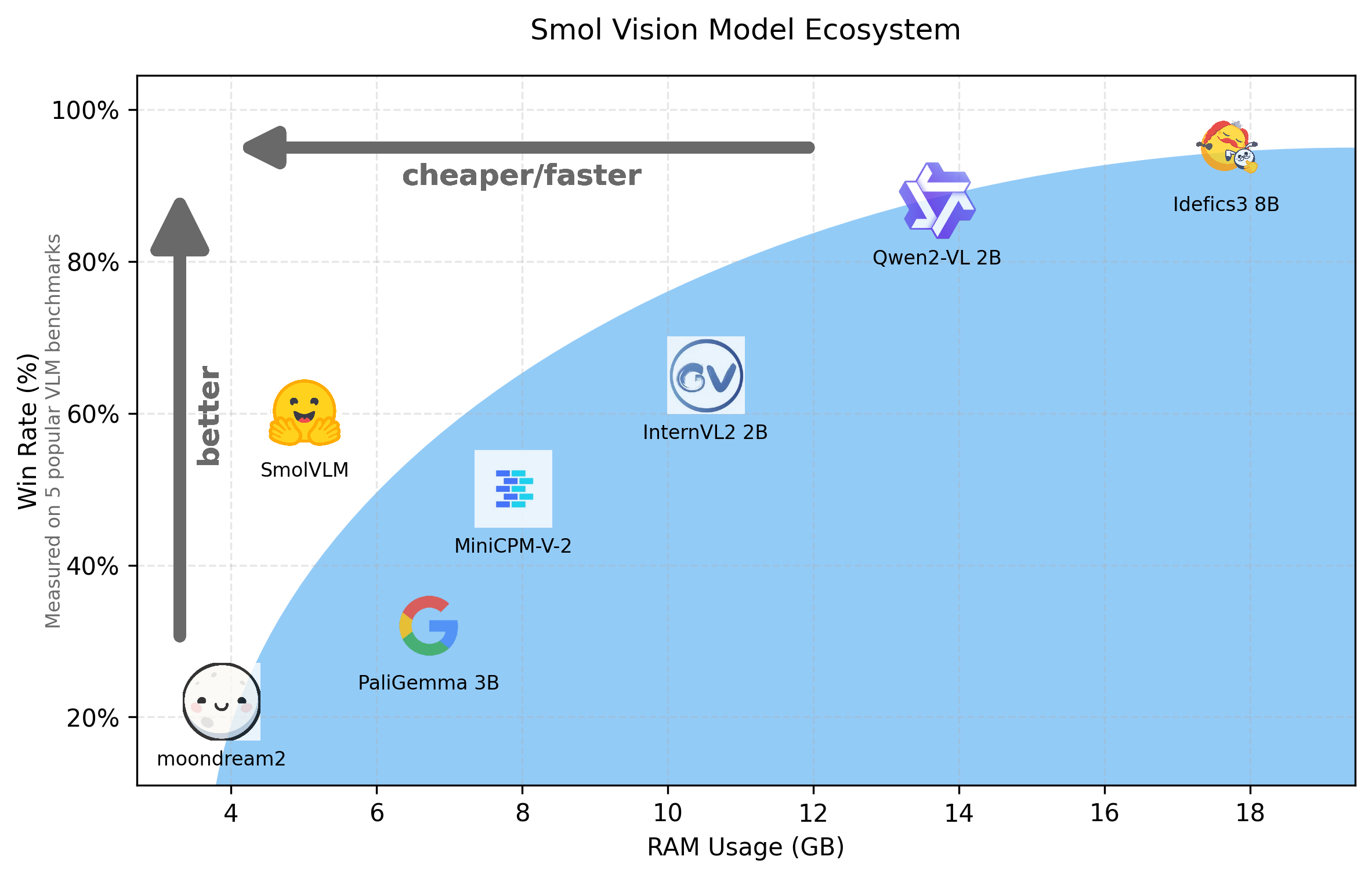
近期 Hugging Face 推出了名为 SmolVLM 的 2B 视觉语言模型系列 这标志着 AI 领域在追求模型效率和本地部署方面迈出了重要一步。SmolVLM 以其卓越的内存占用表现 在同类模型中脱颖而出 提供了小巧 快速 且内存高效的解决方案 更关键的是它完全开源。
大规模多模态 AI 模型在过去一年中呈现爆发式增长 最初侧重于计算规模的提升 随后转向通过大型模型生成合成数据来扩大数据多样性。而现在 行业趋势正向小型化和模型效率倾斜 以实现浏览器或边缘设备的本地部署 降低推理成本 并支持用户定制化。PaliGemma 3B moondream2 Qwen2VL 等模型都体现了这一趋势 而 SmolVLM 正是在这一背景下应运而生。
SmolVLM 深度解析
SmolVLM 是一个全新的 2B 视觉语言模型家族 它支持商业用途 能够部署到小型本地设备 并拥有完全开放的训练流程。
Hugging Face 发布了三个版本的 SmolVLM 模型:
- SmolVLM-Base: 用于下游微调。
- SmolVLM-Synthetic: 基于合成数据进行微调的变体。
- SmolVLM Instruct: 开箱即用的指令微调版本 适用于交互式终端用户应用。
这些开源模型已集成到 Transformers 库中 提供了基于 SmolVLM Instruct 的演示 和监督微调脚本。模型训练使用了 Idefics3 此前采用的完全开源数据集 Cauldron 和 Docmatix。
架构精髓
SmolVLM 的架构与 Idefics3 紧密相连 甚至在 Transformers 库中共享相同的实现。然而 SmolVLM 有几个关键区别:
