容器化部署通用推理镜像 vLLM 篇
该方式部署模型可能需要一定经验。如无特殊需求,建议使用其他预制镜像
目前平台提供三种通用镜像:vLLM, SGLang ,Ollama。三种镜像均提供 OpenAI 兼容接口。可供多种客户端调用。目前模型默认通过 modelscope 在运行时下载 (ollama 需要指定 modelscope.cn/组织/仓库下载)。
关于镜像选择的简单建议:hor
高并发 -> vLLM (稳定), SGLang (前沿)
GGUF 模型 -> Ollama
目前 vllm 镜像已经上线预制服务,只需要在 https://console.suanli.cn/serverless/create 选择镜像
【vllm】后点击部署。
修改模型,只需在部署后修改启动命令。详细可见下文启动命令。
确认模型 id -> 配置部署服务 -> 配置启动参数 -> 启动服务 -> 等待服务初始化 -> 开始使用
确认模型 id
Section titled “确认模型 id”要部署模型,我们首先要知道,我们要部署的是那个模型,比如 Qwen3-8B-FP8
https://modelscope.cn/models/Qwen/Qwen3-8B-FP8
该模型 id 为 Qwen/Qwen3-8B-FP8 (平台默认从 modelscope 下载模型) 记录下这个 id
配置部署服务
Section titled “配置部署服务”进入 https://console.suanli.cn/serverless/create
选择显卡,这里推荐 4090。
下拉到服务配置->选择自定义服务->镜像配置 harbor.suanleme.cn/laiaqwq/vllm-openai:2025-10-13 ->
端口 8000
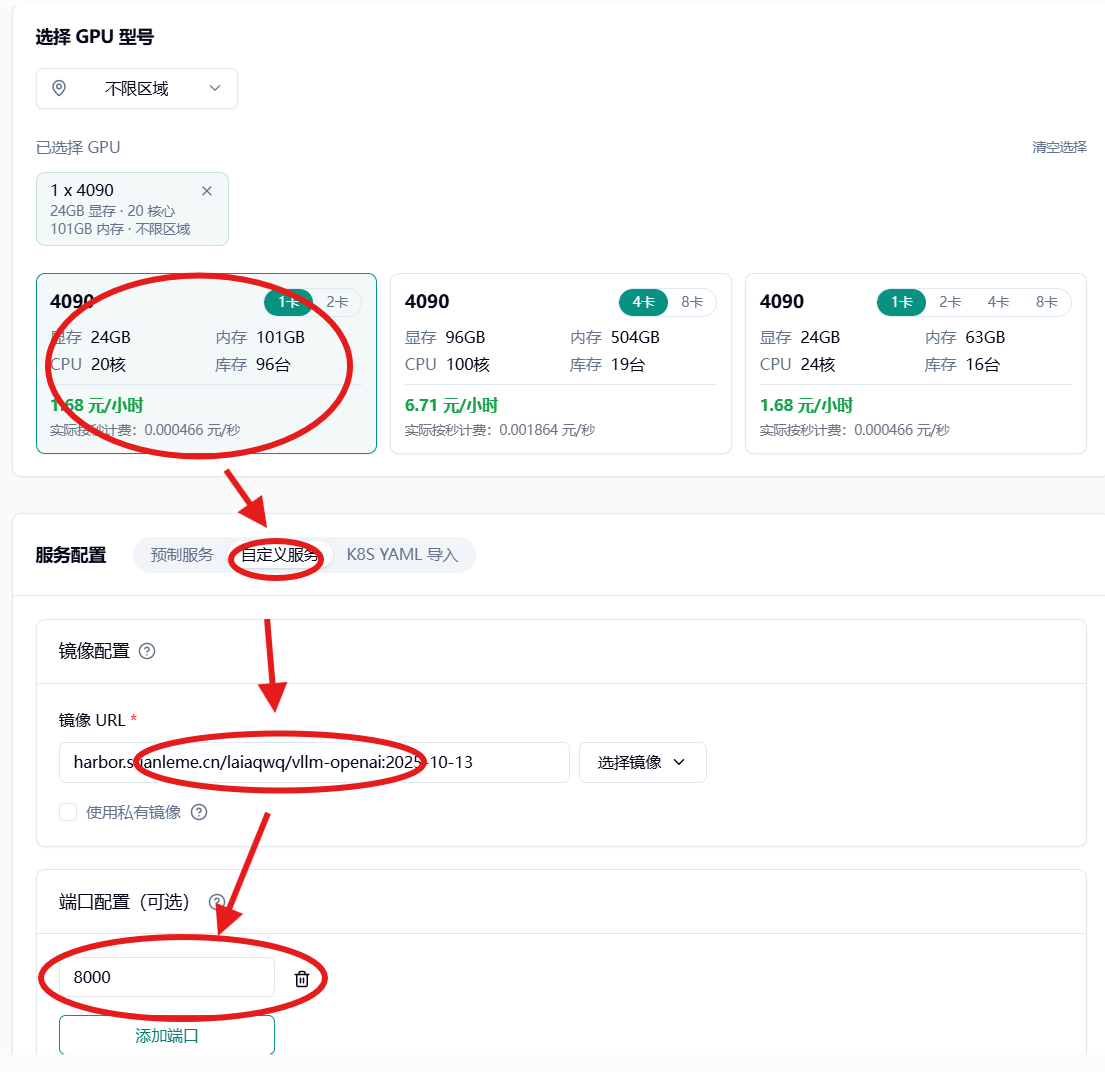
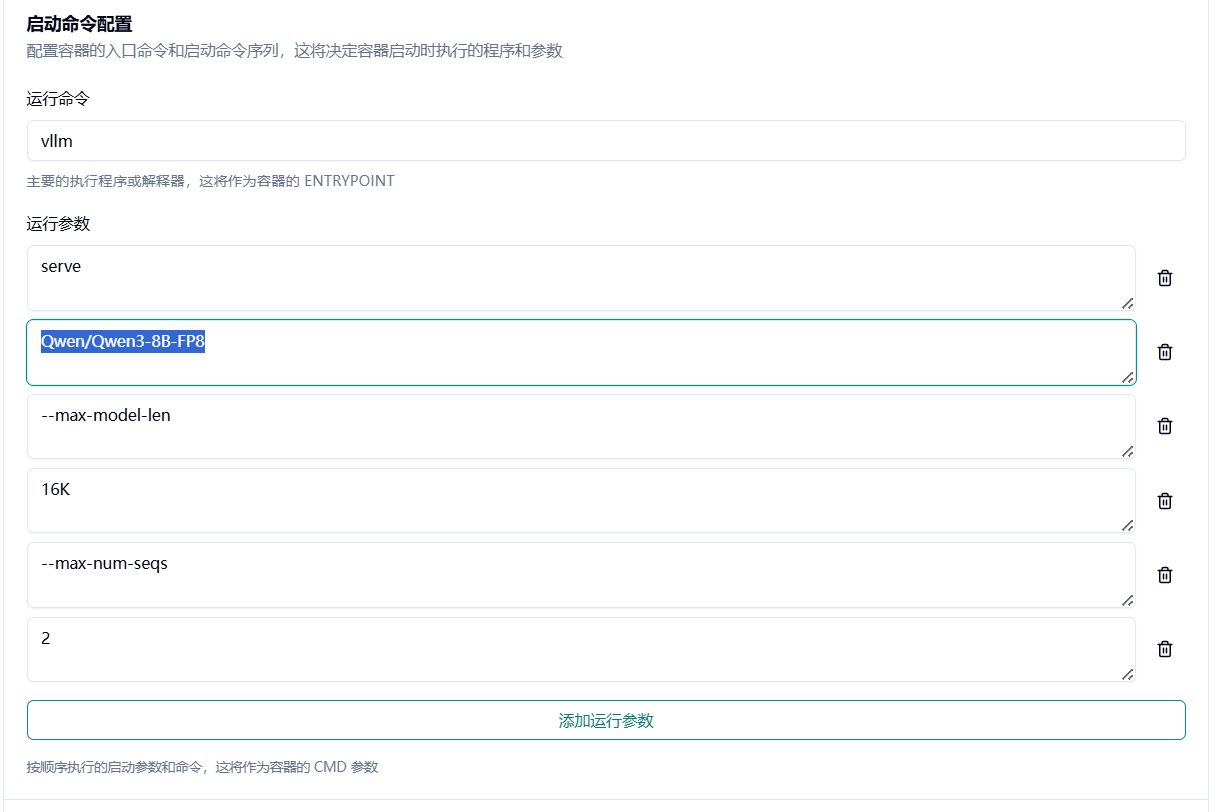
添加启动命令 运行命令
vllm运行参数
serveQwen/Qwen3-8B-FP8 #上面记录的模型 id--max-model-len16K #最大输入上下文--max-num-seqs2 #最大输入序列更多参数可参照 https://docs.vllm.ai/en/latest/configuration/engine_args.html#modelconfig
在多卡并行场景中需要设置共享内存!!!
