摘要与引言
近年来,文本到图像(Text-to-Image, T2I)生成技术取得了革命性进展,然而,其发展也面临两大严峻挑战。一方面,性能最顶尖的模型,如 Nano Banana Pro 与 Seedream 4.0,多为不透明的闭源系统,其技术细节和复现路径难以企及。另一方面,领先的开源模型为追求性能,参数量急剧膨胀至数百亿规模(如 Qwen-Image、Hunyuan-Image-3.0),导致训练与推理成本高昂,普通用户和研究者难以负担。
为应对这些挑战,我们推出了 Z-Image——一个高效的 6B 参数基础生成模型,旨在挑战行业内“不计成本扩展”(scale-at-all-costs)的固有范式。Z-Image 通过系统化、端到端地优化数据、架构、训练和推理的全生命周期,证明了在不依赖庞大模型规模和合成数据蒸馏的前提下,同样可以实现顶尖性能。我们以仅 314,000 H800 GPU 小时(约合 62.8 万美元)的极低计算开销,完成了完整的训练流程。评估结果显示,Z-Image 在多个维度上达到甚至超越了业界领先的竞争对手,尤其在逼真照片生成和中英双语文本渲染方面,其效果可与顶级商业模型相媲美。

Z-Image 在成本效益上的突破,主要得益于四大技术支柱的协同作用:
- 高效的数据基础设施:通过多维特征分析、跨模态向量去重、世界知识图谱引导和主动策管,最大化每单位计算资源的信息获取率。
- 高效的 S3-DiT 架构:采用可扩展单流多模态扩散 Transformer 架构,以 6B 参数实现高参数效率和密集的跨模态交互。
- 高效的训练策略:设计渐进式训练课程,整合任意分辨率生成、文生图与图生图联合训练,实现多任务能力的同步高效习得。
- 高效的推理优化:通过创新的几步蒸馏技术与奖励模型后训练,衍生出 Z-Image-Turbo,在保证质量的同时实现亚秒级推理。
下文将详细阐述 Z-Image 的技术细节、创新方法及其在各项评测中的卓越表现。
系统化数据基础设施:效率之基石
我们认为,在计算资源受限的条件下,数据效率是决定模型能力上限的关键变量。因此,我们没有遵循单纯扩大数据规模的路径,而是设计了一套旨在最大化每单位计算信息增益的集成化数据基础设施。它并非一个静态的数据仓库,而是一个由四个核心模块协同工作的动态、自我完善的系统:数据分析引擎提供量化信号,跨模态向量引擎确保语义效率,世界知识拓扑图提供概念蓝图以实现平衡,而主动策管引擎则通过模型反馈闭合循环,持续引导整个系统。
2.1 数据分析引擎 (Data Profiling Engine)
数据分析引擎是我们数据策略的量化基石,它系统化地处理海量原始数据,提取多维特征,为原则性的数据筛选和课程构建提供支持。该引擎的分析维度涵盖了从底层物理属性到高层语义内容的多个层面:
-
图像元数据:引擎首先缓存图像的基本属性,如分辨率和文件大小,用于初步的尺寸和宽高比筛选。同时,计算感知哈希(pHash)作为图像的视觉指纹,以实现快速、高效的低级别去重,剔除完全相同或高度相似的图像。
-
技术质量评估:为确保模型学习到高质量的视觉信息,引擎从多个维度评估图像的技术质量:
- 压缩伪影检测:通过计算理想文件大小与实际文件大小的比率,识别过度压缩导致的质量下降。
