容器化部署 CosyVoice
本指南详细阐述了在共绩算力平台上,高效部署与使用 CosyVoice 项目的技术方案。基于新一代生成式语音大模型,CosyVoice 将文本理解和语音生成技术深度融合,能够精准解析并诠释各种文本内容,将其转化为如同真人发声般的自然语音,带来高度拟人化的自然语音合成体验。
1.在共绩算力上运行 CosyVoice
Section titled “1.在共绩算力上运行 CosyVoice”共绩算力平台提供预构建的 CosyVoice 容器镜像,用户无需本地复杂环境配置,可快速完成部署并启用服务。以下是详细部署步骤:
1.1 创建部署服务
Section titled “1.1 创建部署服务”登录共绩算力控制台,在控制台首页点击“弹性部署服务”进入管理页面。首次使用需确保账户已开通弹性部署服务权限。
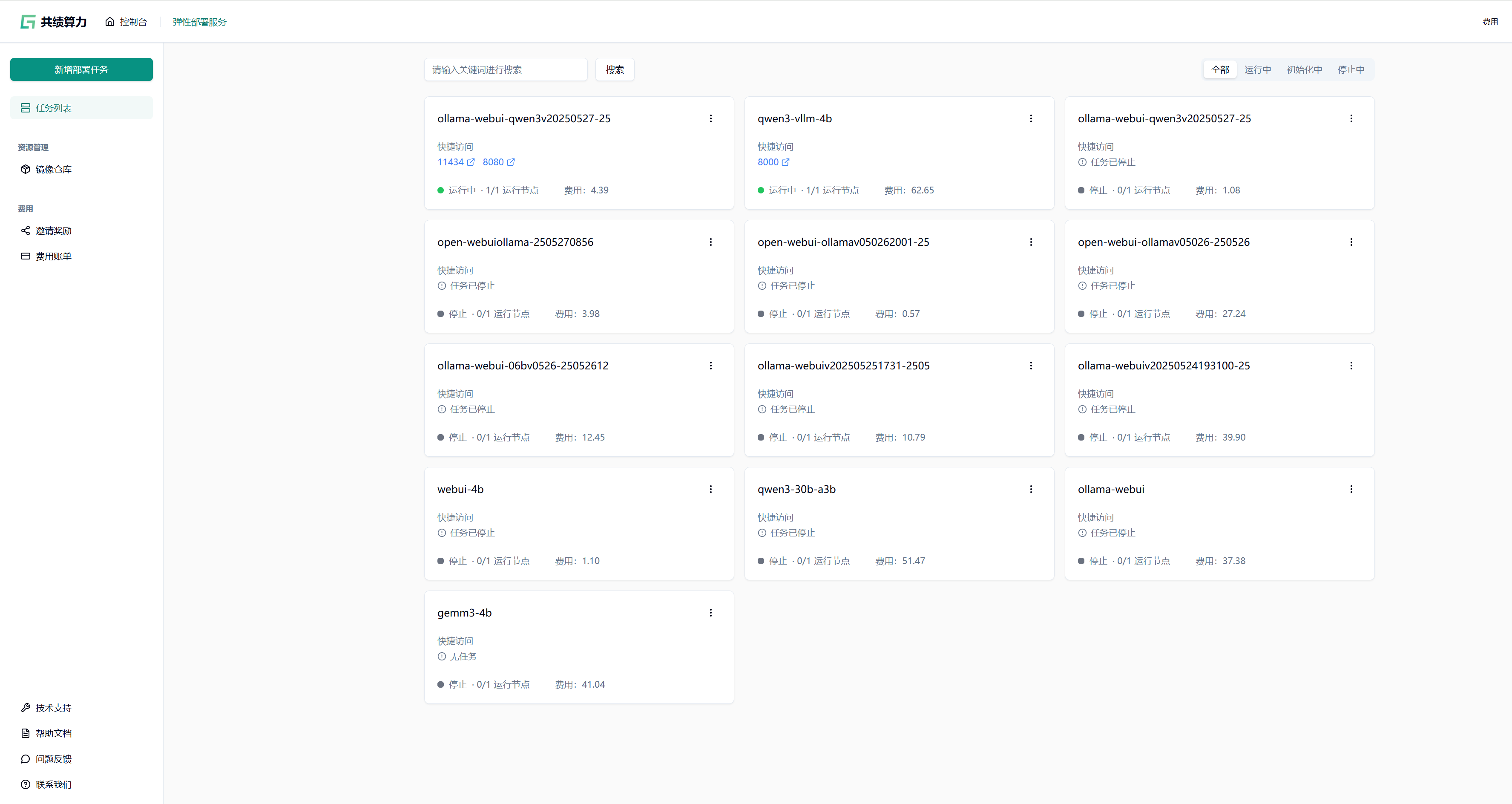
