容器化部署 PaddleOCR-VL-0.9B
此镜像提供了标准化的 API 接口,让您能够便捷地通过 API 调用方式 访问和使用所有功能。
本指南详细阐述了在共绩算力平台上,高效部署与使用 PaddleOCR-VL 项目的技术方案。
PaddleOCR-VL-0.9B 是百度 PaddleOCR-VL-0.9B 团队于 2025 年 10 月发布的超轻量级视觉 - 语言模型,专门针对文档解析场景优化。它是 ERNIE-4.5 系列中最强大的衍生模型之一。
1. 在共绩算力上运行 PaddleOCR-VL-0.9B
Section titled “1. 在共绩算力上运行 PaddleOCR-VL-0.9B”共绩算力平台提供预构建的 PaddleOCR-VL-0.9B 容器镜像,用户无需本地复杂环境配置,可快速完成部署并启用服务。以下是详细部署步骤:
1.1 创建部署服务
Section titled “1.1 创建部署服务”登录共绩算力控制台,在控制台首页点击”弹性部署服务”进入管理页面。首次使用需确保账户已开通弹性部署服务权限。
1.2 选择 GPU 型号
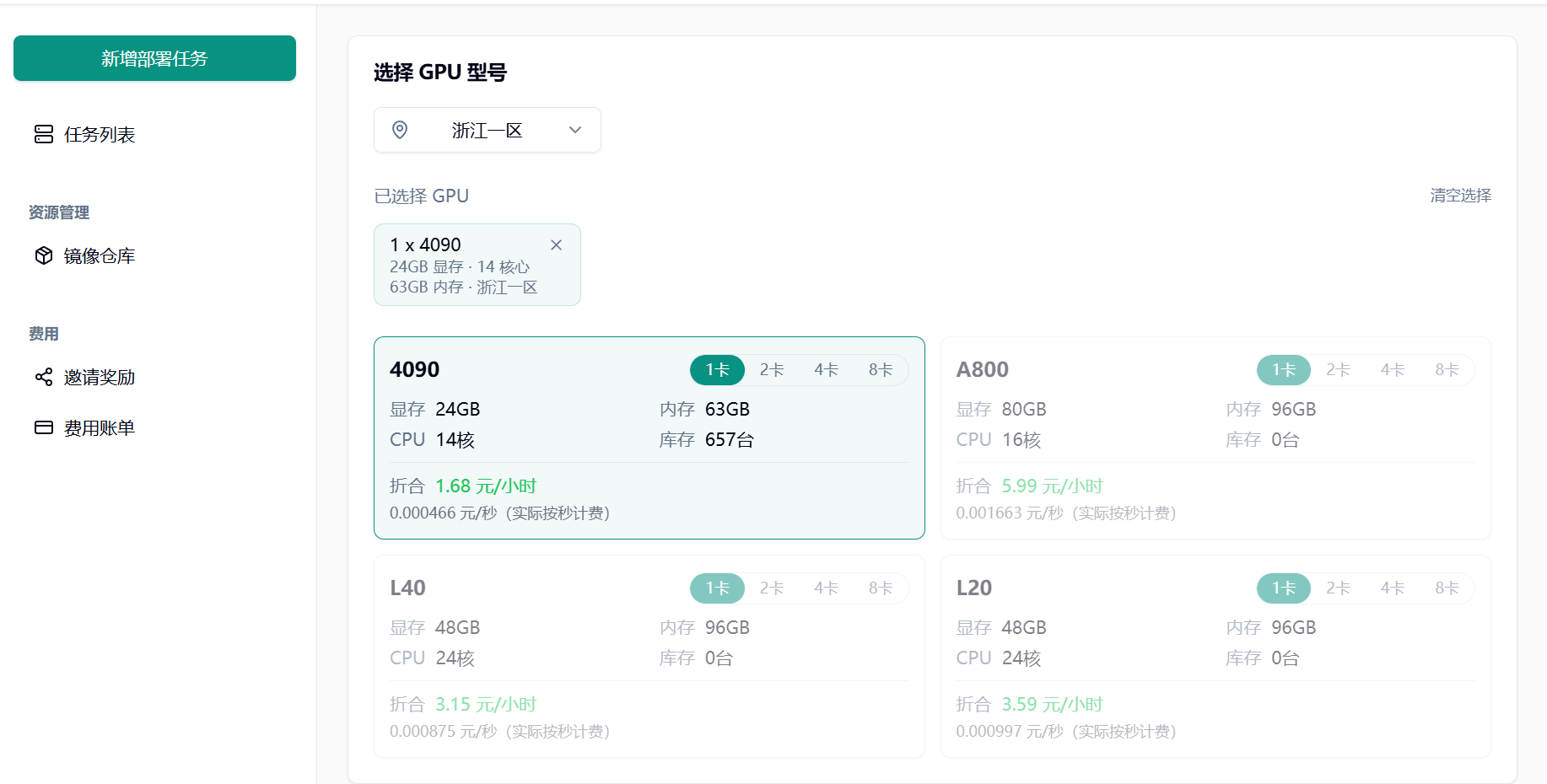
Section titled “1.2 选择 GPU 型号”根据实际需求选择 GPU 型号:
初次使用或调试阶段,推荐配置单张 NVIDIA RTX 4090 GPU
1.3 选择预制镜像
Section titled “1.3 选择预制镜像”在”服务配置”模块切换至”预制服务”选项卡,选择 PaddleOCR-VL-0.9B 官方镜像。
1.4 部署并访问服务
Section titled “1.4 部署并访问服务”点击”部署服务”,平台将自动拉取镜像并启动容器。
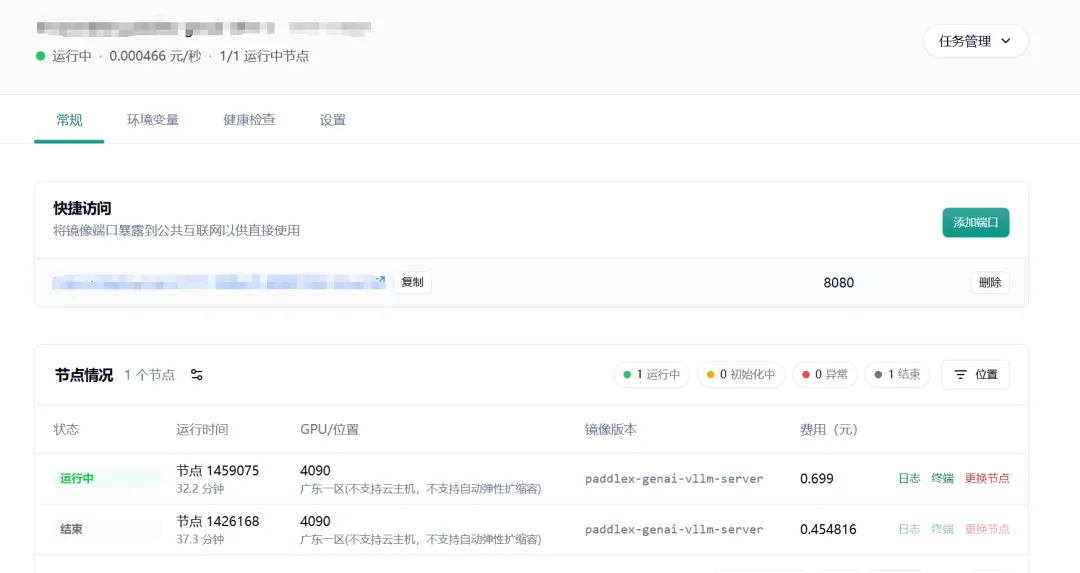
从快捷访问那里把服务端的 URL 复制出来。
2.本地客户端代码
Section titled “2.本地客户端代码”目前这个方案有点麻烦,还是要装一个 paddle 的包,不过CPU 即可运行,享受云端充足算力。
pip install paddlepaddlepip install "paddleocr[doc-parser]"参考下面的代码,替换 url 和图片的路径。
URL 后面不需要再拼上:8080 接口,复制过来的只在后面加/v1 就行
from paddleocr import PaddleOCRVLimport time
