1. 研究背景与意义
人类大脑如何在真实世界的对话中处理和理解语言,是神经科学和人工智能领域长期未解的核心问题。传统神经语言学研究倾向于将语言分解为语音学、音系学、形态学、句法、语义和语用等子领域,分别建模,但这种“分而治之”的方法难以还原日常对话中多层次、动态、上下文依赖的语言处理过程。心理语言学模型多依赖符号化特征(如音素、词性等),但这些模型往往难以解释现实对话中语言分析的复杂互动。
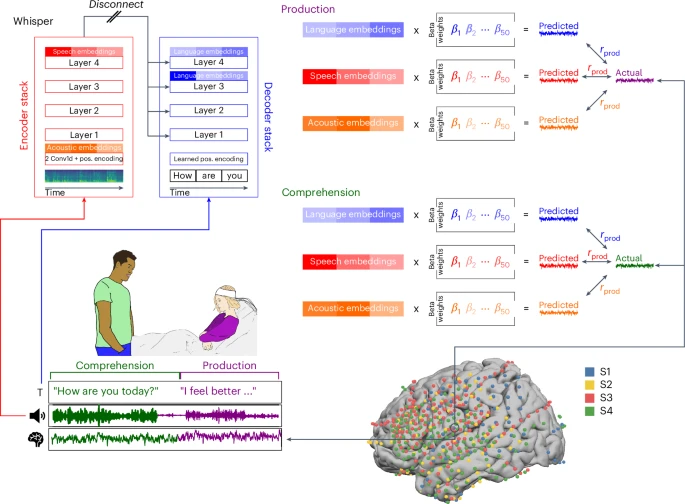
图 1:用于在真实世界对话中模拟神经活动的生态密集采样范式
近年来,人工智能模型的发展为我们提供了一个统一的计算框架,来研究大脑对自然语言的实时加工。特别是基于 Transformer 架构的模型如 Whisper,能够端到端地处理语音到文本的全过程,极大拓展了神经语言学的研究边界。
1.1 传统神经语言学的分而治之与局限
传统的神经语言学方法通常将语言拆解为语音、词汇、句法、语义等独立的加工模块,并在高度控制的实验环境下分别进行研究。这种方法有助于我们理解语言认知的各个方面,但往往也因此缺少一个统一的框架来捕捉真实世界中,自然语言活动各层面间复杂的信息互动。
1.2 AI 统一计算框架的崛起
近年来,深度学习和大型语言模型(LLM)的突破,为统一建模“从声音到语言”的全过程提供了新思路。多模态端到端模型如 Whisper,不仅能处理书面文本的语法、语义和语用,还能高效识别真实语音,为理解大脑如何将连续听觉输入转化为语音和词汇级语言表征提供了理论基础。
