容器化部署 FunASR
此镜像提供了标准化的 API 接口,让您能够便捷地通过 API 调用方式 访问和使用所有功能。
本指南详细阐述了在共绩算力平台上,高效部署与使用 FunASR API 项目的技术方案。FunASR 是一个基本的语音识别工具包,提供多种功能,包括语音识别(ASR)、语音活动检测(VAD)、标点符号恢复、语言模型、说话人验证、说话人分类和多说话者 ASR。
1.在共绩算力上运行 FunASR API
Section titled “1.在共绩算力上运行 FunASR API”共绩算力平台提供预构建的 FunASR API 容器镜像,用户无需本地复杂环境配置,可快速完成部署并启用服务。以下是详细部署步骤:
1.1 创建部署服务
Section titled “1.1 创建部署服务”登录共绩算力控制台,在控制台首页点击“弹性部署服务”进入管理页面。首次使用需确保账户已开通弹性部署服务权限。
1.2 选择 GPU 型号
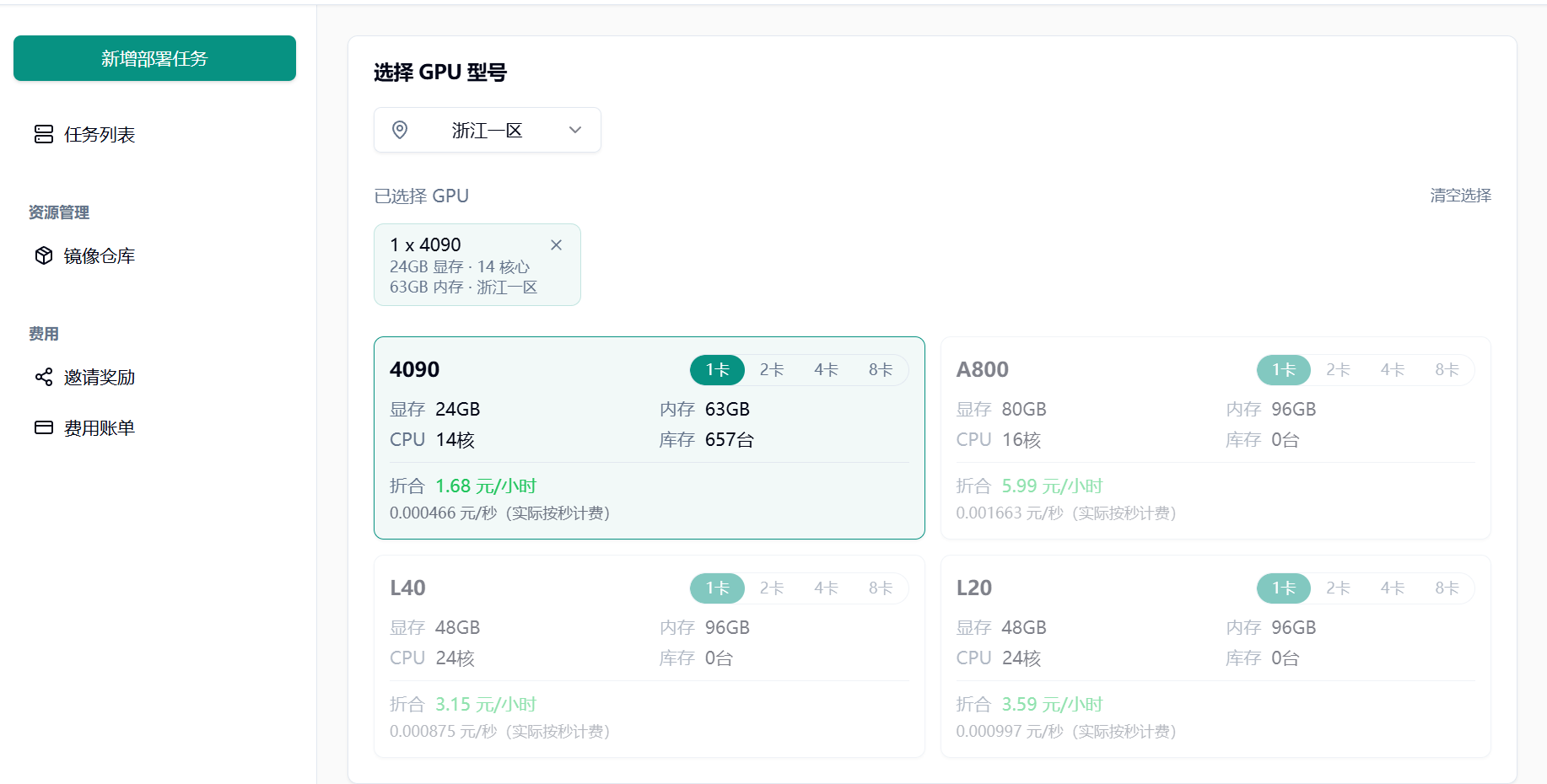
Section titled “1.2 选择 GPU 型号”根据实际需求选择 GPU 型号:
初次使用或调试阶段,推荐配置单张 NVIDIA RTX 4090 GPU
1.3 选择预制镜像
Section titled “1.3 选择预制镜像”在“服务配置”模块切换至“预制服务”选项卡,搜索并选择 FunASR API 官方镜像。
1.4 部署并访问服务
Section titled “1.4 部署并访问服务”点击“部署服务”,平台将自动拉取镜像并启动容器。
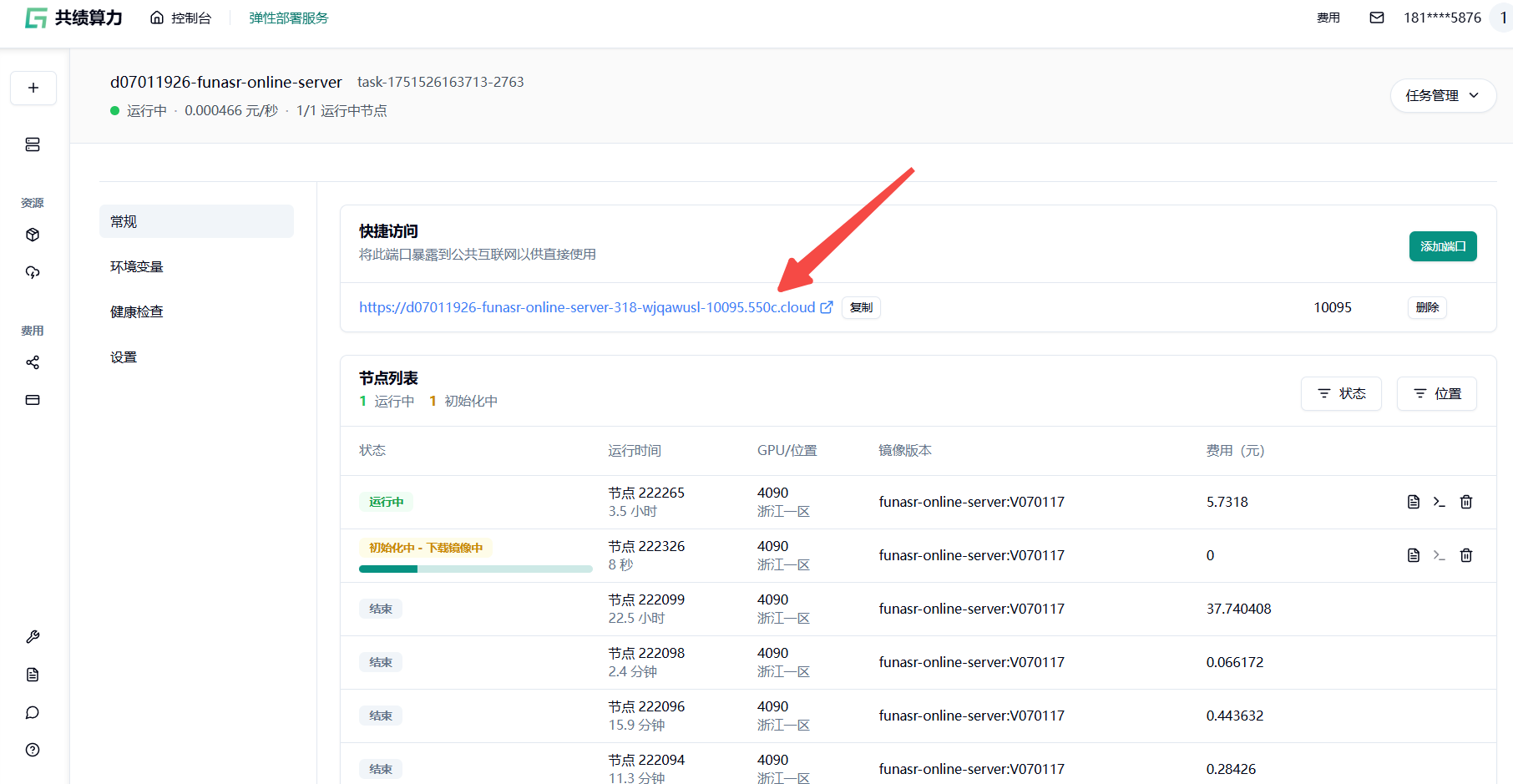
部署完成后,在“快捷访问”中复制端口为 10095 的公网访问链接,后续是通过该地址调用 API 服务。
2. 快速上手