1.2 选择 GPU 型号
Section titled “1.2 选择 GPU 型号”根据实际需求选择 GPU 型号:
初次使用或调试阶段,推荐配置单张 NVIDIA RTX 4090 GPU
1.3 选择预制镜像
Section titled “1.3 选择预制镜像”在“服务配置”模块切换至“预制服务”选项卡,搜索并选择 CosyVoice 官方镜像。
1.4 部署并访问服务
Section titled “1.4 部署并访问服务”点击“部署服务”,平台将自动拉取镜像并启动容器。
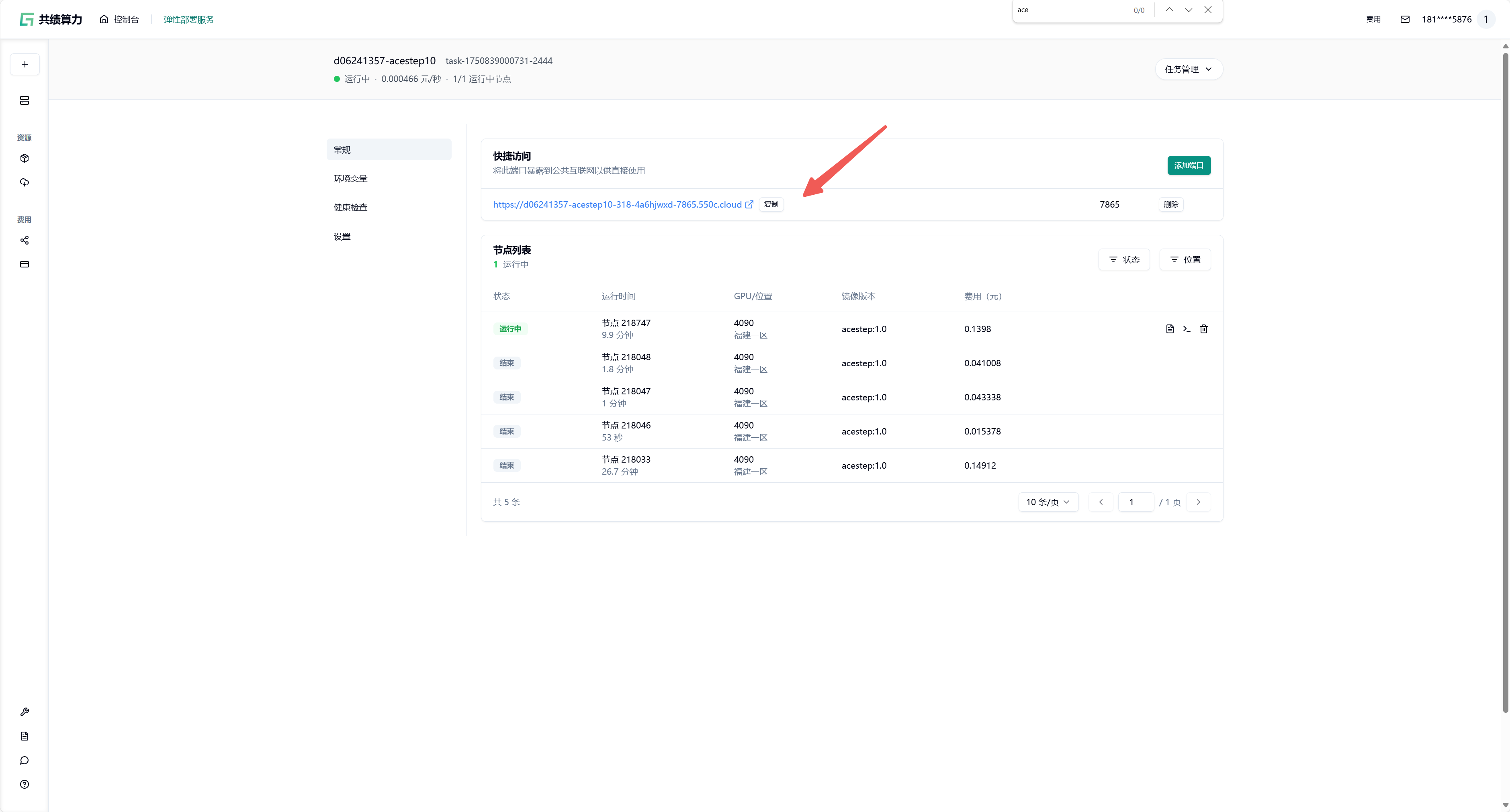
部署完成后,在“快捷访问”中找到端口为 7865 的公网访问链接,点击即可在浏览器中使用 CosyVoice 的 Web 界面,或通过该地址调用 API 服务。
2.快速上手
