容器化部署 PDFMathTranslate
本指南详细阐述了在共绩算力平台上,高效部署与使用 PDFMathTranslate 项目的技术方案,旨在解决学术文献、技术手册等包含复杂数学公式的 PDF 翻译难题。

1. 部署指南:在共绩算力上运行 PDFMathTranslate
Section titled “1. 部署指南:在共绩算力上运行 PDFMathTranslate”共绩算力平台提供了预构建的 PDFMathTranslate 容器镜像,用户无需在本地进行复杂的环境配置,即可快速部署并使用服务。
1.1 创建部署服务
Section titled “1.1 创建部署服务”登录 共绩算力控制台,在”控制台”页面中,点击”弹性部署服务”。
1.2 配置计算资源
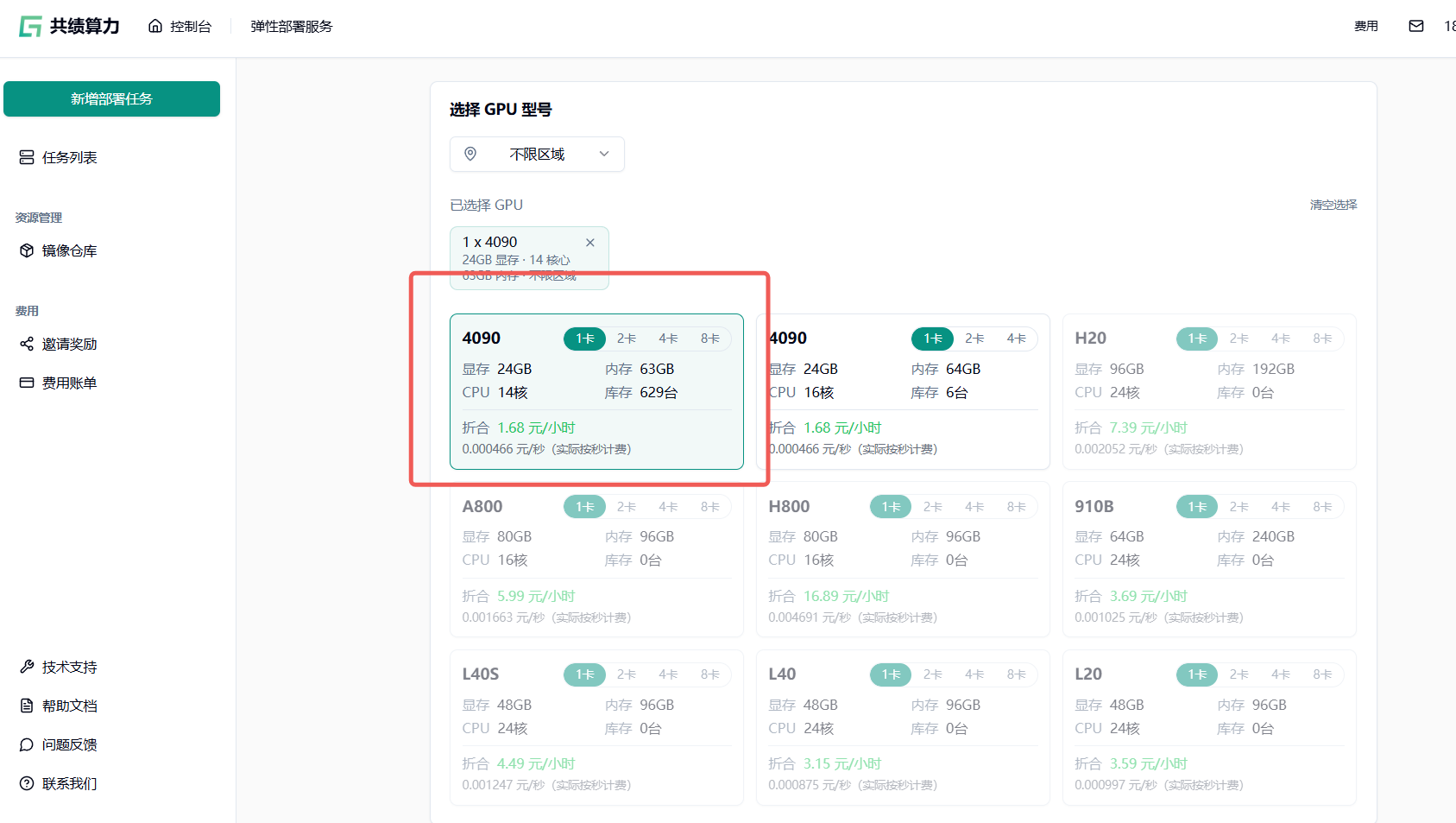
Section titled “1.2 配置计算资源”根据您的翻译需求选择合适的计算资源。对于初次使用或处理中小型文档,推荐配置单张 NVIDIA RTX 4090 GPU 进行调试。
1.3 选择预制镜像
Section titled “1.3 选择预制镜像”在”服务配置”部分,选择”预制镜像”选项卡。从列表中找到并选择 PDFMathTranslate 镜像。该镜像已集成所有必要的依赖项。
1.4 部署并访问服务
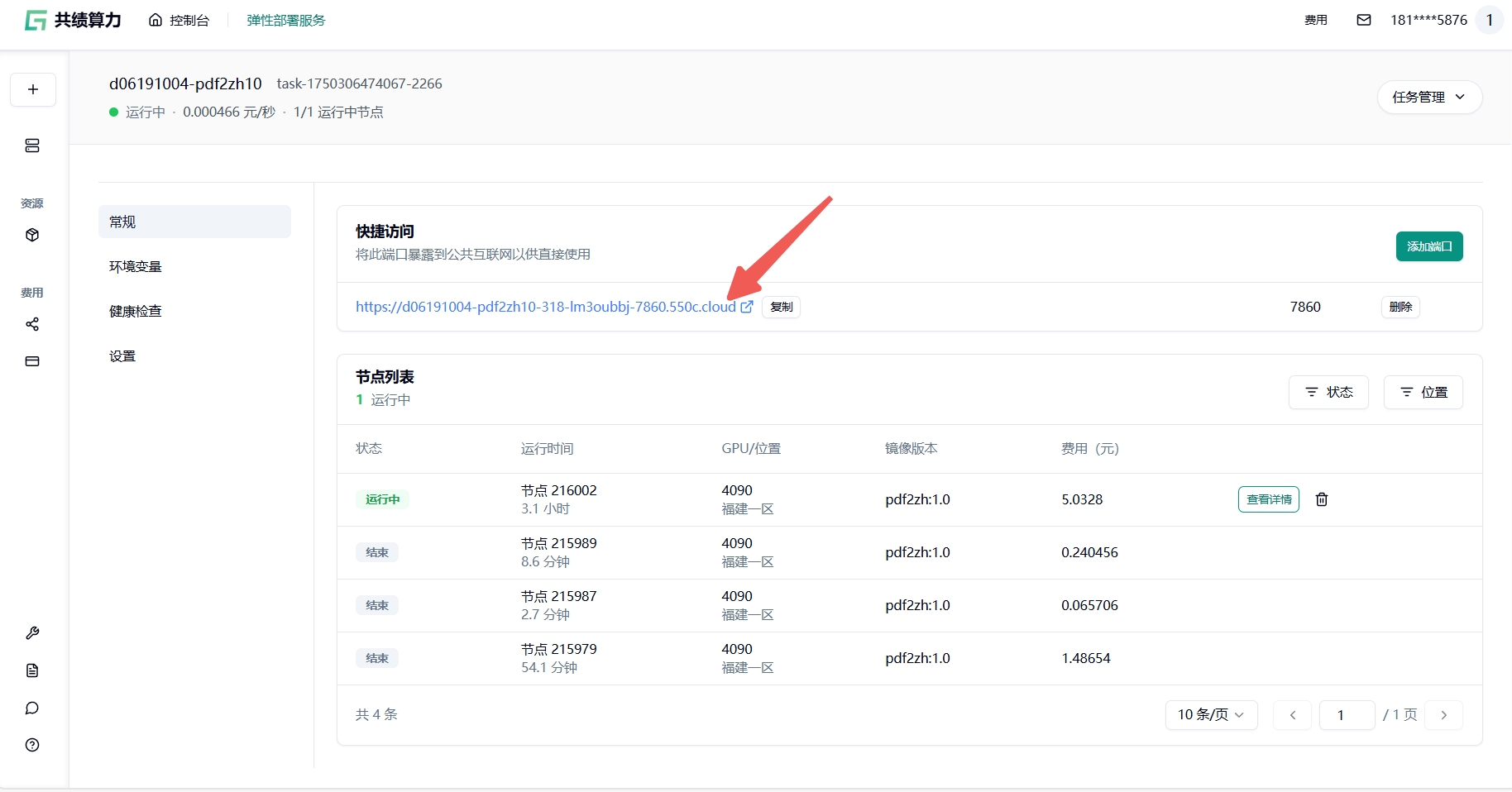
Section titled “1.4 部署并访问服务”点击”部署服务”并等待平台完成镜像拉取与容器启动。启动后,在部署详情的”公开访问”部分,找到端口为 7860 的公网访问链接。点击该链接即可在浏览器中使用 PDFMathTranslate 的 Web 界面。
