1. 嵌入模型基础与原理
1.1 背景与发展历程
嵌入模型是 AI 驱动的搜索、检索和推荐系统的基础。但是,Hugging Face 上有超过 100,000 个嵌入模型,选择理想的模型通常涉及在准确性、嵌入速度和成本之间进行复杂的权衡,尤其是当模型在不同应用中表现出色时。
根据我们从技术基准、客户反馈和内部测试中学到的知识,我们策划了这份嵌入模型列表,以帮助您自信地选择合适的模型来构建从代理到 RAG 管道再到推荐引擎的所有内容。
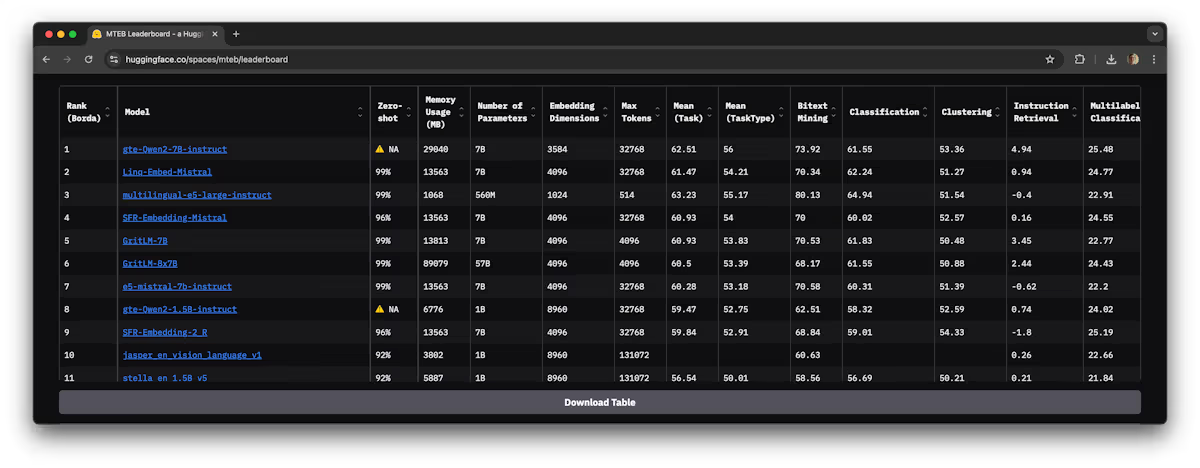
2025 年 6 月 MTEB 排行榜上排名靠前的开源 instruct-tuned 嵌入模型
1.2 工作原理与核心机制
嵌入模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量(如 768 维或 3072 维)对数据进行表达,模型能够捕捉其中的语义信息,使得语义相近的内容在向量空间中的距离更短。例如,“忘记密码”和“账号锁定”这两个短语会被编码为彼此接近的向量,从而支持基于语义的检索,而不仅仅依赖关键词匹配。嵌入模型的核心任务,是将非结构化数据转化为高维向量,使计算机能够用数学方式理解和比较不同内容之间的“语义距离”。常见的实现方法包括神经网络编码器、对比学习和聚类等。以文本为例,模型会将每个句子或段落编码为一个向量,向量之间的距离则反映了它们在语义上的相似程度。
1.3 典型应用场景
嵌入模型广泛应用于语义检索、智能问答、推荐系统、RAG(检索增强生成)、文本聚类、异常检测等领域。例如,企业知识库问答、智能客服、个性化推荐、代码搜索等都离不开高质量的嵌入模型。
1.4 常见问题与误区
初学者常见的误区包括:误以为嵌入模型只能处理英文文本、忽视了模型参数量对推理速度的影响、过度依赖榜单而忽略实际业务需求等。建议结合实际场景和数据进行实验和评估。
2. 主流开源嵌入模型详解
2.1 代表性模型盘点
