容器化部署 minerU
更新(2025 年 9 月 26 日)
目前平台上的镜像已经更新到 minerU 2.5.3,相关功能与原先有所差异。
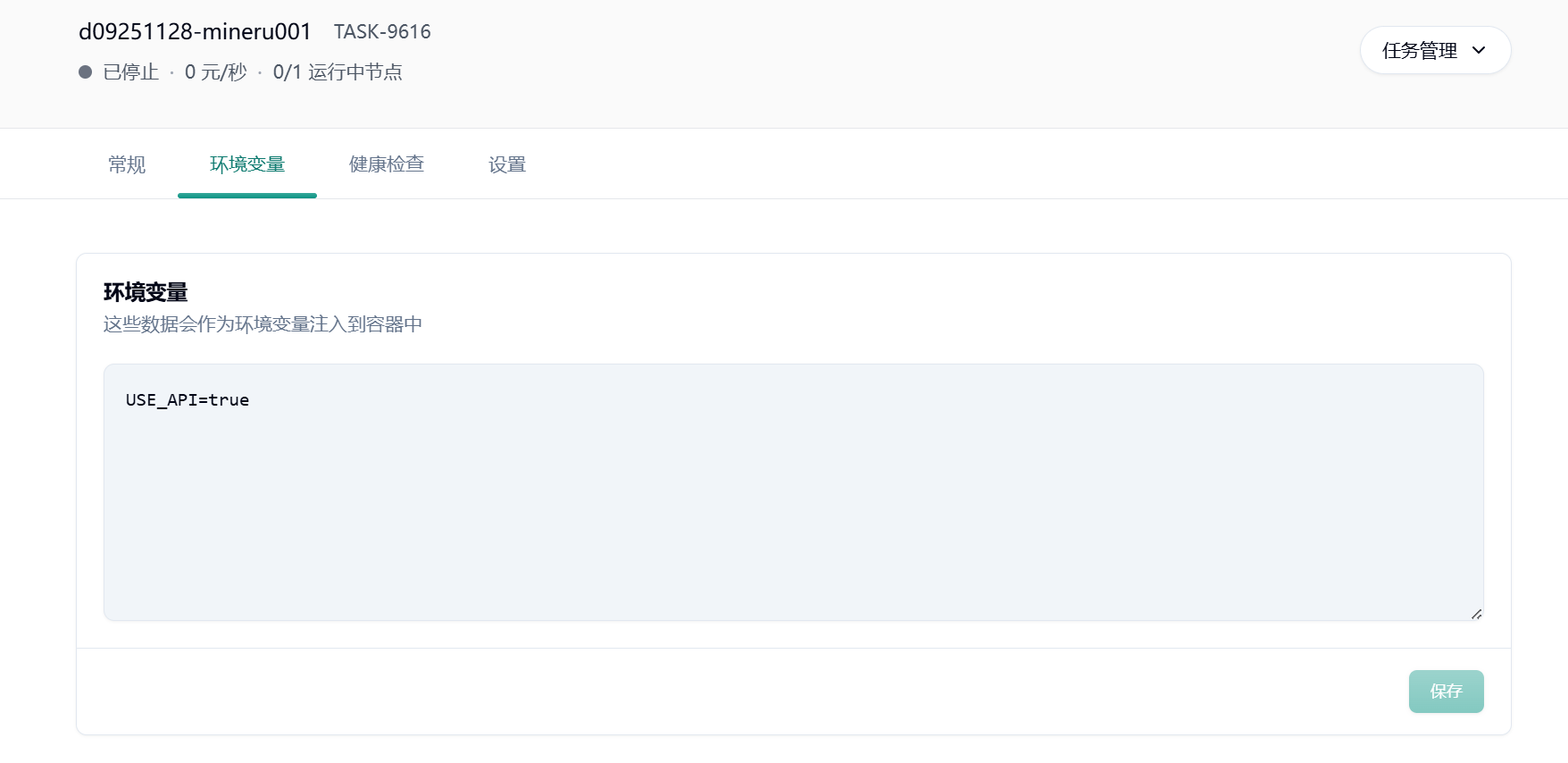
minerU2.5 后推理后端从 sglang 更改为 vllm。web UI 与 api 支持独自部署。平台默认启动 web UI,可通过环境变量USE_API=true部署 api 服务。
🌹
此镜像提供了标准化的 API 接口和 web UI 界面,让您能够便捷地访问和使用所有功能。
本指南详细阐述了在共绩算力平台上,高效部署与使用 minerU API 项目的技术方案。minerU 是一款将 PDF 转化为机器可读格式的工具(如 markdown、json),可以很方便地输出为任意格式。
1.在共绩算力上运行 minerU
Section titled “1.在共绩算力上运行 minerU”共绩算力平台提供预构建的 minerU 容器镜像,用户无需本地复杂环境配置,可快速完成部署并启用服务。以下是详细部署步骤:
1.1 创建部署服务
Section titled “1.1 创建部署服务”登录共绩算力控制台,在控制台首页点击“弹性部署服务”进入管理页面。首次使用需确保账户已开通弹性部署服务权限。

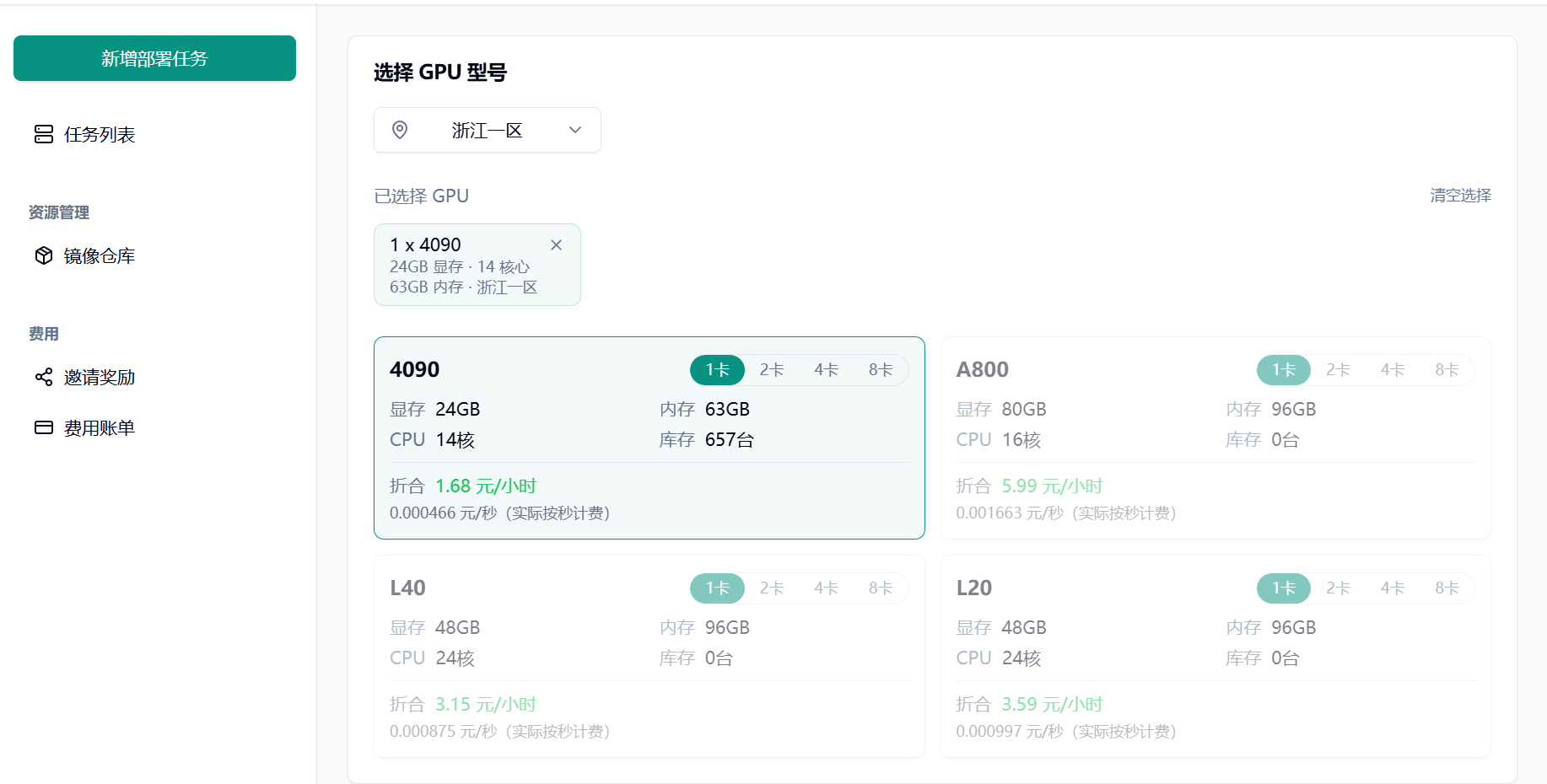
1.2 选择 GPU 型号
