容器化部署 FunASR
此镜像提供了标准化的 API 接口,让您能够便捷地通过 API 调用方式 访问和使用所有功能。
本指南详细阐述了在共绩算力平台上,高效部署与使用 FunASR API 项目的技术方案。FunASR 是一个基本的语音识别工具包,提供多种功能,包括语音识别(ASR)、语音活动检测(VAD)、标点符号恢复、语言模型、说话人验证、说话人分类和多说话者 ASR。
1. 服务简介与应用场景
Section titled “1. 服务简介与应用场景”FunASR 是阿里巴巴开源的语音识别工具包,支持多场景一键部署,适合会议转写、客服质检、字幕生成、语音助手、医疗法律文档整理、多语言识别等实际业务需求。
1.1 典型应用场景
Section titled “1.1 典型应用场景”- 会议/讲座/采访转写:实时或离线将录音转为带时间戳文本,便于归档检索。
- 智能客服与语音质检:实时识别对话内容,支持热词、敏感词检测、服务分析。
- 媒体内容字幕生成:批量处理音视频,自动生成带时间轴字幕文本。
- 语音助手与人机交互:低延迟识别,适合智能音箱、车载、移动端。
- 医疗、法律文档整理:支持专业热词,提升术语识别准确率。
- 多语言识别与翻译前处理:支持多语种、口音,适合国际会议、跨国企业。
2. 部署与接入
Section titled “2. 部署与接入”2.1 共绩算力平台部署步骤
Section titled “2.1 共绩算力平台部署步骤”1.登录共绩算力控制台,在首页点击“弹性部署服务”。
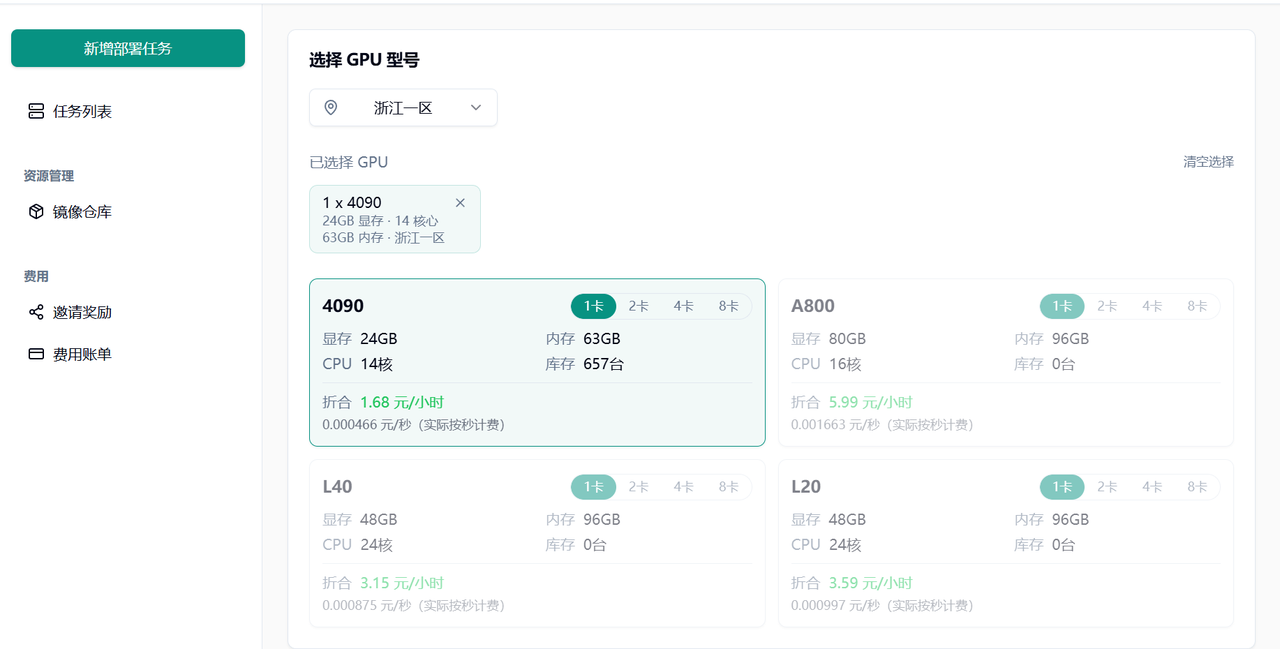
2.选择 GPU 型号(推荐 1 卡 4090)。
3.在“服务配置”选择 FunASR API 官方镜像。
4.点击“部署服务”,平台自动拉取镜像并启动容器。
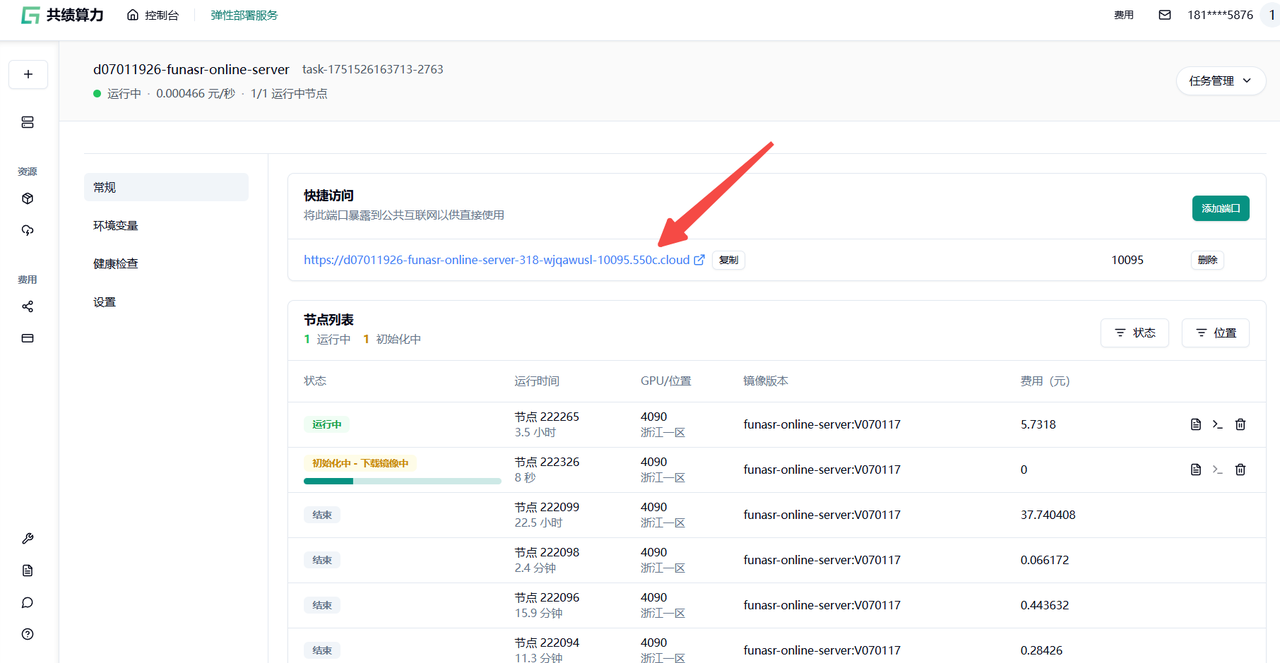
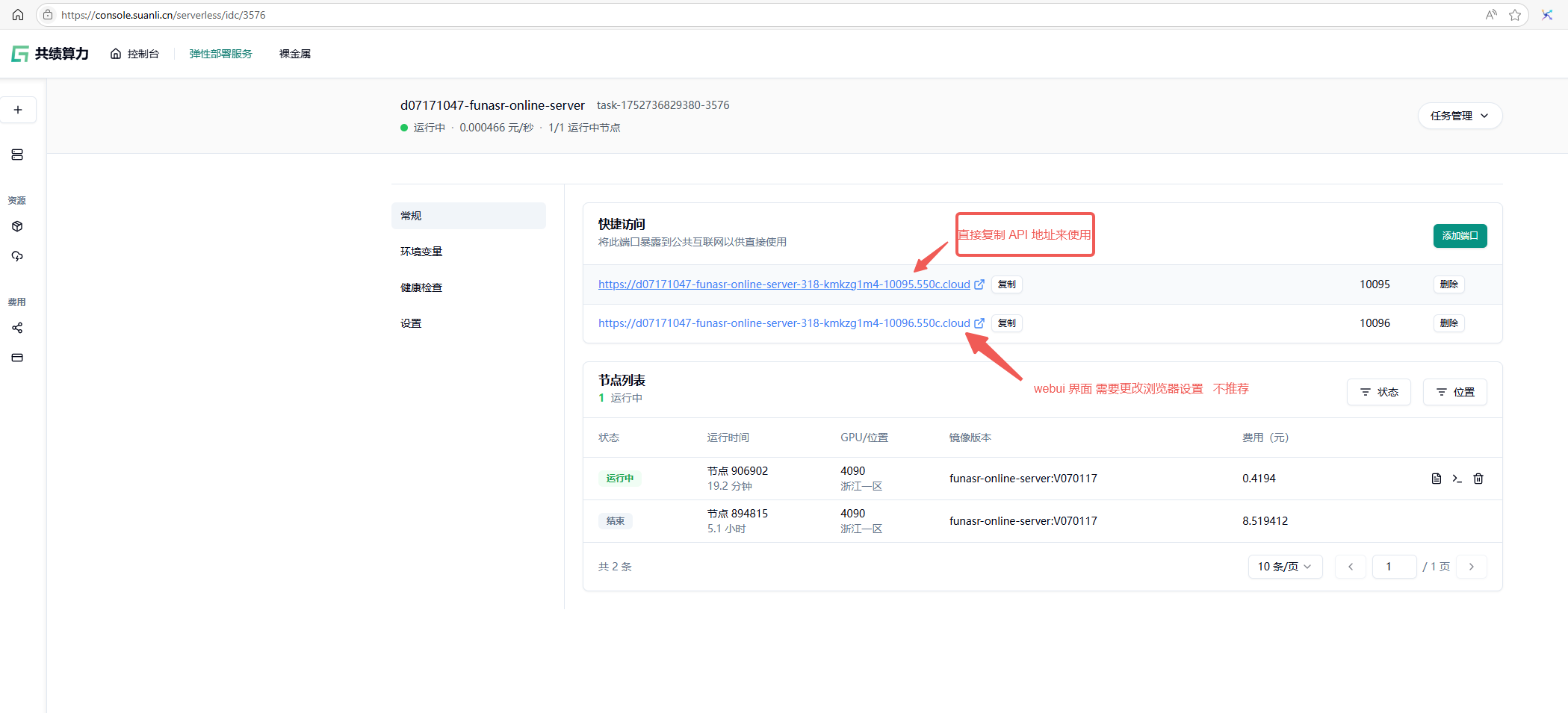
5.部署完成后,在“快捷访问”中复制端口为 10095 的公网访问链接,即为 API 服务地址。
