在 AI 爆发的时代,算力成本成为了悬在每个企业和开发者头顶的达摩克利斯之剑。动辄数万的 4090,价格高昂的 A100/H100,让许多极具潜力的 AI 项目因为“烧不起钱”而被迫搁置。
为了解决这个痛点,共绩算力正式推出了 SPOT 抢占式实例。这不仅仅是一个简单的“降价促销”,而是一套专为解决批处理任务规模、稳定性和低价矛盾而设计的底层技术架构。
今天,我们就来深度揭秘共绩算力 SPOT 实例背后的技术逻辑,看看它是如何做到在提供极致性价比的同时,保障海量任务的稳定运行的。
什么是 SPOT 抢占式实例?
在云计算领域,数据中心总会有部分计算资源处于闲置状态。为了最大化资源利用率,云服务商会将这些闲置资源以极低的折扣(通常为按需价格的 10% - 50%)售卖,这就是 Spot 实例。
共绩算力的 SPOT 实例同样基于这一逻辑,但针对 GPU 算力和 AI 批处理场景进行了深度定制。 它的核心特点可以概括为两句话:
-
价格极低: 相比按量计费,Spot 实例提供大幅折扣。例如 4090 单卡低至 1.68 元/小时。
-
随时可能被抢占: 当系统整体资源紧张,或者有高优先级(按量计费)任务需要算力时,Spot 实例可能会被系统强制回收中断。
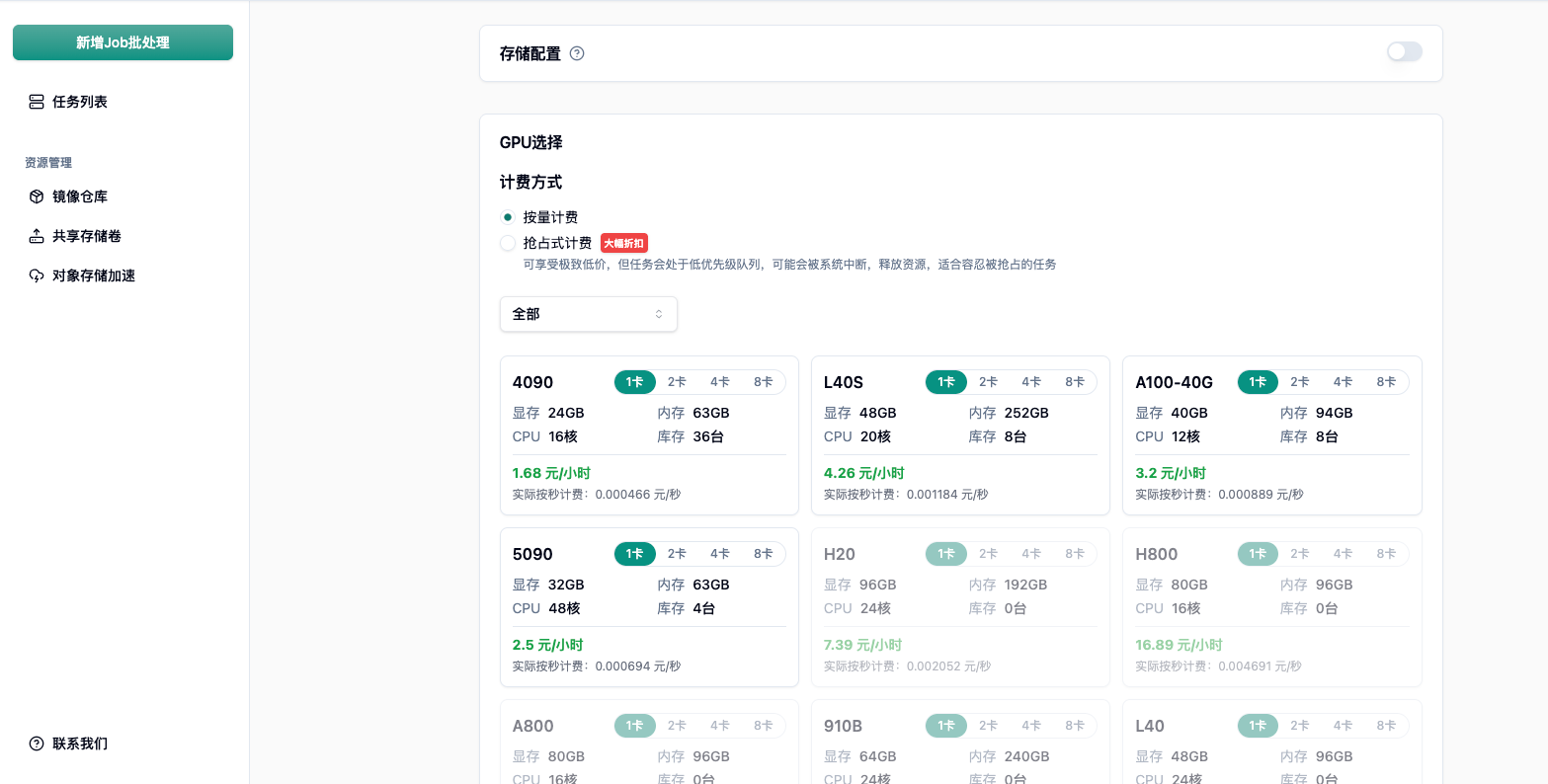
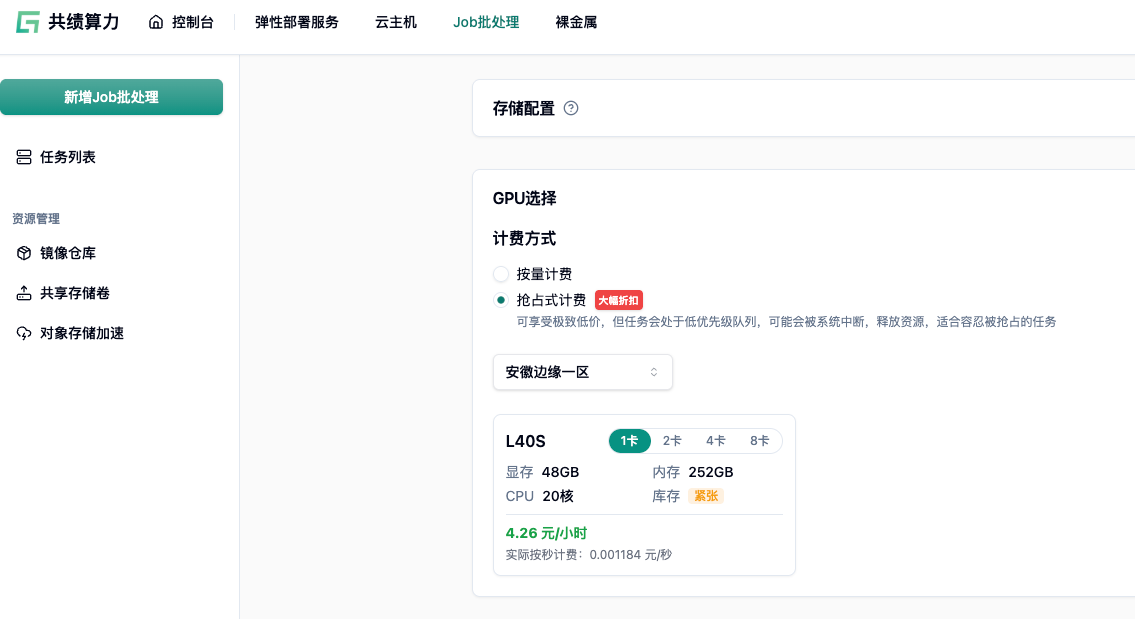
为什么说 SPOT 是 AI 算力的“战略级补充”?
你可能会问:既然随时可能被中断,那谁敢用呢?
这就不得不提 AI 时代工作负载的演变了。在过去,Web 服务、数据库等应用需要 7x24 小时稳定运行,绝对不能容忍中断。但在 AI 时代,大量的计算任务变成了批处理(Batch Processing)。
例如:
- 大模型离线推理: 批量生成 Embedding、定时处理海量文档。
- 图像/视频批量处理: 渲染农场、批量图片打标(如提示词反推)。
- 科学计算与仿真: 基因测序、分子动力学模拟。
这些任务的共同特点是:无状态、可拆分、可断点续算。对于这类任务,只要系统具备完善的容错和重试机制,单个节点的偶尔中断根本不会影响最终结果,反而能通过 Spot 实例省下海量成本。
共绩算力 SPOT 实例的“独门绝技”
