对象存储加速
1. 功能简介
Section titled “1. 功能简介”本功能支持用户将 S3 兼容对象存储(如阿里云 OSS、腾讯云 COS 等国内)挂载到平台,实现模型或数据的高效访问和加速。通过 JuiceFS 缓存机制,大幅提升模型加载和数据读取速度。
2. 操作流程
Section titled “2. 操作流程”2.1. 对象存储加速
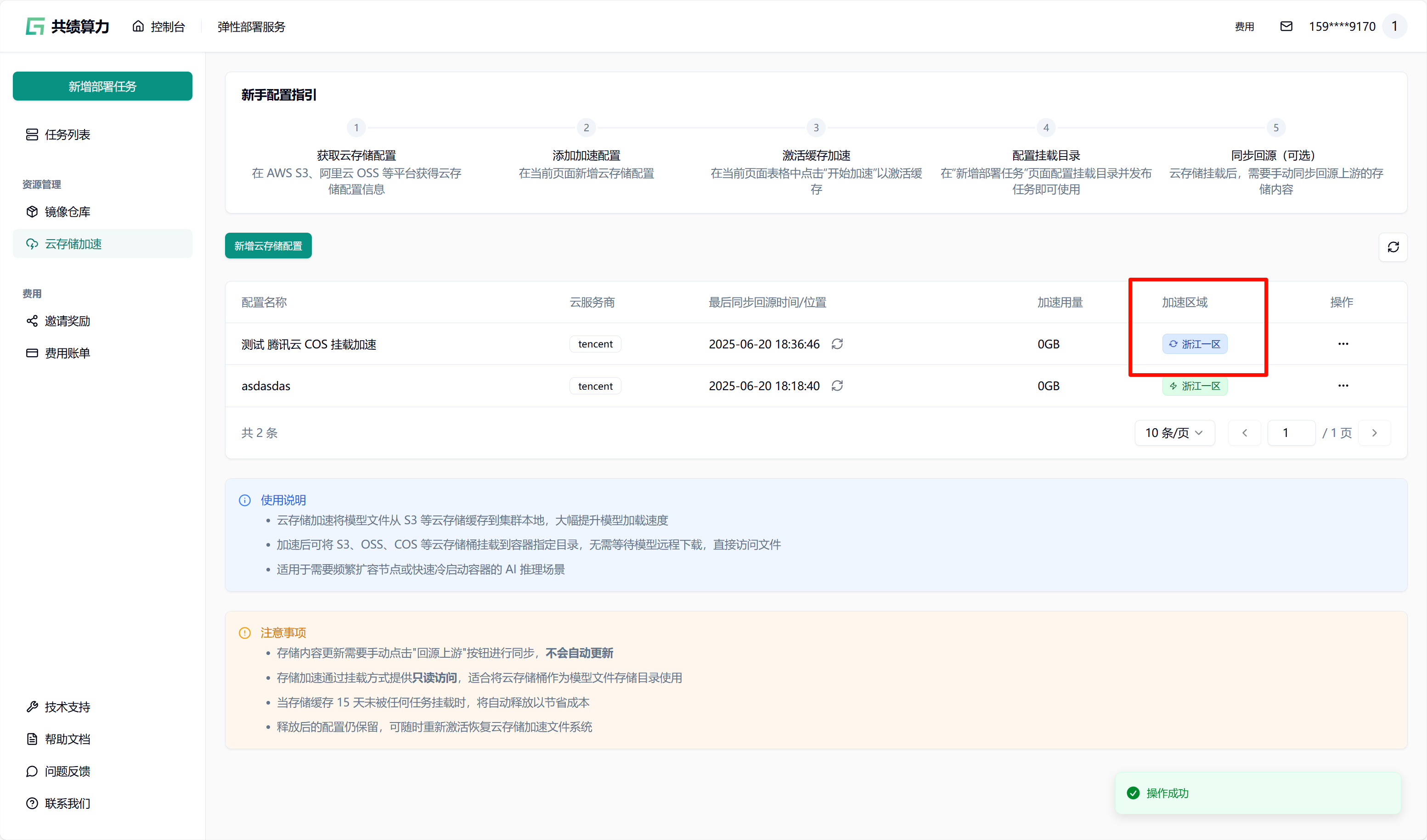
Section titled “2.1. 对象存储加速”进入存储加速管理页面在左侧菜单点击”对象存储加速”,进入管理页面。
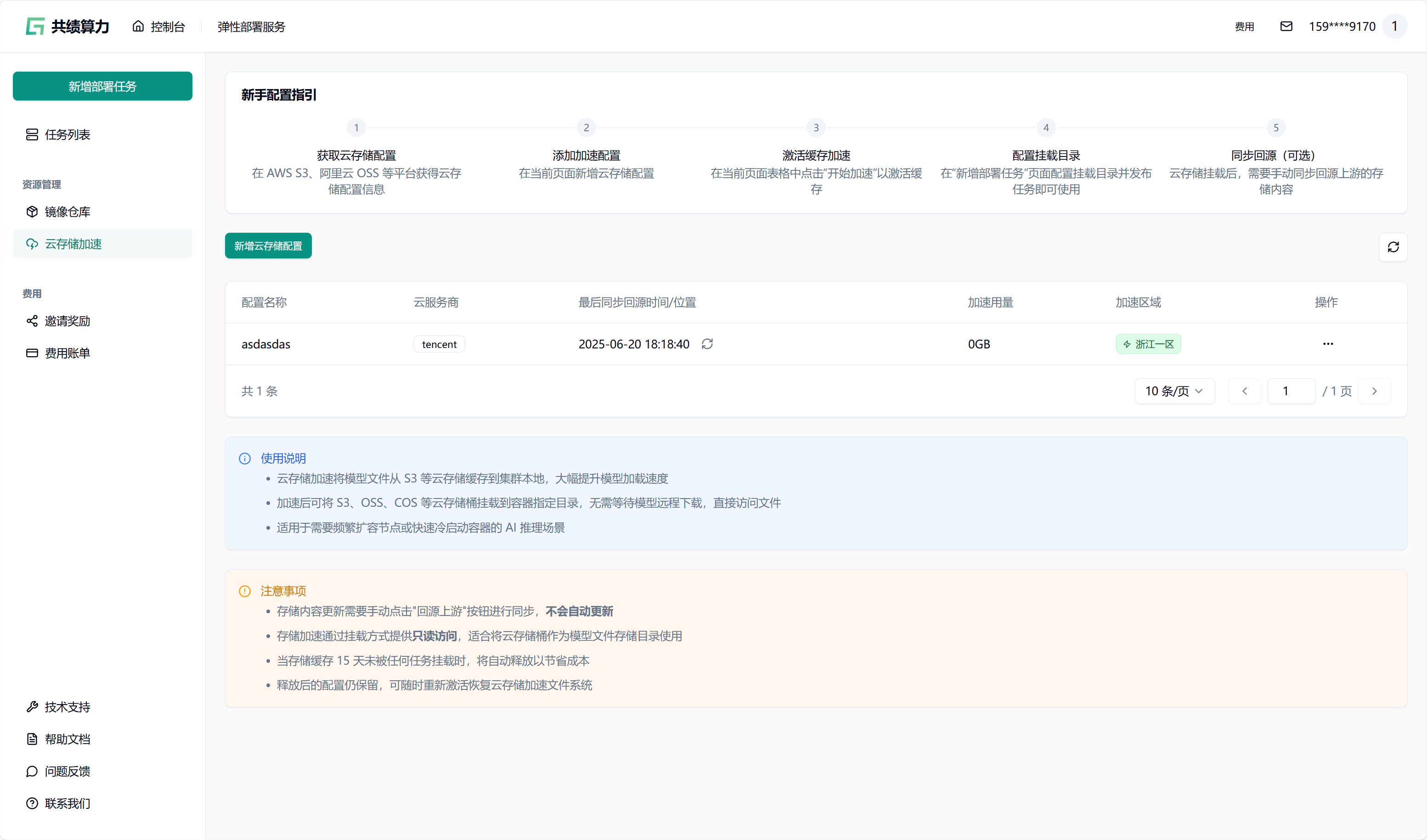
2.2. 获取对象存储配置
Section titled “2.2. 获取对象存储配置”2.2.1. 权限说明
Section titled “2.2.1. 权限说明”必须具备以下权限:
-
ListObjectsV2:用于校验 S3 加速页面所提供的目录是否存在。
- ListObjectsV2Input。
-
PutObject:用于校验对象存储是否具备写权限。此操作会创建临时文件进行校验,原因在于对象存储会生成 uuid 并放置到对象存储目录下。
- PutObjectInput。
-
DeleteObject:用于清理由 PutObject 创建的临时文件。
- DeleteObjectInput。
在使用过程中,请勿停用访问密钥(AK)、安全密钥(SK)或对其进行修改,以免功能不可用,对您的使用体验造成不良影响。
