快速上手云主机服务
数据安全必读
Section titled “数据安全必读”系统盘与数据盘均为本地 SSD,无冗余机制,属于单点故障架构,一旦硬件损坏将可能导致数据永久丢失。
重要说明:
- 本地盘仅适合运行环境与临时数据
- 重要数据必须实时备份
- 平台对本地盘损坏及数据丢失不承担责任
强制建议的数据安全方案: 将重要数据实时备份至「共享存储卷」或本地多副本存储系统。
立即开通共享存储卷(企业级冗余 + 跨区域同步): https://www.gongjiyun.com/docs/cloud-hosting/function-usage-instructions/yvawwrzvcivbypk8vihcgjrkn8c/
一、快速快速上手总览
Section titled “一、快速快速上手总览”流程目标:从 0 到可用云主机环境
完整流程分为三步:
- 使用基础镜像创建云主机
- 配置实例资源与存储
- 查看运行状态并进入使用
二、创建云主机(Step 1)
Section titled “二、创建云主机(Step 1)”2.1 进入云主机控制台
Section titled “2.1 进入云主机控制台”访问控制台并进入云主机页面: https://console-staging.suanli.cn/server
点击顶部【云主机】 → 进入云主机管理界面 → 选择可用设备资源
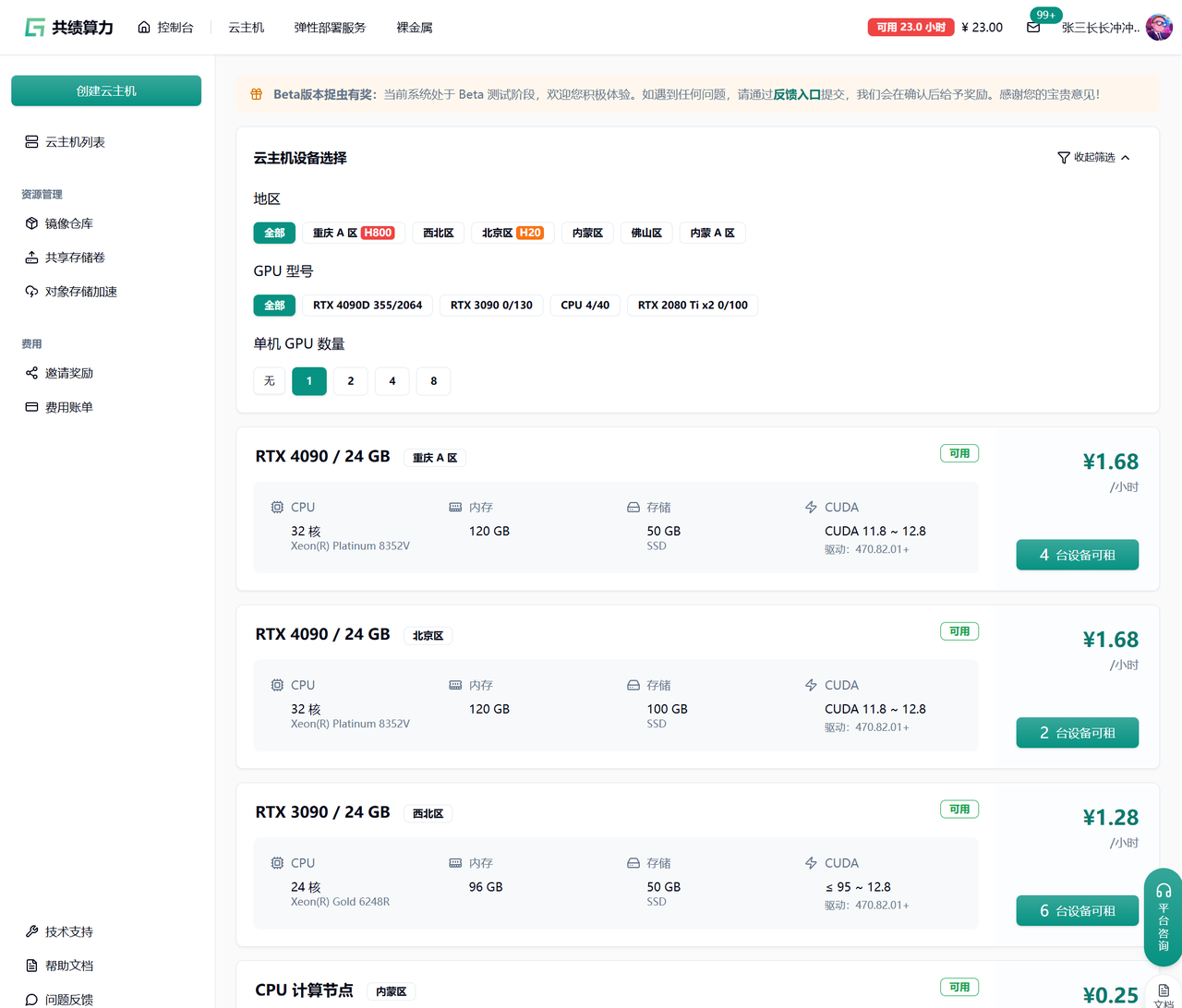
2.2 GPU 设备选择逻辑(简化决策模型)