市面上提供 Spot 实例的云厂商不少(如 AWS、阿里云),但共绩算力的 SPOT 实例在底层设计上,针对 AI 批处理场景做了大量优化,可以说是“独一无二”的。
1. 极致的并发规模与执行效率
传统的虚拟机(VM)拉起速度慢,难以应对突发的并发需求。共绩算力 Job 批处理底层采用 K8s 原生架构,支持成百上千个计算节点的一键并发拉起,瞬间吞吐海量数据。
更重要的是,它提供了 K8s 原生索引模式。系统会为每个并行节点自动注入全局唯一索引(0 至 N-1),计算节点可根据索引精准认领并处理不同的数据分片。这完美适配了分布式模型训练与数据分片场景,避免了任务重复执行。
2. 企业级容错与自动熔断机制
用 Spot 实例最怕什么?怕任务被抢占后,进度全部丢失。共绩算力为此设计了双重容错机制:
- 容器级原地重启: 应对偶发性进程崩溃。
- 任务级重新调度: 当节点被系统抢占或底层硬件故障时,系统会自动跨机拉起新节点续跑。
3. 秒级计费与“阅后即焚”
共绩算力的计费颗粒度精确到秒。对于 Spot 任务,只收取实际存活并运行的时长费用。如果任务跑到一半被抢占,被抢占后立刻停止计费,绝不让用户为未完成的计算买单。
同时,Job 批处理是“阅后即焚”的托管服务。任务一旦结束(成功/失败/被抢占),底层 GPU 资源会立刻被系统回收,彻底杜绝因忘记关机导致的算力闲置浪费。
最佳实践:如何优雅地使用 SPOT 实例?
想要薅 Spot 实例的羊毛,也是需要一点技巧的。以下是推荐的最佳实践:
-
任务拆分(化整为零): 将庞大的单体任务拆分为多个独立的小任务。例如,将 100 万张图片的推理任务,拆分为 1000 个各处理 1000 张图片的小任务。这样即使个别任务被抢占,重试的成本也极低。
-
挂载外部存储: 任务结束或被抢占后,节点内的本地缓存数据会随之销毁。务必使用平台提供的对象存储加速或共享存储卷挂载功能,将重要结果实时保存到云盘。
-
合理设置重试与熔断: 根据业务重要性设置任务重试次数,同时务必设置“最大允许失败节点数”以防止代码 Bug 导致的无效扣费。
结语
共绩算力 SPOT 抢占式实例的推出,不仅是对云端闲置算力的一次深度挖掘,更是为广大 AI 开发者和企业提供了一把降本增效的利器。通过底层架构的创新,它成功化解了批处理任务在“规模、稳定性与低价”之间的矛盾。
告别硬件焦虑,让每一分钱都花在刀刃上。现在就登录共绩算力控制台,体验极致性价比的 AI 算力吧!