点击 10095 的端口会进入不到具体页面,这个是正常现象,直接复制地址到您的对应服务中使用 API 服务即可,可以参考下面的示例程序。
3. API 协议与参数
Section titled “3. API 协议与参数”3.1 通信协议
Section titled “3.1 通信协议”WebSocket 协议,服务地址:wss://d07171047-funasr-online-server-318-kmkzg1m4-10095.550c.cloud
3.2 典型调用流程
Section titled “3.2 典型调用流程”- 连接 WebSocket 服务。
- 发送配置参数(JSON)。
- 分块发送音频数据(bytes)。
- 发送结束标志(
{"is_speaking": false})。 - 接收识别结果(JSON)。
3.3 配置参数说明
Section titled “3.3 配置参数说明”参数 | 类型 | 说明 |
chunk_size | array | 流式模型延迟配置,数组格式,如 [5,10,5] |
wav_name | string | 音频文件名 |
is_speaking | boolean | 说话状态/断句尾点标识 |
wav_format | string | 音频格式,支持 pcm |
chunk_interval | number | 块间隔时间(单位毫秒) |
itn | boolean | 是否逆文本标准化 |
mode | string | 识别模式: |
hotwords | string | 热词配置,JSON 字符串如: |
4. 典型场景与实测程序
Section titled “4. 典型场景与实测程序”4.1 中文音频识别实测示例(test_cn_male_9s.pcm)
Section titled “4.1 中文音频识别实测示例(test_cn_male_9s.pcm)”import asyncioimport websocketsimport json