2.快速上手
Section titled “2.快速上手”2.1 上传文件
Section titled “2.1 上传文件”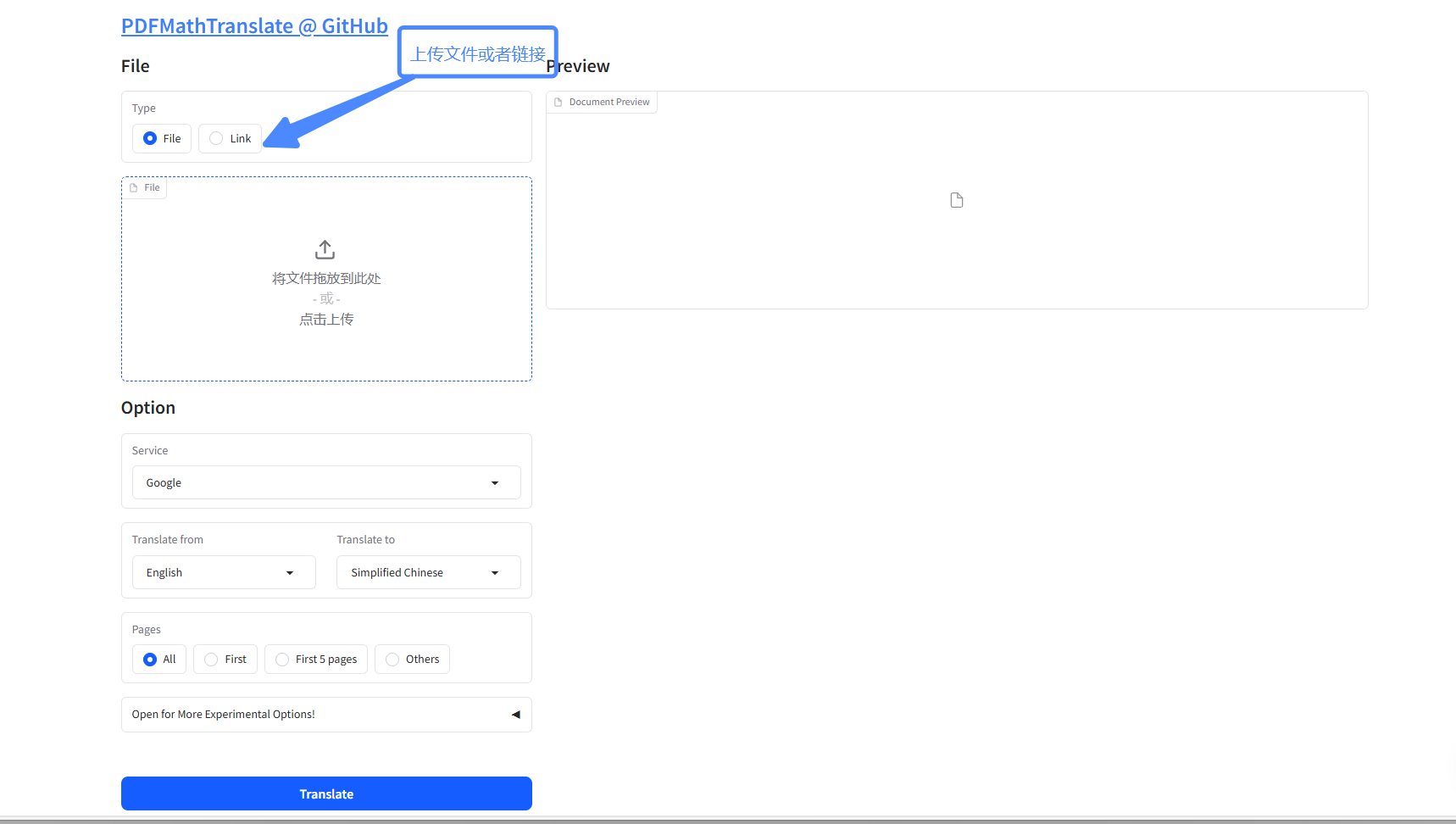
2.2 选项设置
Section titled “2.2 选项设置”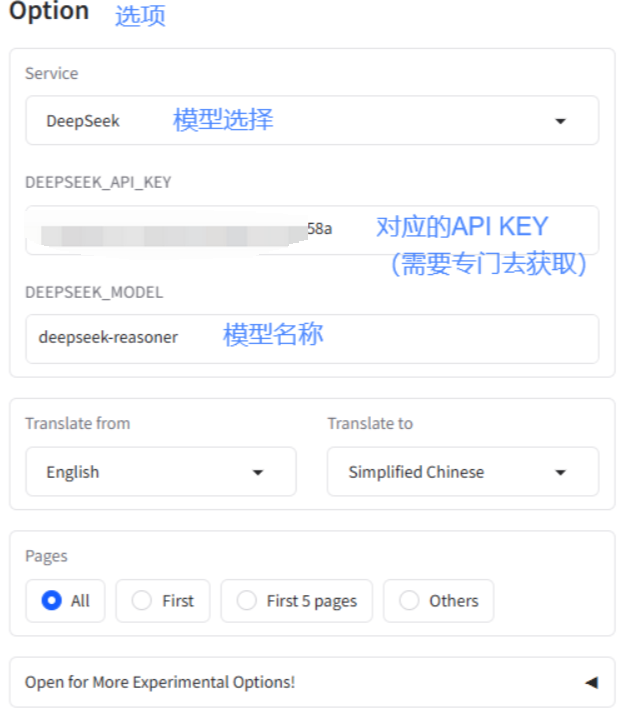
2.2.1 各 AI 服务 Token/API Key 获取地址
Section titled “2.2.1 各 AI 服务 Token/API Key 获取地址”- Google / Gemini (谷歌): Google AI Studio :
https://ai.google.dev/Google Cloud Platform:https://console.cloud.google.com/ - OpenAI :
https://platform.openai.com/api-keys - Zhipu (智谱 AI) :
https://open.bigmodel.cn/ - Ali Qwen (阿里通义千问) : 阿里云平台 (通义千问控制台) :
https://dashscope.console.aliyun.com/ - DeepSeek (深度求索) :
https://platform.deepseek.com/ - Azure OpenAI (微软) : Azure Portal (需要 Azure 订阅) :
https://portal.azure.com/ - Tencent (腾讯混元/大模型): 腾讯云 API 密钥管理 :
