任务创建接口与多容器部署指南
1 任务创建接口
Section titled “1 任务创建接口”1.1 接口概述
Section titled “1.1 接口概述”任务创建接口是系统核心功能之一,用于创建和管理不同类型的计算任务。
接口参数文档位于:https://s.apifox.cn/6aa360d3-d8f2-471e-b841-3a35c33a7b7c/api-296881505
任务创建接口的资源信息需要通过”显卡资源查询接口”获取(mark 标识)(https://s.apifox.cn/6aa360d3-d8f2-471e-b841-3a35c33a7b7c/api-296881020)。如果使用了不存在的资源类型(mark 标识),尽管接口会返回成功,GUI 面板上也能看到任务被成功创建,但是因为实际资源不存在,任务无法匹配到 GPU,Pod 不会被分配,亦不会扣费。
services 数组目前仅支持定义单个 service,因而,建议 service_name 设置为和 task_name 相同。实例名称只能是小写字母开头的(大小写字母,数字,中横线)。
1.2 多任务类型支持
Section titled “1.2 多任务类型支持”接口现在支持两种主要的任务类型:
Job 任务:适用于一次性执行的任务,如批处理、数据处理、机器学习训练等场景。任务完成后 Pod 会自动终止,不会持续运行。
Deployment 任务:适用于长期运行的服务任务,如 Web 服务、API 服务、微服务等场景。支持自动重启、扩缩容和滚动更新。
2 配置示例
Section titled “2 配置示例”2.1 Job 任务示例
Section titled “2.1 Job 任务示例”apiVersion: batch/v1kind: Jobmetadata: creationTimestamp: null name: pispec: backoffLimit: 4 template: metadata: creationTimestamp: null spec: containers: - image: harbor.suanleme.cn/huang5876/jupyter-tf1.15-gpu:v3.0 name: pi resources: limits: cpu: 14000m nvidia.com/gpu: 1 memory: 51200Mi requests: cpu: 1166m nvidia.com/gpu: 1 memory: 2133Mi - image: harbor.suanleme.cn/library/cuda:debugv4 name: pi2 resources: limits: cpu: 9333m nvidia.com/gpu: 1 memory: 4200Mi requests: cpu: 2333m nvidia.com/gpu: 1 memory: 10666Mi restartPolicy: Neverstatus: {}2.2 多容器 Deployment 任务示例
Section titled “2.2 多容器 Deployment 任务示例”apiVersion: apps/v1kind: Deploymentmetadata: creationTimestamp: null labels: app: d09231749-test11-12-pa5gknnq gongjiyun.com/task-type: deployment name: d09231749-test11-12-pa5gknnq namespace: noxx7nxtak81hbk0lqbwsdv5etbjh8ei-12spec: replicas: 1 selector: matchLabels: app: d09231749-test11-12-pa5gknnq strategy: {} template: metadata: annotations: