https://zxyle.github.io/PDF-Explained/ 深入解析 PDF 技术的中文译作
一次调试程序时,我需要检查 PDF 文件的内部结构,顺手用文本编辑器打开了一个看似普通的文档。屏幕上显示的内容让我停下了手头的工作:
%PDF-1.1%¥±ë
1 0 obj << /Type /Catalog /Pages 2 0 R >>endobj这些规整的代码结构背后,隐藏着我们日常使用的 PDF 文档的真实面目。每一个字符的精确位置、每一条线的粗细、每一种颜色的数值,都通过这套指令语言被严格定义和控制。
那一刻我意识到,PDF 不只是个”文档格式”,它更像是一个完整的绘图程序——每份文档都是一系列精密的绘制指令。
这个发现引发了我对 PDF 解析技术的长期关注。从早期基于正则表达式的粗暴匹配,到专业解析库的精细处理,再到如今 AI 模型的智能解读,这个领域的技术演进比我想象的更加精彩。
1.PDF 到底是什么
为什么要有 PDF?答案很简单:保证一份文档在任何地方打开都长得一模一样。
想象一下,你写了份重要合同,在你电脑上看起来完美,结果对方打开后字体乱跑、图片错位,那不就麻烦大了?
所以 Adobe 的工程师设计了一套基于 PostScript 的描述语言。PDF 文件本质上就是一份超详细的”绘图说明书”,PDF 阅读器就是个忠实的”执行者”,严格按说明书把文档”画”出来。
1.1 PDF 文件里有什么
看个最简单的例子:
%PDF-1.1%¥±ë
1 0 obj << /Type /Catalog /Pages 2 0 R >>endobj
2 0 obj << /Type /Pages /Kids [3 0 R] /Count 1 /MediaBox [0 0 300 144] >>endobj
3 0 obj << /Type /Page /Parent 2 0 R /Resources << /Font << /F1 << /Type /Font /Subtype /Type1 /BaseFont /Times-Roman >> >> >> /Contents 4 0 R >>endobj
4 0 obj << /Length 55 >>stream BT /F1 18 Tf 0 0 Td (Im liheng) Tj ETendstreamendobj
xref0 50000000000 65535 f0000000018 00000 n0000000077 00000 n0000000178 00000 n0000000457 00000 ntrailer << /Root 1 0 R /Size 5 >>startxref565%%EOF分解一下:
%PDF-1.1:告诉你这是 PDF 文件,版本 1.1%¥±ë:特殊标记,帮助识别这是真正的 PDF- 对象系统:PDF 像搭积木,每个元素都是独立的对象,有编号
- 交叉引用表:文件的”目录”,记录每个对象在哪里
- 绘图指令:核心部分!告诉阅读器”画什么”和”在哪画”

PDF 的厉害之处在于:它把”内容”和”呈现方式”彻底分开了。内容通过对象组织,呈现通过指令控制。只要严格按说明书执行,在哪里都能画出一样的效果。
2.PDF 解析技术的发展历程
识别理解这份”说明书”的技术,经历了好几轮升级。
2.1 早期:靠规则和 OCR 硬撑
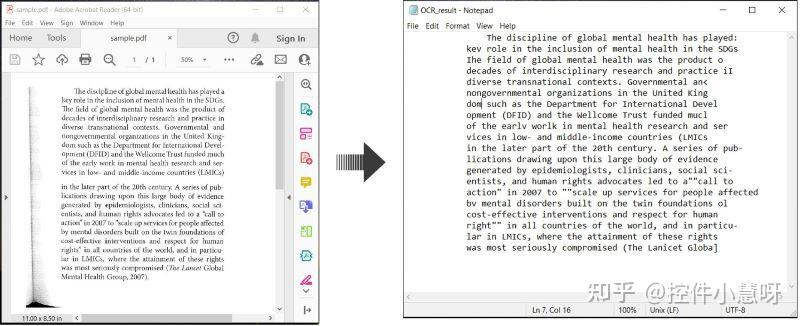
90 年代到 2010 年左右,主要靠 OCR(光学字符识别)。简单说就是把文档当图片,用图像处理技术找出字符,然后猜是什么字。
对简单的印刷体还行,但遇到复杂版面、表格或多语言混合,就抓瞎了。错误率高,适应性差。
2.2 深度学习应用阶段
2010 年代中期,CNN(卷积神经网络)开始发力。它让计算机能自动”看懂”文档图像的特征——边缘、纹理、形状,不用再手工设计一堆规则。
后来 CNN 和 RNN(循环神经网络)结合,能识别整行文本,不用先切分单个字符再拼接。效率和准确性都提升了不少。
2.3 Transformer 带来的革命
2010 年代末到现在,Transformer 架构真正改变了游戏。它的”自注意力”机制让模型能同时关注文档的整体结构和局部细节。Vision Transformer 把文档页面切成小块分析,还能理解空间位置关系。机器开始像人一样从整体和细节两个层面”读”文档。