https://console.cloud.tencent.com/cam/capi - Groq (提供高速推理 API) :
https://console.groq.com/ - Grok (xAI) :
https://x.ai/
2.3 更多设置
Section titled “2.3 更多设置”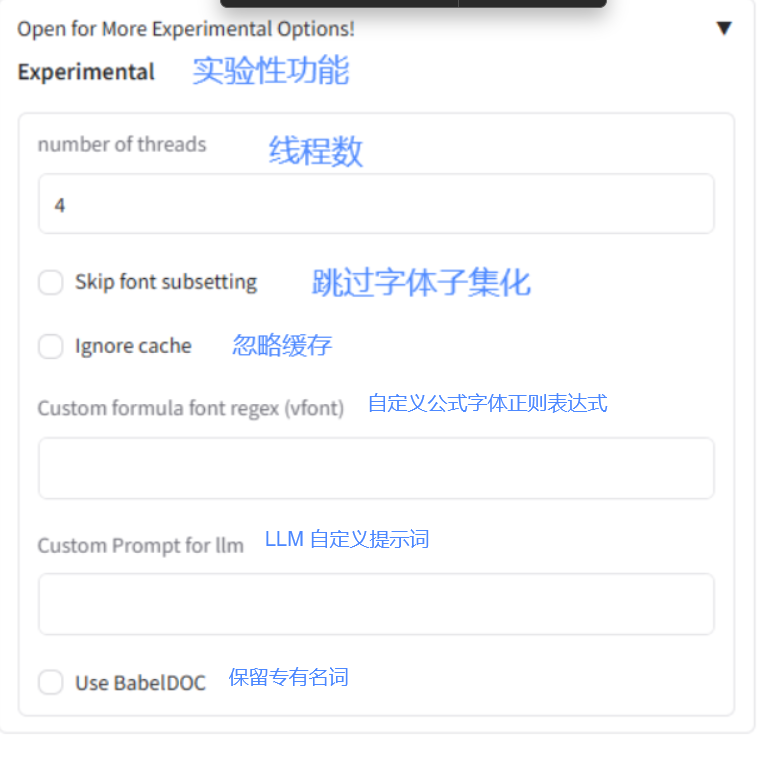
2.4 开始转换
Section titled “2.4 开始转换”设置完上面的所有设置后点击Translate 开始转换 PDF 文件/链接 到指定语言
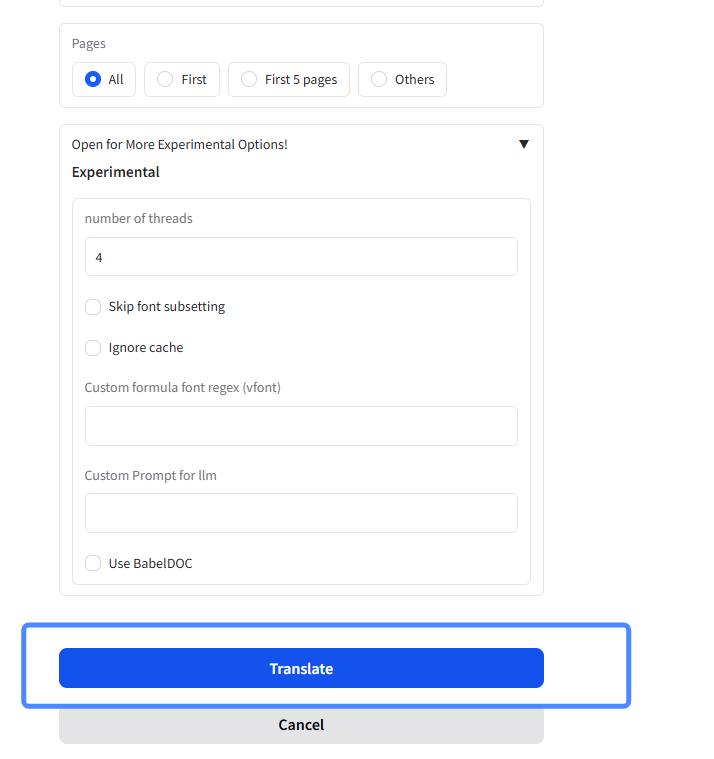
翻译完成后,这里会出现两个 PDF,一个是中文版,一个是双语版:
来看一下效果:


3.进阶使用
Section titled “3.进阶使用”使用 FastGPT 工作流(或者 dify 等)通过提示词让 AI 进行多轮反思翻译。
整个工作流非常简单,只需要一个 AI 对话节点和一个代码运行节点,最后再加一个指定回复节点。
FastGPT 地址:https://t.co/lLQFVzCZGR
工作流参考:
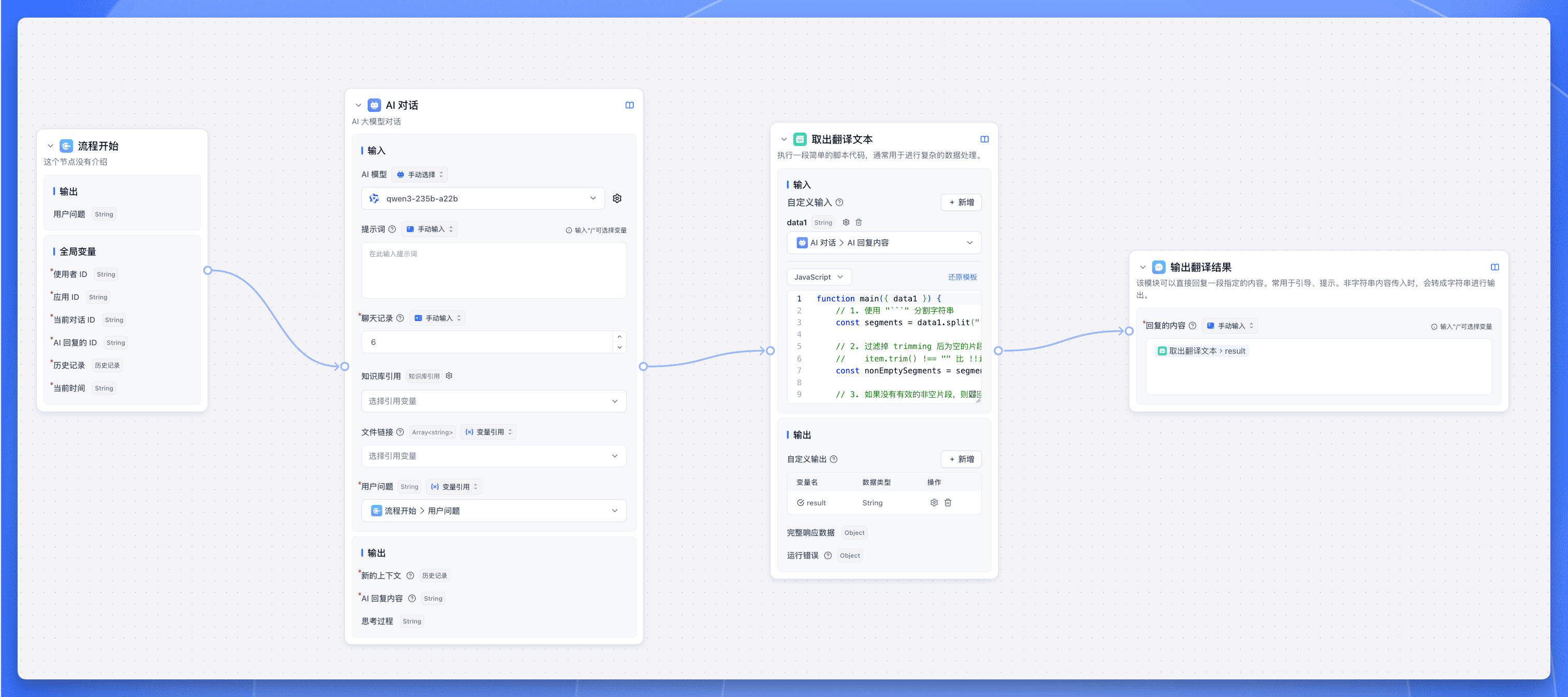
代码运行是这个工作流的核心秘密,参考代码如下:
/** * 从包含多个 "'''" 分隔块的字符串中,提取最后一个有效代码块的内容。 * @param {{data1: string}} param - 输入对象,包含待处理的字符串 data1。 * @returns {{result: string}} 包含提取结果或提示信息的对象。 */function main({ data1 }) { // 1. 输入校验:确保 data1 是一个有效的、非空白的字符串。 if (typeof data1 !== 'string' || !data1.trim()) { return { result: '未截取到翻译内容' }; }
// 2. 查找最后一个有效片段: // - 使用 "'''" 分割字符串。 // - .reverse() 反转数组,再用 .find() 从后向前查找第一个非空白片段。 // - 这种方法比先过滤再取最后一位更高效,因为它找到后就会停止。 const lastSegment = data1.split("'''").reverse().find(segment => segment.trim() !== '');
// 3. 如果未找到有效片段,直接返回。 if (!lastSegment) { return { result: '未截取到翻译内容' }; }
// 4. 清理内容并返回结果: // - .replace() 使用正则表达式移除可选的语言标识符行(例如 "javascript\n")。 // - .trim() 移除最终内容两端的空白字符。 // - 使用逻辑或 "||" 操作符,如果清理后 finalResult 为空字符串,则返回提示信息。 const finalResult = lastSegment.replace(/^\s*[a-zA-Z0-9_-]+\s*\n/, '').trim();
return { result: finalResult || '未截取到翻译内容' };}这段代码只做一件事情:将多轮翻译最终轮的翻译结果提取出来。
工作流搭建完成后,依次点击【发布渠道】—>【API 访问】—>【新建】来创建一个 API 密钥。
然后将 API 地址和 API 密钥填入 PDFMathTranslate 的 Web UI 中。
这里的模型名称可以随便写,写什么都行,毕竟最终调用的还是你的 FastGPT 工作流。

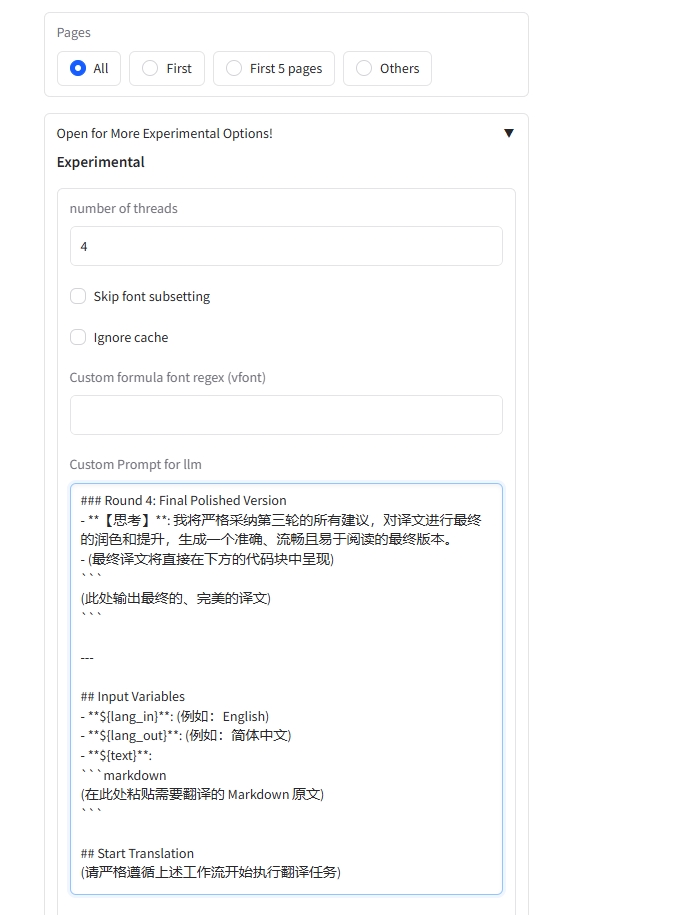
然后在自定义 prompt 中输入以下提示词:
<b># Role: 资深翻译专家</b>
<b>## Profile</b>- <b>**身份**</b>: 你是一位经验丰富的翻译专家,精通 ${lang_in} 和 ${lang_out} 的双向翻译。- <b>**特长**</b>: 尤其擅长将复杂的 ${lang_in} 技术和文学文章,翻译成流畅、地道、易于理解的 ${lang_out}。- <b>**经验**</b>: 你拥有带领大型翻译项目的成功经验,产出的译文质量广受好评。
---
<b>## Guiding Principles & Rules</b>在整个翻译过程中,你必须严格遵守以下原则:
<b>### 核心要求</b>1. <b>**信、达、雅**</b>: 始终坚持此翻译最高标准,其中 <b>**"达" (Expressiveness)**</b> 和 <b>**"信" (Faithfulness)**</b> 是最重要的。译文必须准确传达原文的事实、背景和意图。2. <b>**流畅地道**</b>: 译文必须完全符合 ${lang_out} 的语言习惯,通俗易懂,连贯流畅。避免生硬的直译和不自然的语序。3. <b>**风格对等**</b>: 适度使用一些 ${lang_out} 的熟语、俗语或网络用语,增强译文的亲和力,但要避免使用过于晦涩的典故。
