ComfyUI 文本到图像生成原理深度解析:从噪声到艺术的魔法
深入解析 ComfyUI 文本到图像生成原理,从扩散模型到工作流节点的完整技术指南,包含参数调优、性能优化和故障排除。
如果你已经成功在 ComfyUI 上生成了第一张 AI 图片,那么恭喜你!现在让我们深入了解一下这背后的技术原理。理解这些概念不仅能帮你更好地使用 ComfyUI,还能让你在遇到问题时快速定位原因。ComfyUI 的文本到图像生成本质上是一个反向扩散过程,这个过程就像是在做一件非常神奇的事情:想象一下,你有一杯清水,然后不断往里面滴墨水,水会变得越来越浑浊,这就是扩散过程。而扩散模型做的就是相反的事情:从一杯浑浊的水开始,通过不断”清洗”,最终得到一杯清水。在图像生成中,纯高斯噪声就相当于浑浊的水(随机像素点),迭代去噪就是清洗过程,最终图像就是清澈的水(清晰的图片)。
1. 扩散模型理论基础
Section titled “1. 扩散模型理论基础”1.1 数学原理与工作流程
Section titled “1.1 数学原理与工作流程”扩散模型基于马尔可夫链理论,通过两个过程工作:前向过程(加噪)逐步向图像添加高斯噪声,反向过程(去噪)从纯噪声开始,逐步恢复图像。每一步去噪都基于条件概率,其中条件信息包括文本提示等,神经网络预测的均值和方差决定了去噪的方向和强度。这个过程的核心在于,模型通过学习大量的图像数据,掌握了从噪声到清晰图像的”清洗”路径,就像一个有经验的画家知道如何一笔一笔地完成作品一样。

2. 空间概念理解
Section titled “2. 空间概念理解”2.1 潜在空间与像素空间的关系
Section titled “2.1 潜在空间与像素空间的关系”潜在空间是扩散模型的核心概念,它就像建筑师的蓝图一样,虽然比实际建筑小得多,但包含了所有关键信息。想象一下,建筑师不会直接在建筑物上画图,而是先在蓝图上设计,这样既节省了空间,又便于修改和优化。在 ComfyUI 中,一张 512×512 的图片在潜在空间中可能只有 64×64,这种压缩带来了巨大的优势:存储效率大幅提升,计算效率显著提高,而且重要的视觉特征都得到了保留。数学上,这个过程可以表示为图像编码到潜在空间,再从潜在空间解码回图像,形成了一个完整的压缩 - 解压缩循环。相比之下,像素空间就是我们平时看到的图像,每个像素都有明确的颜色值,这是人类视觉系统能直接理解的形式。在 RGB 模式下,每个像素用三个值表示,范围从 0 到 255,而在归一化模式下,值范围通常是 -1 到 1 或 0 到 1,这种标准化有助于模型的训练和收敛。
3. 工作流程节点深度解析
Section titled “3. 工作流程节点深度解析”3.1 加载检查点节点:模型的”工具箱”
Section titled “3.1 加载检查点节点:模型的”工具箱””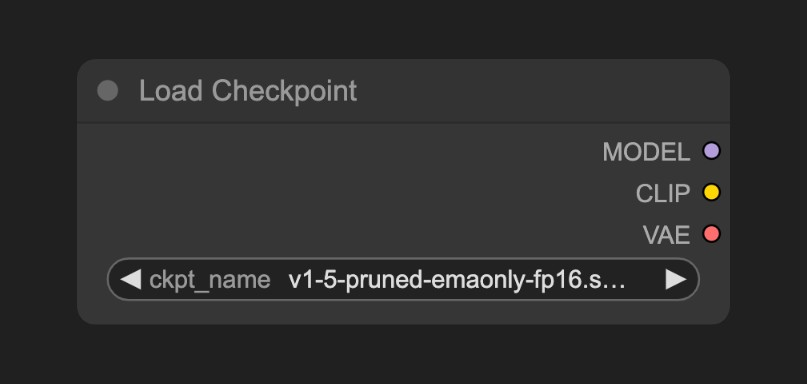
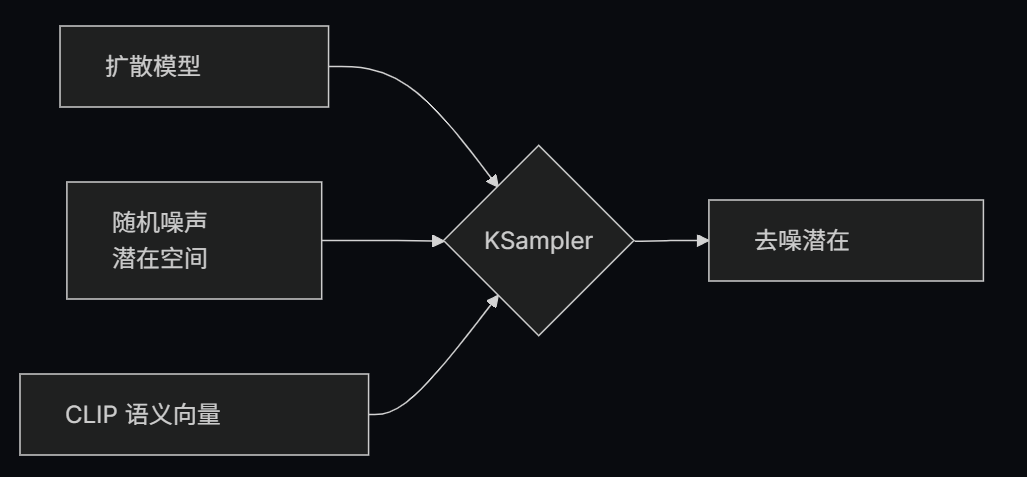
