
此前,Z-Image-Turbo 凭借 8 步极速出图 的优势受到广泛欢迎,但同时也存在 不支持负面提示词、微调难度较大、风格相对单一 等问题。
就在刚刚,阿里通义实验室(Tongyi Lab)正式开源了 Z-Image (Base) 基座模型!
这次不是“阉割版”,而是真正的非蒸馏、全功能版本。
很多小伙伴问:“我有 Turbo 了,为什么还要用 Base?”
简单来说,Turbo 是为了“快”,而 Base 是为了“强”和“准”。它是整个 Z-Image 家族的基石,专为追求最高创作自由度的开发者、研究员和专业创作者设计。
硬核拆解:Z-Image 究竟强在哪?
根据官方技术文档和我们的实测,Z-Image 的强悍主要体现在以下 5 个维度:
S3-DiT 架构:原生中文理解的秘密
不同于传统的双流架构,Z-Image 采用了 S3-DiT (Scalable Single-Stream Diffusion Transformer)。
原理:它将文本、视觉语义 Token 和图像 VAE Token 放在同一个流中处理。
效果:这种深度的跨模态交互,让它对提示词的理解达到了新高度。这也是为什么它能精准渲染中英双语文字的核心原因——它真的“看懂”了你的 Prompt。

非蒸馏基座 (Undistilled Foundation)
这是一个完整的、保留了所有训练信号的 Transformer 模型。
- 支持 CFG (Classifier-Free Guidance):你可以像控制 SDXL 一样,通过调整 CFG Scale (推荐 3.0-5.0) 来平衡画面的创造力和对提示词的忠实度。
- 支持负面提示词 (Negative Prompting):Turbo 版做不到的“去伪影”、“去多余手指”,Base 版轻松搞定。这对专业工作流至关重要。
审美与风格的“全能王” (Aesthetic Versatility)
Z-Image 不偏科。官方数据显示,它掌握了极广的视觉语言:
- 超写实摄影:皮肤纹理、光影质感逼真。
- 电影级数字艺术:构图宏大,氛围感拉满。
- 动漫与插画:二次元风格也能驾驭。
惊人的输出多样性 (Enhanced Output Diversity)
这是 Base 版最让我们惊喜的地方。
在 Turbo 版中,你可能会发现不同 Seed 生成的人脸长得差不多。但在 Base 版中,构图、人脸特征、光影布局在不同 Seed 下变化丰富。这对于生成多人场景或寻找灵感非常关键。
炼丹师的完美底座 (Built for Development)
因为它未被蒸馏,结构完整,所以它是训练 LoRA、ControlNet 的最佳选择。如果你想训练一个特定画风的模型,请务必使用 Base 版而不是 Turbo 版。
实测对比:Z-Image (Base) vs Turbo vs Qwen-Image
为了让大家直观感受,共绩技术团队第一时间在 5090 上进行了对比测试。我们选取了几个典型场景,对比了 Z-Image-Turbo(极速版)、Z-Image (Base)(满血版)以及 Qwen-Image 的表现。
甜酷眨眼半身人像(人像细节与神态)
Prompt:
一、主体与氛围目标
1 主体:年轻女性中景人像,上半身占画面主体,直视镜头
2 氛围:甜酷俏皮但不幼态,带一点英气与自信的表情气质
3 动作表情:左眼眨眼,右眼睁开有神;轻微微笑,嘴角上扬
4 视线关系:眼部对焦镜头,强互动感

甜酷眨眼对比
点评:
- Z-Image (Base):人物神态最自然,皮肤质感细腻,眨眼动作标准,且保留了“甜酷”的气质。
- Z-Image-Turbo:生成速度极快,但在这个复杂表情(单眼眨眼)上,偶尔会出现双眼不一致或表情僵硬的情况。
- Qwen-Image:构图工整,但在此风格下,皮肤质感略显平滑。
咖啡馆招牌(中英文字渲染能力)
Prompt:
竖幅写真照片风格,一名年轻女性站在咖啡馆门口,镜头中景半身人像,暖白色柔光,皮肤细腻自然。背景是干净的奶油白墙面与木质门框,门头挂着一个清晰可读的招牌,上面写着中文“共绩算力”以及英文“GONGJI COMPUTE”,字体工整、边缘锐利、无乱码。整体画面干净、通透、低反差,轻微胶片质感,背景元素简洁不过度花哨,人物与招牌同时清晰但人脸更锐。