- 视觉退化评分:利用内部训练的质量评估模型,对色偏、模糊、水印、噪声等视觉退化因素进行量化评分。
- 信息熵分析:通过分析图像边框像素的方差和 JPEG 重编码后的每像素字节数(BPP),过滤掉包含大面积纯色背景或内容复杂度低的低熵图像。
-
语义与美学内容:引擎进一步评估图像的高层内容属性:
- 美学评分:基于专业标注数据训练的美学模型为每张图像的视觉吸引力打分。
- AIGC 内容检测:我们训练了专门的分类器来识别并过滤 AI 生成内容,以防止模型输出质量和物理真实感的退化。
- 高层语义与安全评估:利用一个专门的视觉语言模型(VLM)生成丰富的语义标签(如物体类别、人物属性),并进行不适宜内容(NSFW)评分。该模型特别关注中国文化相关元素的识别,以增强模型的文化适应性。
-
跨模态一致性与字幕生成:图文对齐是模型训练的核心。
- 图文相关性计算:使用 CN-CLIP 模型计算图像与其原始文本描述的对齐分数,剔除低相关性的数据对。
- 多级字幕生成:我们创新性地利用 VLM 统一处理光学字符识别(OCR)和水印检测任务,将识别出的文本信息无缝集成到最终的多级字幕(标签、短语、长描述)中。这一统一策略不仅简化了流程,还极大地丰富了文本描述的细节。

2.2 跨模态向量引擎 (Cross-modal Vector Engine)
我们通过将传统的去重任务重构为一个可扩展的、基于图的社区检测任务,实现了核心创新。我们用高效的 k-近邻(k-NN)搜索替代了传统方法中存在严重性能瓶颈的range_search,从而将处理效率提升至在 8 个 H800 GPU 上每 8 小时处理 10 亿项数据。
这一设计带来了双重战略价值。首先,它通过大规模语义去重,确保了训练数据集的非冗余性,避免了计算资源的浪费。其次,其强大的跨模态检索能力使我们能够主动诊断和修复模型故障。当模型出现生成错误时,我们可以通过检索找到相关的训练数据簇并进行剔除;当发现模型在某些概念上存在知识空白时,又能反向检索以补充相应数据,实现了从被动训练到主动数据增强的转变。
2.3 世界知识拓扑图 (World Knowledge Topological Graph)
该知识图谱是我们数据基础设施的语义骨干,为实现数据的概念广度提供了结构化支持。其构建过程分为三个阶段:
- 初始构建与剪枝:我们首先从维基百科的所有实体及其超链接结构中构建一个初始图。随后,采用双重策略进行剪枝:一是基于中心度(PageRank)过滤掉孤立或低频的概念节点;二是利用 VLM 进行视觉可生成性评估,剔除无法被连贯可视化的抽象概念。
- 增强与结构化:为弥补初始图谱在概念覆盖上的不足,我们利用内部大规模标注图像数据集,从中提取标签。随后,通过自动分层策略对这些标签的嵌入向量进行组织,构建出一个结构化的分类树,极大地扩充了图谱的广度和深度。
- 权重分配与动态扩展:最后,我们结合用户提示中的高频概念和新兴网络热点,对图谱进行手动管理和权重调整,确保其与实际应用场景保持同步。
在应用层面,该图谱是实现语义级别平衡采样策略的核心。我们会计算每个训练数据标签的 BM25 分数,并结合其在图谱中的层次关系,为每个数据点赋予一个语义采样权重,从而指导数据引擎进行更精细化的、分阶段的采样。
