通过共享存储卷持久化模型缓存
当我们使用例如 Comfyui, vLLM, Ollama 等服务过程中常常有以下几个痛点。
- 多个服务中模型重复下载,重复储存。
- 启动过程拉取模型过慢。
- 服务重启后模型需要重复下载。
共享存储卷介绍
Section titled “共享存储卷介绍”共享存储卷是共绩算力自主研发的高性能云存储解决方案,采用独特的分布式存储技术,实现本地磁盘与云端存储的无缝对接。在模型缓存场景下我们利用了共享存储卷以下特性。
- 可直接挂载至容器指定目录下,读写可直接通过文件系统实现。
- 容器销毁后数据不丢失,重新启动后无需重新拉取。
- 文件可在同集群多个服务容器之间复用。
- 跨集群自动同步,减少人工操作。
我们以 vLLM 为例
1.确认缓存目录
Section titled “1.确认缓存目录”vLLM 通常把模型缓存在 ~/.cache/huggingface/ 下,若是设置了 VLLM_USE_MODELSCOPE=True 模型会缓存在 ~/.cache/modelscope/下。除了模型外我们也可以缓存 vLLM 生成的 Compile Time Cache.
因此我们可以直接缓存整个目录 ~/.cache/,这样我们在容器启动过程中就无需重复编译。
Compile Time Cache 只能在架构相同的 GPU 上共享
