扣子空间:
7629325fe04b48b7992009448bbc5a32.mp3
listenhub:
notebooklm:
The GPU_ Powering AI’s Parallel Future.wav
现在 AI 火得一塌糊涂,但新手朋友刚入门经常会犯嘀咕:为啥大家张口闭口都在聊 GPU?我这电脑里的 CPU 看着也挺强啊,为啥不能拿来跑 AI 呢?今儿咱就掰开揉碎聊聊这事儿,给刚入门的你一份实在的“算力”指南。

1.GPU 与 AI 的渊源:并行计算的重要性
当我们开始学习 AI 时,“你需要一块 GPU “这句话常常被提及。这不仅仅是一台普通笔记本电脑,也不是仅仅拥有强大 CPU 的设备。GPU 在 AI 领域的重要性源于其独特的并行计算能力。
1.1 GPU 的并行计算优势
GPU 最初是为图形处理而设计的,其架构专门针对并行任务进行了优化。与 CPU 专注于顺序处理不同,GPU 能够同时执行数千个小型计算任务。这种并行处理能力正是 AI 模型,尤其是神经网络模型所需要的。
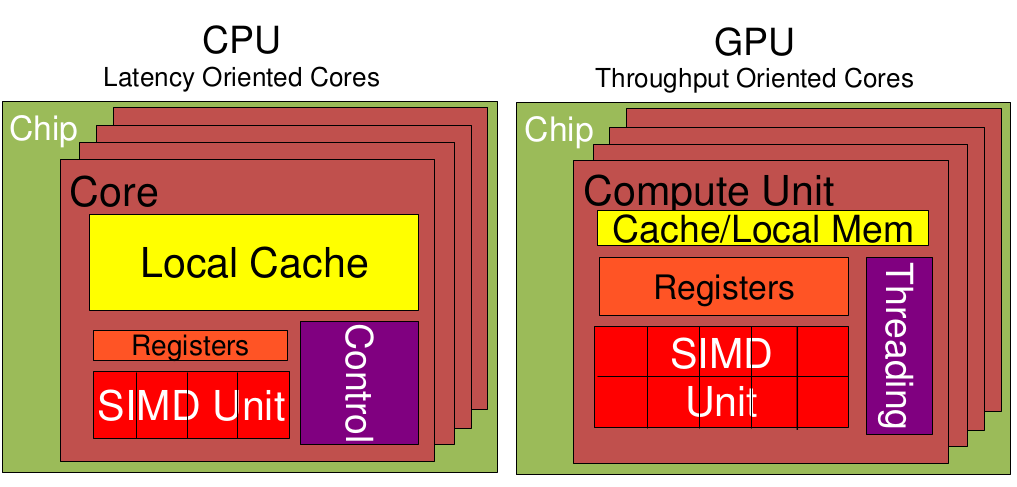
AI 模型的训练和推理涉及大量的矩阵运算和向量操作,这些操作本质上是并行的。GPU 的并行架构使得它能够同时处理这些计算任务,大大加速了 AI 模型的训练和推理过程。简单来说,GPU 的设计理念与 AI 算法的需求完美契合。
当我们将 GPU 与中央处理单元 (CPU) 结合使用时,会发生 GPU 加速计算,让 GPU 处理尽可能多的并行处理应用代码。GPU 采用的并行计算方法超出 CPU 几个数量级,提供数千个计算内核,这使得 GPU 成为 AI 计算的理想选择。

1.2 为什么并行计算对 AI 至关重要?