2.4 主动策管引擎 (Active Curation Engine)
该引擎将上述静态的数据基础设施转变为一个动态的、自我完善的系统,有效解决了长尾概念分布的挑战。
案例分析:长尾概念“松鼠鳜鱼” 如图 5 所示,“松鼠鳜鱼”是一个典型的长尾概念,它是一种中国菜肴的名称。如果模型缺乏关于这道菜的特定领域训练数据,它可能会依赖组合推理,错误地将“松鼠”和“鳜鱼”两个独立概念结合起来,从而生成荒谬的图像。主动策管引擎通过诊断这类失败案例,触发跨模态检索来补充缺失的领域数据,从而有效解决此类问题。
为实现系统的持续优化,我们建立了一套“人在环路”(Human-in-the-Loop)的主动学习循环机制。如图 6 所示,其工作流程如下:首先,从未标注的媒体池中进行概念和质量平衡采样;接着,由奖励模型和字幕生成器为样本分配伪标签(评分和描述);然后,这些伪标签将通过人机混合验证机制进行审核,被拒绝的样本会由人类专家进行修正;最终,这些经过验证的高质量标注数据被用于迭代优化奖励模型和字幕生成器,形成一个不断提升数据质量和模型能力的良性循环。
这一强大的数据基础设施不仅为 Z-Image 的训练提供了坚实基础,也为 Z-Image-Edit 的编辑数据构建提供了高效支持。这个集成的数据引擎是我们效率至上理念的第一大支柱,确保每一个 GPU 小时都用于处理高价值、非冗余的信息,直接挑战了“性能需要海量未策管数据”的传统观念。
创新模型架构:可扩展单流扩散 Transformer (S3-DiT)
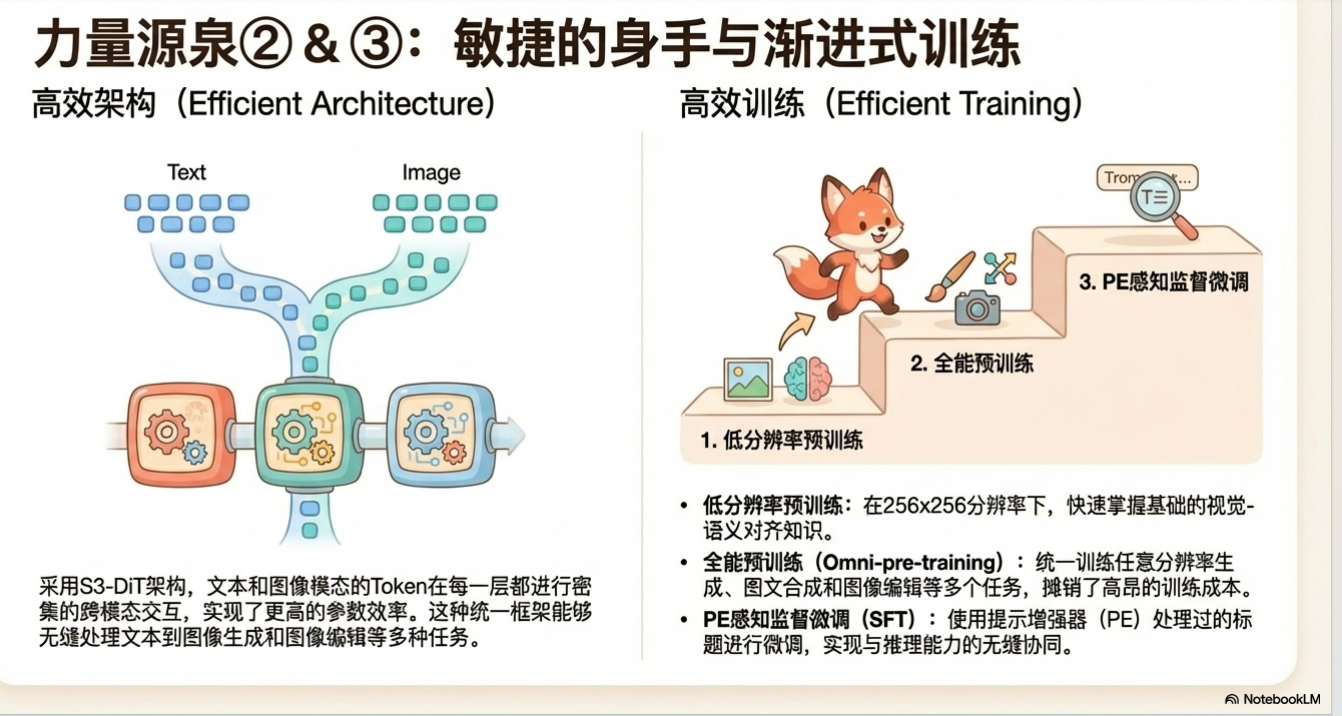
Z-Image 的架构设计以效率与稳定性为核心目标。其核心架构为可扩展单流多模态扩散 Transformer (Scalable Single-Stream Multi-Modal Diffusion Transformer, S3-DiT),其设计灵感来源于大型语言模型中已被证明具有卓越扩展性的仅解码器(decoder-only)架构。
与分别处理文本和图像模态的双流架构不同,S3-DiT 采用了单流设计。它在序列层面将文本令牌、从参考图像中提取的视觉语义令牌以及 VAE 编码的图像令牌进行拼接,形成一个统一的输入序列。这种设计使得不同模态的信息在模型的每一层都能进行密集、深度的交互,从而实现了更高的参数效率。这使得 Z-Image 能够在一个紧凑的 6B 参数规模内,达到甚至超越更大规模模型的性能。
下表总结了 S3-DiT 的关键组件及其战略作用:
S3-DiT 的详细架构配置参数如下表所示:
此外,为了弥补 6B 模型在世界知识和复杂推理能力上的局限,我们引入了提示增强器 (Prompt Enhancer, PE)。PE 是一个外部的、由强大的视觉语言模型(VLM)驱动的模块。它能够在推理时对用户的原始提示进行分析、推理和扩充,将更丰富、更结构化的信息注入到生成模型中。这种设计在不增加 Z-Image 模型本身训练成本的前提下,极大地提升了整个系统的认知与生成能力,实现了效率与性能的最佳平衡。至关重要的是,该外部模块并非事后添加;正如我们将在第 4 节详述,我们的 SFT 过程是明确“PE 感知”的,确保扩散模型学会在无需额外 LLM 训练成本的情况下,优化利用这些增强后的提示。这一高效的架构设计是我们效率至上理念的第二大支柱,证明了巧妙的参数复用和外部认知增强可以媲美纯粹的规模扩展。