2. Nature Human Behaviour 最新研究亮点
在最近发表于《自然 - 人类行为》(Nature Human Behaviour) 上的一项研究中,来自谷歌、普林斯顿、哈佛大学等机构的研究团队,利用语音识别模型 Whisper,成功实现了对人脑语言活动的多方位、多层次预测。Whisper 是由 OpenAI 开发的一种基于 Transformer 架构的自动语音识别模型。通常情况下,模型的输入是音频信号,经过特征提取、编码、解码等过程后,模型会输出音频所对应的文本内容。此次研究的创新之处在于,团队不仅关注模型的最终输出文本,更深入分析了 Whisper 在处理语音时各层内部嵌入的动态变化,并将这些嵌入与人类大脑在自然对话中的皮层脑电图(ECoG)信号进行对齐。结果发现,Whisper 模型的内部表征能够准确预测语言信息在大脑内流动的层级结构、时间进程和空间分布。这意味着,深度学习模型不仅能“听懂”人类语言,还在某种程度上“模拟”了大脑处理语言的方式,为理解人脑语言机制和推动脑机接口等前沿应用提供了全新视角。
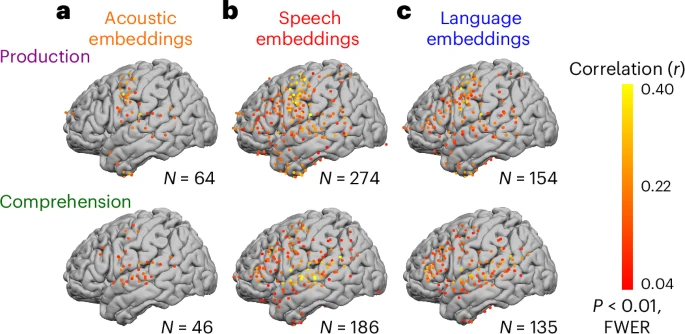
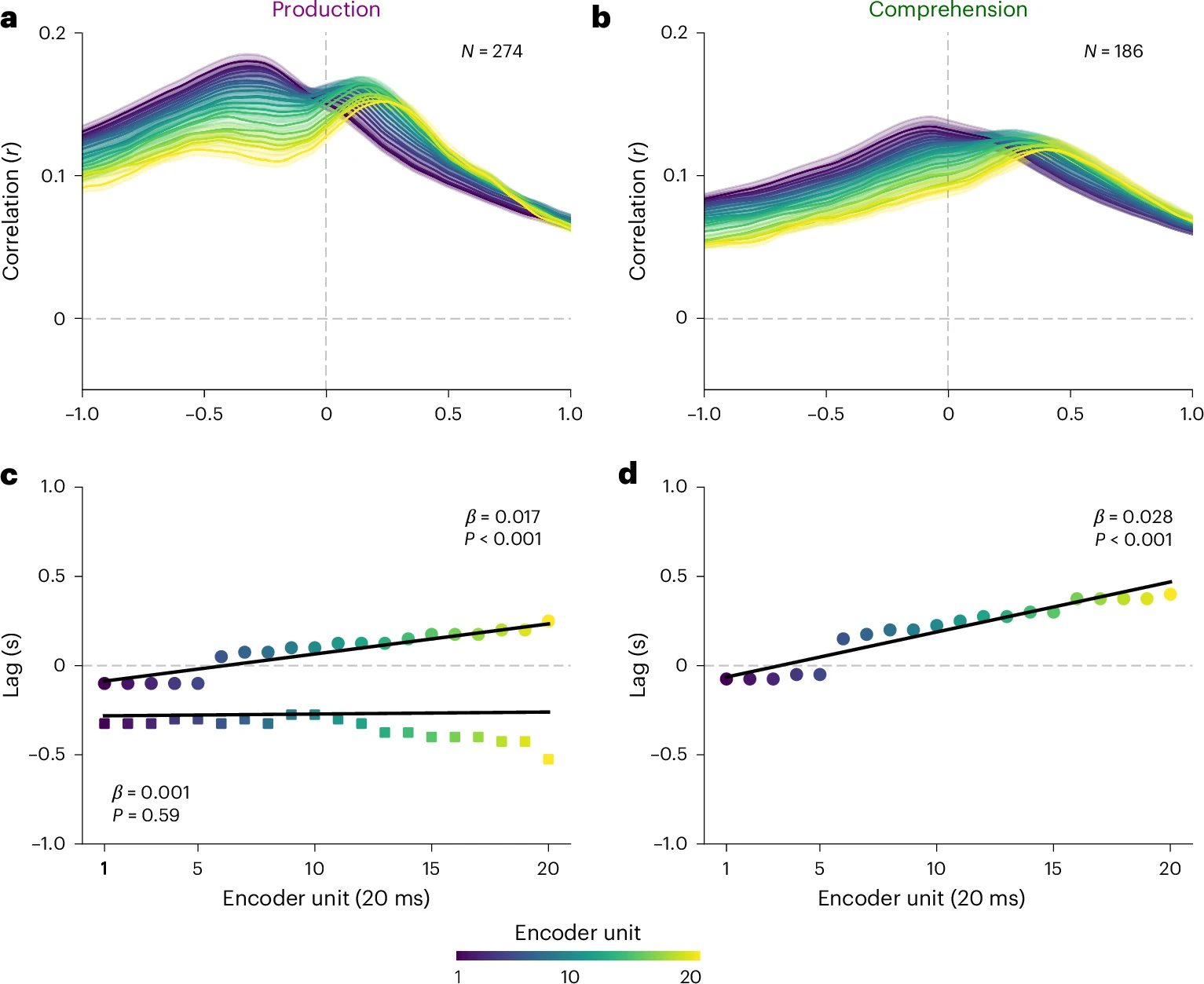
