如何使用自动弹性扩缩容
1. 功能概述
Section titled “1. 功能概述”弹性扩缩容是共绩算力平台的核心功能,能够根据任务队列状态和资源使用情况自动调整计算实例数量,在保证用户体验的同时优化成本效率。通过智能监控,系统可以自动扩容应对高负载,在负载降低时自动缩容节省成本。
2. 功能优势
Section titled “2. 功能优势”- 成本优化
- 性能保障
- 操作简便
3. 使用流程
Section titled “3. 使用流程”3.1 参数设置建议
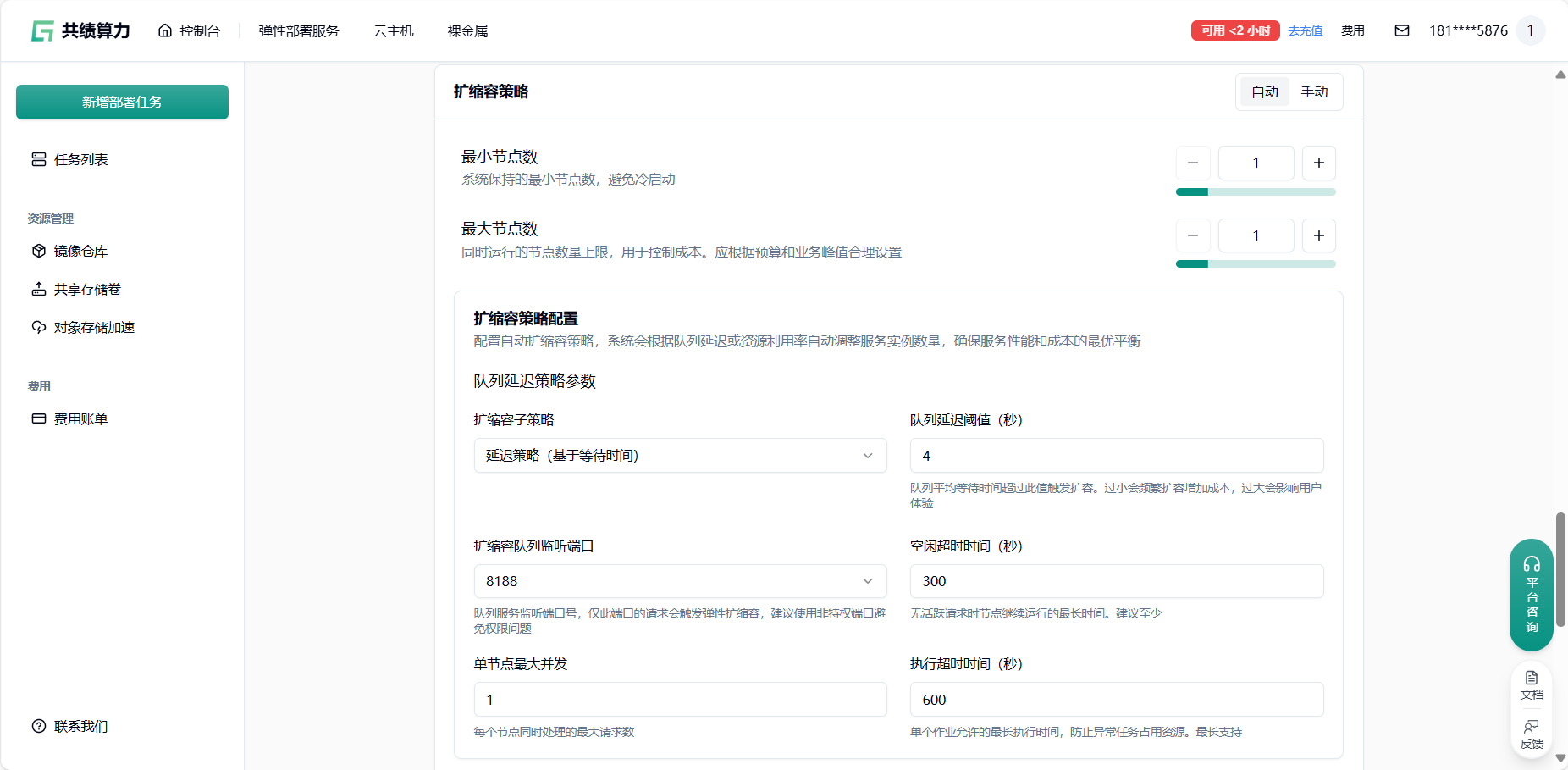
Section titled “3.1 参数设置建议”最小节点数:建议设置为 1,避免冷启动影响。如果业务对响应时间要求极高,可以适当增加。
最大节点数:根据预算和业务峰值合理设置。建议先从小值开始,观察实际使用情况后逐步调整。
队列延迟阈值:建议设置为 4-10 秒,平衡成本和体验。对于实时性要求高的任务,可以设置较小值。
空闲超时时间:建议设置为 300-600 秒,减少冷启动影响的同时控制成本。
3.2 创建任务时配置
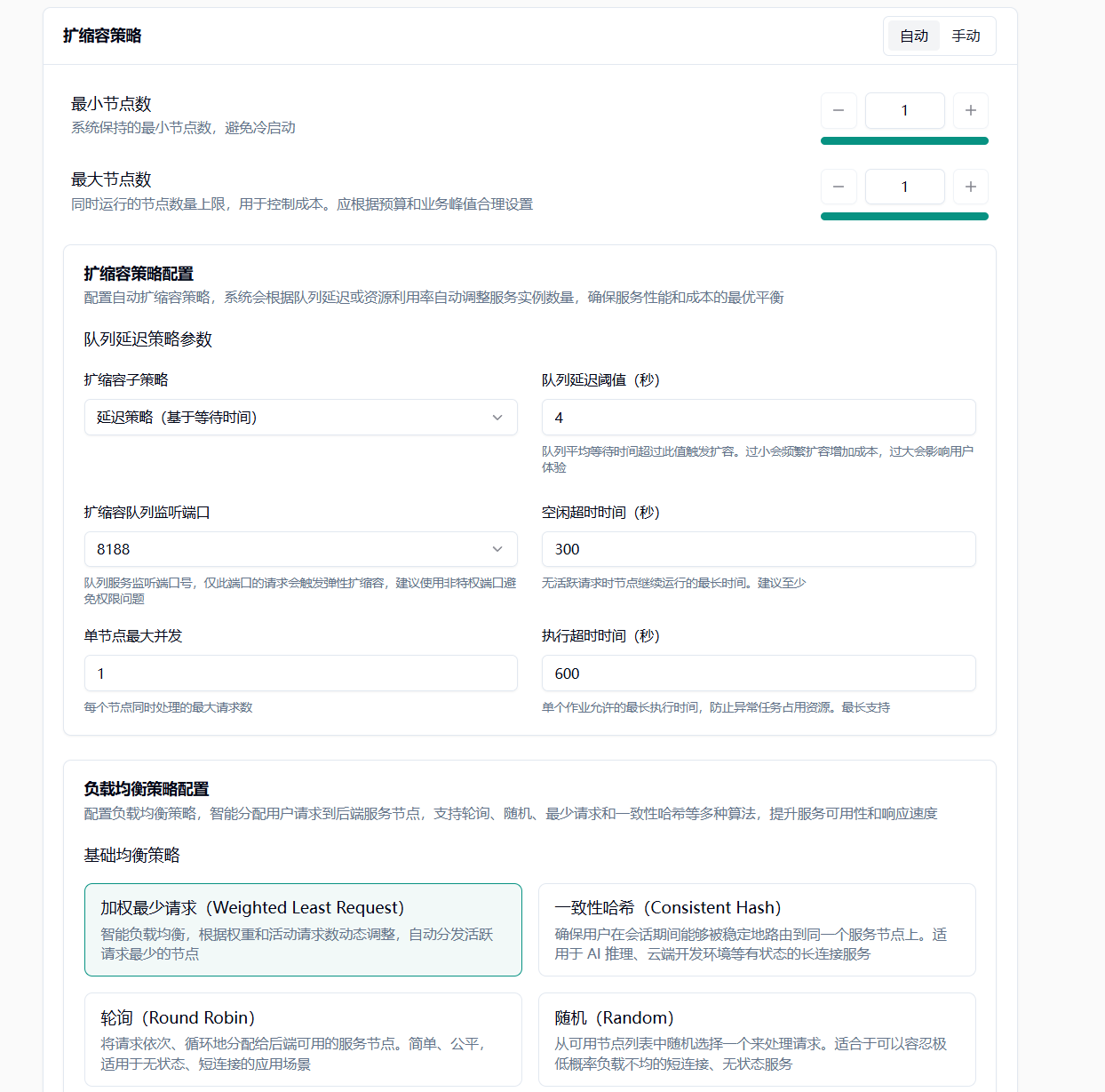