目前,开源社区涌现出多款高质量的嵌入模型。
BAAI bge-en-icl 是由北京智源人工智能研究院(BAAI)推出的通用英文嵌入模型,拥有 7B 参数,适合大规模英文文本检索、RAG、智能问答等场景。
Mixedbread Embed Large V1 以 330M 参数实现了极高的性价比,推理速度快,效果接近 OpenAI 的 text-embedding-3-large,非常适合资源有限或对成本敏感的应用场景。

Nomic Embed Code 专为代码检索和代码相似度分析设计,拥有 7B 参数,能够更好地理解代码语义。
BAAI bge-reranker-v2-m3 主要用于 RAG 系统中的重排序环节,参数量为 279M,能够在初步检索后对候选内容按相关性重新排序。
AllanAI Llama 3.1 Tulu 3 8B Reward 是一款奖励模型,拥有 8B 参数,适用于强化学习(RL)和 AI 代理反馈场景。
2.2 模型架构与技术细节
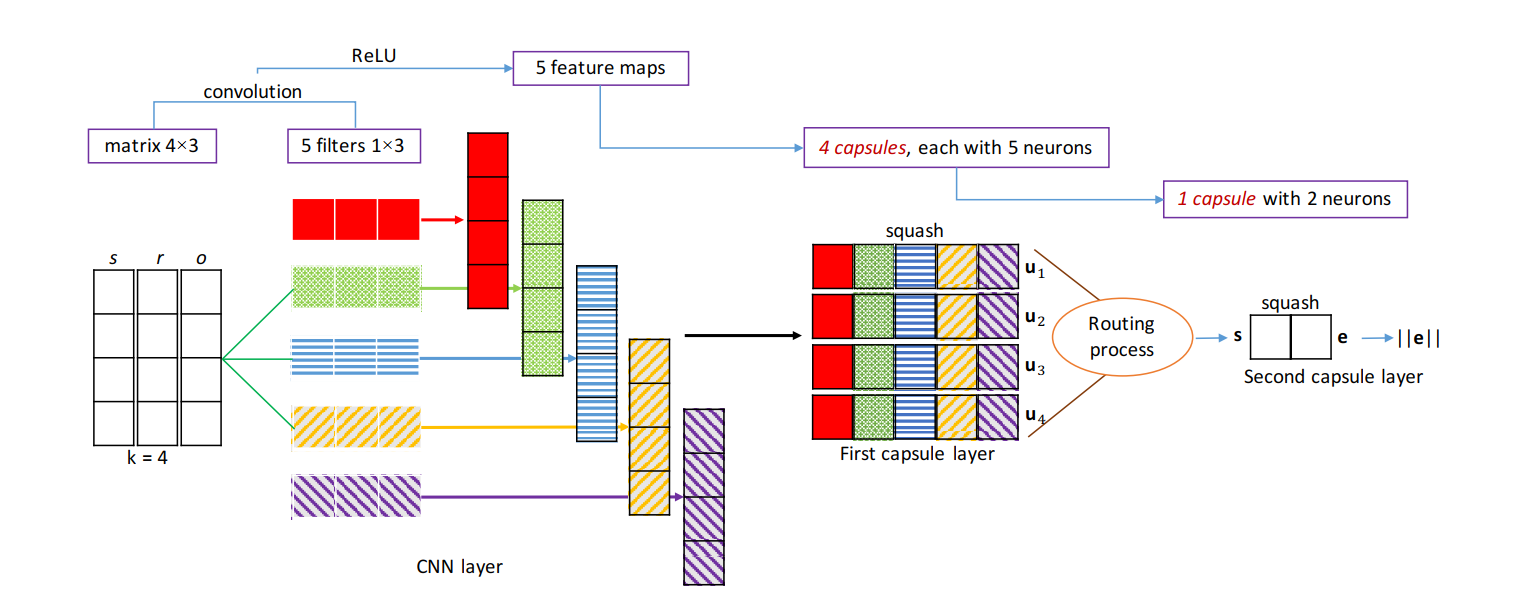
不同模型采用了不同的底层架构,如 Transformer、BERT、Qwen2、XLMRoberta 等。部分模型还引入了量化、蒸馏、对比学习等技术以提升推理效率和表达能力。下图为主流嵌入模型架构示意:
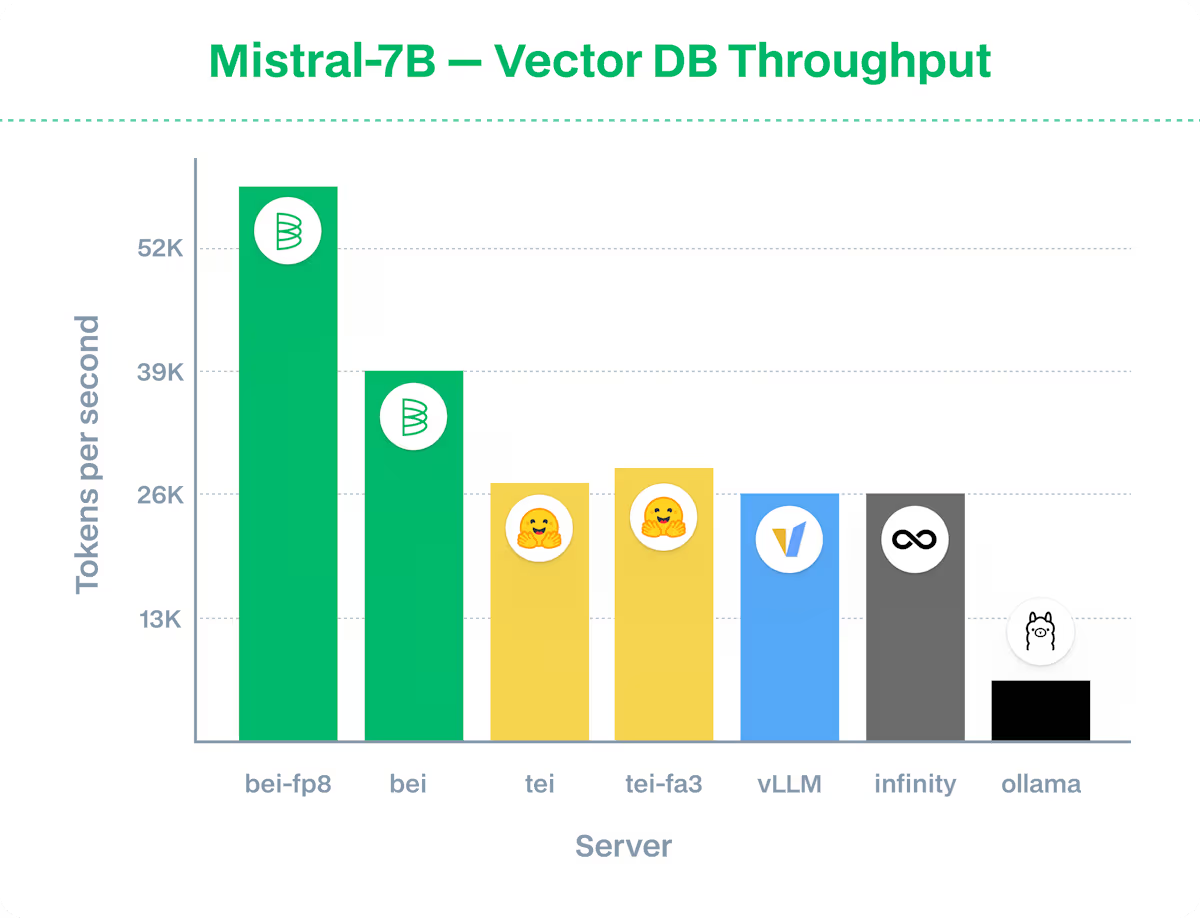
2.3 性能对比与选型建议
模型在参数规模、推理速度、适用场景等方面各有优势。bge-en-icl 适合高性能 GPU 场景,追求极致效果;Mixedbread Embed Large V1 适合轻量部署和成本敏感场景;Nomic Embed Code 针对代码检索优化,适合开发者和技术团队;bge-reranker-v2-m3 适合需要高相关性排序的 RAG 系统;Tulu 3 8B Reward 适合 RL 任务和智能体反馈。建议根据实际需求、硬件资源和业务目标综合考量。
