怎么用云主机配置 LLM 环境并使用自动弹性扩缩容
1.背景目标
Section titled “1.背景目标”在共绩算力云主机上搭建可弹性伸缩的 Qwen-7B-Chat 服务环境,实现:
- 私有化部署大模型 API 服务
- 根据流量自动扩缩容
- 支持高并发访问
模型链接:https://huggingface.co/Qwen/Qwen-7B-Chat
Qwen-7B 是由阿里云提出的大型语言模型系列 Qwen(简称 Tongyi Qianwen)的 7B 参数版本。Qwen-7B 是一个基于 Transformer 的大型语言模型,预训练于大量数据,包括网页文本、书籍、代码等。此外,基于预训练的 Qwen-7B,我们发布了 Qwen-7B-Chat,一个基于大型模型的 AI 助手,采用对齐技术进行训练。现在我们已经更新了预训练和聊天模型,性能提升。
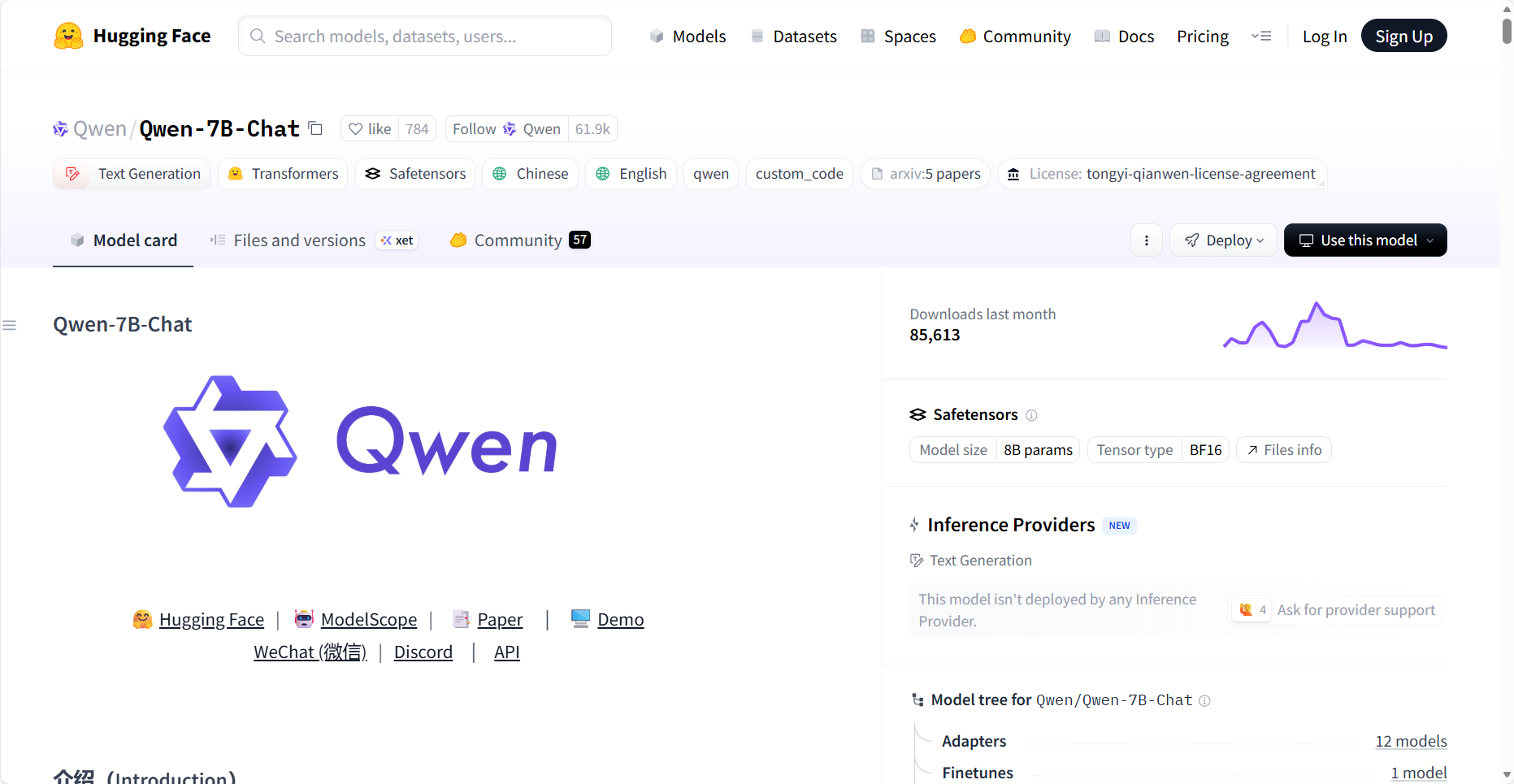
查看模型环境要求以及必要依赖项
2.准备工作
Section titled “2.准备工作”
登录共绩算力云主机,选择合适的云主机设备(大部分情况选择 4090 即可,如果需要先下载模型的情况。可以选择 CPU 启动 节省成本)
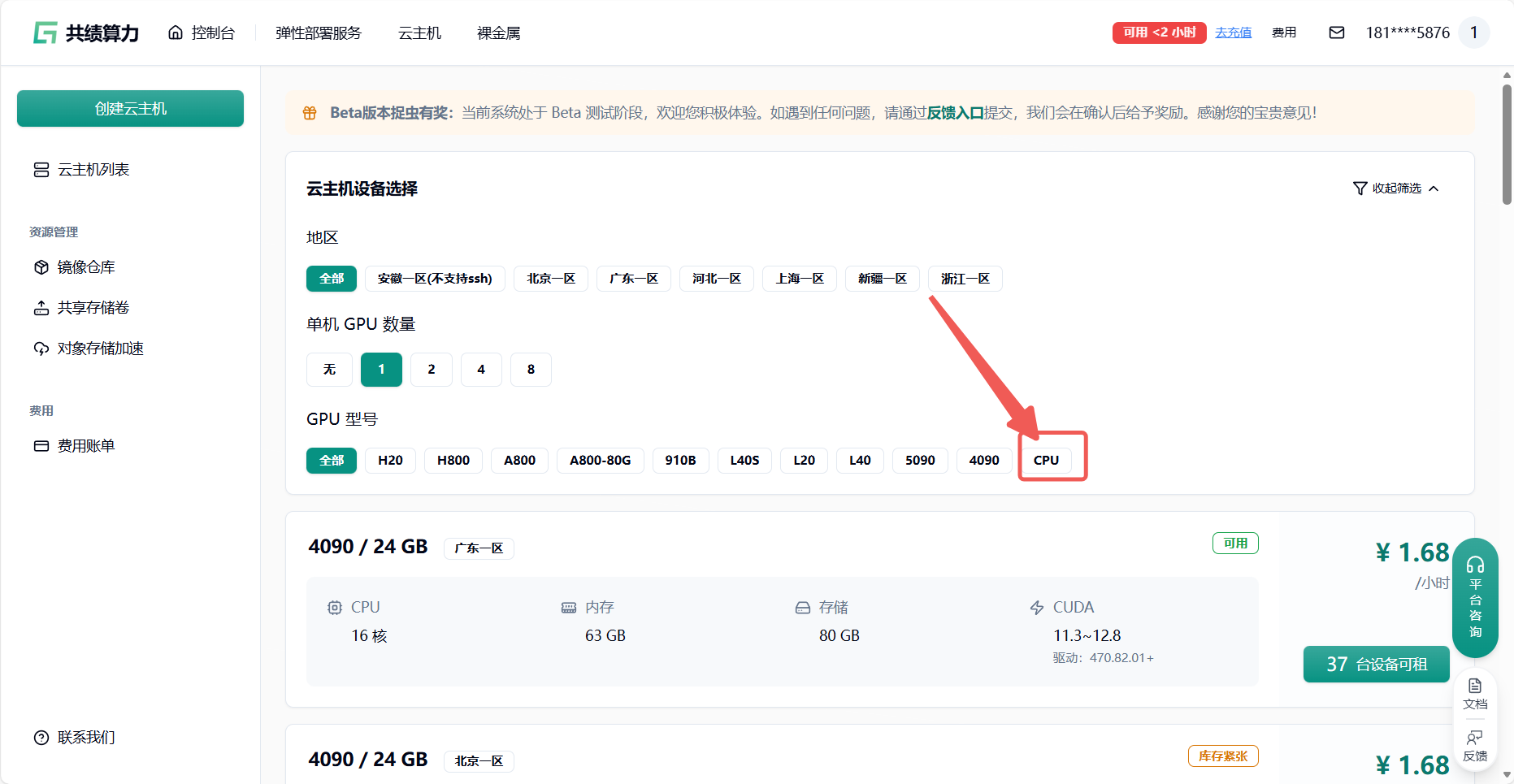
通过刚才的模型环境建议 选择适合的云主机框架环境
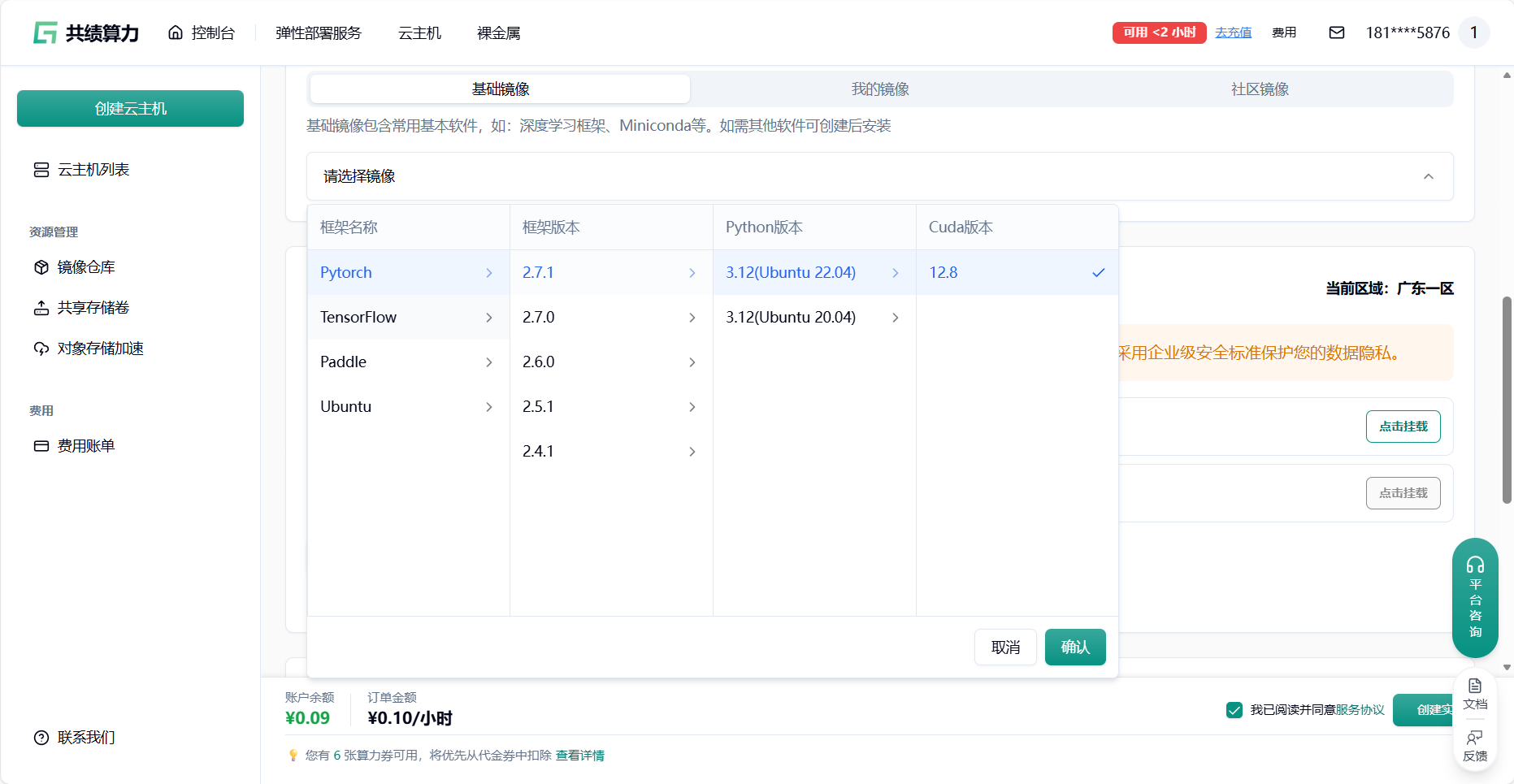
我们推荐在云主机中配置环境,存储模块中(对象存储加速中或者共享存储卷)放模型以达到镜像和模型的分离。
目前云主机磁盘限额 80GB,云主机磁盘内存过大会导致 关机/启动 时间过长
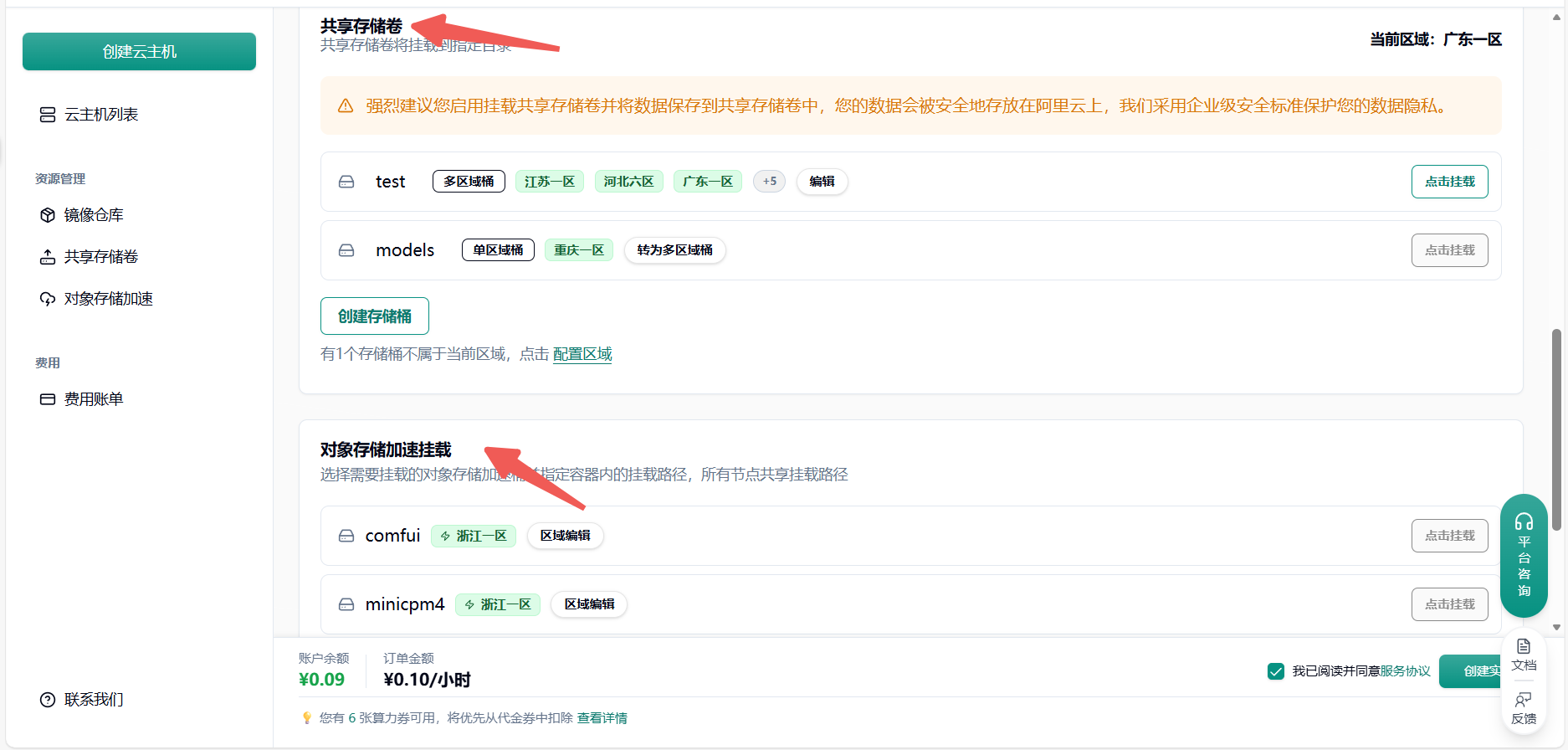
详细配置过程可以查看本文档底部附录一 附录二
- 共享存储卷:主要用于高性能、高并发的读写场景。它像传统的硬盘或网络文件系统(如 NFS),可以被多个计算节点同时挂载,支持文件的频繁读写和修改,适合训练数据、模型中间结果、日志等需要频繁读写的场景。
- 对象存储加速挂载:主要用于高效读取大规模数据,通常是只读场景。它将对象存储(如 S3)的数据通过挂载的方式直接呈现为本地文件系统,方便访问和读取,适合加载大数据集、预训练模型等只读需求。
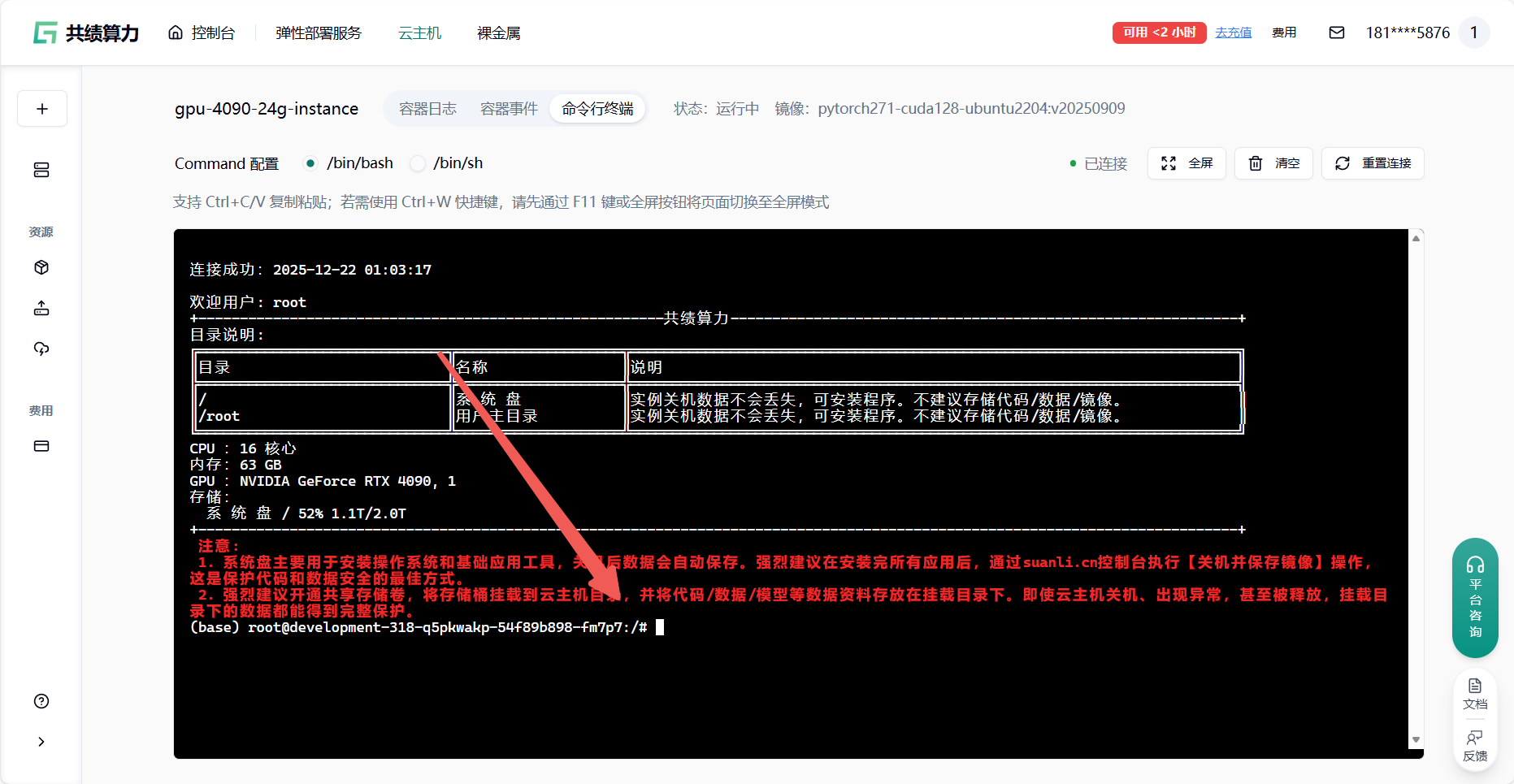
通过共绩算力平台提供的 Web 终端或 Jupyter 终端登录,直接执行接下来的操作
如果需要使用 SSH 远程连接可以参考这篇文档:
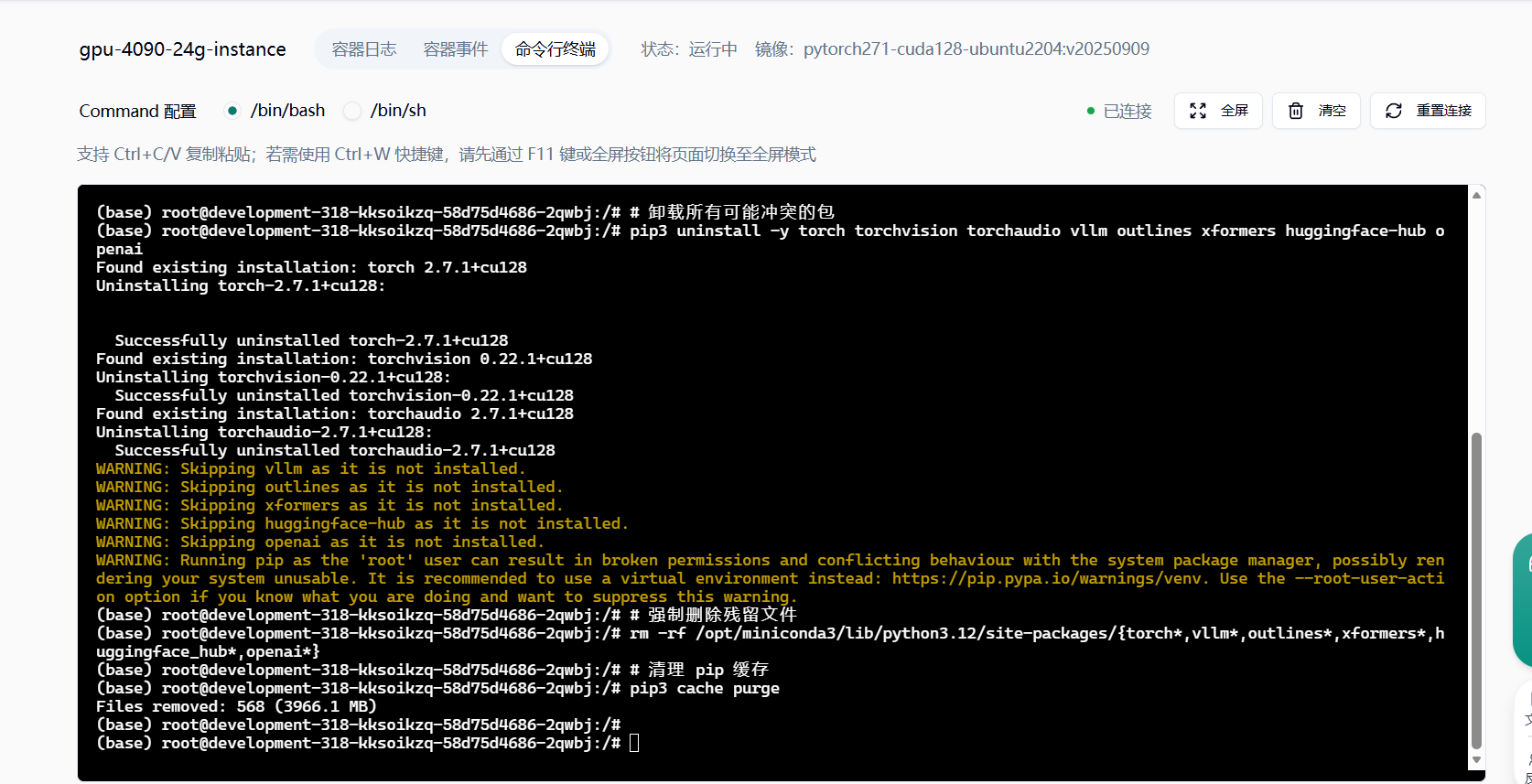
清理旧环境(彻底消除冲突残留)
pip3 uninstall -y torch torchvision torchaudio vllm outlines xformers huggingface-hub openai
rm -rf /opt/miniconda3/lib/python3.12/site-packages/{torch*,vllm*,outlines*,xformers*,huggingface_hub*,openai*}
pip3 cache purge安装核心依赖(从模型的说明文档中获取必要的配置信息 然后在云主机中进行安装)
pip3 install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install sentencepiece -i https://pypi.tuna.tsinghua.edu.cn/simple --only-binary :all:
