
Rhymes AI 最新推出了 Aria 模型 它以业界首个开源多模态原生 Mixture-of-Experts MoE 模型的姿态 重新定义了 AI 领域的交互与理解范式。Aria 的核心在于其能够同时处理文本 图像 视频以及代码等多种模态输入 并在这些任务上展现出卓越的性能。
多模态原生性能突破
传统的理解中 多模态模型可能只是将不同类型的数据简单拼接 Aria 则更进一步 它所强调的“多模态原生”意味着单一模型在理解多种输入模态 如文本 代码 图像 视频时 能够达到或超越同等容量下模态专用模型的强大能力。这并非简单的兼容 而是深度融合与优化。
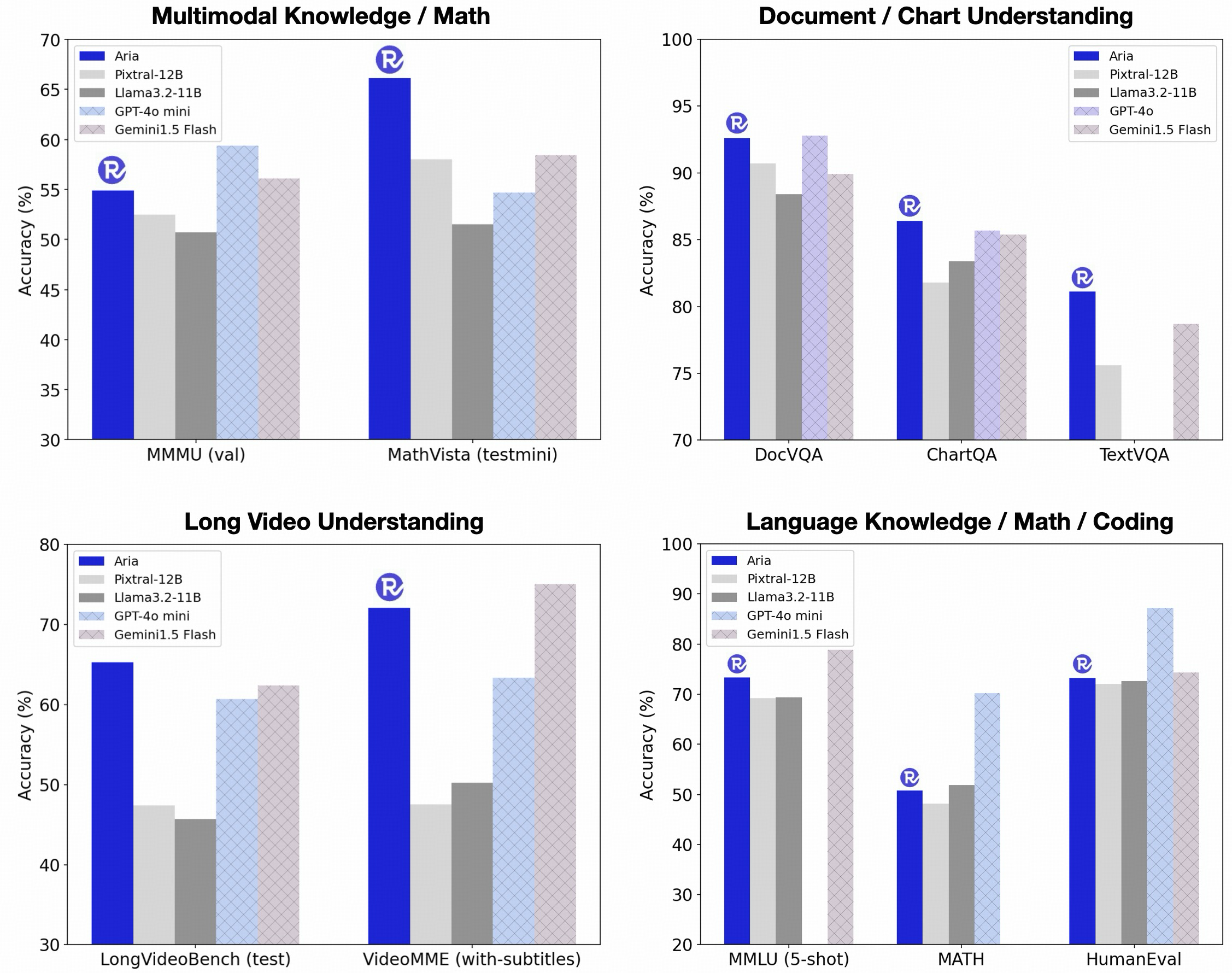
Aria 在多项基准测试中展现出领先地位 例如在多模态 语言和编码任务上超越了 Pixtral-12B 和 Llama3.2-11B 等开源模型。更令人印象深刻的是 它甚至能与 GPT-4o Gemini-1.5 等闭源模型在文档理解 图表阅读 场景文字识别和视频理解等任务上进行有效竞争。Aria 的参数效率极高 凭借 MoE 架构 每次推理仅激活 3.9 亿参数 显著优于那些需要完全激活参数的模型。
卓越的长上下文理解能力