2.2.2. 阿里云 OSS
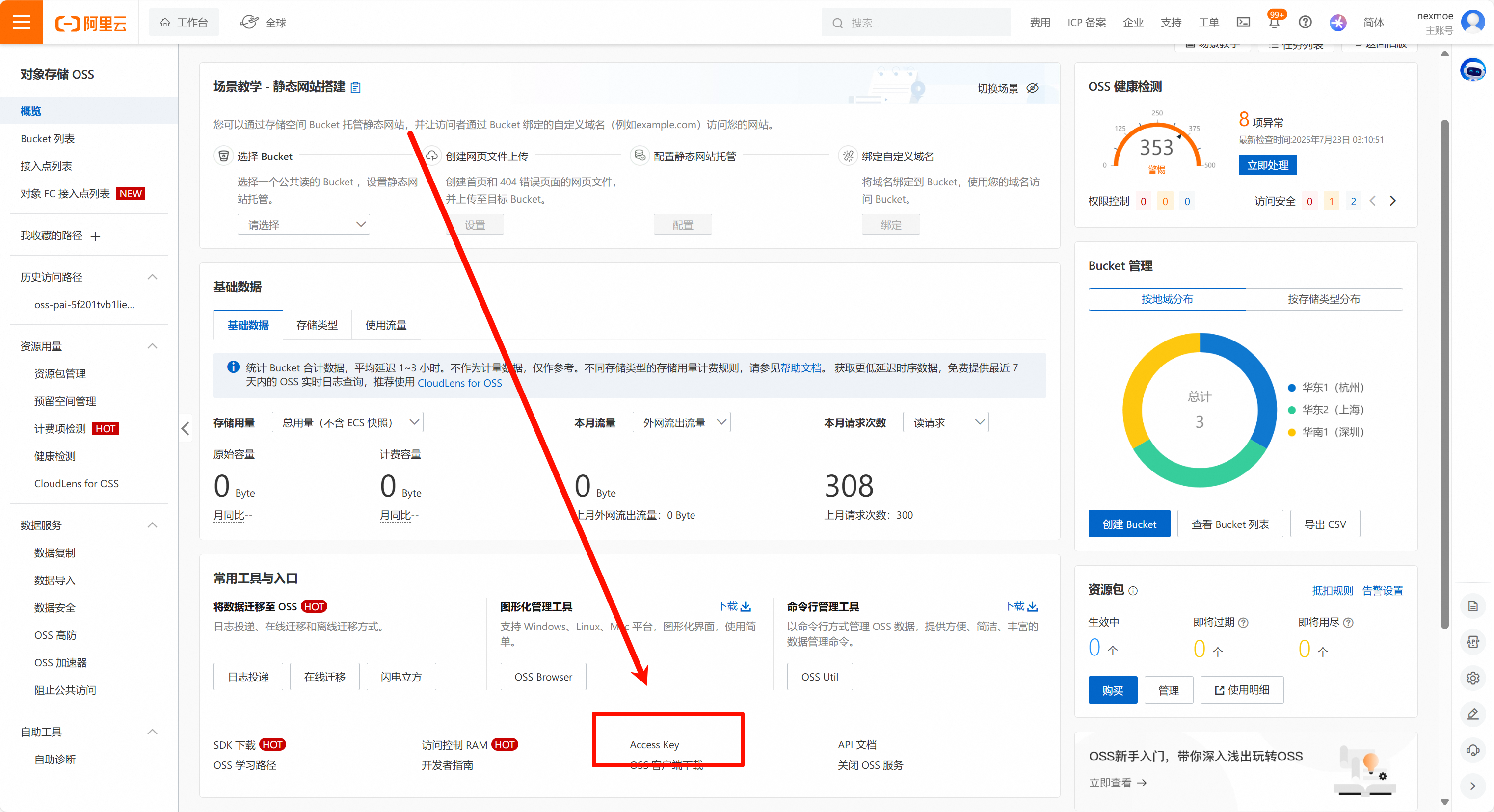
Section titled “2.2.2. 阿里云 OSS”可参照 这篇文档 了解如何创建 Access Key 和 Secret Key。
进入对象存储的控制台,找到 Access Key 入口:
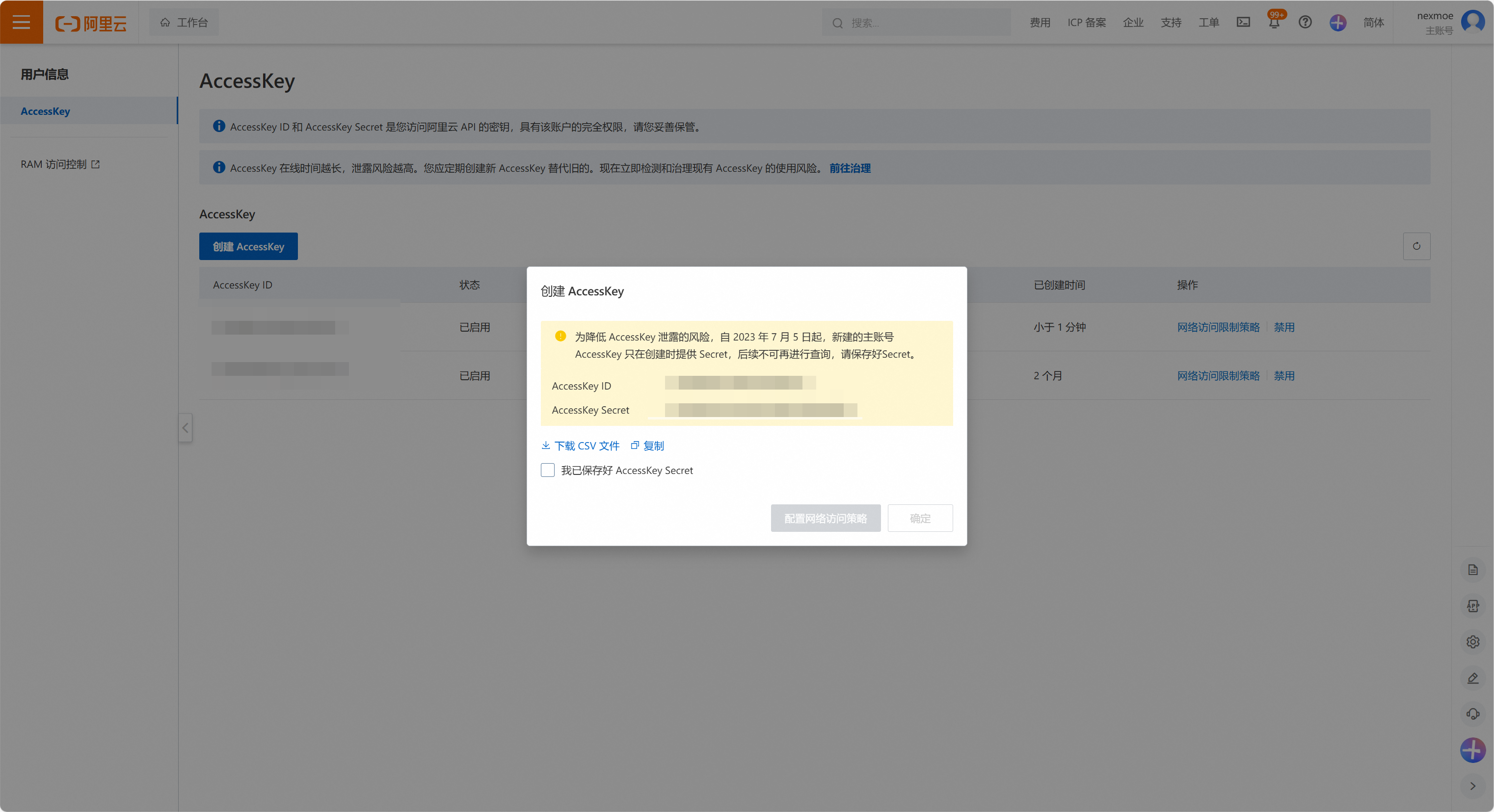
创建一个 Access Key 用于挂载:
2.2.3. 腾讯云 COS
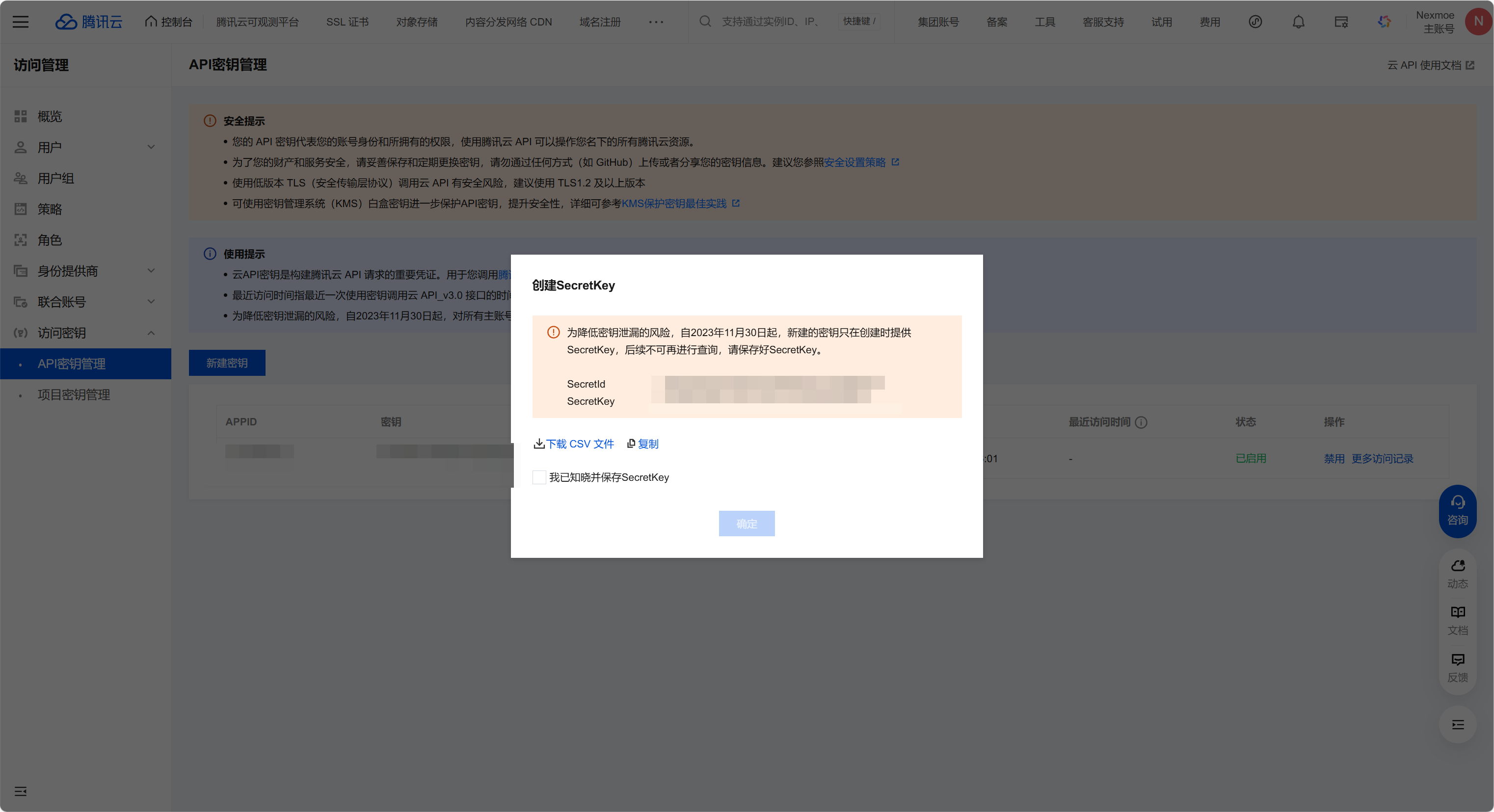
Section titled “2.2.3. 腾讯云 COS”Secret ID(AccessKey)和 Secret Key 需要在 API 密钥管理 中查看或创建。
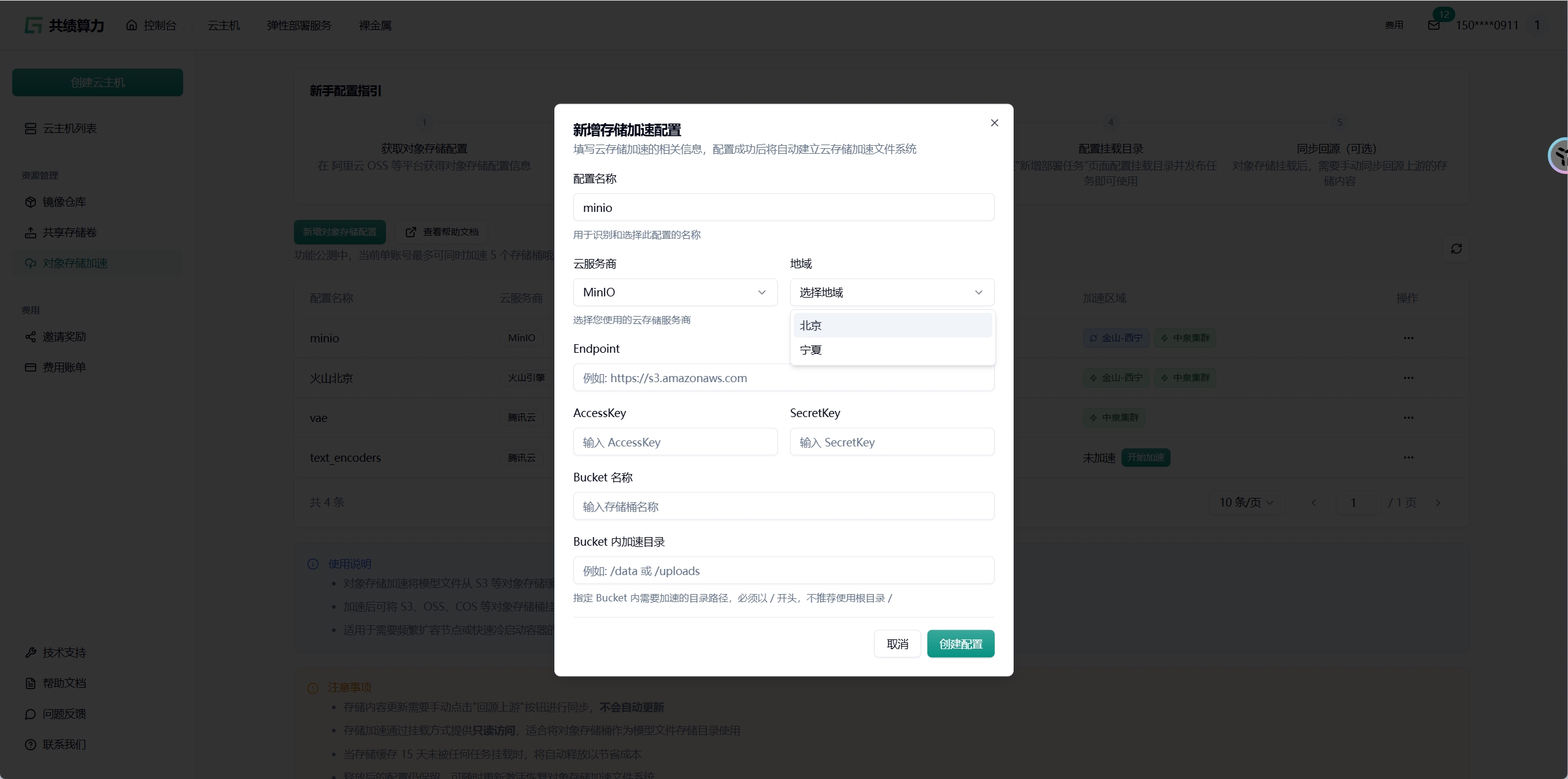
2.2.4. 自建 S3 - MinIO
Section titled “2.2.4. 自建 S3 - MinIO”理论上兼容 MinIO 和 RustFS
2.2.5. 火山引擎 TOS
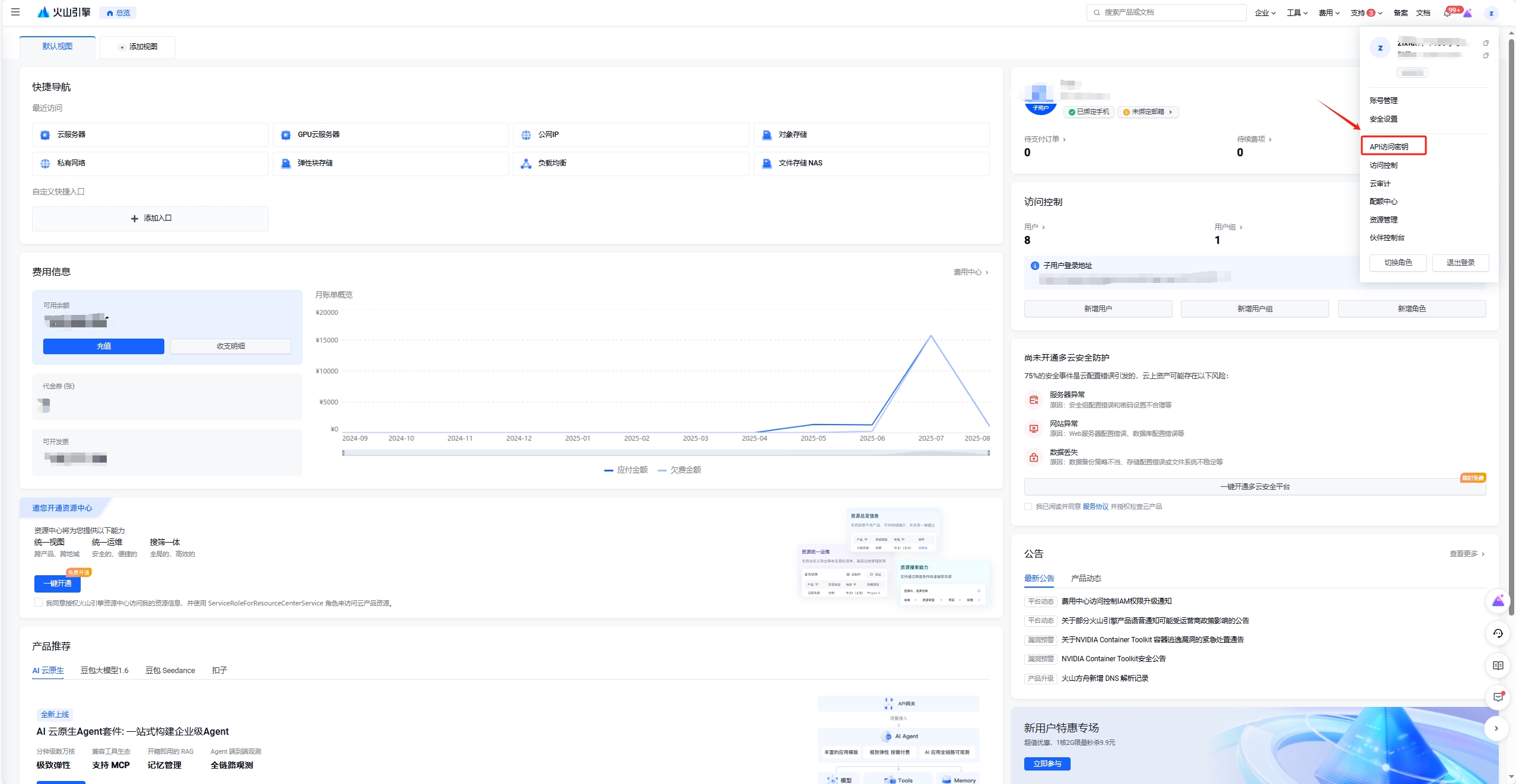
Section titled “2.2.5. 火山引擎 TOS”可参照 这篇文档 了解如何创建 Access Key 和 Secret Key。
火山引擎 TOS 为每个区域都提供了公网和内网 endpoint 链接,你可以根据实际的场景选用。