Section titled “3.2 创建任务时配置”在 弹性部署服务 任务创建页面,您可以在「扩缩容策略」配置模块中设置扩缩容策略。系统提供两种主要策略供您选择:延迟策略(基于等待时间)和计数策略(基于排队数量)。
3.3 任务运行中调整
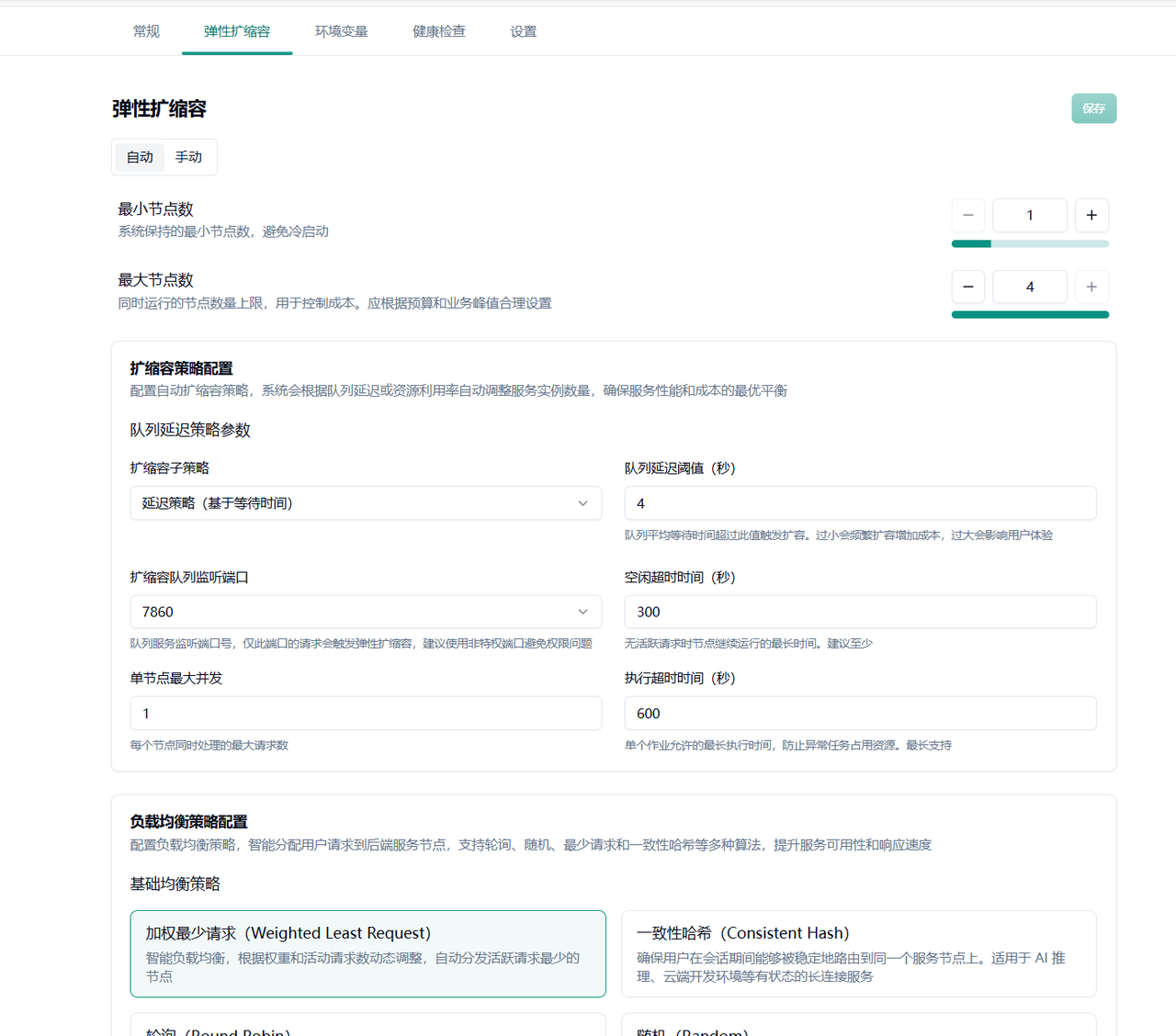
Section titled “3.3 任务运行中调整”任务创建后,您可以在任务详情页面通过「修改扩缩容策略」入口动态调整策略参数,无需重启任务即可生效。
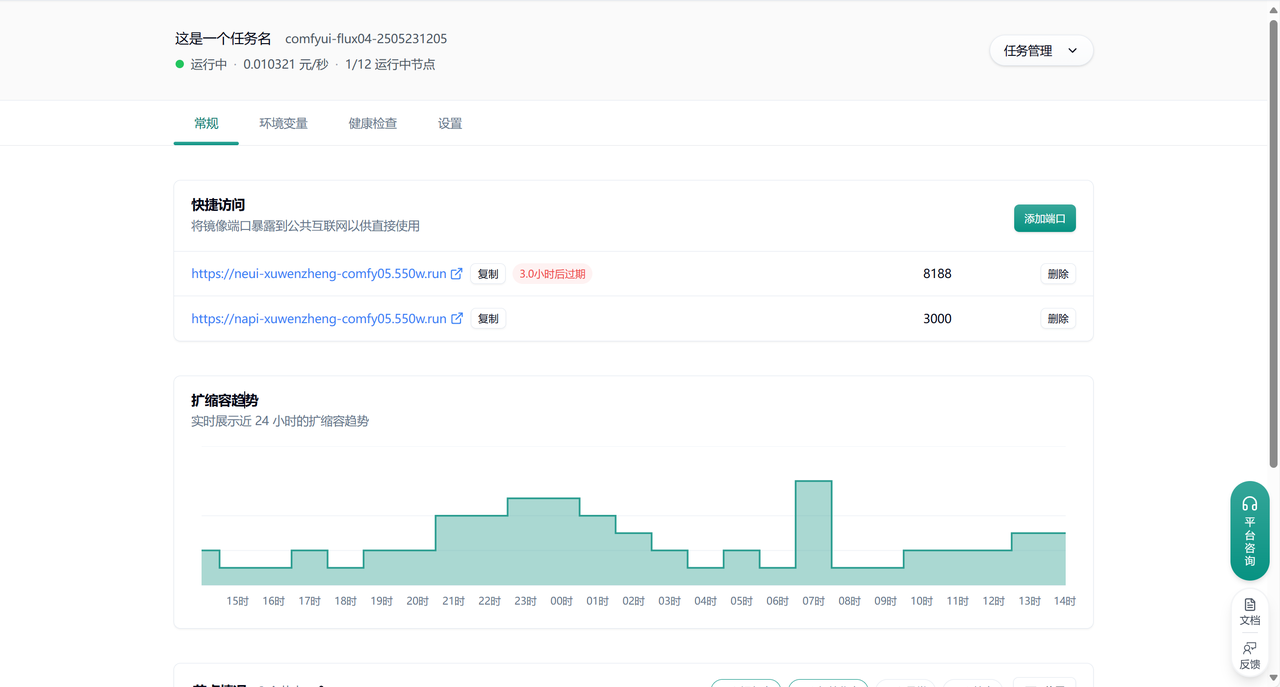
3.4 实时监控
Section titled “3.4 实时监控”系统提供 24 小时扩缩容趋势图表,以半小时为颗粒度展示节点数量变化,帮助您了解资源使用情况。
4. 策略配置详解
Section titled “4. 策略配置详解”4.1 延迟策略(基于等待时间)
Section titled “4.1 延迟策略(基于等待时间)”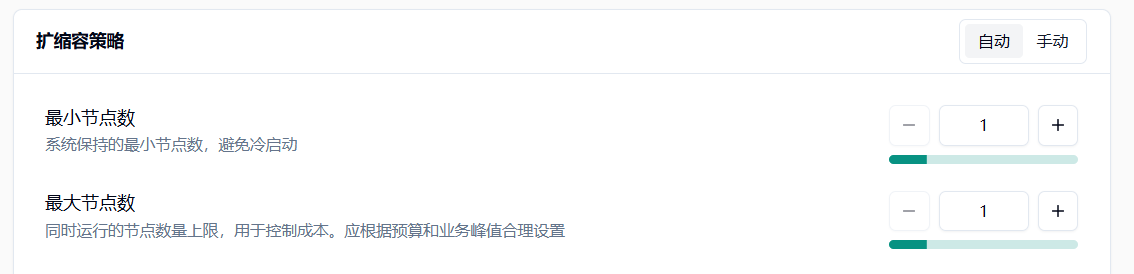
队列延迟策略基于任务队列的等待时间进行扩缩容决策,适合大多数 AI 推理和批处理任务场景。
4.1.1 基本参数配置