高效训练与优化策略
Z-Image 的训练流程是一个为实现效率最大化而精心设计的多阶段、渐进式课程。它始于低分辨率的基础知识学习,逐步过渡到多任务、多分辨率的全能预训练,再通过监督微调、几步蒸馏和强化学习进行精细对齐与优化。本节将详细介绍这些关键阶段。
4.1 渐进式预训练课程
Z-Image 的预训练分为两个核心阶段,旨在以最高效的方式奠定模型的基础能力。
4.1.1 低分辨率预训练
此阶段的目标是在固定的 256x256 分辨率下,让模型高效地学习基础的视觉 - 语义对齐和图像合成知识。根据表 1的数据,这一阶段占据了超过一半的预训练计算资源(147.5K H800 GPU 小时,占预训练总量的 51.6%)。之所以进行如此大的投入,是因为我们发现模型的大部分基础视觉知识,例如对多样化概念的理解和关键的中文文本渲染能力,都是在这一阶段习得的。通过在低分辨率下集中火力,我们为后续更高阶能力的学习奠定了坚实的基础。
4.1.2 全能预训练 (Omni-pre-training)
“全能(Omni)”一词精准地概括了此阶段的三个核心特性,它将多个原本独立的训练任务整合为一个统一的框架:
- 任意分辨率训练:我们设计了一个分辨率映射函数,支持模型在不同分辨率和宽高比的图像上进行训练。这使得模型能够学习跨尺度的视觉信息,减少了因固定分辨率降采样导致的信息损失,显著提升了数据利用效率。
- 文生图与图生图联合训练:我们将图生图任务融入预训练中,利用大规模、弱对齐的自然图像对,为下游的图像编辑任务提供了一个强大的初始化模型。实验证明,这种联合训练方案在赋予模型编辑能力的同时,并未损害其文生图的性能。
- 多层次与双语字幕训练:我们利用 Z-Captioner 生成的双语、多粒度字幕(包括长、中、短三种描述,以及标签和模拟用户提示)和图像的原始元数据进行训练。这种多层次的文本监督实现了广泛的模式覆盖,赋予了模型强大的双语指令遵循能力。
4.2 监督微调 (SFT) 与模型对齐
在 SFT 阶段,我们的战略目标是将模型从预训练阶段形成的广泛生成分布,收敛到一个聚焦于高保真度和精确指令遵循的子流形(sub-manifold)上。我们通过以下三个关键策略实现此目标:
- 通过高质量对齐进行分布收窄:在此阶段,我们将训练课程从预训练时的噪声监督,过渡到由精选的高质量图像和超详细字幕主导。这种严格的监督迫使模型摒弃低质量的生成模式,将其行为从“多样性最大化”转向“质量最大化”,从而严格对齐详细的文本描述。
- 通过标签重采样进行概念平衡:为避免在分布收窄过程中对长尾概念产生灾难性遗忘,我们利用世界知识拓扑图和 BM25 算法进行动态重采样。该机制通过上采样代表性不足的概念,确保模型在收敛到高质量分布的同时,依然保持了丰富的语义多样性。
- 通过模型合并提升鲁棒性:我们从同一个预训练基座上微调出多个具有不同能力偏向的 SFT 变体(例如,一个偏向照片真实感,另一个偏向风格多样性)。最后,通过对这些模型的权重进行线性插值,有效地中和了单一模型的偏见,最终获得一个在多样化提示下表现更稳定、鲁棒性更强的最终模型。
4.3 人类反馈强化学习 (RLHF)