处理长序列多模态数据是真实世界应用中的一大挑战 例如带有字幕的长时间视频或复杂文档。Aria 在这方面表现出色 其长达 64K token 的多模态上下文窗口 赋予了它处理复杂输入的能力。这意味着 Aria 能够在短短 10 秒内为长达 256 帧的视频生成描述。
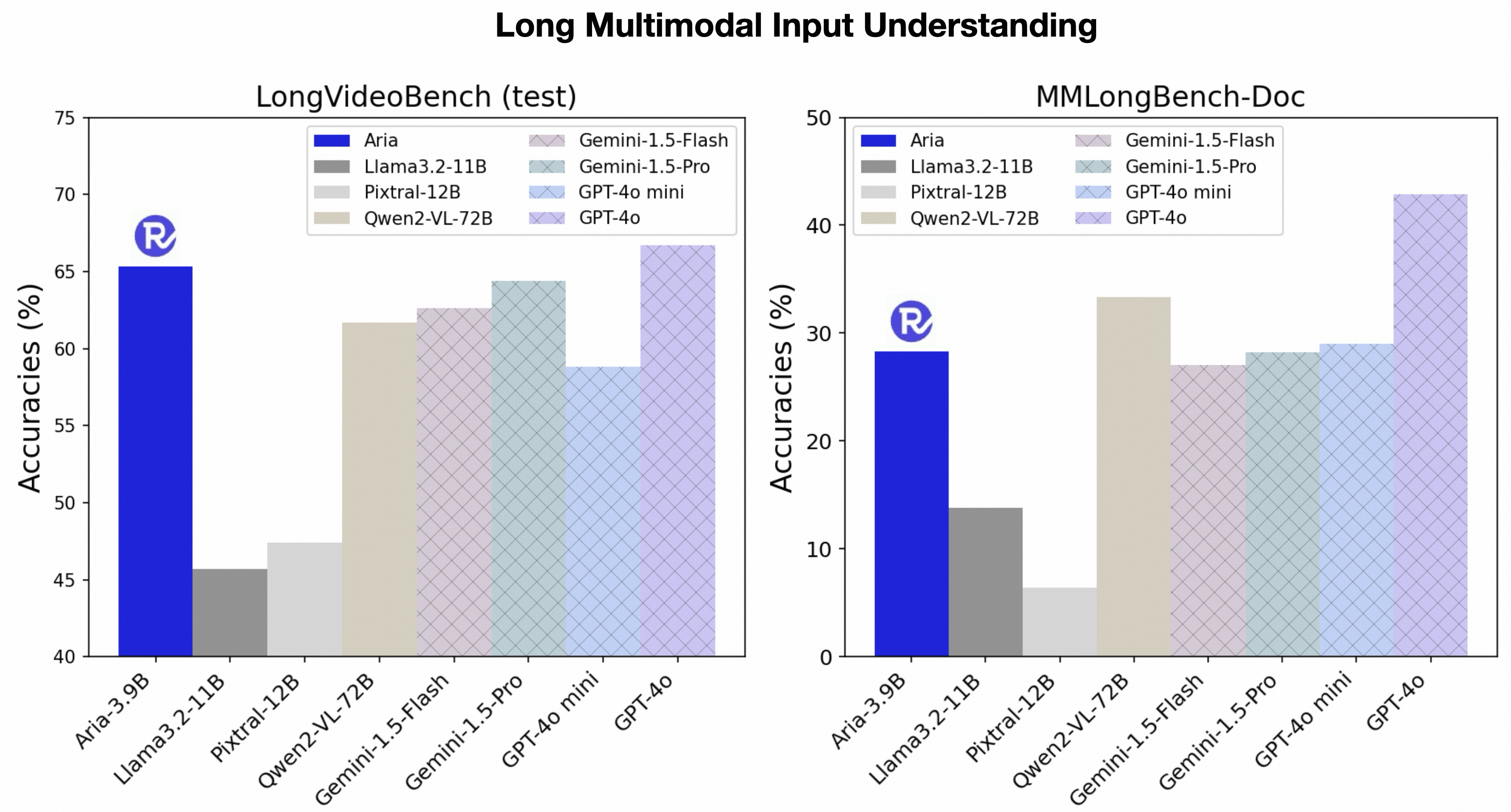
在长视频理解上 Aria 甚至超越了 GPT-4o mini 在长文档理解上则优于 Gemini-1.5-Flash 这使得它在处理海量多模态数据时更加高效且准确。
精准的指令遵循
模型理解并执行用户指令的能力至关重要。Aria 在多模态和语言输入下的指令遵循能力表现突出 在 MIA-Bench 和 MT-Bench 等主流评测基准上 均优于现有的顶级开源模型。

创新的多模态原生训练
Aria 的强大性能源于其独特的四阶段训练流水线 确保模型逐步学习新能力的同时 保留并增强现有知识:
- 语言预训练 使用 6.4 万亿文本 token 训练 MoE 解码器 建立通用世界知识。
- 多模态预训练 结合 1 万亿高质量语言 token 和 4000 亿多模态 token 赋予模型广泛的多模态理解能力。
- 长上下文多模态预训练 将模型上下文窗口扩展至 64K token 处理超过 330 亿的长序列文本和多模态 token。