Section titled “4.1.1 基本参数配置”最小节点数:系统保持的最小节点数量,建议设置为 1,避免冷启动影响。默认值:1,最小值:1,最大值:租户剩余可用 Pod 数。
最大节点数:自动扩容的节点数量上限,用于控制成本。应根据预算和业务峰值合理设置,不能小于最小节点数。默认值:10,最小值:1,最大值:租户剩余可用 Pod 数。
4.1.2 队列延迟策略专用参数
Section titled “4.1.2 队列延迟策略专用参数”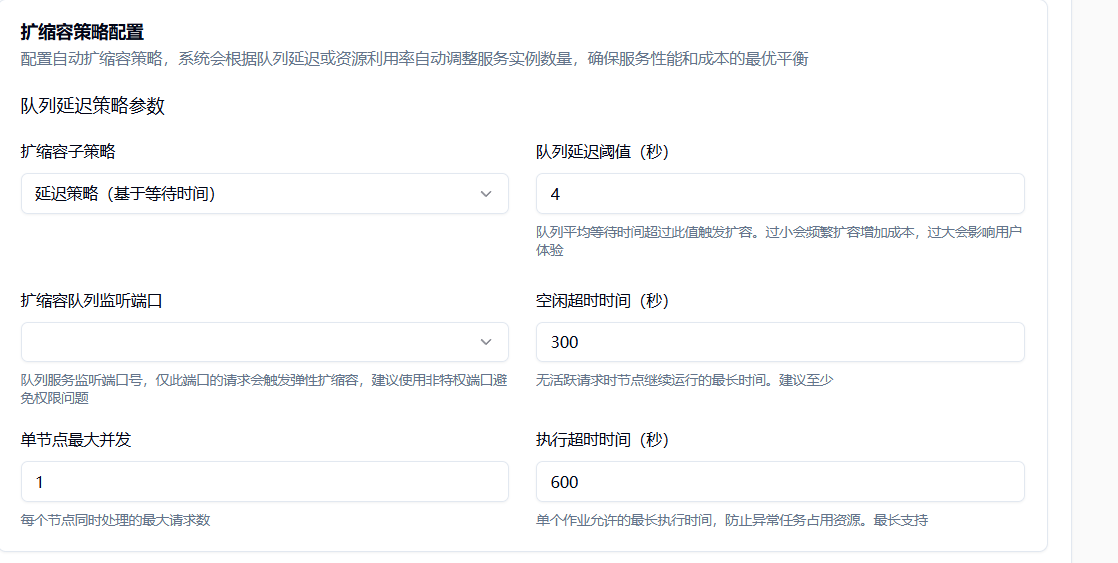
队列延迟阈值:队列平均等待时间超过此值触发扩容。过小会频繁扩容增加成本,过大会影响用户体验。最小值:1 秒。
队列监听端口:队列服务监听端口号,用于接收任务请求。建议使用非特权端口避免权限问题。范围:1-65535。
空闲超时时间:无活跃请求时节点继续运行的最长时间。过短会增加冷启动,过长会增加成本。默认值:300 秒,最小值:1 秒。
单节点最大并发:每个节点同时处理的最大请求数。默认值:1,最小值:1。
执行超时时间:单个作业允许的最长执行时间,防止异常任务占用资源。默认值:600 秒,最小值:30 秒,最大值:86400 秒(24 小时)。
4.2 计数策略(基于排队数量)
Section titled “4.2 计数策略(基于排队数量)”