Section titled “2. 快速上手”系统架构图:
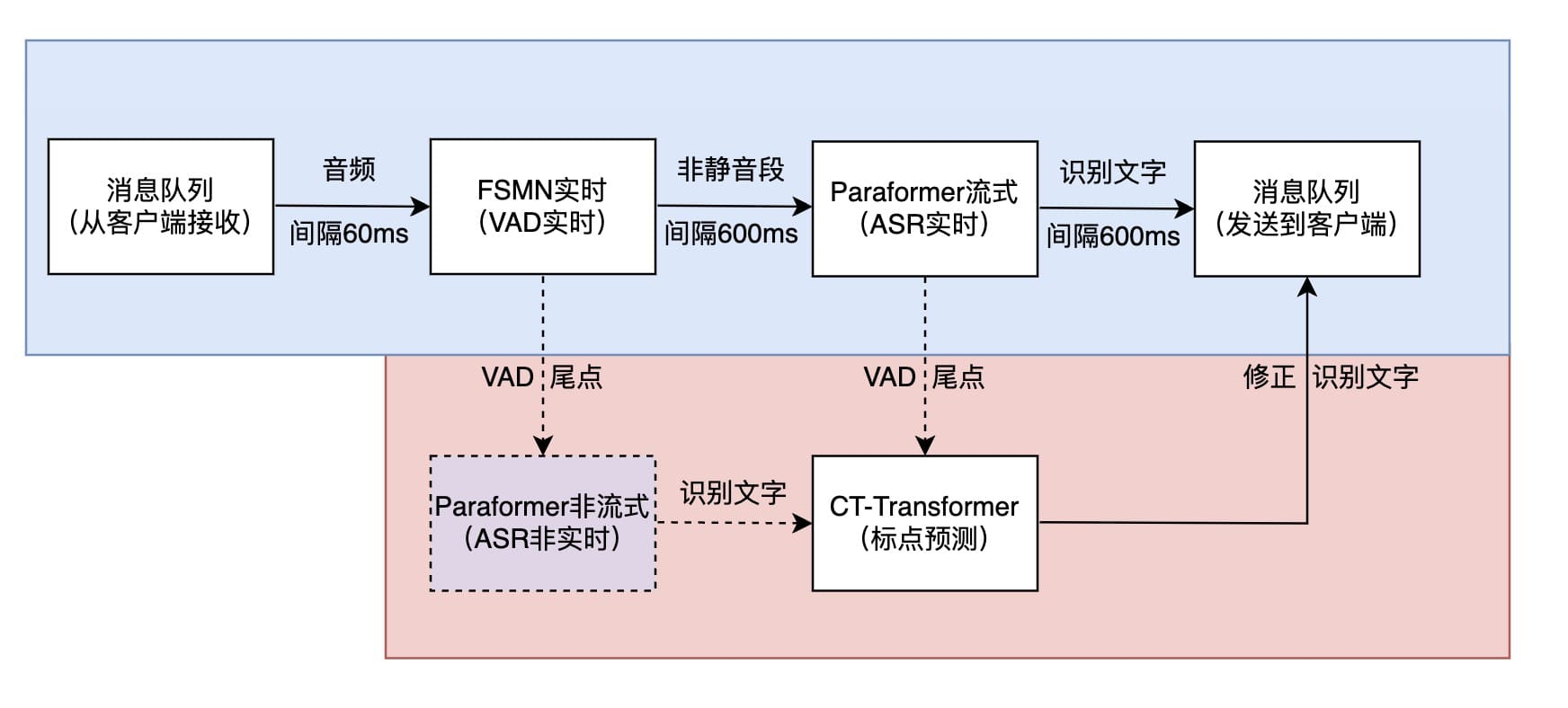
通信协议:
使用 WebSocket 协议进行通信,消息格式:
- 配置参数:
JSON格式 - 音频数据:
bytes格式
2.1 客户端向服务端发送数据
Section titled “2.1 客户端向服务端发送数据”2.1.1 首次通信 - 发送配置参数
Section titled “2.1.1 首次通信 - 发送配置参数”{ "chunk_size": [5, 10, 5], "wav_name": "h5", "is_speaking": true, "wav_format": "pcm", "chunk_interval": 10, "itn": true, "mode": "2pass", "hotwords": "{\"阿里巴巴\":20,\"hello world\":40}"}参数说明:
参数 | 类型 | 说明 |
| string | 音频文件名 |
| string | 音视频文件后缀名,只支持 pcm 音频流 |
| boolean | 断句尾点标识 |
| array | 流式模型延迟配置 |
| number | 块间隔时间 |
| boolean | 是否使用逆文本标准化,默认 true |
| string | 模型模式,支持: |
| string | 热词配置,JSON 字符串格式 |
2.1.2 发送音频数据
Section titled “2.1.2 发送音频数据”直接将音频数据(移除头部信息)以 bytes 格式发送,支持 8000Hz 采样率。
2.1.3 发送结束标志
Section titled “2.1.3 发送结束标志”{ "is_speaking": false}2.2 服务端向客户端发送数据