Section titled “1.2 选择 GPU 型号”根据实际需求选择 GPU 型号:
初次使用或调试阶段,推荐配置单张 NVIDIA RTX 4090 GPU
1.3 选择预制镜像
Section titled “1.3 选择预制镜像”在“服务配置”模块切换至“预制服务”选项卡,搜索并选择 minerU 官方镜像。
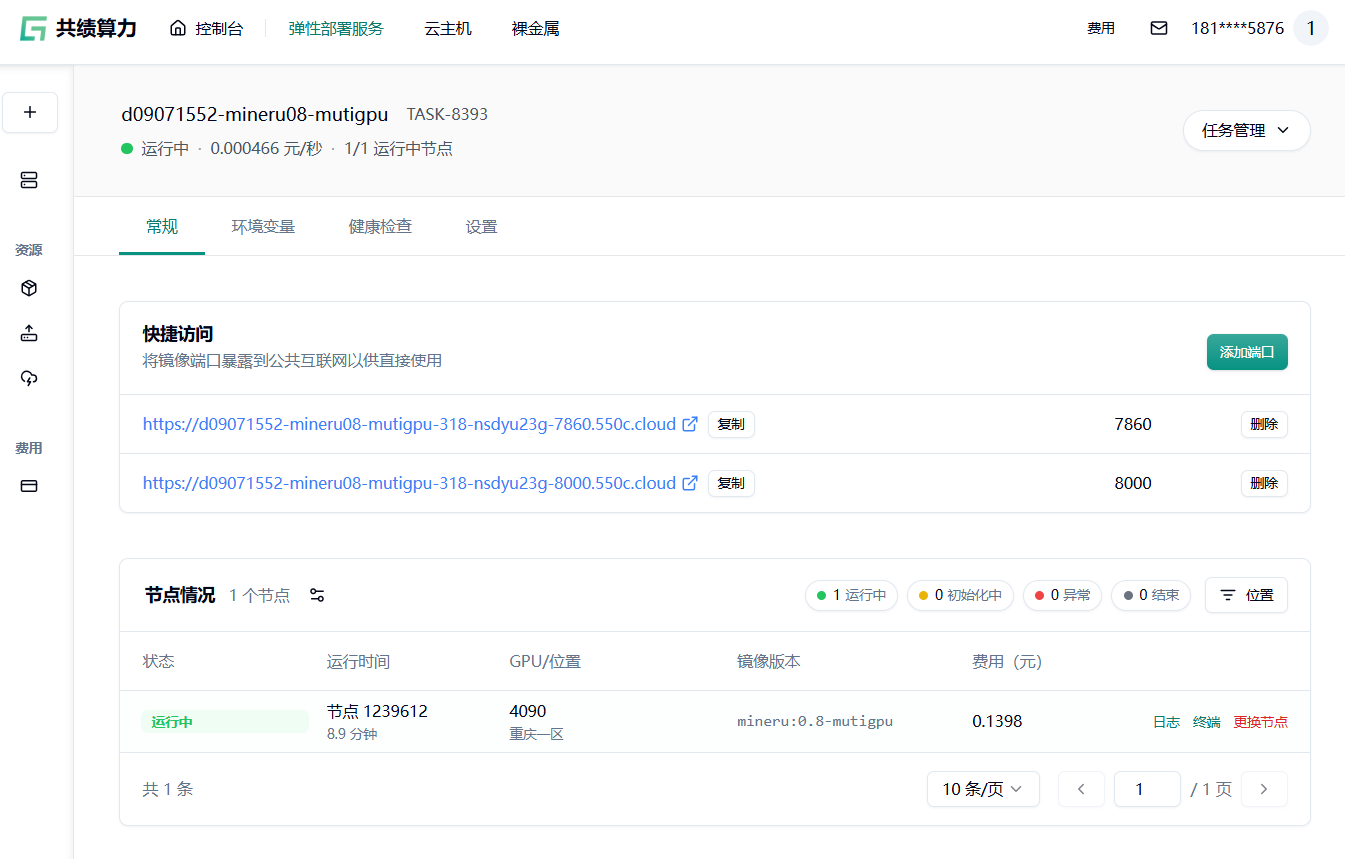
1.4 部署并访问服务
Section titled “1.4 部署并访问服务”点击“部署服务”,平台将自动拉取镜像并启动容器。
2.快速上手—— web UI 界面使用说明
Section titled “2.快速上手—— web UI 界面使用说明”点击 7860 端口对应的链接进入 web UI 界面
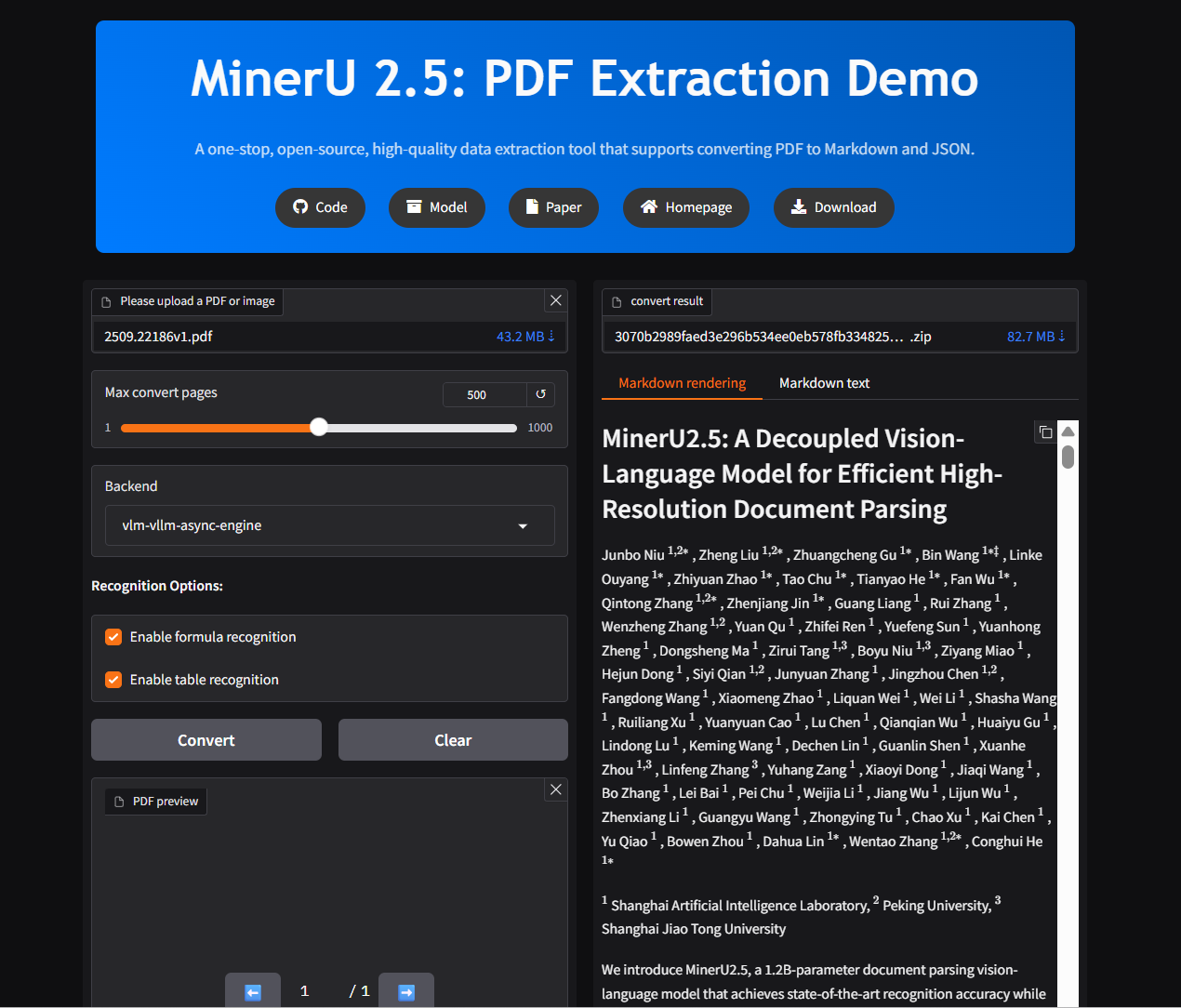
上传完成后即可开始解析:
3.快速上手—— API 使用说明
Section titled “3.快速上手—— API 使用说明”启动前设置环境变量 USE_API=true 部署完成后,在“快捷访问”中复制端口为 8000 的公网访问链接,后续是通过该地址调用 API 服务。
地址后面加上 /docs 进入 API 接口文档
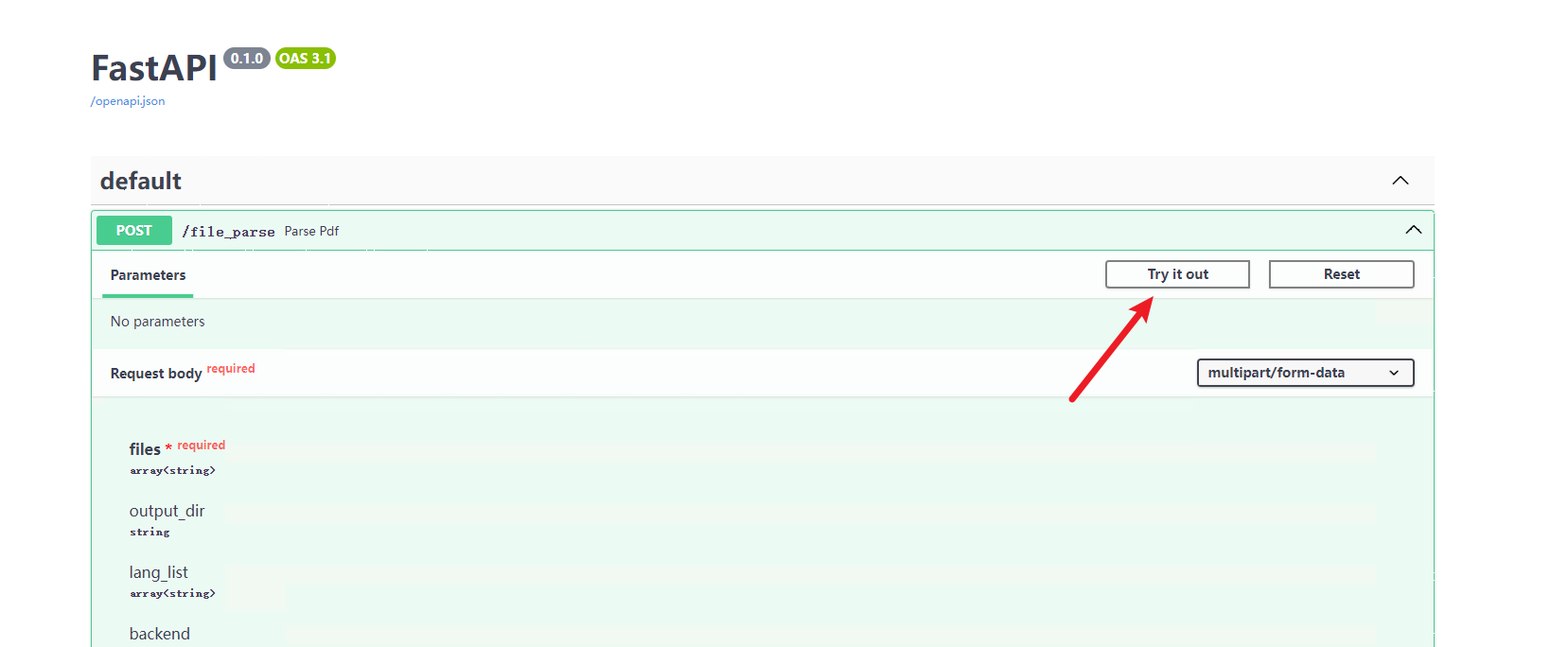
3.1 直接使用
