容器化部署 ACE-Step
本指南详细阐述了在共绩算力平台上,高效部署与使用 ACE-Step 项目的技术方案。ACE-Step 是由人工智能公司阶跃星辰(StepFun)与数字音乐平台 ACE Studio 联合研发并于 2025 年 5 月 7 日开源。模型在 A100 GPU 上只需 20 秒即可合成长达 4 分钟的音乐,比基于 LLM 的基线快 15 倍,同时在旋律、和声和节奏指标方面实现了卓越的音乐连贯性和歌词对齐。此外,该模型保留了精细的声学细节,支持高级控制机制,例如语音克隆、歌词编辑、混音和音轨生成。
1.在共绩算力上运行 ACE-Step
Section titled “1.在共绩算力上运行 ACE-Step”共绩算力平台提供预构建的 ACE-Step 容器镜像,用户无需本地复杂环境配置,可快速完成部署并启用服务。以下是详细部署步骤:
1.1 创建部署服务
Section titled “1.1 创建部署服务”登录共绩算力控制台,在控制台首页点击“弹性部署服务”进入管理页面。首次使用需确保账户已开通弹性部署服务权限。
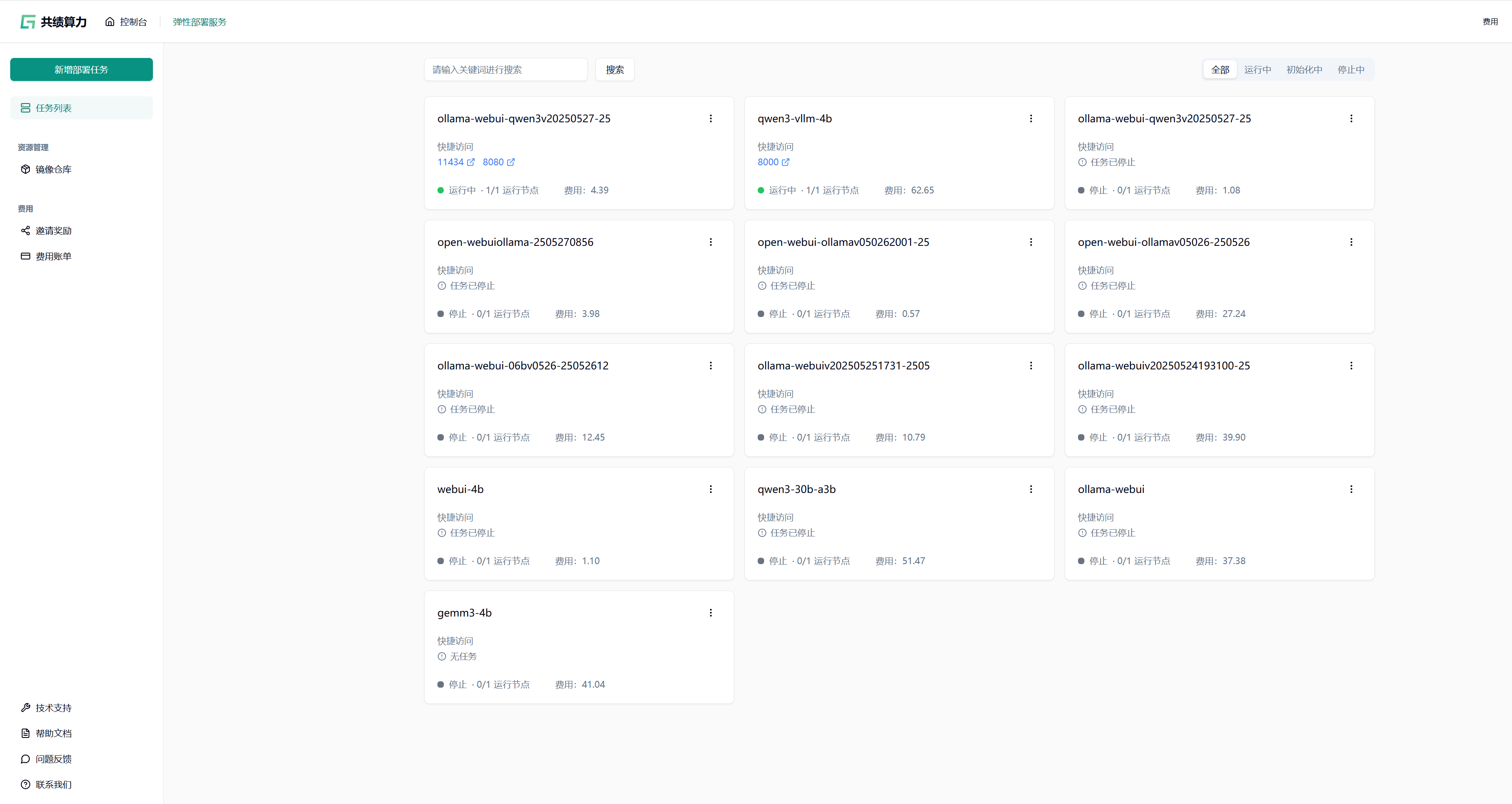
1.2 选择 GPU 型号
Section titled “1.2 选择 GPU 型号”根据实际需求选择 GPU 型号:
初次使用或调试阶段,推荐配置单张 NVIDIA RTX 4090 GPU
1.3 选择预制镜像
