1. 引言:文生图技术的痛点与突破

Qwen 团队发布了其系列中的最新力作——Qwen-Image,一个在文生图领域,尤其是在复杂文字渲染和精准图像编辑方面取得重大突破的基础模型。许多用户惊艳于它生成清晰、美观中英文文字的能力,彻底告别了以往 AI 绘画中常见的“文字乱码”问题。那么,Qwen-Image 是如何做到这一点的呢?本文将依据其技术报告,带你一探究竟,深入了解其背后的模型原理与精妙的训练策略。
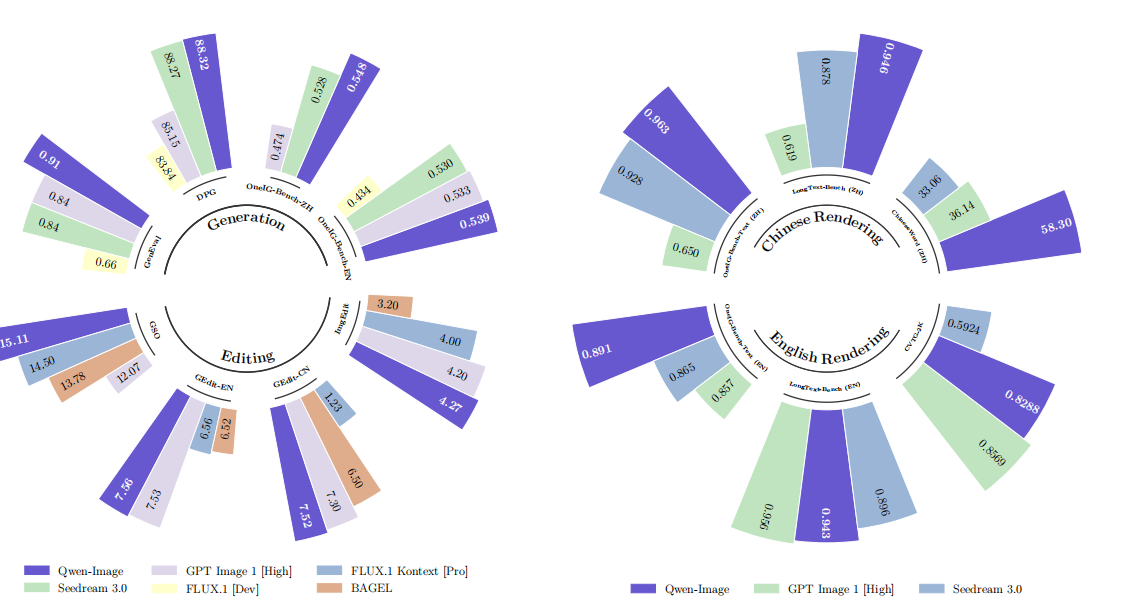
在多个公开基准测试中的评估表明,Qwen-Image 在各类生成与编辑任务中均获得 SOTA(最先进)水平的表现,充分证明了其作为强大图像生成基础模型的实力。

2. 三大架构创新:理解与生成的完美解耦
2.1 创新一:条件编码的革命性改变
传统做法的问题
以前的条件编码主要依赖纯文本编码器,比如 CLIP 或 T5。这些编码器在处理多模态信息时,图文对齐的效果并不理想,特别是对中文的支持比较弱。
Qwen-Image 的解决方案
他们直接使用了 Qwen2.5-VL 多模态大模型作为条件编码器。这个选择很聪明,因为 VL 模型本身就具备图文理解能力,能够更好地理解文本和图像之间的语义关系。而且原生支持中文,解决了我们之前遇到的中文处理问题。

2.2 创新二:图像编解码的双重优化
传统架构的局限
传统的做法是用单一的图像 VAE 来处理所有任务。这种设计在细节重建方面存在瓶颈,特别是文本细节的还原效果不够理想。
Qwen-Image 的突破
他们采用了视频通用 VAE + 微调图像解码器的组合方案。这个设计的巧妙之处在于,视频 VAE 天然具备处理时序信息的能力,能够更好地保持图像的一致性和连续性。通过微调图像解码器,他们实现了文本细节重建提升 5-7 dB 的效果。