proxy.istio.io/config: | drainDuration: 120s terminationDrainDuration: "120s" holdApplicationUntilProxyStarts: true quota.k8s.io/enabled: 'true' quota.k8s.io/ephemeral-storage: 50Gi quota.k8s.io/project-id: auto sidecar.istio.io/rewriteAppHTTPProbers: 'false' creationTimestamp: null labels: app: d09231749-test11-12-pa5gknnq gongjiyun.com/task-type: deployment spec: affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - preference: matchExpressions: - key: kubernetes.io/role operator: In values: - node weight: 80 - preference: matchExpressions: - key: gongjiyun.com/can-be-used-develop operator: NotIn values: - 'true' weight: 20 requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: nvidia.com/gpu.product operator: In values: - NVIDIA-GeForce-RTX-4090 containers: - image: harbor.suanleme.cn/library/fluentd:1.81 lifecycle: preStop: exec: command: - sleep - '120' name: d1758620954106-62013-container1 ports: - containerPort: 7860 resources: limits: cpu: '28' memory: 100Gi nvidia.com/gpu: '1' requests: cpu: '7' memory: 25Gi volumeMounts: - mountPath: /data name: gjs3-00 - mountPath: /dev/shm name: gj-shm-d09231749-test11-12-pa5gknnq - image: harbor.suanleme.cn/library/nginx:v1.20 lifecycle: preStop: exec: command: - sleep - '120' name: d1758620954106-62013-container2 ports: - containerPort: 80 resources: limits: cpu: '28' memory: 1000Gi nvidia.com/gpu: '1' requests: cpu: '7' memory: 25Gi volumeMounts: - mountPath: /data name: gjs3-00 - mountPath: /dev/shm name: gj-shm-d09231749-test11-12-pa5gknnq priorityClassName: default-pc schedulerName: requested-to-capacity-ratio-custom-scheduler volumes: - name: gjs3-00 persistentVolumeClaim: claimName: s3-12-47177-dataset - emptyDir: medium: Memory sizeLimit: 80Mi name: gj-shm-d09231749-test11-12-pa5gknnqstatus: {}3 多容器部署资源分配算法