ws_url = "wss://d07171047-funasr-online-server-318-kmkzg1m4-10095.550c.cloud"async def test_asr(audio_file, wav_name): config = { "chunk_size": [5, 10, 5], "wav_name": wav_name, "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "2pass" } async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(8000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print(f"{audio_file} 识别结果:", resp) if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
if __name__ == "__main__": asyncio.run(test_asr("test_cn_male_9s.pcm", "test_cn_male_9s"))实际输出:
test_cn_male_9s.pcm 识别结果: {"is_final":true,"mode":"2pass-offline","stamp_sents":[...],"text":"这是一期非广告视频,给你们介绍一下我养猫。这 3 年用到 过最好用的几样养猫物品。","timestamp":"[[50,150],[150,250],...]主要内容:
这是一期非广告视频,给你们介绍一下我养猫。这 3 年用到过最好用的几样养猫物品。
4.2 英文音频识别实测示例(test_en_steve_jobs_10s.pcm)
Section titled “4.2 英文音频识别实测示例(test_en_steve_jobs_10s.pcm)”import asyncioimport websocketsimport json
ws_url = "wss://d07171047-funasr-online-server-318-kmkzg1m4-10095.550c.cloud"async def test_asr(audio_file, wav_name): config = { "chunk_size": [5, 10, 5], "wav_name": wav_name, "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "2pass" } async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(8000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print(f"{audio_file} 识别结果:", resp) if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
if __name__ == "__main__": asyncio.run(test_asr("test_en_steve_jobs_10s.pcm", "test_en_steve_jobs_10s"))实际输出:
test_en_steve_jobs_10s.pcm 识别结果: {"is_final":true,"mode":"2pass-offline","stamp_sents":[...],"text":" thank you, designed the first time time, pure and and designed all in the land。 it was the first cure you,you。","timestamp":"[[270,450],[450,750],...]主要内容:
thank you, designed the first time time, pure and and designed all in the land. it was the first cure you, you.