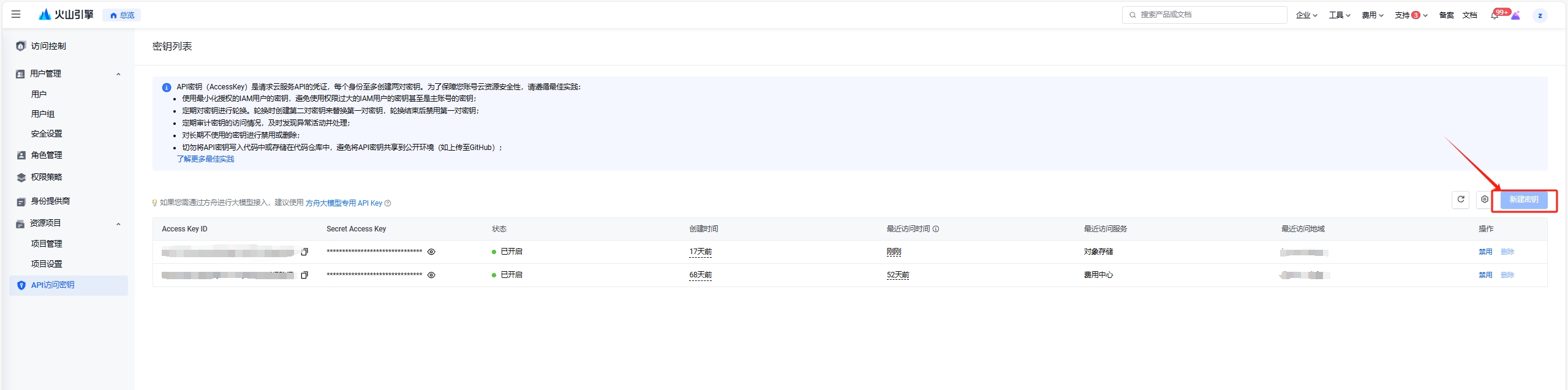
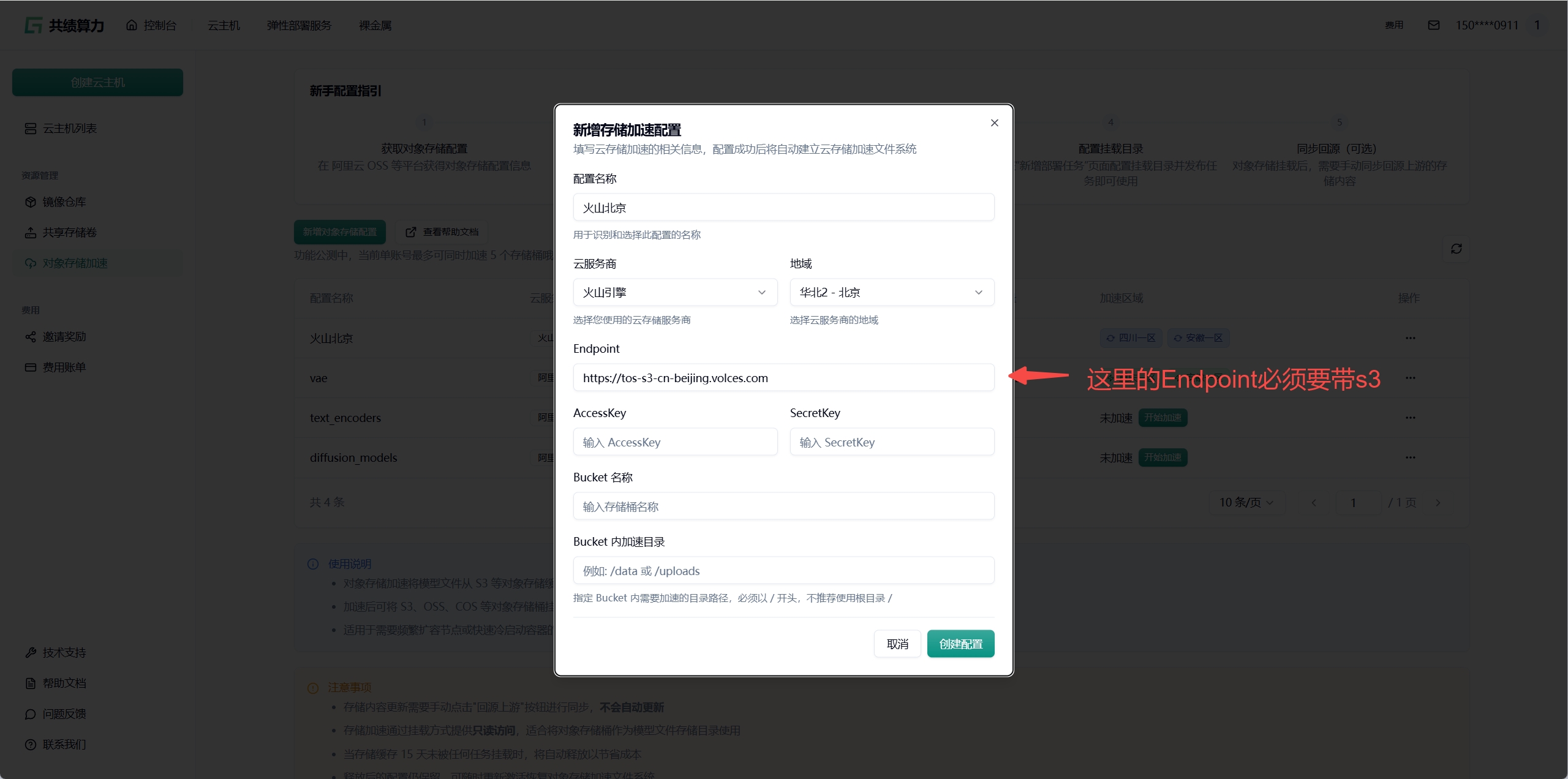
Endpoint 获取:需要选择 S3 Endpoint
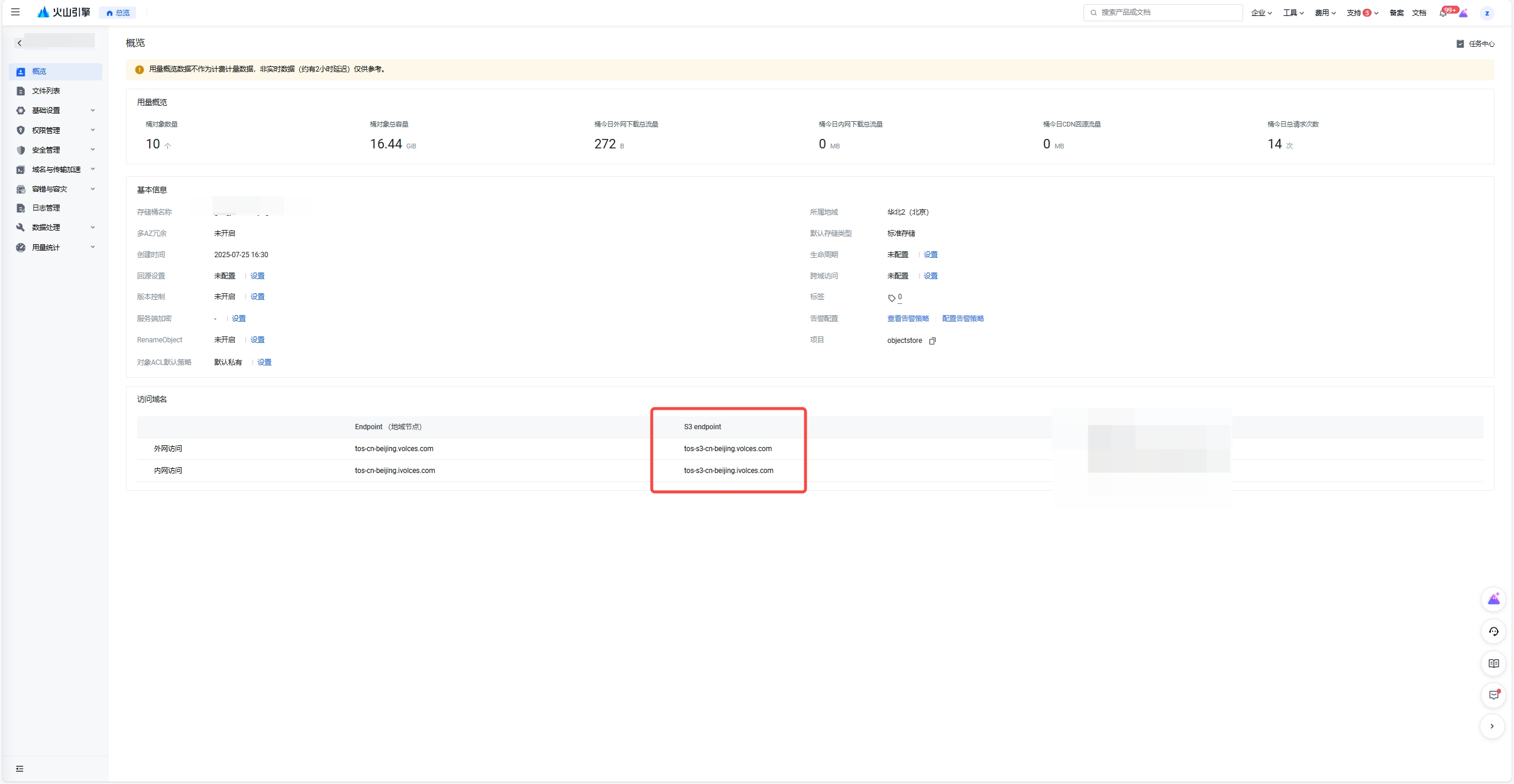
在下面 2.3 章节中配置对象存储时,需要使用携带 s3 的 Endpoint
2.3. 配置对象存储加速
Section titled “2.3. 配置对象存储加速”点击”新增对象存储配置”按钮,选择云服务商,填写以下信息:
- 配置名称
- 对象存储:服务商、地域、Endpoint(不能带 Bucket)、AccessKey、SecretKey、Bucket 名称
- 加速目录:Bucket 中需进行加速处理的目录(不建议挂载根目录,因这会致使根目录下所有文件被缓存,占用大量空间,且不利于业务的合理分割)
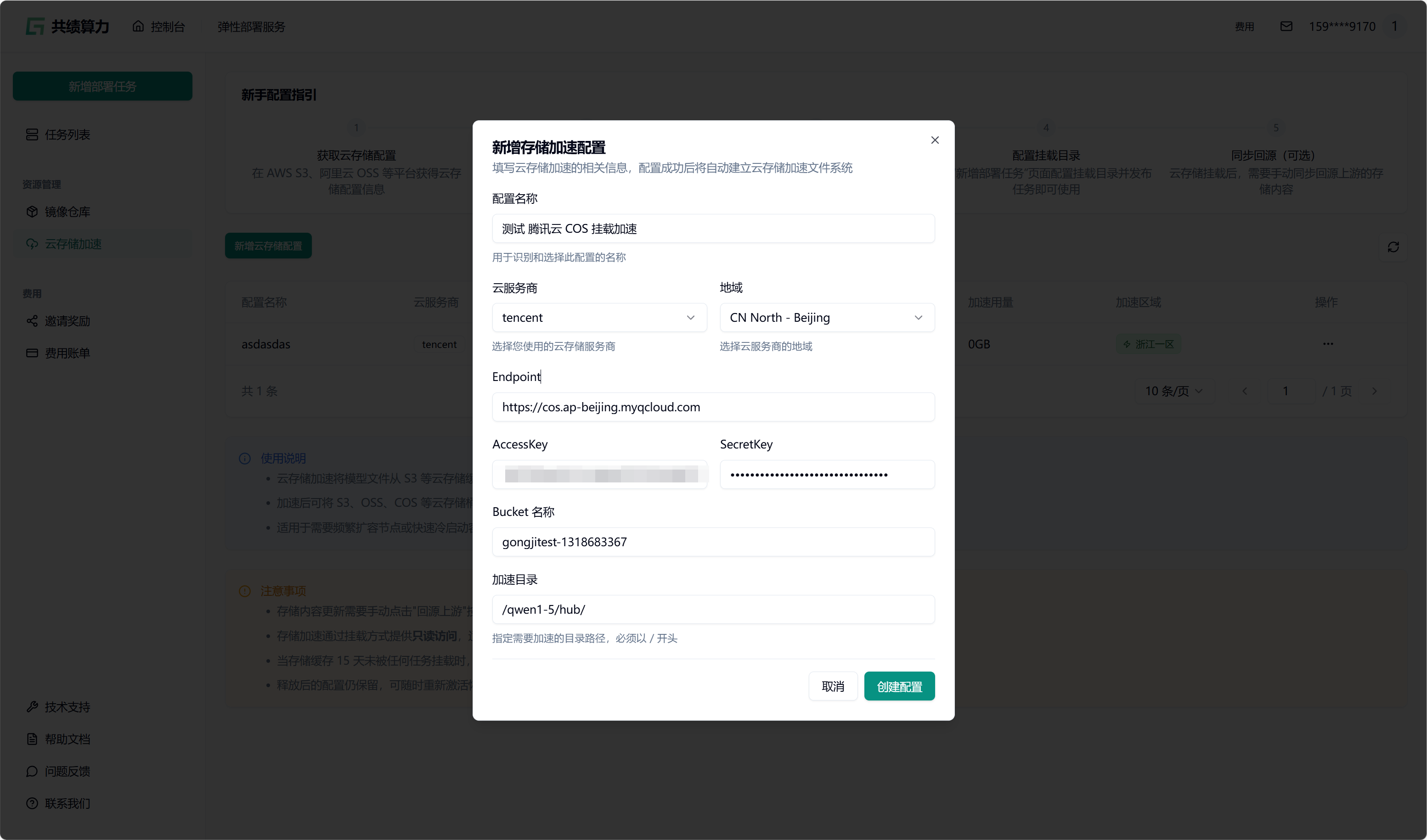
当执行保存配置操作时,系统会自动对配置的可用性进行检测。只有在校验通过之后,配置才可成功保存。在列表中查找到相应配置后,点击“开始加速”选项,接着选择加速区域,此时系统将自动对 JuiceFS 文件系统进行初始化(此过程约需 1 - 2 分钟,期间状态会从蓝色转变为绿色,状态为绿色时已可以挂载此存储桶)。同时,系统还会执行提前预热操作(此操作需从云端将文件下载至本地,因此需等待一定时长。例如,若文件大小为 6.6 G,下载完成大约需要 30 分钟)。
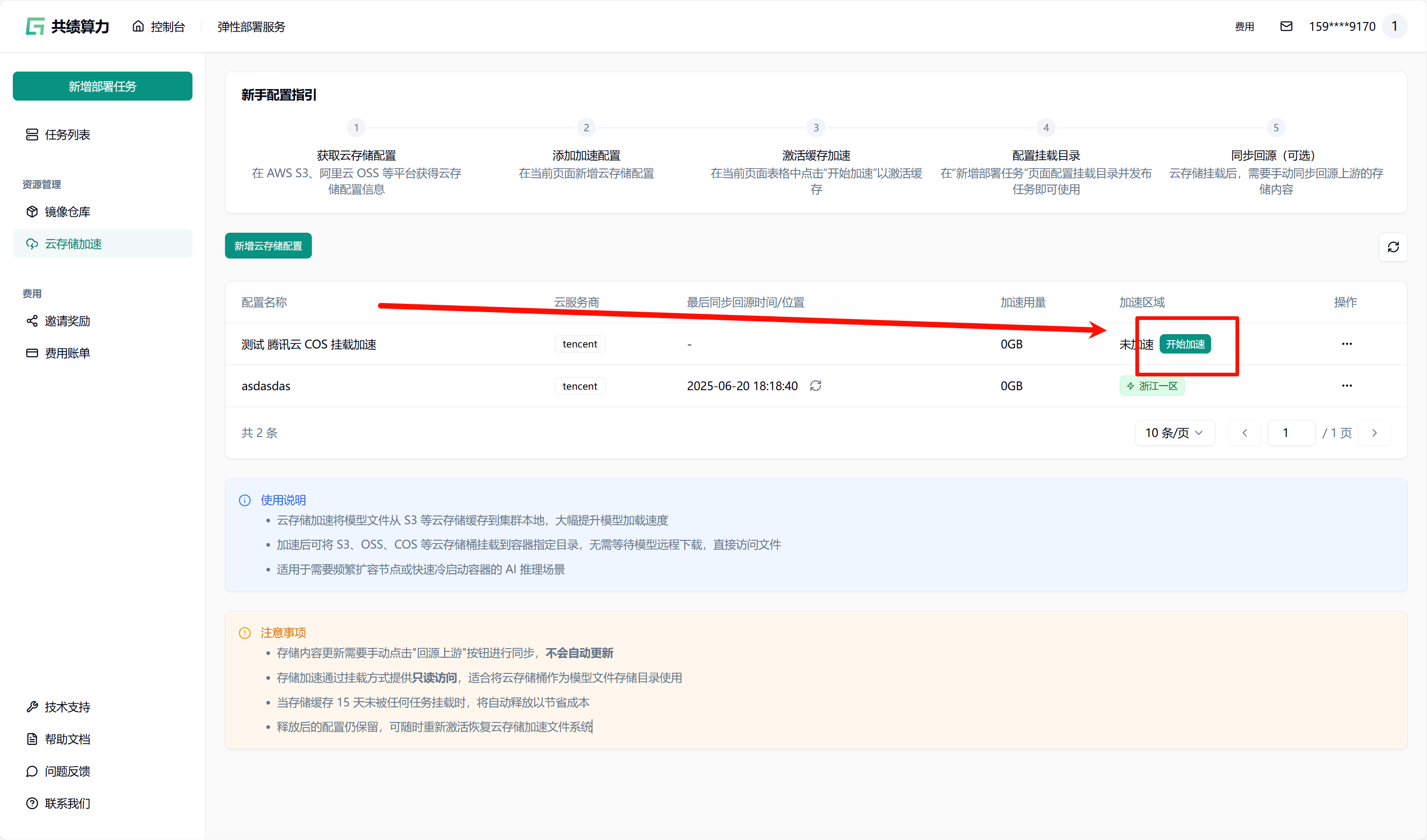
