 self.competitors = competitors # 竞品关键词 self.session = requests.Session() self.session.timeout = 20
def get_platform_data(self, platform): """获取单个平台数据""" try: response = self.session.get(f"{self.base_url}/{platform}") if response.status_code == 200: data = response.json() if data.get('code') == 200: return data.get('data', []) except requests.RequestException as e: print(f"[错误] 获取 {platform} 数据失败:{e}") return []
def run_analysis(self): """执行分析并生成报告""" print("=" * 60) print(f"📈 市场洞察报告 - {datetime.now().strftime('%Y-%m-%d')}") print("=" * 60)
for platform in self.platforms: print(f"\n【平台:{platform.upper()}】") items = self.get_platform_data(platform) if not items: print(" -> 未获取到数据或平台不支持。") continue
found_items = [] all_keywords = self.keywords + self.competitors
for item in items: title = item.get('title', '').lower() for keyword in all_keywords: if keyword.lower() in title: found_items.append({ "keyword": keyword, "title": item.get('title'), "url": item.get('url'), "hot": item.get('hot', 'N/A') }) break
if found_items: print(f" -> 发现 {len(found_items)} 条相关热点:") for found in found_items: print(f" - [{found['keyword']}] {found['title']}") print(f" 热度:{found['hot']} | 链接:{found['url']}") else: print(" -> 未发现相关热点。")
def main(): # --- 配置监控参数 --- # 关注的平台 target_platforms = ['v2ex', '36kr', 'huxiu', 'juejin', 'hackernews'] # 关注的行业关键词 industry_keywords = ['AI', 'Agent', 'LLM', '多模态'] # 关注的竞品 competitor_keywords = ['Moonshot', 'Inflection', 'Perplexity']
tool = MarketInsightTool(API_BASE_URL, target_platforms, industry_keywords, competitor_keywords) tool.run_analysis()
if __name__ == "__main__": main()根据自己的产品和行业,修改 target_platforms, industry_keywords, competitor_keywords 列表。脚本会输出一份按平台分类的日报,清晰地列出在各大科技媒体和开发者社区中,与你所设定的关键词相关的热门讨论。这能帮助 PM 快速捕捉到最新的技术趋势、用户需求和竞品动态,为产品规划和迭代提供数据支持。
3.2 开源爱好者:发掘潜力项目与技术风向
对于开源爱好者和开发者而言,GitHub、Hacker News、V2EX 等平台是每日必逛的”寻宝地”。通过 DailyHot API,可以轻松打造一个个性化的技术雷达,自动发现热门的开源项目和前沿技术讨论。
代码示例:开源技术雷达脚本
import requestsfrom datetime import datetime
API_BASE_URL = "https://d06171702-dailyhot10-318-czfurtsr-6688.550c.cloud"
def discover_open_source_trends(platforms, tech_keywords): """发现开源趋势""" print("=" * 60) print(f"🚀 开源技术雷达 - {datetime.now().strftime('%Y-%m-%d')}") print(f"关注技术:{', '.join(tech_keywords)}") print("=" * 60)
with requests.Session() as session: for platform in platforms: print(f"\n【平台:{platform.upper()}】") try: response = session.get(f"{API_BASE_URL}/{platform}", timeout=15) if response.status_code == 200 and response.json().get('code') == 200: items = response.json().get('data', [])
# 1. 发现包含特定技术的热门项目 print(" [*] 关键词匹配项目:") found_count = 0 for item in items: title = item.get('title', '').lower() if any(keyword.lower() in title for keyword in tech_keywords): found_count += 1 print(f" - {item.get('title')} | 热度:{item.get('hot', 'N/A')}") print(f" 链接:{item.get('url')}") if found_count == 0: print(" - 无")
# 2. 列出该平台总体 Top 3 项目 print("\n [*] 平台 Top 3 热榜:") for i, item in enumerate(items[:3], 1): print(f" {i}. {item.get('title')} | 热度:{item.get('hot', 'N/A')}")
else: print(f" -> 获取数据失败 (Status: {response.status_code})") except requests.RequestException as e: print(f" -> 请求异常:{e}")
def main(): # 关注的平台 source_platforms = ['github', 'hackernews', 'v2ex'] # 关注的技术领域 keywords = ['Rust', 'WebAssembly', 'AI Agent', 'Sora']
discover_open_source_trends(source_platforms, keywords)
if __name__ == "__main__": main()在 keywords 列表中定义你感兴趣的技术关键词。脚本会扫描 GitHub、Hacker News 等平台,并输出两类信息:一是包含你所关注技术的热门项目,二是不限领域的平台总热榜 Top 3。这就像有了一个不知疲倦的助手,每天帮你筛选出最值得关注的技术和项目,让你始终保持在技术浪潮的前沿。
3.3 运营人员:捕捉热点与舆情监控
对于新媒体运营和市场人员来说,“追热点”和”造内容”是日常。DailyHot API 聚合了微博、Bilibili、抖音、知乎等主流内容平台的热榜,是绝佳的内容创意来源和品牌舆情哨站。
代码示例:运营热点追踪脚本
import requestsimport jsonfrom datetime import datetime
API_BASE_URL = "https://d06171702-dailyhot10-318-czfurtsr-6688.550c.cloud"