- 语言骨干网络从 Llama 3.1 8B 替换为更小巧的 SmolLM2 1.7B。
- 通过像素混洗策略 将图像视觉信息的压缩倍数从 Idefics3 的 4 倍提升到 9 倍 大幅减少信息量。
- 图像补丁尺寸由 364x364 改为 384x384 因为 384 能被 3 整除 有利于像素混洗策略的执行。
- 视觉骨干网络采用了形状优化的 SigLIP 模型 结合 384x384 像素的补丁和 14x14 的内部补丁。
性能表现
SmolVLM 在内存效率和推理速度方面表现突出 即使与一些更大的模型相比也毫不逊色。

基准测试
SmolVLM 在 MMMU MathVista MMStar DocVQA TextVQA 等多个基准测试中展现了竞争力 其性能平衡了小模型的高效性与实际应用的需求。
内存效率
SmolVLM 在现有视觉语言模型中提供了最佳的内存使用表现 仅需 5.02GB 的最小 GPU 内存 能够在笔记本电脑等设备上高效运行。
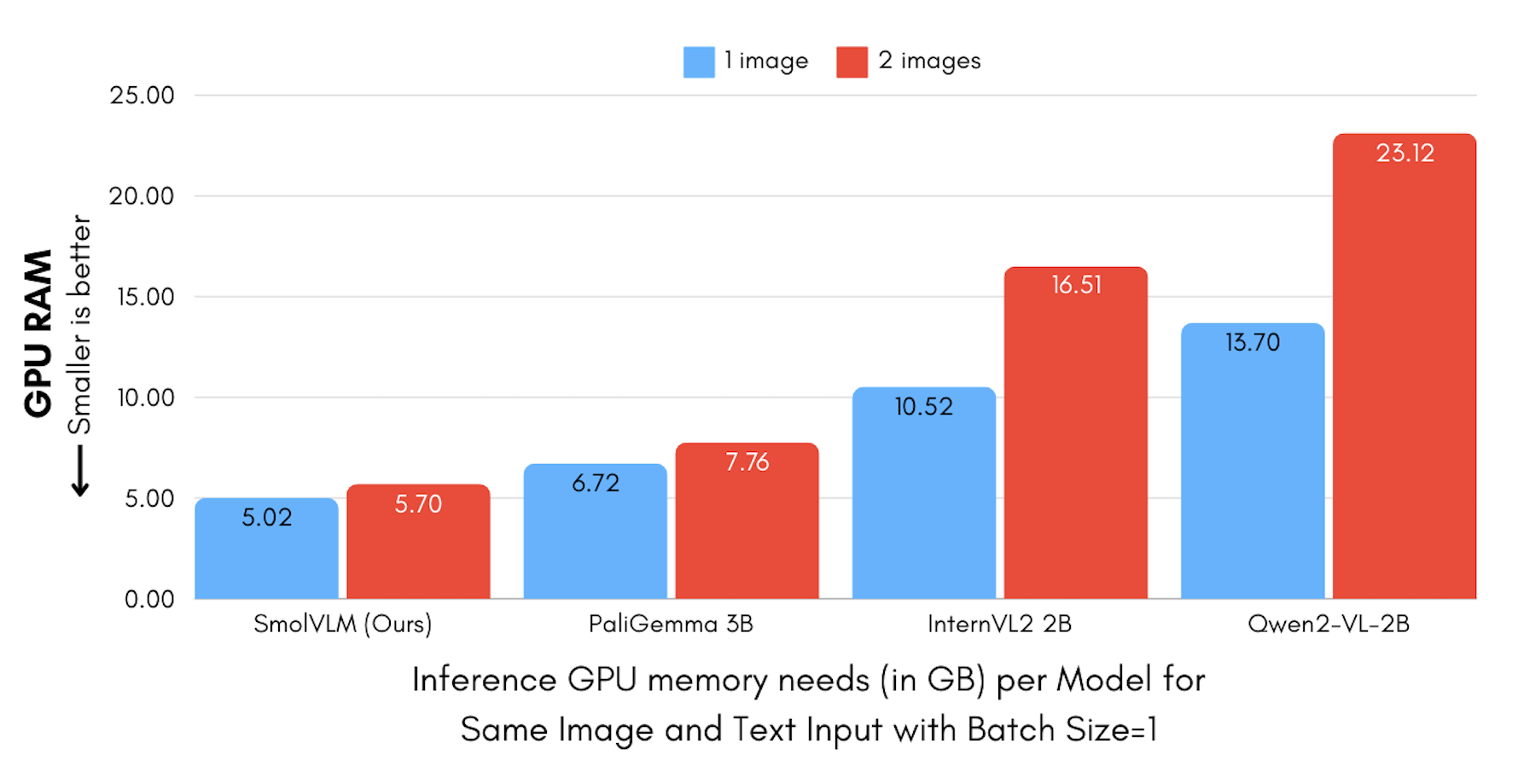
这种效率得益于其独特的图像编码方式:SmolVLM 将每个 384x384 图像补丁编码为 81 个 Token 而 Qwen2-VL 则使用 16k 个 Token。这解释了 SmolVLM 在处理多张图像时内存消耗增长更为缓和的原因。
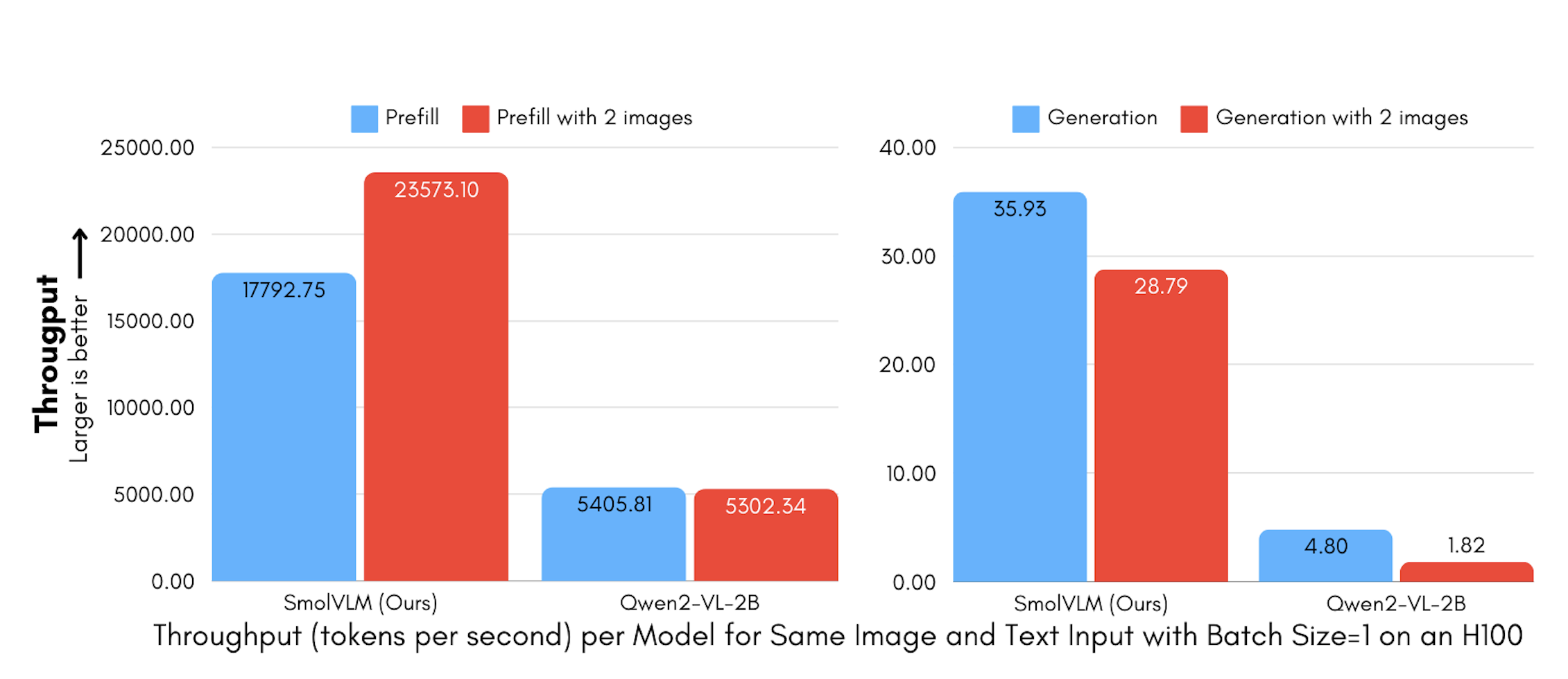
吞吐量
SmolVLM 极小的内存占用也意味着其预填充模型和生成所需的计算量大大减少。相较于 Qwen2-VL SmolVLM 的预填充吞吐量快 3.3 至 4.5 倍 生成吞吐量快 7.5 至 16 倍 带来了显著的推理速度优势。
视频能力