Section titled “2.2 服务端向客户端发送数据”识别中结果:
{ "is_final": false, "mode": "2pass-online", "text": "阿里", "wav_name": "h5"}识别结束结果:
{ "is_final": false, "mode": "2pass-offline", "stamp_sents": [ { "end": 4385, "punc": "", "start": 820, "text_seg": "阿 里 开 源 的 语 音 识 别 真 是 太 牛 了" } ], "text": "阿里开源的语音识别真是太牛了", "timestamp": "[[820,1060],[1060,1319],[1319,1480],[1480,1760],[1760,2220],[2220,2420],[2420,2659],[2659,2820],[2820,3300],[3300,3480],[3480,3659],[3659,3820],[3820,4060],[4060,4385]]", "wav_name": "h5"}返回参数说明:
参数 | 说明 |
| 推理模式: |
| 音频文件名 |
| 语音识别输出文本 |
| 是否为最终结果 |
| 句子分割信息 |
| 时间戳信息 |
2.3 模型模式说明
Section titled “2.3 模型模式说明”2pass:默认模式,实时语音识别 + 句尾离线模型纠错(准确度更高)
online:实时语音识别
offline:一句话识别
2.4 逆文本标准化(ITN)
Section titled “2.4 逆文本标准化(ITN)”ITN 将标准化文本转换为更自然的书面格式:
"一二三" → "123"
"二零二四年七月二十五日" → "2024年7月25日"
"五千七百六十三" → "5763"
3.Python 调用 API 功能示例
Section titled “3.Python 调用 API 功能示例”基本依赖:
pip install websocketspip install pyaudio # 可选,用于实时录音核心文件:
python test_connection.py # 基础连接测试python quick_demo.py # 最简API演示
python simple_websocket_test.py # 综合功能测试python simple_test.py # 虚拟音频测试
python simple_audio_converter.py # 音频格式转换python funasr_client_no_audio.py # 音频文件识别python recognize_audio.py # 识别示例3.1 基础连接测试
Section titled “3.1 基础连接测试”代码示例:
import asyncioimport websocketsimport jsonimport logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')logger = logging.getLogger(__name__)
async def test_connection():
server_url = "wss://d07011926-funasr-online-server-318-wjqawusl-10095.550c.cloud/"
try: logger.info(f"正在连接到:{server_url}")
async with websockets.connect(server_url) as websocket: logger.info("✅ WebSocket 连接成功!")