pip3 install transformers==4.41.0 accelerate==0.31.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install modelscope==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
验证环境(确保无兼容问题)
执行以下命令,输出均符合预期则环境正常:
python3 -c "import torch; print('CUDA 可用:', torch.cuda.is_available()); print('GPU 型号:', torch.cuda.get_device_name(0)); print('PyTorch 版本:', torch.__version__)"
python3 -c "from transformers import AutoModelForCausalLM, AutoTokenizer; import modelscope; print('所有库导入成功')"

3.下载 Qwen-7B-Chat 模型
Section titled “3.下载 Qwen-7B-Chat 模型”3.1 终端下载模型
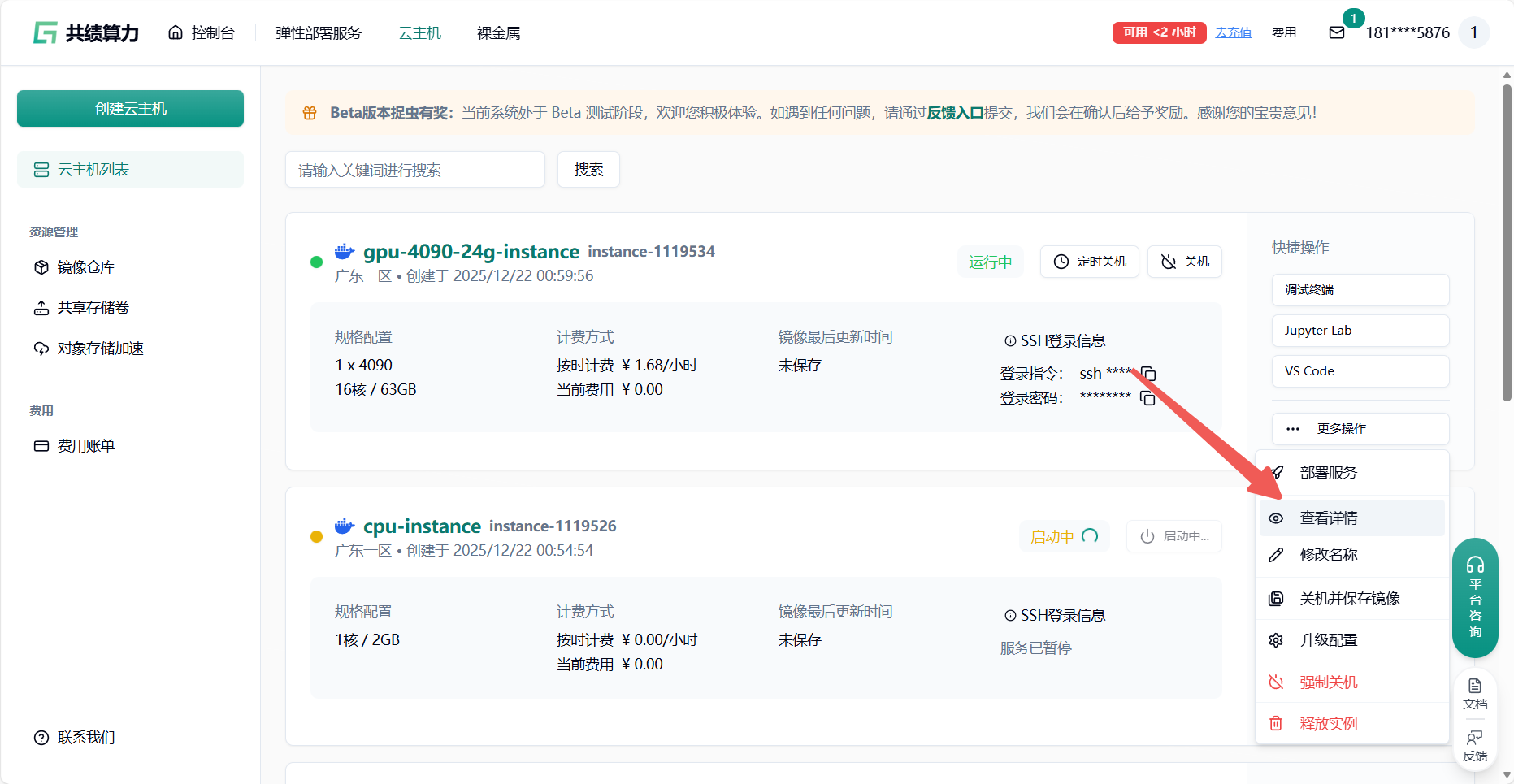
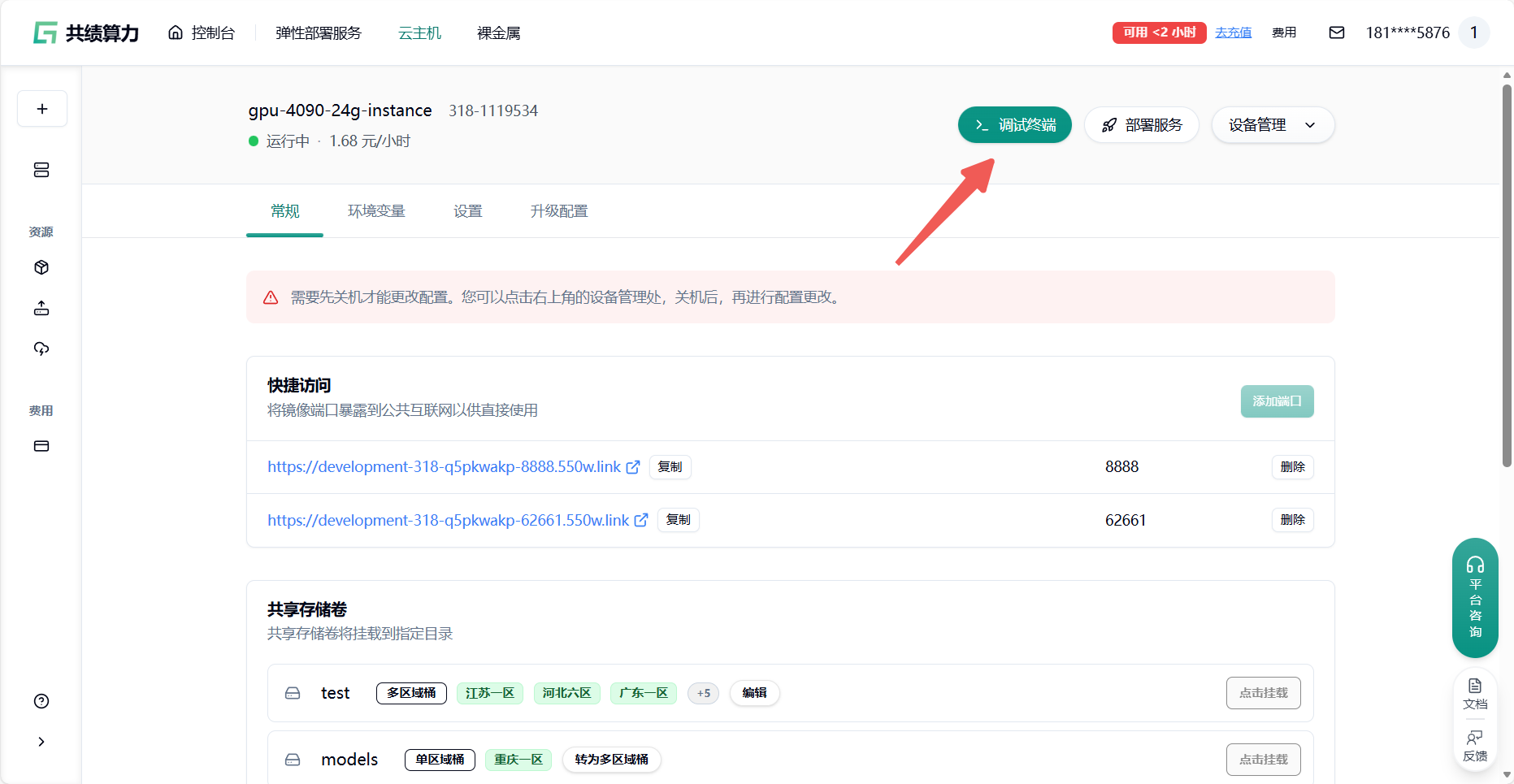
Section titled “3.1 终端下载模型”云主机启动成功后点击 查看详情——调试终端
推荐使用 ModelScope 国内镜像下载,避免 Hugging Face 官方源的网络问题,且自动下载完整配置文件(含 config.json、tokenizer.json 等):
cd /root/models/Qwen-7B-Chat
pip3 install tiktoken -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install transformers_stream_generator -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install modelscope fastapi uvicorn pydantic starlette python-multipart -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install --upgrade modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
apt update -y && apt install -y libgl1-mesa-glx
export MODEL_SCOPE_ENDPOINT=https://modelscope.cn/api/v1
modelscope download --model qwen/Qwen-7B-Chat --local-dir /root/models/Qwen-7B-Chat3.2 python 代码 下载模型
Section titled “3.2 python 代码 下载模型”cd /root/models/Qwen-7B-Chat
cat > download_ultimate.py << 'EOF'from modelscope.hub.snapshot_download import snapshot_downloadimport os
os.makedirs(os.getcwd(), exist_ok=True)