图 2:语音、语音和语言编码模型在语音产生和理解过程中的性能
2.1 皮层脑电图(ECoG):高时空分辨率的神经信号
皮层脑电图 (Electrocorticography, ECoG) 是一种侵入性的神经监测技术,通过将电极阵列直接放置在大脑皮层表面,能够以极高的时空分辨率记录神经活动信号。这种方法通常用于临床上需要进行颅内监测的难治性癫痫患者,对于科学研究而言,ECoG 的主要优势在于其具有很高的时空分辨率,能够非常精确地测量大脑在执行特定任务时,其神经活动在时间和空间上的变化。
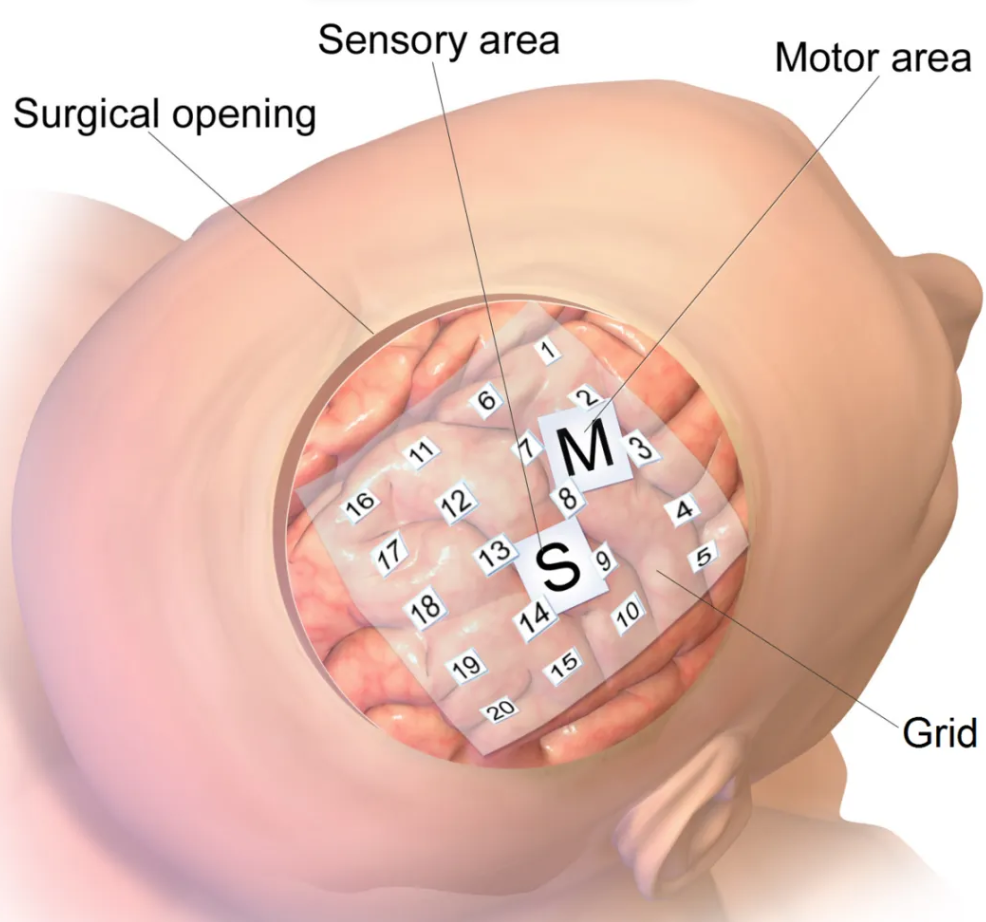
图三:皮层脑电图
3. 真实对话神经 - 语音同步数据的采集与处理
3.1 实验设计与数据采集流程
研究团队招募了 4 名为治疗癫痫而植入了 ECoG 电极的被试。在被试住院期间,进行了连续数天 7×24 小时的 ECoG 和语音的同步记录,涵盖了被试与家人、朋友、医护人员之间完全自然的、无脚本的对话。最终收集了约 100 小时的对话和神经数据,其中约 50 小时是语言理解,50 小时是语言产生,数据总量达数十万单词。所有语音被转录为文字,并将每个词的起止时间精确到毫秒级,与录音对应。ECoG 信号经过预处理,提取 gamma 频段 (75-200 Hz) 的功率包络,并与语音数据以约 20 毫秒的精度对齐,为后续分析奠定了坚实基础。