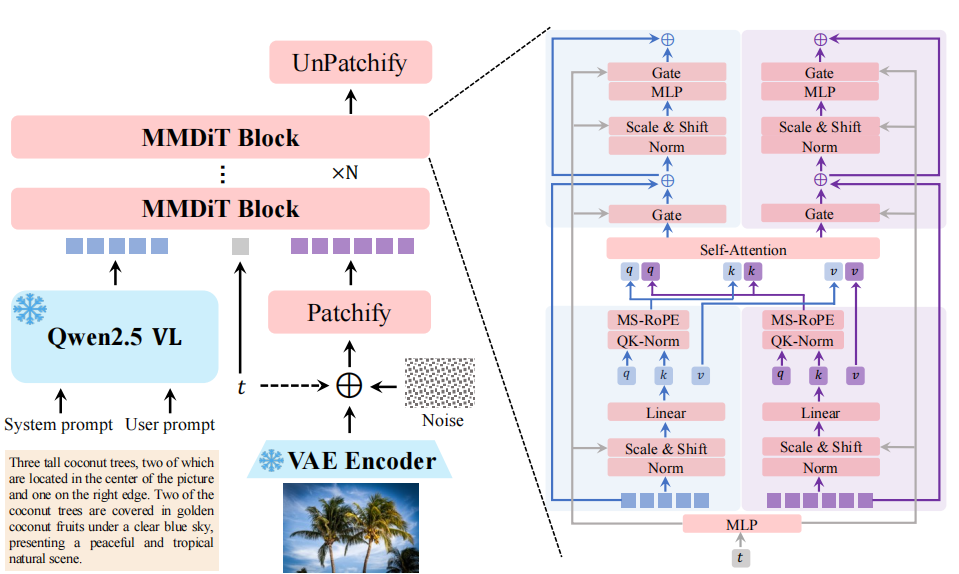
2.3 创新三:扩散骨架的维度对齐
传统 DiT 的问题
单流 DiT 在处理不同维度的信息时,文本 token 和图像 patch 之间往往存在维度不匹配的问题,这限制了模型对任意分辨率的支持。
Qwen-Image 的改进
他们引入了双流 MMDiT + MS-RoPE 的架构。MMDiT 能够同时处理多个模态的信息,而 MS-RoPE 则确保了文本 token 与图像 patch 在相同维度上的对齐。这样设计的好处是,模型能够支持任意分辨率的输入,不再受限于固定的尺寸。

3. 数据炼金术:从海量到精炼的七重过滤
3.1 数据处理的挑战与策略
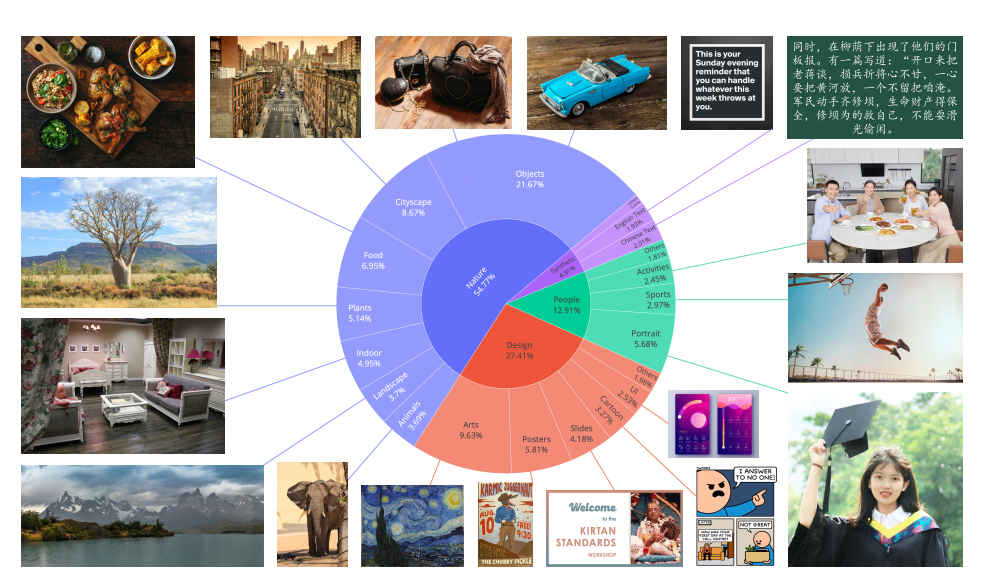
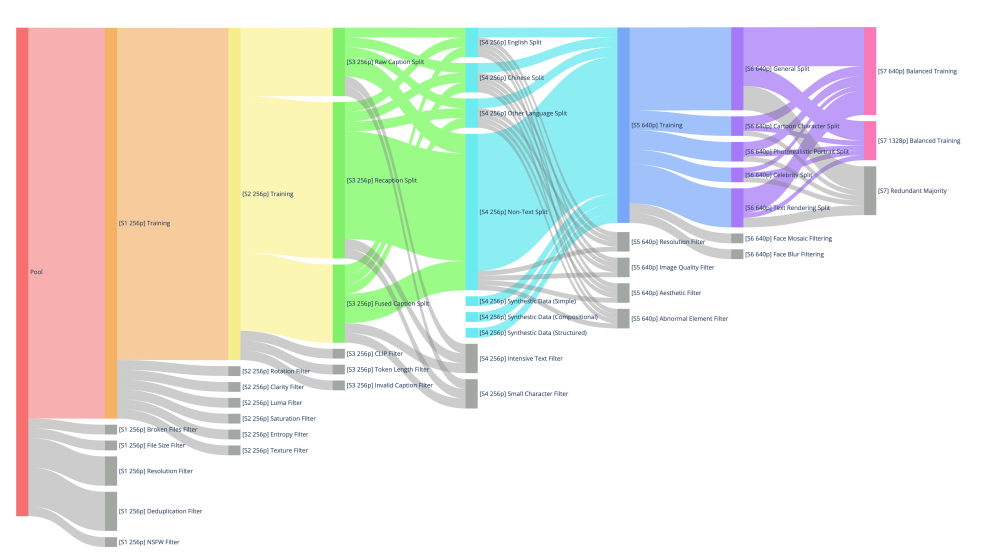
训练一个高质量的 AI 模型,数据质量比数据数量更重要。Qwen-Image 团队设计了一个七级数据精馏管线,把 5B 原始图文对浓缩为 1.2B 高质量样本。
第一到第三级:基础清理
去重、去噪、去 NSFW 内容
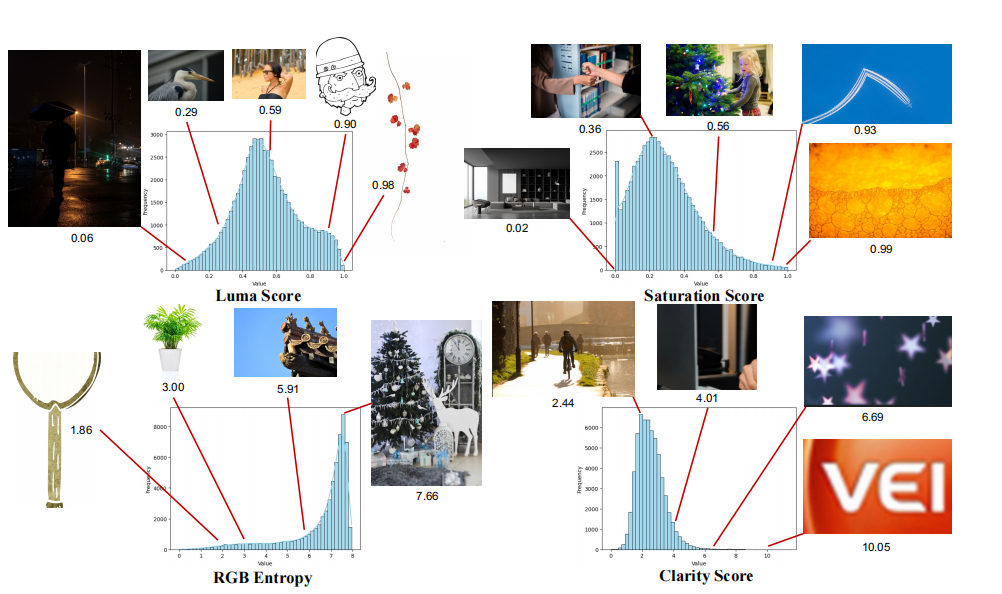
美学评分 + 清晰度评估 + 旋转矫正
图文一致性验证(CLIP/SigLIP 双保险)
第四级:文本渲染专项增强
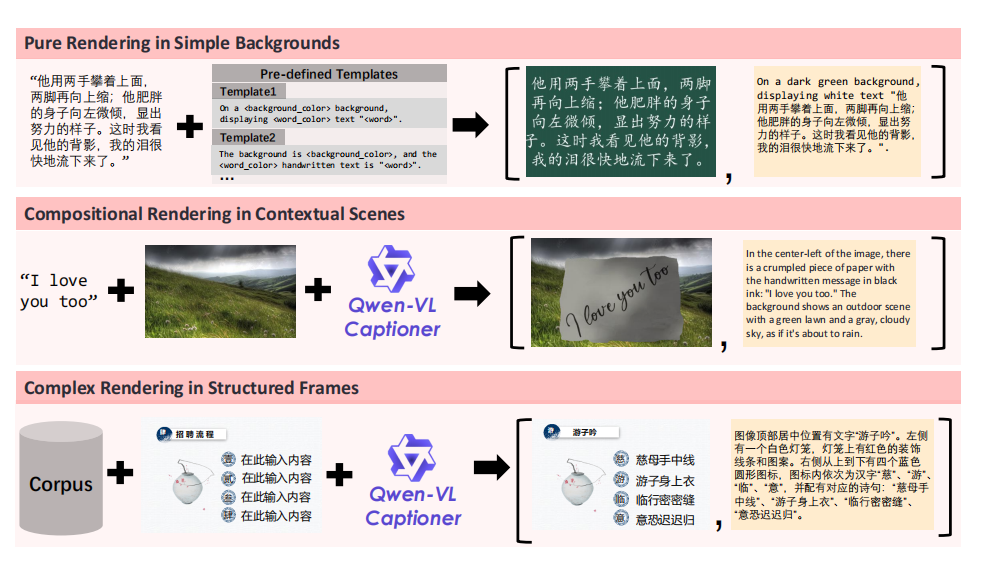
这是最让我感兴趣的部分。他们合成了 8000 万中英段落,专门用于训练模型的文本渲染能力。中文文本渲染数据占总合成量的 45%,覆盖了 8105 个常用字。
第五到第七级:精细化处理
高分辨率(1328 px)美学再筛选
类别均衡 + 人像增补