RLHF 阶段的战略目的,是弥合模型的基础生成能力与人类细微、主观的偏好之间的差距。我们首先构建了一个能够从多个维度(如指令遵循度、AI 生成痕迹、美学质量)进行评估的奖励模型,并采用一个两阶段优化策略:首先是基于 DPO 的离线对齐,然后是基于 GRPO 的在线优化。
4.3.1 第一阶段:基于 DPO 的离线对齐
在 DPO 阶段,我们专注于可被客观验证的维度,如文本渲染的准确性和对象计数的正确性。这些维度的正确性判断标准清晰,非常适合利用 VLM 进行自动化评估。我们设计了一个混合流程:首先利用 VLM 程序化地生成大量候选的偏好对(例如,正确渲染文本的图像为“优选”,错误渲染的为“劣选”),然后结合人工验证进行筛选。这种人机协作的方式极大地提升了偏好数据的标注效率和一致性。训练中,我们还采用了从简单到复杂的课程学习策略,并优化了偏好对的选择,以加速模型的收敛。
4.3.2 第二阶段:基于 GRPO 的在线优化
在第二阶段,我们利用奖励模型提供的多维度反馈信号(如真实感、美学、指令遵循度)进行在线优化。通过将这些信号聚合成一个复合优势函数,GRPO 能够对模型进行细粒度的、多目标的优化。这种方法比单一奖励信号的优化更有效,使得模型能够在多个质量维度上实现更好的平衡,从而全面提升生成质量。这一渐进式、多阶段的训练策略是我们效率至上理念的第三大支柱,它通过课程学习和任务整合,确保了模型能力的全面发展,同时最大化了计算资源的利用效率。
推理加速:Z-Image-Turbo 的实现
此阶段的核心目标是将基础 SFT 模型约 100 次函数评估(NFE)的推理时间大幅缩减,以满足实时交互等实际应用需求。我们通过创新的几步蒸馏技术,成功打造了高效的 Z-Image-Turbo 模型。
我们发现,标准的分布匹配蒸馏(DMD)方法在实践中常会导致高频细节丢失和颜色偏移等问题。为解决这些痛点,我们引入了两项关键的改进技术。
5.1 解耦 DMD:解决细节与色彩退化
该方法的核心洞察在于:我们将 DMD 的有效性解耦为两个独立且协同的机制——作为主要驱动力的分类器无关指导增强 (CFG-Augmentation, CA) 分布匹配 (Distribution Matching, DM)。
通过将这两个机制解耦并独立进行优化,我们开发的 Decoupled DMD 框架有效解决了传统 DMD 的痛点。它不仅成功恢复了清晰的图像细节和色彩保真度,甚至在某些情况下,其视觉效果超越了原始的多步教师模型,实现了速度与质量的双重提升。
5.2 DMDR:结合强化学习增强模型能力
将强化学习(RL)直接应用于生成模型时,一个常见的风险是“奖励黑客”(reward hacking),即模型为了最大化奖励分数而生成视觉上不合逻辑或失真的图像。
我们提出的 DMDR(Distribution Matching Distillation meets Reinforcement Learning)巧妙地解决了这一问题。它利用了从 Decoupled DMD 中洞察到的分布匹配(DM)项的强大正则化功能,将其作为内在约束来防止 RL 优化过程中的奖励黑客行为。这种协同作用使得 Z-Image-Turbo 在通过 RL 提升美学对齐和语义忠实度的同时,能够保持严格的生成稳定性。