2.新建共享存储卷
Section titled “2.新建共享存储卷”具体的操作我们可以参考 https://www.gongjiyun.com/docs/server/jojuw4rfdiepfxkchonctw0jnxe/yvawwrzvcivbypk8vihcgjrkn8c/
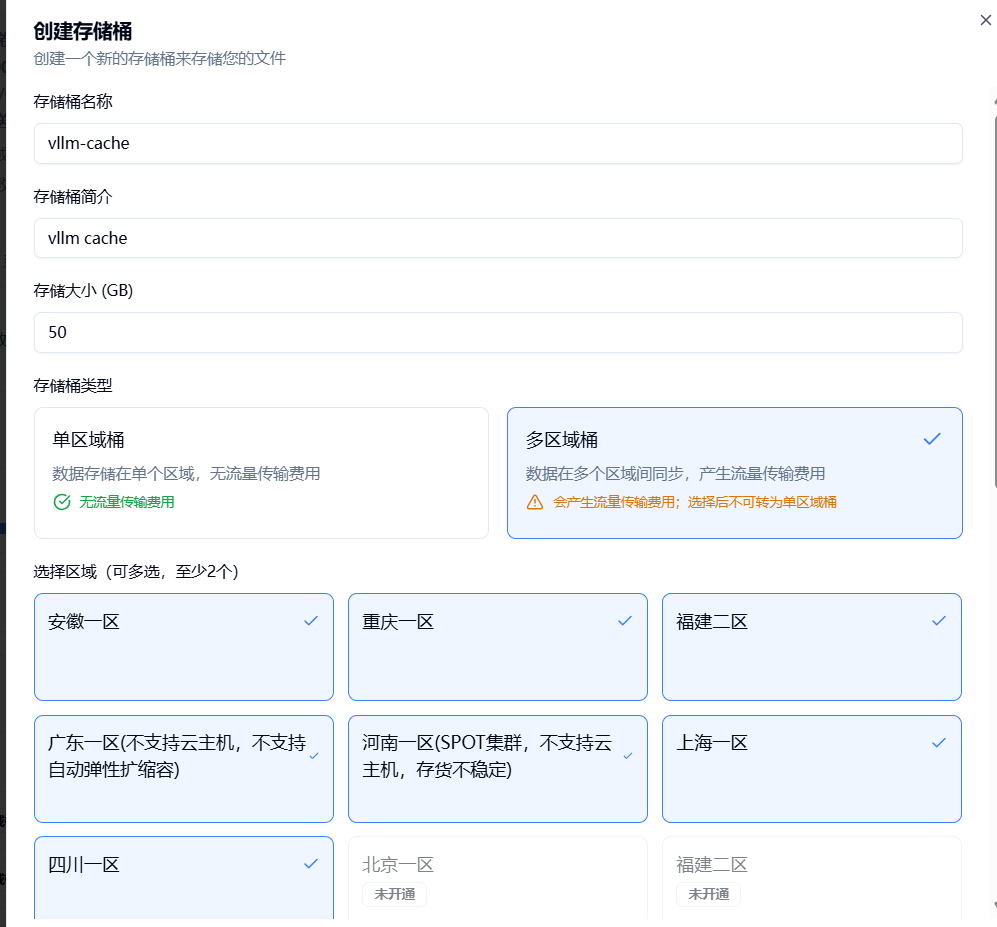
建议根据自己的实际需求。新建存储桶。
存储桶大小必须大于模型文件大小而且留有余量。
区域必须与业务容器所在区域对应。
3.挂载到业务容器
Section titled “3.挂载到业务容器”创建完成后我们可以在对应任务下方设置挂载共享存储卷。
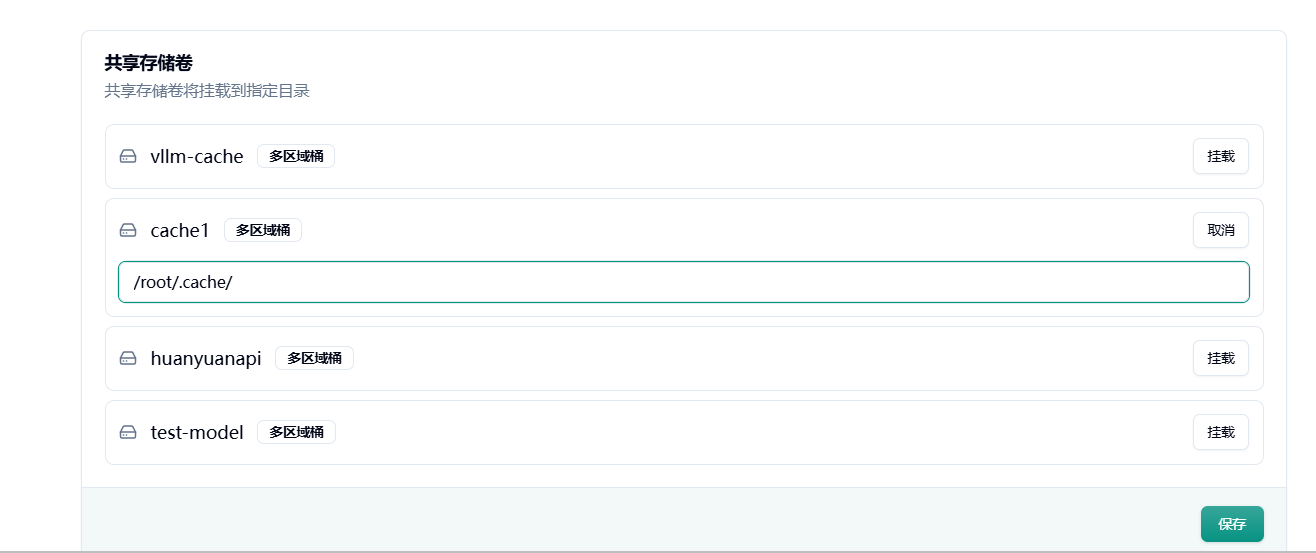
建议在首次启动前挂载,首次启动 vLLM 仍会下载模型,下载完成后再次启动或者其他容器即可重复利用缓存。
不要出现多个容器同时下载模型的情况。
4.效果验证
Section titled “4.效果验证”我们建立一个 vLLM 的自定义服务如下:
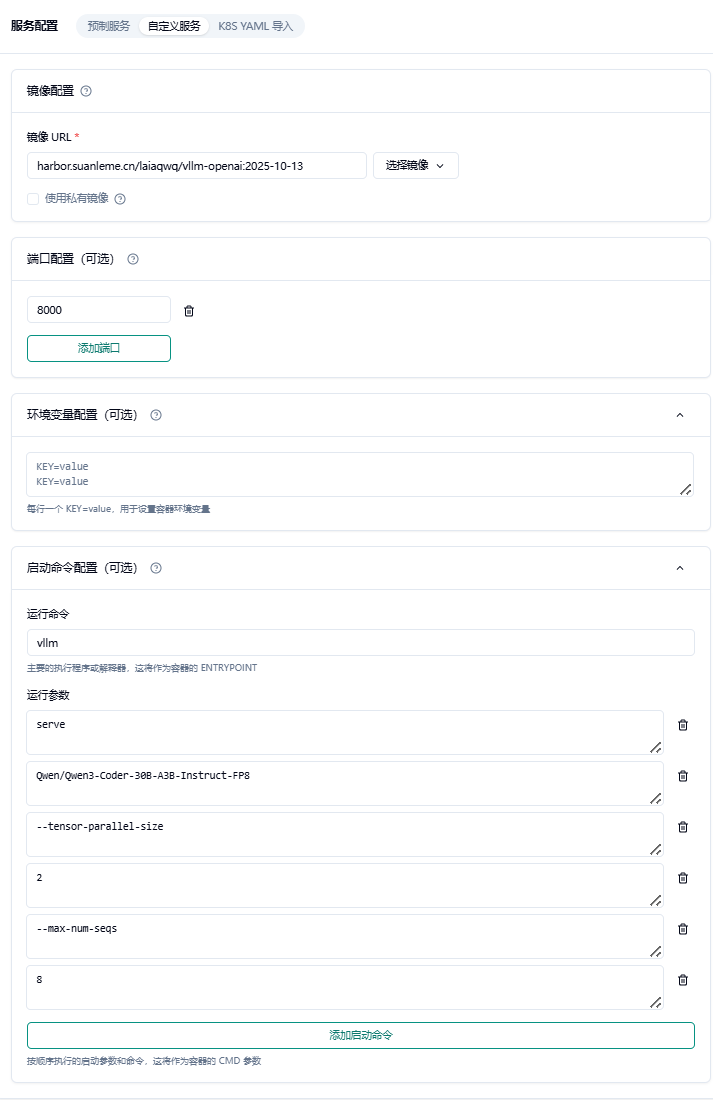
镜像 URL = harbor.suanleme.cn/laiaqwq/vllm-openai:2025-10-13
