多模态不是终点 它只是起点
微软最新发布的多模态模型 Magma 不是在走传统视觉语言模型那条老路。它针对的不是静态感知任务,而是让 AI 理解、计划并行动。换句话说,Magma 并不只是看图说话,更像是看图干活。
在整个 Agent 赛道,Magma 给出了一个令人信服的方向:AI 不止要理解世界,还得动手处理世界。
SoM 和 ToM 才是真正关键资产
Magma 引入了两个独特机制:Set-of-Mark(SoM)和 Trace-of-Mark(ToM),分别用于图像动作锚定和视频时序规划。这两者像是给 AI 装上了“视觉指针”和“动作记忆”。
通过这两个机制,Magma 在 UI 导航和机器人操作中远超常规大模型;它甚至能在零样本设定下完成复杂规划。这说明,想让 Agent 动起来,最重要的不一定是更大的模型,而是更细致的符号化监督。
小数据强泛化和真实的 Zero-shot 能力
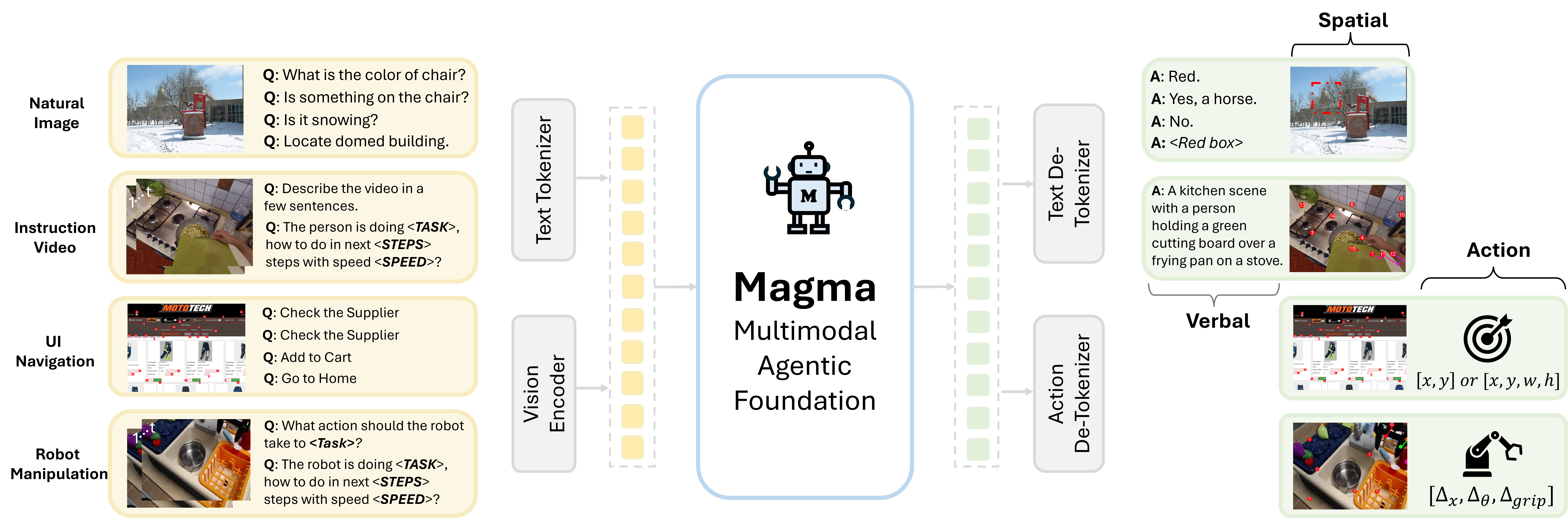
不同于动辄用上百亿帧训练的视觉语言模型,Magma 用的数据远少于市面主流模型,但在跨模态任务如视频问答、UI 操作、机器人控制上表现却更稳定。尤其是在 Sim2Real 测试中,Magma 能从模拟环境无调参转移到真实 WidowX 机器人身上。
这种 zero-shot 迁移能力意味着未来我们可能只需很少量数据和极简调参就能部署一个通用智能体。
从感知模型到行动体的拐点正在发生
Magma 之所以值得关注,是因为它真正补足了当前 Agent 系统最缺的一环——空间与时间上的执行能力。它可以理解界面按钮、操作机器人手臂,甚至在视频中预测接下来的动作,而不仅仅是输出一句答案。

相比 GPT-4o 那种偏语言驱动的模型,Magma 更像是在催生一种“体智能”模型方向。
相关链接
- GitHub 源码:https://github.com/microsoft/Magma
- Hugging Face 页面:https://huggingface.co/microsoft/Magma-8B
- ArXiv 论文:https://www.arxiv.org/abs/2502.13130
- 在线试玩 Magma UI:https://huggingface.co/spaces/microsoft/Magma-UI