pipeline = PaddleOCRVL(vl_rec_backend="vllm-server", vl_rec_server_url="https://deployment-1717-t68kcrlt-8080.550c.cloud/v1")
start_time = time.time()output = pipeline.predict("./table_test/pdf.png")end_time = time.time()print(f"预测耗时:{end_time - start_time:.2f} 秒")
for res in output: res.print() res.save_to_json(save_path="output") res.save_to_markdown(save_path="output")运行上面的代码,paddle 第一次先要去下载一个 layout 模型,之后会缓存在本地。这个模型可以用 CPU 跑。

然后在共绩算力的后台可以看到请求的日志。
最后再 output 目录下就可以看到 OCR 的结果了。
有了 GPU 速度还是快很多的。昨天在 modelscope 的 gradio demo,用 CPU 跑一张测试图片大概要30 秒,今天同样的图片用了一半 GPU(layout 模型用 CPU,OCR 模型用 GPU)只要10 秒。
3.可能遇到的坑
Section titled “3.可能遇到的坑”如果遇到这样的报错
File "D:\code\susu\table_ocr\pdclient\Lib\site-packages\paddleocr\_common_args.py", line 61, in prepare_common_init_args device = get_default_device() ^^^^^^^^^^^^^^^^^^^^ File "D:\code\susu\table_ocr\pdclient\Lib\site-packages\paddlex\utils\device.py", line 44, in get_default_device if paddle.device.is_compiled_with_cuda() and paddle.device.cuda.device_count() > 0: ^^^^^^^^^^^^^AttributeError: module 'paddle' has no attribute 'device'可以改源码跳过这一段直接返回 cpu。