- 多模态后训练 通过 200 亿高质量数据微调 提升模型的问答和指令遵循能力。
模型架构与开发生态
Aria 的架构包括一个支持可变图像尺寸和长宽比的视觉编码器 以及一个多模态原生的 MoE 解码器。每个 MoE 层包含 66 个专家 其中 2 个专家共享以捕获通用知识 另外 6 个专家由路由器模块根据输入动态激活 以捕获特定于模态或任务的知识。
Rhymes AI 提供了一整套开发者工具和资源 包括开放的模型权重 Hugging Face Rhymes AI Aria 代码库 GitHub rhymes-ai Aria 和详细的技术报告 所有这些都基于 Apache 2.0 许可证 旨在促进社区协作和创新。
洞察与未来展望
Aria 的推出不仅仅是又一个多模态模型 更是对“多模态原生”概念的一次深刻实践。它通过 MoE 架构实现了性能与效率的平衡 证明了稀疏激活在构建强大通用 AI 模型中的巨大潜力。这种“原生”特性和卓越的长上下文处理能力 预示着 AI 在理解和处理真实世界复杂信息方面迈出了坚实的一步。
Rhymes AI 相信 AI 的未来在于多模态 高效且无缝集成于日常体验之中。Aria 只是开端 期待与研究人员 开发者共同塑造 AI 的未来。