阿里巴巴 Qwen 团队推出了开创性的 Qwen3-Omni 多模态大模型。这款模型旨在重新定义 AI 与世界的互动方式,它原生支持端到端的多模态处理,能够同时理解和生成文本、图像、音频和视频内容,并以自然的语音和文本形式进行实时流式响应。
架构创新驱动性能飞跃
Qwen3-Omni 并非简单地堆叠多模态能力,其内部进行了显著的架构升级。它采用了基于 MoE 的 Thinker–Talker 设计,辅以 AuT 预训练,这为模型提供了强大的通用表征能力。
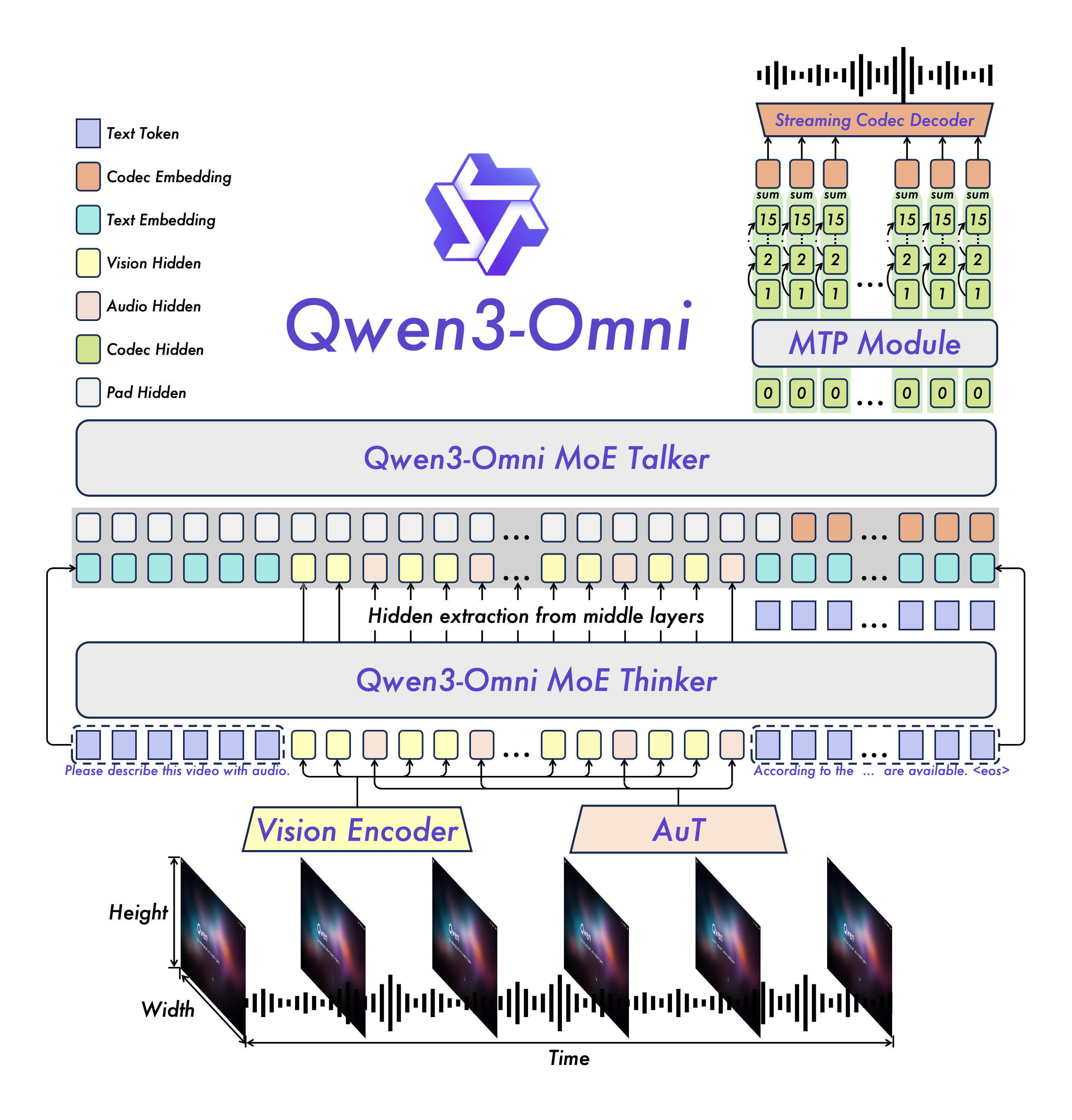
此外,多码本设计将延迟降至最低,确保了实时交互的流畅性。这种设计哲学让模型在处理复杂多模态输入时,仍能保持卓越的效率和性能。
全方位性能表现
Qwen3-Omni 在多个维度展现出领先的实力。在 36 个音频和音视频基准测试中,它在 22 个上达到行业领先水平,并在 32 个上实现开源 SOTA 表现,甚至与 Gemini 2.5 Pro 和 GPT-4o 等闭源模型在 ASR、音频理解和语音对话性能上媲美。
值得一提的是,其原生多模态支持在增强音视频能力的同时,并未牺牲纯文本和图像任务的性能。模型还支持 119 种文本语言、19 种语音输入语言和 10 种语音输出语言,覆盖范围极广。
突破性实时交互体验
以往的多模态模型在实时性和自然交互方面常有瓶颈。Qwen3-Omni 通过其低延迟流式响应和自然的轮流对话机制,彻底改变了这一局面。
这意味着 AI 助手可以像真人一样,在接收到用户指令或提问后,几乎立即给出文本或语音回复,极大地提升了用户体验。同时,通过灵活的系统提示词,开发者可以对模型的行为进行精细控制,打造高度定制化的 AI 应用。
应用展望与开源贡献
Qwen3-Omni 的应用潜力巨大,从智能客服到虚拟伙伴,从内容创作到教育辅助,无所不包。
例如,其衍生模型 Qwen3-Omni-30B-A3B-Captioner 就填补了开源社区在通用、高细节、低幻觉音频描述模型方面的空白。
Qwen3-Omni 的开源(可在 Hugging Face 平台获取)为 AI 社区提供了一个强大的工具,推动了多模态 AI 研究与应用的边界,加速了未来智能交互模式的到来。
开发者可以通过 Hugging Face Transformers 或 vLLM 等工具轻松部署和使用 Qwen3-Omni 模型,并利用其提供的qwen-omni-utils工具包更便捷地处理各类音视频输入,开启全新的多模态应用探索。