try: # 第 1 个参数:模型 ID,第 2 个参数:当前目录(/root/models/Qwen-7B-Chat) model_dir = snapshot_download("qwen/Qwen-7B-Chat", os.getcwd()) print("\n🎉 模型下载成功!所有文件已保存到:", os.getcwd()) print("💡 立即启动交互:python3 /root/qwen_chat_stream_reset.py")except Exception as e: print("\n❌ 下载异常:", str(e)) print("🔧 自动重试(使用默认缓存目录)...") model_dir = snapshot_download("qwen/Qwen-7B-Chat") print(f"\n🎉 模型下载成功!默认路径:{model_dir}") print("📥 正在自动复制到目标目录...") os.system(f"cp -r {model_dir}/* {os.getcwd()}/") print("✅ 复制完成!启动命令:python3 /root/qwen_chat_stream_reset.py")EOF
export MODEL_SCOPE_ENDPOINT=https://modelscope.cn/api/v1 && python3 mxUpload.py3.3 验证模型完整性
Section titled “3.3 验证模型完整性”下载完成后执行以下命令,确保核心文件存在:
ls -l /root/models/Qwen-7B-Chat | grep -E "config.json|tokenizer.json|safetensors"预期输出应包含:config.json、tokenizer.json、model-00001-of-00002.safetensors、model-00002-of-00002.safetensors
3.4 非平台基础镜像如何配置 SSH 连接
Section titled “3.4 非平台基础镜像如何配置 SSH 连接”4.编写 Python 启动脚本(控制台循环交互)
Section titled “4.编写 Python 启动脚本(控制台循环交互)”https://huggingface.co/Qwen/Qwen-7B-Chat
从 huggingface 上看到快速使用调用模型脚本代码
创建 qwen_chat.py 脚本,代码无任何过时参数,适配当前依赖版本:
- 首次启动:需编译 CUDA 内核,耗时约 5-10 分钟,耐心等待即可;
- 后续启动:直接加载缓存,耗时 1-2 分钟。
from transformers import AutoModelForCausalLM, AutoTokenizerimport torch
MODEL_PATH = "/root/models/Qwen-7B-Chat"
def load_model(): """加载模型和 Tokenizer,仅初始化一次""" print("正在加载 Qwen-7B-Chat 模型...(首次启动较慢,约 5-10 分钟,请耐心等待)")