Section titled “2.2 GPU 设备选择逻辑(简化决策模型)”当前图片中所有 GPU 型号均满足基础部署需求,选择逻辑如下:
- 单卡显存 ≥ 24GB
- 已远超大多数服务部署、推理任务、数据处理需求
- 无需担心显存不足问题
- 1 卡配置:低成本、按秒计费、适合开发/测试/推理
- 多卡配置:适用于训练任务、高并发、多模型场景
实际选择策略
Section titled “实际选择策略”- 常规任务(推理、服务部署、数据处理):1 卡足够
- 训练任务(LLM、多模态、大模型):再考虑 2 卡 / 4 卡
结论: 如果没有明确的大模型训练需求,直接选择 1 卡配置即可,开箱即用、成本可控、无需纠结型号差异。
三、配置资源(Step 2)
Section titled “三、配置资源(Step 2)”3.1 实例基础配置
Section titled “3.1 实例基础配置”3.1.1 设置实例名称
Section titled “3.1.1 设置实例名称”实例名称用于后续管理与识别,建议命名规则:
用途 + 场景 + 日期
示例:
- llm-inference-20260206
- data-process-20260206
- model-train-test
也可使用系统自动生成名称。
3.1.2 选择基础镜像
Section titled “3.1.2 选择基础镜像”选择平台预制基础镜像即可快速获得完整运行环境。
示例镜像:
- Ubuntu 22.04
- PyTorch 2.1.2
- Python 3.10
- CUDA 11.9
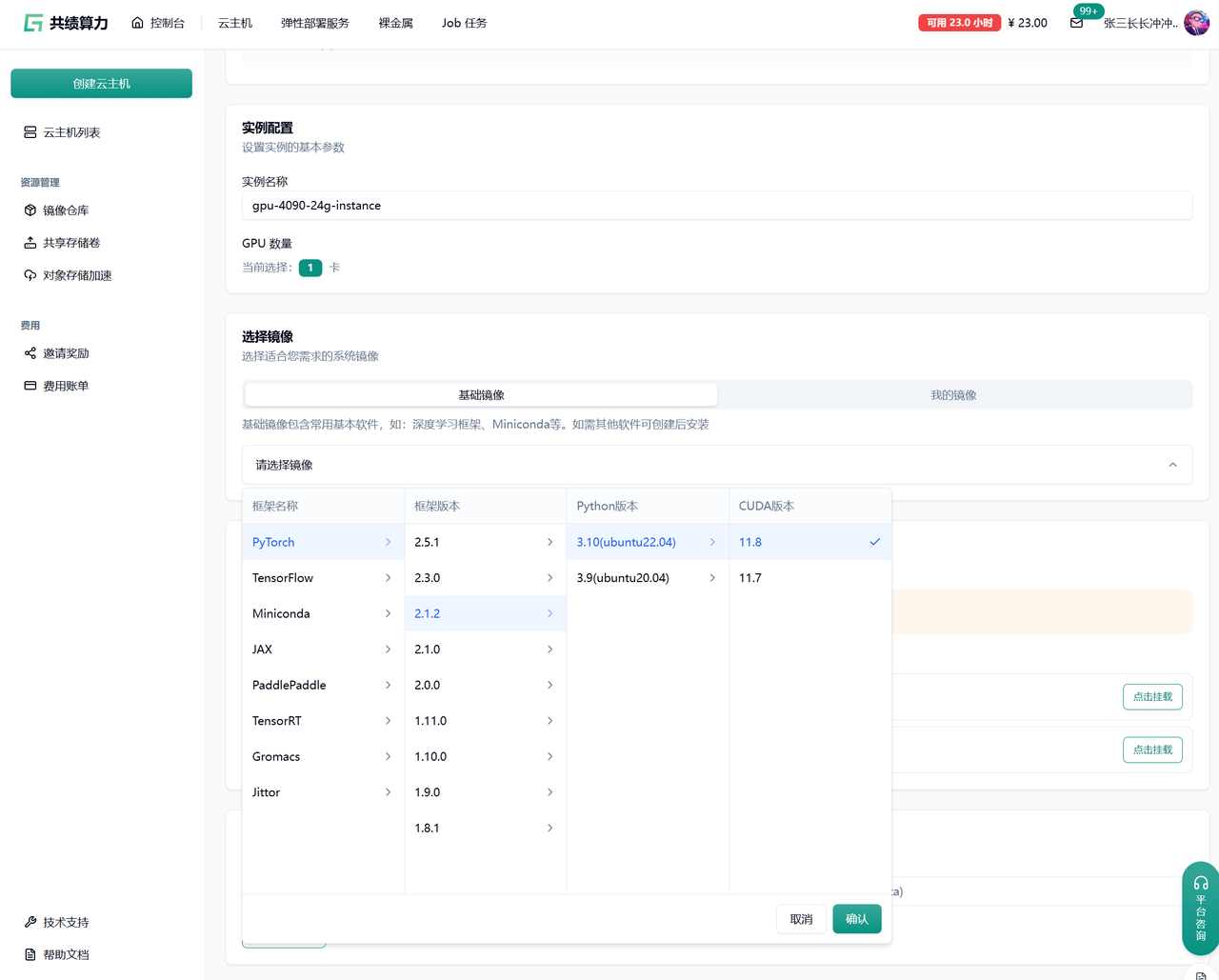
说明:
- 平台已提供完整适配环境
- 无需手动安装 CUDA、驱动、深度学习框架
- 环境一致性强,适合迁移与部署
3.2 挂载共享存储卷(数据安全核心步骤)
Section titled “3.2 挂载共享存储卷(数据安全核心步骤)”开通共享存储卷服务,并挂载到实例目录:
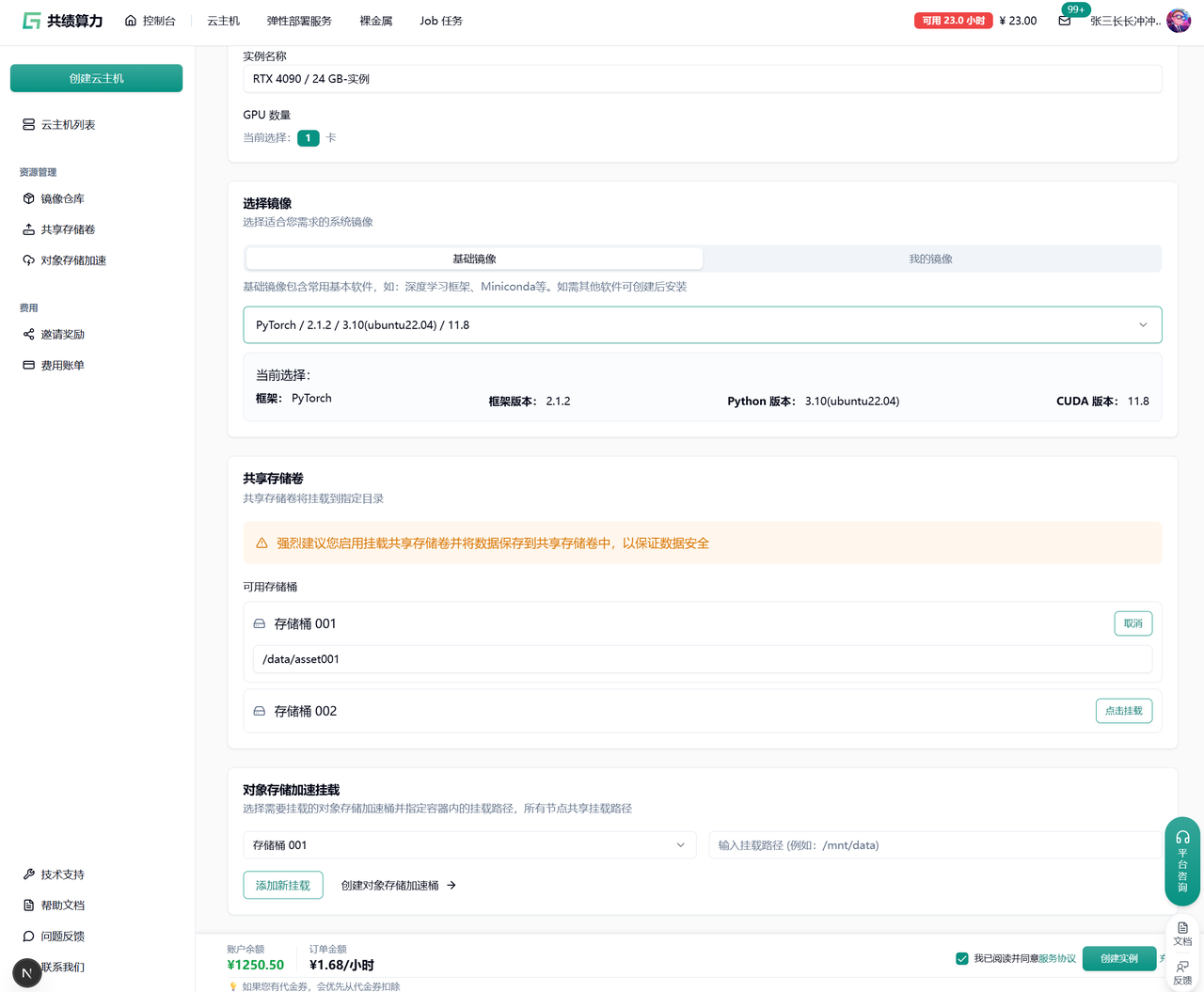
挂载规范(非常重要):
-
禁止挂载到以下目录:
- /
- /root
-
推荐目录结构:
- /root/data
- /root/code
- /root/workspace
说明:
- 根目录挂载会引发系统权限与环境异常问题
- 二级目录结构安全且可控
完成配置后:同意协议 → 点击【创建实例】
3.3 对象存储加速桶(大模型与大文件推荐方案)
Section titled “3.3 对象存储加速桶(大模型与大文件推荐方案)”使用场景说明
Section titled “使用场景说明”当涉及以下数据类型时:
- 大模型权重文件(LLM / 多模态模型 / 向量模型)
- 预训练模型参数
- 大型数据集
- 只读型公共模型文件
- 多实例共享模型文件
强烈建议使用「对象存储加速桶」挂载到云主机,而不是存放在云主机本地盘或共享存储卷中。
为什么不建议直接存放在云主机本地盘