2.4 多模态大模型的突破
最新的进展是多模态大模型。它们不再依赖传统 OCR 流程,能像人一样同时理解文档的视觉外观、空间位置和文字内容。可以直接从文档图像生成结构化结果,比如精准识别数学公式、重建表格结构。整个流程简化了很多,理解能力也上了个台阶。
3.现代 PDF 解析的核心技术
深度学习,特别是 Transformer,为 PDF 解析打开了新世界。真正带来突破的是两大核心技术:多模态融合和端到端架构。
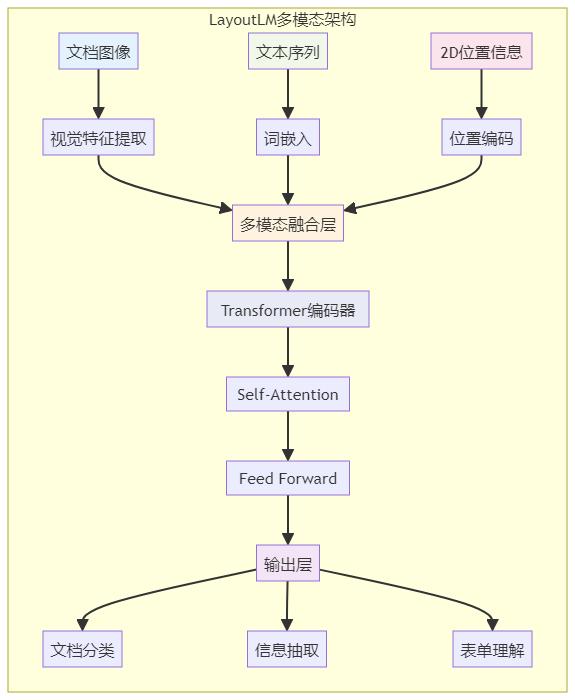
3.1 多模态融合:看见、读懂、理解布局
以前的 OCR 只关心”文字是什么”。现代多模态模型同时处理三种信息:
-
文本内容:单词、句子的含义
-
视觉特征:字体大小、颜色、图片内容
-
空间布局:每个元素在页面上的位置和相互关系
怎么融合的?模型把这三种信息都转换成高维向量,然后拼在一起输入给 Transformer。自注意力机制能学会这些信息之间的关联——比如识别出图片下方的文字可能是图注,页面顶部的大号粗体文字可能是标题。
LayoutLM 系列是这方面的代表。它们在预训练时要求模型同时利用文本、视觉和布局信息来预测被遮盖的内容,逼着模型学习深层次的多模态关联。
3.2 端到端架构:跳过繁琐步骤
传统 PDF 解析是个复杂的流水线:
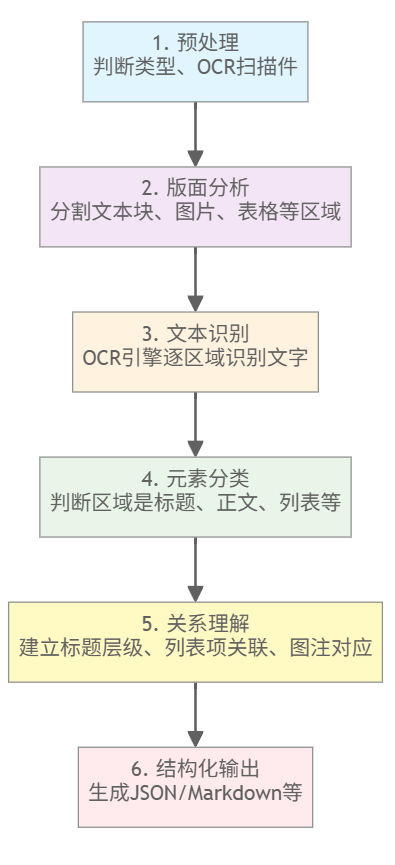
每步的错误都会传递到下一步,最终结果经常出问题。
端到端模型直接从原始输入生成最终输出,跳过所有中间步骤:

Donut 和 Nougat 是这方面的典型代表:
Donut:直接从图像生成 JSON,跳过传统 OCR 的所有环节
Nougat:专门处理学术 PDF,能准确识别数学公式和复杂表格,输出可直接编译的 Markdown 或 LaTeX
3.3 多模态 + 端到端=真正的理解
两大技术结合,让 PDF 解析从”识别元素”变成”理解内容”。模型不仅能告诉你”这里有个文档”,还能理解文档结构、内容含义,甚至回答关于文档的问题。
4.挑战与未来
当然,事情还没那么完美,有几个问题还很头疼:
复杂版面:报刊杂志那种图文混排、多栏布局,机器还是搞不太定。
低质量文档:模糊扫描件、低分辨率图片,识别起来还是很困难。
深度理解:专业术语、上下文的言外之意、图表想表达的深层逻辑,机器还很难真正抓住。
接下来,有几个方向值得关注:
零样本学习:让模型拿到没见过的新类型文档也能直接处理,不用单独训练。
更好的多模态融合:把文字、图像、布局信息捏得更紧,让理解更全面。
边缘计算:让手机、平板这些设备自己就能处理 PDF,又快又安全。
5.结语
PDF 解析技术的发展,说白了就是让机器从死板地执行指令,进化到尝试真正理解内容。
未来的目标很简单,就是让 AI 变成一个能干的助理。你把任何 PDF 丢给它,它都能快速读懂,并按你的要求整理好里面的信息。
到那时,我们或许就不用再被埋在成堆的文档里,可以把时间花在更有意思的事情上。