Section titled “3.1 直接使用”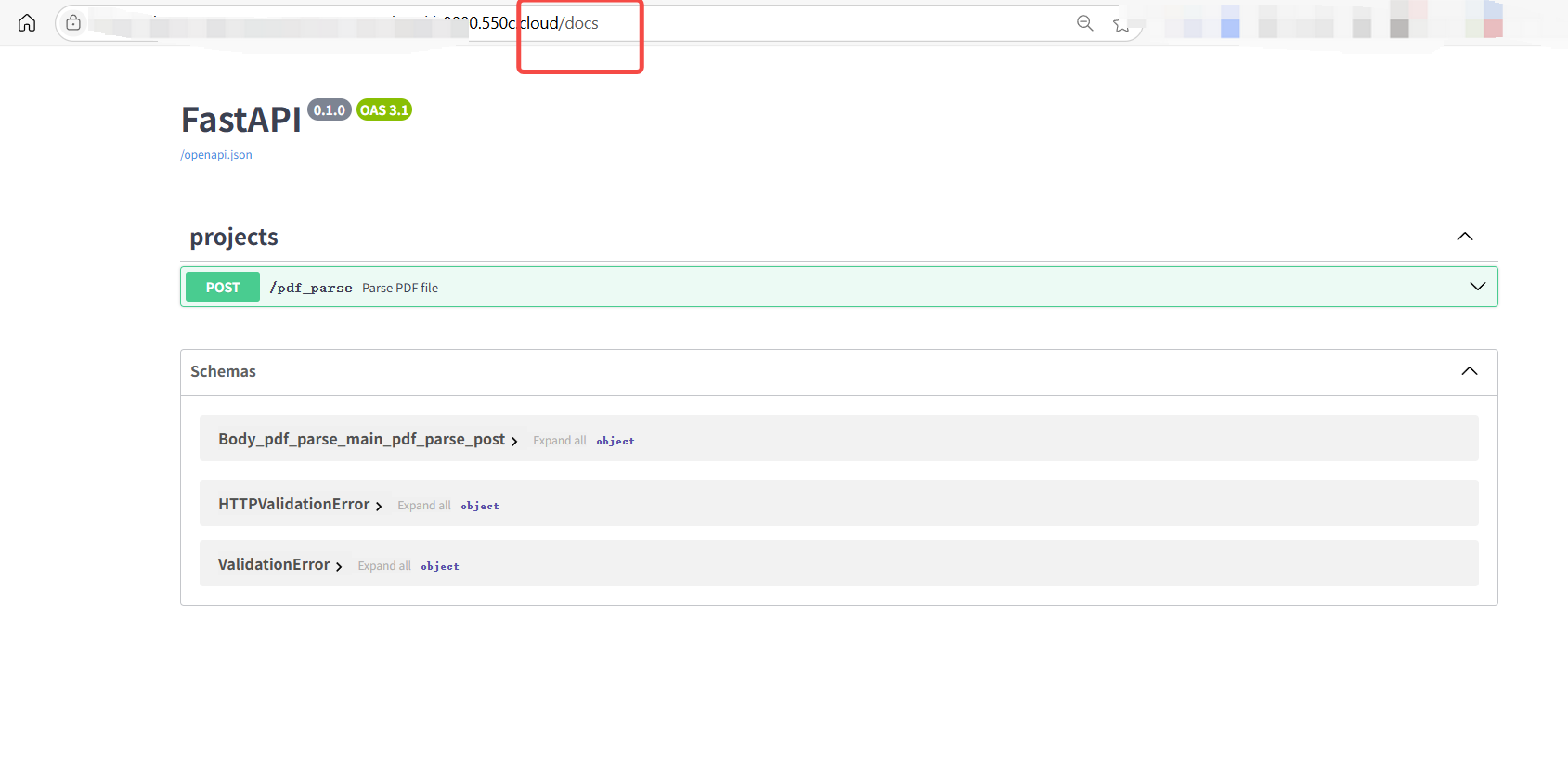
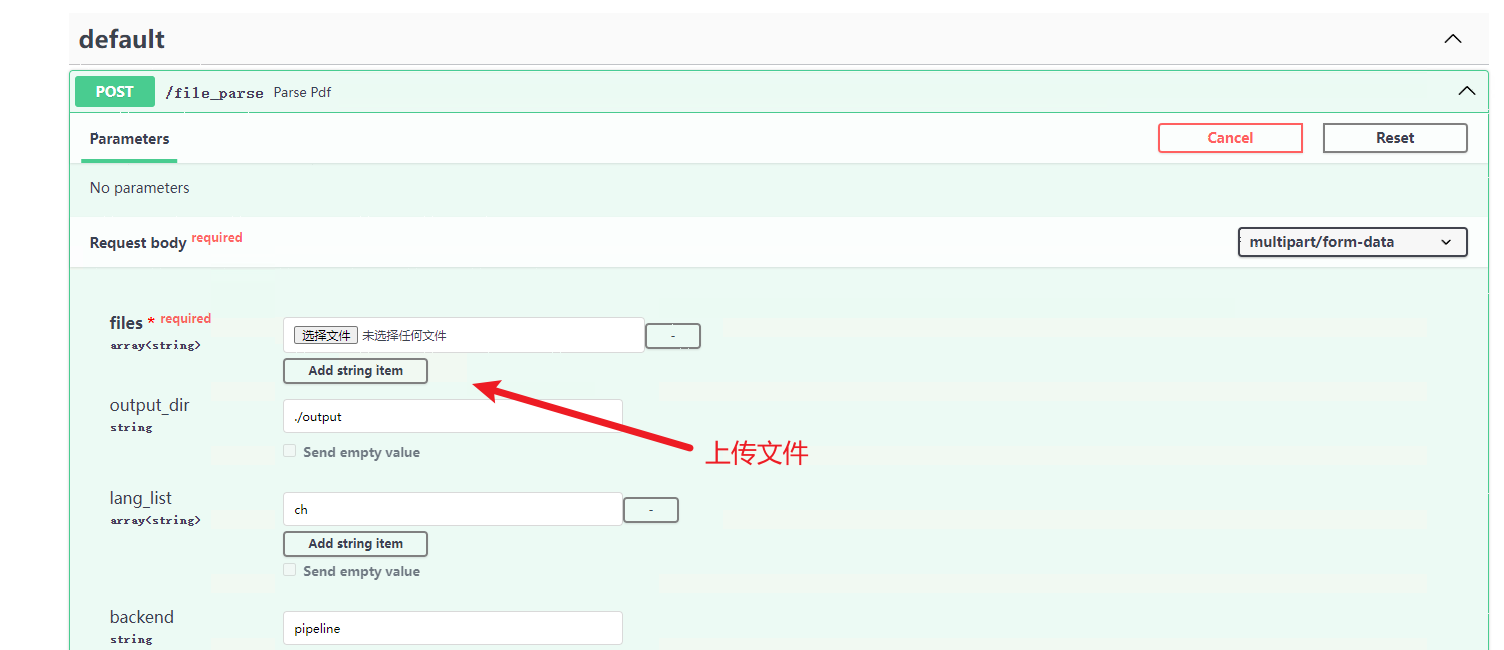
3.2 完整 API 使用示例
Section titled “3.2 完整 API 使用示例”import requestsimport jsonimport osfrom pathlib import Pathimport base64
API_URL = "https://test-mineru-service-239-4vxz4deq-8000.550c.cloud/file_parse"
FILES = [ r"C:\Users\27461\Downloads\ 13710204986.pdf",]
OPTIONS = { "output_dir": None, "backend": "pipeline", "parse_method": "auto", "formula_enable": True, "table_enable": True, "return_md": True, "return_middle_json": False, "return_model_output": False, "return_content_list": False, "return_images": True, "start_page_id": 0}