Section titled “为什么不建议直接存放在云主机本地盘”存在以下风险与问题:
- 存储空间限制风险 云主机本地盘存在容量上限,大模型文件体积通常为 50GB:
- 可能导致磁盘空间不足
- 镜像无法正常保存
- 环境无法持久化
- 性能与稳定性风险 在云主机中直接上传/下载大文件:
- 高峰期网络带宽波动大
- 下载速度不稳定
- 容易出现下载中断、文件损坏
- 架构设计问题 本地盘存储模型文件会导致:
- 实例与数据强耦合
- 实例不可快速销毁重建
- 无法实现多实例共享
对象存储加速桶的架构优势
Section titled “对象存储加速桶的架构优势”对象存储 + 加速挂载模式具备:
- 高吞吐读取能力
- CDN 级访问加速
- 多实例共享访问
- 只读数据集中管理
- 云主机无状态化
- 模型统一版本管理
推荐模式:
计算层:云主机 存储层:对象存储加速桶 安全层:共享存储卷(业务数据)
标准使用模型
Section titled “标准使用模型”模型/权重文件存放位置:对象存储加速桶(只读)
业务数据/用户数据:共享存储卷(读写)
运行环境:云主机本地盘(临时环境)
形成标准云架构分层:
- 计算层:云主机实例
- 模型层:对象存储
- 数据层:共享存储卷
配置文档参考
Section titled “配置文档参考”对象存储加速配置说明文档:https://www.gongjiyun.com/docs/flexible-deployment/function-usage-instructions/wqhqwbcf3i6byykijbvct9dkn0e/