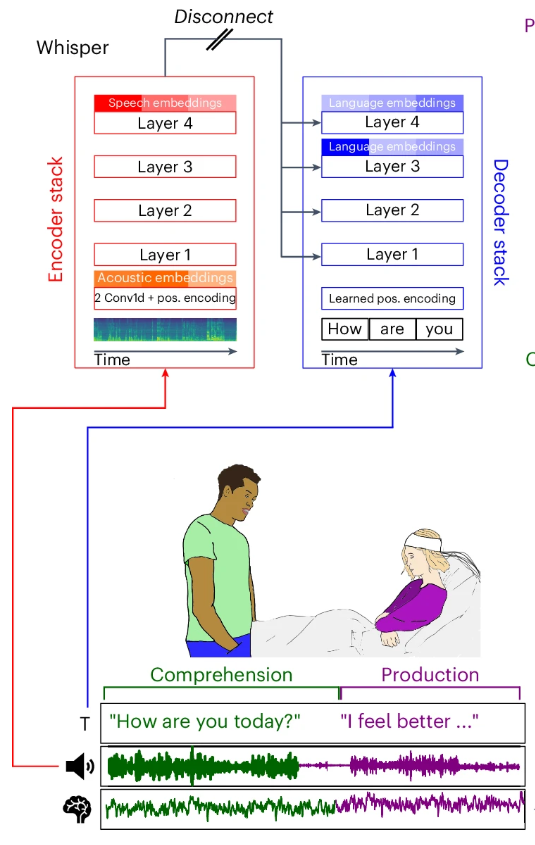
3.2 数据预处理与对齐细节
所有对话均通过高质量麦克风录音,采用半自动流程进行去标识化(去除姓名、地名等敏感信息),并由人工转录。随后,利用 Penn Forced Aligner 工具将文本与音频对齐,精确到每个单词的 20 毫秒级时间戳。音频与神经信号通过专用通道同步,确保两者精确对齐。ECoG 信号进一步去除运动伪影、异常电极、癫痫放电等噪声,带通滤波(75-200Hz),计算功率包络,z-score 标准化。
4. Whisper 模型的分层表征与神经预测
4.1 Whisper 内部表征的三层级
研究者将自然语言加工划分为声学、语音和语言三个层级。声学层级反映音频信号的物理属性,语音层级对应口语信号的结构化单元,语言层级则基于词级文本转录理解句法和语义。Whisper 模型的多层级架构恰好模拟了这一从具体到抽象的加工过程。研究者分别从编码器输入层(Layer 0)提取声学嵌入,从编码器顶层(Layer 4)提取语音嵌入,从解码器倒数第二层(Layer 3)提取语言嵌入。每个词的嵌入向量通过主成分分析 (PCA) 降至 50 维,既保留了关键信息,又便于后续建模。
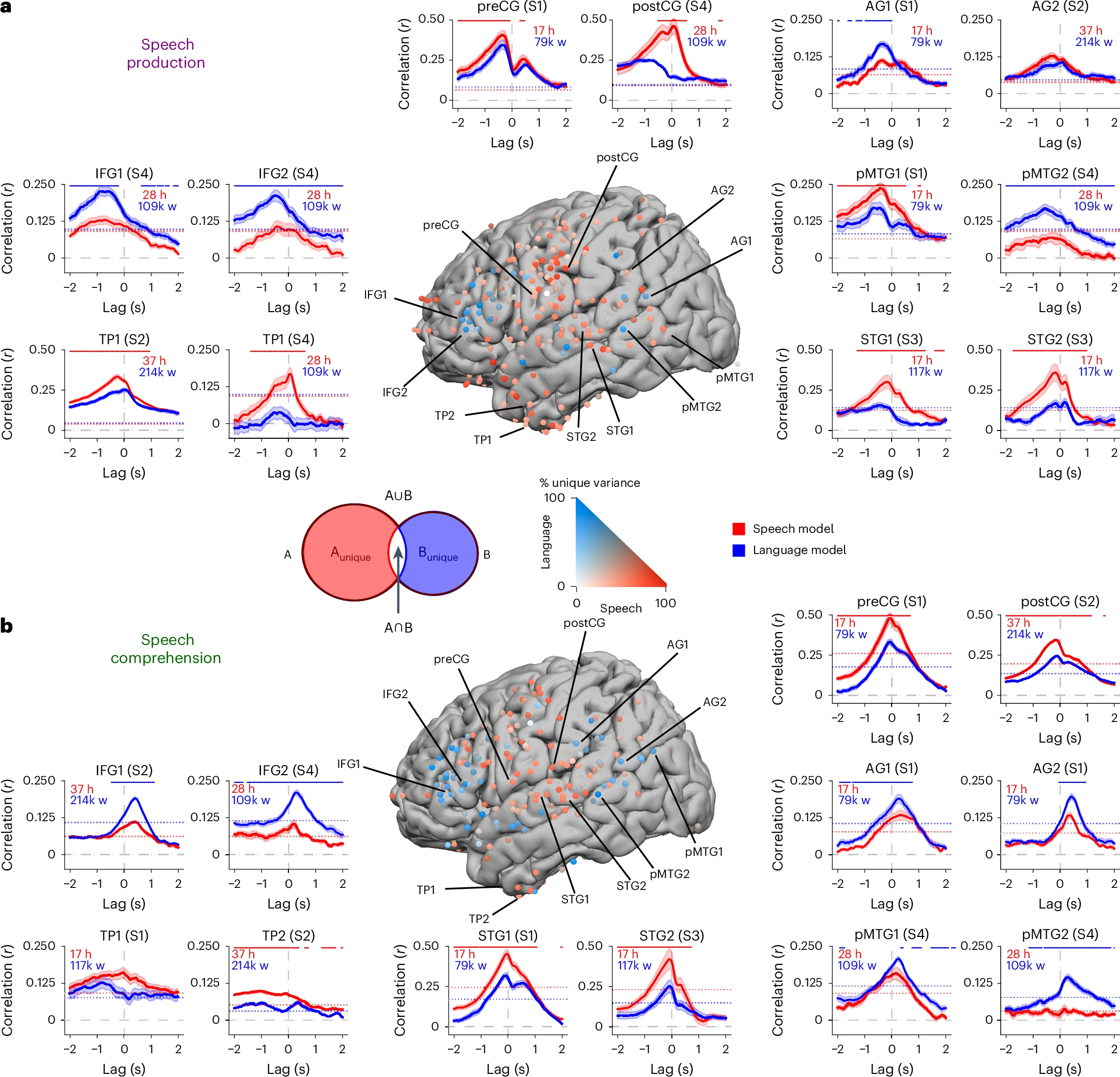
4.2 Whisper 嵌入与神经信号的对齐与预测