def get_file_key(file_path): path = Path(file_path) return path.stem
def save_md_content(md_content, output_path="output.md"): with open(output_path, "w", encoding="utf-8") as f: f.write(md_content) print(f"📄 Markdown 内容已保存至 {output_path}")
def save_images(images, output_dir="output_images"): os.makedirs(output_dir, exist_ok=True)
# 🔴 修复:images 是 dict,不是 list if isinstance(images, dict): items = images.items() elif isinstance(images, list): items = enumerate(images) else: print("❌ images 格式不支持,类型:", type(images)) return
saved_count = 0 for key, img_b64 in items: try: if not isinstance(img_b64, str): print(f"❌ 图片 {key} 不是字符串,跳过") continue
# 去除 data:image/xxx;base64, 前缀 if "," in img_b64: img_b64 = img_b64.split(",", 1)[1]
# 补齐 padding missing_padding = len(img_b64) % 4 if missing_padding: img_b64 += "=" * (4 - missing_padding)
# 解码 img_bytes = base64.b64decode(img_b64)
# 使用 key 作为文件名,或用序号 if isinstance(key, str): img_name = key # 保留原始文件名,如 "image_0.png" else: img_name = f"image_{saved_count:03d}"
img_path = Path(output_dir) / f"{img_name}" with open(img_path, "wb") as f: f.write(img_bytes) print(f"✅ 保存图片:{img_path.name}") saved_count += 1
except Exception as e: print(f"❌ 保存图片 {key} 失败:{e}")
print(f"🖼️ 已保存 {saved_count} 张图片到 {output_dir}/")