# 加载 Tokenizer(适配 Qwen 模型格式) tokenizer = AutoTokenizer.from_pretrained( MODEL_PATH, trust_remote_code=True, padding_side="right", # 右侧填充,避免生成错误 truncation=True )
# 加载模型(自动适配 RTX 5090 GPU) model = AutoModelForCausalLM.from_pretrained( MODEL_PATH, trust_remote_code=True, device_map="auto", # 自动分配 GPU/CPU,优先使用 RTX 5090 torch_dtype=torch.float16, # 显存优化,32GB GPU 足够运行 load_in_8bit=False, # 不量化,保证生成效果 low_cpu_mem_usage=True # 降低 CPU 内存占用 ).eval() # 推理模式,禁用 Dropout 确保结果稳定
print("\n✅ 模型加载完成!输入 'quit' 退出对话,输入提示词即可开始交互~") return tokenizer, model
def chat_loop(tokenizer, model): """控制台循环交互""" while True: prompt = input("\n请输入提示词:") if prompt.lower().strip() == "quit": print("👋 退出对话,感谢使用!") break if not prompt.strip(): print("❌ 提示词不能为空,请重新输入~") continue
# 构建输入(适配 Qwen 模型的 Prompt 格式) inputs = tokenizer( prompt, return_tensors="pt", truncation=True, max_length=8192 # 匹配 Qwen 模型最大序列长度 ).to(model.device)
# 生成回答(无梯度计算,节省显存) with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=1024, # 最大生成 1024 个字符 temperature=0.7, # 随机性:0-1,值越大越灵活 top_p=0.95, # 采样阈值:过滤低概率词汇 do_sample=True, # 启用采样生成 eos_token_id=tokenizer.eos_token_id, # 结束标记 pad_token_id=tokenizer.pad_token_id, # 填充标记 repetition_penalty=1.1 # 重复惩罚,减少废话 )
# 解码并提取回答(去除输入提示词) response = tokenizer.decode(outputs[0], skip_special_tokens=True) response = response.replace(prompt, "").strip()
# 打印结果 print(f"\n📢 模型回答:\n{response}")
if __name__ == "__main__": try: tokenizer, model = load_model() chat_loop(tokenizer, model) except Exception as e: print(f"\n❌ 运行出错:{str(e)}") print("请检查:1. 模型文件是否完整;2. 依赖包是否安装正确;3. 显存是否充足")5.启动模型并交互
Section titled “5.启动模型并交互”运行脚本
python3 /root/qwen_chat.pyfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torch
MODEL_PATH = "/root/models/Qwen-7B-Chat"(如果使用平台共享存储卷存储模型文件就用<b>共享存储卷的路径</b>来下载存储模型文件)