请求计数阈值:队列等待请求数超过此值触发扩容,适用于请求计数策略。最小值:1。
队列监听端口:队列服务监听端口号,用于接收任务请求。建议使用非特权端口避免权限问题。范围:1-65535。
空闲超时时间:无活跃请求时节点继续运行的最长时间。过短会增加冷启动,过长会增加成本。默认值:300 秒,最小值:1 秒。
单节点最大并发:每个节点同时处理的最大请求数。默认值:1,最小值:1。
执行超时时间:单个作业允许的最长执行时间,防止异常任务占用资源。默认值:600 秒,最小值:30 秒,最大值:86400 秒(24 小时)。
5. 负载均衡策略
Section titled “5. 负载均衡策略”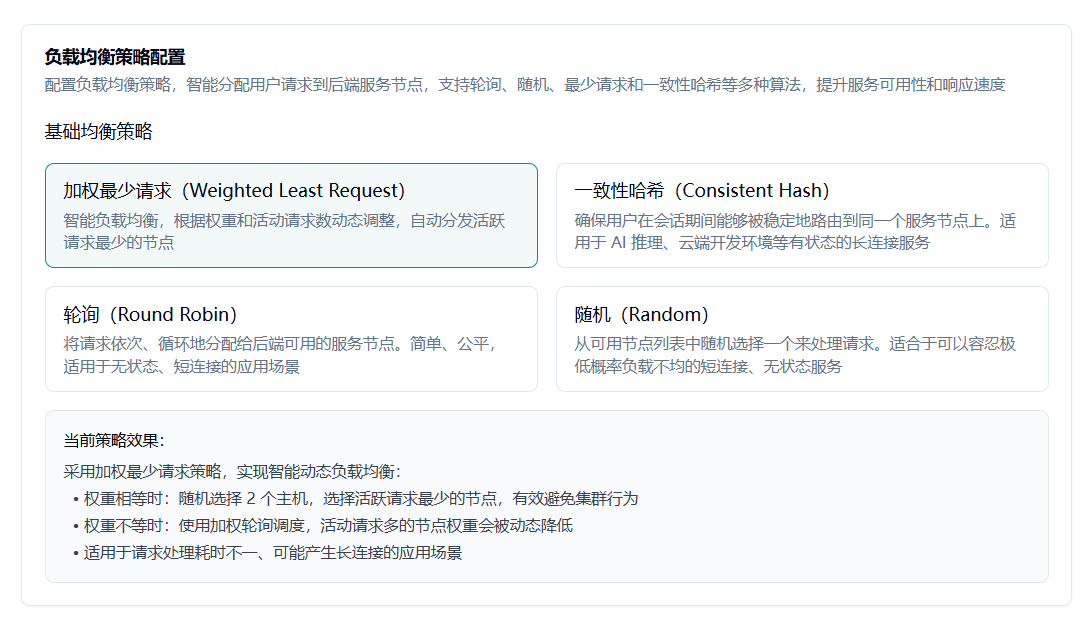
5.1 默认策略:加权最少请求
Section titled “5.1 默认策略:加权最少请求”调度中心像个人事主管,手里实时记着每台节点“正在干的活”和“本事值(权重)”。新人请求进门,它先筛掉请病假的,再把剩下的人按“当前工作量”排队;谁活最少、且本事大,就第一时间把新活塞过去。节点只要定期回一句“我还活着、现在忙 N 个”,就能被公平又高效地“能者多劳”。
5.2 一致性哈希策略
Section titled “5.2 一致性哈希策略”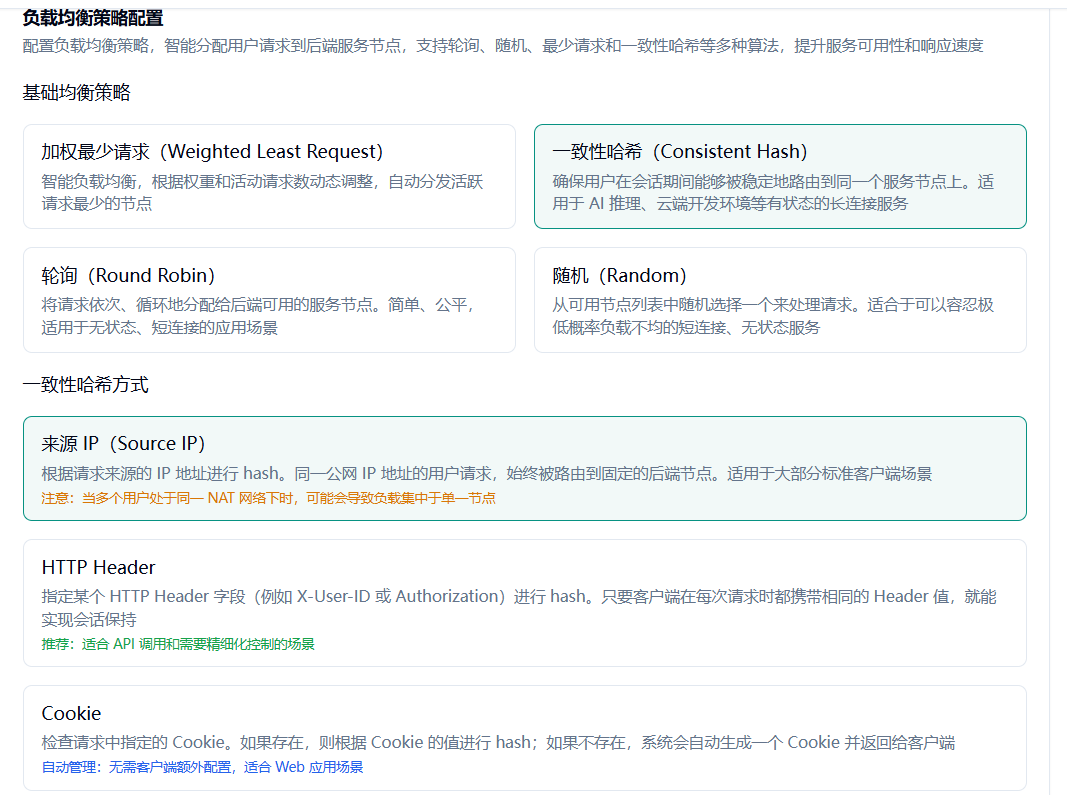