咖啡馆招牌对比
点评:
Z-Image (Base):文字渲染能力最强。中文“共绩算力”笔画清晰,英文拼写正确,且招牌与环境光影融合得非常好。
Turbo & Qwen:也能生成文字,但在复杂笔画或长文本的排版上,Base 版的稳定性明显更高。
二次元插画风格(风格多样性)
Prompt:
日系动漫风格插画,一名少女站在樱花树下,长发随风飘动,身穿白色衬衫与深蓝色百褶裙,手持一本精装书。背景是虚化的粉色樱花与蓝天,画面清新明亮,线条干净,色彩柔和。人物大眼睛、精致五官,略带透明感的皮肤与高光。竖幅构图,上半身与部分背景,插画质感,无照片噪点。
二次元插画对比
点评:Z-Image (Base):展现了惊人的风格可塑性。它不仅能画写实人像,切换到二次元风格时,线条和上色都非常地道,没有“AI 伪厚涂感”。
强负面词控图(Robust Negative Control)
Prompt:
年轻女性半身人像,纯白背景,穿简约黑色上衣,自然微笑直视镜头。皮肤通透、妆容清淡,发型简洁马尾。摄影棚柔光,高清人像,肤色均匀,无多余道具。
Negative Prompt: blurry, out of focus, lowres, jpeg artifacts, ugly, bad anatomy, deformed, extra fingers, extra arms, extra legs, bad hands, missing fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, extra limbs, malformed limbs, disfigured, gross proportions, long neck, long body, text, watermark, logo, nsfw, cartoon, anime, illustration, worst quality, low quality

强负面词控图对比
点评:这是 Base 版的杀手锏。由于支持 Negative Prompt,我们可以通过堆叠负面词来精准过滤掉畸变、多余手指等瑕疵,画面纯净度远超不支持负面词的 Turbo 版。
更多实测场景展示
为了全面评估,我们还测试了以下场景:
- 电影感肖像 (Cinematic Portrait)
展现 Z-Image Base 在光影和皮肤质感上的极致表现。
Prompt: 电影级数字艺术风格,超写实摄影。一名亚洲女性侧脸特写,柔和的伦勃朗光从侧面打来,鼻梁与颧骨轮廓清晰,背景完全虚化的深色。眼神略带忧郁,嘴唇微张。肤质细腻保留毛孔与肌理,电影胶片质感,低饱和、高对比度,以藏青与暖棕为主色调。竖幅构图,人物居中,景深极浅,仅眼部到鼻尖清晰。

电影感肖像对比
- 多人合影 (Diversity Test)
拒绝“千人一面”,三人合影中每张脸都有独特特征。
Prompt: 三名年轻女性站成一排的合影,背景为浅灰墙面。从左到右:第一位长发戴眼镜穿米色针织衫,第二位短发穿黑色高领毛衣,第三位中长发穿白色衬衫。三人表情自然各异,有的微笑有的严肃,光线从左侧窗来,在三人脸上形成不同明暗。照片风格,自然光,中等景深,面部均清晰,服装与发型区分明显,整体休闲时尚。

多人合影对比
- 电商白底图 (E-commerce)
干净、通透,适合商用的产品图生成。
Prompt: 电商白底商品图,竖幅构图,纯白偏暖背景无任何纹理。主体是一个米杏色针织护手套(露指长护手),质地厚实,针织纹理清晰但不过锐。护手套上有一个棕色格纹蝴蝶结装饰,细节干净无毛边。画面光源为柔光箱式漫射软光,阴影极轻,整体高明度、低反差,颜色真实,细节丰富。商品居中但左右留出明显空白,适合电商主图。

电商白底图对比
- 官方示例复刻 (Two Girls)
经典的双人合影 Prompt 复刻。
Prompt: 两名年轻亚裔女性紧密站在一起,背景为朴素的灰色纹理墙面,可能是室内地毯地面。左侧女性留着长卷发,身穿藏青色毛衣,左袖有奶油色褶皱装饰,内搭白色立领衬衫,下身白色裤子;佩戴小巧金色耳钉,双臂交叉于背后。右侧女性留直肩长发,身穿奶油色卫衣,胸前印有“Tun the tables”字样,下方为“New ideas”,搭配白色裤子;佩戴银色小环耳环,双臂交叉于胸前。两人均面带微笑直视镜头。照片,自然光照明,柔和阴影,以藏青、奶油白为主的中性色调,休闲时尚摄影,中等景深,面部和上半身对焦清晰,姿态放松,表情友好,室内环境,地毯地面,纯色背景。