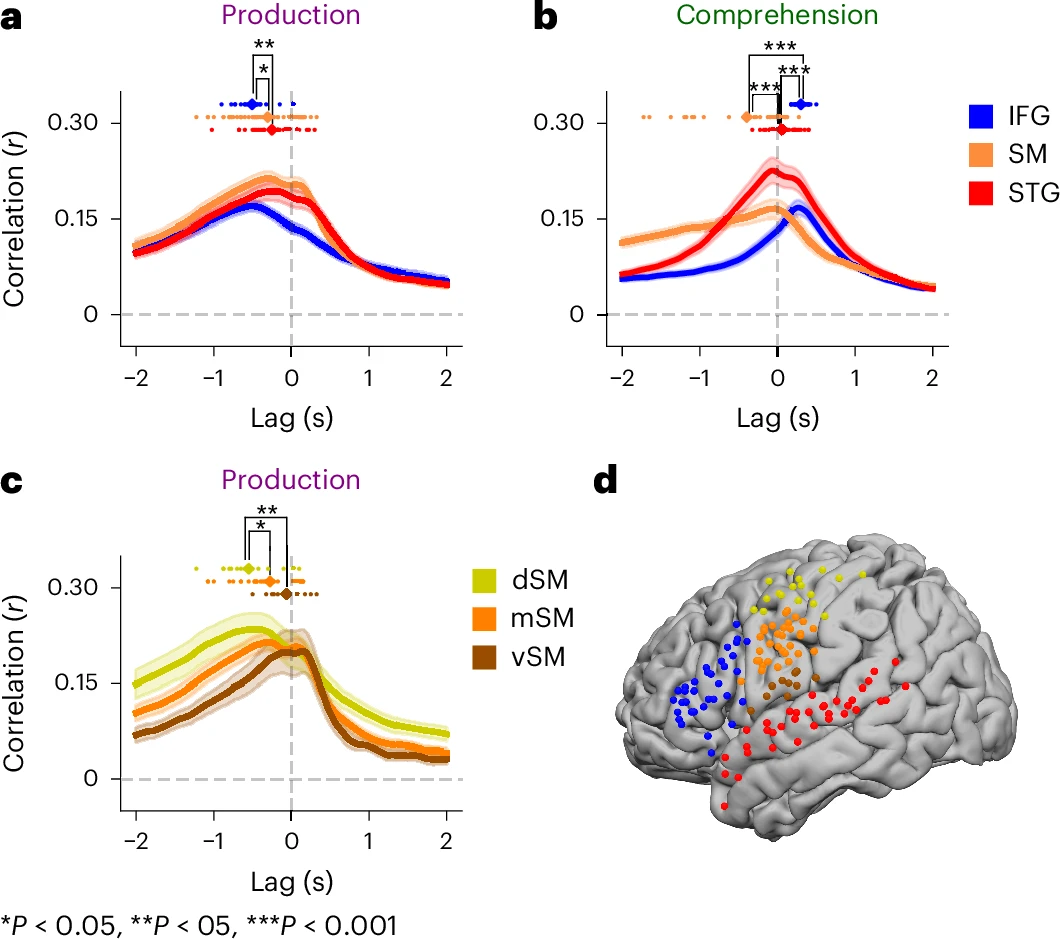
研究团队为每个电极、每个时间点(从目标词出现前 2000 毫秒到出现后 2000 毫秒,每 25 毫秒一个点)训练了独立的线性回归模型,用 Whisper 的嵌入向量预测该电极在该时间点上的神经信号。采用 10 折交叉验证,确保模型泛化能力。最终,Whisper 嵌入对神经活动的预测相关性最高可达 0.5,显著优于传统符号化模型。语音嵌入在感觉区(STG)和运动区(preCG、postCG)预测效果最佳,语言嵌入在高阶语言区(IFG、AG)表现更优。语言产生时,IFG 的语言编码在单词出现前约 500 毫秒达到峰值,SM 区的语音编码则在单词出现前 200 毫秒达到峰值;语言理解时,STG 区的语音编码在单词出现后 50 毫秒达到峰值,IFG 的语言编码则在 300 毫秒后达到峰值。
5. Whisper 表征的层级结构、空间分布与多模态整合
5.1 方差分解与分层神经表征
通过方差分解分析,研究者发现语音嵌入在 STG、IFG 和 SM 等脑区解释了更多神经活动的变异,声学嵌入仅在少数外侧裂和腹侧运动皮层电极上有独特贡献。较低级的感知和运动相关脑区更多被语音嵌入解释,高级语言区则更多被语言嵌入解释。这种分层结构在语言产生和理解过程中都表现得非常清晰。
5.2 多模态整合与信息流动