4.3 会议/讲座/采访转写(带时间戳)
Section titled “4.3 会议/讲座/采访转写(带时间戳)”import asyncioimport websocketsimport json
ws_url = "wss://console.suanli.cn/serverless/idc/3576"async def meeting_transcribe(): config = { "chunk_size": [5, 10, 5], "wav_name": "meeting_demo", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "2pass" } audio_file = "meeting_8k.pcm" # 8kHz 单声道 PCM async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(8000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print("识别结果:", resp) # 示例输出:{"is_final":true,"text":"欢迎参加会议...","timestamp":"[[0,800],[800,1600],...]"} if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
asyncio.run(meeting_transcribe())4.4 智能客服与语音质检(热词增强)
Section titled “4.4 智能客服与语音质检(热词增强)”import asyncioimport websocketsimport json
ws_url = "wss://console.suanli.cn/serverless/idc/3576"async def customer_service_asr(): hotwords = {"产品 A": 30, "专有名词": 25, "投诉": 20} config = { "chunk_size": [5, 10, 5], "wav_name": "service_demo", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "online", "hotwords": json.dumps(hotwords, ensure_ascii=False) } audio_file = "service_call_8k.pcm" async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(8000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print("客服识别:", resp) # 示例输出:{"is_final":true,"text":"您好,欢迎致电产品 A 客服..."} if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
asyncio.run(customer_service_asr())4.5 媒体内容字幕生成(带时间轴)
Section titled “4.5 媒体内容字幕生成(带时间轴)”import asyncioimport websocketsimport json
ws_url = "wss://console.suanli.cn/serverless/idc/3576"async def subtitle_generation(): config = { "chunk_size": [8, 15, 8], "wav_name": "media_demo", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "offline" } audio_file = "media_8k.pcm" async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(8000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print("字幕识别:", resp) # 示例输出:{"is_final":true,"text":"...","timestamp":"[[0,800],[800,1600],...]"} if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
asyncio.run(subtitle_generation())4.6 语音助手与人机交互(低延迟实时识别)
Section titled “4.6 语音助手与人机交互(低延迟实时识别)”import asyncioimport websocketsimport json
ws_url = "wss://console.suanli.cn/serverless/idc/3576"async def voice_assistant(): config = { "chunk_size": [3, 6, 3], "wav_name": "assistant_demo", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 5, "itn": True, "mode": "online" } audio_file = "assistant_8k.pcm" async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(4000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print("助手识别:", resp) # 示例输出:{"is_final":true,"text":"打开空调"} if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
asyncio.run(voice_assistant())4.7 医疗/法律文档整理(专业热词)
Section titled “4.7 医疗/法律文档整理(专业热词)”import asyncioimport websocketsimport json
ws_url = "wss://console.suanli.cn/serverless/idc/3576"async def medical_legal_asr(): hotwords = {"高血压": 30, "肝功能": 25, "原告": 20, "被告": 20} config = { "chunk_size": [5, 10, 5], "wav_name": "medlaw_demo", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "offline", "hotwords": json.dumps(hotwords, ensure_ascii=False) } audio_file = "medlaw_8k.pcm" async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(8000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print("专业识别:", resp) # 示例输出:{"is_final":true,"text":"患者高血压... 原告陈述..."} if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
asyncio.run(medical_legal_asr())4.8 多语言识别与翻译前处理
Section titled “4.8 多语言识别与翻译前处理”import asyncioimport websocketsimport json
ws_url = "wss://console.suanli.cn/serverless/idc/3576"async def multilingual_asr(): config = { "chunk_size": [5, 10, 5], "wav_name": "multi_demo", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "2pass" } audio_file = "multilang_8k.pcm" async with websockets.connect(ws_url) as ws: await ws.send(json.dumps(config, ensure_ascii=False)) with open(audio_file, "rb") as f: while True: chunk = f.read(8000) if not chunk: break await ws.send(chunk) await ws.send(json.dumps({"is_speaking": False})) while True: try: resp = await asyncio.wait_for(ws.recv(), timeout=5) print("多语言识别:", resp) # 示例输出:{"is_final":true,"text":"Welcome to the conference..."} if 'is_final' in resp and json.loads(resp).get('is_final'): break except asyncio.TimeoutError: break
asyncio.run(multilingual_asr())5. 常见问题与参考资料
Section titled “5. 常见问题与参考资料”音频需为 8kHz 单声道 PCM,建议用 ffmpeg 或 sox 转换
详细参数与高级用法见 FunASR 官方文档
GitHub:https://github.com/alibaba/FunASR
共绩算力 Open API 使用文档:https://www.gongjiyun.com/docs/y/openapi/zx3iwhbv1i8sxdkeiapcprxhn8d/