# 发送测试配置 test_config = { "chunk_size": [5, 10, 5], "wav_name": "connection_test", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "2pass" }
logger.info("📤 发送测试配置...") await websocket.send(json.dumps(test_config, ensure_ascii=False)) logger.info("✅ 配置发送成功!")
# 发送结束信号 end_signal = {"is_speaking": False} await websocket.send(json.dumps(end_signal)) logger.info("✅ 结束信号发送成功!")
# 尝试接收响应 try: response = await asyncio.wait_for(websocket.recv(), timeout=5.0) logger.info(f"📥 收到服务器响应:{response}") except asyncio.TimeoutError: logger.info("⏰ 未在 5 秒内收到响应(这是正常的,因为没有发送音频数据)")
logger.info("🎉 连接测试完成!")
except Exception as e: logger.error(f"❌ 连接测试失败:{e}")
if __name__ == "__main__": logger.info("🚀 开始 FunASR WebSocket API 连接测试") asyncio.run(test_connection())运行输出:
2025-07-03 11:37:28,981 - INFO - 🚀 开始 FunASR WebSocket API 连接测试2025-07-03 11:37:28,982 - INFO - 正在连接到:wss://d07011926-funasr-online-server-318-wjqawusl-10095.550c.cloud/2025-07-03 11:37:29,436 - INFO - ✅ WebSocket 连接成功!2025-07-03 11:37:29,436 - INFO - 📤 发送测试配置...2025-07-03 11:37:29,437 - INFO - ✅ 配置发送成功!2025-07-03 11:37:29,437 - INFO - ✅ 结束信号发送成功!2025-07-03 11:37:29,516 - INFO - 📥 收到服务器响应:{"is_final":true,"text":"","wav_name":"connection_test"}2025-07-03 11:37:29,516 - INFO - 🎉 连接测试完成!3.2 音频文件识别示例
Section titled “3.2 音频文件识别示例”代码示例:
import asynciofrom funasr_client_no_audio import FunASRClientNoAudio
async def recognize_converted_audio(): """识别转换后的音频文件"""
audio_file = "output_20250625084849_0_converted_8k.wav"
print(f"🎙️ 开始识别音频文件:{audio_file}") print("=" * 60)
client = FunASRClientNoAudio()
try: # 连接服务器 print("📡 正在连接 FunASR 服务器...") if not await client.connect(): return
# 发送配置 - 使用 offline 模式处理长音频 print("📤 发送配置参数...") await client.send_config( mode="offline", # 离线模式更适合长音频 itn=True, # 启用逆文本标准化 hotwords='{"语音识别":20,"人工智能":25,"技术":15}' # 添加热词 )
# 创建结果监听任务 print("👂 开始监听识别结果...") results = []
def collect_results(result): """收集识别结果""" results.append(result) print(f"📨 收到结果:{result.get('text', '')}") if result.get('timestamp'): print(f" 时间戳:{result['timestamp']}")
listen_task = asyncio.create_task(client.listen_for_results(collect_results))
# 发送音频文件 print("📁 开始发送音频文件...") await client.send_audio_file(audio_file)
# 发送结束标志 print("📤 发送识别结束标志...") await client.send_end_flag()
# 等待识别完成 print("⏳ 等待识别完成...") await asyncio.sleep(60)
# 取消监听任务 listen_task.cancel()
# 输出最终结果 print("\n" + "=" * 60) print("🎯 识别结果汇总:") print("=" * 60)
if results: for i, result in enumerate(results[:5], 1): # 显示前 5 个结果 text = result.get('text', '') mode = result.get('mode', 'unknown')
print(f"\n结果 {i}:") print(f" 模式:{mode}") print(f" 文本:{text}")