进一步分析发现,融合了音频和文本信息的语言嵌入,在 STG、SM 区乃至 IFG 等高级语言区,对神经活动的预测准确性均显著优于仅用文本信息的模型。这表明大脑的语言区在处理词义时,也会整合声音线索,存在多层级整合过程。通过分析不同时间延迟的编码模型表现,研究者还追踪了语言信息在不同脑区的处理顺序。语言产生时,IFG 的编码活动在单词说出前 500 毫秒达到峰值,SM 区则更靠近发音时刻;语言理解时,STG 的编码活动在单词出现后 50 毫秒达到峰值,IFG 则在 250-300 毫秒后达到峰值,反映了从“听到声音”到“理解意思”的神经流动。
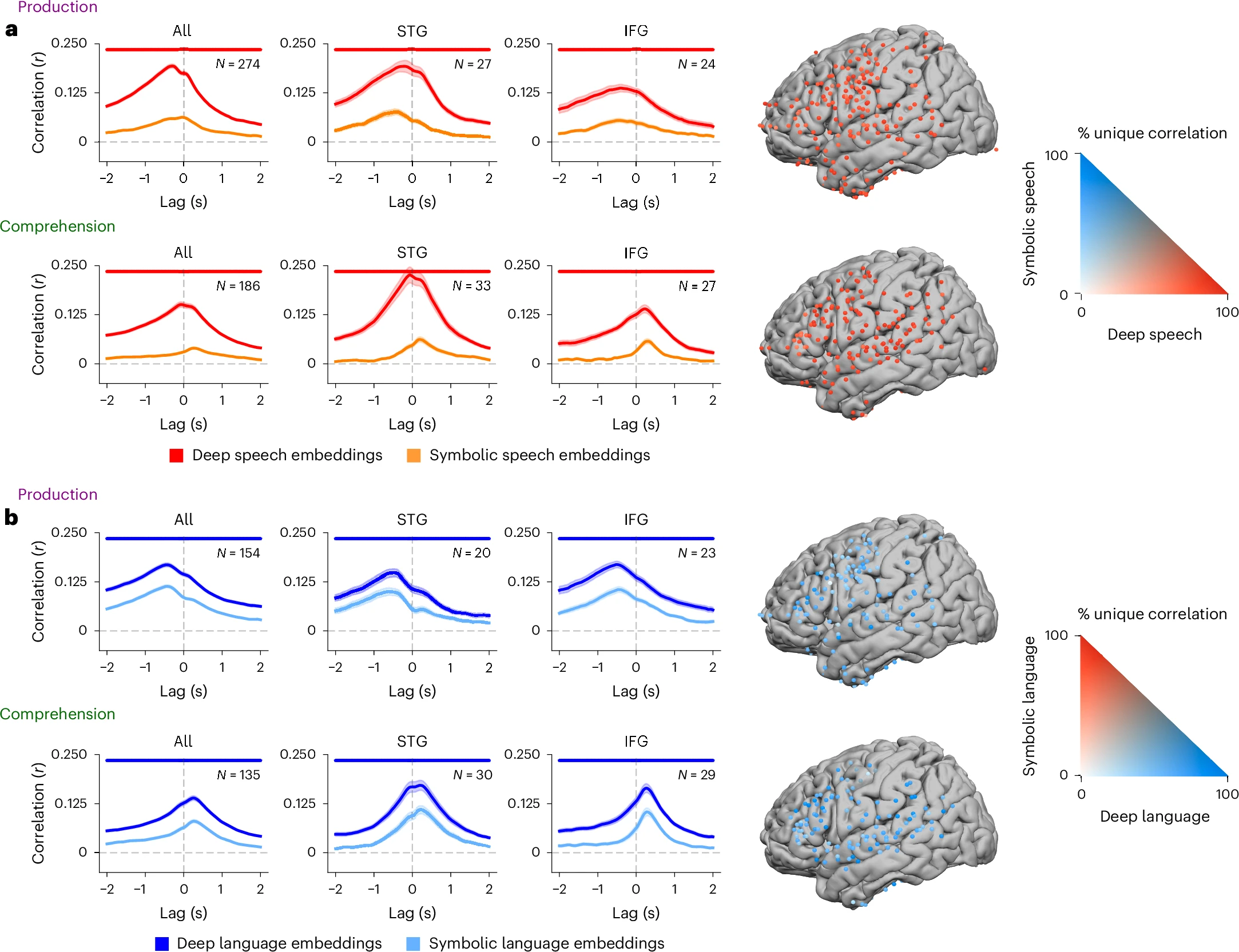
5.3 Whisper 嵌入优于传统符号模型
研究者将传统的符号语言学特征(如音素、词性、句法等)转换为二值化向量,与 Whisper 嵌入在同一框架下比较。结果显示,无论是语音层面还是语言层面,Whisper 的深度嵌入在预测神经活动方面均显著优于基于规则的传统符号模型。这表明,基于大规模数据统计学习到的分布式表征,比人为定义的离散符号更能捕捉自然言语的神经活动。
6. Whisper 嵌入的语言学结构、方法细节与未来展望
通过 t-SNE 降维可视化和多项逻辑回归分类,研究者发现,尽管 Whisper 并未外显地编码语言学符号,但其嵌入空间中自发地组织出了音素、发音部位、发音方式和词性等结构。语音嵌入能以约 54% 的准确率识别音素,语言嵌入能以约 67% 的准确率识别词性,均远高于随机水平。这说明,AI 模型在无监督条件下也能自发学习并组织出心理语言学中的高级结构。