AI 工作负载涉及海量的并行计算。训练和运行 AI 模型意味着要并行执行数百万(甚至数十亿)次数学运算。每次模型做出预测时,它都在进行向量乘法、应用权重和调整参数。
这不仅仅是速度问题——更是规模问题。一个简单的模型在 CPU 上或许还能应付。但一个拥有数十亿参数的现代 LLM?你可能要等上几天——如果它能运行起来的话。这就是为什么 GPU 成为了 AI 默认的计算层。它们快速、高效,并且针对神经网络所依赖的数学运算进行了优化。
GPU 的并行计算能力使其特别适合处理深度学习中的矩阵乘法、卷积神经网络 (CNN) 等运算。在 GPU 上进行并行计算时,可以将矩阵分成更小的块,然后由不同的线程组同时计算这些块的乘积,最后将这些小块的结果组合起来形成最终的矩阵。
2.GPU:驱动人工智能(AI)的计算引擎
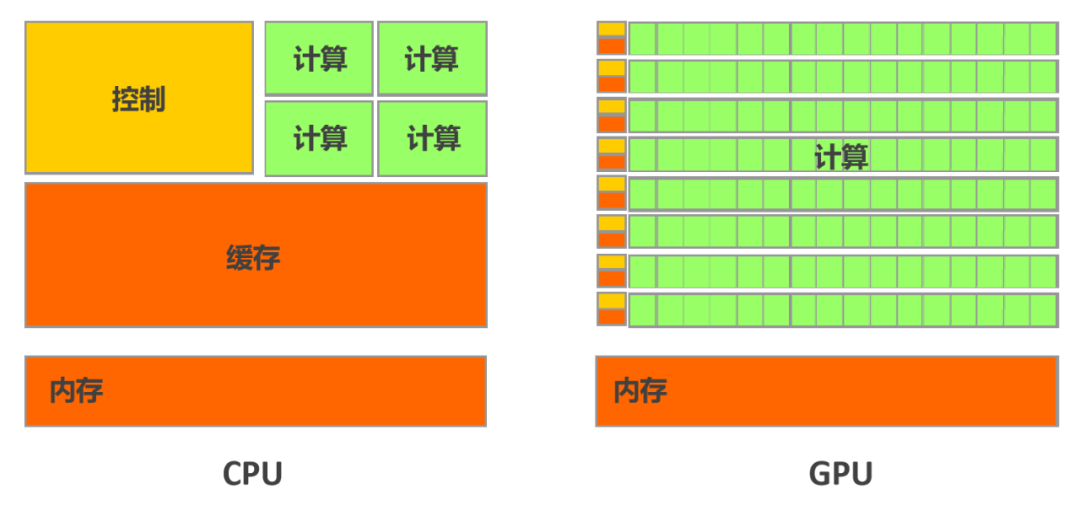
为啥 GPU 这么适合“多线程作业”?这事儿得从头说起。GPU 本来就是给图形处理设计的,比如疯狂渲染游戏画面。你想啊,一幅复杂的画面,每个像素点的颜色计算其实都差不多可以同时搞吧?所以它的硬件架构就是为了这种“同时做大量类似任务”而生的。这不巧了吗?AI 模型训练和推理,核心就是做海量的矩阵(想象成表格数据)运算和向量操作,这些运算的本质就是一个字——同时干!CPU 吭哧吭哧一个个算得冒烟,GPU 这边“唰”一下就搞定了。说白了,GPU 这体质,就跟 AI 是“绝配”。
-
GPU 的压倒性优势:
- 极致算力 (FLOPS): 提供超高的浮点运算速度(如 A100 达 5PFLOPS),快速处理海量计算。
- 专用硬件加速 (Tensor Core): 对 AI 核心运算(矩阵乘法)进行硬件级加速。
- 超大内存带宽: GPU 显存带宽(如 A100 达 2TB/s)远超 CPU(数十倍),数据传输速率成为处理需要反复加载参数的 AI 任务(如文本/图像生成)的关键。
- 卓越能效比: 单位功耗下完成远超 CPU 的计算工作。
-
协作关系: CPU 作为系统中枢,负责调度、资源管理、通信协调及部分数据预处理/后处理。部分 CPU 内置 NPU(神经处理单元)可与 GPU 协同加速 AI 推理。
2.3 选择 AI GPU:关键性能指标解读
- 显存容量 (VRAM): 决定能够运行的模型大小和批处理输入量。容量不足会导致无法加载模型或需要极小的批次大小,显著降低性能或引发内存不足错误 (OOM)。
- Tensor 核心 (Tensor Cores): AI 加速专用硬件核心(尤其在 NVIDIA GPU 中),大幅优化深度学习的关键运算(如矩阵乘法)。
- 计算吞吐量 (Throughput): 常以 TFLOPS (每秒万亿次浮点运算) 衡量。更高的 TFLOPS 意味着更高的计算密度,直接带来更快的训练/推理速度。
- 核心架构 (Architecture): 新一代 GPU 架构(如 NVIDIA Hopper/H100, Ada Lovelace/RTX 40 系列)引入了优化的指令集、更高的 IPC(每时钟周期指令数) 以及对 Transformer 等大模型操作的原生硬件支持,显著提升效率和性能,尤其在大规模语言模型 (LLM) 处理上优势显著。