def test_file_parse(): for file_path in FILES: if not os.path.exists(file_path): print(f"❌ 文件不存在:{file_path}") return
file_entries = [] file_objects = []
for file_path in FILES: path = Path(file_path) f = open(file_path, 'rb') content_type = 'application/pdf' if path.suffix.lower() == '.pdf' else 'image/jpeg' file_entries.append(('files', (path.name, f, content_type))) file_objects.append(f)
data = {} for key, value in OPTIONS.items(): if value is not None: if isinstance(value, (list, tuple)): data[key] = json.dumps(value, ensure_ascii=False) else: data[key] = str(value)
try: print("📤 正在发送请求到 MinerU API...") response = requests.post(API_URL, data=data, files=file_entries)
print(f"📡 状态码:{response.status_code}")
if response.status_code == 200: result = response.json() print("✅ 解析成功!")
if "results" not in result: print("❌ 缺少 'results' 字段") print("返回:", json.dumps(result, indent=2, ensure_ascii=False)) return
results = result["results"]
for file_path in FILES: file_key = get_file_key(file_path) if file_key not in results: print(f"❌ 找不到结果:{file_key},可用 keys: {list(results.keys())}") continue
file_result = results[file_key]
if "md_content" in file_result: save_md_content(file_result["md_content"], f"output_{file_key}.md") else: print(f"⚠️ 无 md_content")
if "images" in file_result and file_result["images"]: save_images(file_result["images"], "images") else: print(f"🔍 无图片内容")
if "content_list" in file_result: with open(f"content_list_{file_key}.json", "w", encoding="utf-8") as f: json.dump(file_result["content_list"], f, indent=2, ensure_ascii=False) print(f"📋 content_list 已保存")
else: print("❌ 请求失败:") try: print(json.dumps(response.json(), indent=2, ensure_ascii=False)) except: print(response.text)
except Exception as e: print(f"🚨 异常:{e}") finally: for f in file_objects: try: f.close() except: pass
if __name__ == "__main__": test_file_parse()