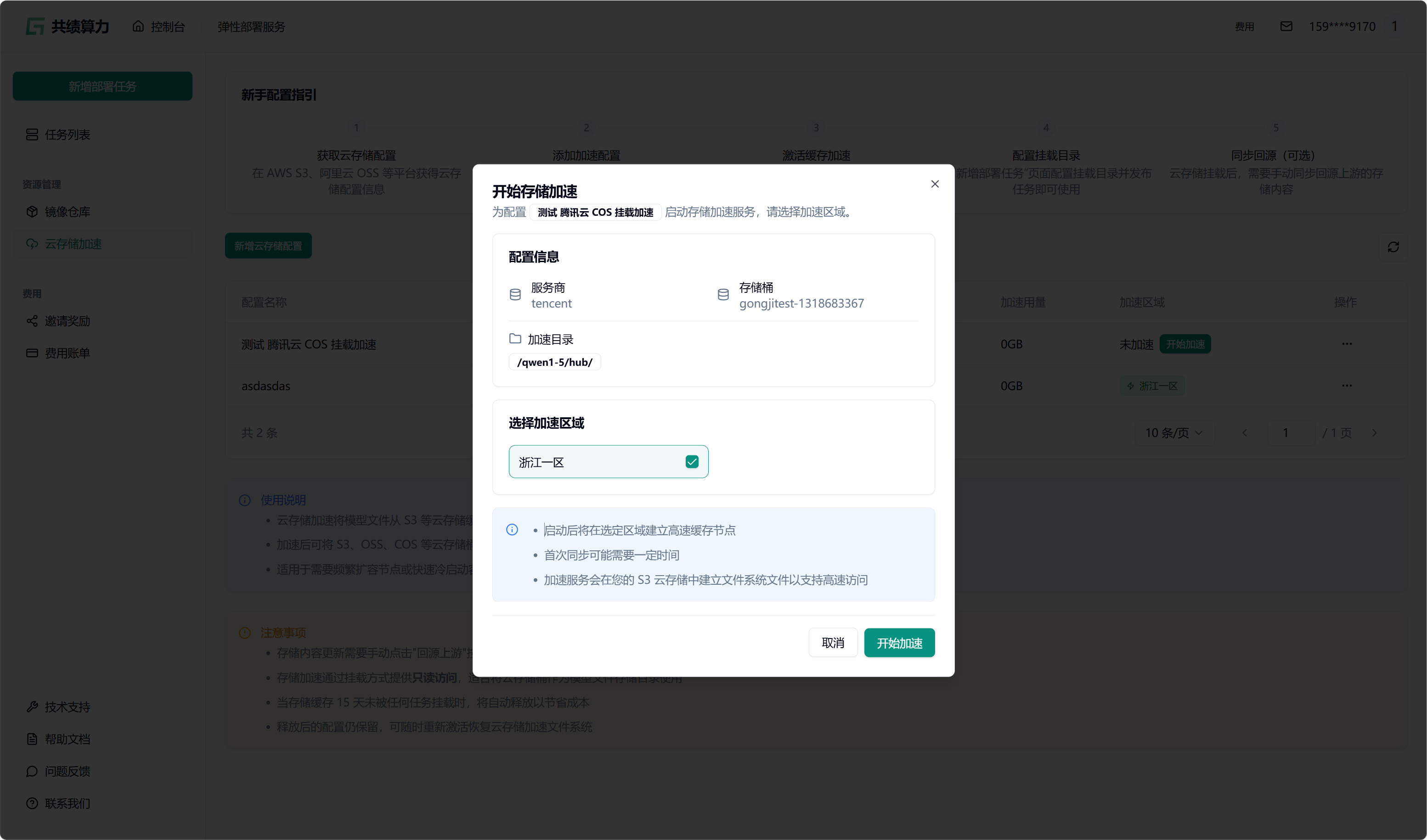
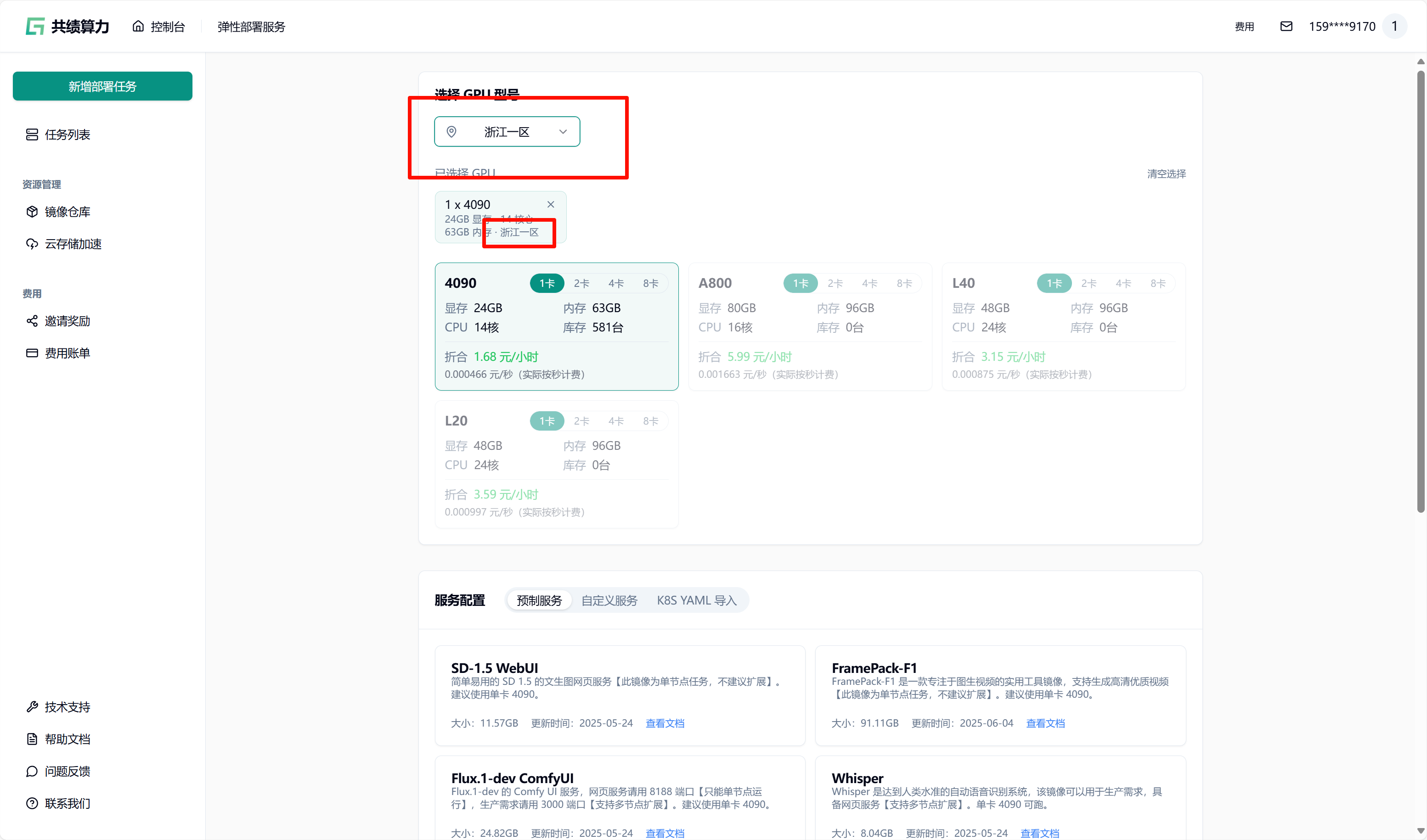
2.4. 任务发布时挂载
Section titled “2.4. 任务发布时挂载”先选择 GPU、GPU 区域(需要与对象存储选择的加速区域一致)。我的对象存储加速了“浙江一区”,所以我选择“浙江一区”的 4090 GPU。
然后在任务发布页面的”存储配置”区域,选择已配置并加速的 S3 存储桶(当前状态为绿色时,可以直接挂载。集群内第一次使用需要等待从云端拉取文件到集群。此操作需从云端将文件下载至本地,因此需等待一定时长。例如,若文件大小为 6.6 G,下载完成大约需要 30 分钟。集群第二次挂载则会直接从本地拉取模型文件)。
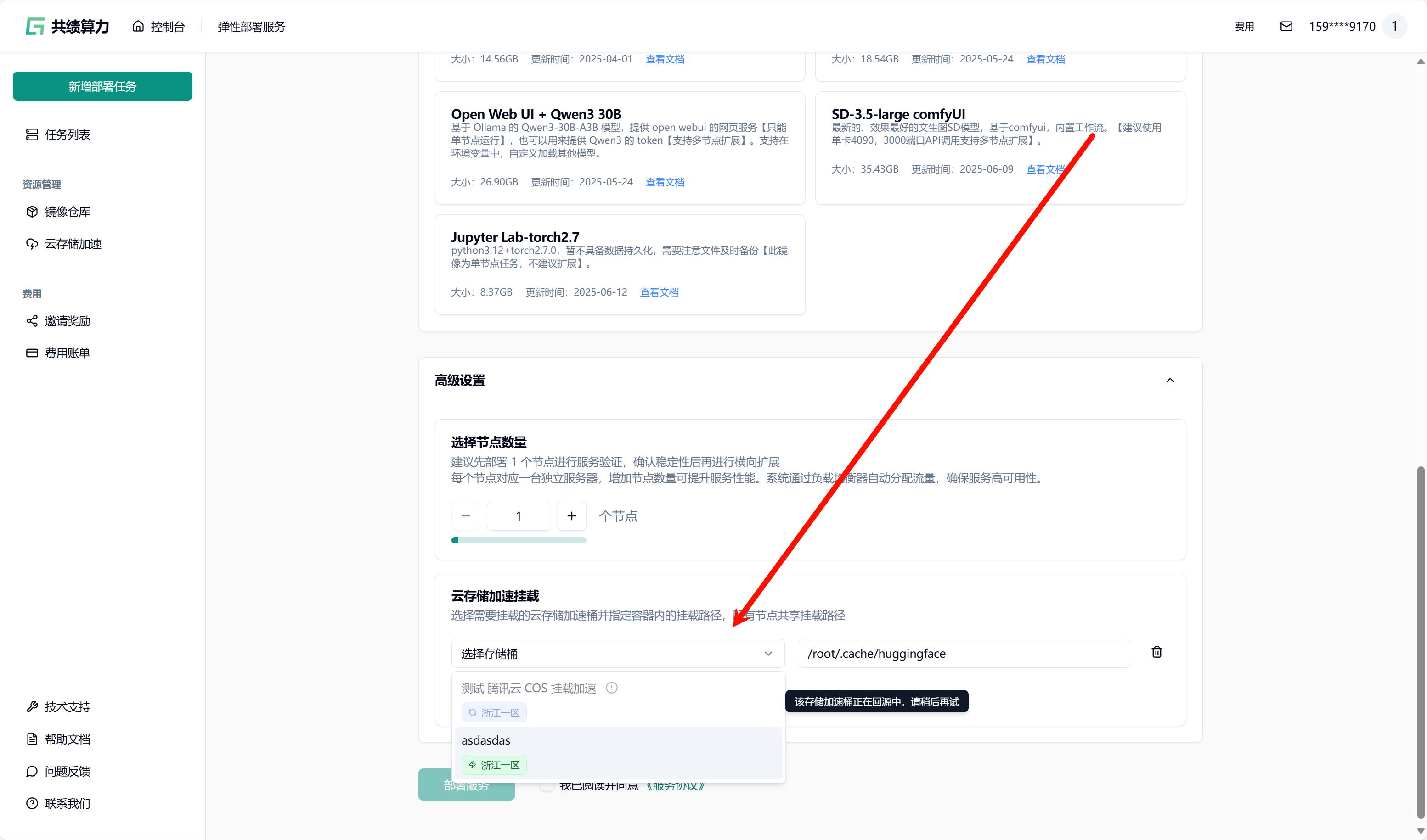
为每个对象存储加速目录填写容器内的挂载路径(如 /mnt/my_model_data),路径需以 / 开头。需要注意两个目录的对应关系。
我这里将对象存储 Bucket 中的 /qwen1-5/hub/挂载到了容器中的 /root/.cache/huggingface 目录中
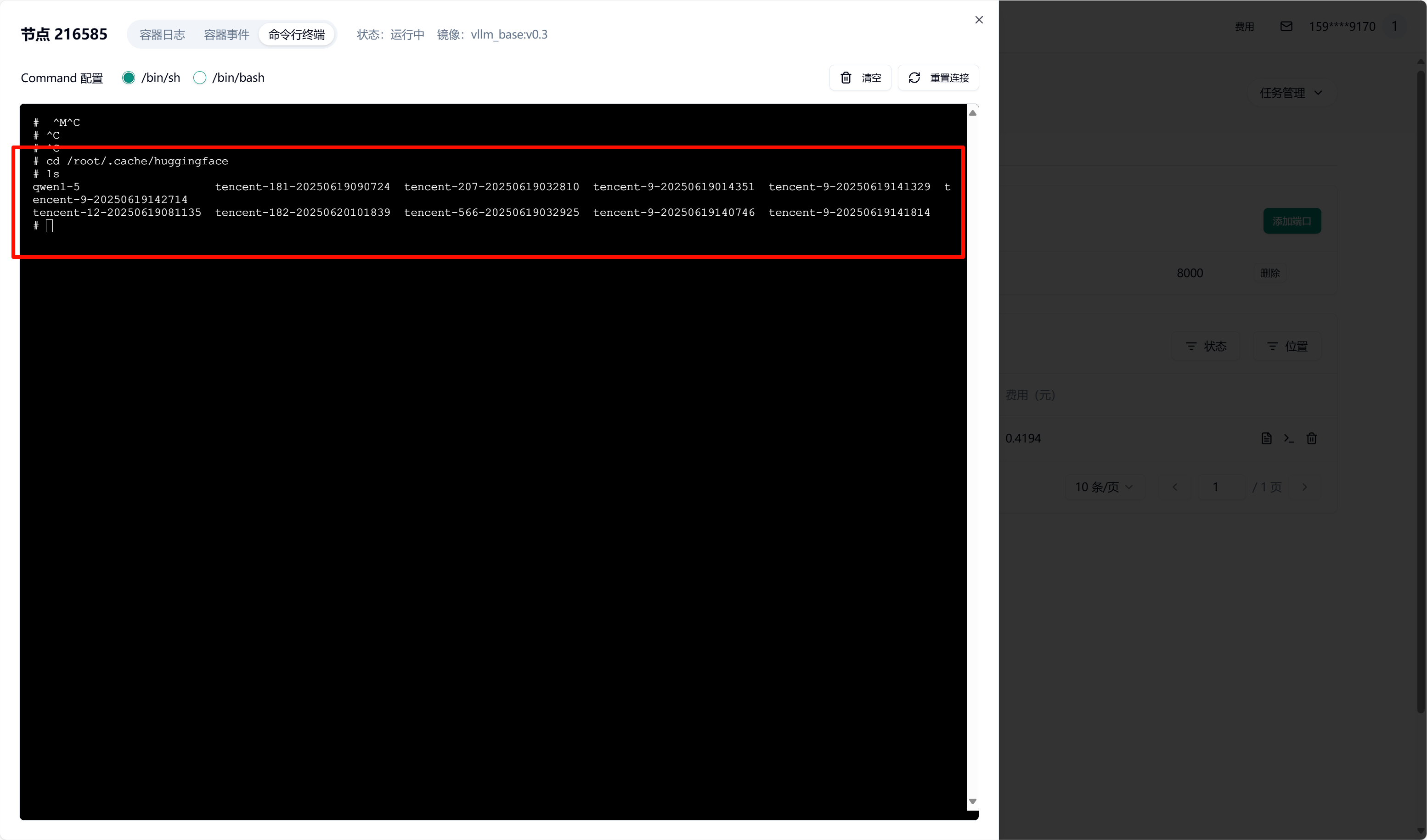
2.5. 验证挂载
Section titled “2.5. 验证挂载”提交任务后,容器启动时会自动挂载所选 S3 存储。待容器启动完成后,可进入容器并验证挂载。查看挂载目录下的文件是否存在。