多尺度联合训练(640 px & 1328 px)
3.2 真实 + 合成的混合策略
他们的数据处理策略很有启发性:先用合成数据”教会”模型字形,再用真实场景数据”教会”排版。这种渐进式的训练方法,避免了模型过度依赖合成数据,提高了泛化能力。
4. 训练策略:课程式学习的智慧
4.1 分阶段训练的设计思路
Qwen-Image 采用了类似人类学习的课程式训练策略,从简单到复杂,逐步提升模型能力:
S1-S2 阶段:基础能力培养
分辨率:256 px
重点:通用场景理解、基本构图能力
目标:建立语义对齐的基础
S3-S4 阶段:文本渲染入门
分辨率:256 px
重点:引入合成文本数据
目标:掌握字符级渲染能力
S5-S6 阶段:高分辨率挑战
分辨率:640 px
重点:高分辨率处理、复杂布局理解
目标:段落排版、中英混排能力
S7 阶段:细节完美主义
分辨率:1328 px
重点:人像细节、文本质量双强化
目标:细节保真、身份一致性
4.2 技术实现的亮点
Producer-Consumer 异步管线
这个设计很巧妙,GPU 只负责训练,CPU 集群负责 VAE 和 MLLM 的预处理工作。这样分离的好处是,整体吞吐提升了 2.4 倍,避免了 GPU 资源的浪费。
混合并行策略
他们使用了 4-way Tensor Parallel + ZeRO-3 的组合,单卡 80G A100 就能跑 1328 px 的训练。这种配置对硬件要求相对友好,很多研究机构都能负担得起。
5. 评测结果:全面领先的技术实力
5.1 基准测试的压倒性优势
Qwen-Image 在多个公开基准测试中都表现出了明显的优势:


5.2 中文场景的碾压级表现
最让我印象深刻的是,Qwen-Image 是首个在中文长文本渲染上超过 90% 准确率的模型。这个成绩对于中文 AI 应用来说意义重大,因为中文的复杂性和多样性比英文更具挑战性。