if result.get('timestamp'): print(f" 时间戳:{result['timestamp']}") else: print("❌ 没有收到识别结果")
except Exception as e: print(f"❌ 识别过程出现错误:{e}")
finally: await client.close() print("\n🔒 连接已关闭")
if __name__ == "__main__": asyncio.run(recognize_converted_audio())运行输出:
🎙️ 开始识别音频文件:output_20250625084849_0_converted_8k.wav============================================================📡 正在连接 FunASR 服务器...✅ 成功连接到 FunASR 服务器📤 发送配置参数...📤 发送配置:{'chunk_size': [5, 10, 5], 'wav_name': 'python_client_no_audio', 'is_speaking': True, 'wav_format': 'pcm', 'chunk_interval': 10, 'itn': True, 'mode': 'offline', 'hotwords': '{"语音识别":20,"人工智能":25,"技术":15}'}👂 开始监听识别结果...📁 开始发送音频文件...📊 音频信息:1 声道,8000Hz, 1665892 帧📨 收到结果:看 aslow 的 night 时间戳:[[5070,5330],[5330,5570],[5570,5710],[5710,5950]]📨 收到结果:你你妈 时间戳:[[8109,8310],[8310,8490],[8490,8650]]📨 收到结果:我来听听他 时间戳:[[9410,9490],[9490,9590],[9590,9670],[9670,9790],[9790,9995]]📤 音频文件发送完成📤 发送识别结束标志...⏳ 等待识别完成...
============================================================🎯 识别结果汇总:============================================================
结果 1: 模式:2pass-offline 文本:看 aslow 的 night 时间戳:[[5070,5330],[5330,5570],[5570,5710],[5710,5950]]
结果 2: 模式:2pass-offline 文本:你你妈 时间戳:[[8109,8310],[8310,8490],[8490,8650]]
结果 3: 模式:2pass-offline 文本:我来听听他 时间戳:[[9410,9490],[9490,9590],[9590,9670],[9670,9790],[9790,9995]]
🔒 连接已关闭3.3 音频格式转换示例
Section titled “3.3 音频格式转换示例”代码示例:
import structimport waveimport math
def convert_ieee_float_to_pcm(input_file, output_file=None, target_rate=8000): """将 IEEE Float WAV 文件转换为 PCM 格式"""
if output_file is None: input_name = input_file.rsplit('.', 1)[0] output_file = f"{input_name}_converted_8k.wav"
try: print(f"📁 读取音频文件:{input_file}")
# 读取 IEEE Float 数据 audio_data, sample_rate, channels = read_ieee_float_wav(input_file)
print("🔄 开始转换...")
# 转换为单声道 if channels > 1: print("🔄 转换为单声道...") mono_data = convert_to_mono(audio_data, channels) else: mono_data = list(audio_data)
# 重采样 if sample_rate != target_rate: print(f"🔄 重采样:{sample_rate} Hz -> {target_rate} Hz") resampled_data = simple_resample(mono_data, sample_rate, target_rate) else: resampled_data = mono_data
# 标准化音频 print("🔄 标准化音频...") normalized_data = normalize_audio(resampled_data, 0.95)
# 转换为 16 位 PCM print("🔄 转换为 16 位 PCM...") pcm_data = [] for sample in normalized_data: pcm_value = int(max(-32768, min(32767, sample * 32767))) pcm_data.append(pcm_value)
# 保存为 WAV 文件 print(f"💾 保存转换后的音频:{output_file}") with wave.open(output_file, 'wb') as wf: wf.setnchannels(1) # 单声道 wf.setsampwidth(2) # 16 位 = 2 字节 wf.setframerate(target_rate)
# 将 PCM 数据转换为 bytes pcm_bytes = b''.join(struct.pack('<h', sample) for sample in pcm_data) wf.writeframes(pcm_bytes)
print("✅ 音频转换完成!") print(f"📊 转换后信息:") print(f" 采样率:{target_rate} Hz") print(f" 声道数:1 (单声道)") print(f" 位深:16 bit") print(f" 时长:{len(pcm_data) / target_rate:.2f} 秒") print(f" 文件大小:{len(pcm_data) * 2 / 1024 / 1024:.2f} MB")