2.4 开源模型的优势与局限
开源嵌入模型的最大优势在于可控性和灵活性,用户可以根据自身需求进行二次开发和优化,避免服务中断或被动迁移带来的风险。但开源模型也存在文档不完善、社区支持有限、需要自行维护等挑战,初学者在选型和部署时需多加关注。
3. 应用实践与优化建议
嵌入模型已在企业知识库问答、智能客服、电商推荐、代码检索等场景广泛落地。例如,企业通过嵌入模型实现高效的语义检索和智能问答,显著提升了客服自动化水平;电商平台利用嵌入模型进行商品推荐和用户兴趣建模,带动转化率提升;开发团队则通过代码嵌入模型优化代码搜索和自动补全体验。在实际部署过程中,初次处理大规模语料时建议选择高吞吐推理引擎,批量生成嵌入向量;上线后则需关注低延迟响应,合理配置模型和硬件。对于资源有限的团队,可以优先考虑参数量较小、推理速度快的模型,结合量化、剪枝等技术进一步优化性能。虽然榜单和基准测试可以作为参考,但最终效果还需在真实业务数据上验证。建议初学者多做实验,结合自身业务场景进行对比,关注模型在实际数据上的表现和可维护性。常见问题包括模型推理延迟高、向量检索精度不足、模型更新带来的兼容性问题等,解决方案包括采用高效的向量数据库、定期评估和微调模型、结合多模型融合等。
4. 未来趋势与展望
随着 AI 技术的不断进步,嵌入模型正朝着多模态与跨领域方向发展,不仅能处理文本,还能同时理解图片、音频、视频等多种数据类型,跨领域嵌入和统一语义空间的研究也在不断推进。模型的体积和推理效率也会进一步优化,既能满足大规模企业级应用的高性能需求,也能兼顾边缘设备和个人开发者的轻量化部署。模型压缩、蒸馏、量化等技术将持续推动嵌入模型的普及。开源社区的活跃推动了模型创新和应用落地,越来越多的模型在实际业务中展现出媲美甚至超越闭源方案的表现。未来嵌入模型还面临数据隐私保护、跨语言与跨文化适应性、模型安全性等挑战,持续的技术创新和社区协作将是推动嵌入模型健康发展的关键。