6. 能力全景:不只是文生图,更是视觉操作系统

6.1 文本渲染的全面能力
多语言支持
- 支持多行、段落、混合语言
- 自动排版、换行、对齐
- 可生成手写、印刷、霓虹、雕刻等 20+ 风格文字
排版智能
模型能够理解文本的语义结构,自动调整字体大小、行间距、对齐方式,生成专业级的排版效果。
6.2 图像编辑的精确控制
对象级编辑
- 增删改换:可以精确地添加、删除、修改图像中的对象
- 保持一致性:编辑过程中保持背景、光影、身份等要素的连贯性
风格级转换
- 风格迁移:油画→真人、日漫→水墨,一键完成风格转换
- 保持内容:在改变风格的同时,保持原始内容的完整性
结构级调整
- 姿势调整:改变人物姿势而不影响其他部分
- 视角旋转:调整观察角度,生成新的视角
- 景深控制:精确控制图像的景深效果
6.3 理解任务的零样本能力
最让我惊讶的是,Qwen-Image 仅用编辑接口就能零样本完成深度估计、分割、超分、新视角合成等任务,效果逼近专用模型。这说明模型对图像的理解已经达到了相当高的水平。
8. 技术架构的深度思考
8.1 设计理念的先进性
Qwen-Image 的最大价值不在于又多了一个”画图工具”,而在于展示了生成即理解的新范式。这种设计理念有几个重要的优势:
语义理解的深度:通过将语言模型和图像模型的优势结合,Qwen-Image 能够更好地理解用户的意图,生成更符合要求的图像。
编辑的精确性:传统的图像编辑往往需要复杂的蒙版和图层操作,而 Qwen-Image 通过自然语言就能实现精确的编辑控制。
应用的广泛性:从简单的文生图到复杂的图像编辑,从静态图像到动态内容,Qwen-Image 的应用场景非常广泛。
8.2 技术实现的巧妙之处