加载检查点节点是整个工作流程的起点,它加载了三个核心组件,每个组件都有其独特的作用。MODEL (UNet) 是整个系统的”大脑”,负责预测噪声应该往哪个方向去除,决定图像生成的每一步应该怎么做,就像一个有经验的画家知道如何一笔一笔地完成作品。UNet 架构采用了编码器 - 解码器结构,通过逐步提取和重建特征来实现图像生成,同时使用跳跃连接保留低层细节信息,注意力机制关注重要的图像区域,时间嵌入理解去噪过程的当前阶段。CLIP 组件则扮演着文本理解的”翻译官”角色,它把你的文字描述转换成模型能理解的数字向量,比如”一只可爱的小猫”会被转换成 [0.8, 0.9, 0.2, …] 这样的向量,模型根据这个向量来指导图像生成。CLIP 的工作原理包括四个步骤:文本编码将提示词转换为高维向量,图像编码将图像转换为相同维度的向量,相似度计算评估文本和图像的匹配程度,最后通过梯度指导生成过程朝向目标方向。VAE 组件则充当空间转换的”桥梁”,在像素空间和潜在空间之间来回转换,就像货币兑换一样把一种形式转换成另一种形式。VAE 的压缩原理基于编码器将高维像素空间压缩到低维潜在空间,解码器将潜在空间重建回像素空间,瓶颈结构强制模型学习最重要的特征表示,从而实现高效的压缩和重建。
3.2 空潜像节点:定义画布大小
Section titled “3.2 空潜像节点:定义画布大小”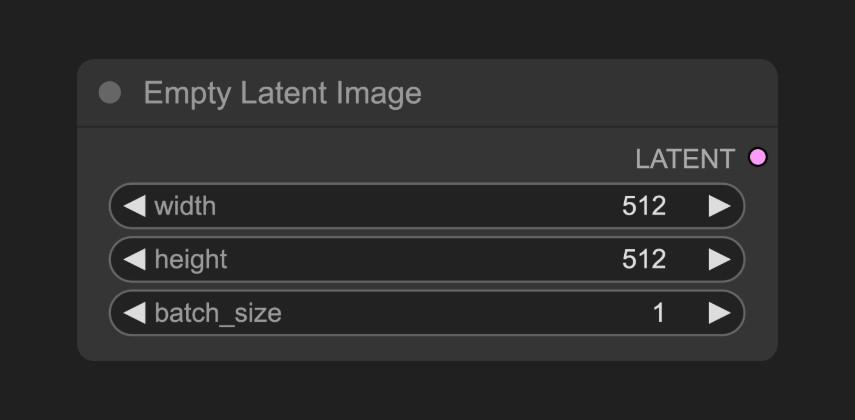
空潜像节点决定了最终图像的尺寸,就像画画前要先确定画布大小一样,它创建了一个纯噪声的”画布”。这个节点的设置直接影响生成图像的质量和速度,因此需要根据具体需求来选择合适的参数。在测试阶段,建议使用 512×512 或 512×768 的尺寸,这样生成速度快,能够快速验证概念和效果。对于正式创作,可以选择 1024×1024 或更高的尺寸,这样能够获得更丰富的细节和更高的分辨率。如果需要生成宽屏图片,可以选择 1024×576 或 1280×720 的尺寸,这种比例特别适合风景画和电影海报等横向构图的作品。尺寸选择需要权衡多个因素:小尺寸(512×512)的优点是生成快、显存占用少,缺点是细节有限、分辨率低,适用于快速测试和概念验证;中等尺寸(768×768)能够平衡质量和速度,显存占用适中,适用于日常创作和社交媒体分享;大尺寸(1024×1024+)的优点是细节丰富、质量高,缺点是生成慢、显存占用大,适用于专业作品和打印输出。
3.3 CLIP 文本编码器:提示词处理器
Section titled “3.3 CLIP 文本编码器:提示词处理器”
CLIP 文本编码器节点把你的文字转换成模型能理解的”指令”,这是整个生成过程的关键环节。正面提示词应该包含你想要的内容描述,比如”masterpiece, best quality, highly detailed, 8k uhd, a beautiful landscape with mountains and lake, golden hour lighting, cinematic composition”,这些词汇能够指导模型生成高质量、符合要求的图像。