def load_model(): """加载模型和 Tokenizer,仅初始化一次""" print("正在加载 Qwen-7B-Chat 模型...(首次启动较慢,约 5-10 分钟,请耐心等待)")
# 加载 Tokenizer(适配 Qwen 模型格式) tokenizer = AutoTokenizer.from_pretrained( MODEL_PATH, trust_remote_code=True, padding_side="right", # 右侧填充,避免生成错误 truncation=True )
# 加载模型(自动适配 RTX 5090 GPU) model = AutoModelForCausalLM.from_pretrained( MODEL_PATH, trust_remote_code=True, device_map="auto", # 自动分配 GPU/CPU,优先使用 RTX 5090 torch_dtype=torch.float16, # 显存优化,32GB GPU 足够运行 load_in_8bit=False, # 不量化,保证生成效果 low_cpu_mem_usage=True # 降低 CPU 内存占用 ).eval() # 推理模式,禁用 Dropout 确保结果稳定
print("\n✅ 模型加载完成!输入 'quit' 退出对话,输入提示词即可开始交互~") return tokenizer, model
def chat_loop(tokenizer, model): """控制台循环交互""" while True: prompt = input("\n请输入提示词:") if prompt.lower().strip() == "quit": print("👋 退出对话,感谢使用!") break if not prompt.strip(): print("❌ 提示词不能为空,请重新输入~") continue
# 构建输入(适配 Qwen 模型的 Prompt 格式) inputs = tokenizer( prompt, return_tensors="pt", truncation=True, max_length=8192 # 匹配 Qwen 模型最大序列长度 ).to(model.device)
# 生成回答(无梯度计算,节省显存) with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=1024, # 最大生成 1024 个字符 temperature=0.7, # 随机性:0-1,值越大越灵活 top_p=0.95, # 采样阈值:过滤低概率词汇 do_sample=True, # 启用采样生成 eos_token_id=tokenizer.eos_token_id, # 结束标记 pad_token_id=tokenizer.pad_token_id, # 填充标记 repetition_penalty=1.1 # 重复惩罚,减少废话 )
# 解码并提取回答(去除输入提示词) response = tokenizer.decode(outputs[0], skip_special_tokens=True) response = response.replace(prompt, "").strip()
# 打印结果 print(f"\n📢 模型回答:\n{response}")
if __name__ == "__main__": try: tokenizer, model = load_model() chat_loop(tokenizer, model) except Exception as e: print(f"\n❌ 运行出错:{str(e)}") print("请检查:1. 模型文件是否完整;2. 依赖包是否安装正确;3. 显存是否充足")交互示例:
正在加载 Qwen-7B-Chat 模型...(首次启动较慢,约 5-10 分钟,请耐心等待)
✅ 模型加载完成!输入 'quit' 退出对话,输入提示词即可开始交互~
请输入提示词:介绍一下自己📢 模型回答:我是 Qwen-7B-Chat 大模型,基于 Transformer 架构训练而成,支持多轮对话、信息查询、创意生成等多种功能。我具备较强的语言理解和生成能力,能够根据你的需求提供准确、流畅的回答,适用于日常交流、学习辅助、工作协作等场景~
请输入提示词:quit👋 退出对话,感谢使用!6.本地调用(远程访问云主机模型)
Section titled “6.本地调用(远程访问云主机模型)”若需从本地电脑调用云主机上的模型,可在云主机上通过 FastAPI 搭建简单 API 服务:
- 安装 API 依赖
pip3 install fastapi uvicorn pydantic -i https://pypi.tuna.tsinghua.edu.cn/simple- 创建 API 服务脚本
qwen_api.py
from fastapi import FastAPI, HTTPExceptionfrom pydantic import BaseModelfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torch
app = FastAPI(title="Qwen-7B-Chat API")MODEL_PATH = "/root/models/Qwen-7B-Chat"
tokenizer, model = None, None@app.on_event("startup")def startup(): global tokenizer, model tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( MODEL_PATH, trust_remote_code=True, device_map="auto", torch_dtype=torch.float16 ).eval()
class PromptRequest(BaseModel): prompt: str
@app.post("/generate")async def generate(request: PromptRequest): try: inputs = tokenizer(request.prompt, return_tensors="pt").to(model.device) with torch.no_grad(): outputs = model.generate(**inputs, max_new_tokens=1024, temperature=0.7, top_p=0.95) response = tokenizer.decode(outputs[0], skip_special_tokens=True).replace(request.prompt, "").strip() return {"prompt": request.prompt, "response": response} except Exception as e: raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__": import uvicorn # 允许外部访问(云主机公网 IP 可访问) uvicorn.run(app, host="0.0.0.0", port=8000)- 启动 API 服务