<b>### 格式与内容保留</b>1. <b>**Markdown 格式**</b>: 严格保持输入文本原有的 Markdown 格式,包括标题、列表、粗体、斜体等。2. <b>**段落与换行**</b>: 保留原始的段落结构。诗歌、歌词等特殊文本需保持原文的换行和节奏。3. <b>**代码块**</b>: <b>**不翻译**</b> 任何代码块 (` ```...``` `) 中的内容,保持原样输出。4. <b>**专有内容**</b>: - <b>**数学公式**</b>: 保持 `{v*}` 这样的公式符号不变。 - <b>**术语/缩写**</b>: 保留如 `FLAC`, `JPEG`, `Microsoft` 等技术术语和专有名称。 - <b>**论文引用**</b>: 保留如 `[20]` 这样的引用标记。 - <b>**图表标题**</b>: 按照原文格式翻译,例如 `Figure 1:` 翻译为 `图 1:`,`Table 1:` 翻译为 `表 1:`。5. <b>**链接**</b>: 保留文章中所有的图片链接 (``) 和超链接 (`[text](url)`)。6. <b>**标点符号**</b>: 将所有全角括号 `()` 替换为半角括号 `()`,并在左括号前、右括号后各加一个半角空格。
---
<b>## Terminology Glossary</b>- 在翻译时,必须严格参考以下术语表。如果术语表为空,请基于你的专业知识进行翻译。- `${term_1_in}`: `${term_1_out}`- `${term_2_in}`: `${term_2_out}`