Section titled “1.3 选择预制镜像”在“服务配置”模块切换至“预制服务”选项卡,搜索并选择 ACE-Step 官方镜像。
1.4 部署并访问服务
Section titled “1.4 部署并访问服务”点击“部署服务”,平台将自动拉取镜像并启动容器。

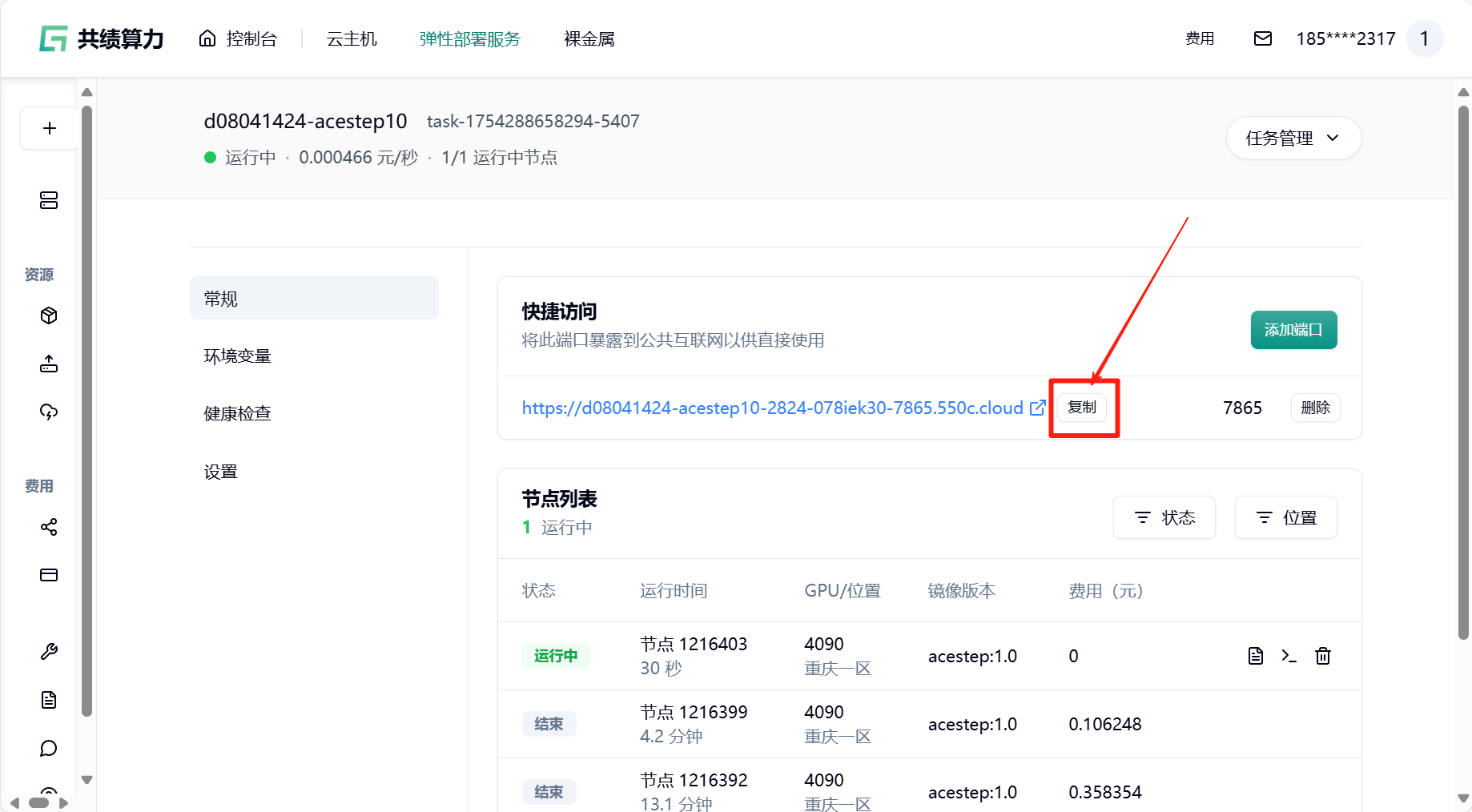
部署完成后,在“快捷访问”中找到端口为 7865 的公网访问链接,点击即可在浏览器中使用 ACE-Step 的 Web 界面,或通过该地址调用 API 服务。
2.快速上手
Section titled “2.快速上手”使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
该项目提供多任务创作面板:Text2Music Tab、Retake Tab、Repainting Tab、Edit Tab 和 Extend Tab。
各模块功能如下:
2.1 Text2Music Tab
Section titled “2.1 Text2Music Tab”-
Input Fields
- Tags:输入描述性标签、音乐流派或场景描述,用逗号分隔
- Lyrics:输入带有结构标签的歌词,如 [verse] 、 [chorus] 、 [bridge]
- Audio Duration:设置生成音频的时长(-1 表示随机生成)
-
Settings
- Basic Settings:调整推理步数、指导比例和种子值
- Advanced Settings:微调调度器类型、CFG 类型、ERG 设置等参数