return output_file
except Exception as e: print(f"❌ 音频转换失败:{e}") return None
if __name__ == "__main__": convert_ieee_float_to_pcm("input.wav", "output.wav", 8000)运行输出:
$ python simple_audio_converter.py output_20250625084849_0.wav test_converted.wav📁 读取音频文件: output_20250625084849_0.wav📊 原始音频信息: 采样率: 48000 Hz 声道数: 2 位深: 32 bit 格式: IEEE Float (3) 数据大小: 79962840 bytes 时长: 208.24 秒 样本数: 19990710🔄 开始转换...🔄 转换为单声道...🔄 重采样: 48000 Hz -> 8000 Hz🔄 标准化音频...🔄 转换为16位PCM...💾 保存转换后的音频: test_converted.wav✅ 音频转换完成!📊 转换后信息: 采样率: 8000 Hz 声道数: 1 (单声道) 位深: 16 bit 时长: 208.24 秒 文件大小: 3.18 MB🔍 验证音频文件: test_converted.wav 声道数: 1 采样率: 8000 Hz 采样位深: 16 bit 总帧数: 1665892 时长: 208.24 秒 压缩类型: NONE✅ 音频格式完全符合FunASR要求!3.4 热词功能测试示例
Section titled “3.4 热词功能测试示例”代码示例:
import asyncioimport websocketsimport json
async def test_hotwords():
"""测试热词功能""" uri = "wss://d07011926-funasr-online-server-318-wjqawusl-10095.550c.cloud/"
# 定义热词 hotwords = { "阿里巴巴": 25, "人工智能": 30, "语音识别": 28, "机器学习": 22 }
print("🔥 测试热词功能") print("🎯 设置的热词及权重:") for word, weight in hotwords.items(): print(f" {word}: {weight}")
try: async with websockets.connect(uri) as websocket: print("✅ 连接成功!")
# 发送带热词的配置 config = { "chunk_size": [5, 10, 5], "wav_name": "hotwords_test", "is_speaking": True, "wav_format": "pcm", "chunk_interval": 10, "itn": True, "mode": "2pass", "hotwords": json.dumps(hotwords, ensure_ascii=False) }
await websocket.send(json.dumps(config, ensure_ascii=False)) print("✅ 热词配置发送成功!")
# 发送结束信号 await websocket.send(json.dumps({"is_speaking": False}))
# 接收响应 response = await websocket.recv() result = json.loads(response) print(f"📥 收到响应:{result}")
except Exception as e: print(f"❌ 热词测试失败:{e}")
asyncio.run(test_hotwords())运行输出:
🔥 测试热词功能🎯 设置的热词及权重: 阿里巴巴:25 人工智能:30 语音识别:28 机器学习:22✅ 连接成功!✅ 热词配置发送成功!📥 收到响应:{'is_final': True, 'text': '', 'wav_name': 'hotwords_test'}4. API 调用配置说明
Section titled “4. API 调用配置说明”基础配置参数:
{ "chunk_size": [5, 10, 5], // 延迟配置:[3,6,3] 低延迟 [8,15,8] 高精度 "wav_name": "test", // 音频标识 "is_speaking": true, // 说话状态 "wav_format": "pcm", // 音频格式 "chunk_interval": 10, // 块间隔 "itn": true, // 逆文本标准化 "mode": "2pass", // 识别模式 "hotwords": "{}" // 热词配置}识别模式选择:
online: 实时模式,低延迟,适合对话offline: 离线模式,高精度,适合文件转写2pass: 双通道模式,平衡延迟和精度
热词配置示例:
{ "阿里巴巴": 25, "人工智能": 30, "语音识别": 28, "机器学习": 22}音频格式转换:如果音频不符合要求(8000Hz、单声道、16 位 PCM),使用转换器:
python simple_audio_converter.py input.wav output.wav 8000