Section titled “2.快速上手”使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
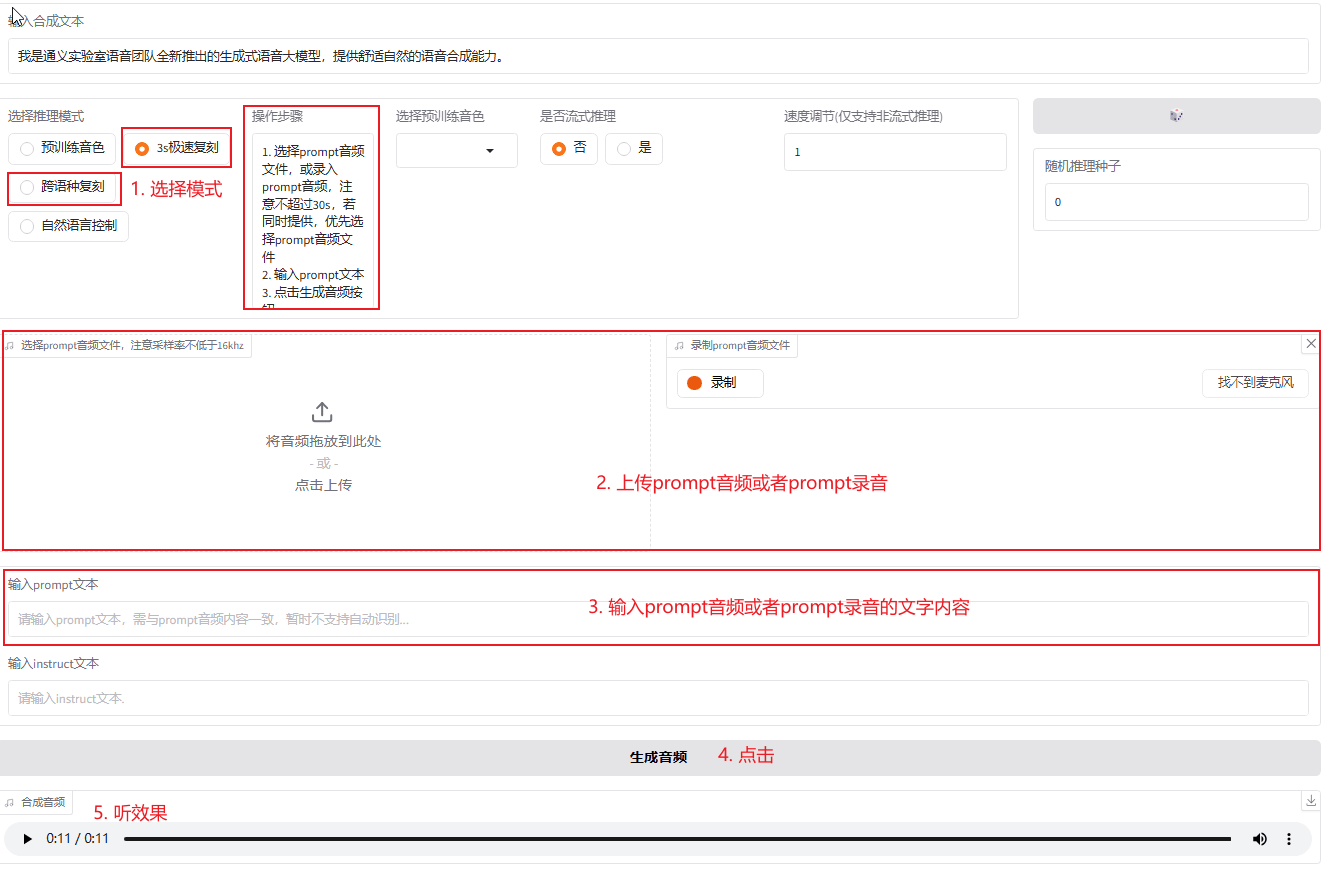
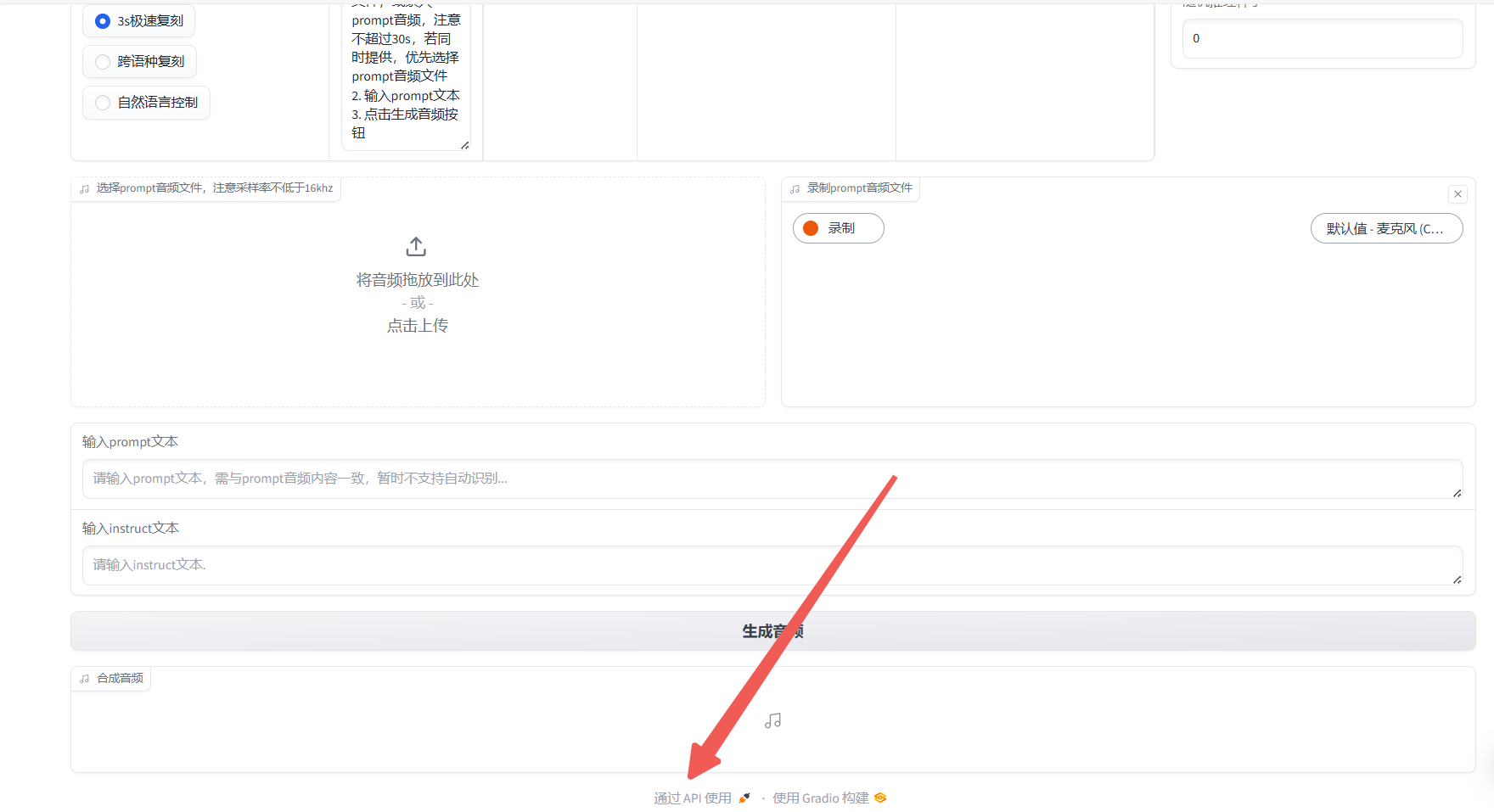
各模块功能如下:
3.API 调用指南
Section titled “3.API 调用指南”CosyVoice 提供完整的 API 接口体系,支持通过编程方式实现音乐创作全流程自动化。以下为核心接口详解与调用示范:
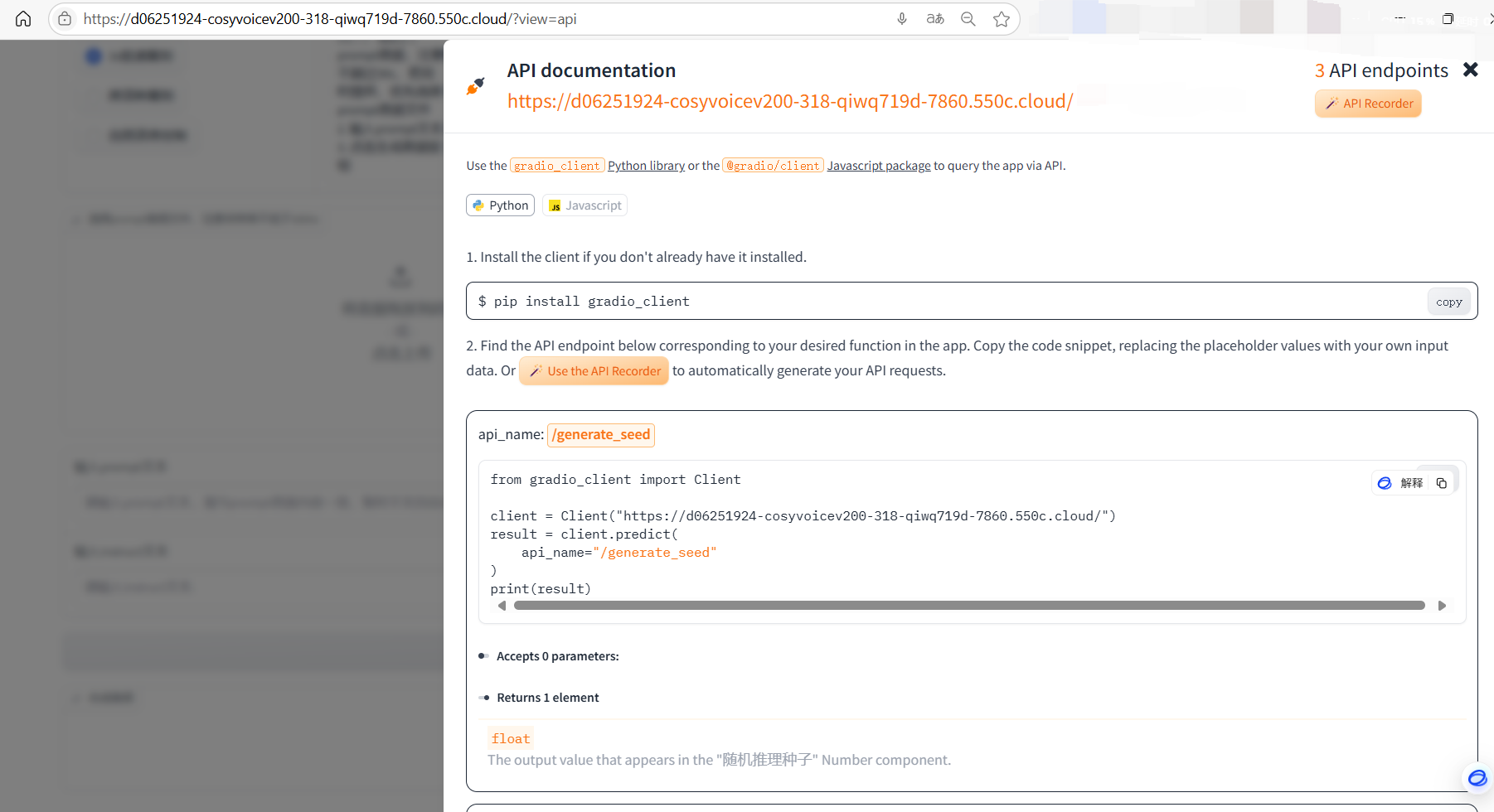
使用前请确保已安装 gradio_client 包:
pip install gradio_client3.1 基础调用流程
