deepseek-ai 再次展现其在 AI 前沿的探索精神,最新推出的 Janus-Pro 模型,为多模态 AI 领域带来了创新的统一框架。这款模型不仅能理解图像内容,还能生成图像,其独特之处在于视觉编码的巧妙解耦设计,打破了传统多模态模型在理解与生成任务中的潜在冲突。

Janus-Pro 的发布预示着新一代统一多模态模型的新趋势,其高灵活性和高效性使其成为一个强有力的竞争者。
核心亮点
Janus-Pro 的核心创新在于其统一的多模态理解与生成能力。它通过将视觉编码过程拆分为独立的通路,有效解决了视觉编码器在执行理解和生成任务时可能遇到的角色冲突。
尽管视觉编码被解耦,模型依然保持了单一且统一的 Transformer 架构来处理信息流,这极大地提升了框架的灵活性。
技术原理与性能
Janus-Pro 基于 DeepSeek-LLM-1.5b-base 或 DeepSeek-LLM-7b-base 构建,展现了强大的语言基础。在多模态理解方面,它采用 SigLIP-L 作为视觉编码器,支持 384 x 384 的图像输入,确保了精细的视觉分析能力。至于图像生成,Janus-Pro 则使用了来自 LlamaGen 的 tokenizer,并具备 16 倍的下采样率。

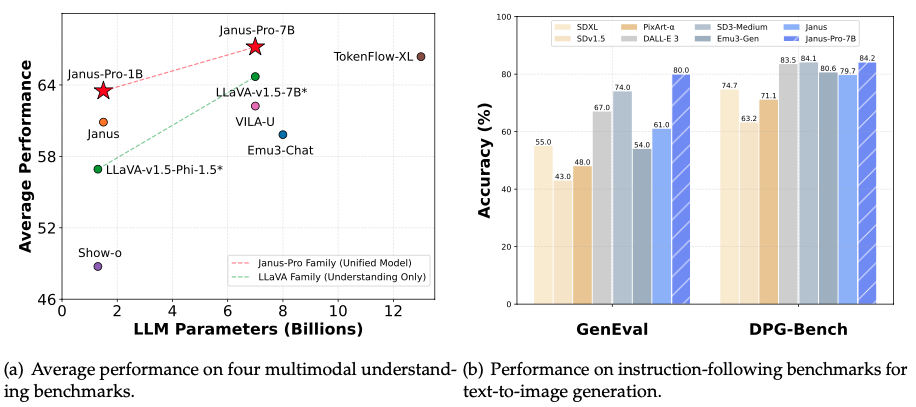
官方数据显示,Janus-Pro 的性能超越了此前诸多统一模型,并且在某些特定任务上,其表现甚至能够匹敌或超越那些专门针对单一任务优化的模型。这种兼顾统一性与高性能的设计,预示着下一代多模态模型的新方向。
独到见解 视觉编码的艺术
在多模态大模型的发展浪潮中,许多模型倾向于追求端到端的“大一统”结构,试图让一个视觉编码器同时承担所有视觉任务。然而,Janus-Pro 的视觉编码解耦设计,提出了一种反直觉但极为高效的策略。这并非是简单地增加复杂度,而是对视觉任务本质的深刻洞察。理解图像需要提取高级语义特征,而生成图像则可能需要更细致、可逆的特征表示。
通过解耦,Janus-Pro 避免了“让同一个组件既当运动员又当教练”的潜在效率瓶颈,使得每个视觉通路都能更专注、更优化地完成其特定任务,同时在更高层的 Transformer 中实现优雅的统一。
这种设计思路,为未来多模态模型的架构创新提供了新的视角:真正的统一,可能并非是单一路径的强行融合,而是对功能差异的巧妙平衡与协同。
更多技术细节可参考其 GitHub 仓库:https://github.com/deepseek-ai/Janus