调度中心化身“指纹管理员”,把用户 IP 或 Header、Cookie 做成指纹,在一条首尾相接的哈希环上找对应位置,然后顺时针把用户“钉”到第一个遇见的健康节点。只要指纹不变,用户每次来都被领到老位置;节点宕机,环缺一块,指纹顺势滑到隔壁,其余人原地不动。节点这边基本无感,只需保证自己重启后如果环位变化能尽快重新加载状态即可。
5.2.1 来源 IP 策略
Section titled “5.2.1 来源 IP 策略”根据请求来源的 IP 地址进行 hash。同一公网 IP 地址的用户请求,始终被路由到固定的后端节点。适用于大部分标准客户端场景。
5.2.2 HTTP Header 策略
Section titled “5.2.2 HTTP Header 策略”可以指定某个 HTTP Header 字段(例如 X-User-ID 或 Authorization)进行 hash。只要客户端在每次请求时都携带相同的 Header 值,就能实现会话保持。适合 API 调用和需要精细化控制的场景。
5.2.3 Cookie 策略
Section titled “5.2.3 Cookie 策略”当采用此策略时,网关会检查请求中是否携带了指定的 Cookie。如果存在,则根据 Cookie 的值进行 hash;如果不存在,系统会自动为该请求生成一个 Cookie 并通过 Set-Cookie 响应头返回给客户端。