四、查看运行状态(Step 3)
Section titled “四、查看运行状态(Step 3)”实例创建完成后,可在云主机列表查看运行状态:
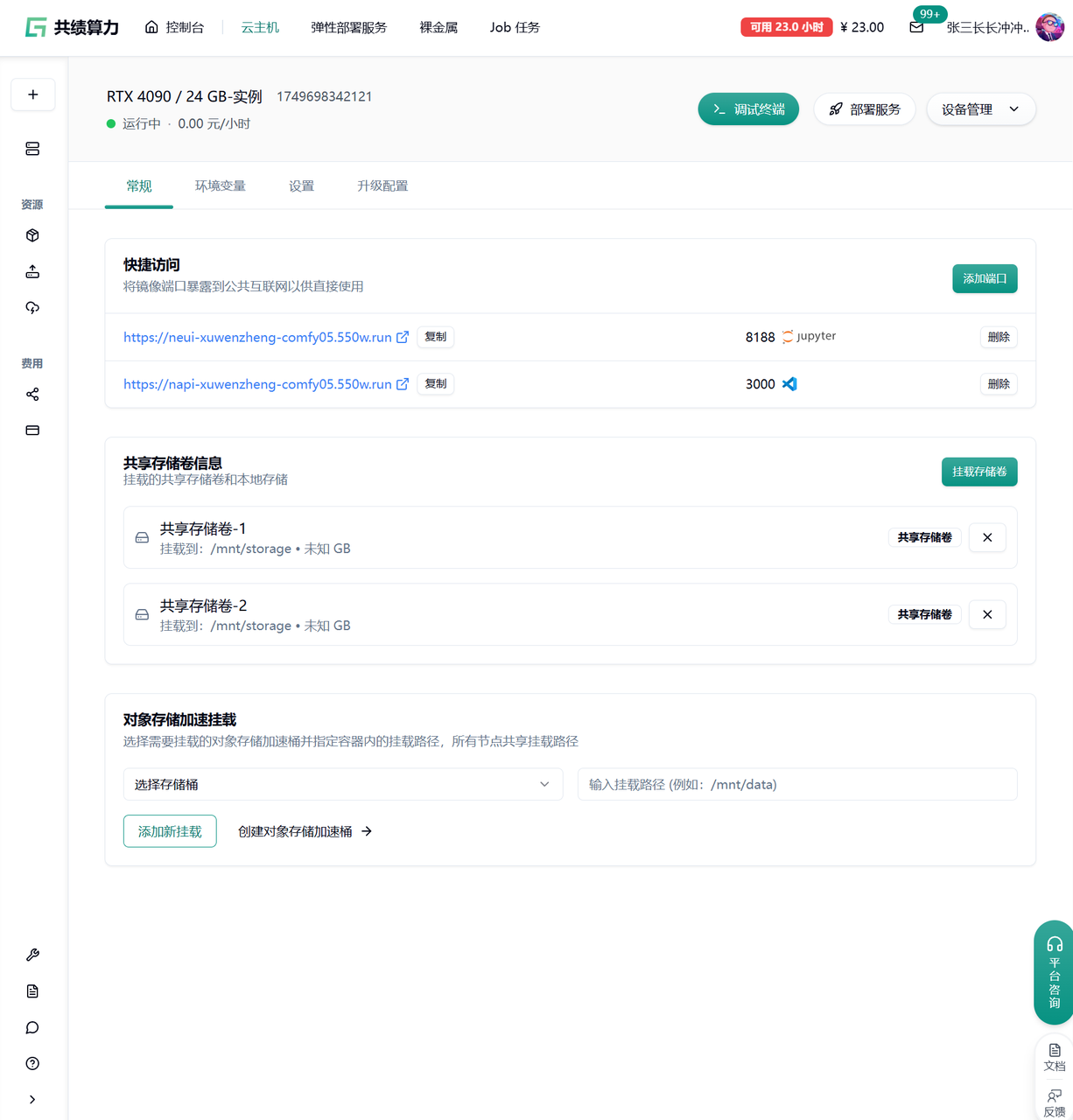
状态说明:
- 运行中:可直接连接使用
- 创建中:等待资源初始化
- 停止:可重新启动
五、核心概念说明
Section titled “五、核心概念说明”5.1 GPU 资源模型
Section titled “5.1 GPU 资源模型”逻辑理解模型:
- GPU 数量(1 卡 / 2 卡 / 4 卡 / 8 卡):并行计算能力
- 显存大小:单任务可承载模型规模
- 内存大小:多任务调度能力
- CPU 核心数:数据处理与调度能力
适用场景:
- 1 卡:推理服务、API 部署、数据处理
- 多卡:分布式训练、大模型训练、高并发任务
5.2 实例名称的管理意义
Section titled “5.2 实例名称的管理意义”实例名称本质是资源管理标签,用于:
- 成本追踪
- 项目区分
- 运维管理
- 权限管理
推荐命名结构:
项目 + 功能 + 时间
5.3 基础镜像体系结构说明
Section titled “5.3 基础镜像体系结构说明”- Ubuntu 20.04 / 22.04
- CUDA 自动适配 GPU 架构
- apt 源已加速优化
运行与管理层