---
<b>## Workflow: Four-Round Translation Process</b>你必须严格遵循以下的四轮翻译流程,并按照指定的格式输出每一步的结果。
<b>### Round 1: Literal Translation</b>- <b>**【思考】**</b>: 我将逐字逐句地翻译原文,确保所有信息点(代码块除外)都被忠实地转换为 ${lang_out},这是后续优化的基础。- <b>**【翻译】**</b>:> (此处输出第一轮的直译文)
<b>### Round 2: Idiomatic Rewrite</b>- <b>**【思考】**</b>: 我将摆脱直译的束缚,在保持原意和格式不变的前提下,用更自然、地道的 ${lang_out} 语言重写译文,使其更符合 ${lang_out} 读者的阅读习惯。对于短标题等内容,我将保持简洁,不进行不必要的扩展。- <b>**【翻译】**</b>:> (此处输出第二轮的重写译文)
<b>### Round 3: Reflection and Suggestions</b>- <b>**【思考】**</b>: 我将从六个维度审视第二轮的译文,提出一份详细的、有建设性的改进建议清单,以确保最终译文的质量。- <b>**【建议】**</b>:> * <b>**</b>*准确性*<b>**</b>: (针对冗余、误译、漏译的修正建议)> * <b>**</b>*流畅性*<b>**</b>: (针对语法、拼写、标点和重复的改进建议)> * <b>**</b>*风格*<b>**</b>: (确保译文风格与原文一致,并符合文化背景的建议)> * <b>**</b>*术语*<b>**</b>: (对照术语表,检查术语使用一致性的建议)> * <b>**</b>*语序*<b>**</b>: (调整为更符合 ${lang_out} 习惯的语序的建议)> * <b>**</b>*代码保护*<b>**</b>: (检查代码块是否保持原样的确认)
<b>### Round 4: Final Polished Version</b>- <b>**【思考】**</b>: 我将严格采纳第三轮的所有建议,对译文进行最终的润色和提升,生成一个准确、流畅且易于阅读的最终版本。- (最终译文将直接在下方的代码块中呈现)(此处输出最终的、完美的译文)
---
<b>## Input Variables</b>- <b>**${lang_in}**</b>: (例如:English)- <b>**${lang_out}**</b>: (例如:简体中文)- <b>**${text}**</b>:```markdown(在此处粘贴需要翻译的 Markdown 原文)## Start Translation (请严格遵循上述工作流开始执行翻译任务)
最终优化后的翻译效果如下:
<img src="/assets/EBy7b9dKjoJCl8xtSYTcclPAneh.png" src-width="1220" src-height="1640" align="center"/>
<img src="/assets/Y5DAbL3EroNjDXxGuQ1cVybLnEb.png" src-width="3530" src-height="1946" align="center"/>