鉴于 SmolVLM 支持长上下文 并能调整内部帧重采样功能 它被探索作为基础视频分析任务的可行选择 尤其是在计算资源有限的情况下。通过简单的视频处理管道代码 从视频中提取 50 个均匀采样的帧 SmolVLM 在 CinePile 基准测试中取得了 27.14% 的成绩 介于 InternVL2 2B 和 Video LLaVa 7B 之间。这表明尽管模型小巧 但其场景理解和对象识别能力令人惊喜。
易用性与扩展
SmolVLM 已集成到 Hugging Face Transformers 库中 使用Auto类即可轻松加载和使用。它支持图像和文本的任意交错输入。
示例代码:
from transformers import AutoProcessor, AutoModelForVision2Seqimport torchfrom PIL import Imagefrom transformers.image_utils import load_imageDEVICE = "cuda" if torch.cuda.is_available() else "cpu"processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-Instruct", torch_dtype=torch.bfloat16, _attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager").to(DEVICE) image1 = load_image("[https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/resolve/main/example_images/rococo.jpg](https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/resolve/main/example_images/rococo.jpg)")image2 = load_image("[https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/resolve/main/example_images/rococo_1.jpg](https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/resolve/main/example_images/rococo_1.jpg)")messages = [ { "role": "user", "content": [ {"type": "image"}, {"type": "image"}, {"type": "text", "text": "Can you describe the two images?"} ] },]prompt = processor.apply_chat_template(messages, add_generation_prompt=True)inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")inputs = [inputs.to](http://inputs.to)(DEVICE)generated_ids = model.generate(**inputs, max_new_tokens=500)generated_texts = processor.batch_decode( generated_ids, skip_special_tokens=True,)print(generated_texts[0])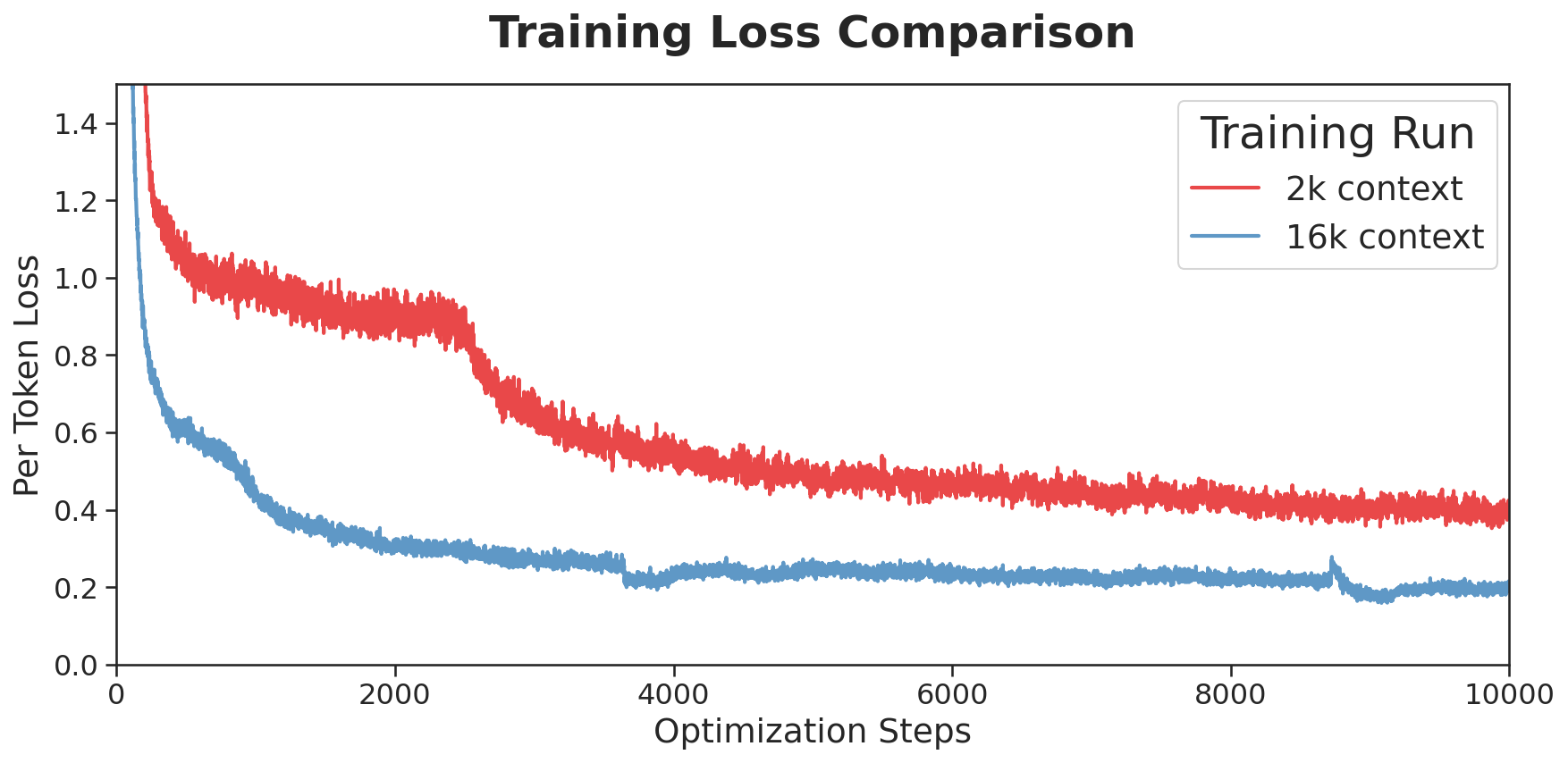