负面提示词则用来避免不想要的内容,常见的负面词汇包括”blurry, low quality, distorted, deformed, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits”,这些词汇能够帮助模型避免生成模糊、低质量或畸变的图像。提示词权重控制是一个高级技巧,通过使用括号和数字来调整关键词的重要性,比如”(beautiful:1.2), (detailed:1.1), (blurry:-0.5)“,其中数字大于 1 表示加强该特征,小于 1 表示减弱该特征。高级提示词技巧包括分层结构、权重平衡、风格混合和时间控制等。分层结构建议按照”主体对象、动作/状态、环境/背景、艺术风格、技术质量”的顺序组织提示词;权重平衡通过调整不同关键词的权重来实现更精确的控制;风格混合可以结合多种艺术风格,比如”oil painting style, impressionist art, (photorealistic:0.7)“;时间控制则通过调整时间相关的词汇来影响图像的氛围,比如”(golden hour:1.1), (sunset:1.0), (night:-0.3)“。
3.4 KSampler 节点:核心生成引擎
Section titled “3.4 KSampler 节点:核心生成引擎”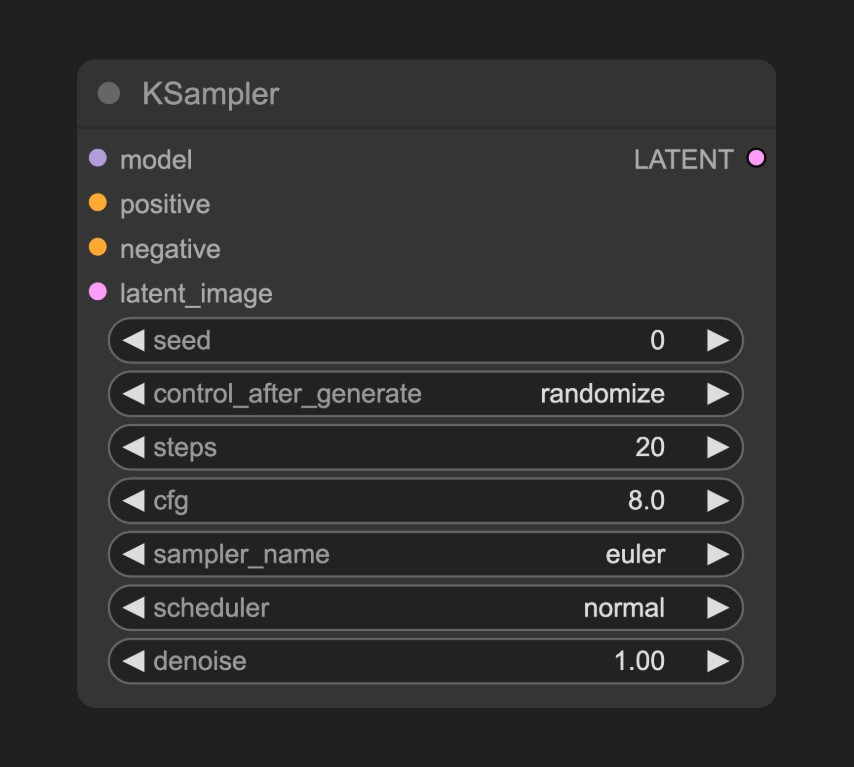
KSampler 节点是整个工作流程的心脏,所有的魔法都在这里发生。这个节点包含了多个关键参数,每个参数都会显著影响最终生成图像的质量和风格。采样步数(Steps)是最重要的参数之一,它决定了去噪过程的精细程度:20-30 步适合快速生成和测试迭代,30-50 步能够平衡质量和速度,是日常使用的推荐设置,50 步以上能够获得最高质量,但生成时间会显著增加。步数选择需要根据具体需求来决定:快速测试可以使用 20-25 步,日常使用选择 30-40 步,高质量输出需要 40-60 步,极致质量则需要 60-100 步,但时间成本会很高。
CFG 值(Classifier Free Guidance)控制提示词的约束强度,这个参数直接影响生成图像与提示词的匹配程度。CFG 值在 7-8 之间是标准值,能够平衡创造性和准确性;10-12 提供强约束,严格按照提示词生成;5-6 则提供弱约束,允许更多创造性发挥。CFG 值的影响分析显示:小于 5 会导致过度创造性,可能偏离提示词;5-7 能够平衡创造性和准确性;7-10 是标准范围,推荐使用;10-15 提供强约束,适合精确控制;大于 15 则可能过度约束,产生伪影。
采样器选择是另一个关键参数,不同的采样器在速度和质量之间有不同的权衡。Euler 采样器速度最快,适合测试和批量生成,但质量一般;Euler Ancestral 在速度和质量之间取得平衡,适合日常使用;DPM++ 2M Karras 提供最高质量,适合专业创作,但速度较慢;DDIM 速度快但质量一般,适合快速预览和概念验证。采样器性能对比显示,Euler 在速度上获得五星评价,质量三星,适用于快速测试和批量生成;Euler Ancestral 速度四星,质量四星,适用于日常使用和平衡选择;DPM++ 2M Karras 速度三星,质量五星,适用于高质量输出和专业创作;DDIM 速度五星,质量三星,适用于快速预览和概念验证。