本研究不仅展示了 Whisper 作为统一的多层级声学 - 语音 - 语言计算模型,在解释真实自然对话中人脑神经活动方面的强大能力,也为神经语言学与人工智能的交叉融合提供了新范式。研究结果表明,AI 模型与人脑在处理语言时可能共享某些核心的计算原理。未来,随着多模态模型(如 GPT-4o 等)和端到端音频 - 音频语言模型的发展,基于高维嵌入空间的非符号化语言处理范式有望进一步推动我们对大脑语言机制的理解。
在方法细节方面,ECoG 数据预处理包括去除运动伪影、异常电极、癫痫放电等噪声,带通滤波(75-200Hz),计算功率包络,z-score 标准化。嵌入提取方面,音频按 30 秒滑窗输入 Whisper,编码器每 20 毫秒输出一个隐藏状态,最后 10 个状态拼接为单词级嵌入,所有嵌入降维至 50 维。编码模型部分,每个电极、每个时间滞后点分别训练线性回归模型,预测神经信号,并通过置换检验和 FDR 校正确定显著性。方差分解用于分析语音和语言嵌入对神经信号的独特解释力,揭示不同脑区的选择性。分类分析则用逻辑回归对嵌入进行音素和词性分类,验证其表征能力。原始音频和神经数据仅在签署数据共享协议后向合规研究者开放。