官方示例复刻对比

实测结论:如果你是做视频拆解、风格化训练或者对画面有极致要求的专业玩家,Z-Image Base 才是你的主力军。Turbo 更适合用来快速抽卡验证灵感。
为什么 Z-Image 是创作者的理想选择?
引用社区(小红书@通义大模型)的精准总结,Z-Image 不仅仅是一个模型,更是创意落地的“稳定引擎”:
- 风格无界 · 审美不设限
打破了单一维度的写实局限。无论是追求光影极致的 Photorealism,还是极具情绪张力的动漫与数字艺术,Z-Image 均能精准捕捉并重构每一处风格细节。
- 原生基座 · 微调更友好
非蒸馏基座架构,赋能社区生态。它保留了全量权重分布,原生支持 CFG 引导机制,为 LoRA、ControlNet 等微调任务提供了高上限、高稳健性的训练底座。
- 拒绝同质 · 千人千面
专项优化了生成“同质化”痛点。优化采样空间分布,确保不同原生出图的面孔与构图具备显著差异;多人场景精准剥离个体特征,拒绝 AI“大众脸”。
- 高敏响应 · 精准调度
极高灵敏度的负向提示词响应,赋予创作者指挥家般的调度权。通过 Negative Prompt 快速过滤瑕疵、净化画面,实现从构图到光影的深度掌控。
如何在共绩平台上畅玩 Z-Image Base?
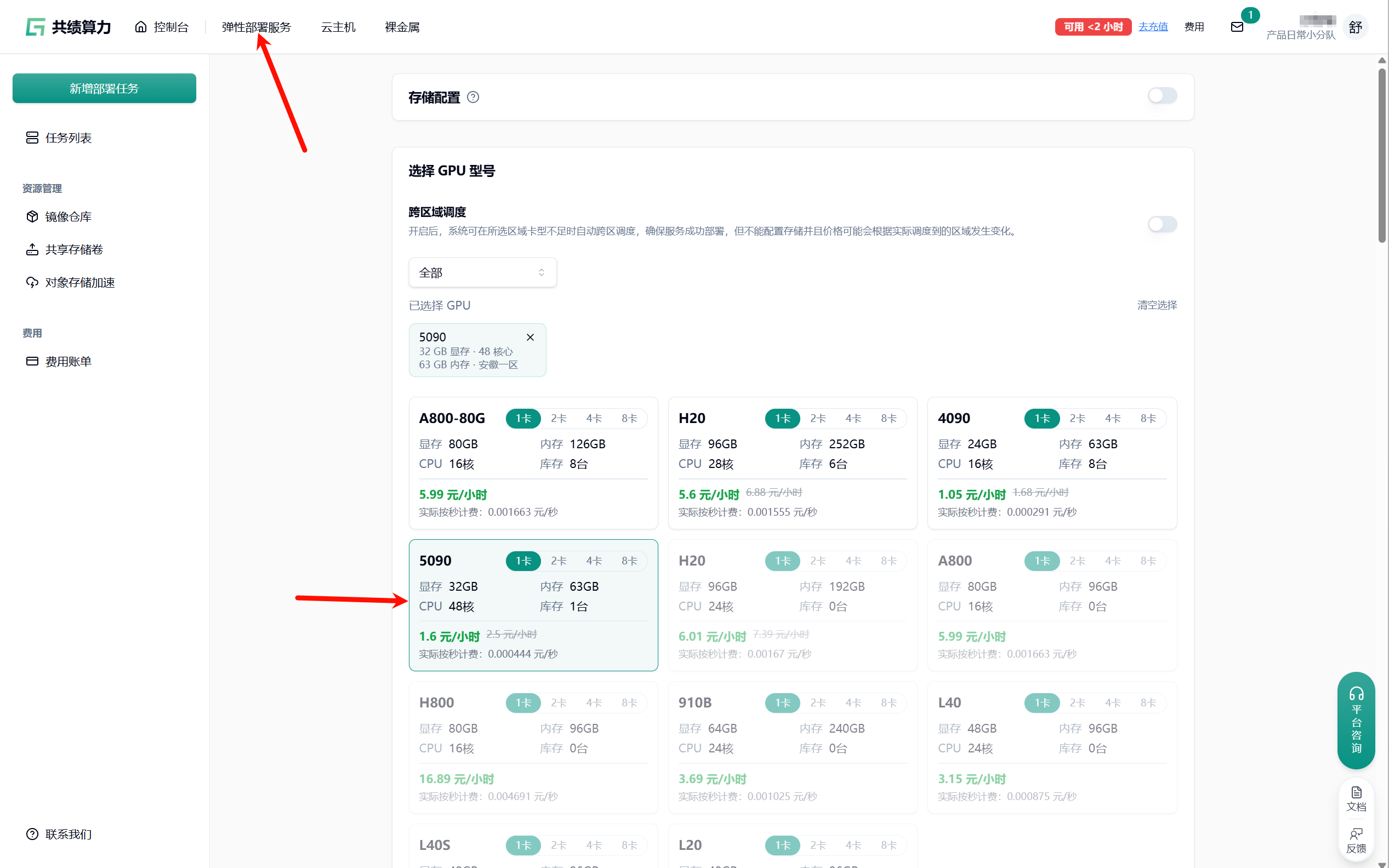
虽然是 6B 参数的大模型,但得益于 S3-DiT 的高效架构,在共绩云的 RTX 5090 (32G) 上,半精度 (bf16) 推理毫无压力!
推荐配置:
- 机型:RTX 5090 (32G) —— 强烈推荐,显存充裕,推理速度快
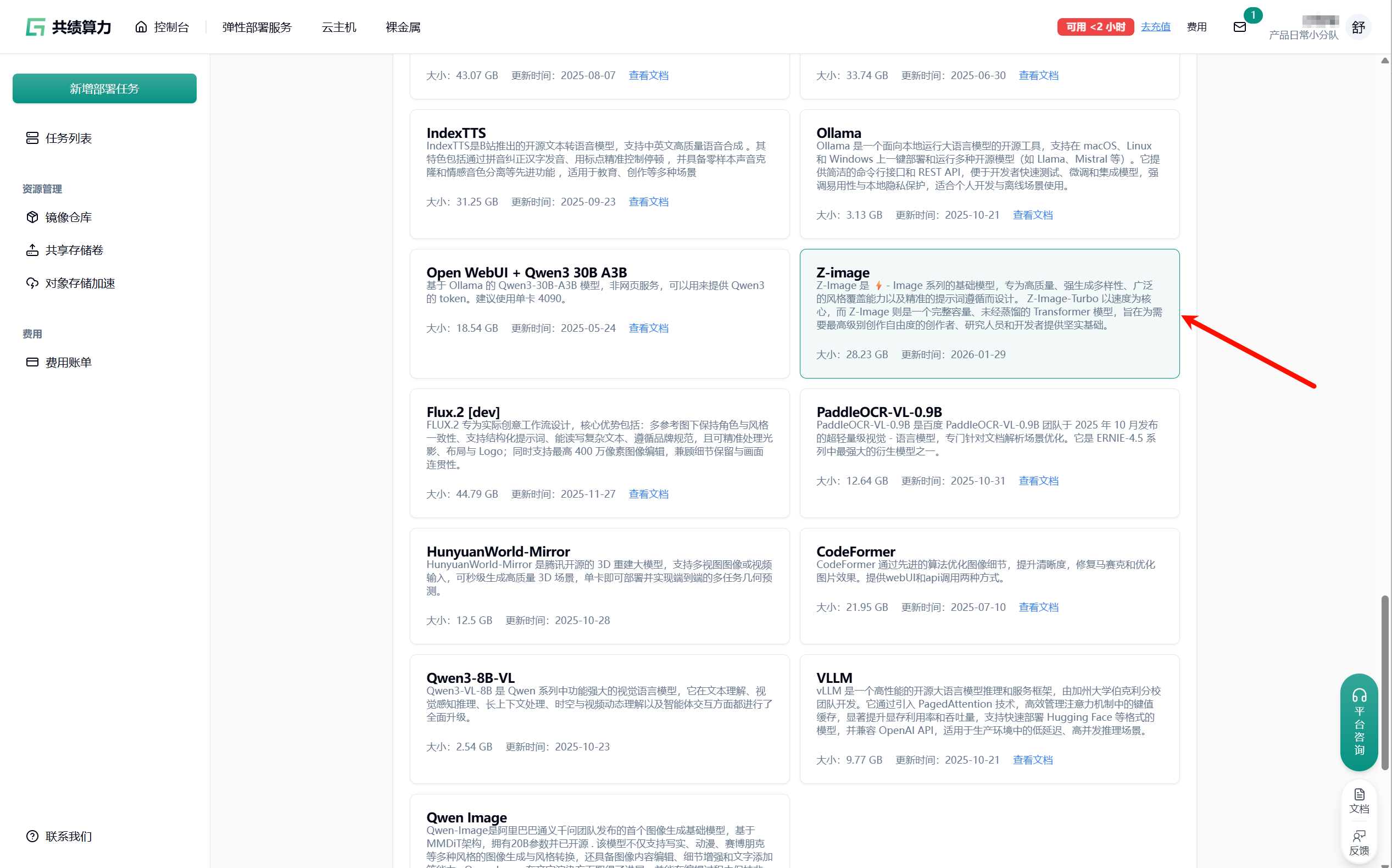
- 镜像:弹性部署服务里面直接选择 Z-image 预制镜像
开始生成:
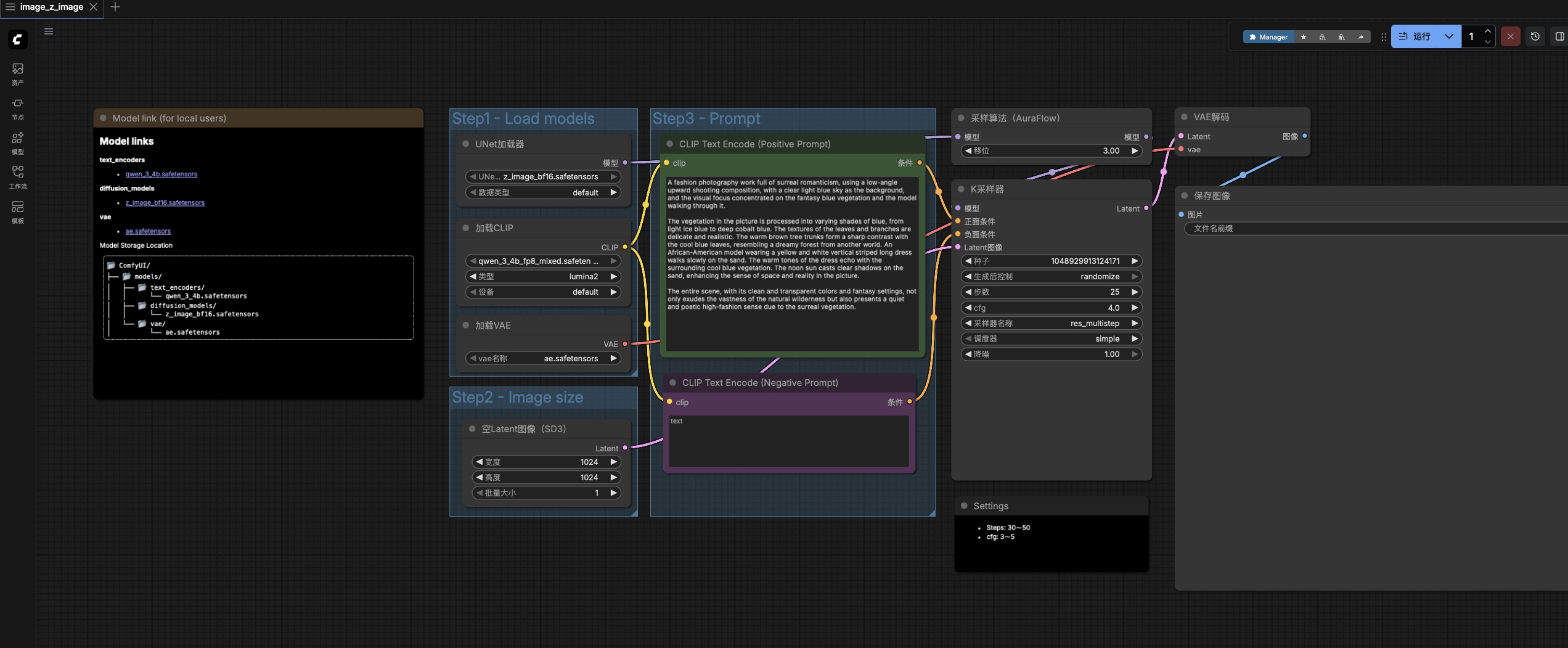
我们为大家准备了 comfyui 工作流,把你的咒语(Prompt)填进去,享受掌控画面的快感吧!
💡 炼丹师请注意:
如果你想基于 Z-Image Base 训练自己的 LoRA,建议使用我们的 H800 或 5090 多卡 集群,效率提升更明显。
封面图 Prompt 分享 (Z-Image Base 直出)
为了验证 Z-Image Base 在复杂光影和文字渲染上的极限,我们生成了本文的封面图。
新海诚风格,绝美天空,巨大的积雨云,夕阳余晖。画面下方是一个现代化的玻璃建筑,楼顶矗立着巨大的发光招牌,清晰写着:“共绩算力 Z-image 30 秒出图”。光影绚丽,色彩鲜艳,画面极具冲击力,8k 壁纸级画质。
算力福利
体验满血版国产大模型,算力必须跟上!
- RTX 5090 低至 ¥2.5/小时
- 新用户注册即送算力金,扫码进群获取 Z-Image 专属工作流 和 LoRA 训练脚本!