各位注意了,OpenBMB 刚刚扔出了一颗重磅炸弹——MiniCPM-V 4.5,一个号称能达到 GPT-4o 级别性能,却能在你手机上流畅运行的多模态大模型。这不仅刷新了我们对小型模型的认知上限,更意味着高性能多模态 AI 正加速走向普惠。
核心能力
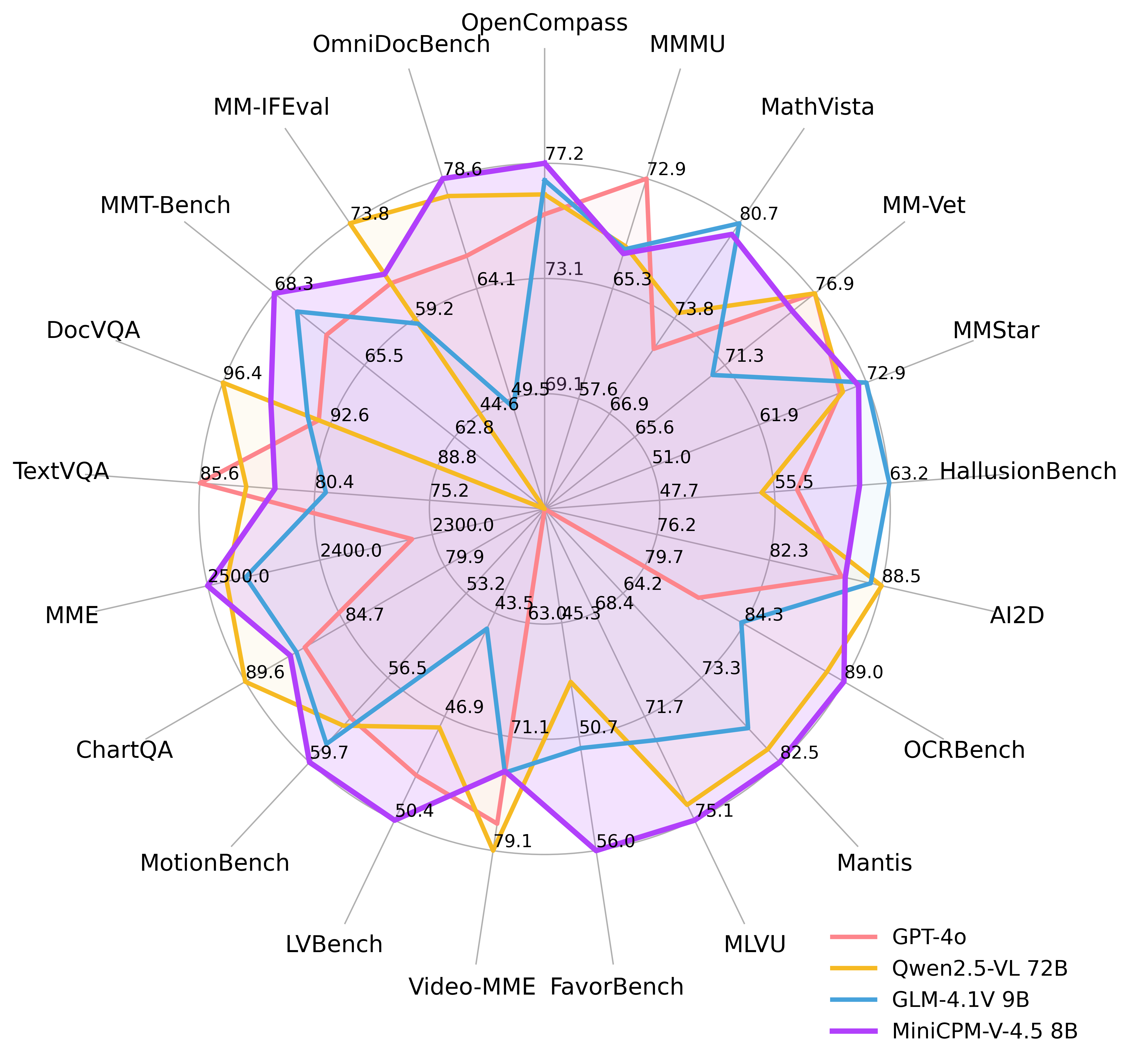
MiniCPM-V 4.5 以其仅 80 亿的参数规模,在 OpenCompass 八项基准测试中取得了平均 77.2 分的傲人成绩。它真正做到了以小博大,在视觉语言理解能力上,甚至超越了 GPT-4o 最新版、Gemini 2.0 Pro 以及 720 亿参数的开源强手 Qwen2.5-VL。这颠覆了业界参数越大越强的传统观念,展现了极致效率与卓越性能的完美结合。
视频理解效率革命
面对视频内容的复杂性,MiniCPM-V 4.5 引入了创新的统一 3D-Resampler 技术,实现了惊人的 96 倍视频 Token 压缩率。这意味着模型能够以极低的推理成本,处理更多的视频帧,支持高达每秒 10 帧的高刷新率视频理解和长视频内容分析。无论是 Video-MME 还是 LVBench,其表现都处于行业领先水平。想象一下,过去需要 1536 个 Token 表示的视频片段,现在只需 64 个就能精准捕捉核心信息。
思维模式按需切换
模型还支持快思与深思两种混合控制模式,这非常灵活。对于日常高频使用场景,可以选择高效的快思模式获得迅速响应;而面对需要更复杂推理的问题时,则能切换到深思模式,以追求更深入、更准确的解决方案。这种按需调整的能力,极大地提升了模型在不同应用场景下的实用性。
图像与文档解析利器
基于 LLaVA-UHD 架构,MiniCPM-V 4.5 在处理高分辨率图像和复杂文档方面表现出色,能够处理高达 180 万像素的任意长宽比图像,且视觉 Token 消耗比大多数多模态大模型少四倍。在 OCRBench 上,它的表现超越了 GPT-4o 最新版和 Gemini 2.5,而在 OmniDocBench 上,其 PDF 文档解析能力也达到了通用多模态大模型的顶尖水平。同时,结合 RLAIF-V 和 VisCPM 技术,模型具备值得信赖的行为表现,并在 MMHal-Bench 上优于 GPT-4o 最新版,更支持超过 30 种语言的多语种能力。

易于部署广泛兼容
OpenBMB 在部署易用性上也下足了功夫。无论是通过 llama.cpp 和 ollama 在本地设备上进行高效 CPU 推理,还是提供 int4、GGUF、AWQ 等多种量化模型格式,亦或是支持 SGLang 和 vLLM 实现高吞吐量推理,都极大地降低了开发者的使用门槛。此外,它还能通过 Transformers 和 LLaMA-Factory 进行微调,提供了便捷的本地 WebUI 演示,甚至优化了 iOS 应用,让你在 iPhone 或 iPad 上也能体验到指尖上的 AI 能力。
结语
MiniCPM-V 4.5 的出现,不只是多模态大模型领域的一次性能飞跃,更是一个深远的信号:AI 的小时代正在加速到来。它证明了在参数量并不庞大的前提下,通过精巧的架构设计和优化,模型依然能达到甚至超越顶尖大模型的性能,并且能够真正落地到我们日常使用的移动设备上。这种对效率和实用性的极致追求,将极大拓宽 AI 的应用边界,让 AI 不再是云端的专属,而是真正触手可及。
GitHub 链接:https://github.com/OpenBMB/MiniCPM-o
在线 Demo: http://101.126.42.235:30910/
Hugging Face 模型页面:https://huggingface.co/openbmb/MiniCPM-V-4_5