端口配置 = 8000
启动命令 = vllm
启动参数 =
serve
Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8
—tensor-parallel-size
2
—max-num-seqs
8
—max_model_len
32K
挂载共享存储卷

启动服务
挂载存储卷后,模型首次下载,将保存在共享存储卷内。
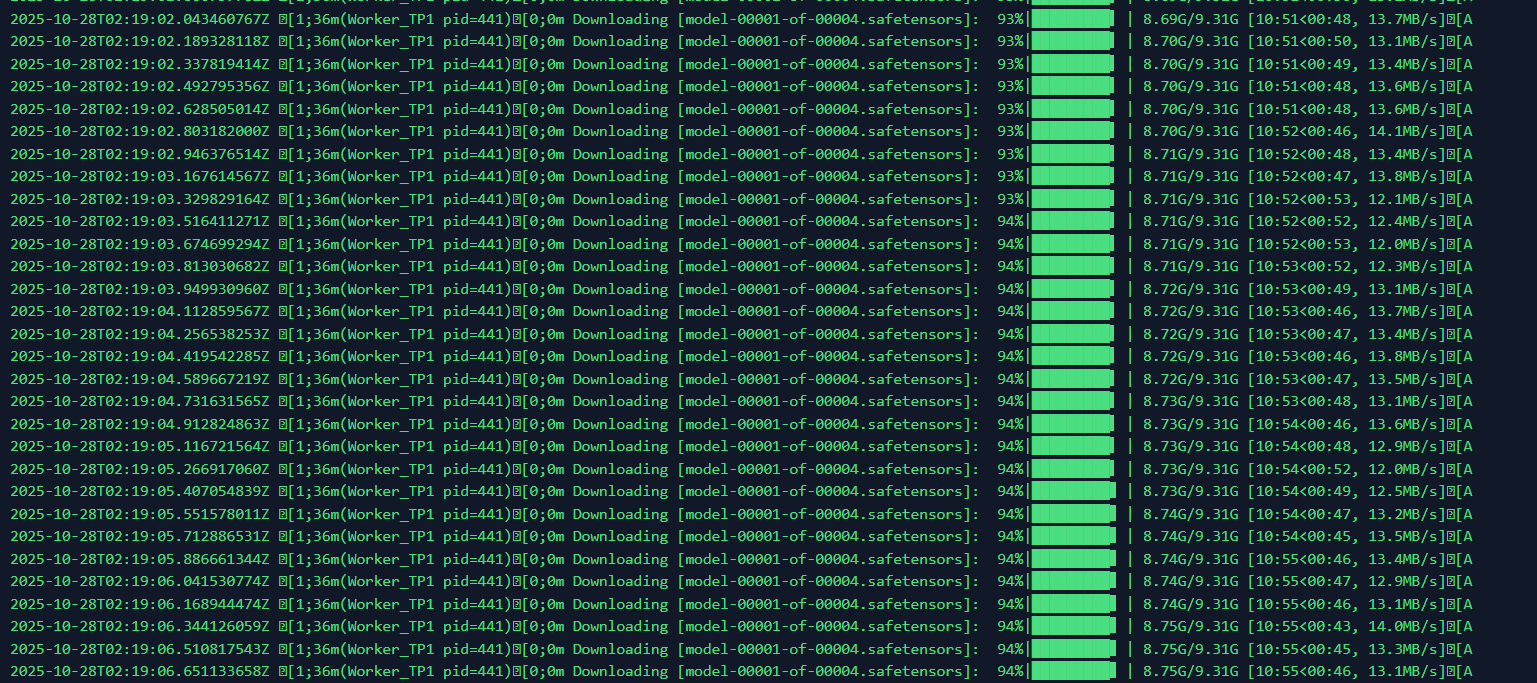
而在第二次启动过程中,模型可直接从共享存储卷加载。
2025-10-28T02:46:46.057044894Z [1;36m(Worker_TP0 pid=290)[0;0mLoading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]2025-10-28T02:46:48.780100908Z [1;36m(Worker_TP0 pid=290)[0;0mLoading safetensors checkpoint shards: 25% Completed | 1/4 [00:02<00:08, 2.72s/it]2025-10-28T02:46:52.630730526Z [1;36m(Worker_TP0 pid=290)[0;0mLoading safetensors checkpoint shards: 50% Completed | 2/4 [00:06<00:06, 3.39s/it]2025-10-28T02:46:55.682877231Z [1;36m(Worker_TP0 pid=290)[0;0mLoading safetensors checkpoint shards: 75% Completed | 3/4 [00:09<00:03, 3.23s/it]2025-10-28T02:46:56.240727472Z [1;36m(Worker_TP0 pid=290)[0;0mLoading safetensors checkpoint shards: 100% Completed | 4/4 [00:10<00:00, 2.18s/it]2025-10-28T02:46:56.240787500Z [1;36m(Worker_TP0 pid=290)[0;0mLoading safetensors checkpoint shards: 100% Completed | 4/4 [00:10<00:00, 2.55s/it]对于一个 30GB 的模型加载只需要不到 20 秒。接近直接从本机加载。