模块化设计:三大创新模块相对独立,便于后续的升级和维护。每个模块都可以单独优化,不会影响整体架构。
资源利用效率:异步管线和混合并行策略,大大提高了训练和推理的效率,降低了硬件成本。
扩展性考虑:架构设计考虑了未来的扩展需求,为视频生成、3D 建模等功能预留了空间。
9. 结语:迈向视觉与语言的融合新时代
Qwen-Image 的成功,标志着人工智能技术在实现“视觉与语言统一体”方面迈出了重要一步。正如报告所言:
“当传统的语言模型难以用千言万语说清一幅画时,Qwen-Image 却能用一张图讲清楚千言万语。”
这种能力不仅体现在技术层面,更在实际应用中展现出巨大价值。借助 Qwen-Image,我们能够:
用自然语言精准控制图像生成,让创意表达更加直观高效;
通过图像编辑轻松完成复杂的视觉任务,提升创作效率;
在众多领域实现人工智能的落地应用,推动行业创新与发展。
展望未来,让我们携手将视觉与语言融合的用户界面,从概念变为触手可及的日常体验,开启智能交互的新篇章。
相关资源链接:
ModelScope 平台:https://modelscope.cn/models/Qwen/Qwen-Image
Hugging Face 平台:https://huggingface.co/Qwen/Qwen-Image
GitHub 开源代码:https://github.com/QwenLM/Qwen-Image
技术报告:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf
在线体验:
即刻登录「共绩算力」https://www.gongjiyun.com/ 全国边缘节点自动扩缩容。无论你训练大模型、生成音乐、渲染影像,还是上线多模态 AI 服务,都能让每一度绿电即刻化作澎湃算力——零门槛、零等待、零碳排,灵感从此落地!