def track_social_hotspots(platforms, brand_keywords): """追踪社交热点和品牌声量""" print("=" * 60) print(f"💡 运营热点与品牌舆情 - {datetime.now().strftime('%Y-%m-%d')}") print("=" * 60)
with requests.Session() as session: for platform in platforms: print(f"\n【平台:{platform.upper()}】") try: response = session.get(f"{API_BASE_URL}/{platform}", timeout=15) data = response.json() if response.status_code == 200 and data.get('code') == 200: items = data.get('data', [])
# 1. 输出 Top 5 热点作为内容创作灵感 print(" [+] 今日热点 Top 5 (内容灵感):") for i, item in enumerate(items[:5], 1): print(f" {i}. {item.get('title')} (热度:{item.get('hot', 'N/A')})")
# 2. 扫描品牌关键词,进行舆情监控 print("\n [+] 品牌相关舆情:") found_mentions = 0 for item in items: title = item.get('title', '').lower() if any(keyword.lower() in title for keyword in brand_keywords): found_mentions += 1 print(f" - 发现提及:\"{item.get('title')}\"") print(f" 链接:{item.get('url')}") if found_mentions == 0: print(" - 未发现品牌相关内容。")
else: print(f" -> 获取数据失败。") except requests.RequestException as e: print(f" -> 请求异常:{e}")
def main(): # 主要监控的内容平台 content_platforms = ['weibo', 'bilibili', 'douyin', 'zhihu'] # 监控的品牌名或产品名 brand_names = ['我们的产品 A', 'OurProductB']
track_social_hotspots(content_platforms, brand_names)
if __name__ == "__main__": main()在 brand_names 中填入自己的品牌或产品关键词。该脚本能快速提供两大价值:一是各大社交媒体平台最热门的 5 个话题,为内容创作提供灵感;二是在这些热榜中自动搜索品牌关键词,一旦发现相关讨论,立即高亮显示,起到基础的舆情监控作用。
3.4 普通用户:构建个人化信息流
在算法推荐大行其道的今天,我们接收到的信息往往是平台”想让我们看到的”。利用 DailyHot API,任何一个普通用户都可以轻松打破信息茧房,打造一个完全由自己掌控的、无干扰的”个人专属头条”。
代码示例:个人化每日简报
import requestsfrom datetime import datetime
API_BASE_URL = "https://d06171702-dailyhot10-318-czfurtsr-6688.550c.cloud"
def generate_personal_briefing(interests): """生成个性化每日简报""" print("=" * 70) print(f"📬 您的专属热点简报 - {datetime.now().strftime('%Y-%m-%d %H:%M')}") print("=" * 70)
with requests.Session() as session: for topic, details in interests.items(): print(f"\n--- {topic} ---") platforms = details['platforms'] keywords = details['keywords']
all_matched_items = []
for platform in platforms: try: response = session.get(f"{API_BASE_URL}/{platform}", timeout=15) data = response.json() if response.status_code == 200 and data.get('code') == 200: for item in data.get('data', []): title = item.get('title', '').lower() if any(keyword.lower() in title for keyword in keywords): all_matched_items.append(item) except requests.RequestException: continue # 忽略获取失败的平台
if all_matched_items: # 按热度粗略排序(提取数字部分) all_matched_items.sort(key=lambda x: int(str(x.get('hot', '0')).split()[0].replace(',', '')) if str(x.get('hot', '0')).split()[0].replace(',', '').isdigit() else 0, reverse=True) for i, item in enumerate(all_matched_items[:5], 1): # 每个主题显示 5 条 print(f" {i}. {item.get('title')}") print(f" 链接:{item.get('url')}") else: print(f" 今天在 {', '.join(platforms)} 没有发现你关心的内容。")
def main(): # 定义你的兴趣领域、想看的平台和关键词 my_interests = { "科技与 AI": { "platforms": ["36kr", "ithome", "juejin", "github"], "keywords": ["AI", "芯片", "鸿蒙", "Apple"] }, "轻松一刻": { "platforms": ["weibo", "douyin", "bilibili"], "keywords": ["电影", "游戏", "旅行"] }, "财经动态": { "platforms": ["sina-news", "thepaper"], "keywords": ["财报", "市场", "央行"] } }
generate_personal_briefing(my_interests)
if __name__ == "__main__": main()核心是修改 my_interests 字典。你可以自由定义自己感兴趣的主题(如 “科技与 AI”),并为每个主题配置想看哪些平台(platforms)和关心哪些关键词(keywords)。
运行脚本:python my_briefing.py。你可以设置一个定时任务,让它每天早上自动运行。
运行后,你会得到一份完全为你量身定制的”报纸”。它不受任何算法干扰,只包含你明确定义过感兴趣的内容,并且信息源头多样化。这是一种复古而又高效的信息获取方式,能帮你夺回信息消费的主动权。
4.总结
DailyHot 的价值,不在于它告诉了我们“世界在想什么”,而在于它把“世界在聊什么”的开关交到了我们手上。它剥离了推荐算法的层层包裹,让信息回归到最朴素的聚合状态。无论是通过简洁的 Web 页面快速浏览,还是利用开放的 API 深度定制,其核心都在于一点:让我们在信息的洪流中,重新掌握选择的主动权。
这次技术体验证明,打破信息茧房、构建个人化的信息流,并非遥不可及。一个聚合热榜的工具,加上一点代码的创造力,就能成为我们对抗信息过载、提升认知效率的实用武器。在算法的时代,能主动选择“看什么”和“怎么看”,本身就是一种珍贵的能力。DailyHot 提供的就是这样一把钥匙,至于用它打开什么样的信息世界,则完全取决于我们自己。
原项目仓库地址:https://github.com/imsyy/DailyHotApi
共绩算力平台预制镜像 开箱即用 无需环境配置等:https://console.suanli.cn/serverless/create