去噪强度(Denoise)参数控制对原始图像的修改程度:0.0 表示完全保持原图,0.5 表示部分修改,1.0 表示完全重新生成。去噪强度的应用场景包括:0.0-0.3 适合轻微修改,保持原图大部分特征;0.3-0.7 适合中等修改,常用于风格转换;0.7-1.0 适合大幅修改,完全重新生成图像。
3.4.1 实际应用示例
Section titled “3.4.1 实际应用示例”假设你想生成一张”夕阳下的山景”,这是一个典型的风景画生成任务。首先需要设置采样步数为 40 步,这样能够在质量和速度之间取得平衡;然后设置 CFG 值为 8,这是标准约束强度,能够确保生成的图像符合提示词要求;接着选择 DPM++ 2M Karras 采样器,这个采样器虽然速度较慢,但能够提供最高质量;最后设置去噪强度为 1.0,表示完全重新生成图像。根据不同的使用场景,可以调整这些参数组合:快速测试配置使用 Steps=25、CFG=7、Sampler=Euler、Denoise=1.0,这样能够快速验证概念;标准质量配置使用 Steps=40、CFG=8、Sampler=DPM++ 2M Karras、Denoise=1.0,适合日常创作;高质量配置使用 Steps=60、CFG=8、Sampler=DPM++ 2M Karras、Denoise=1.0,适合专业作品和最终输出。
3.5 VAE 解码与图像保存
Section titled “3.5 VAE 解码与图像保存”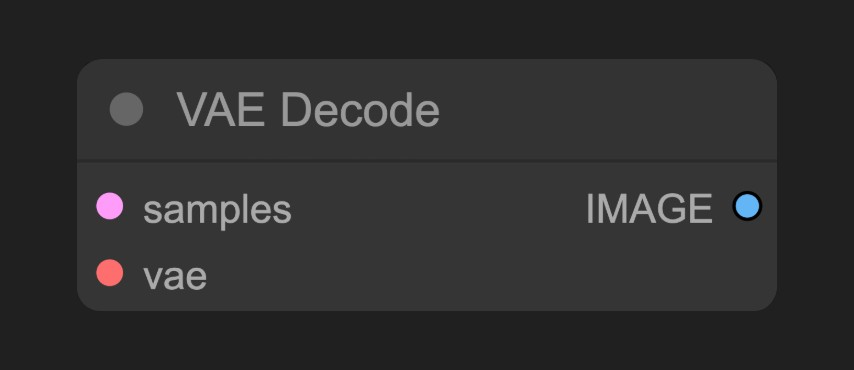
VAE 解码节点把潜在空间的抽象表示转换回我们能看到的具体图像,就像把建筑师的蓝图变成实际的建筑物。这个节点的质量直接影响最终图像的清晰度和细节表现。VAE 选择建议包括使用默认 VAE(大多数情况下够用)和专用 VAE(某些模型有配套的 VAE,效果更好)。VAE 的质量影响体现在多个方面:编码质量影响潜在空间的表示能力,解码质量影响最终图像的清晰度和细节,兼容性决定了不同模型是否需要特定的 VE。保存图像节点是工作流程的最后一步,负责把生成的图像保存到本地,默认保存在 ComfyUI/output 文件夹中。输出格式选择需要考虑多个因素:PNG 格式提供无损压缩,文件较大但质量最高;JPEG 格式采用有损压缩,文件较小但质量适中;WebP 是现代格式,能够在质量和文件大小之间取得平衡。
4. 高级技巧与参数调优
Section titled “4. 高级技巧与参数调优”4.1 批量生成优化策略
Section titled “4.1 批量生成优化策略”批量生成是提高工作效率的重要技巧,当你需要生成多张图片时,可以通过多种策略来优化这个过程。首先,设置不同的种子值是基础,每张图片使用不同的随机种子能够确保生成结果的多样性。其次,调整 CFG 值在 7-12 之间尝试不同值,这样能够探索不同的创造性和准确性平衡点。最后,变化采样步数,比如 30、40、50 步各试几张,能够找到最适合当前任务的步数设置。