2.6. 存储加速释放与管理
Section titled “2.6. 存储加速释放与管理”- 手动释放:在存储加速管理页面可手动释放缓存,释放后 JuiceFS 文件系统和缓存会被清除,会清除加速用量,但对象存储的配置信息仍保留。
- 自动释放:若 15 天内无任务挂载该存储,加速服务会自动释放,配置数据保留,可随时重新激活。
2.7 子账号授权
Section titled “2.7 子账号授权”2.7.1 授权操作
Section titled “2.7.1 授权操作”2.7.1.1 腾讯云
Section titled “2.7.1.1 腾讯云”- 找到对象存储。
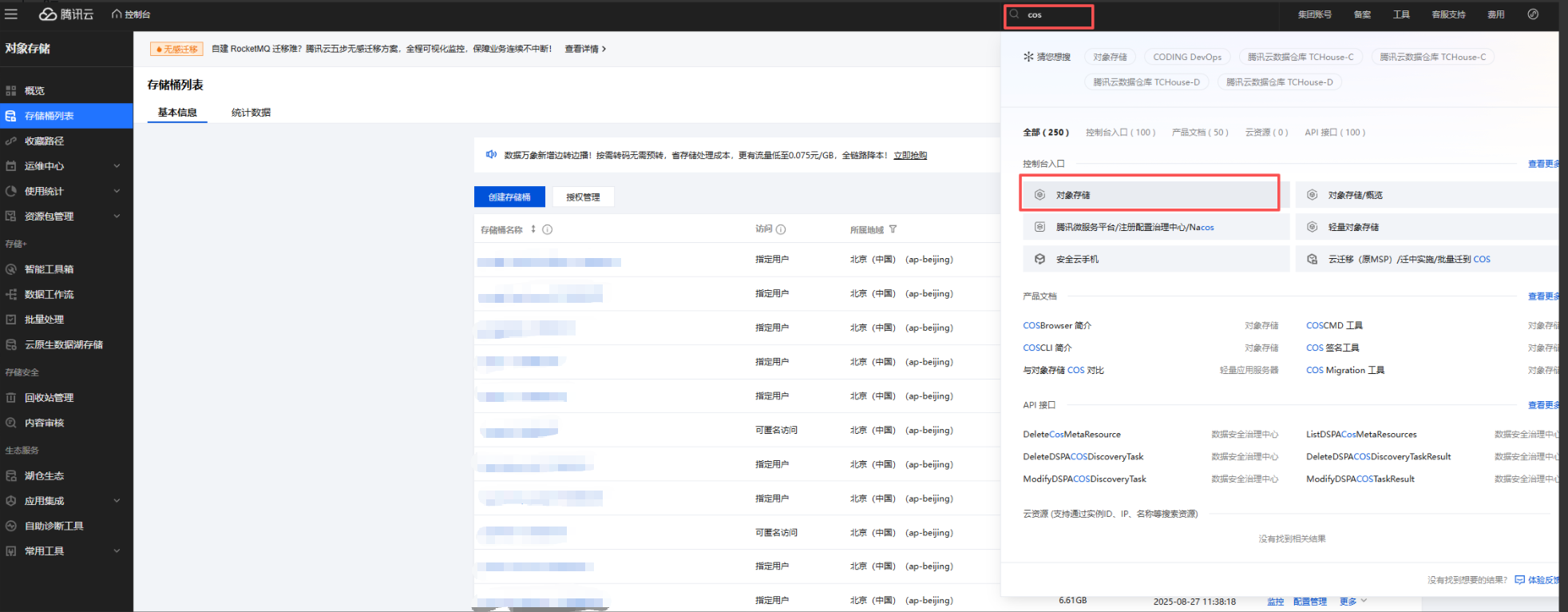
- 点击存储桶列表。
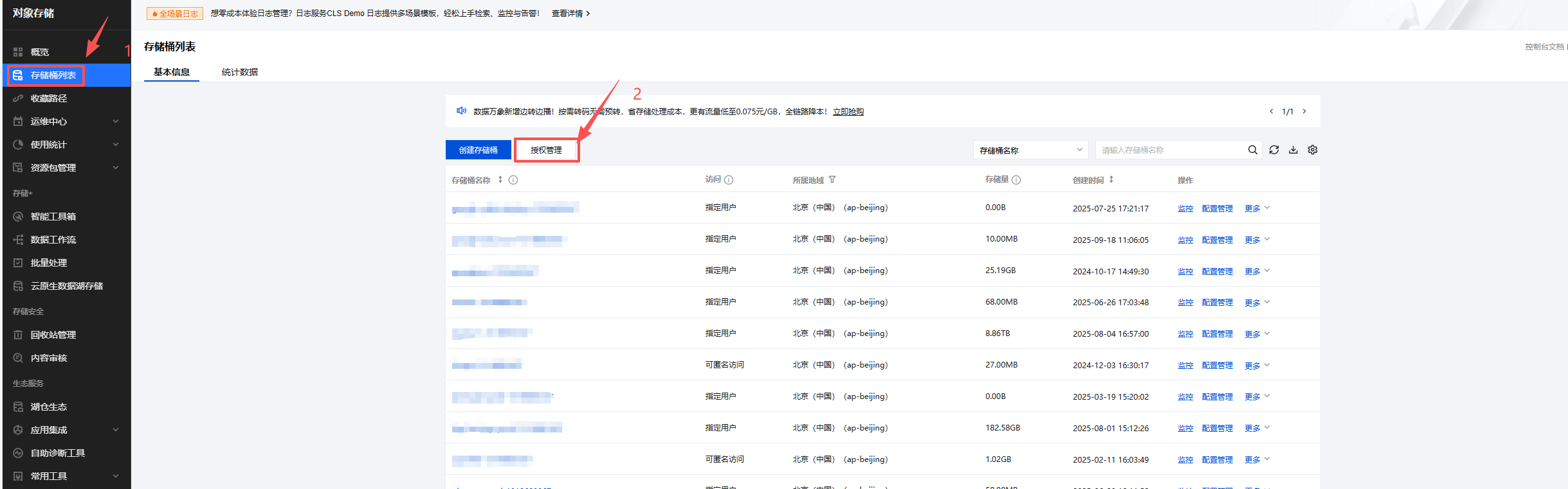

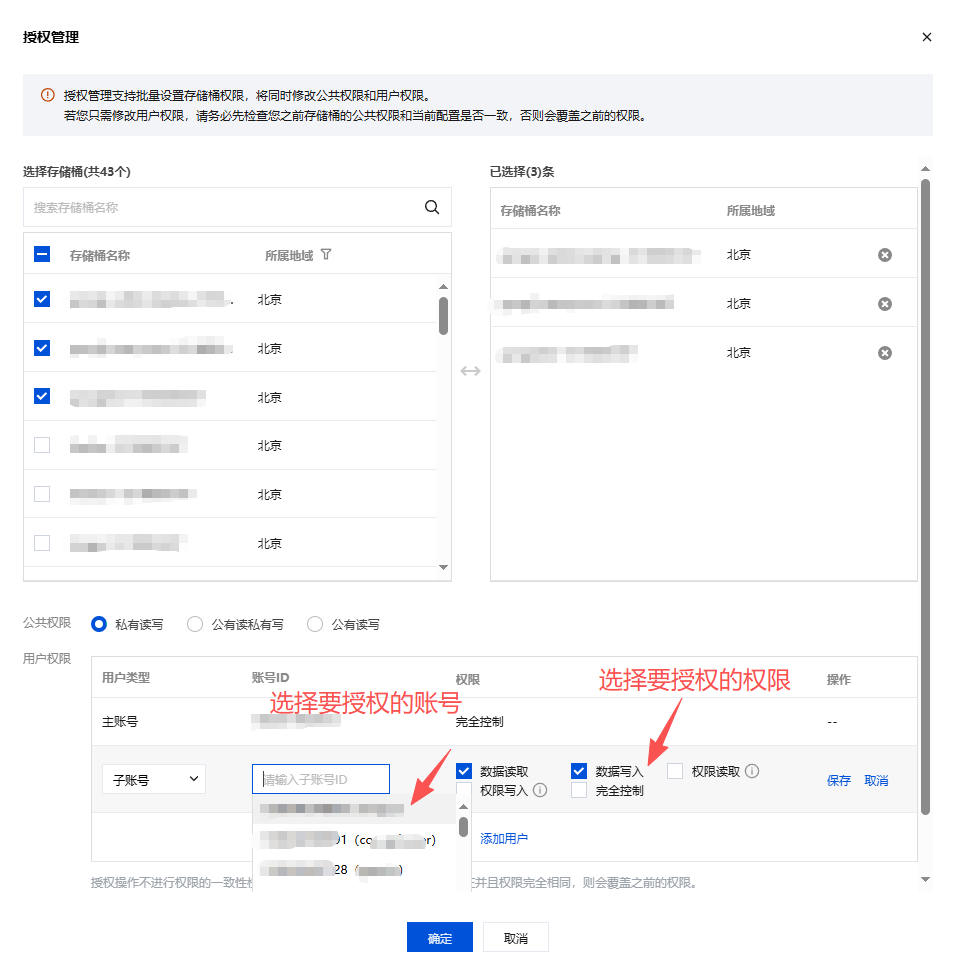
2.7.1.2 阿里云
Section titled “2.7.1.2 阿里云”- 找到对象存储。
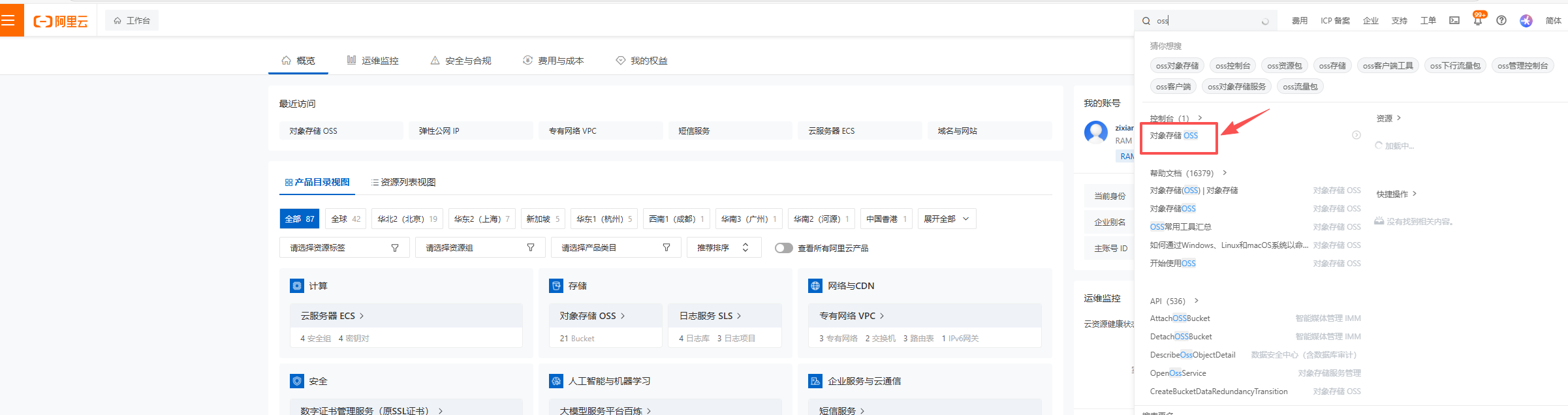
- 找到要设置权限的桶,然后点进去。
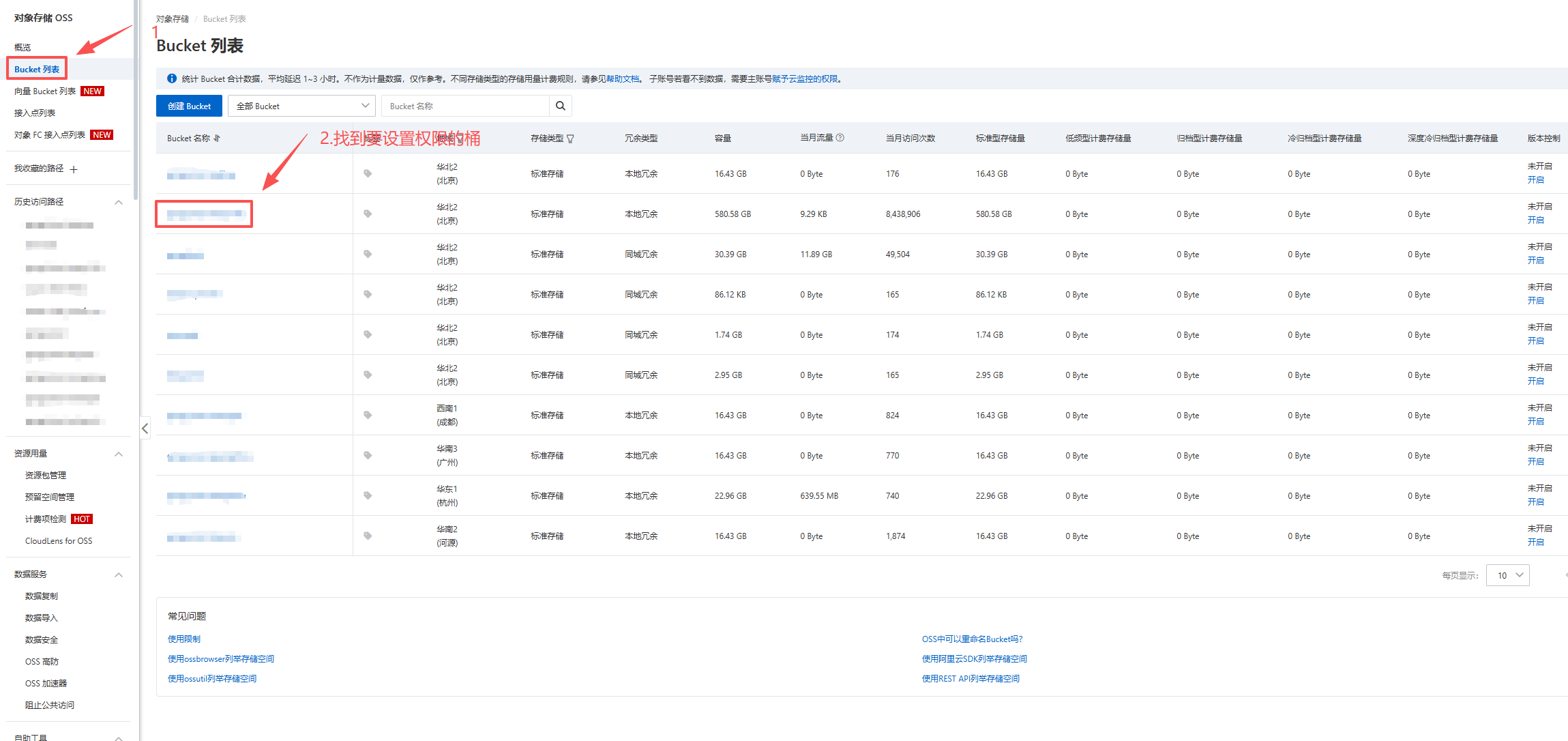
- 设置权限。
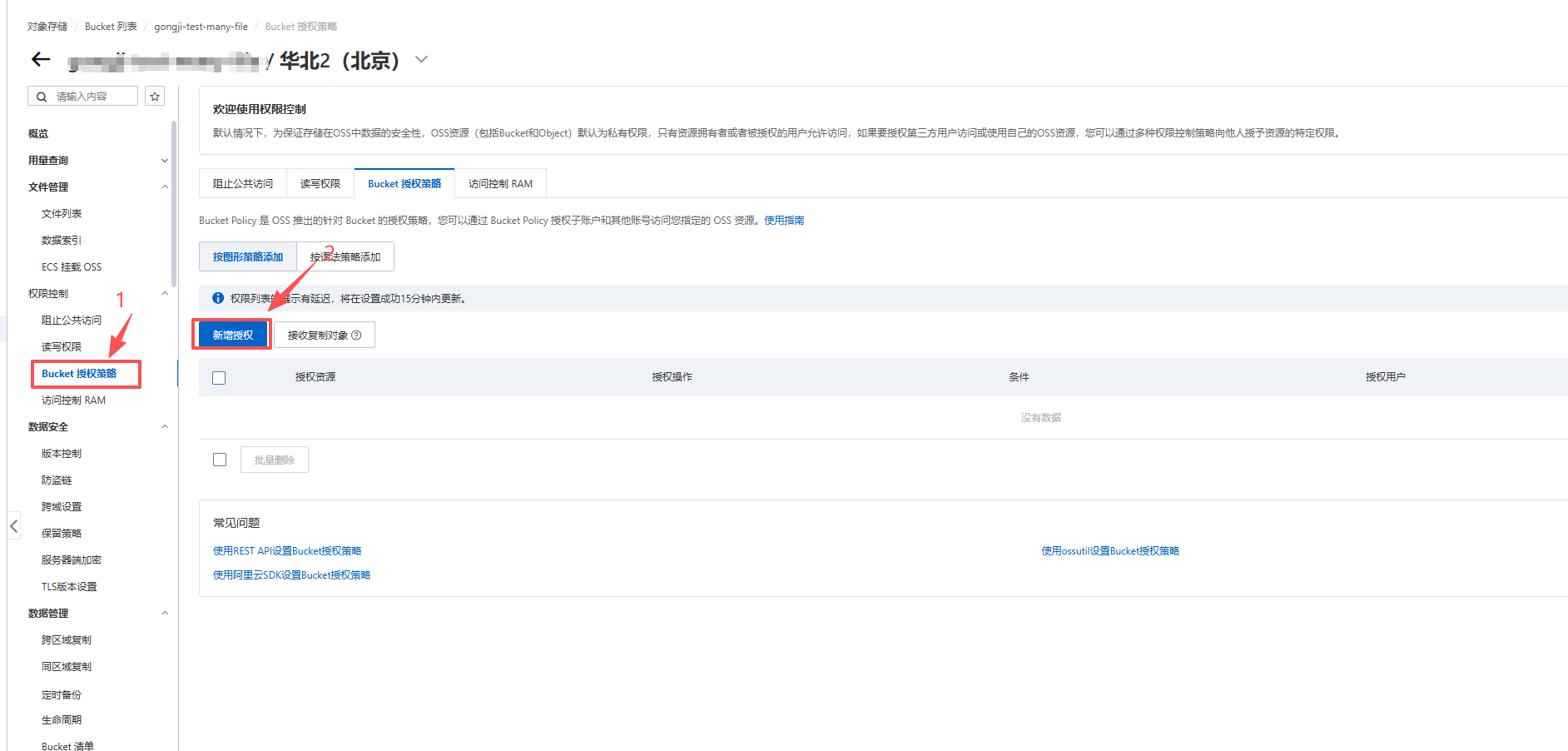
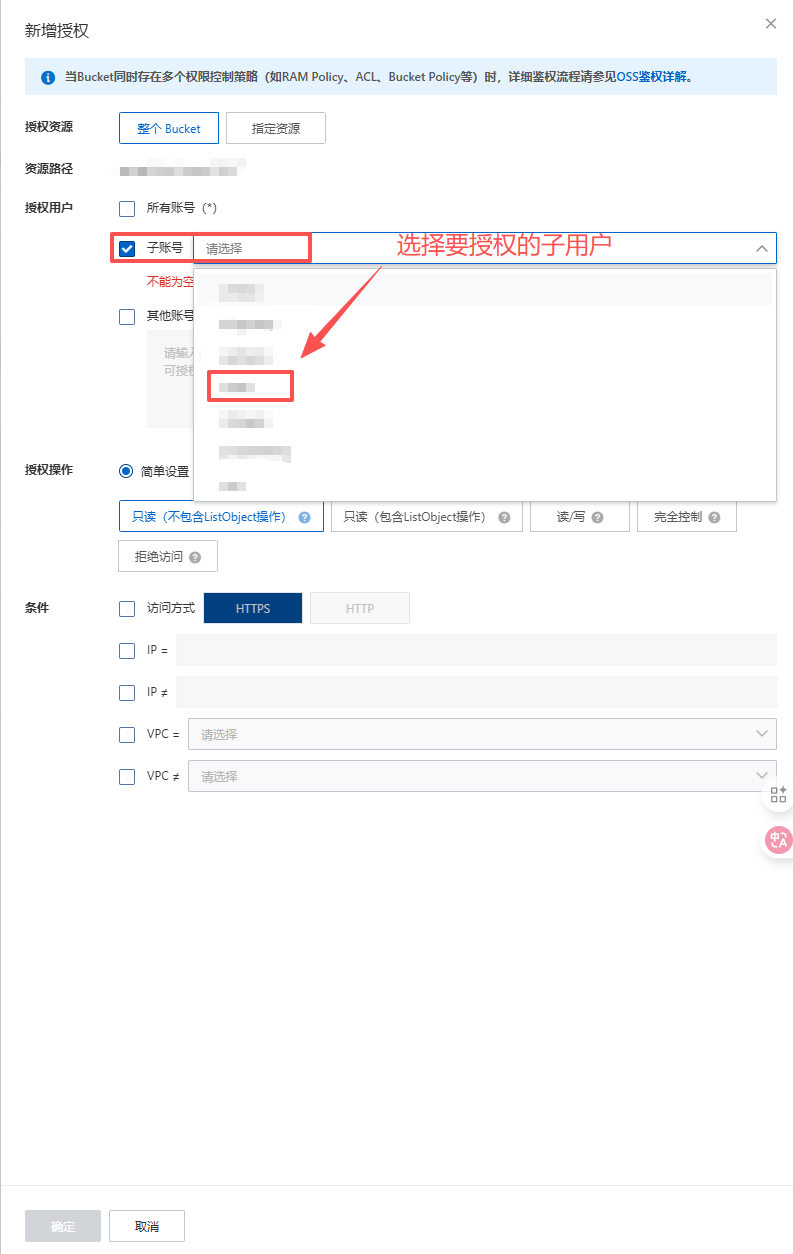