Section titled “3 多容器部署资源分配算法”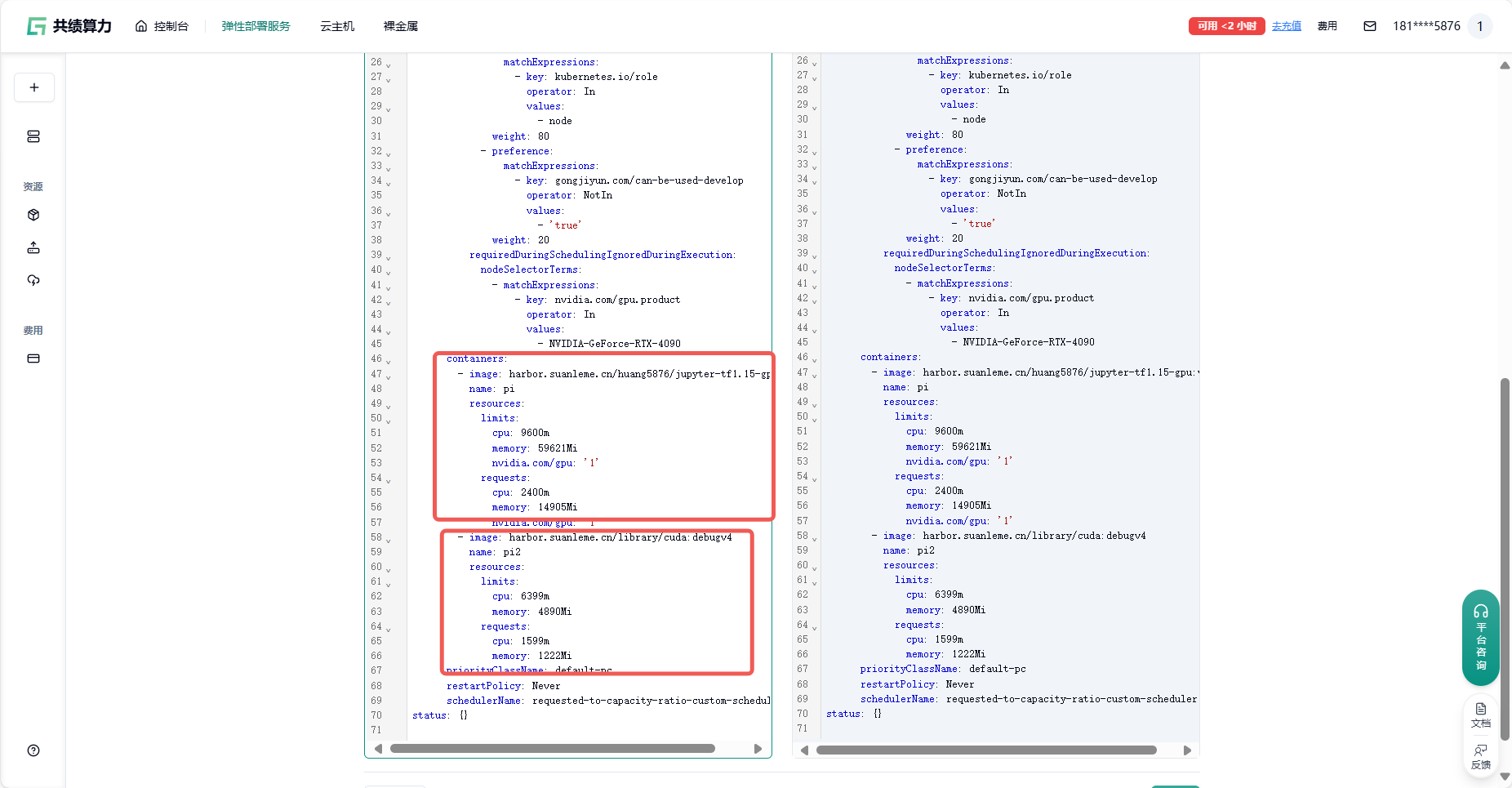
3.1 CPU 资源分配机制
Section titled “3.1 CPU 资源分配机制”在多容器部署场景中,系统采用加权平均算法进行 CPU 资源分配。该算法确保每个容器按照其配置比例获得相应的 CPU 资源。
算法实现过程如下:首先计算所有容器的 CPU 配置总和,然后根据每个容器的配置占比,将实际机器的 CPU 核心数按比例分配给各个容器。例如,当第一个容器配置 14,000 微核,第二个容器配置 9,333 微核时,总和为 23,333 微核。
在实际分配过程中,假设选择 4090 卡(20 核)作为目标机器,系统会计算第一个容器的分配比例:14,000 ÷ 23,333 ≈ 60%,因此第一个容器将获得 20 核 × 60% = 12 核的 CPU 资源。
3.2 内存资源分配机制
Section titled “3.2 内存资源分配机制”内存分配采用总量计算和比例分配相结合的策略。系统首先汇总所有容器的内存配置需求,然后按照各容器的内存配置比例进行资源分配。
具体分配流程如下:以第一个容器内存配置 51,200 兆,第二个容器配置 4,200 兆为例,系统计算出总内存需求为 55,400 兆。随后,系统根据第一个容器的内存配置占比(51,200 ÷ 55,400 ≈ 92%)将目标机器的内存资源进行分配,假设目标机器内存为 101 G,则第一个容器将获得 101 G × 92% ≈ 93 G 的内存资源。
3.3 GPU 资源分配策略
Section titled “3.3 GPU 资源分配策略”GPU 资源分配采用优先级分配策略,确保关键任务能够优先获得 GPU 资源支持。
分配规则如下:当选择单 GPU 配置时,系统优先将 GPU 资源分配给第一个容器;当选择多 GPU 配置时,系统会为所有容器分配 GPU 资源。这种策略确保了资源分配的公平性和效率。
在资源请求计算方面,系统采用统一的规则:计算完 limit 值后,request 值设置为 limit 除以 4,这种配置方式既保证了资源的有效利用,又避免了资源过度预留。
4 任务类型与限制说明
Section titled “4 任务类型与限制说明”4.1 Job 任务特性与限制
Section titled “4.1 Job 任务特性与限制”Job 任务适用于一次性执行的批处理任务,如数据处理、模型训练等场景。任务完成后 Pod 会自动终止,不会持续占用资源。
Job 任务创建成功后具有以下特性:任务名称可以随时修改,支持任务暂停和重启功能,为用户提供了基本的任务管理能力。然而,Job 任务在创建后存在诸多不可修改的限制,包括高级设置、yaml 文件配置、共享内存设置、镜像地址、暴露端口配置以及节点数量等核心参数。
这些限制的存在主要基于 Job 任务的一次性执行特性,确保任务执行的稳定性和一致性。用户如需修改这些参数,需要重新创建任务实例。
4.2 Deployment 任务特性
Section titled “4.2 Deployment 任务特性”Deployment 任务适用于长期运行的服务场景,如 Web 服务、API 服务、微服务等。与 Job 任务相比,Deployment 任务具有更高的灵活性和可配置性。
Deployment 任务支持自动重启、扩缩容和滚动更新等高级功能,能够根据实际负载情况动态调整资源分配。更重要的是,Deployment 任务没有 Job 任务的那些修改限制,用户可以在任务运行过程中灵活调整各种配置参数,包括资源限制、端口配置、环境变量等。
这种灵活性使得 Deployment 任务特别适合需要持续运行和动态调整的服务场景,为用户提供了更加灵活的任务管理体验。