-
Generation
- 点击「Generate」按钮,根据输入内容创作音乐
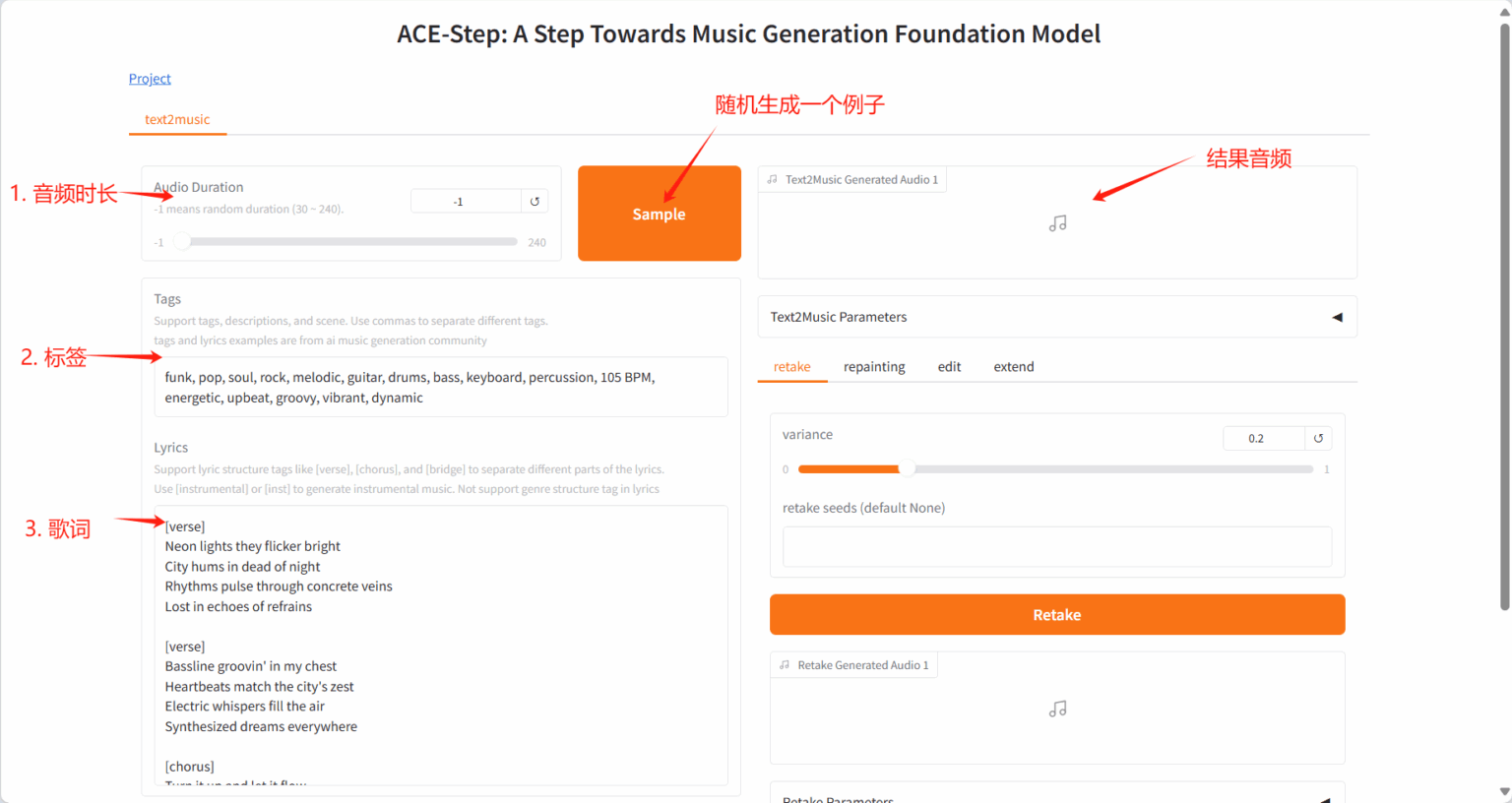
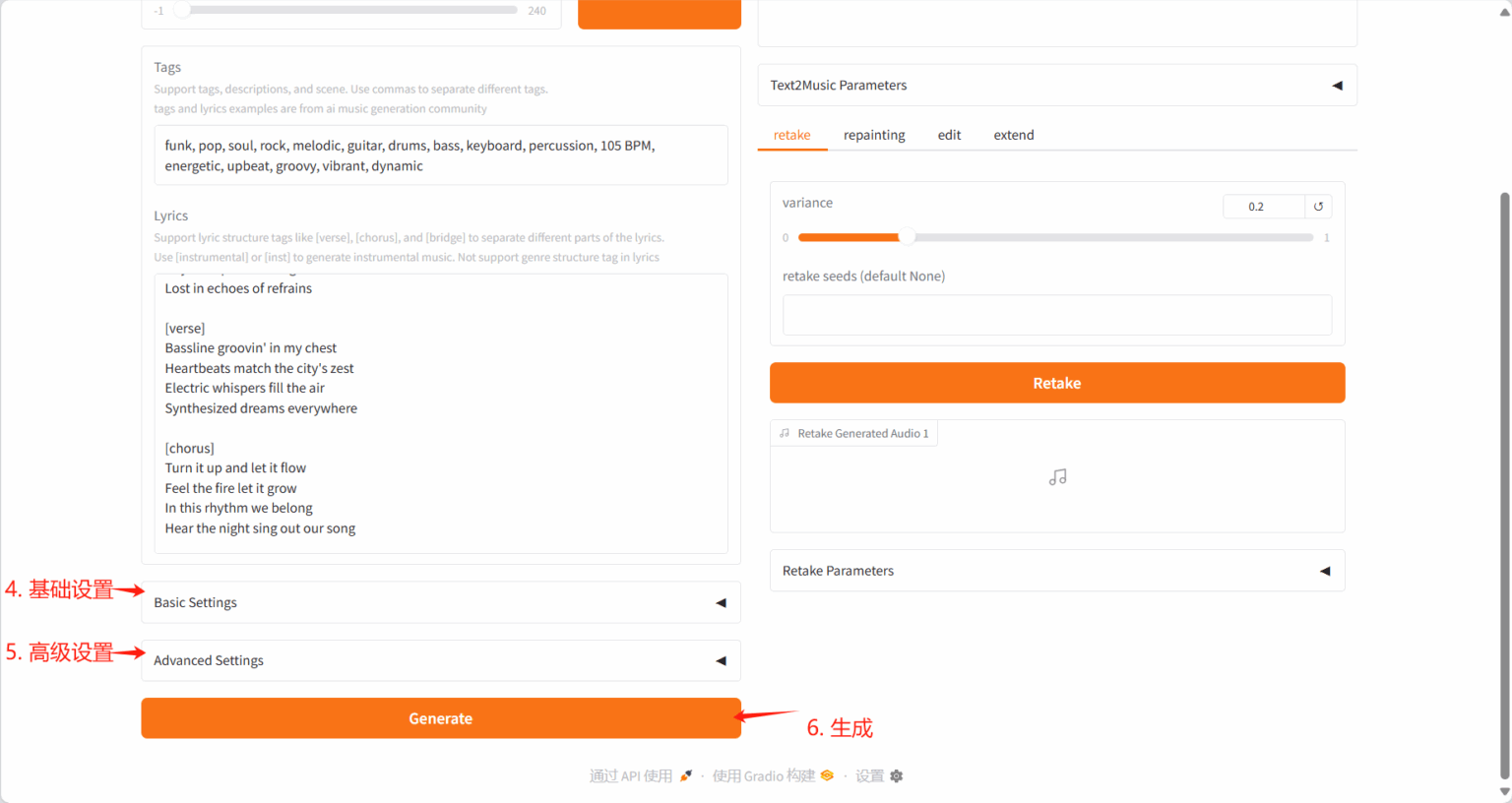
生成结果:
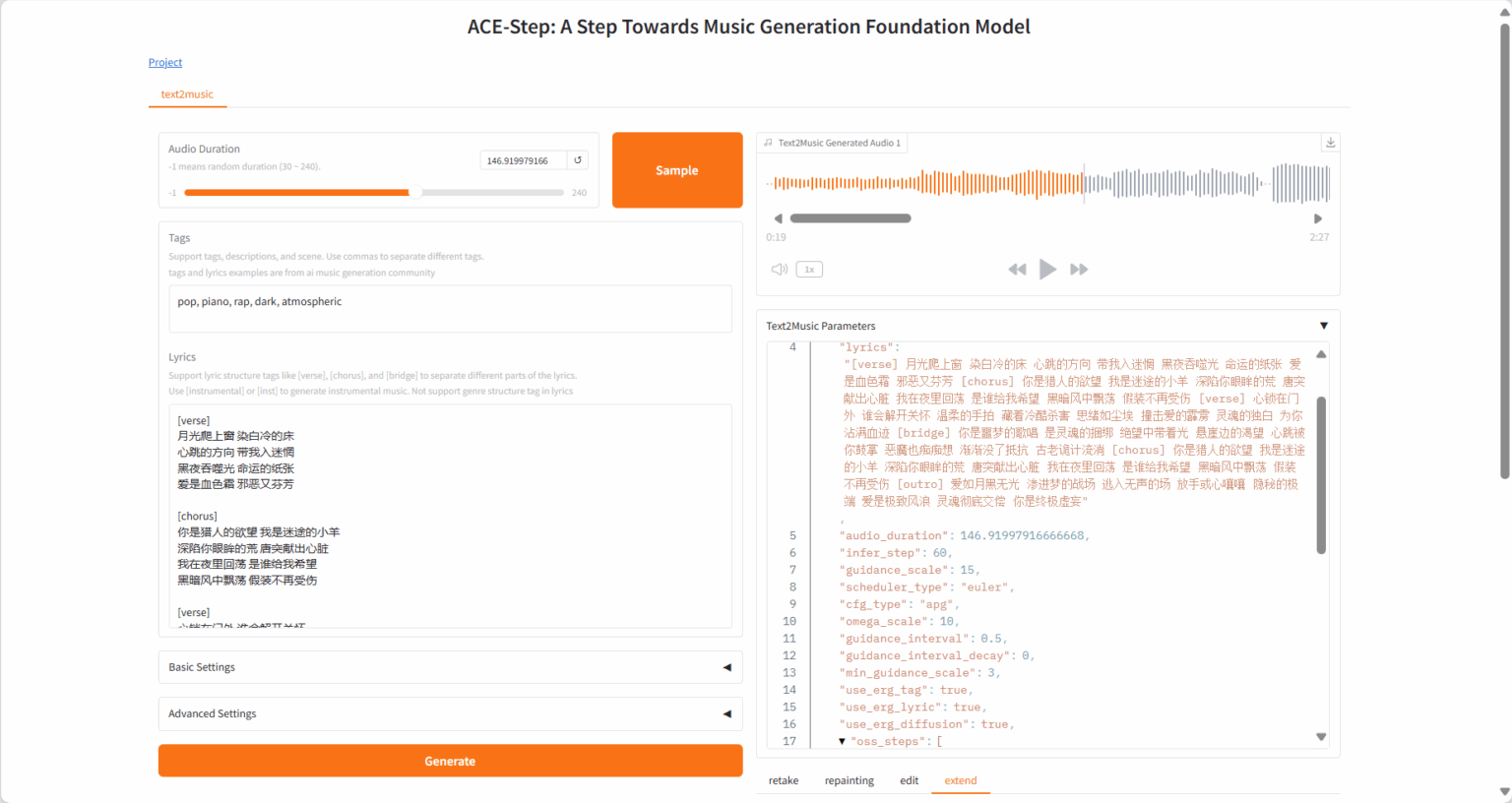
2.2 Retake Tab
Section titled “2.2 Retake Tab”- 通过不同种子值重新生成音乐并产生细微变化
- 调整变化参数以控制新版本与原版的差异程度
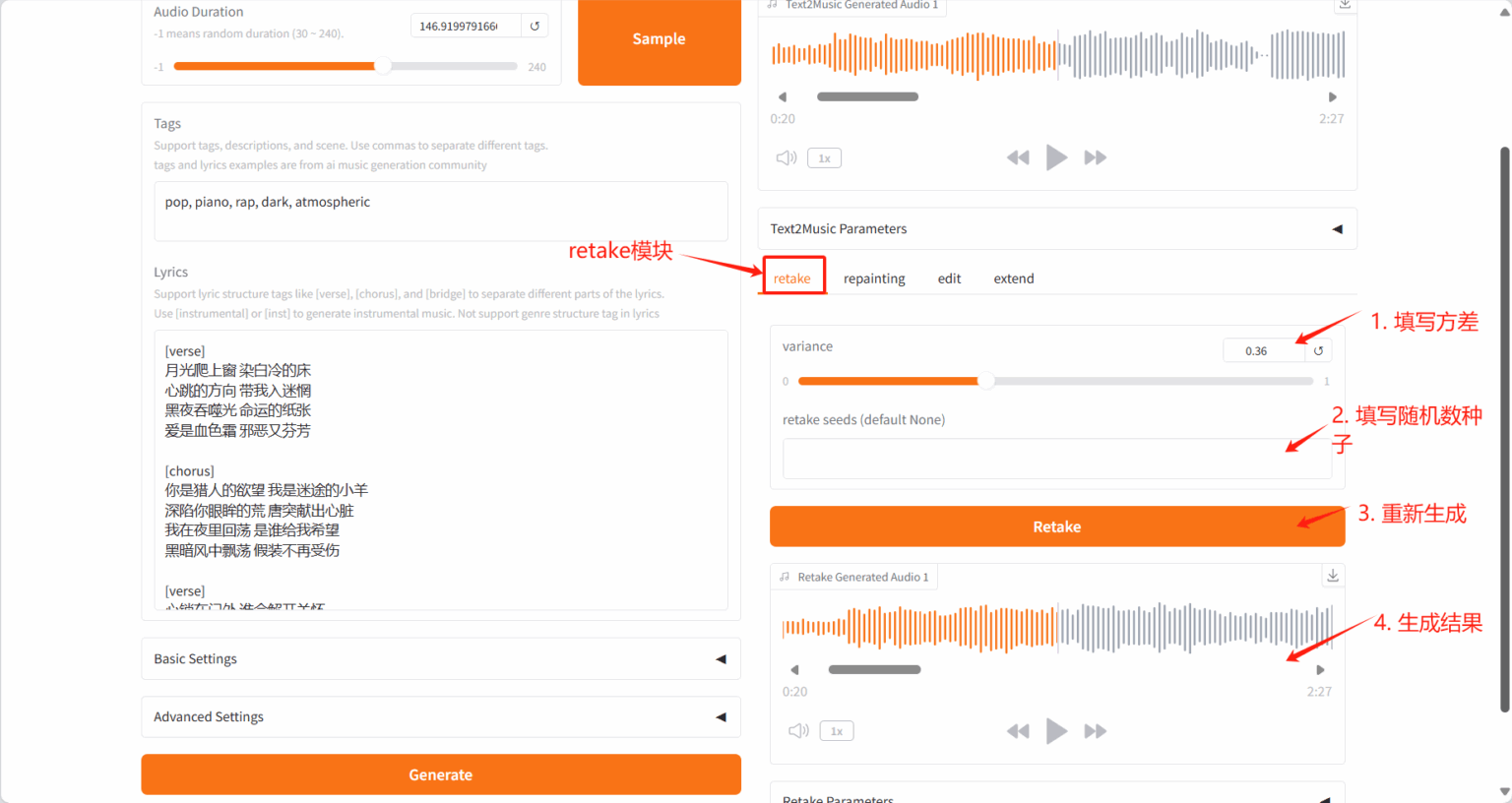
2.3 Edit Tab
Section titled “2.3 Edit Tab”- 通过修改标签或歌词来改编现有音乐
- 可选择「only_lyrics」模式(保留原旋律)或「remix」模式(改变旋律)
- 通过调整编辑参数控制对原曲的保留程度
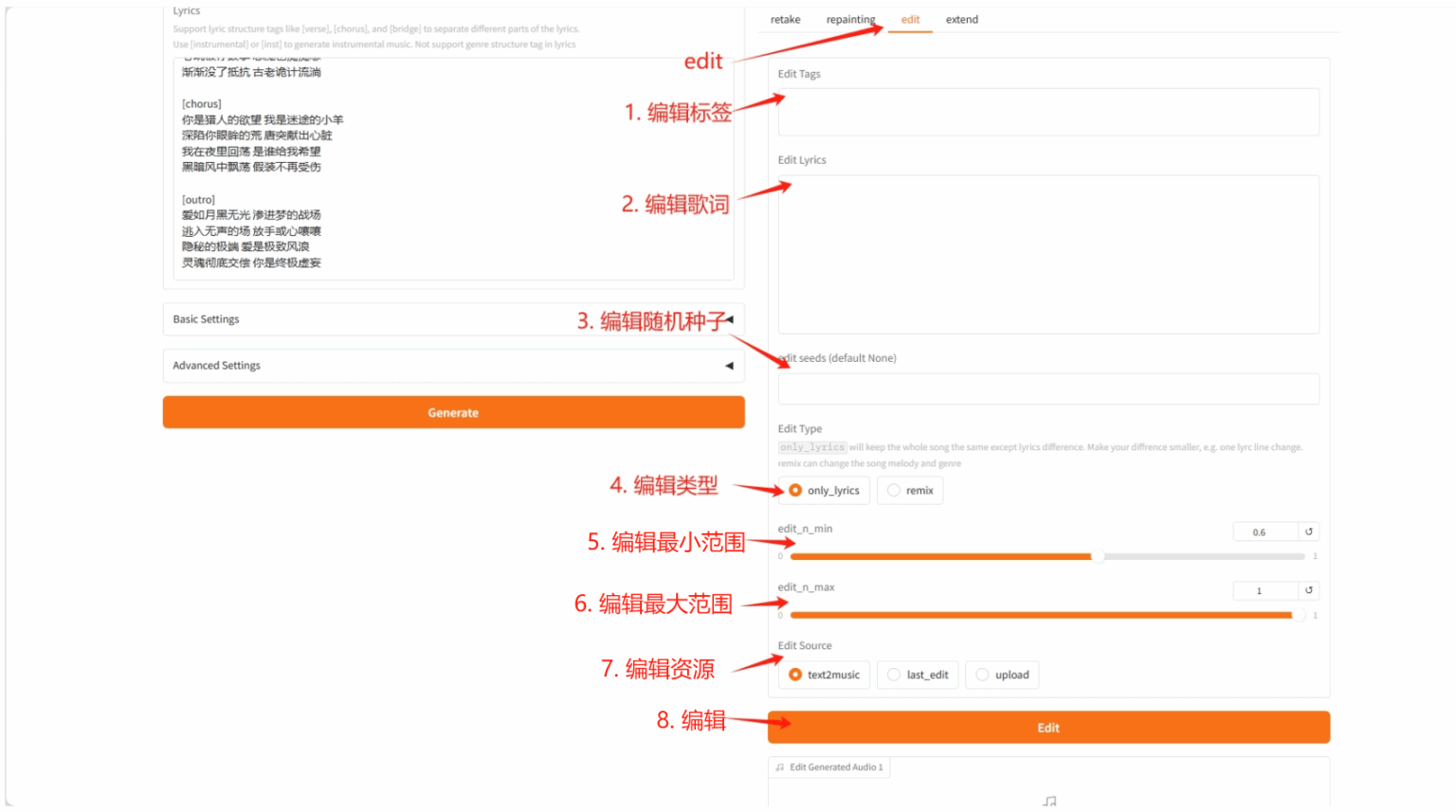
2.4 Extend Tab
Section titled “2.4 Extend Tab”- 在现有音乐的开头或结尾添加音乐片段
- 指定左右两侧的扩展时长
- 选择需要扩展的源音频
3.API 的调用
Section titled “3.API 的调用”ACE-Step 提供完整的 API 接口体系,支持通过编程方式实现音乐生成与编辑。以下为官方核心接口详解与调用示范:
我们预制好的镜像中 7865 端口为 API 调用接口地址,可以在生产环境中直接使用
3.1 环境准备指南
Section titled “3.1 环境准备指南”首先需要在电脑上安装 gradio_client
pip install gradio_client连接到音乐生成网站
from gradio_client import Client, handle_file
client = Client("https://d08041424-acestep10-2824-078iek30-7865.550c.cloud/")3.2 核心功能接口
Section titled “3.2 核心功能接口”- 最基础:生成一首新音乐 (
/__call__)
这是最常用的功能,根据文字描述生成音乐。
result = client.predict( # 你可以修改这些参数! format="wav", # 生成的音乐格式,可选 mp3, wav 等 audio_duration=60, # 音乐时长,单位是秒。-1 可能表示默认时长 prompt="jazz, piano, saxophone, smooth, 80 BPM, relaxing, nighttime", # 音乐风格描述,用英文逗号分隔关键词 lyrics="""[verse]The city sleeps beneath the moonA gentle tune begins too soon[chorus]Let the music carry you awayInto the night, where dreams will stay""", # 你的歌词,可以为空 infer_step=50, # 生成步骤,数值越高细节越好,但更慢 guidance_scale=12, # 指导强度,数值越高越贴近你的描述 scheduler_type="euler", # 生成算法,一般用默认的就行 # ... 其他参数保持默认或根据需要修改 api_name="/__call__")
generated_audio_path = result[0] # 这是生成的音乐文件的链接generated_params = result[1] # 这是生成时用的参数,可以保存下来以后用
print("音乐生成完成!")print("音乐文件:", generated_audio_path)print("参数:", generated_params)- 修改现有音乐 (
/edit_process_func)
这个功能可以让你“重混”或修改歌词。
result = client.predict( # 你需要提供之前生成音乐时得到的参数 text2music_json_data=generated_params, # 用上一步的 generated_params edit_input_params_json=generated_params, # 通常和上面一样 edit_source="text2music", # 