Section titled “运行与管理层”- Bash 作为主 Shell
- screen 多会话管理
- supervisord 统一进程管理
- SSH Server
- VSCode Server(Python、Pylance、Jupyter、Debugger 插件已配置)
- JupyterLab(Debugger、LSP、TOC、LaTeX、Matplotlib 等插件)
- miniconda(环境管理、Python 依赖管理)
AI 框架支持(合并展示)
Section titled “AI 框架支持(合并展示)”PyTorch: 1.8.2, 1.13.1, 2.0.1, 2.1.2, 2.2.2, 2.3.1, 2.4.1, 2.5.1, 2.6.0, 2.7.1
TensorFlow: 1.15、2.1、2.4、2.7、2.11、2.15、2.18、2.19(按 Python 版本适配)
说明:
- 所有镜像已完成 CUDA / Python / 系统兼容适配
- 环境即开即用
- 无需手动配置驱动与依赖
六、整体使用逻辑总结
Section titled “六、整体使用逻辑总结”标准使用结构:
- 云主机只负责计算
- 共享存储卷负责数据安全
- 镜像负责环境一致性
架构模型:
计算层(云主机) + 存储层(共享存储卷) + 环境层(基础镜像)
这是一个标准的云计算安全架构模型,具备:
- 数据安全
- 环境可复制
- 实例可销毁
- 成本可控
- 可扩展性强