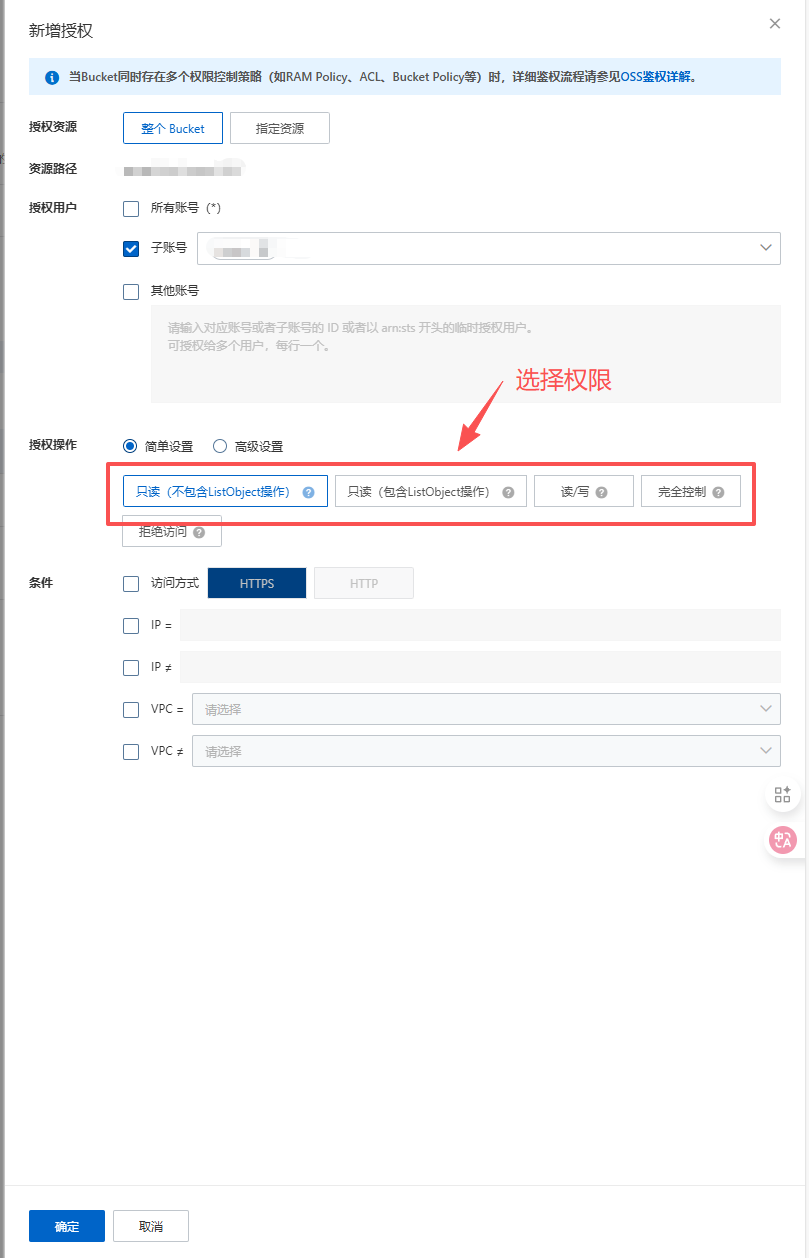
2.7.1.3 火山云
Section titled “2.7.1.3 火山云”- 找到对象存储。

- 找到要设置的桶
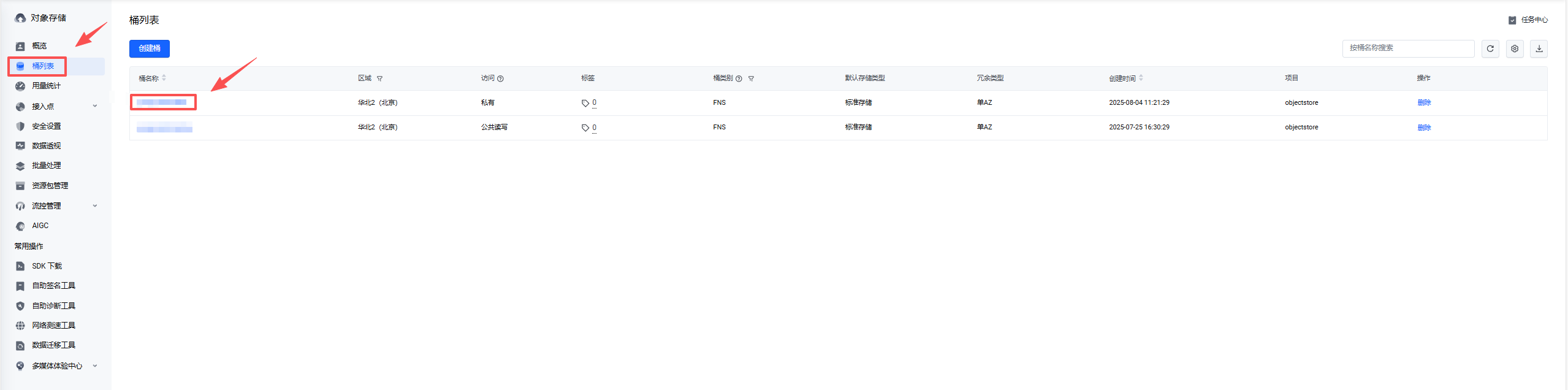
- 设置权限
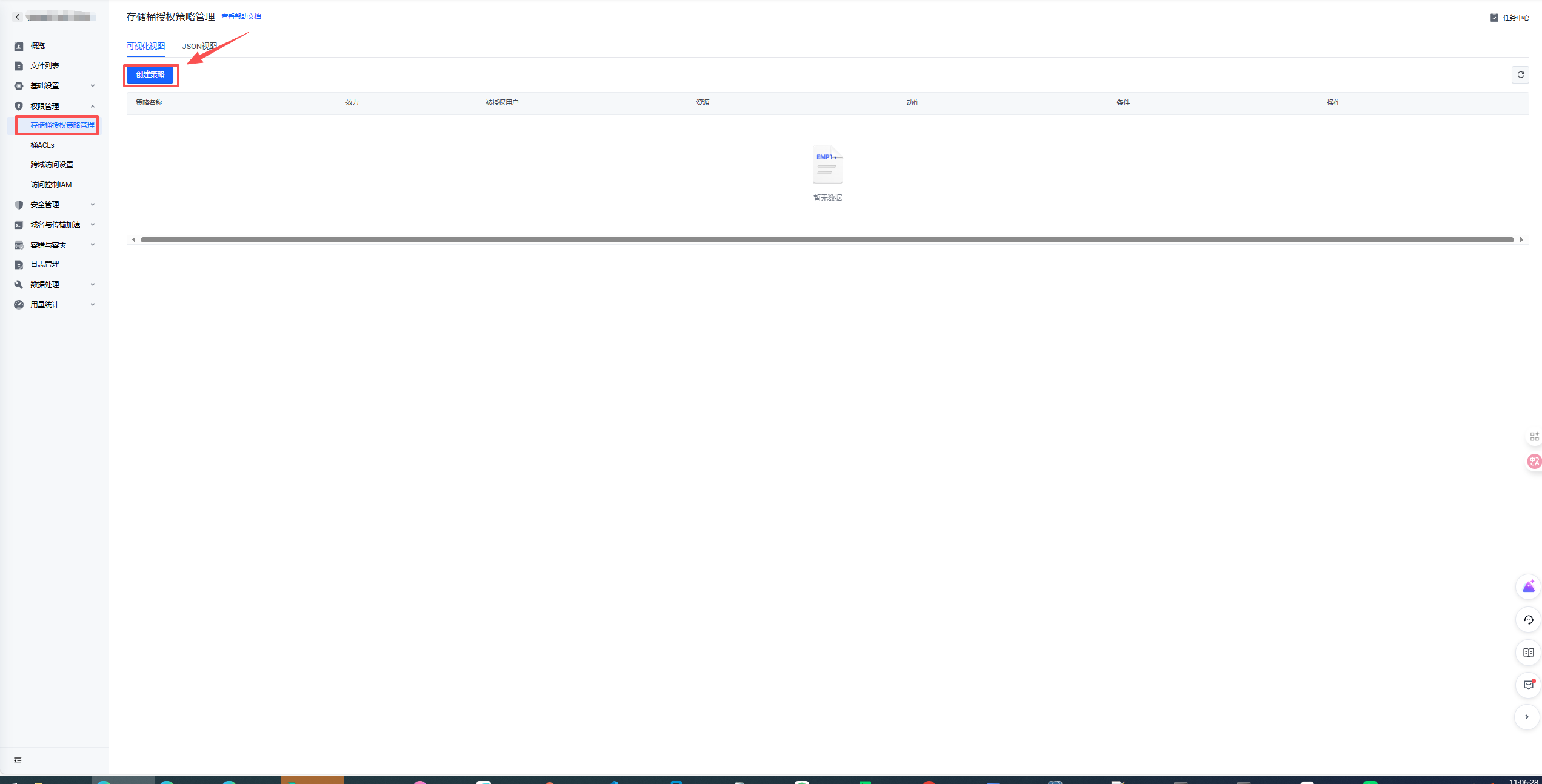
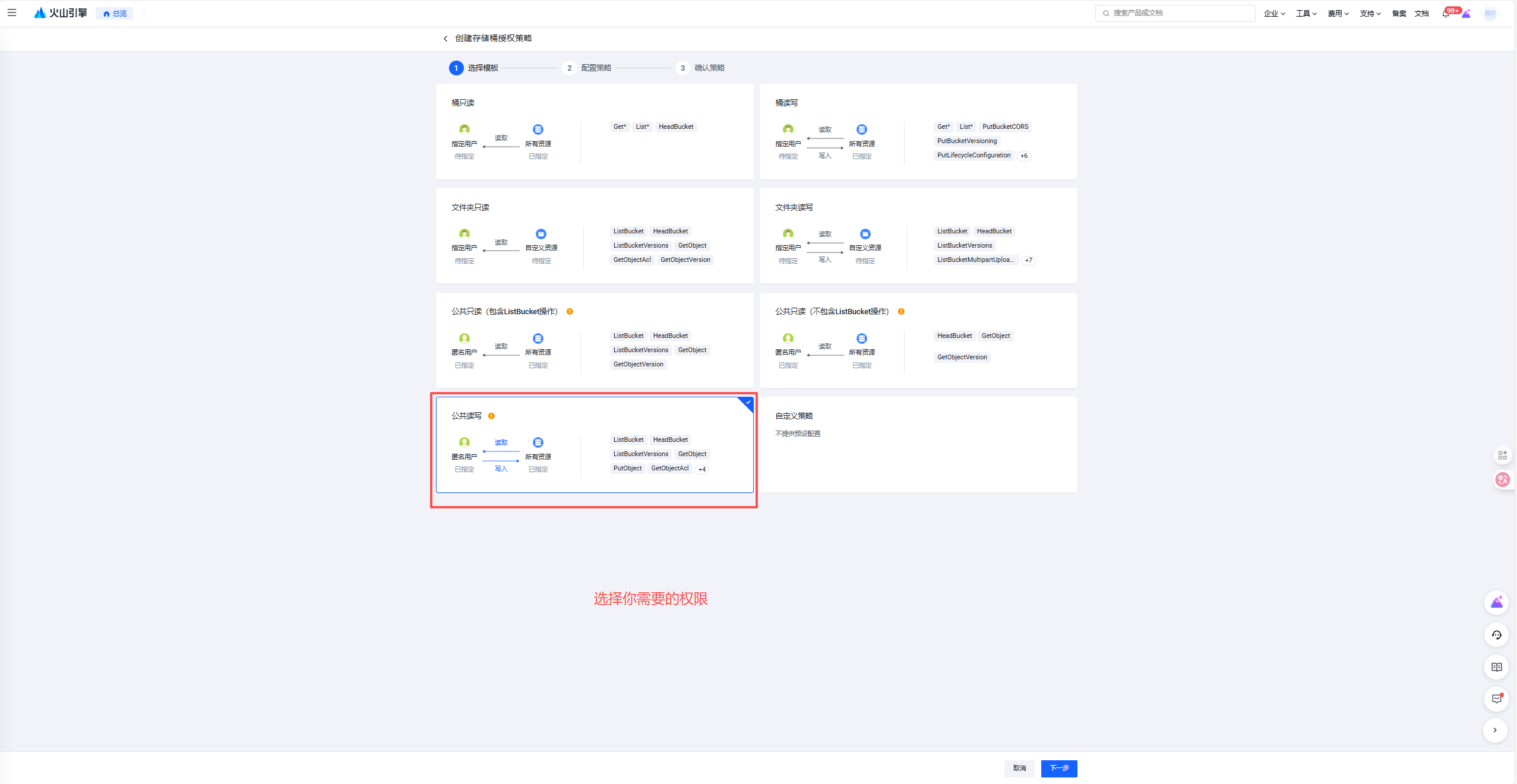
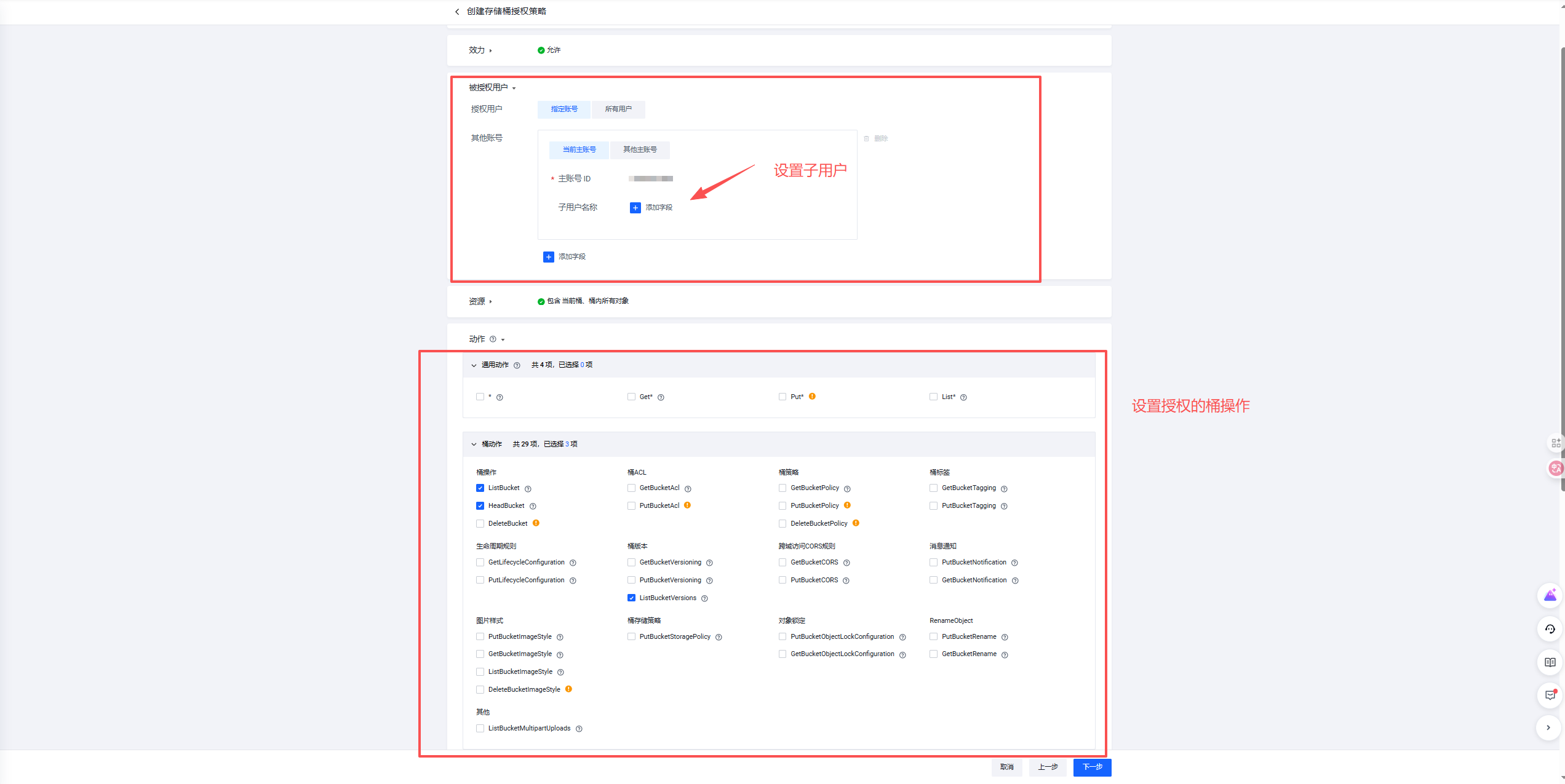
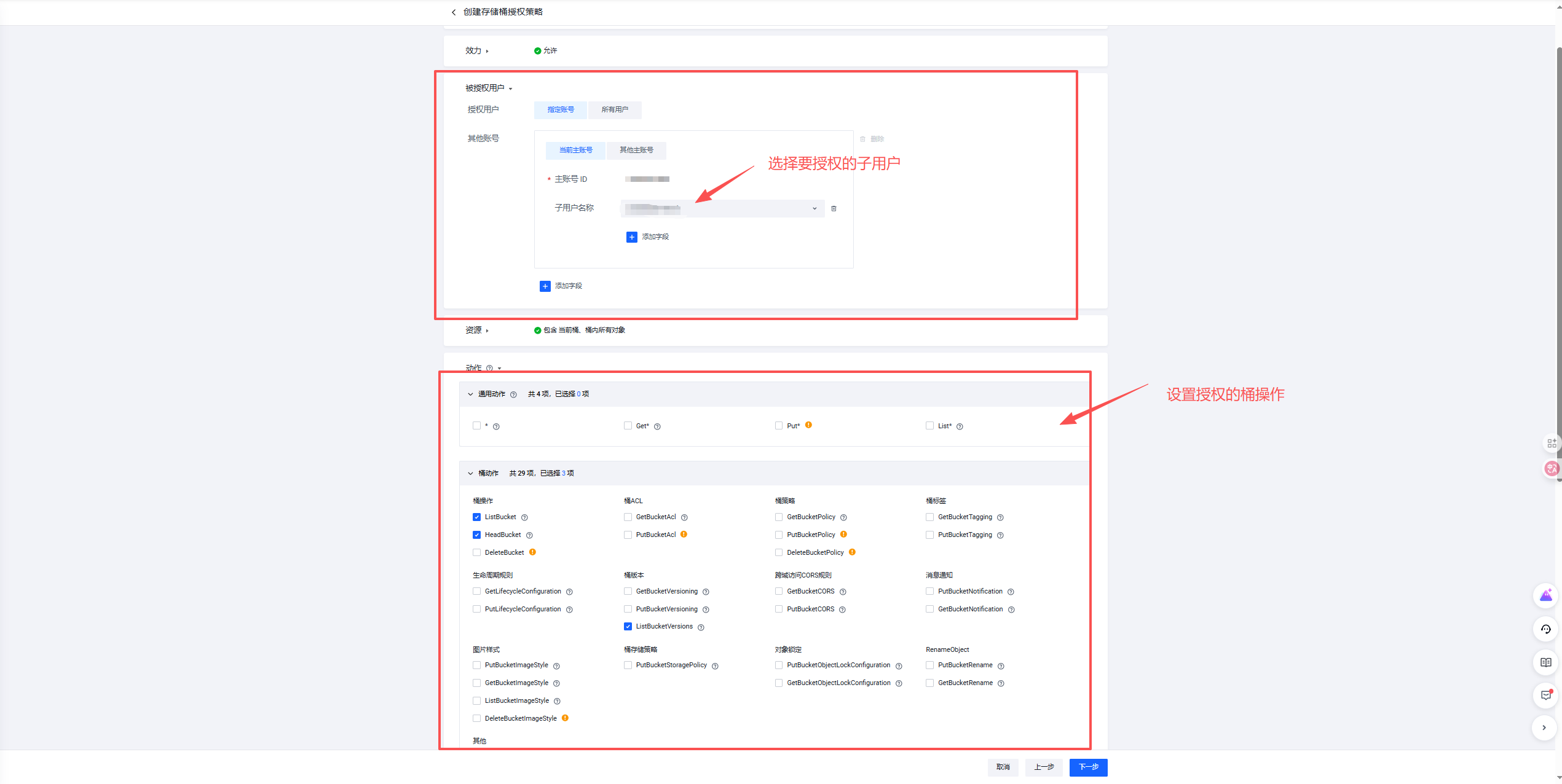
2.7.2 IAM 权限和桶权限的关系
Section titled “2.7.2 IAM 权限和桶权限的关系”
2.7.2.1 核心区别与重叠
Section titled “2.7.2.1 核心区别与重叠”为了更具体地理解,我们来看看两者的对比:
场景一:简单权限控制(within one account)
“我希望我创建的某个 IAM 用户只能读取 A 桶。”
- 方案 A (使用 IAM):在 IAM 中,给该用户附加一个策略,策略内容为对
arn:aws:s3:::bucket-A资源拥有s3:GetObject和s3:ListBucket权限。 - 方案 B (使用 Bucket Policy):在 A 桶的策略中,添加一条语句,允许该用户的 ARN 执行