Section titled “3.1 基础调用流程”from gradio_client import Client, file
client = Client("https://d06251924-cosyvoicev200-318-qiwq719d-7860.550c.cloud/")
seed = client.predict(api_name="/generate_seed")[0]
instruction = client.predict( mode_checkbox_group="预训练音色", api_name="/change_instruction")[0]
result = client.predict( tts_text="这里是需要合成的文本内容", mode_checkbox_group="预训练音色", sft_dropdown="default", # 替换为实际音色名 seed=seed, prompt_wav_upload=file("/本地路径/参考音频.wav"), prompt_wav_record=file("/本地路径/参考音频.wav"), stream="false", api_name="/generate_audio")audio_path = result[0] # 获取生成音频路径3.2 参数使用说明
Section titled “3.2 参数使用说明”3.3 音频生成注意事项
Section titled “3.3 音频生成注意事项”-
文件要求:参考音频需满足:
- 采样率 ≥16kHz
- WAV 格式最佳
- 长度根据模式调整(“3s 极速复刻”需 5 秒素材)
-
跨语种模式:
result = client.predict( tts_text="Hello world", mode_checkbox_group="跨语种复刻", prompt_text="英文发音提示词", api_name="/generate_audio")- 流式生成(适用长内容):
stream = "true"3.4 错误处理建议
Section titled “3.4 错误处理建议”- 音色加载失败 → 检查
sft_dropdown值是否有效 - 音频生成中断 → 降低
speed数值(1.0 为原速) - 跨语种发音异常 → 补充
prompt_text发音提示
3.5 输出结果示例
Section titled “3.5 输出结果示例”print(result)
import shutilshutil.copyfile('/tmp/gradio/synth_audio.wav', '最终成品.wav')实际调用时请根据业务场景调整模式选择和音频参数,预置音色列表可通过 Web 界面查看或在调用/change_instruction时获取关联值。