5.3 其他均衡策略
Section titled “5.3 其他均衡策略”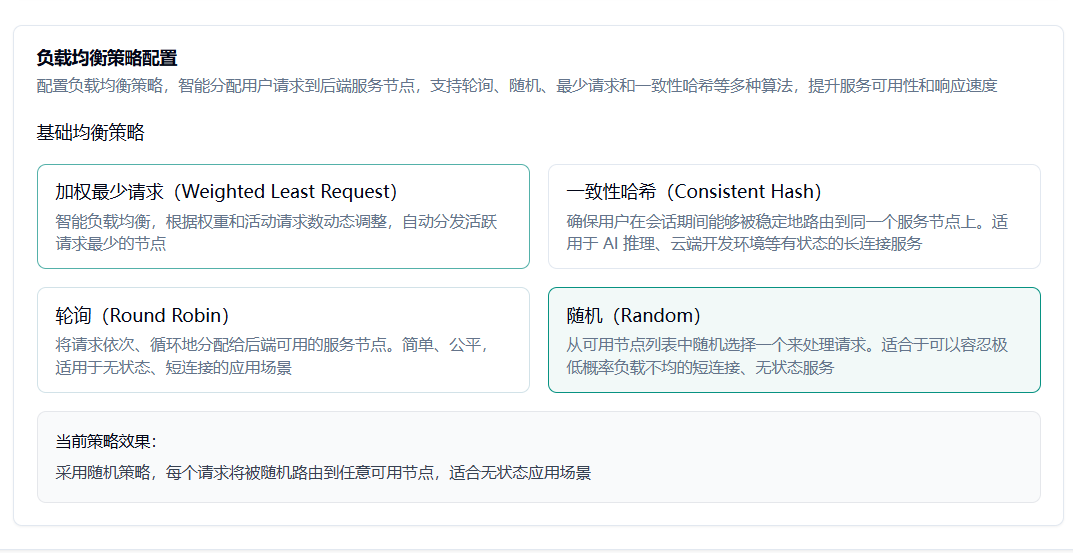
随机策略:调度中心当起“骰子庄家”:把所有在岗节点写进名单,新请求进门就掷一次随机数,指到谁便把活甩给谁。节点完全不用汇报工作量,只要保持“我活着”心跳,就有被点中的机会;长期来看大家被抽中的概率趋于平均,简单快速,适合短平快的小任务。
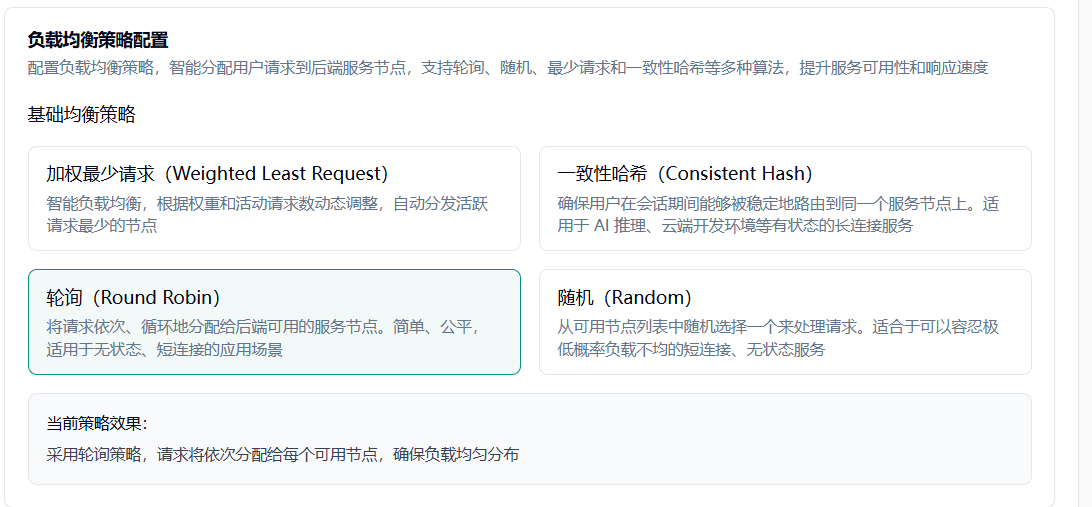
轮询策略:调度中心变成“顺序叫号机”,维护一根“上次轮到谁”的指针。请求一来,指针往后移一格,点到谁就给谁,走到名单末尾再折回开头。节点依旧只需报心跳,调度逻辑零计算、零状态,保证每人严格一人一个,公平得肉眼可见,最宜无状态、耗时相近的短连接场景。
6. 异常处理机制
Section titled “6. 异常处理机制”异常处理后会通过站内信和短信形式通知用户
6.1 扩容失败处理
Section titled “6.1 扩容失败处理”当扩容失败时,系统会根据失败原因采取不同的处理策略:
资源不足:当平台侧资源暂时不足时,系统会保持当前集群规模,尽力处理现有请求,并将溢出任务置于等待队列,避免反复尝试。
配额限制:当扩容请求将导致用户总节点数超过配额限制时,系统会立即停止针对该任务的扩容操作,避免无限重试。系统会通过站内信和短信通知用户具体原因。
6.2 缩容失败处理
Section titled “6.2 缩容失败处理”当节点无法被系统正常释放时,系统会在几次短暂的释放尝试后,将该节点隔离,不再向其分配新任务,并对此类「待释放」节点免除费用。系统会清晰地告知用户平台正在处理资源回收问题。
6.3 其他异常处理
Section titled “6.3 其他异常处理”当系统无法获取监控数据时,系统会通过站内信和短信通知用户,并锁定当前节点数量,暂停所有自动伸缩行为,避免无限重试。
7. 通知机制
Section titled “7. 通知机制”7.1 扩容失败通知
Section titled “7.1 扩容失败通知”资源不足通知:
站内信:任务扩容失败通知,说明当前任务所选区域资源暂时不足,扩容操作已自动停止
短信:【共绩算力】集群扩容失败,当前地域资源不足。系统已暂停扩容,请稍后重试
7.2 缩容失败通知
Section titled “7.2 缩容失败通知”站内信:节点释放异常处理通知,说明检测到节点释放异常,相关节点已被隔离并暂停计费