s3:GetObject和s3:ListBucket。 - 结论:两种方案效果几乎一样,任选其一即可。通常更推荐使用 IAM 方案,因为权限集中在 IAM 控制台,更易于统一管理身份及其权限。
3. 功能效果
Section titled “3. 功能效果”冷启动定义:模型服务从零实例状态(缩放到 0)接收请求到准备处理第一个请求的时间间隔,是影响部署响应能力、服务等级协议(SLA)和成本控制的关键因素。为了优化冷启动,我们将介绍以下策略:对象存储加速,它通过提前将 S3 数据缓存到本地,从而提高性能。
性能提升显著
冷启动带来的挑战:
- 用户体验:首次请求响应时间长,影响用户满意度
- 成本控制:频繁冷启动导致资源浪费和成本增加
- 服务可用性:冷启动时间过长可能导致服务超时
S3 存储加速的优化策略:
- 预取机制:利用 JuiceFS 预取功能,后台线程提前下载模型权重和数据
- 分布式缓存:将模型权重缓存在分布式文件系统中,避免重复下载
- 智能预热:对高频访问的模型进行预热处理
部署方式 | 冷启动时间 | 性能提升 |
传统方式 | 数分钟(如 Stable Diffusion XL) | |
S3 加速 | 10 秒以内 | 提升 90% 以上 |
资源利用优化
- 读取加速:本地缓存机制提供接近本地磁盘的读取速度
- 并行下载:多线程并行下载,充分利用网络带宽
- 智能缓存:自动管理缓存空间,优先缓存高频访问数据
- 按需加载:仅在首次访问时从云端拉取数据,避免重复下载
- 空间复用:多个任务可共享同一份缓存数据,节省存储空间
4. 应用场景
Section titled “4. 应用场景”4.1. 模型版本管理与无停机更新