批量生成策略可以分为三种主要类型:策略一是固定质量变化风格,保持 Steps=40、CFG=8、Sampler=DPM++ 2M Karras 等质量参数不变,通过改变提示词和种子值来获得不同风格的图像;策略二是固定风格变化质量,保持提示词和种子值不变,通过调整 Steps(25/40/60)和 CFG(7/8/10)来获得不同质量级别的图像;策略三是参数网格搜索,系统性地尝试不同参数组合,记录每种组合的效果,这种方法虽然耗时较长,但能够帮助你找到最优的参数配置。
4.2 提示词工程进阶技巧
Section titled “4.2 提示词工程进阶技巧”提示词工程是 AI 图像生成中的一门艺术,掌握这门艺术能够显著提升生成图像的质量和准确性。分层提示词结构是基础技巧,建议按照”主体描述、风格描述、质量描述、技术参数”的顺序组织提示词,这样能够确保模型理解你的意图。具体示例可以这样组织:“a majestic mountain landscape, oil painting style, impressionist art, masterpiece, best quality, highly detailed, 8k uhd, professional photography”,这个提示词包含了完整的描述层次。负面提示词系统化同样重要,应该按照”质量缺陷、技术问题、风格不匹配、内容禁忌”的顺序来组织,这样能够有效避免不想要的效果。
提示词优化技巧包括多个方面:关键词权重调整通过使用括号和数字来精确控制特征强度,比如”(beautiful:1.3), (detailed:1.2), (blurry:-0.8)“能够加强美丽和细节特征,同时减弱模糊效果;风格混合可以结合多种艺术风格,比如”oil painting style, (photorealistic:0.7), impressionist art”能够创造出独特的混合风格;质量提升通过添加质量相关的词汇来提升整体效果,比如”masterpiece, best quality, highly detailed, 8k uhd, professional”;技术参数则通过添加技术性词汇来优化图像质量,比如”sharp focus, high resolution, detailed texture”能够提升图像的清晰度和细节表现。
5. 常见问题诊断与解决方案
Section titled “5. 常见问题诊断与解决方案”5.1 图像质量问题诊断
Section titled “5.1 图像质量问题诊断”图像质量不佳是使用 ComfyUI 时最常见的问题之一,可能的原因包括采样步数太少、CFG 值过高、模型质量差等。当遇到图像质量问题时,首先应该增加采样步数,从 40 步增加到 50 步能够显著提升细节表现;其次调整 CFG 值,从 12 降低到 8 能够避免过度约束导致的伪影;最后考虑更换采样器,从 Euler 切换到 DPM++ 2M Karras 能够获得更高质量的输出。质量提升检查清单包括:增加采样步数到 40-50、调整 CFG 值到 7-8、使用高质量采样器、优化提示词质量、检查模型版本等步骤,按照这个清单逐步排查能够有效解决大部分质量问题。