2.4 GPU 型号对比与选型策略
-
消费级 GPU (如 RTX 4090):
- 优点: 高性价比,适合个人研究/实验、中小模型推理、轻量级训练。新一代产品(如 RTX 4090)在特定推理任务上性价比可能媲美甚至超越专业卡。
- 缺点: 通常缺乏完整的专业特性(如极高 FP64 性能)、ECC 内存、强大的多 GPU 互联(如 NVLink)和官方企业支持。
-
专业级 GPU (如 H100, A100, L4):
- 优点: 超高计算密度、强大的多 GPU 扩展能力、企业级稳定性和特性支持(大显存、高精度、高速互联),是大规模训练和推理部署的工业标准。
- 缺点: 价格昂贵。
-
选型要点 (性价比 = 合适>最贵/最强): 任务需求: 是训练巨型模型?还是部署推理服务?模型大小、精度要求? 预算限制: 严格控制成本?还是有充足预算? 扩展性考量: 未来是否需要多卡并行? 能效评估: 大规模部署下,能效比高的卡(如 L4,P4)长期运营成本更低。 对比参考: 考虑特定优化型号(如 A800/H800)或旧旗舰(如 V100 32G)以平衡预算与性能。明确“需要满足基本需求”和“追求极限性能”的区别。
3.云 GPU 服务:初学者的理想选择
如果你有一台配备 RTX 3090 的游戏 PC,那么这是学习 AI 的可靠起点。但是在本地训练或运行大型模型存在局限性:
上限是一张卡(除非构建了多 GPU 设备)支付了电费 无法轻松扩展…
这就是云 GPU 的用武之地。在共绩算力(https://www.gongjiyun.com/)平台上,可以按需使用所需 GPU 启动计算机 —— 时长灵活至几分钟、几小时或几个月,无前期硬件成本,无需关注基础设施问题,仅需聚焦核心计算需求。支持通过无服务器终端节点完全跳过设置,进一步降低使用门槛。
3.1 无服务器 GPU
作为国内首个专注 AI 推理服务的 GPU Serverless 平台,共绩算力提供无服务器 GPU 节点,其核心优势在于:无需管理任何基础设施,仅需发送一个请求(如 API 调用),即可获取模型推理结果。
等等 —— 节点到底是什么?
若您对开发术语不熟悉,“节点”可能听起来像某种复杂的技术概念。实际上,节点只是一个“请求 - 响应”的在线桥梁:您发送输入(如文本提示或图像生成需求),共绩算力的无服务器 GPU 会自动调度资源、运行模型,并将结果返回给您。整个过程无需手动部署、无需管理节点,真正实现“仅需关注结果”的极简体验。
共绩算力的无服务器 GPU 基于 智能调度网络 聚合全国海量闲置 GPU(包括个人消费级显卡),结合随流量自动弹性扩缩容和按量计费模式,能在保障响应速度(秒级冷启动)的同时,当前这一模式可以为您的推理任务节省大量时间与资金,显著降低算力成本。
弹性部署服务-Serverless 基础认识:https://www.gongjiyun.com/docs/y/OFL0wHeYsi5kWHkh2nfcOwnhnxf/ZelUwbyiIiLlgskxfMRc2ytsn0e.html
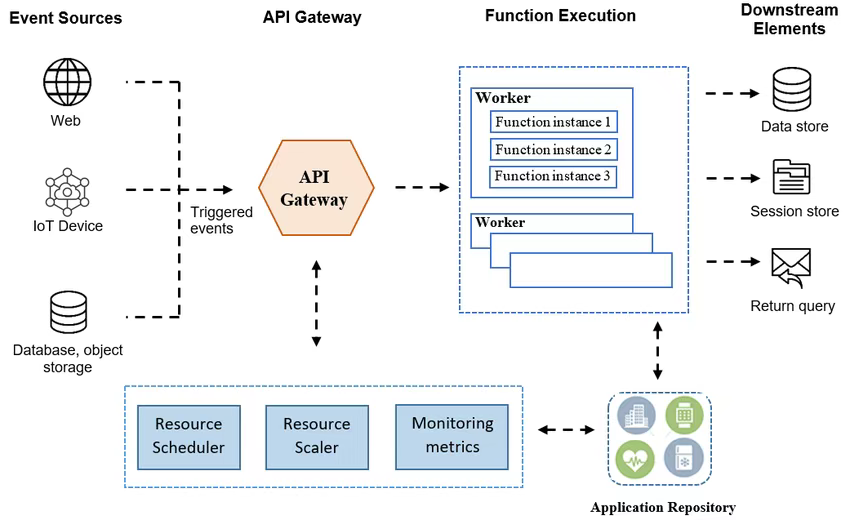
Serverless 架构工作机制示意
3.2 应该选择哪种 GPU?