nohup python3 /root/qwen_api.py > qwen_api.log 2>&1- 本地电脑调用脚本
local_client.py
import requests
API_URL = "https://云主机公网 IP:8000/generate(任务暴露的公网映射地址链接)"
def call_qwen(prompt): try: response = requests.post(API_URL, json={"prompt": prompt}, timeout=60) if response.status_code == 200: return response.json()["response"] else: return f"调用失败:{response.text}" except Exception as e: return f"网络错误:{str(e)}"
if __name__ == "__main__": while True: prompt = input("请输入提示词(输入'quit'退出):") if prompt.lower() == "quit": break result = call_qwen(prompt) print(f"\n模型回答:\n{result}\n")7.如何转换为弹性部署服务(自动弹性扩缩容)
Section titled “7.如何转换为弹性部署服务(自动弹性扩缩容)”若您的业务流量存在明显波动或需要按需使用资源以控制成本,强烈建议启用自动扩缩容功能。按需分配资源,避免资源浪费,确保任务稳定运行,提升效率并降低长时间占用成本。
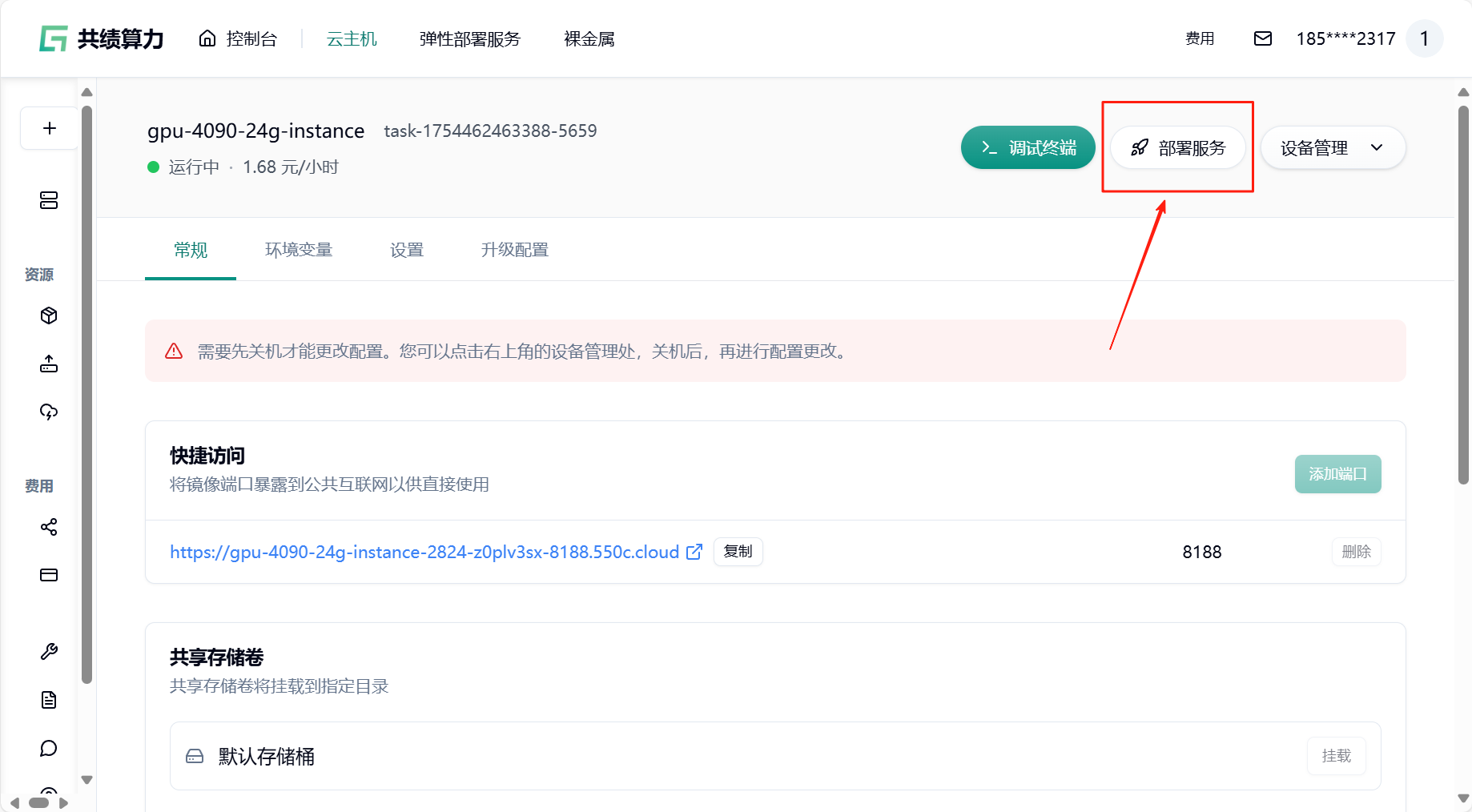
- 回到云主机页面,找到“部署服务”
- 关机并保存镜像,输入镜像标签
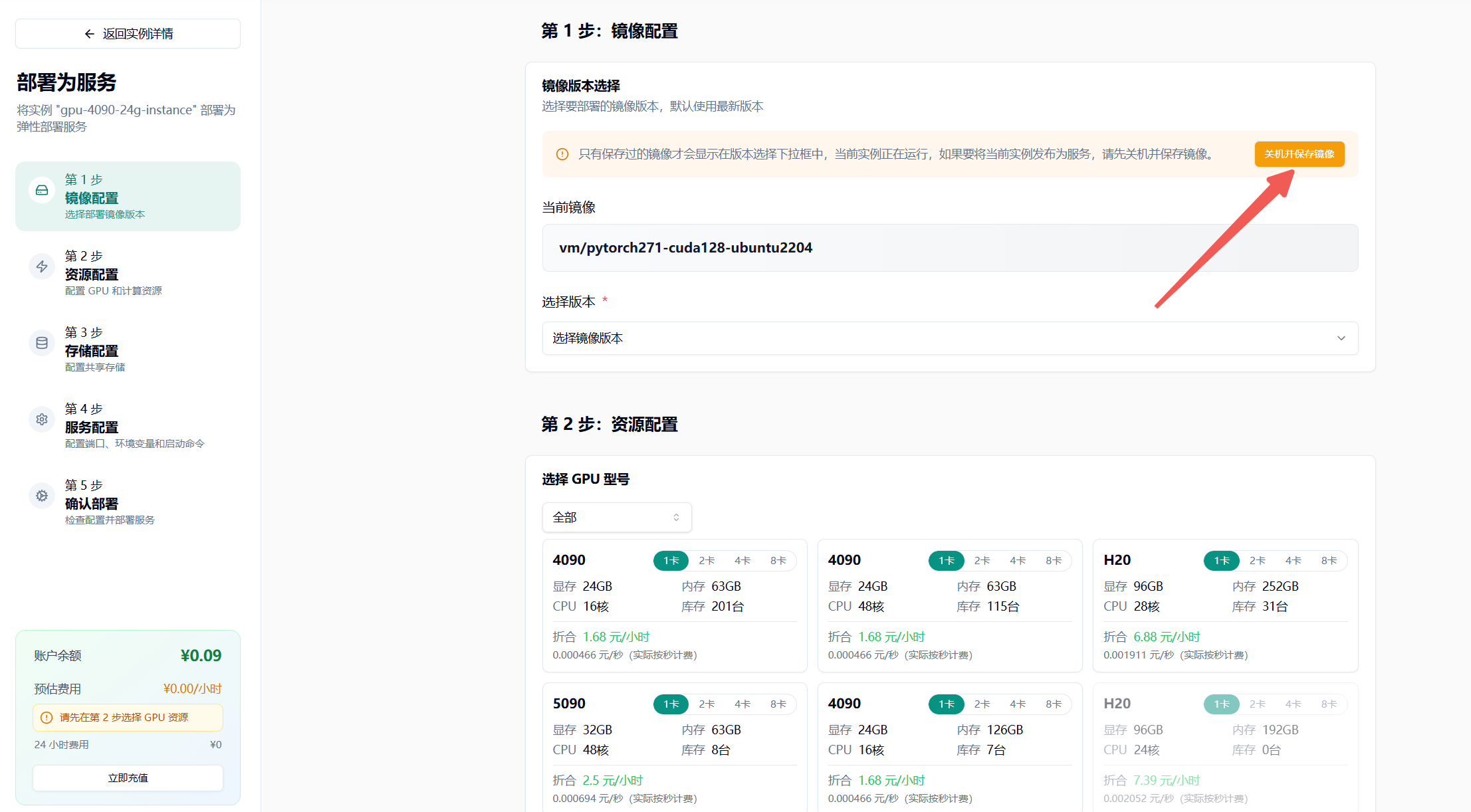
- 选择最新版本
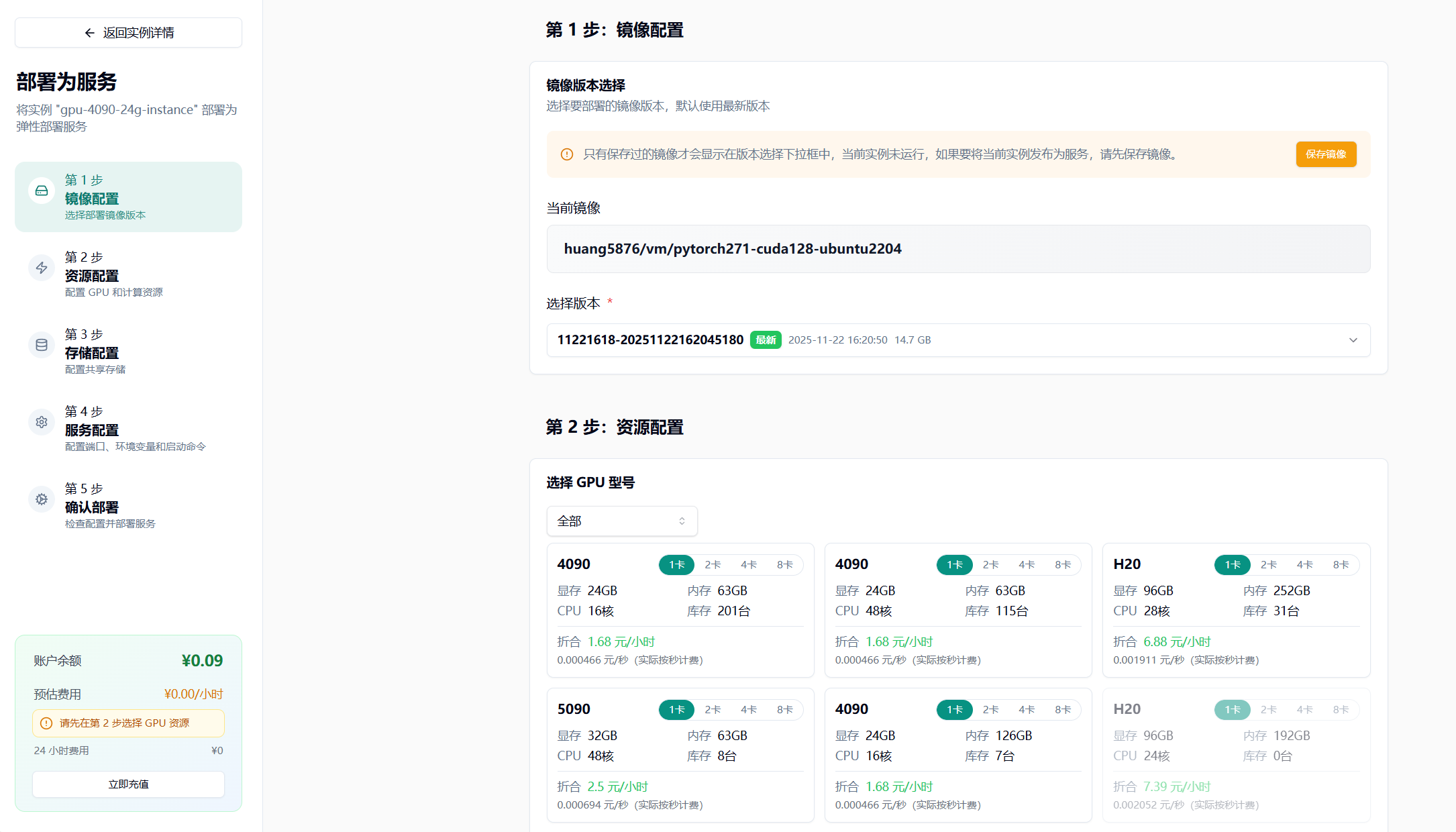
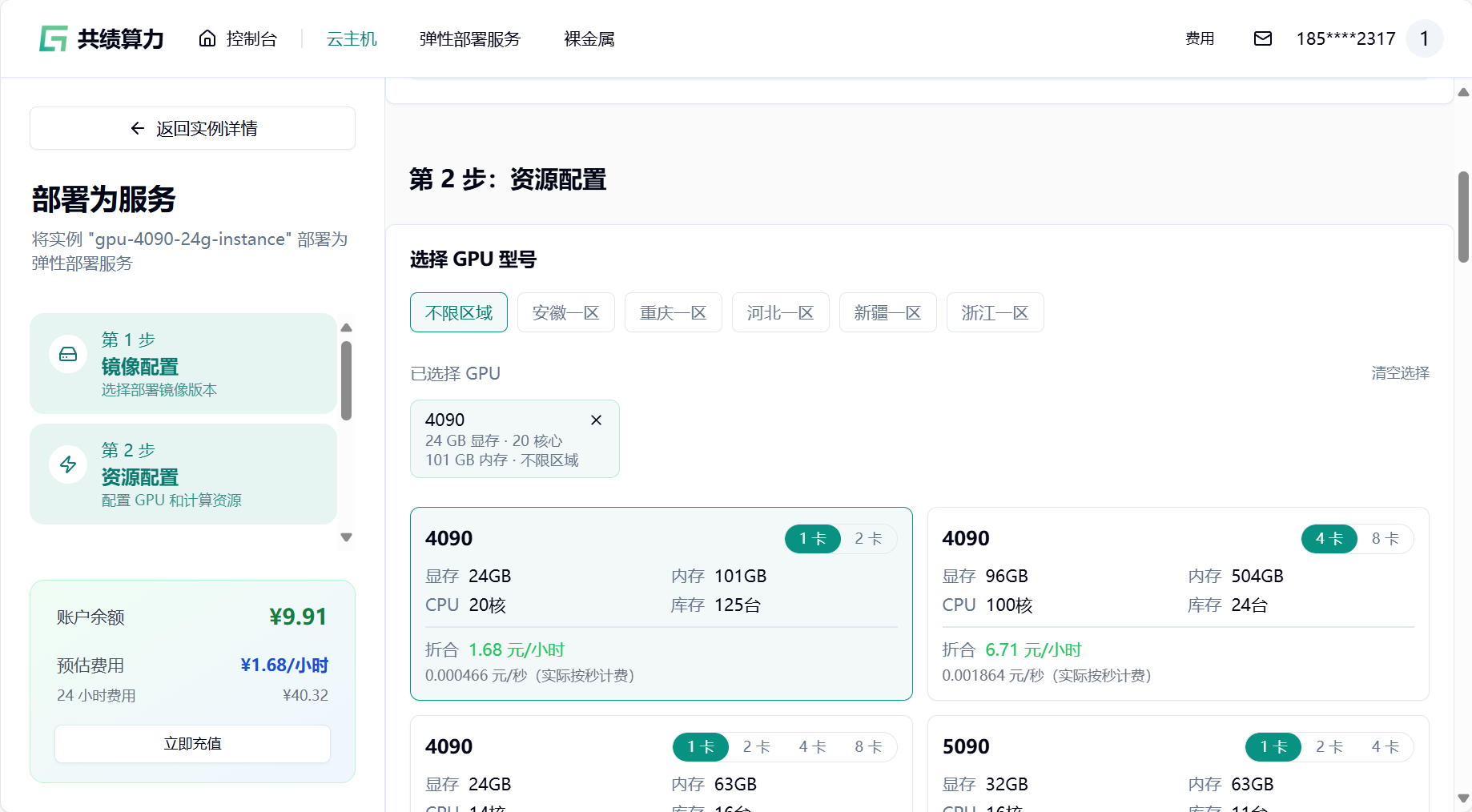
- 选择 GPU 配置(如 4090),节点默认选择 1 个
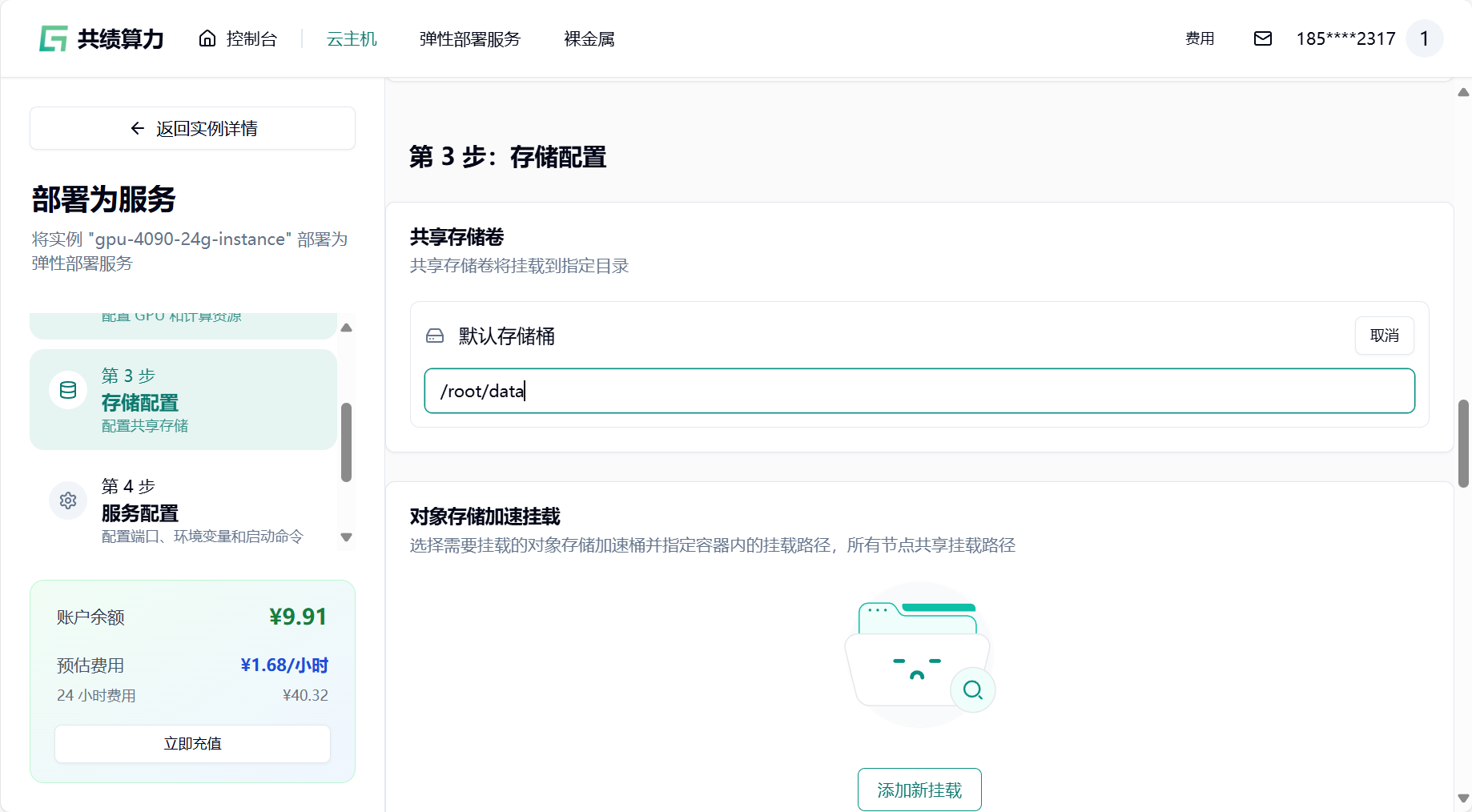
- 挂载存储卷
注意:挂载存储的时候,不要直接挂载到/、/root、 /root/目录,否则会出现一些奇怪的问题。建议挂载在类似/root/data、/root/code 之类的二级目录。
其他配置根据自己镜像的需要来进行配置
- 点击最下方“确认部署”即可,若无问题则会进入节点拉取界面,耐心等待即可
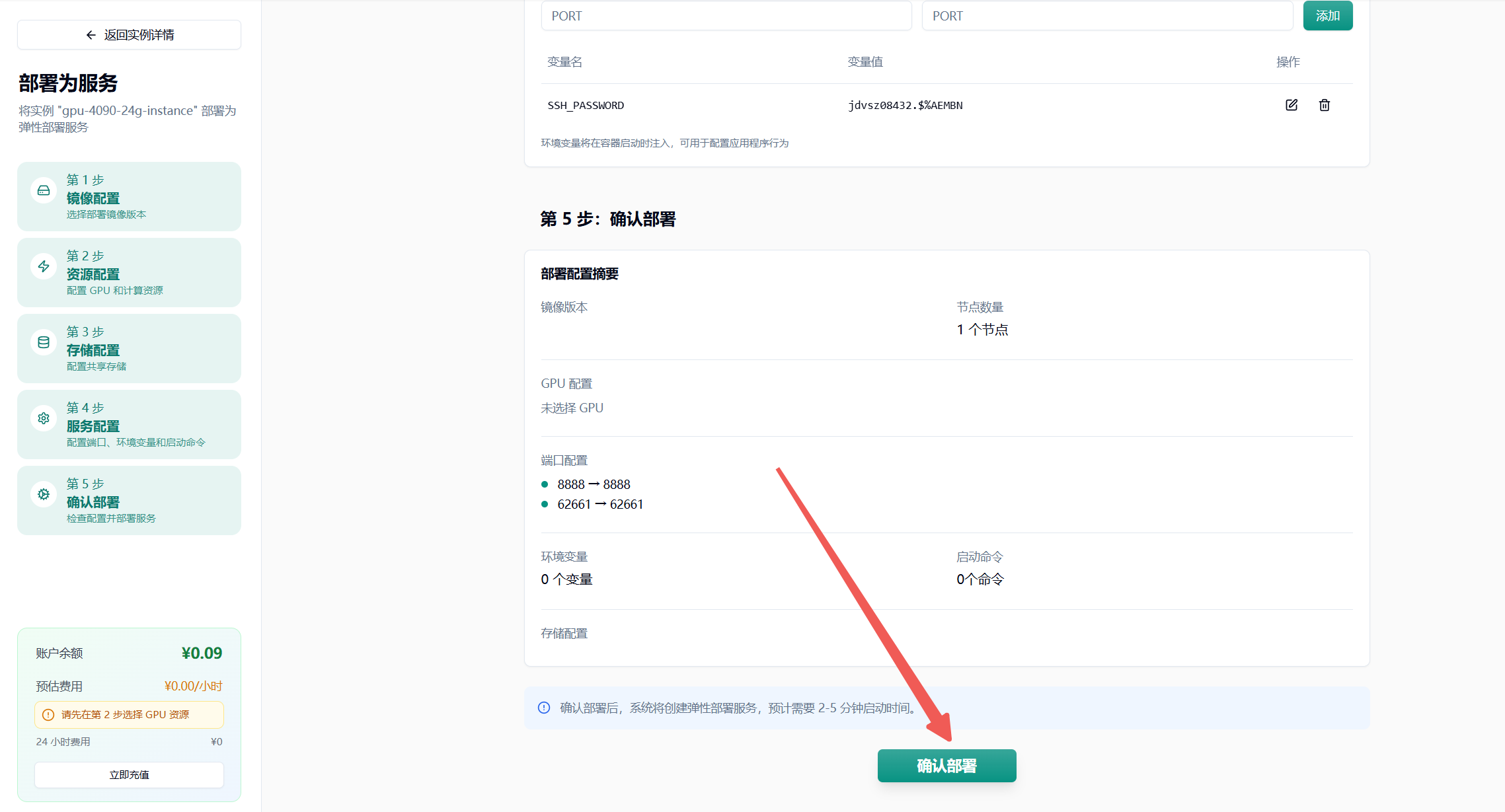
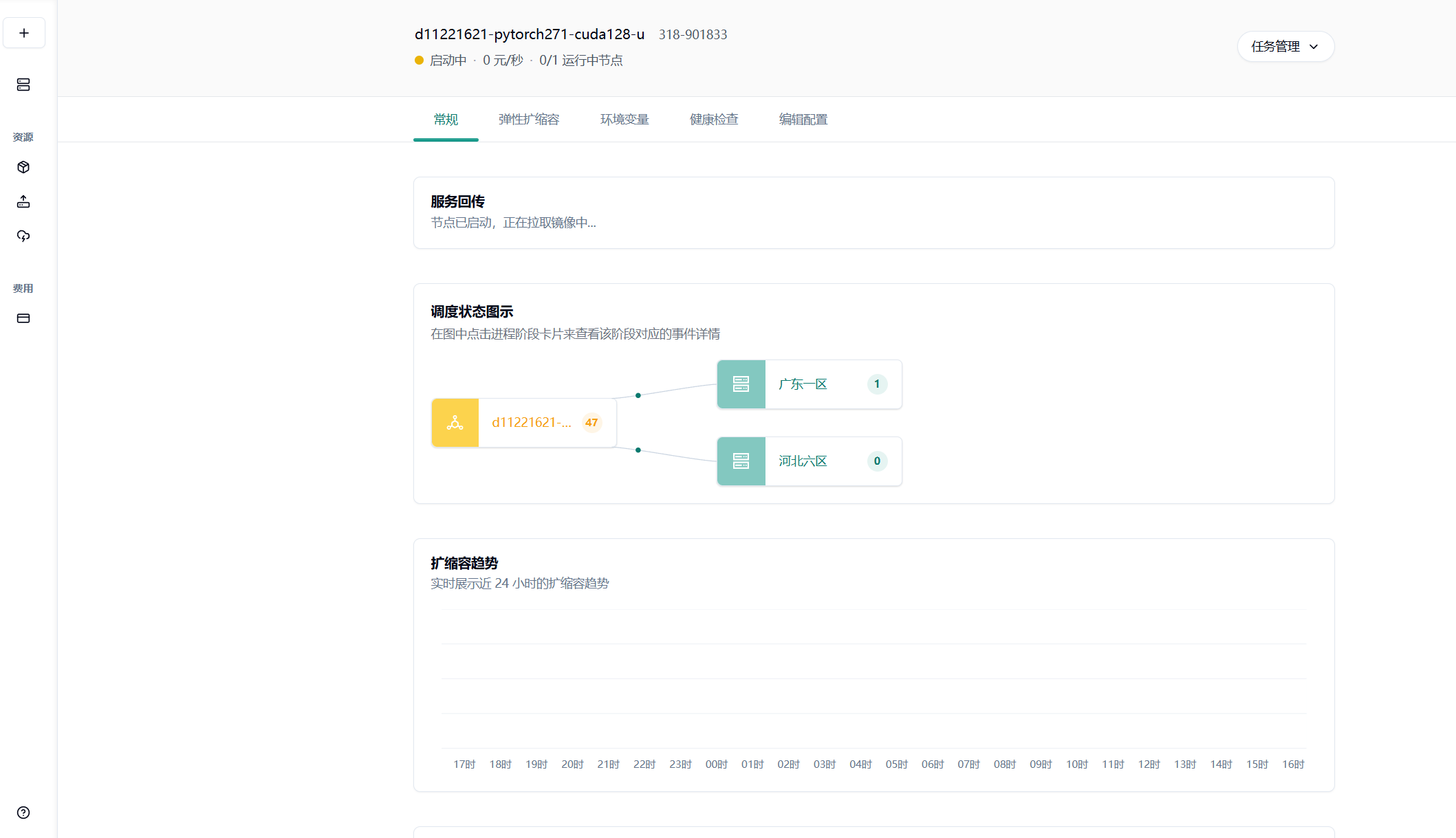
具体的自动弹性扩缩容设置可以参考这篇使用文档:https://www.gongjiyun.com/docs/flexible-deployment/function-usage-instructions/jurlwpstdiyokzkzwqocfpclnbf/
参数设置建议
最小节点数:建议设置为 1,避免冷启动影响。如果业务对响应时间要求极高,可以适当增加。
最大节点数:根据预算和业务峰值合理设置。建议先从小值开始,观察实际使用情况后逐步调整。
队列延迟阈值:建议设置为 4-10 秒,平衡成本和体验。对于实时性要求高的任务,可以设置较小值。
空闲超时时间:建议设置为 300-600 秒,减少冷启动影响的同时控制成本。