短信:【共绩算力】节点释放异常,已暂停计费并隔离问题节点
7.3 其他异常通知
Section titled “7.3 其他异常通知”站内信:自动扩缩容异常通知,说明发生未知异常,已暂停自动扩缩容,任务仍然正常运行
短信:【共绩算力】自动扩缩容发生未知异常,已暂停自动扩缩容,任务仍然正常运行
8. 常见问题解答
Section titled “8. 常见问题解答”8.1 为什么扩容失败?
Section titled “8.1 为什么扩容失败?”扩容失败通常是由于资源不足或配额限制。请检查当前地域资源情况,或联系客服了解配额使用情况。
8.2 如何选择合适的扩缩容策略?
Section titled “8.2 如何选择合适的扩缩容策略?”对于大多数 AI 推理和批处理任务,建议使用队列延迟策略。对于对资源使用有精确控制需求的场景,可以选择资源利用率策略。
8.3 如何优化成本?
Section titled “8.3 如何优化成本?”合理设置最大节点数和空闲超时时间,定期监控资源使用情况,根据实际需求调整配置参数。
8.4 如何确保任务稳定性?
Section titled “8.4 如何确保任务稳定性?”建议设置合适的最小节点数,避免冷启动影响。同时关注异常通知,及时处理相关问题。