Section titled “4.1. 模型版本管理与无停机更新”在生产环境中,AI 模型需要频繁更新迭代,传统方式需要重新构建和发布 Docker 镜像,过程繁琐且耗时。
S3 存储加速解决方案:
- 解耦模型与镜像:将模型文件存储在 S3 中,Docker 镜像只包含运行环境,实现模型与代码的分离
- 快速模型切换:通过更新 S3 中的模型文件,无需重建镜像即可完成模型更新
- A/B 测试:可同时挂载多个模型版本,方便进行对比测试
实际效果:
- 模型更新时间:从数小时缩短至几分钟
- 运维效率:提升 80% 以上
4.2. 弹性扩容与负载均衡
Section titled “4.2. 弹性扩容与负载均衡”在业务高峰期或突发流量场景下,需要快速扩容计算节点以应对负载增长。
S3 存储加速解决方案:
- 快速节点启动:新扩容的节点可直接使用缓存的模型数据,避免重复下载
- 智能缓存预热:新节点启动时自动预热常用模型,减少首次访问延迟
- 跨区域部署:支持在不同区域快速部署节点,提升服务覆盖范围
实际效果:
- 扩容时间:从传统的 10-30 分钟缩短至 1-3 分钟
- 资源利用率:提升 60% 以上
- 服务稳定性:显著提升,支持平滑扩缩容
5. 操作流程一览
Section titled “5. 操作流程一览”
6. 注意事项
Section titled “6. 注意事项”- 存储内容更新需手动点击”回源上游”按钮,不会自动同步。
- 存储加速仅支持只读访问,适合模型或数据文件的高效读取。
- 释放后的配置仍保留,可随时重新激活。