附录 1 对象存储加速中放置模型
Section titled “附录 1 对象存储加速中放置模型”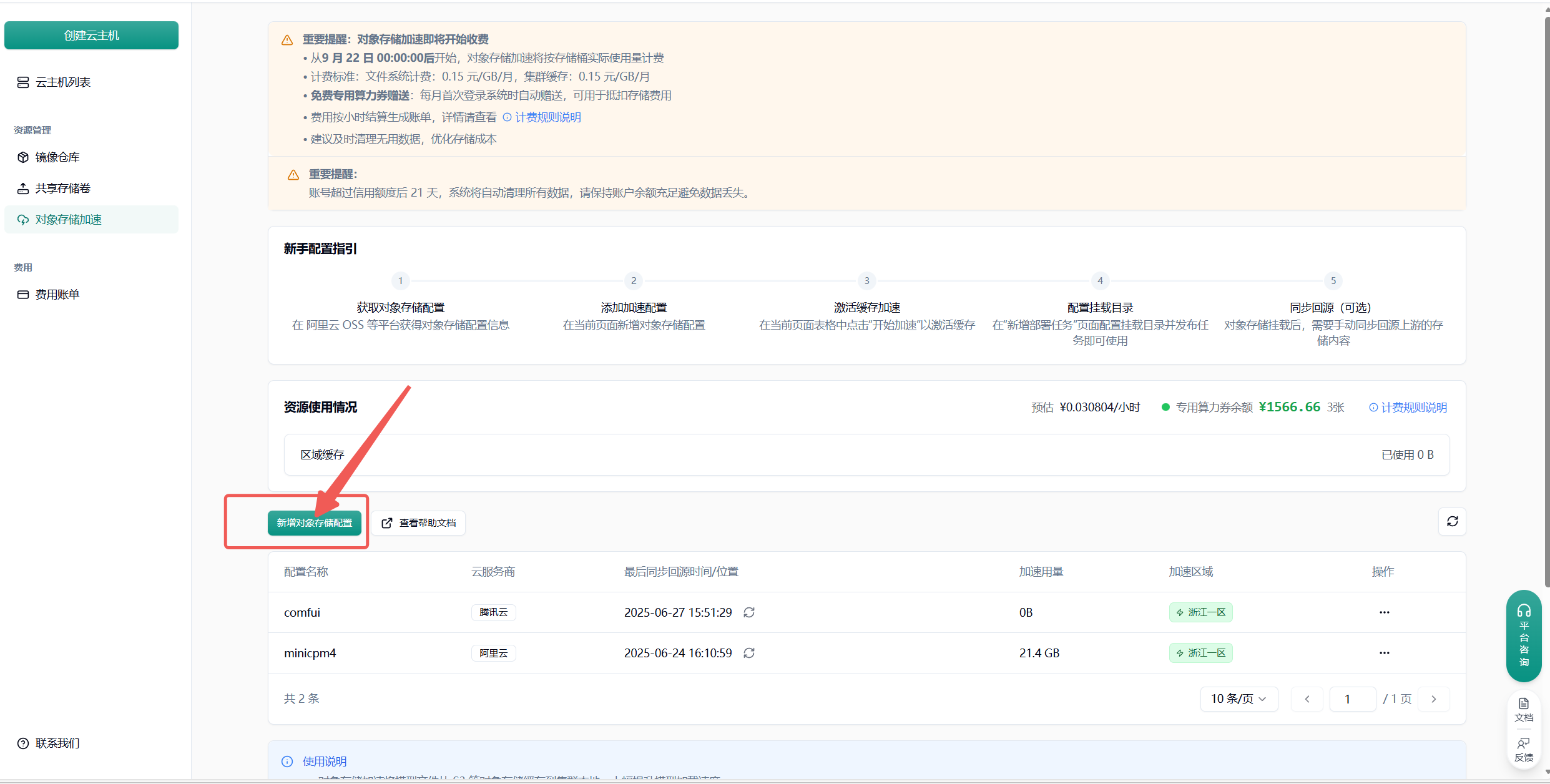
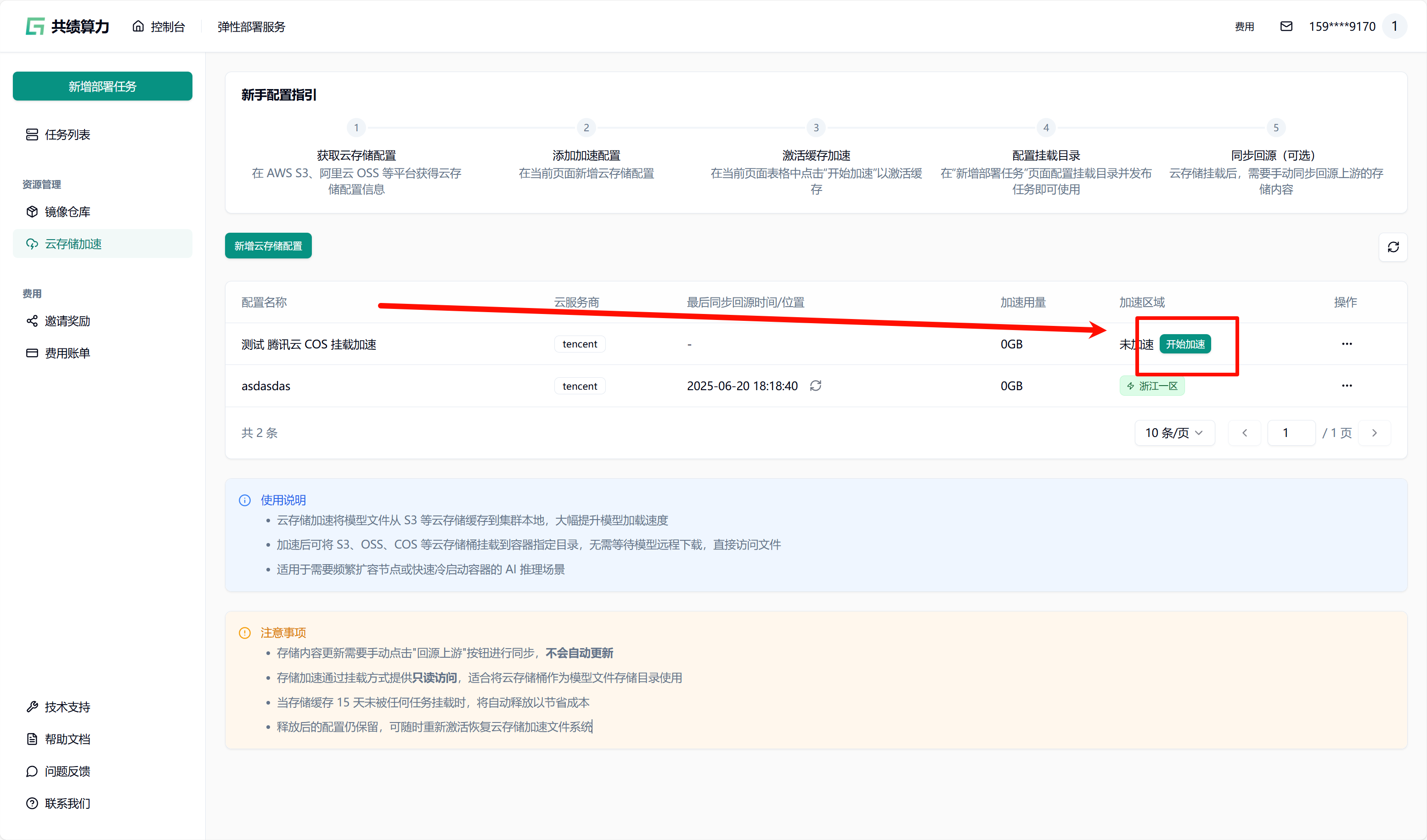
点击”新增对象存储配置”按钮,选择云服务商,填写以下信息:
- 配置名称
- 对象存储:服务商、地域、Endpoint(不能带 Bucket)、AccessKey、SecretKey、Bucket 名称
- 加速目录:Bucket 中需进行加速处理的目录(不建议挂载根目录,因这会致使根目录下所有文件被缓存,占用大量空间,且不利于业务的合理分割)
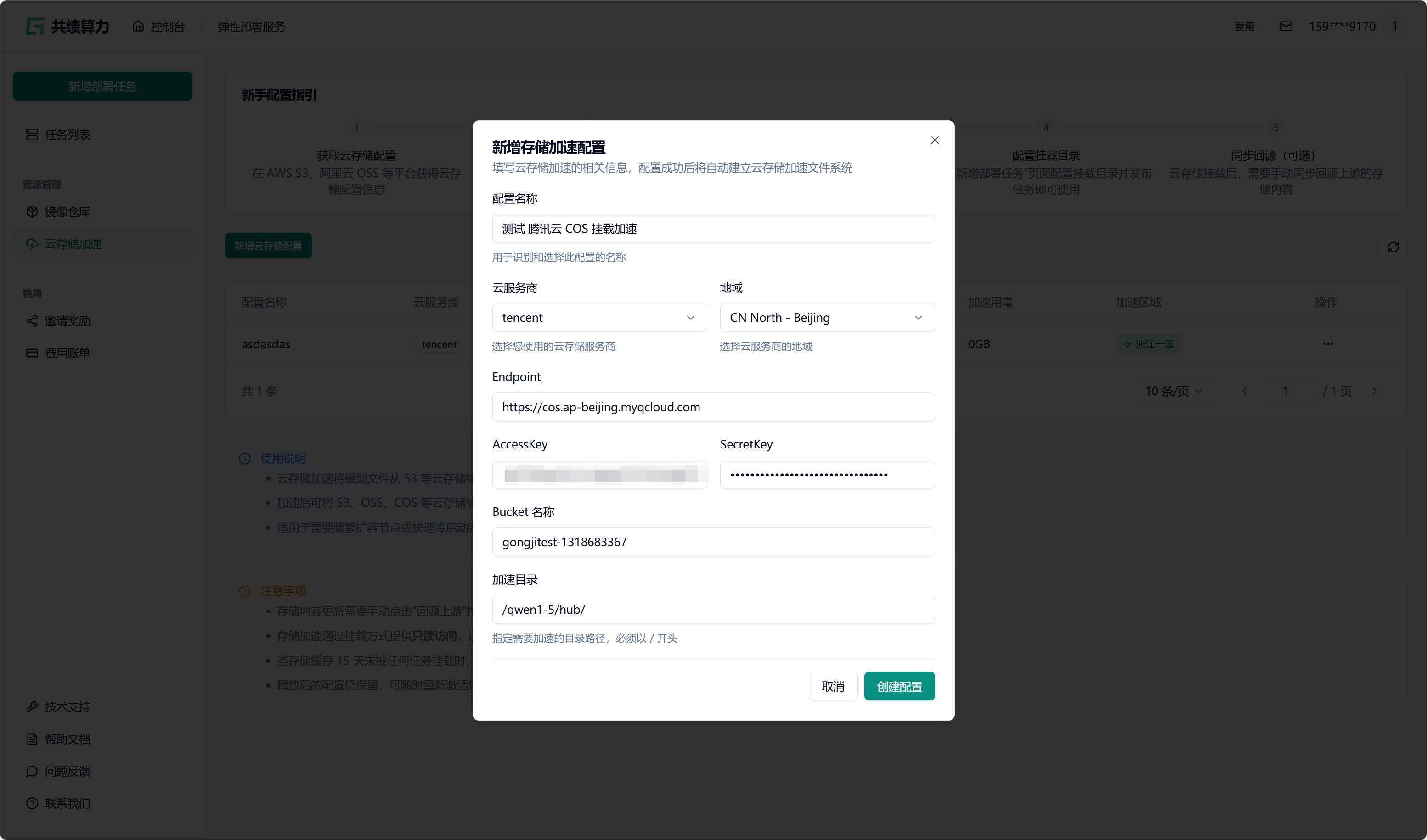
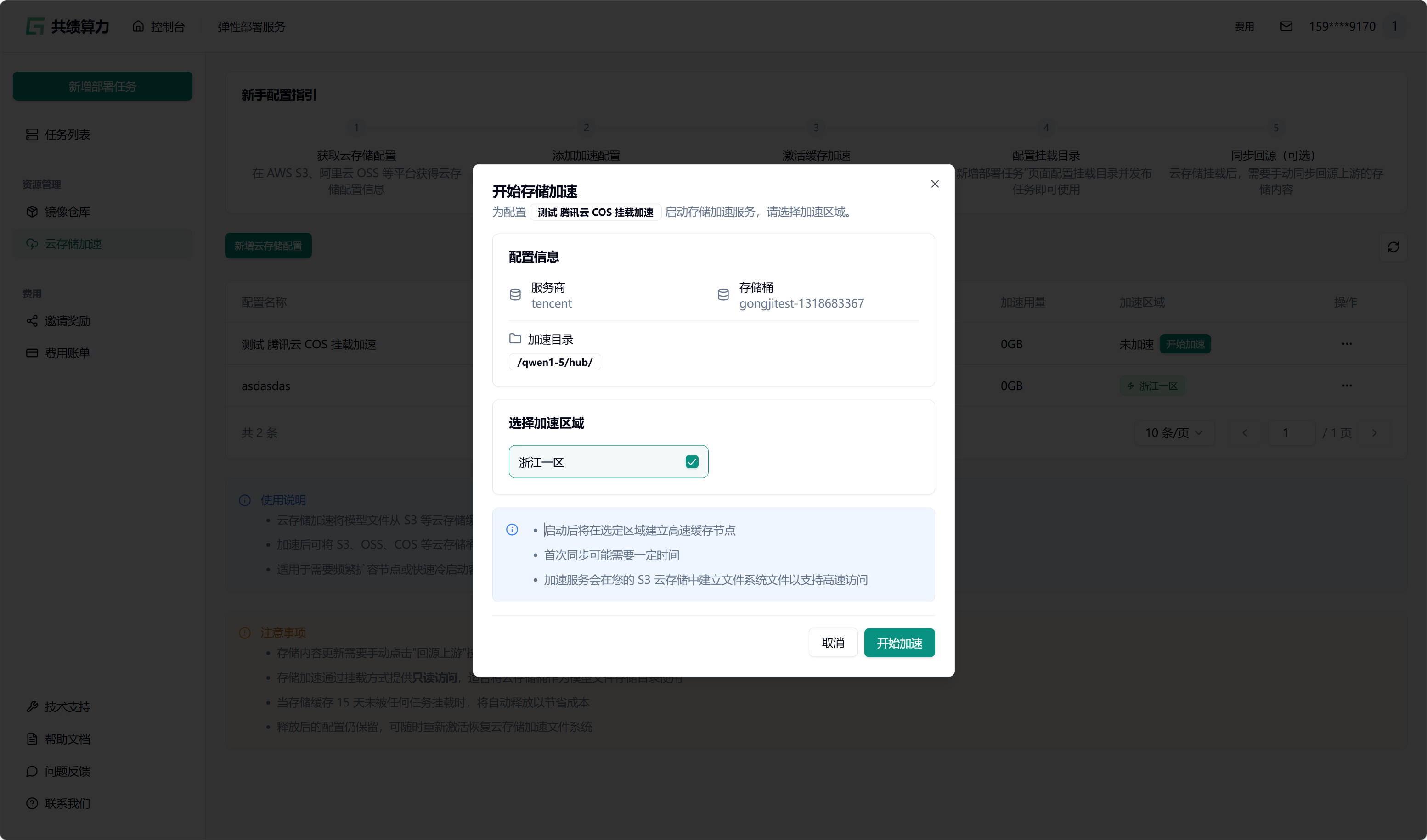
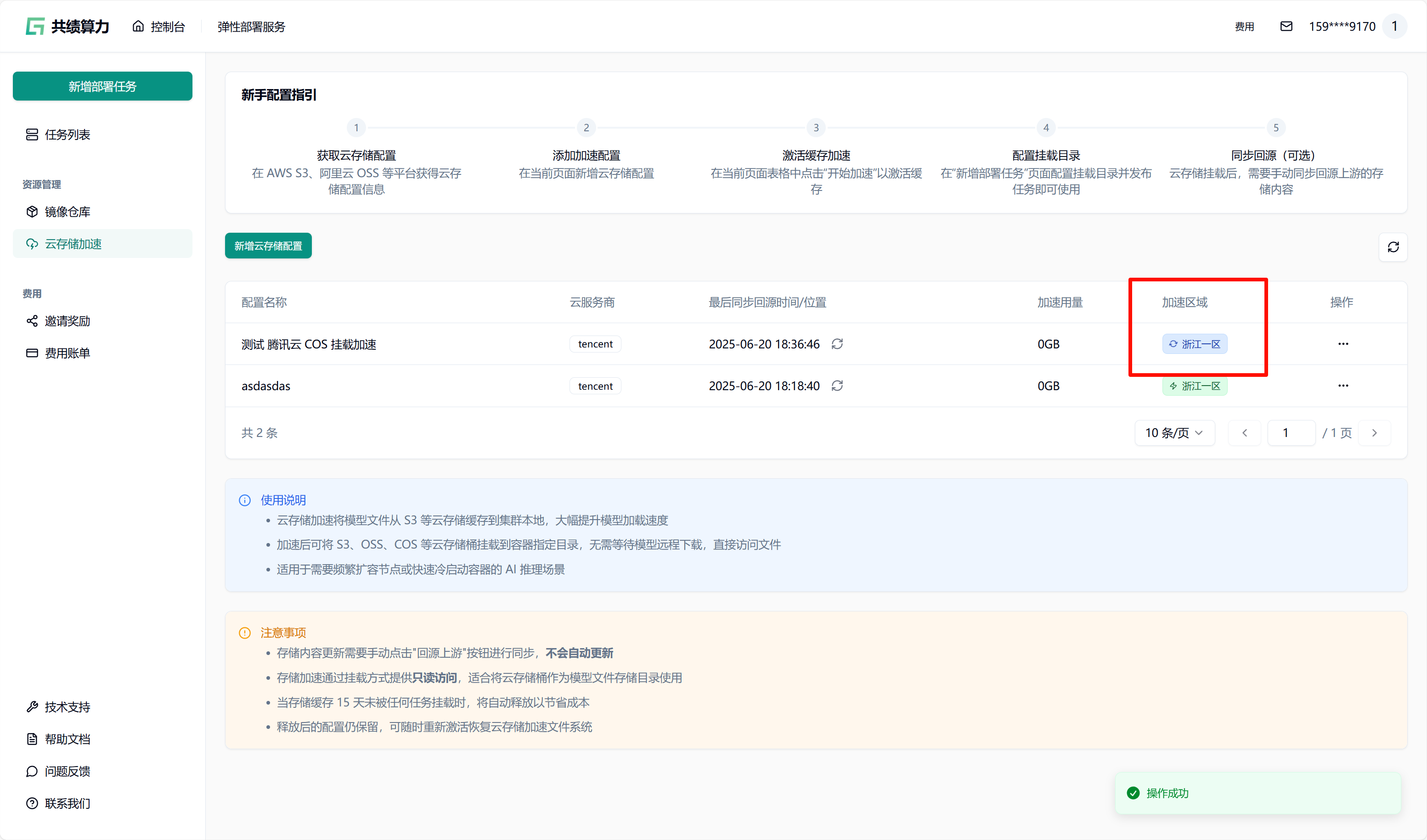
当执行保存配置操作时,系统会自动对配置的可用性进行检测。只有在校验通过之后,配置才可成功保存。在列表中查找到相应配置后,点击“开始加速”选项,接着选择加速区域,此时系统将自动对 JuiceFS 文件系统进行初始化(此过程约需 1 - 2 分钟,期间状态会从蓝色转变为绿色,状态为绿色时已可以挂载此存储桶)。同时,系统还会执行提前预热操作(此操作需从云端将文件下载至本地,因此需等待一定时长。例如,若文件大小为 6.6 G,下载完成大约需要 30 分钟)。
任务发布时挂载
先选择 GPU、GPU 区域(需要与对象存储选择的加速区域一致)。我的对象存储加速了“浙江一区”,所以我选择“浙江一区”的 4090 GPU。
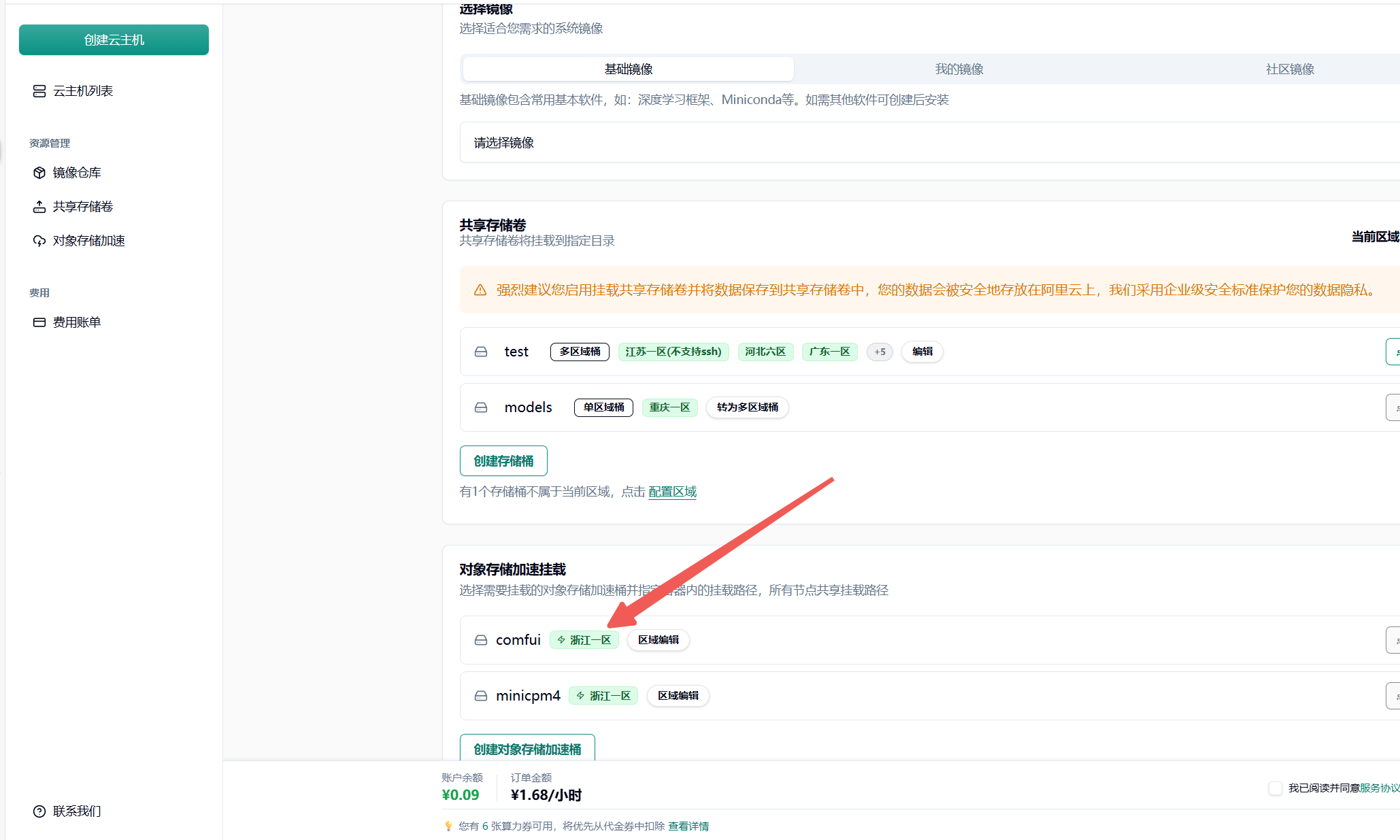
然后在任务发布页面的”存储配置”区域,选择已配置并加速的 S3 存储桶(当前状态为绿色时,可以直接挂载。集群内第一次使用需要等待从云端拉取文件到集群。此操作需从云端将文件下载至本地,因此需等待一定时长。例如,若文件大小为 6.6 G,下载完成大约需要 30 分钟。集群第二次挂载则会直接从本地拉取模型文件)。
为每个对象存储加速目录填写容器内的挂载路径(如 /mnt/my_model_data),路径需以 / 开头。需要注意两个目录的对应关系。
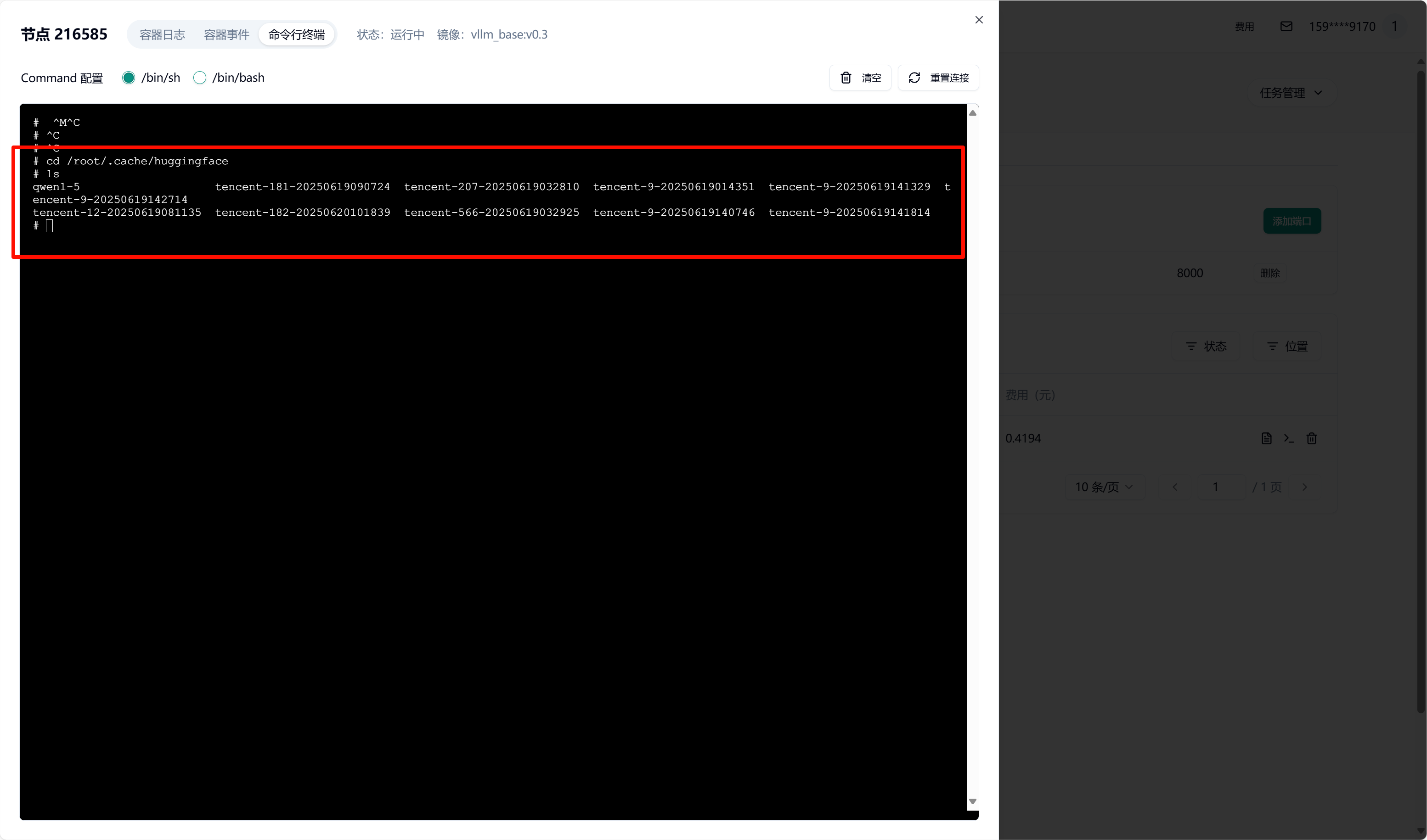
我这里将对象存储 Bucket 中的 /qwen1-5/hub/挂载到了容器中的 /root/.cache/huggingface 目录中
提交任务后,容器启动时会自动挂载所选 S3 存储。待容器启动完成后,可进入容器并验证挂载。查看挂载目录下的文件是否存在
详细配置细节可以参考对象存储加速文档
附录 2 共享存储卷中放置模型
Section titled “附录 2 共享存储卷中放置模型”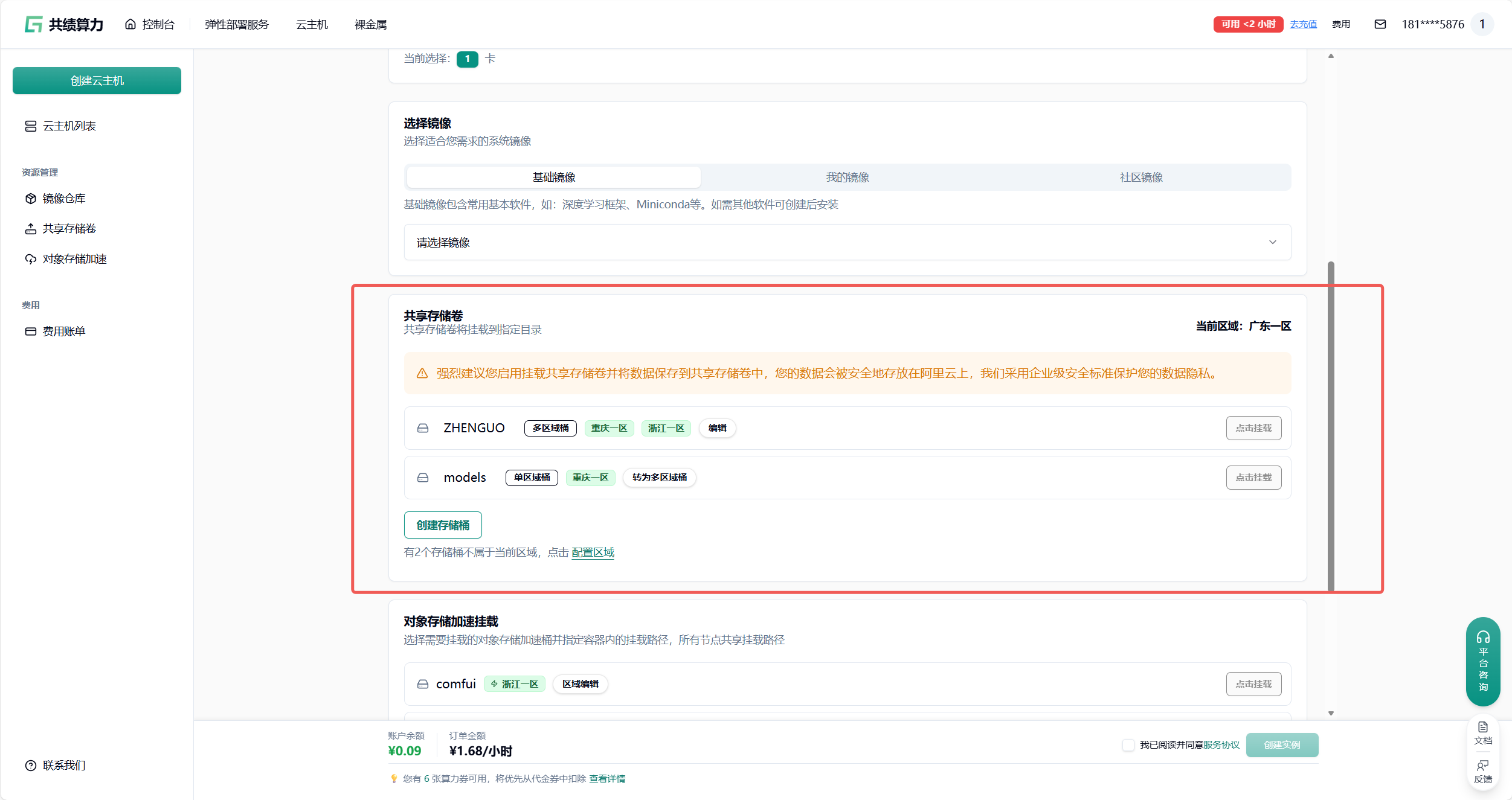
创建新的存储桶:
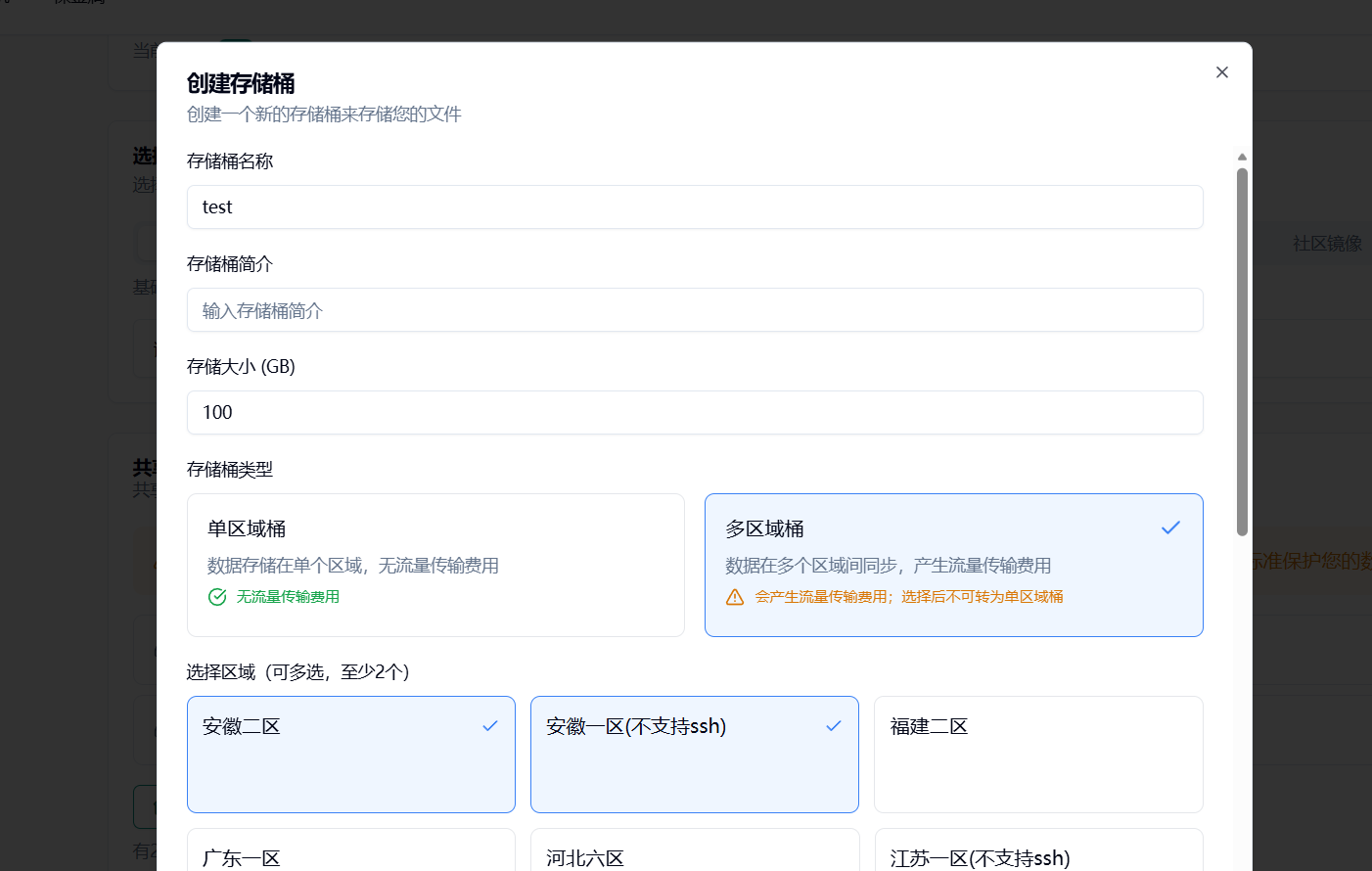
重要提醒:
• 存储桶共享 200.0 GBGB 总容量,可创建多个存储桶
• 单区域桶无流量传输费用,多区域桶会产生区域间同步费用
• 某地区未使用节点 15 天后,缓存组将被自动释放
• 多实例同时读写可能存在短暂延迟,但保证最终一致性
• 建议定期使用存储桶以避免节点释放影响
配置完成后输入挂载路径
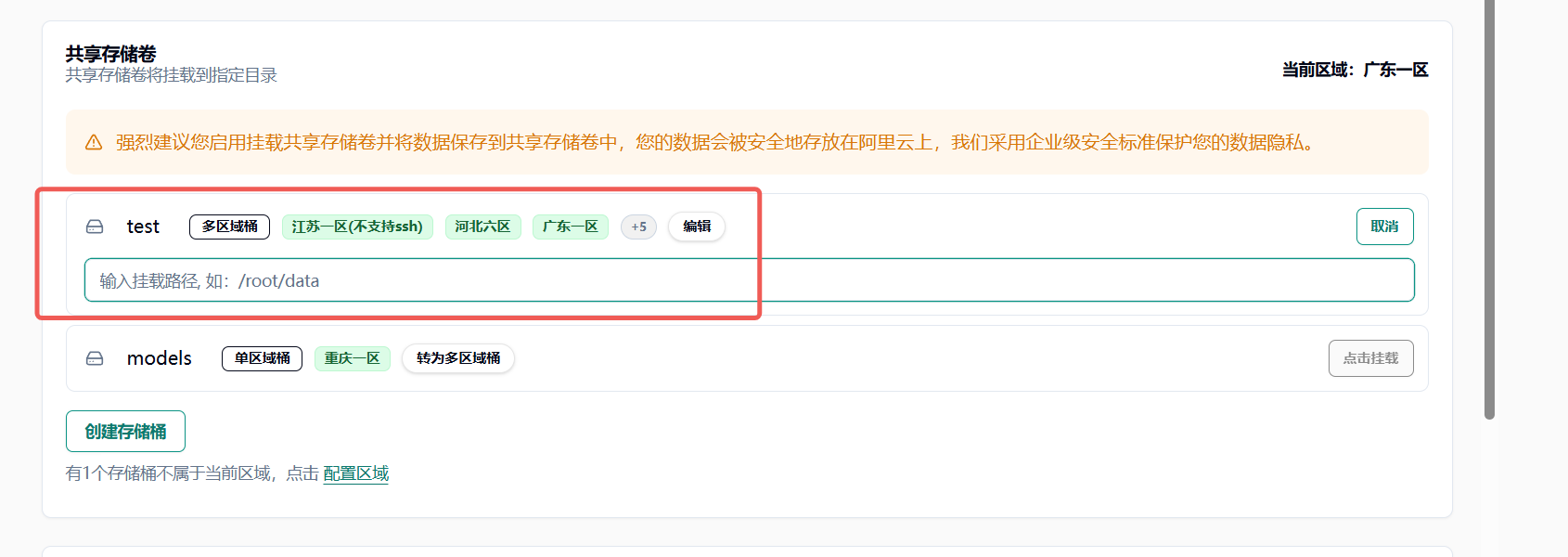
在 jupyterlab 中将模型相关配置下载在挂载路径中(例如 /root/data)以实现多机数据共享 达到镜像和模型的分离