如图 13所示,Decoupled DMD 和 DMDR 的组合效果显著。Z-Image-Turbo 实现了仅需 8 步的超快推理,其生成质量不仅与 100 步的教师模型相当,甚至在感知质量和美学吸引力上更胜一筹。
全面性能评估
为了全面、客观地验证 Z-Image 系列模型的能力,本节将展示其在多个人类偏好评估平台和权威定量基准测试中的表现,并与业界顶尖的开源及闭源模型进行直接对比。
6.1 人类偏好评估
相比于自动化指标,基于 Elo 评分系统的大规模人类评估能更真实地反映用户对生成图像质量的感知。我们在 Artificial Analysis AI Arena 和 Alibaba AI Arena 这两个独立的公开评测平台上对 Z-Image-Turbo 进行了测试。
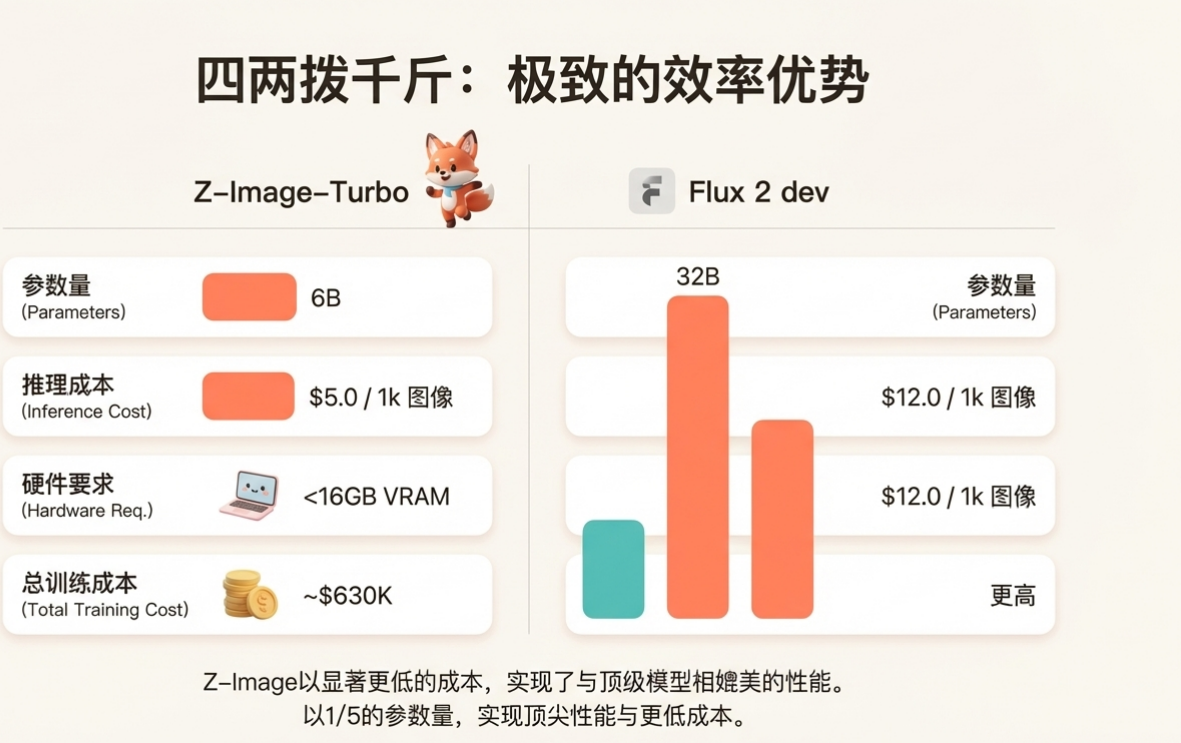
综合两大平台的结果,Z-Image-Turbo 表现卓越。在 Artificial Analysis AI Arena 的排行榜上,它不仅在所有开源模型中排名第一,并且在总榜中位列第八。值得注意的是,在排名前十的模型中,Z-Image-Turbo 以6B 的参数量和每千张图像 5.0 美元的推理成本,成为效率最高的模型。这一发现在 Alibaba AI Arena 的评测中得到进一步验证,Z-Image-Turbo 在该平台位列总榜第四,同样是开源模型中的第一名。
此外,我们还进行了一项与 Flux 2 dev(32B 参数)的直接对比用户研究。如表 4所示,在 222 个用户风格的提示词测试中,Z-Image 的“优或同等”(G+S)率高达87.4%,表现出显著优势,而其参数量仅为对方的五分之一。
6.2 定量与定性评估
我们在多个权威的定量基准测试中对 Z-Image 进行了评估,结果如下表所示:
在定性评估方面,如图 18 至图 26所示,Z-Image-Turbo 在逼真照片生成(人物特写、场景拍摄)和双语文本渲染(复杂段落、海报设计)等任务中,其视觉质量可与 Nano Banana Pro 等顶尖闭源模型相媲美,并优于其他主流开源和闭源模型。
同时,图 27 至图 31展示了 Z-Image-Edit 强大的指令遵循编辑能力,以及提示增强器(PE)在注入世界知识(如根据诗名生成符合意境的插画)和实现复杂逻辑推理(如解决鸡兔同笼问题)方面的关键作用。
结论
Z-Image 系列模型是对当前生成模型领域“不计成本扩展”范式的一次成功挑战。我们证明了通过对四大支柱——数据、架构、训练、推理——进行系统化的端到端优化,一个 6B 参数量的模型同样可以达到世界一流的性能,而其训练成本(314K H800 GPU 小时)远低于行业平均水平。
我们的工作产生了两个具有高度实用价值的模型:Z-Image-Turbo,它实现了亚秒级的推理速度,并能适配主流消费级硬件(<16GB VRAM),极大地降低了高质量生成模型的应用门槛;以及Z-Image-Edit,一个通过我们高效的全能预训练范式衍生的、具备强大指令遵循能力的编辑模型。
总而言之,Z-Image 不仅提供了一系列性能卓越的开源工具,更重要的是,它为社区提供了一套经过验证的、可行的实践蓝图,展示了如何开发经济、易用且性能卓越的下一代生成模型。