SmolVLM 也提供了灵活的微调选项。你可以在 (https://github.com/huggingface/smollm/blob/main/vision/finetuning/Smol_VLM_FT.ipynb) 中进行 LoRA QLoRA 或完全微调 甚至可以在消费级 GPU 上进行训练 比如使用 L4 显卡。
通过 TRL 集成 用户还可以轻松应用直接偏好优化 DPO 技术 对模型进行对齐 微调数据集为RLAIF-V。
训练洞察
为了支持多图像输入和长上下文场景 SmolVLM2 的语言骨干 SmolLM2 的预训练上下文窗口被扩展到 16k Token。这是通过将 RoPE 基值从 10k 增加到 273k 实现的 遵循了《Scaling Laws of RoPE-based Extrapolation》论文的指导。模型在长短上下文数据集的混合上进行微调 其中包括 Dolma 的“books”子集 The Stack 中的代码文档 FineWeb-Edu DCLM 以及一个定制的数学数据集。训练过程中每 25 个优化步骤保存检查点 通过综合多模态理解 文档问答 数学推理等多个基准指标来选择最优模型版本。
总结
SmolVLM 的推出 为 AI 社区带来了一个完全开放 小巧而强大的视觉语言模型。它不仅在性能上保持竞争力 更在内存效率和本地部署方面展现了巨大潜力 助力 AI 应用走向更广阔的边缘场景。Hugging Face 鼓励开发者利用这些工具进行创新和定制化。 如需深入了解 SmolVLM 演示和微调指南都是不错的起点。