从哪里获取原始音频,"text2music"表示用上面的参数重新生成 # edit_source_audio_upload=handle_file('你的本地音乐文件路径'), # 或者上传一个本地文件 prompt="jazz, piano, saxophone, smooth, 80 BPM, relaxing, nighttime", lyrics="[verse] The city sleeps beneath the moon... [chorus] Let the music carry you away...", # 原歌词 # 关键:你要修改的部分 edit_prompt="jazz, piano, saxophone, **upbeat**, **danceable**, 100 BPM", # 修改风格 edit_lyrics="**[verse] Wake up! It's time to move!** ... [chorus] Dance the night away!", # 修改歌词 edit_n_min=0.5, # 从音乐的 50% 处开始修改 edit_n_max=1.0, # 修改到 100% 结束(即后半部分) # ... 其他参数 api_name="/edit_process_func")- 扩展音乐长度 (
/extend_process_func)
把一首 30 秒的音乐延长到 60 秒。
result = client.predict( text2music_json_data=generated_params, # 用原始音乐的参数 extend_input_params_json=generated_params, extend_source="text2music", # 基于原始音乐 # extend_source_audio_upload=..., # 或者上传原始音频 right_extend_length=30, # 在音乐末尾延长 30 秒 # ... 其他参数 api_name="/extend_process_func")- 加载预设配置
/sample_data(/load_data)
这个功能非常有用,可以帮你快速获得一个样本(历史记录)。
result = client.predict( lora_name_or_path_="none", # 选择不使用特殊模型 api_name="/sample_data")
audio_duration, tags, lyrics, infer_step, guidance_scale, ... = result- 重绘音乐片段(
/repaint_process_func)
这个功能可以让你重新生成音乐的某个时间段。
result = client.predict( text2music_json_data=generated_params, # 原始音乐的参数 repaint_json_data=generated_params, # 重绘时使用的参数 retake_variance=0.2, # 重绘变异度 retake_seeds="Hello!!", # 种子值 repaint_start=0, # 重绘开始时间 repaint_end=30, # 重绘结束时间 repaint_source="text2music", # 重绘来源 repaint_source_audio_upload=handle_file('https://github.com/gradio-app/gradio/raw/main/test/test_files/audio_sample.wav'), # 上传原始音频文件 api_name="/repaint_process_func")
repainted_audio_url = result[0] # 重绘后的音乐文件链接repainted_params = result[1] # 重绘时使用的参数3.3 高级控制参数
Section titled “3.3 高级控制参数”参数 | 作用 | 推荐值 |
| 控制节奏变化密度 | 0.3-0.7 |
| 音符粒度精细度 | 8-12 |
| 启用声学细节增强 | True |
| 语音克隆强度(需上传参考音频) | 0.5-0.8 |
| 风格 LoRA 权重(如中文说唱) | 0.7-1.0 |
通过 API 集成,开发者可构建自动化音乐生产线,结合 Retake 的种子控制、Edit 的歌词替换、Extend 的时长扩展等功能,实现全链路音乐创作智能化。