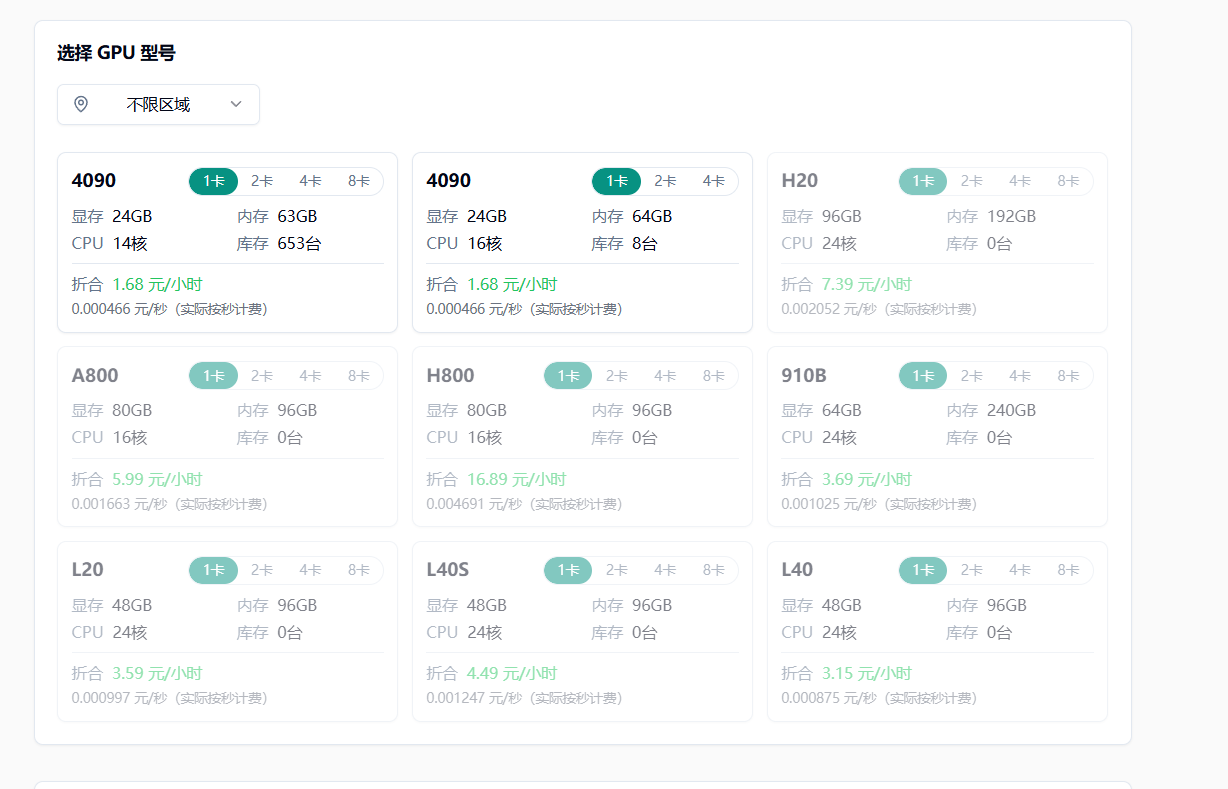
刚刚开始运行小型模型:
- 4090 – 经济实惠、功能强大,非常适合大多数入门级 LLM 或图像生成。
如果要纵向扩展:
- ⚡ A100 – 非常适合训练或运行具有高 VRAM 要求的大型模型
- 🚀 H20 – 适用于超高吞吐量工作负载或大规模模型推理的最新、最出色的产品
如有疑问?从 4090 开始。一旦达到限制,随时可以在不影响任务的情况下随意扩大规模。
想自己尝试一下吗? 此处体验我们预制好的服务,在几分钟内启动模型 - 无需代码。
5.总结
从并行计算的底层优势,到 Tensor Core 的硬件级加速;从消费级显卡的性价比之选,到专业级 GPU 的工业标准——GPU 已深度嵌入 AI 技术的每一步演进,成为人工智能从“概念”到“落地”的核心引擎。
对于无代码初学者而言,GPU 不再是高不可攀的“硬件壁垒”:云 GPU 服务(如共绩算力)提供了灵活小时计费、无服务器部署等极简模式,让你无需购买硬件、无需管理基础设施,即可快速开启 AI 实践;而模型轻量化、终端智能化的趋势,更让 AI 学习的门槛从“专业设备”降至“手机/PC”。
展望未来,随着 AI 算力需求持续激增、GPU 技术加速创新、计算模式向场景化适配,AI 的边界将被不断拓宽。无论是尝试图像生成的爱好者,还是探索行业模型的开发者,深入理解 GPU 的特性、合理选择算力资源(如从 4090 起步,按需升级至 A100/H20),都将是在 AI 浪潮中抓住机遇的关键一步。
愿每一位初学者,都能以 GPU 为翼,在 AI 的世界里自由翱翔。

立即访问 suanli.cn,开启您的 AI 推理新纪元,让算力不再是您创新的瓶颈!