配置完成后启动即可
配置模型缓存(可选)
Section titled “配置模型缓存(可选)”为了避免重复下载模型,我们可以通过持久化模型缓存实现,通过共享存储卷缓存目录 /root/.cache/
模型下载后即可保存至共享存储卷,共享存储卷重启不丢失,跨机器共享。

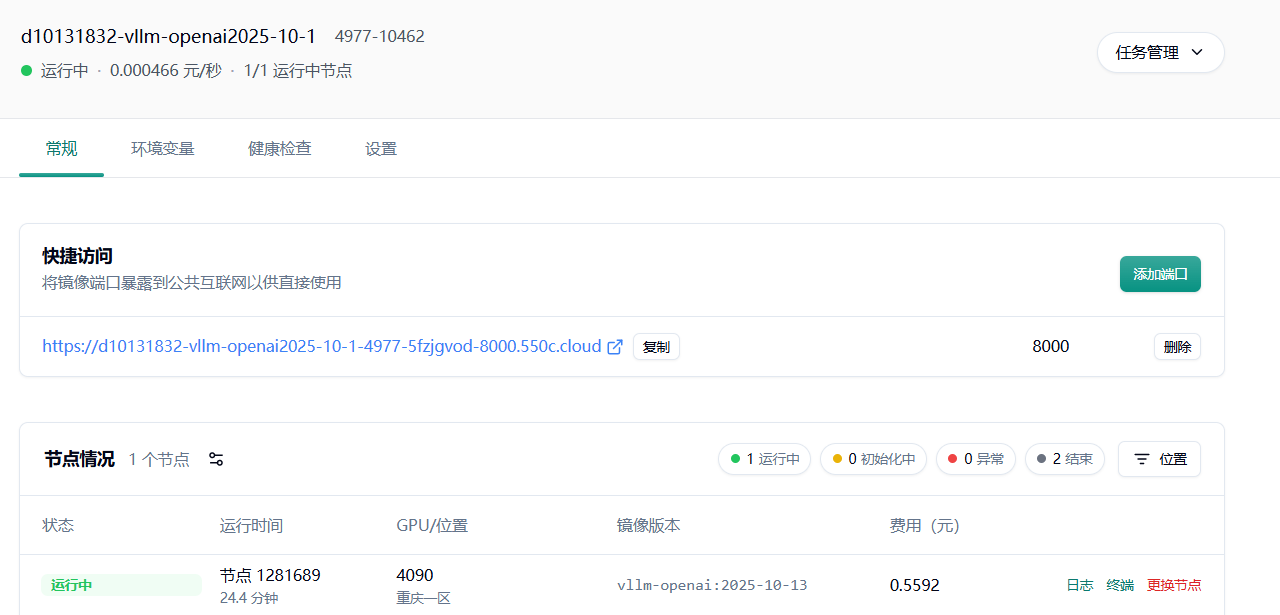
等待服务启动
Section titled “等待服务启动”等待镜像拉取,模型下载,CUDA 图编译。
启动完成后即可通过 OpenAI Completion API 调用服务。
小 Tips
可以创建共享存储卷挂载到 /root/.cache 上。防止模型重复下载。
显存不足
- 可以通过限制最大上下文长度,最大序列大小解决。
- 通过多节点,设置张量并行 or 专家并行。
- 通过量化运行,如 AWQ,GPTQ。