核心分析代码已开源,嵌入提取可在 https://github.com/hassonlab/247-pickling/tree/whisper-paper-1 获取,编码模型可在 https://github.com/hassonlab/247-encoding/tree/whisper-paper-1 获取。所有编码结果、图表、阈值和显著性标记可在 https://github.com/hassonlab/247-plotting/blob/main/scripts/tfspaper_whisper.ipynb 获取。
限时优惠:开启你的 AI 推理之旅 新用户注册共绩算力平台,可领取 最高 1500 元免费算力(含 50 元无门槛体验券),用于探索弹性算力部署、开发机等服务:
- 用弹性部署快速上线 AIGC 应用(如文生图、语音识别);
- 用开发机导入第三方镜像,一键发布至生产环境;
- 用云 GPU API 调用,直接获取推理结果。
抓住机会,让你的 AI 创意通过共绩算力高效落地!
关于共绩算力
共绩算力是国内首个专注 AI 推理服务的 GPU Serverless 平台,通过智能调度网络整合全国闲置算力,为开发者提供 弹性部署(Docker 一键启动)、API 调用(秒级响应)、开发机(无缝衔接)、裸金属短租(定制化配置)等服务,以“成本立省 50%、资源管饱、部署极简”的核心优势,助力 AI 应用从创意到落地的每一步。