
全新架构带来超长上下文
Llama 4 Scout 的问世,再次把上下文窗口拉到了一个几乎荒谬的长度——1000 万 token。这并非仅仅是一个宣传用的数据,在实际部署中,它确实可以处理数百万字的输入而不崩溃,更重要的是:模型理解长文的能力明显增强。
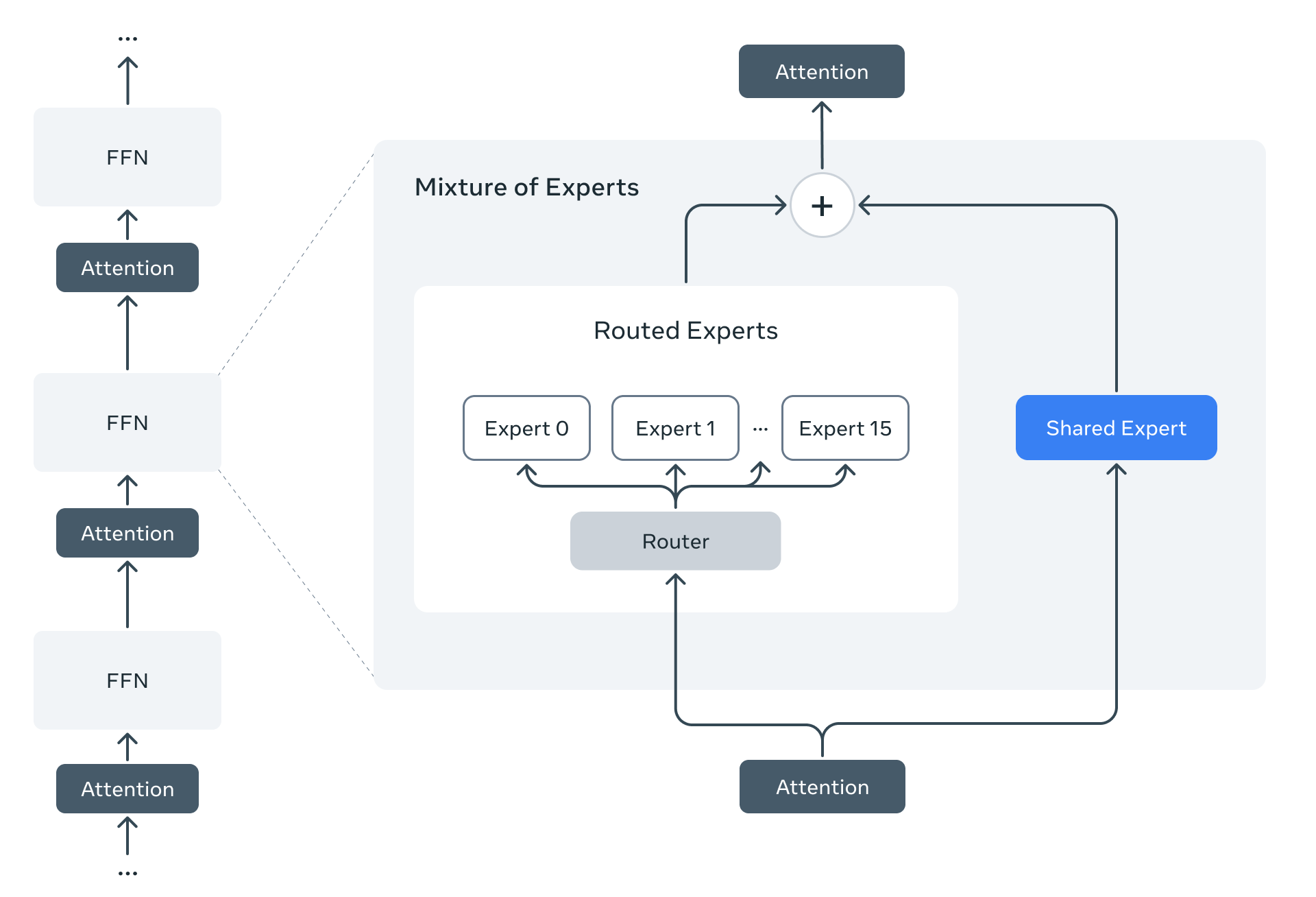
这与 Meta 在架构设计上的大刀阔斧直接相关。它舍弃了 RoPE 中位置编码的普遍方案,转而让 NoPE 层以固定节奏加入。这种交错使用 RoPE 和 NoPE 的结构,被称为 iRoPE,用温度尺度调节长句注意力,是在工程和理论上都独立思考的结果,并非参数堆叠。
MoE 架构的“老派创造性”
Scout 使用 16 个专家网络,实现了 109B 总参数但只有 17B 激活参数的设计。这种低激活比例的 Mixture-of-Experts 模型,被一些开发者误以为在实际效果上“不如全连接的大模型”。事实上,Scout 的多专家网络在数学题、知识推理任务上的表现击败了 Llama 3.1 405B,这再次证明有效算力比纯模型规模更重要。
更有趣的是这种 MoE 设计对部署非常友好。通过 4-bit 或 8-bit 量化,Scout 可以在单块服务器级显卡上运行,从而大幅降低了私有部署的门槛。
超越“大而强”的范式
一个意料之外但反直觉的发现是:Llama 4 Scout 使用了专门为“比自己更大的模型”设计出来的训练机制。具体是通过从 Llama Behemoth 这类超大模型中进行共蒸馏,Scout 居然在多个衡量多语言能力、图文理解、文本精度的评估中做到反击。
换句话说,在这个版本中,Meta 明确表达了一个观点:不是每一代更强的模型都需要“从头依赖超大参数规模”。
对终端开发者意味着什么
Llama 4 Scout 和 Maverick 均已集成至 Hugging Face transformers v4.51.0,所有衍生模型、量化模型、微调生成物也都使用 Xet Storage 进行存储。这意味着开发者无需再为巨大的模型 checkpoint 耗费大量时间和流量。约 40% 的 deduplication 提升,省下的不只是磁盘。
Scout 的出现补足了一个空白——一个足够聪明、足够便宜、足够懂长文的 AI 模型,这对法律、科研文献处理、小说生成类场景是实质性的改变。
快速上手链接
- 模型主页:meta-llama/Llama-4-Scout-17B-16E-Instruct(Hugging Face)
- 源码仓库与详细推理示例:https://github.com/huggingface/blog/blob/main/llama4-release.md