5.2 性能优化策略
Section titled “5.2 性能优化策略”生成速度慢是另一个常见问题,特别是在处理大尺寸图像或使用高质量采样器时。优化策略包括减少图片尺寸、使用更快的采样器、降低采样步数、检查 GPU 使用率等。快速配置使用 Steps=25、Sampler=Euler、Size=512×512、CFG=7,这种配置能够在保证基本质量的前提下最大化生成速度;平衡配置使用 Steps=40、Sampler=Euler Ancestral、Size=768×768、CFG=8,这种配置在速度和质量之间取得平衡,适合日常使用。除了参数调整,还需要检查硬件资源使用情况,确保 GPU 没有被其他程序占用,显存充足,这样能够获得最佳的性能表现。
5.3 提示词与显存问题解决
Section titled “5.3 提示词与显存问题解决”提示词不生效是另一个常见问题,可能的原因包括 CLIP 编码器连接错误、提示词语法不正确、CFG 值设置不当、模型不支持该类型内容等。检查要点包括确认 CLIP 编码器连接正确、检查提示词语法是否正确、尝试调整 CFG 值、确认模型支持该类型的内容。提示词调试步骤建议采用渐进式方法:首先简化提示词,只保留核心概念;然后逐步增加复杂度;接着测试不同的 CFG 值;最后检查模型的能力范围。这种方法能够帮助你快速定位问题所在,避免在复杂的提示词中迷失方向。
显存不足是硬件限制导致的问题,特别是在处理大尺寸图像时。显存优化策略包括减少图片尺寸、降低批处理大小、使用更轻量的模型、启用 VAE 缓存等。显存占用估算显示:512×512 图像大约需要 4-6GB 显存,768×768 需要 6-8GB,1024×1024 需要 8-12GB,1280×1280 需要 12-16GB。了解这些估算值能够帮助你合理规划显存使用,避免因为显存不足导致的工作中断。在实际使用中,建议预留一定的显存余量,这样能够确保系统的稳定性和其他程序的正常运行。
6. 总结与展望
Section titled “6. 总结与展望”ComfyUI 的文本到图像生成是一个复杂而精妙的系统,虽然表面看起来复杂,但核心原理并不难理解。通过掌握扩散模型的基本概念、潜在空间与像素空间的关系、各个节点的功能作用、参数调优的技巧等,你就能从”随机生成”变成”精确控制”,创作出真正符合你想象的作品。关键要点回顾包括理解扩散原理(从噪声到图像的逆向过程)、掌握空间概念(潜在空间 vs 像素空间)、熟悉节点功能(每个节点的作用和参数)、学会参数调优(根据需求调整生成参数)、持续学习实践(AI 图像生成是不断进化的技术)等五个方面。
AI 图像生成是一门艺术,需要不断实践和调整,多尝试不同的参数组合,多观察生成结果,你很快就能成为 ComfyUI 的高手。下一步学习建议包括尝试 ControlNet 进行精确控制、学习 LoRA 模型的使用、探索工作流的组合和优化、参与社区讨论分享经验等。这些进阶技能能够进一步扩展你的创作能力,让你在 AI 图像生成的道路上走得更远。记住,学习是一个渐进的过程,不要急于求成,稳扎稳打地掌握每个概念和技巧,最终你将成为这个领域的专家。